@huanghaian
2020-09-27T00:48:57.000000Z
字数 10857
阅读 2438
mmdetection最小复刻版(四):独家yolo转化内幕
mmdetection
0 摘要
github地址:https://github.com/hhaAndroid/mmdetection-mini
欢迎star和提出改进意见。
本文深入讲解将darnket模型权重转化为mmdetection中模型和权重以及yolov5转化为mmdetection的心路历程,其中有泪、有汗还有无尽的心酸,不过好在最好都解决了。我想全网应该没有比我更细的解读了吧。
在这其中,踩了很多坑,我会一一说明。只要掌握了我这套转化流程,那么任何darknet中的模型或者yolov5代码中的模型,你都可以自己转化到mmdetection-mini中。那么为何要转化呢?好处是啥?我个人觉得应该可以归纳如下:
(1) 彻底掌握算法模型
darknet采用文件cfg模式来构建模型,好处是不用会写代码也可以写模型,坏处也比较明显:
1. 切分过细,从头构建大模型会累死,且容易出错
2. 采用索引形式来进行跳层连接,不太好把握结构
3. 配置过长,无法把握网络设计的思想精华
4. 不好调试,各层的连接关系在forward时候才能知道,比较麻烦
5. 纯c写的,我c和c++语言只会皮毛
熟悉darknet的人应该都有体会。而yolov5的github代码不可谓不乱(大家知道的),虽然他是pytorch写的。但是在构建模型时候也是参考了darknet的cfg思想,虽然开发比较快,但是对于用户学习来说,不太友好。
而一旦转化为mmdetection框架来构建pytorch模型,那么结构就一目了然了,调试要多方便有多方便,哪里不会bug哪里。轻松愉快
(2) 能够掌握所有细节
很多时候,自己不写一遍,其实不能算是掌握了,浮于表面。如果我能够将darknet模型或者yolov5模型转化到mmdetection中,并且评估指标mAP完全一致,那么我就必须理解每一个cfg内容,理解每一个细节包括模型结构、bbox编解码、数据处理逻辑等等。这可以督促我分析更加底层的东西,对于学习来说是一个不错的思路
(3) 所有代码统一到mmdetection-mini中
目前主流的darknet系列和yolov5系列,以及可能以后新出了的模型,都可以全部在mmdetection-mini中进行训练和测试,特别是基于darknet或者yolov5权重进行微调训练。不过目前我只完成了模型和测试步骤,从头训练部分还没有完成,这将是一个长期任务。
本来想这篇文章把yolov5心酸历程也写进去的,但是后来发现文字太多了,就放到下一篇吧!
1 darknet系列转化过程
由于yolov2比较老了,性能和速度都无法和yolov3、tiny-yolov3相比,故这里不包括yolov2,具体是yolov3/yolov4以及tiny-yolo3/tiny-yolov4,一共4个模型。
