@huanghaian
2020-07-16T02:29:42.000000Z
字数 6434
阅读 2834
从代码角度分析高效文本检测算法EAST
目标检测
0 摘要
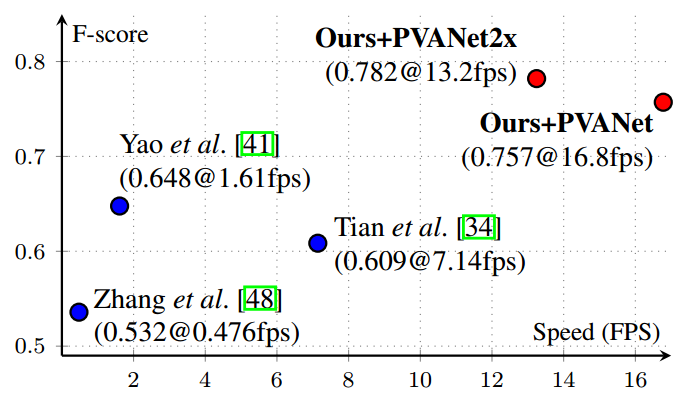
论文名称:EAST: An Efficient and Accurate Scene Text Detector
arxiv: https://arxiv.org/abs/1704.03155
开源代码:
1 https://github.com/songdejia/EAST
2 https://github.com/SakuraRiven/EAST
EAST全称是An Efficient and Accurate Scene Text Detector,可以看出其特点是简单高效,是一个非常常用的文本检测算法,目前已经集成到opencv里面了。其抛弃了以前各种复杂的操作,直接将文本检测分成了简单的两个stage:第一个stage是FCN全卷积网络,直接产生字符或者文本行的预测(可以是旋转矩形或者四边形);第二个stage是后处理,主要是倾斜bbox或者四边形的nms操作,而且为了防止后处理耗时,还提出对应的加速版本。 由于其算法的设计,无法直接处理弯曲文本,主要用于倾斜文本或者水平文本检测,应该非常广泛,目前也出现了很多改进版本。
由于官方没有开源算法,而argman/EAST版本得到了官方的认可,但是其是基于tensorflow的,目前基于pytorch的代码基本都是参考这个版本写的,代码都大同小异,我选择了一个相对简单的进行分析即:https://github.com/SakuraRiven/EAST
1 算法分析
EAST是一个非常简单的算法,没有啥复杂设计,容易理解和实现。
1.1 网络设计
骨架网络包括PVANet和VGG16,都是其他论文里面的算法,本文不分析。
特征提取后采用了U形结构进行多尺度特征融合,也是常规操作,如下所示:
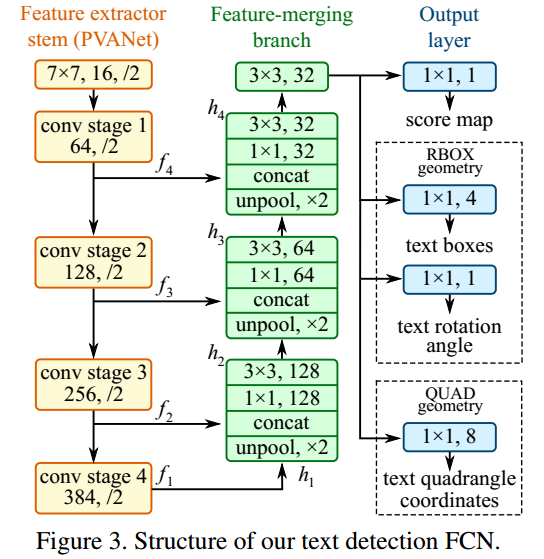
SakuraRiven版本EAST采用骨架是VGG,而songdejia版本采用的是标准resnet,特征融合就是U-shape结构,这个没啥好分析的,就不贴代码了。
