@huanghaian
2020-11-02T03:52:12.000000Z
字数 4353
阅读 2748
mmdetection最小复刻版(十六):iou感知VarifocalNet深入分析
mmdetection
0 摘要
论文名称:VarifocalNet: An IoU-aware Dense Object Detector
论文地址:2008.13367
官方github: https://github.com/open-mmlab/mmdetection
github: https://github.com/hhaAndroid/mmdetection-mini
欢迎star
本文从fcos和atss存在的分类和回归分支不一致性问题出发,对推理过程进行详细分析,指出目前目标检测最大瓶颈依然是分类分支和回归分支分值不一致问题。虽然Generalized Focal Loss在atss基础上进一步缓解了该问题,但是或许有更好的解决办法,为此作者提出了两个改进:
- 提出了正负样本不对称加权的 Varifocal Loss
- 借助dcn思想,提出星型bbox特征提取refine网络,对atss的输出初始bbox进行refine
纵观全文,这篇论文和Generalized Focal Loss非常相似,不仅仅算法出发点类似,做法也类似,当然本文的改进也值得进行分析解读。
阅读本文前,最好先阅读Generalized Focal Loss解读:https://zhuanlan.zhihu.com/p/271636072
1 fcos和atss算法问题
为了引出本文观点,作者对atss的推理过程进行了详细分析,如下所示:
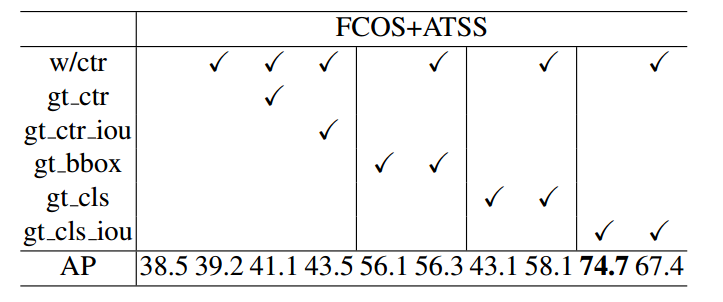
我个人觉得这副图才是本文最大亮点,值得深入思考,至于改进好像也没有特别大,性能也没有提升多少。
首先作者以ATSS算法为例,ATSS结构和FCOS完全相同,只不过在正负样本定义阶段引入了自适应策略而已,差别不大。
(1) 在没有centerness分支时候训练atss,其map是38.5,训练时候加入centerness即w/ctr(标准结构)从而得到39.2,此时baseline设置为39.2。
(2) gt_ctr是指在baseline基础上,测试时候把centerness分支替换为对应label值,可以发现map仅仅提高到41.1。
从以上两点分析可以说明centerness的作用其实非常不明显,引入这个额外分支最多也是从38.5提升到41.1,划不来。虽然分类和回归分支不一致性问题得到缓解,但是仅仅解决了一点点而已。