刚开始我对darknet不熟悉,只是看cfg而已,darknet源码是完全没看过(当然现在也没有看过)。如果你想找pytorch版本的yolo系列,github当然也是不计其数。搜索yolov3,带有pytorch的star最多的是eriklindernoren/PyTorch-YOLOv3库,但是一旦打开model.py,如下所示:

很明显,他也是直接解析yolov3.cfg来构建模型的。而前面说过我比较不喜欢这个做法,所以这种方式我直接就放弃了。
然后我找到了腾讯优图的目标检测库https://github.com/Tencent/ObjectDetection-OneStageDet,在当时他就已经实现了yolov2和yolov3系列了,他的模型构建就是标准的pytorch写法,通俗易懂,所以我一直沿用了这种做法。
有了参考写法,再配合darknet里面的cfg可以采用https://lutzroeder.github.io/netron/软件直接可视化网络结构,那么就可以动手了。通过netron可视化网络结构,可以非常容易看出网络结构以及检查自己写的代码是否正确,起到了极大的帮助。
我首先把ObjectDetection-OneStageDet代码看了一遍并且跑了下,基本上了解了细节。考虑到yolov3模型太大了,不好搞,所以先拿tiny-yolov3开刀,一旦整个流程通了,那么新增yolov3那还不是手到擒来。
1.1 第一步:构建模型
构建tiny-yolov3模型,那实在是太简单了,因为结构非常简单,为了快速实现,我们可以模仿腾讯优图做法,如下所示,地址为https://github.com/Tencent/ObjectDetection-OneStageDet/blob/master/vedanet/network/backbone/_tiny_yolov3.py:

我开始也是按照这个写法写的,对应框架代码里面的mmdet/models/backbones/rr_tiny_yolov3_backbone.py。tiny-yolov3是两个输出尺度,而不是三个,下采样率为32和16。为了检查代码是否正确,我还使用了darknet的cfg文件进行可视化。
显示backbone已经写好了,下面就是构建head了。head部分也非常简单,就是对stride=32的分支采用上采样层然后和stride=16的特征层进行concat操作即可:
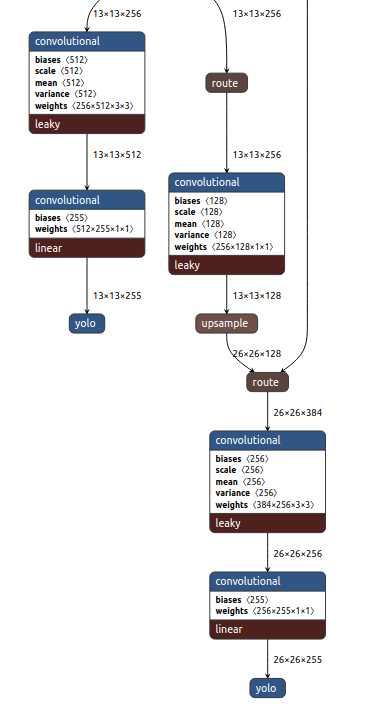
整个模型就构建好了。
1.2 第二步:权重转化
构建模型是非常容易的,可以直接抄腾讯优图的代码,但是权重转化就没那么容易了,需要自己搞定。要将tiny-yolov3权重转化到mmdetection-mini中,需要做以下几件事情:
(1) 熟悉darknet权重保存格式.weights
(2) 权重转化为pytorch结构
对于darknet保存的weigts的格式解析,在网上有很多,我梳理了下大概就理解了。对应代码在mmdet/models/utils/brick.py里面的WeightLoader类中。整个权重文件其实是一个numpy矩阵,前几个字节是一些版本以及head信息,后面开始才是权重,其格式为:
(1) 如果仅仅是卷积层,那么存储格式是先bias,然后采用卷积权重参数
(2) 如果是conv+bn+激活,那么存储格式是先bn的bias,weights,然后采用卷积的bias,weights
明白这两个就可以了,解析时候必须要按照这个格式来读取,否则后果非常严重,后面会细说。并且必须以conv+bn+激活的组合格式来解析,因为darkent的最小配置单位就是这个,如果你在pytorch构建模型时候,把conv和bn分开写,那么解析难度会增加非常多,注意看我的yolo系列的最小模型单位是Conv2dBatchLeaky或者Conv2,目的就是为了解析方便。
理解了上面的流程,就大概知道咋弄了,但是为了转换方便以及转换本身就是仅仅运行一次即可,不需要每次跑训练都转换一次,故我把tiny-yolov3在tools/darknet/tiny_yolov3.py里面copy了一遍,模型是一样的,主要目的是:任何人先用这个脚本转换一下模型,保存为mmdetection-mini能够直接读取的格式,然后在训练和测试时候就直接用转换后的模型即可,而不再需要读取darknet原始weights权重。
tools/darknet/tiny_yolov3.py里面采用了WeightLoader类来加载darknet权重:

注意必须实现__modules_recurse方法,该方法的作用是遍历复杂模型的每个子模块,一定要遍历到最小单位即conv+bn+激活或者conv,因为WeightLoader类的输入必须是这两个,否则无法解析。
下载darknet的tiny-yolov3权重,替换tiny_yolov3.py的权重路径,运行即可。
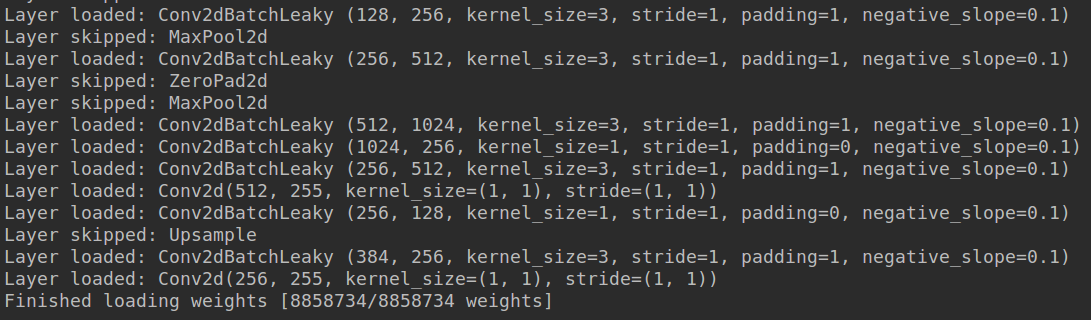
打印信息如下,跑到这里,你需要检查两个部分:
(1) 最后一行[8858734/8858734 weights],如果两者不相等,说明你代码写错了,因为权重居然没有全部导入
(2) 检查Layer skipped的层是否是没有参数的层,如果跳过了带参数层,那么你一定写错了
到目前为止,一切都搞定了,tiny-yolov3的所有权重全部导入了,美好的一比,如果你这样认为,那你就打错特错了。
还有一个收尾的工作要做,这里保存的pth模型和mmdetection-mini里面的算法虽然一样,但是模型的key是不一样的,为了能够在mmdetection-mini中直接跑,你还需要替换key,对于tiny-yolov3来说,稍微比较简单,如下:
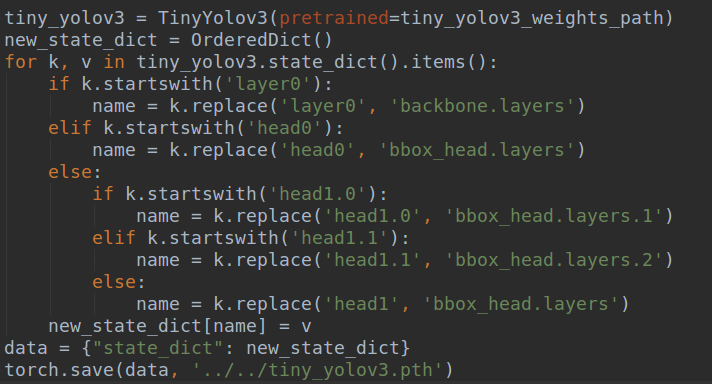
如果你想说我咋知道哪些key要替换?我的做法是:先去mmdetection-mini中把模型的所有key保存下来,然后和这里的key比对下就行了。工作虽然繁琐一些,但是还是能接受的。
到这里为止,保存的pth就可以真的在mmdetection-mini中跑起来了。美好的一比,如果你这样认为,那你又打错特错了。
1.3 第三步: 结果检查
前面都是准备工作,模型也得到了,最核心的是验证你转化的模型进行推理时候效果对不对,可以从单张图预测可视化和验证集计算mAP两个方面验证。
