@huanghaian
2020-06-17T06:31:31.000000Z
字数 2085
阅读 2015
噪声label学习
分类
https://github.com/subeeshvasu/Awesome-Learning-with-Label-Noise
https://zhuanlan.zhihu.com/p/110959020
1 understanding deep learning requires rethinking generalization
最重要的结论:Deep neural networks easily fit random labels,同时正则化可以避免过拟合,但是并非必须。
神经网络的参数量大于训练数据的量,generalization error 有的模型好,有的模型差,区别在哪里? 本文仅仅分析了现象,没有得出啥实质性结论。
aum
论文名称:Identifying Mislabeled Data using the Area Under the Margin Ranking
arxiv:2001.10528
论文目的主要是找出错误标注数据。主要创新包括:
(1) 提出了aum分值 Area Under the Margin来区分正确和错误标注样本
(2) 由于aum分值是和数据集相关的,阈值切分比较关键,故作者提出指示样本indicator samples的概念来自动找到最合适的aum阈值
Not all data in a typical training set help with generalization
AUM的定义非常简单:
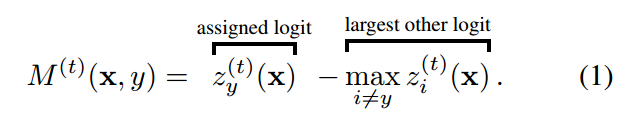
对于任何一个样本,z是指softmax预测概率值,zy是指的分配label位置对应的预测输出值,max zi是指除了label位置预测输出最大值。当样本label正确时候,该值比较大,当label不正确的时候,该值比较小甚至是负数。
利用该特性就可以把错误标签样本找出来。仅仅计算样本当前epoch时候的AUM值不太靠谱,一个错误样本应该aum值都差不多,故作者采用了所有epoch的aum平均值:
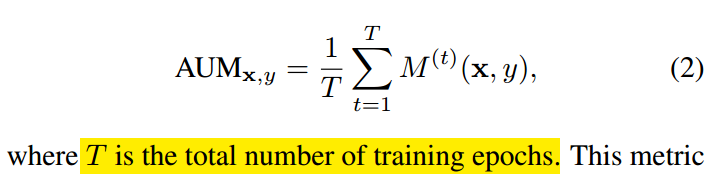
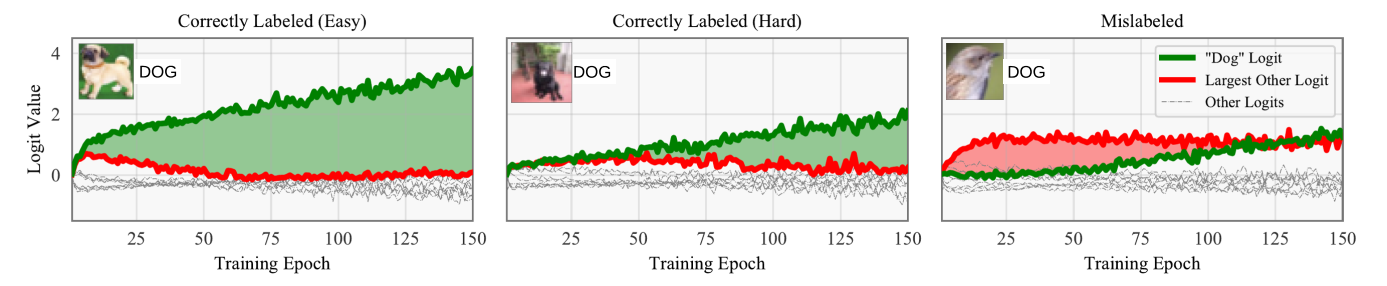
中间的绿色区域就是AUM。
基于上述办法可以得到每个样本的AUM值,但是如何设置阈值来确定噪声样本?本文提出Indicator Samples概念自动确定阈值。
做法其实非常简单:挑选一部分正确label数据,然后把这些数据全部算作c+1类,相当于在原始类别基础上扩展一个类,可以发现这些样本数据其实全部算是错误label数据,可以利用这部分数据的aum值来作为阈值。
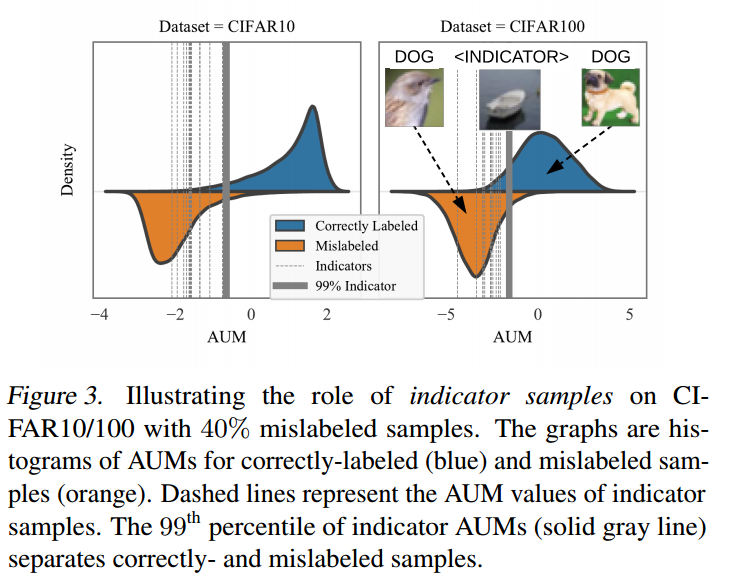
得到这些样本的aum值后,选择第99百分位数作为阈值即可,小于阈值的就是噪声样本。
算法流程:

需要注意的是上述过程需要不断迭代,并且每次迭代所选择的指示样本都不一样,这样才能有效挖掘出来所以噪声样本。
并且不能在过拟合很严重时候计算aum,作者采用的是在第一次学习率下降时候统计aum。
实验采用的是ResNet-32,300 epochs using 10−4 weight decay, SGD with Nesterov
momentum, a learning rate of 0.1, and a batch size of 256。The learning rate is dropped by a factor of 10 at epochs 150 and 225.