1.2 head设计
本文的预测输出支持旋转bbox形式(RBOX)和四边形形式(QUAD),故其输出head也可以包括两种形式。
- 都有score map分支,shape为(h',w',1),用于表示哪些区域是文本区域
- 对于RBOX格式,其输出包括(h',w',4)的geometry几何形状分支,和旋转角度预测分支angle,shape是(h',w',1)
- 对于QUAD格式,其预测的是点到4个标注点的距离,包括xy方向,故一共是8个通道输出
后面会结合代码详细说明label生成过程。
目前各种复现代码都是仅仅基于RBOX格式,如果想实现QUAD应该也是非常简单的,只需要换一下输出头、label生成改成QUAD和loss即可,其他应该不需要改。两者性能应该没有啥很大差异,故我也是以RBOX格式来分析。
前面说过,RBOX格式,其实输出三条分支,一个是score map,一个是RBOX分支,还有一个是angle分支。如果不结合label生成过程,不太好分析后续代码。
其代码如下:
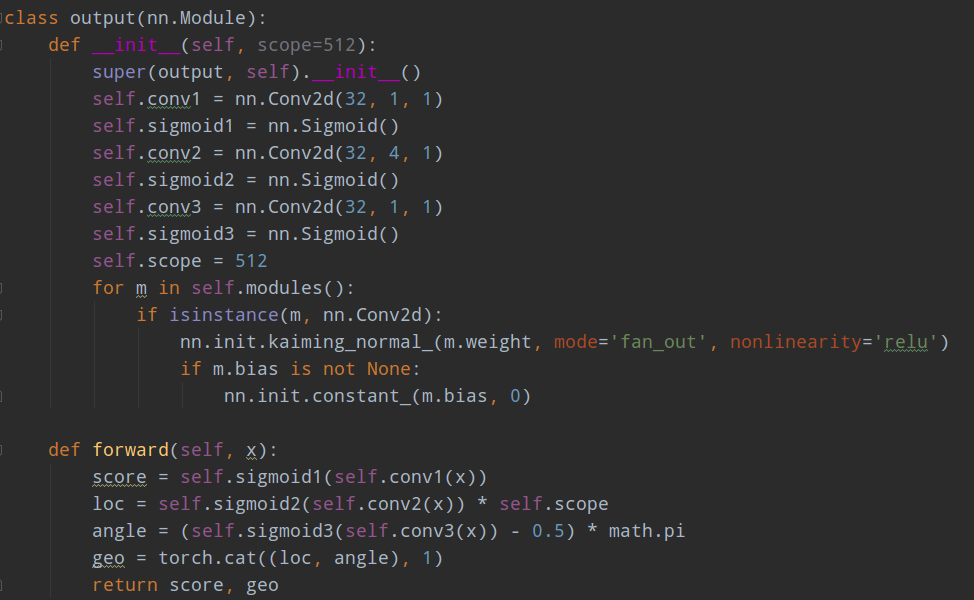
首先score map shape=(h/4,w/4,1),其实是语义分割分支,故有sigmod函数;对于loc分支也就是RBOX分支,其预测的是当前像素位置距离4条边的距离(由于采用的是RBOX格式,故即使标注的时候不是倾斜矩形而是四边形,那么也是强制按照矩形来计算,否则无法计算4条边距),由于网络输入图片大小是512x512,故代码实现时候其实是也是经过sigmod,压缩到0-1之间,然后乘上512;对于angle分支,其label范围是-90~90度,也和loc一样,采用sigmod进行压缩,然后乘上相应系数即可。乘以512这个操作太迷了,因为其训练时候是512x512,但是测试时候其实不是,测试时候没有512x512的限制,这感觉会有问题,当然在icdar2015上面可能还好,毕竟文本没有那么长,但是如果有些数据集可能就会出问题了。不管咋说这个策略肯定不make sense的,应该采用类似focs算法的做法,输出值是相对当前特征图的size来回归的,达到自适应的目的,而且也没必要采用sigmod。