先对单张图进行推理,看下预测效果对不对吧。此时你可以发现,基本上啥都预测不出来。这一步才是最要命的,搞了半天,各种确认,最后发现没有效果?这个地方坑很多,我开始被坑了一天。出现这个原因的主要问题是还是对darknet框架不熟悉。下面我说下错误原因,有好几个。
(1) 模型构建顺序不能错
因为darknet里面的权重是没有开始和结尾的numpy数组,你只能自己去切割数组,这就会带来一个问题:假设原始模式是ConvBN_1+ConvBN_2,但是你在pytorch里面写成了ConvBN_2+ConvBN_1,那么上面写的整个过程都是不会报错而且是正常的,但是实际上你写错了。
例如你可以在tools/darknet/tiny-yolov3.py里面把:
self.layer0 = nn.ModuleList([nn.Sequential(layer_dict) for layer_dict in layer0])
self.head0 = nn.ModuleList([nn.Sequential(layer_dict) for layer_dict in head0])
顺序调换,写成:
self.head0 = nn.ModuleList([nn.Sequential(layer_dict) for layer_dict in head0])
self.layer0 = nn.ModuleList([nn.Sequential(layer_dict) for layer_dict in layer0])
就是这么简单,你再跑脚本,打印也是完全正确的,但是实际你错的非常严重,因为权重切割错了。
总的来说就是darkent里面的权重,保存顺序完全按照cfg从上到下的顺序,而不是网络实际运行顺序。如果你的解析顺序不正确,那么即使网络结构写对了,导入的权重也可能是错误的,因为不会报错。
(2) head模型顺序不能错
要说明这个问题,tiny-yolov3说明不了问题,需要上大模型yolov3。yolov3是典型的darknet53+fpn+head的结构,一般我们在构建模型时候,都是按照mmdetection-mini的做法来写,例如head部分我们的写法是:
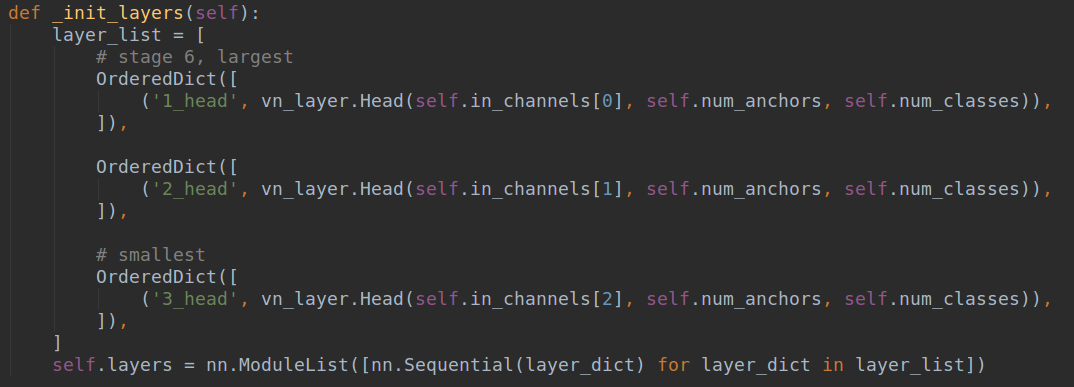
这种写法本身没有问题,但是对于导入darknet权重来说就不行了,因为yolov3里面的配置是:
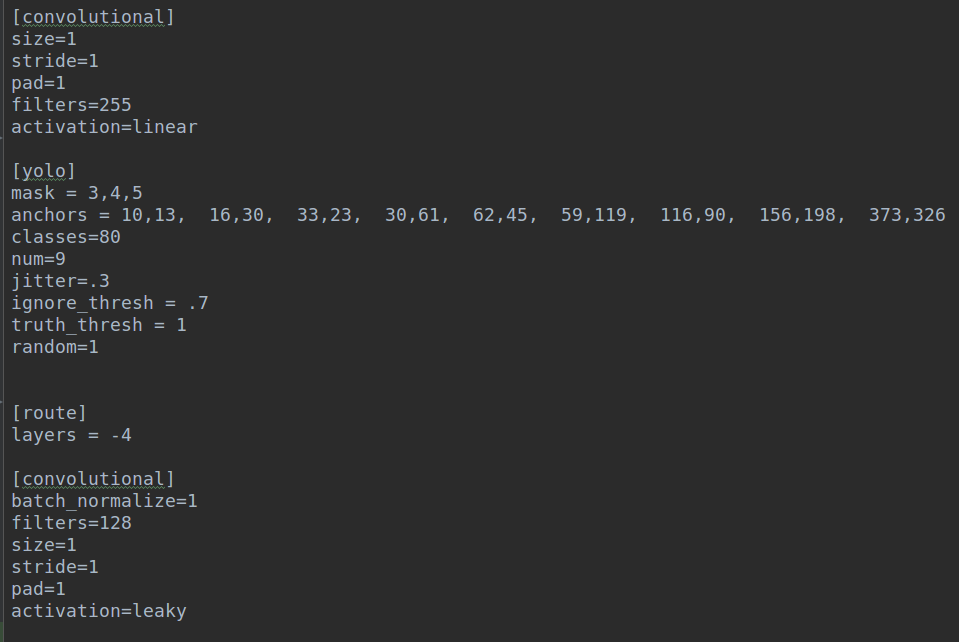
yolo层其实就是输出层,他的三个输出层其实不是放在最后,而是插在中间的,也就是说他的权重保存模式是backbone+卷积+输出1+fpn融合+输出2+fpn融合+输出3,而是通常的backbone+fpn+输出1+输出2+输出3。
这种结构导致我们的pytorch模型构建瞬间复杂很多,大家仔细看tools/darknet/yolov3.py里面的代码拆分非常细,原因就是如此:
self.layers1 = nn.ModuleList([nn.Sequential(layer_dict) for layer_dict in layer_list1])