When computing the AUM to identify mislabeled data, we train these models up until the first learning rate drop (150 epochs),并且把batch size变成64,主要是增加sgd训练时候的方差,对统计aum有好处。在移除错误样本后,再采用上述策略进行训练。

Learning Adaptive Loss for Robust Learning with Noisy Labels
论文名称:Learning Adaptive Loss for Robust Learning with Noisy Labels
arxiv:2002.06482
本文没有啥参考价值,主要是采用元学习自动学习鲁棒loss的超参。但是本文总结了目前常用的对噪声鲁棒loss,可以看看这部分。
(1) ce loss
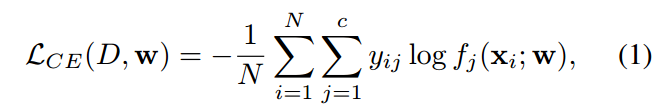
(2) Generalized Cross Entropy (GCE)
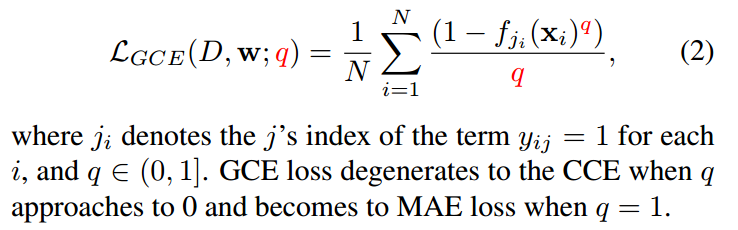
(3) Symmetric Cross Entropy (SL)
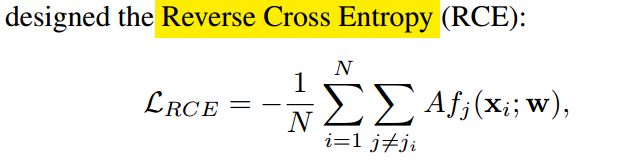
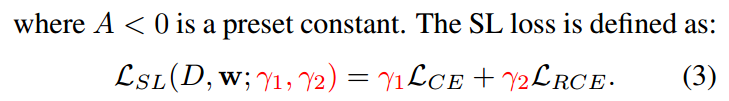
(4) Bi-Tempered logistic Loss (Bi-Tempered)
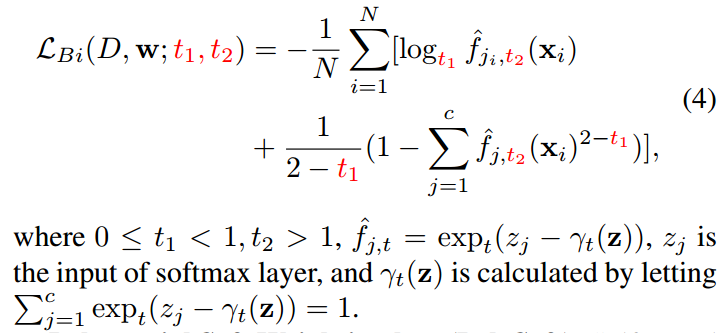
(5) Polynomial Soft Weighting loss (PolySoft)
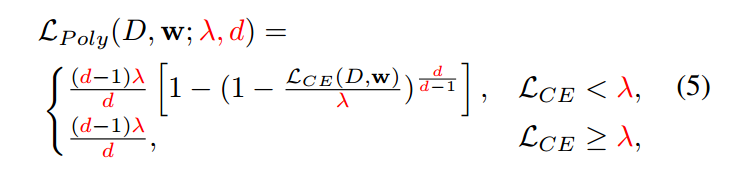
Symmetric Cross Entropy for Robust Learning with Noisy Labels
https://zhuanlan.zhihu.com/p/146174015
知乎有人说有效。
论文
DivideMix: Learning with Noisy Labels as Semi-supervised Learning
Simple and Effective Regularization Methods for Training on Noisily Labeled Data with Generalization Guarantee
SELF: Learning to Filter Noisy Labels with Self-Ensembling