(3) 如果将centerness分支的输出变成预测bbox和gt bbox的iou值(gt_ctr_iou),也就是常说的iou感知分支,此时map是43.5。从这个角度来看,使用iou分支代替centernss是更好的,在Generalized Focal Loss中反映过这个问题,但是依然提升不大。
(4) 假设预测bbox回归分支值全部替换为真实gt bbox,在使用还是不使用centerness分支的时候,map没有很大改变。为啥全部替换为gt bbox,其map提升没有想象中的大?这很说明问题:影响mAP性能的主要因素不是bbox预测不准确,而在于分类分支,同时这个实验也可以看出centerness的作用非常微弱。
(5) 如果将分类分支的输出中,对应真实类别设置为1,也就是类别预测完全正确(gt_cls),此时map是43.1,加入centernes后提升到58.1,这也间距验证了(4)的说法,同时也说明nms排序分值非常重要,在类别预测完全正确的情况下,centerness可以在一定程度上区分准确和不准确的边界框。
(6) 惊奇的是:如果把分类分值的输出中,对应真实类别设置为预测bbox和真实bbox的iou(gt_cls_iou),那么即使不用centernss,也可以达到74.7,非常高,用于centerness还稍有下降。这其实很说明问题:目前的目标检测bbox分支输出的密集bbox中其实存在非常精确的预测框,关键是没有好的预测分值来选择出来,也就是Generalized Focal Loss中提到的如何加强分类分支和bbox分支一致性的问题。采用centerness分类分值的做法提升非常有限,最合适的做法就是将分类分支对应类别预测值中能够同时反映出物体类别和物体预测准确度,此时理论上限最高。
通过上述分析,本文目标就是要实现分类分支同时包含物体类别和物体预测准确度的功能,当然Generalized Focal Loss也是这样做的。通过上述分析,我们可以总结下:
- centernss作用还不如iou分支
- 单独引入一条centernss或者iou分支,作用非常有限
- 目前目标检测性能瓶颈不在于bbox预测不准确,而在于没有一致性极强的分值排序策略选择出对应bbox
- 将iou感知功能压缩到分类分支中是最合适的,理论mAP上限最高。
2 算法改进
2.1 varifocal Loss
在分析这个loss前,我们先回顾下Generalized Focal Loss做法
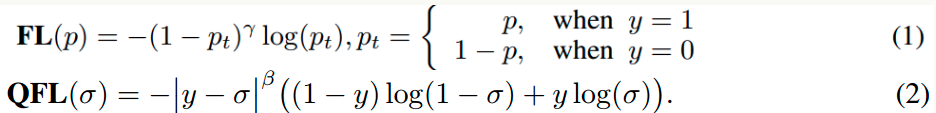