self.head1 = nn.ModuleList([nn.Sequential(layer_dict) for layer_dict in head_1])
self.layers2 = nn.ModuleList([nn.Sequential(layer_dict) for layer_dict in layer_list2])
self.head2 = nn.ModuleList([nn.Sequential(layer_dict) for layer_dict in head_2])
self.layers3 = nn.ModuleList([nn.Sequential(layer_dict) for layer_dict in layer_list3])
self.head3 = nn.ModuleList([nn.Sequential(layer_dict) for layer_dict in head_3])
顺序是layers1+head1+layers2+head2+layers3+head3,任何一个顺序都不能乱,否则都是错误的。
(3) concat一定要注意顺序
即使前面的你都弄好了,你依然可能出错,因为concat不管你是a+b,还是b+a,代码都不会报错,但是实际你错了,这个要非常小心,一定要执行检查,不要concat顺序反了。
我开始没有想到这个问题,在测试tiny-yolov3时候,总是发现有一层的预测是正确的,但是另一个层是错误的,当时想了很久都搞不懂,最后才想到可能是concat的问题,最后调换下顺序就好了。
这个问题出现的原因依然是没有仔细研究cfg,参数如下:
[route]
layers = -1, 8
这个就表示是将最后一层输出和第8个输出层结果进行concat,顺序是[-1,8]。
(4) tiny-yolov3里面MaxPool2d写错了
这个问题也被坑了很久,注意是因为腾讯优图里面写错了(他现在也是错误的),我当时没有想到会错,所以一直没有怀疑这个,查了大概1天才发现,被坑的很惨。tiny-yolov3的cfg中maxpool有一个地方非常奇怪:
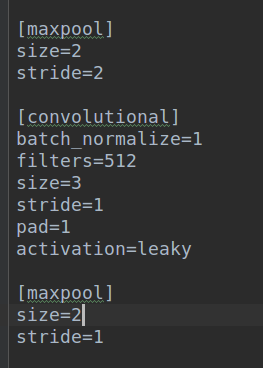
注意看这两个maxpool参数,第一个maxpool是标准写法,但是第二个maxpool的stride=1,而不是2,腾讯优图里面写的是:
('11_max', nn.MaxPool2d(3, 1, 1)),
这个明显不是cfg里面的写法。对于腾讯优图复现的来说,可能影响很小,因为他根本就没有导入tiny-yolov3权重,所以改了下没有问题,但是我就不能这么搞了。正确的写法应该是:
('10_zero_pad', nn.ZeroPad2d((0, 1, 0, 1))),
('11_max', nn.MaxPool2d(2, 1)),
先pad,然后在maxpool。当时写错情况下预测现象是预测的bbox会存在偏移即预测正确,但是bbox偏掉了。我开始一直怀疑是我bbox还原代码写错了,因为解码错误也很出现Bbox偏移,最后才发现是这个参数,好惨啊!