1.3 label生成过程分析
以SakuraRiven/EAST代码和ICDAR2015数据集为例,所有代码都在dataset.py里面。
上层类如下所示:
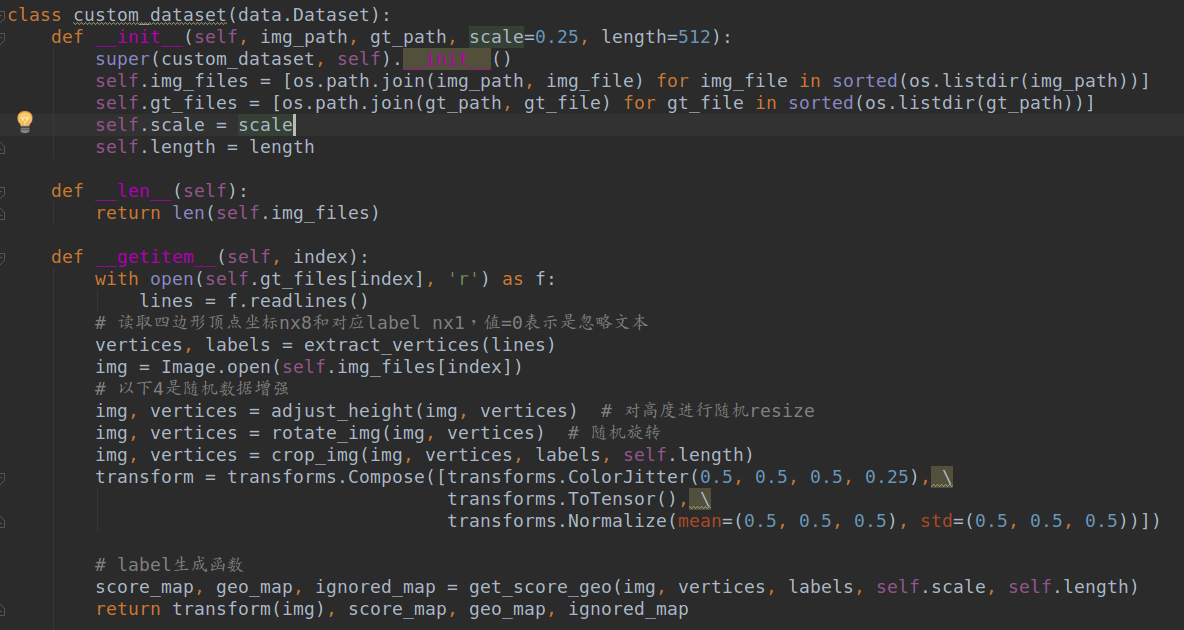
其逻辑如下:
(1) 对icdar2015文件进行解析,得到图片名和四边形顶点坐标、以及label表示该文本标注是否是忽略样本
(2) 遍历图片list,对图片和关键点进行随机高度resize数据增强操作
(3) 对图片和关键点进行随机旋转操作,图片大小不变,其余地方填黑
(4) 对图片和关键点进行随机裁剪为指定的(length,length)大小,具体是首先判断图片是否最短边小于length,如果小于则先进行保存长宽比的resize操作;然后进行随机裁剪,随机裁剪的时候要保证不能正好裁断四边形标注,否则不好处理。
但是这种操作可能会出现裁剪的bbox内部没有任何一个gt 标注,对于icdar2015这种文本区域占比很小,裁剪区域很大的数据集可能影响不大,但是换一个不同数据集可能就难说了。这种裁剪策略太暴力了,实际上不太可取。
对上述处理完后的数据进行可视化,代码如下所示:

下面分析label具体生成过程,具体就是get_score_geo函数。先分析上层逻辑:
(1) 遍历每条poly,对每条poly,shape=(4,2)进行处理
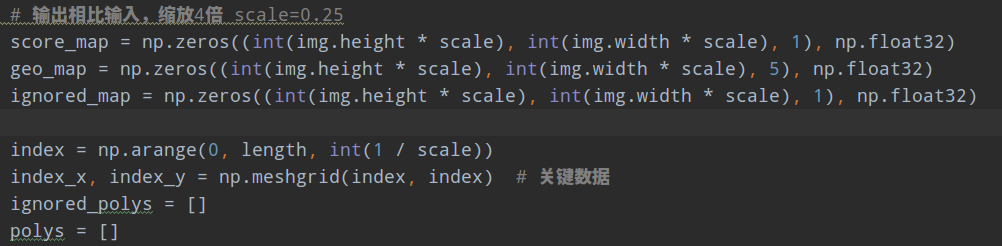
(2) 对poly先进行向内shrink,然后乘以0.25,转化到输出尺度。因为输出是输入的1/4倍数
(3) 对poly计算倾斜角,角度范围设置为-90到90度,利用倾斜角计算旋转矩阵
(4) 以poly的第一个点为固定anchor点,对poly点进行旋转校正,得到正矩形坐标点;然后计算bbox的x_min, x_max, y_min, y_max
(5) 对整图坐标点进行相同角度旋转,然后可以计算图片坐标内每个点到bbox的x和y方向距离图,得到RBOX分支和A
ngle分支的label
(6) 计算得到score map和ignored map
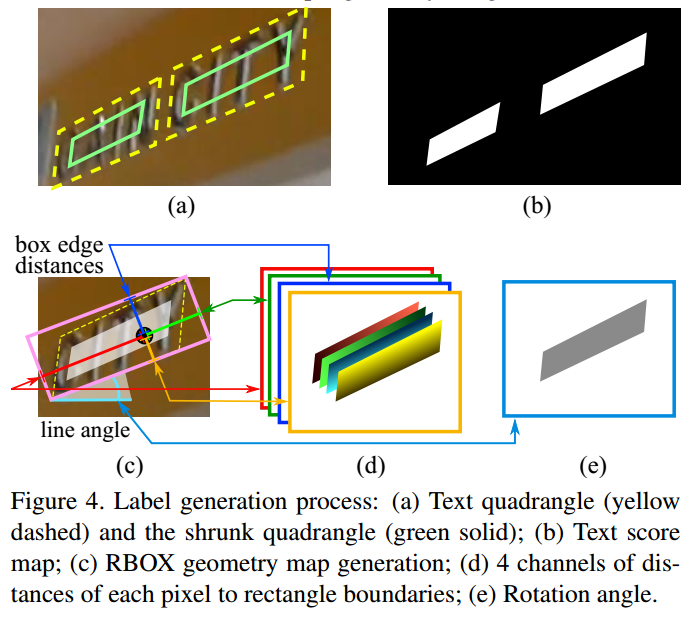
下面详细分析。论文图示:
1. 准备数据
2. 遍历每条poly,对poly先进行向内shrink,然后乘以0.25
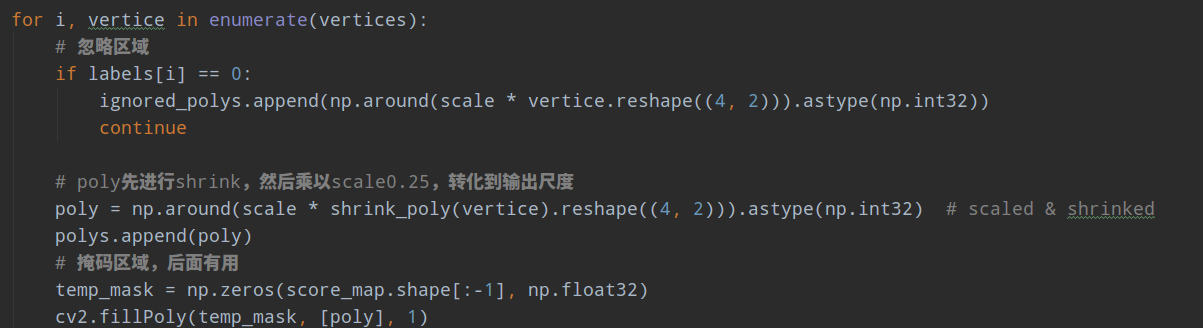
其中论文对4条边如何进行shrink操作,进行了详细讲解,具体为:以图示为例
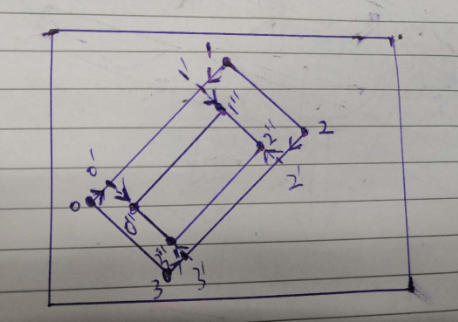
(1) 计算出两条长边和短边的索引,大部分数据标注都是倾斜矩形,但是也可以是四边形,以上图为例,假设是倾斜矩形,长边分别是0-1和2-3两条边
(2) 计算每个顶点的移动基数,对于每个顶点而言,该顶点的移动基数就是相连的两个边取最小边长度。可以看出4条边的移动基数相同,都是20
(3) 先移动两条长边,顺时针开始,由于长边是0-1,故移动的第一个点是0,移动方向是0->1,移动的比例是设置的0.3,也就是沿着线段0->1方向移动0.3r,r=20的比例,此时得到0';在移动第二个点1,移动方向是1->0,移动的比例是设置的0.3,也就是沿着线段1->0方向移动0.3r,r=20的比例,此时得到1'
(4) 再移动第二个长边顶点2和3,先移动2,方向是2->3,移动基数也是相同,此时得到2',再移动3,移动方向是3->2,得到3'
(5) 再移动两个短边对应顶点,先移动1',再移动2',对于1',其移动方向是1'->2',移动基数也是相同的,此时得到1'',后面的操作完全相同
(6) 此时,就可以得到0'',1'',2''和3'',4个新的顶点,此时构成的矩形就是shrink后的Poly了。
核心就是理解移动方向,其余就比较简单了。
其实上述操作可以直接用pyclipper第三方库实现,输入比例和多边形边,会自动输出shrink的边,非常简单,具体可以看文章,里面有用法。
3. 计算几何分支label
其是要计算倾斜矩形或者四边形内部点距离4条边的距离,以及倾斜角。
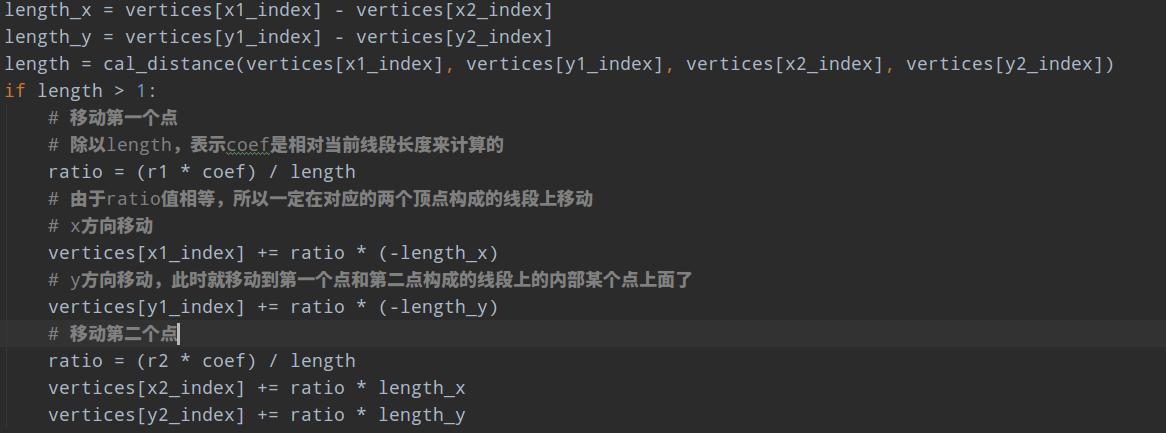
为了计算边距离,对倾斜矩形或者四边形进行旋转校正是必须的,故
(1) 对4个顶点计算最佳的角度值作为角度label,为啥叫最佳,是因为可能标注是四边形,而不是标准的倾斜矩形
(2) 然后利用角度进行旋转校正,得到正矩形,从而得到x_min, x_max, y_min, y_max