其中y为0~1的质量标签,来自预测的bbox和gt bbox的iou值,注意如果是负样本,则y直接等于0,是分类分支经过sigmoid后的预测值。可以发现广义focal loss将focal loss只能支持离散label的限制推广到了连续label,并且强制将分类分支对应类别处的预测值变成了包括bbox预测准确度。
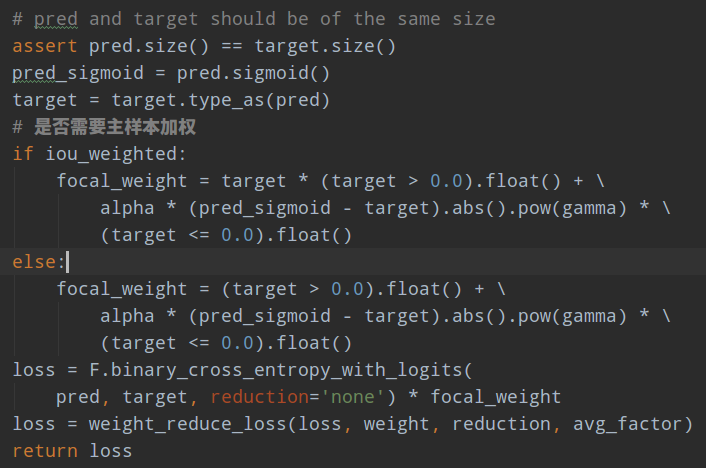
而本文的Varifocal Loss主要改进是提出了非对称的加权操作,focal loss和Generalized Focal Loss都是对称的。而非对称加权的思想来源于论文PISA,该论文指出首先正负样本有不平衡问题,即使在正样本中也存在不等权问题,因为mAP的计算是看主样本的(PISA论文分析已经写好了,马上发布)。基于这些思想,作者的Varifocal Loss定义如下:
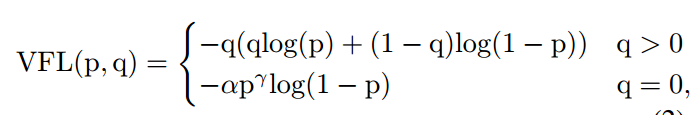
q是label,正样本时候q为预测bbox和gt bbox的iou,负样本时候q=0,当为正样本时候其实没有采用focal loss,而是普通的bce loss,只不过多了一个自适应iou加权,用于突出主样本。而为负样本时候就是标准的focal loss了。可以明显发现本文所提Varifocal Loss比Generalized Focal Loss更加简单,主要特点是正负样本非对称加权、突出正样本的主样本。
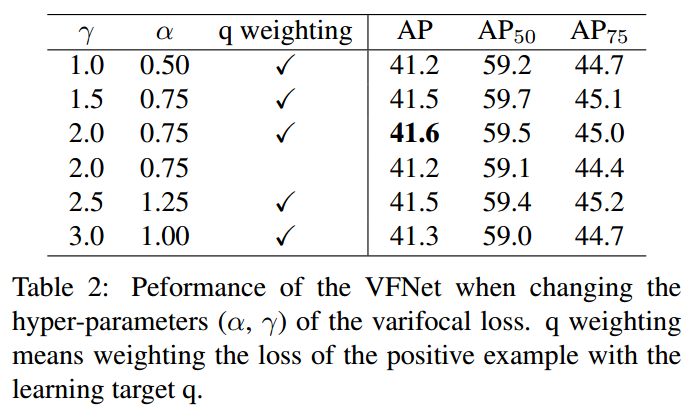
可以看出,虽然上述思想是很不错的,但是好像也没有提升多少啊。
相比Generalized Focal Loss会好一点点的。
2.2 bbox refinement
除了上面改进后,本文还提出bbox refinement思想,进一步提高性能。其整个网络结构如下:
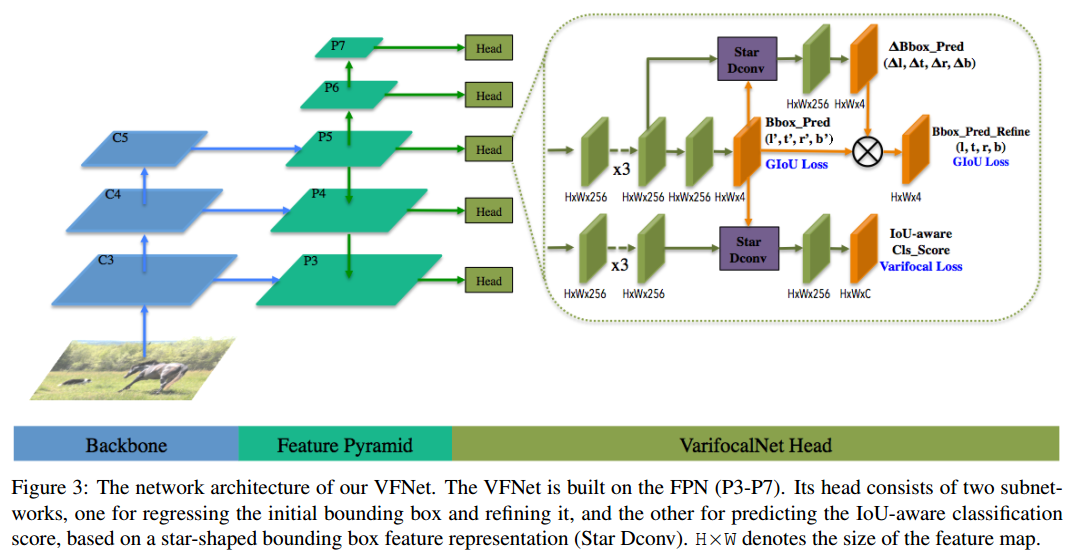
可以发现,和fcos的区别是:
- 不需要centerness分支
- 多了星型bbox特征提取和refine操作
其基本流程是:
(1) 任何一个head,对分类和回归分支特征图堆叠一系列卷积,输出通道全部统一为256
for cls_layer in self.cls_convs:
cls_feat = cls_layer(cls_feat)
for reg_layer in self.reg_convs:
reg_feat = reg_layer(reg_feat)
(2) 对回归分支特征图进行回归预测,得到初始bbox预测值,输出通道是4,代表lrtb预测值,然后对预测值进行还原得到原图尺度的lrtb值
reg_feat_init = self.vfnet_reg_conv(reg_feat)