这个坑,被坑了很久。
(5) bn和激活参数设置不一致
这个也要非常小心,一定要执行看下bn和激活函数参数设置,否则影响很大。例如LeakyReLU的激活参数是0.1,而不是默认的0.01。你最好先检查这个参数。
(6) 图片输入处理流程不一致
假设输入是416x416,其测试流程是先进行pad为正方形,然后resize,但是需要注意其resize图片是采用最近邻,而框架中是线性插值。实际测试表明差距还是比较大,会导致一些框丢失,可能darknent训练时候采用的是最近邻。
而且,我原来写的代码一直都是bgr输入,测试时候发现效果总是不太对,后来才发现darknet网络输入是rgb,且直接除以255进行归一化。
注意:我在mmdetection-mini中测试依然用的是线性插值模式,没有修改,而且数据前处理逻辑也没有完全按照darknet来做,而且沿用mmdetection的处理逻辑,如果你是用权重来微调,我认为影响很小的。
以上就是全部坑了,我踩过的坑全部记录下了,希望对大家有点帮助。下面针对各个模型说明下一些细节。
2 yolov3特殊说明
按照前面的流程可以转换darknet中的所有模型。对于yolov3而言,有些细节说明下:
(1) __modules_recurse函数
前面说过darknet权重的最小单位是ConvBnAct,故需要通过自己递归模块,直到符合条件为止。故对于自定义模块例如HeadBody,你需要在Yolov3类开头定义custom_layers,然后在__modules_recurse递归。如果子模块里面还包括非最小模块,则内部模块也要加入,否则依然无法导入:
custom_layers = (vn_layer.Stage, vn_layer.Stage.custom_layers, vn_layer.HeadBody, vn_layer.Transition,
vn_layer.Head)
例如上面的Stage模块,内部还有定制模块StageBlock,那么也要加入。

如果你不加入,那么运行时候会看到很多conv层都被跳过了。
并且由于yolov3的head写法,导致在模型的key替换时候会稍微麻烦一些,这种问题只需要细心点就可以解决,不难。
对于我来说,只要搞定了tiny-yolov3和yolov3,那么其余模型都可以很快就转换成功。
3 tiny-yolov4特殊说明
在tiny-yolov4中引入了一种新的配置:
[route]
layers=-1
groups=2
group_id=1
groups=2表示将该特征图平均分成两组,group_id=1表示取第1组特征。实际上就是:
x0 = x[:, channel // 2:, ...]
其他地方就没啥要注意的了,按照cfg可视化写就行。
4 转化性能说明
对应的文档在docs/model_zoo.md中,这里写下详情。
在给出指标前,有一个地方一定要理清楚,否则各种指标你会看起来很懵。
coco数据集划分方法有两种:coco2014和coco2017,在https://cocodataset.org/#download里面有说明,大概就是
MSCOCO2014数据集:
训练集: 82783张,13.5GB, 验证集:40504张,6.6GB,共计123287张
MSCOCO2017数据集:
训练集:118287张,19.3GB,验证集: 5000张,1814.7M,共计123287张
数据集应该还是那些,但是划分原则改变了。在coco2014中验证集数据太多了,很多大佬做实验时候其实不是这样搞的,参考retinanet论文里面的说法:训练集通常都是train2014+val2014-minival2014,也就是从val2014中随机挑选5000张图片构成minival数据集,其余数据集全部当做训练集。论文中贴的指标都是test_dev2014数据,是本地生成json,然后发送给coco官方服务器得到mAP值,本地是没有label的。
基于大家通常的做法,coco官方在2017年开始也采用了这种切分方式,也就是原来是大家各种随机切分val得到minival,但是现在官方统一了minival,让大家数据完全一样,对比更加公平。故在2017年开始,划分就变成train2014+val2014-minival2014=train2017,minival2014=val2017,测试集应该没咋变。
也就是是说yolov3论文中的指标都是test_dev2014的结果,训练是train2014+val2014-minival2014。一定要注意minival2014是各自随机切分的,也就是minival2014虽然图片数和val2017一样,但是有可能val2017的数据有部分数据其实在train2014+val2014-minival2014中。
4.1 测试前置说明
(1) mmdetection中贴的指标都是在val2017上面测试的,而darknet中提供的指标都是test_dev2014上面的,不具有非常强的对比性,因为val2017可能出现在darknet的训练集中,而且val数据集一般会比test_dev简单一些
(2) mmdetection中数据处理流程还是沿用mmdetection的,而不是darknet一样的处理流程,会有点点差距,而且阈值也不太一样,但是对于最终结果不会差距很大或者说没有关系(只要证明我的代码没有问题就行)。在后面的yolov5中我进行了深入分析,可以保证处理流程完全一致,这里就暂时不写了。
4.2 yolov3指标
- 权重下载链接: https://github.com/AlexeyAB/darknet
- 对应配置: https://raw.githubusercontent.com/AlexeyAB/darknet/master/cfg/yolov3.cfg