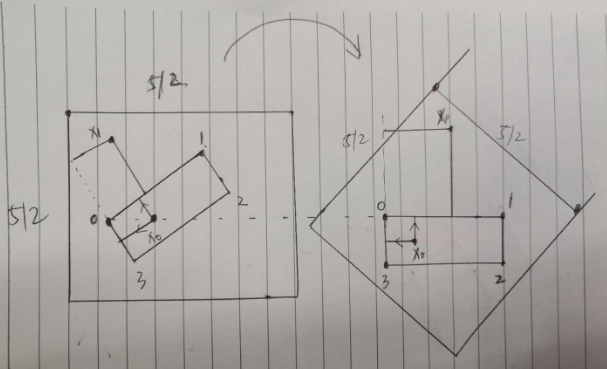
(3) 由于前面设定了旋转的中心点是标注四边形的0点(也就是这个点旋转前后坐标是不变的),故首先在原图尺度上构造两个和原图一样大的(length,length)的正方形坐标矩阵,代表图片上面的x方向和y方向2d坐标,或者说距离起始原点(0,0)的xy方向距离;以固定点为中心进行旋转,将正方形坐标矩阵转化为旋转的矩阵下的坐标;此时相当于vertices四边形坐标进行了旋转校正,得到正矩形坐标点,此时就容易计算边距了
(4) 利用index_x和index_y矩阵可以查找出未旋转前原图坐标上面每个点距离4条边的距离,乘上shrink的mask就可以得到内部边距了
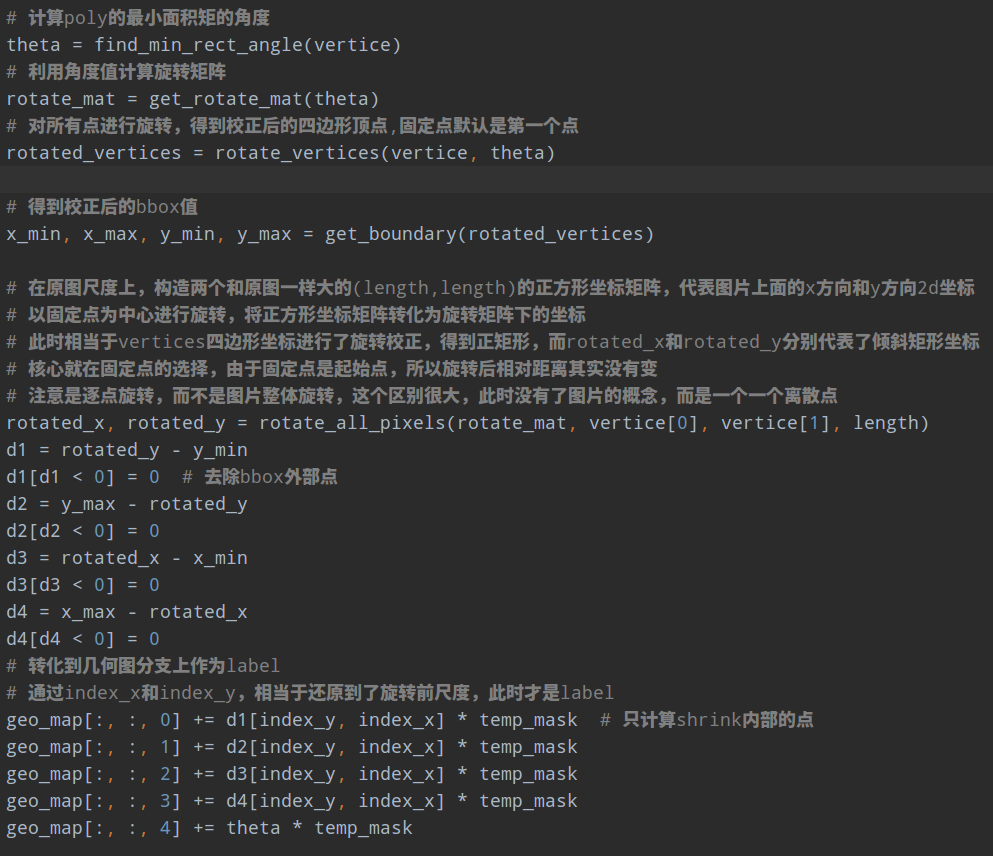
重点说下rotate_all_pixels函数,其要做的就是新建2个512x512的矩阵,第一个矩阵内部值其实是相对于(0,0)点的x方向距离,第二个矩阵内部值是相对于(0,0)点的y方向距离,对该矩阵里面的每个坐标点进行旋转,得到旋转后的坐标值,旋转的固定点必须是poly的起始点坐标,可视化如下所示,如上上图的右边图所示,此时相当于文本区域校正了,此时计算矩阵内部每个点距离校正后的bbox四条边的距离就非常简单了,直接相减即可;最后采用原始的512x512索引矩阵对距离图进行索引就可以旋转前的512x512个点相对于poly的4条边的距离了,然后和mask相乘就可以保留poly内部的值了。

白色是旋转前,黄色是旋转后,可以看出是基于第一个点进行旋转的。
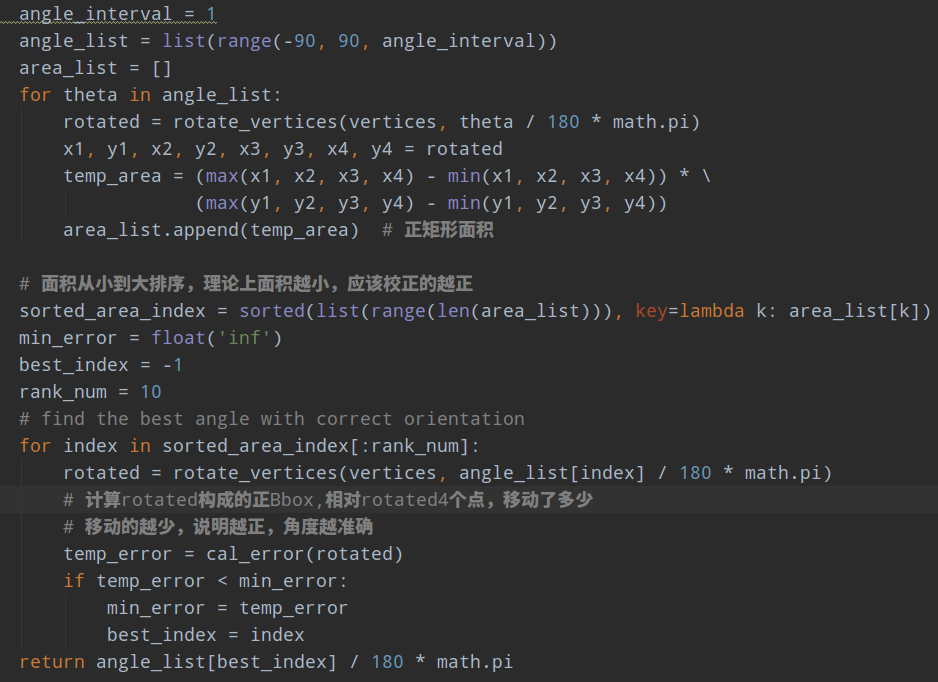
在计算最佳倾斜角度的时候,也就是find_min_rect_angle函数,其计算方法是遍历-90~90度,然后计算每个角度下旋转后面积,面积最小的理论上应该就是校正效果最好的角度了,但是考虑到四边形标注,为了更加精确,内部还对移动距离再一次进行了排序,主要目的就是通过遍历方式或者说拟合方式找到最佳的倾斜角度。如果标注都是倾斜矩形,那么就没必要这么麻烦了,可以直接用opencv里面的cv2.minAreaRect函数计算出倾斜角:
而且从上面代码计算流程可以发现,对于所有标注的四边形而言,点的标注顺序必须是固定的,也就是从左上角开始标注,作为第一个点,然后按照顺时针标注。
4. 计算score map和忽略图
这个就非常简单了,对shrink后的poly区域填1,就可以得到score map,同样对于忽略区域填1即可
cv2.fillPoly(ignored_map, ignored_polys, 1)
cv2.fillPoly(score_map, polys, 1)
5.可视化
将输出的分值图和几何图分支resize到原图大小进行可视化,如下所示:
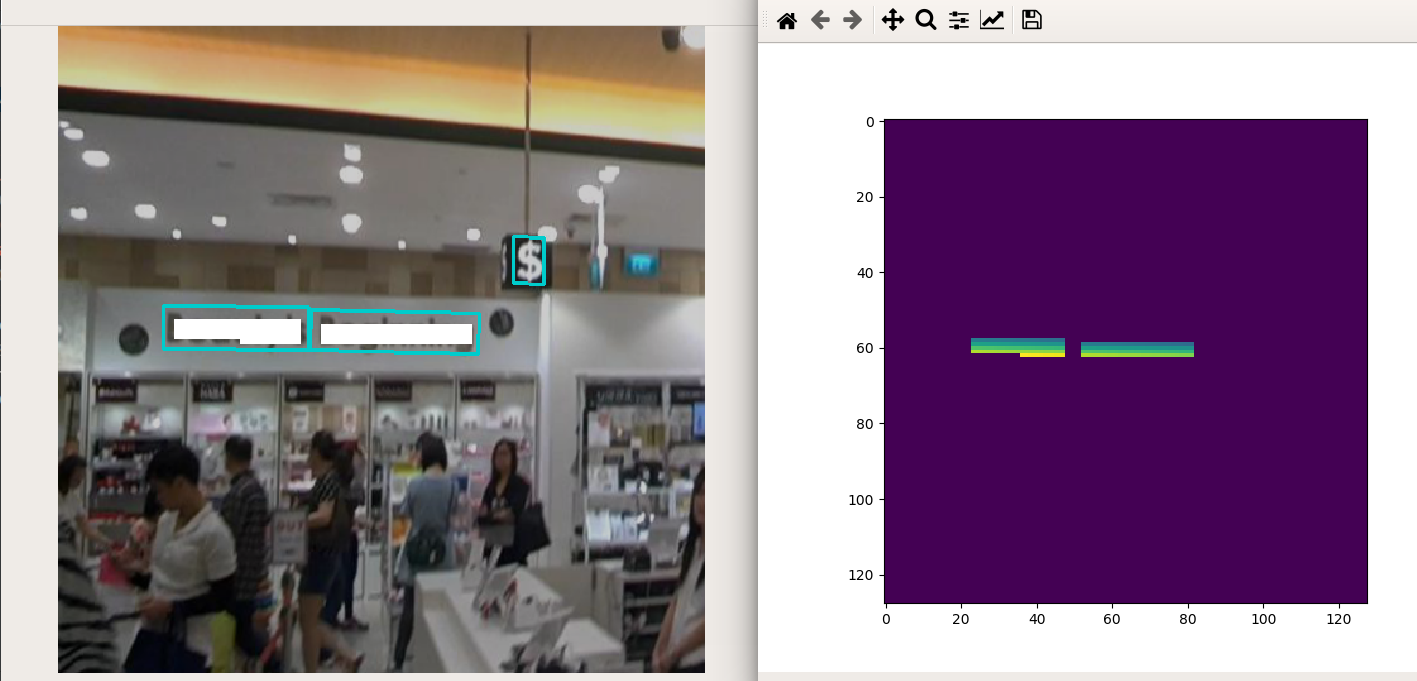
出现锯齿应该是绘图显示问题。
1.4 Loss计算
前面已经分析了label形式,对于RBOX而言,一共有三个分支,分别是score map(h/4,w/4,1),值为1表示该位置有待检测文本;几何geo分支(h/4,w/4,4),每个位置值代表距离矩形4条边的距离;角度angle分支(h/4,w/4,1),每个位置值代表倾斜角度,在score map区域内值都是相同的。还有额外辅助的ignored_map(h/4,w/4,1)表示忽略样本区域,值为1的区域不计算loss。
(1) score map分支loss
该分支其实是语义分割分支,作者采用的是类平衡bceloss。
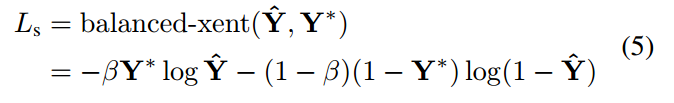
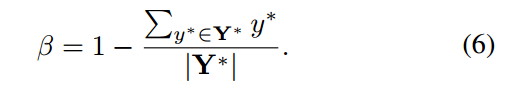
用于控制正负样本权重,假设score map面积大小是 100x100,有90个像素区域值为1,故,由于正样本区域比较少,故给予的权重比较大。
在代码复现中,实验表明dice loss效果明显好于平衡bce,故复现的代码其实是dice loss

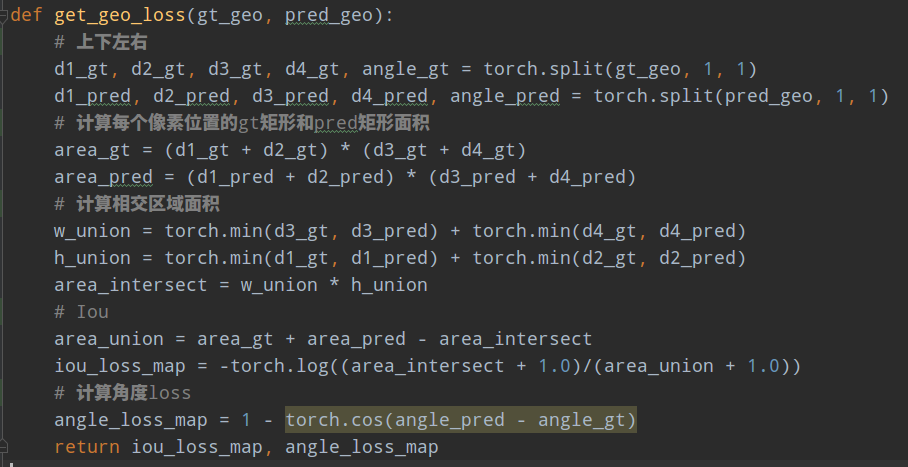
(2) geo map分支loss
对于RBOX格式,在Unitbox论文中提出了IOU loss,本文也是采用该loss:
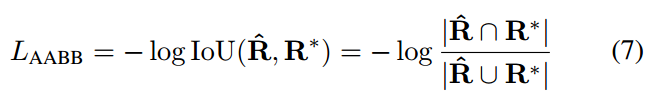
其中相交部分面积计算过程是:
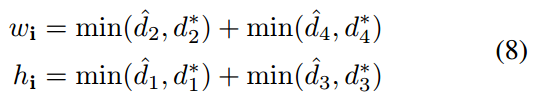
并集面积计算过程是:
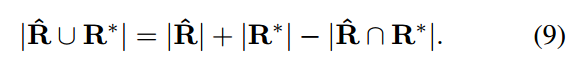
其中d1234分别代表当前像素位置距离4条边的上右下左的距离
(3) angle分支Loss
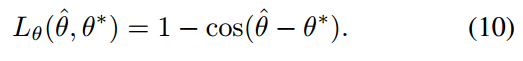
其中geo map和angle loss的权重比例是1:10,整体的比例是1:1
1.5 网络推理
推理阶段流程为:
- 将原始图片resize为32的整数倍
- 输入网络中进行推理,得到score map和geo map
- 对score map采用阈值切割,得到有文本区域的xy坐标
- 对xy坐标点按照行排序,也就是高排序,保证相邻的polys 列表里面存放顺序是近邻
- 利用geo的4条距离图预测分支,联合前面得到坐标位置可以得到bbox坐标
- 利用预测角度对bbox4个坐标点进行旋转,得到poly坐标
- 组成nx9的poly数据,前8个poly坐标,最后一个是预测分值,后续nms要用
- 先进行行合并的nms操作,然后再进行标准的nms操作,得到抑制后的poly坐标
- 最后在还原到原图尺寸即可
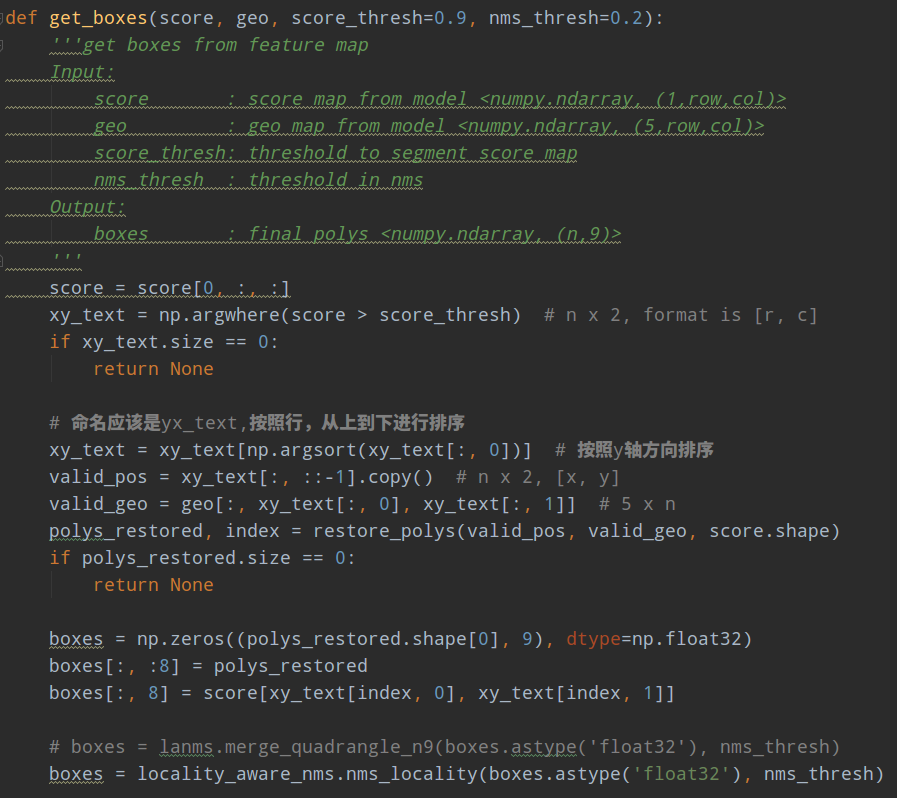
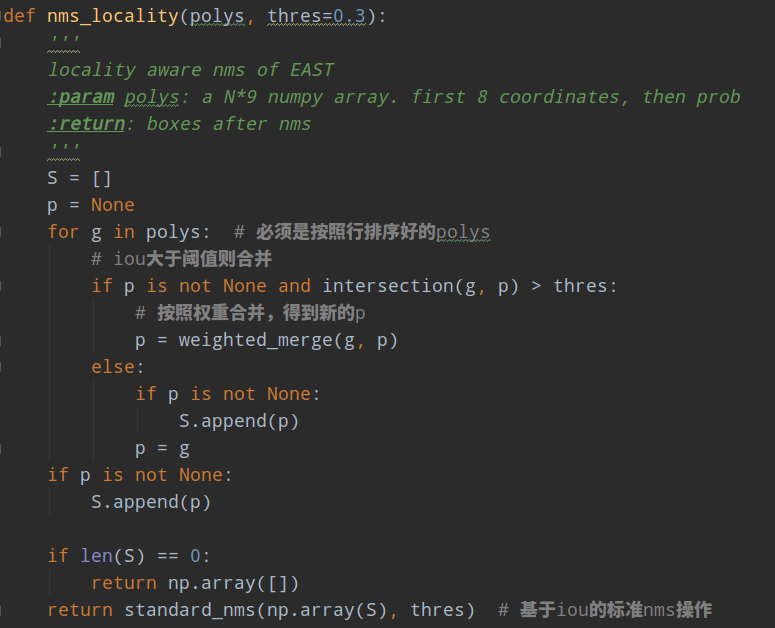
对于nms需要重点说明。在推理阶段,首先利用三条分支,可以得到最终的旋转bbox,但是由于每个位置都会预测倾斜框,故Nms是必不可少的,采用标准的nms算法,复杂度是,复杂度太高了,难以做到实时,考虑到文本检测的特殊性:来自附近像素的倾斜bbox往往高度相关,作者建议按照行顺序加权合并倾斜bbox,并且迭代地合并当前遇到的倾斜bbox与最后一个合并的几何倾斜bbox,这样再采用nms,复杂度就变成了了,再采用c++实现,就可以实现进一步加速了。

作者提供了c++版本代码lanms,但是大部分电脑都难以编译通过,故又提供了python简化版本,速度慢一点,但是精度应该影响不大,注意python版本的nms操作属于简化版本,其算法流程其实非常简单,如下所示:
geo是nx9的矩阵,前8个poly左边,最后一个位置是该点的预测分支来自score map
1 首先对预测的nx9个多边形,按照行排序,具体是基于预测的score map分支上的像素位置进行行排序,保证遍历poly时候,是按照近邻来排序,可以最大程度合并poly,减轻后续标准nms的计算量,加快速度
1 初始化p和S为空
2 遍历每条poly,如果是第一次运行,此时直接设置p=g,且加入到S集合中;如果不是,则和上一次保存的g(也就是近邻位置poly)计算iou,如果iou大于预测则表示是同一条文本,可以合并,合并的原则采用加权,权重就是各自Poly的score map预测值,合并后的新的poly设置p=g;如果不能合并的则表示是新文本区域,直接加入S中即可
3 遍历完成后,就可以得到S集合,在进行标准的nms即可
采用开源作者训练好的模型进行预测,可视化如下所示:


2 训练和实验结果
对图片进行随机增强,然后裁剪为512x512,优化器采用的是ADAM,学习率为1e-3,batch=24。预测出来的几个分支可视化如下所示:
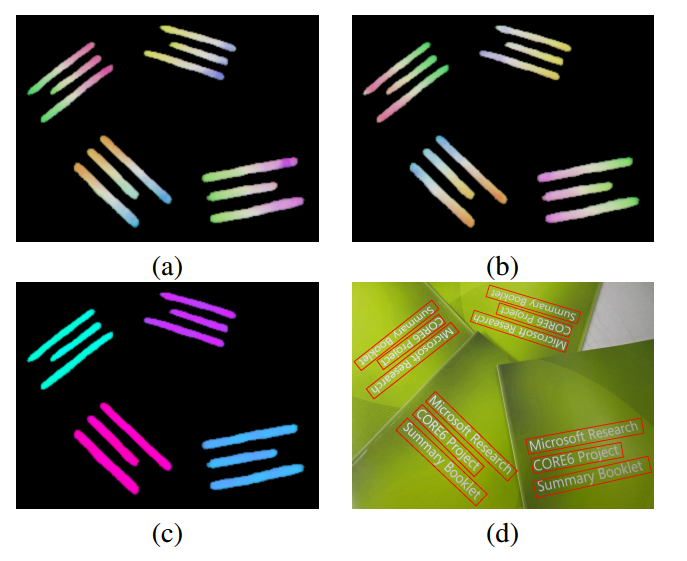
a,b是预测的距离图,c是角度图,d是最终效果。
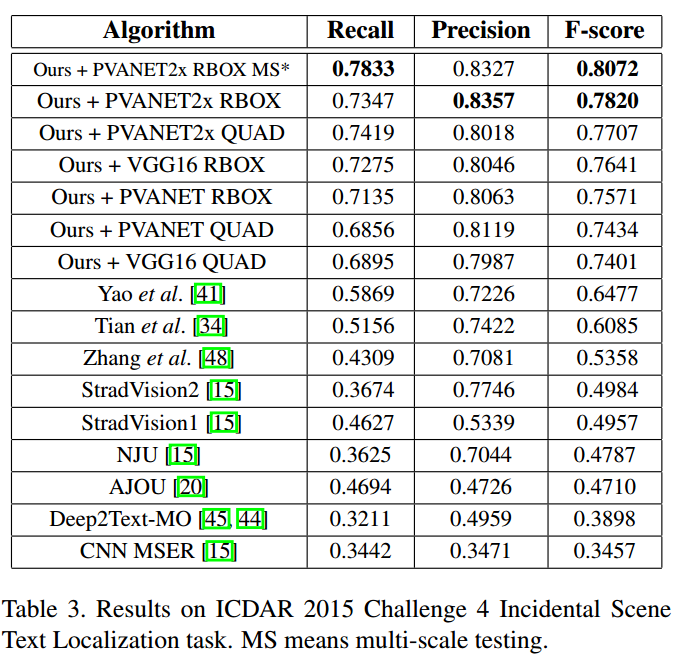
可以看出采用RBOX还是QUAD格式,效果差不多。
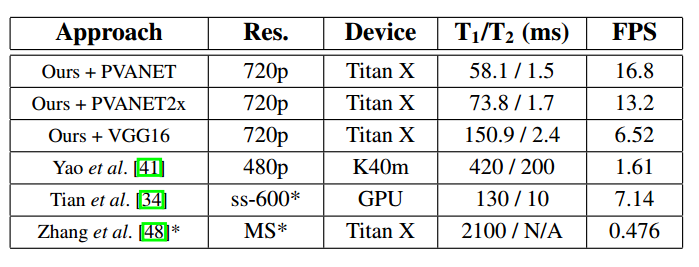
速度方面也比其他快很多,但是由于输入图片很大,整体速度依然很慢。
在论文结尾作者也说明了:对于预测长文本而已,感受野很重要,如果想效果比较好,则需要对骨架网络进行改进;而且对于垂直样本效果可能也不是很好。对于现在而言,resnet才是标准网络,故现在很多复现都会采用resnet作为骨架,效果会更好。在百度开源的PaddleOCR库里面采用的就是标准的resnet,可以发现效果是比原始论文好不少的,地址为https://github.com/PaddlePaddle/PaddleOCR
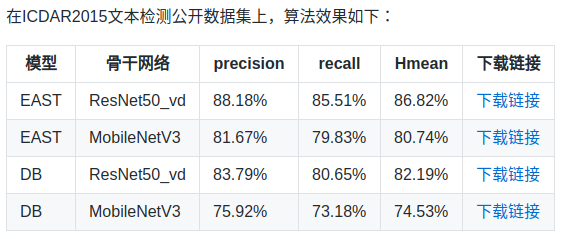
而且百度这个ocr库,还提供了从训练到部署的完整流程,对于需要部署的人来说,还是蛮好用的。