if self.bbox_norm_type == 'reg_denom':
# 默认
bbox_pred = scale(
self.vfnet_reg(reg_feat_init)).float().exp() * reg_denom
(3) 利用lrtb预测值对每个特征图上面点生成9个offset坐标,示意图如下:
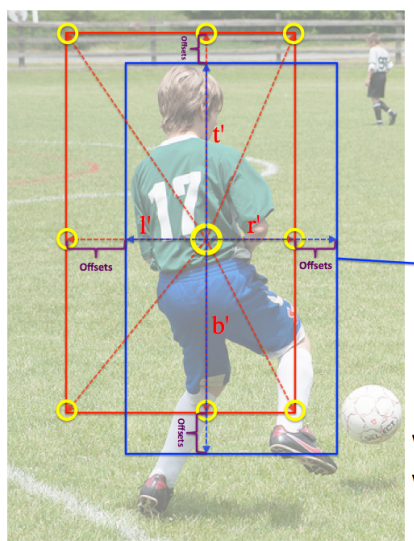
红色是(2)步骤在某个特征图点上生成的bbox坐标,然后利用(x, y), (x-l’, y), (x, y-t’), (x+r’, y), (x, y+b’), (x-l’, y-t’),(x+l’, y-t’), (x-l’, y+b’) 和 (x+r’, y+b’),得到9个采样点的浮点offset,此时每个特征图上面点都会得到9个新的浮点offset
dcn_offset = self.star_dcn_offset(bbox_pred, self.gradient_mul, stride)
(4) 将offset作为变形卷积的offset输入,然后进行dcn操作,此时每个点的特征感受野就可以和初始时刻预测值重合,也就是常说的特征对齐操作,方便refine,此时就得到了refine后的bbox预测输出值,需要特别注意的是refine分支输出值是代表scale值,将该refine输出值和初始预测值相乘即可得到refine后的真实bbox值
reg_feat = self.relu(self.vfnet_reg_refine_dconv(reg_feat, dcn_offset))
# bbox refine输出
bbox_pred_refine = scale_refine(
self.vfnet_reg_refine(reg_feat)).float().exp()
# 注意需要乘上bbox_pred.detach(),才是最终值
bbox_pred_refine = bbox_pred_refine * bbox_pred.detach()
(5) 对分类分支也是同样处理,加强分类和回归分支一致性
cls_feat = self.relu(self.vfnet_cls_dconv(cls_feat, dcn_offset))
cls_score = self.vfnet_cls(cls_feat)
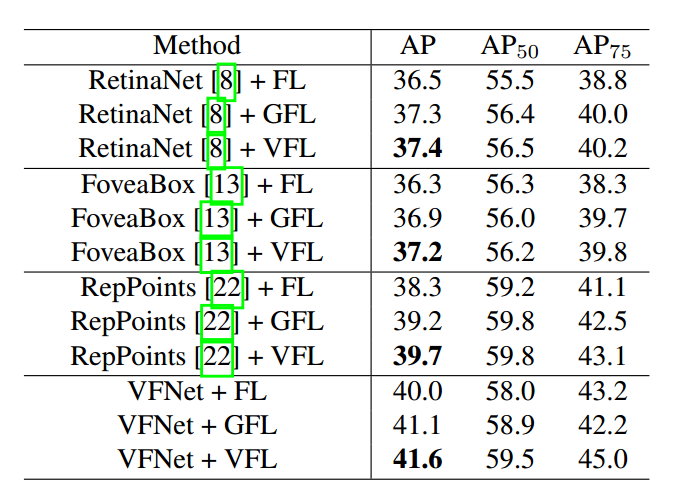
总体效果如下所示:
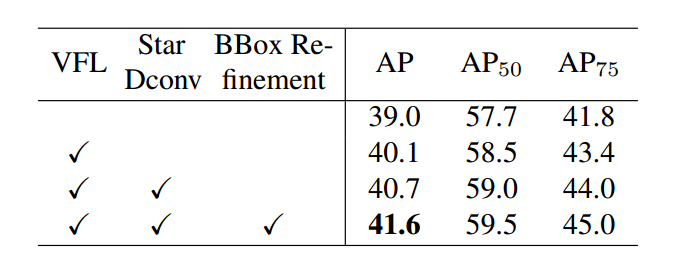
可以看出所提的两个部件确实有性能提升,但是好像不大哦!