- darknet(test_dev2014): 416x416 55.3% mAP@0.5 (31.0 mAP@0.5:0.95) - 66(R) FPS - 65.9 BFlops - 236 MB
- darknet(val2017): 416x416 65.9 mAP@0.5
- mmdetection(val2017): 416x416 66.8 mAP@0.5 (37.4 mAP@0.5:0.95) -248 MB
darknet(test_dev2014)是官方论文指标,而darknet(val2017)是我直接用darknet框架测试val2017数据得到的指标,而mmdetection(val2017)是mini框架转换后进行测试的指标。可以发现指标会更高一些,原因应该是后处理阈值不一样。
这里就可以完全确定代码肯定没有问题了。
4.3 yolov4
- 权重下载链接: https://github.com/AlexeyAB/darknet
- 对应配置: https://raw.githubusercontent.com/AlexeyAB/darknet/master/cfg/yolov4.cfg
- darknet(test_dev2014): 416x416 62.8% mAP@0.5 (41.2% AP@0.5:0.95) - 55(R) FPS / 96(V) FPS - 60.1 BFlops 245 MB
- darknet(test_dev2014): 608x608 65.7% mAP@0.5 (43.5% AP@0.5:0.95) - 55(R) FPS / 96(V) FPS - 60.1 BFlops 245 MB
- mmdetection(val2017): 416x416 65.7% mAP@0.5 (41.7% AP@0.5:0.95) -257. MB
- mmdetection(val2017): 608x608 72.9% mAP@0.5 (48.1% AP@0.5:0.95) -257.7 MB
注意: yolov4的anchor尺寸变了,我开始没有发现导致测试mAP比较低,不同于yolov3,下载的权重是608x608训练过的,测试用了两种尺度而已
4.4 tiny-yolov3
- 权重下载链接: https://github.com/AlexeyAB/darknet
- 对应配置: https://raw.githubusercontent.com/AlexeyAB/darknet/master/cfg/yolov3-tiny.cfg
- darknet(test_dev2014): 416x416 33.1% mAP@0.5 - 345(R) FPS - 5.6 BFlops - 33.7 MB
- mmdetection(val2017): 416x416 36.5% mAP@0.5 -35.4 MB
注意: yolov3-tiny.cfg中最后一个[yolo]节点,mask应该是 1,2,3,而不是github里面的0,1,2
4.5 tiny-yolov4
- 权重下载链接: https://github.com/AlexeyAB/darknet
- 对应配置: https://raw.githubusercontent.com/AlexeyAB/darknet/master/cfg/yolov4-tiny.cfg
- darknet(test_dev2014): 416x416 40.2% mAP@0.5 - 371(1080Ti) FPS / 330(RTX2070) FPS - 6.9 BFlops - 23.1 MB
- mmdetection(val2017): 416x416 37.9% mAP@0.5 (19.2 mAP@0.5:0.95) -24.3 MB
注意:更低的原因应该是该配置里面有一个scale_x_y = 1.05参数不一样,目前没有利用到,我后面会解决这个问题。
由于我的测试集是val2017,而不是test_dev2014,所以我提供的mAP会高一些,这是非常正常的。
5 总结
我提供的代码应该没有大问题,但是有些细节可能有点问题,我后面会慢慢完善。希望大家看完这篇文章能够学会:
(1) darknet的cfg可视化方式;权重存储方式
(2) 对于以后任何darknet模型,都可以仅仅用1个小时就转换到mmdetection中进行微调训练
(3) darknet训练、测试方式和mmdetection中的区别
我后面会去研究darknet的具体实现过程,争取理解的更加透彻。还有一些不完善的地方,欢迎提出改进意见。下一篇对yolov5转换过程进行深度讲解。
6 附加
其实后续我还想完成一件事情即模仿大部分pytorch复现yolo系列写法,提供一个通用的pytorch模型,可以直接加载darknet权重,输入也是cfg模式,内部自动解析cfg来构建模型。这样就可以实现两种目的:
(1) 如果想了解所有模型细节,可以按照原来的流程,先转化再导入pth权重
(2) 如果想快速将darknet模型应用到mmdetection中,而不写一行代码,那么就可以用这个通用的pytorch模型了。
但是其需要做如下工作:
(1) 这个pytorch模型要能够适应所有cfg,也就是必须实时了解darknet里面有没有新增一些骚操作,这边也要实时兼容
(2) 对于微调训练,也要支持不同输出层的权重不导入
看下啥时候进行排期吧!
github地址:https://github.com/hhaAndroid/mmdetection-mini
欢迎star和提出改进意见