2.3 loss设计
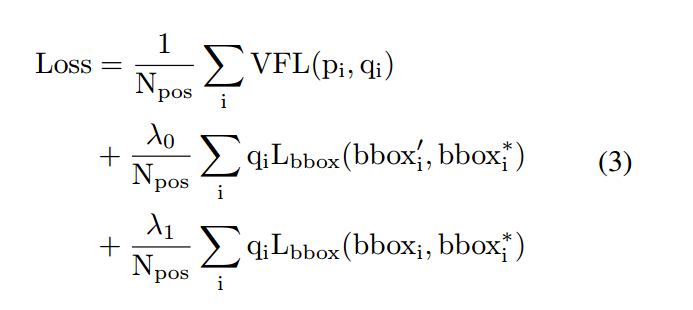
经过上述操作可以发现其包括三个输出:分类输出,初始回归输出和refine回归输出。对分类输出采用Varifocal Loss,对其余两个回归分支采用giou loss进行训练。还有一个小细节是两个回归分支的权重乘上了iou值,用于突出主样本。
3 性能分析
vfnet的推理过程和atss完全相同,只不过使用的回归分支是refine后的而已。
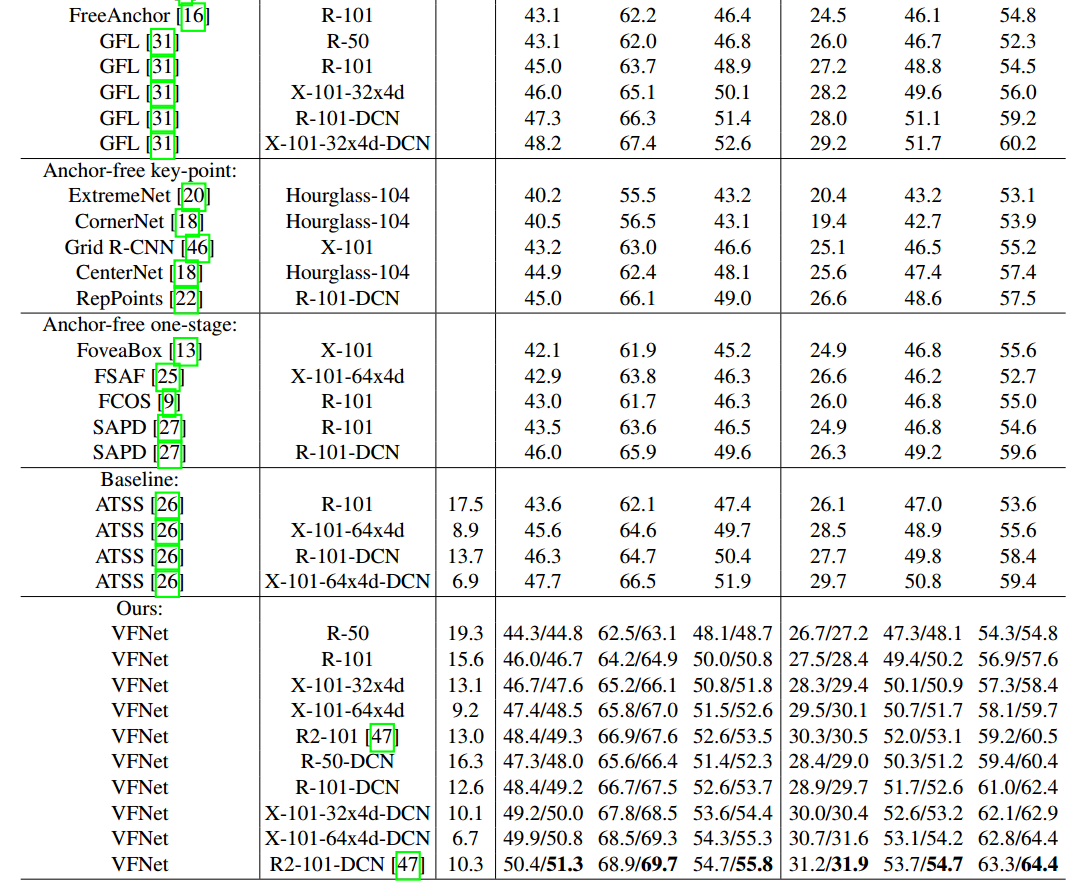
vfnet指标有两个是因为多尺度训练时候参数不一样,其范围是1333×[640:800]和1333×[480:960]。
4 总结
纵观整篇文章,我个人觉得最大亮点就是其对atss的分析过程。至于改进嘛,都是常规操作,性能也没有提升很多。
github: https://github.com/hhaAndroid/mmdetection-mini
欢迎star
