@frank-shaw
2016-09-24T08:27:50.000000Z
字数 5049
阅读 5896
angularJS的compile过程与link过程
angular.js
参考文章:
1. http://www.ifeenan.com/angularjs/2014-09-04-[%E8%AF%91]NG%E6%8C%87%E4%BB%A4%E4%B8%AD%E7%9A%84compile%E4%B8%8Elink%E5%87%BD%E6%95%B0%E8%A7%A3%E6%9E%90/
2. http://www.jvandemo.com/the-nitty-gritty-of-compile-and-link-functions-inside-angularjs-directives/
3. https://hairui219.gitbooks.io/learning_angular/content/zh/chapter05_5.html
对于一个新手而言,想要完全理解compile过程与link过程,确实很难。link过程又可分为pre-link与post-link过程。这里我疑惑的不仅仅是compile过程与link过程,同时对于compile link函数中的参数含义也不了解。所以需要查找很多资料,慢慢消化。
感性认知compile过程与link过程
compile过程与link过程的具体区别可以直接通过下面的实例来感受一下:
//HTML文件<!DOCTYPE html><html ng-app="plunker"><head><meta charset="utf-8" /><title>演示例子1</title><script>document.write('<base href="' + document.location + '" />');</script><link rel="stylesheet" href="style.css" /><script data-require="angular.js@1.2.x" src="https://code.angularjs.org/1.2.22/angular.js" data-semver="1.2.22"></script><script src="app.js"></script></head><body><level-one><level-two><level-three>Hello {{name}}</level-three></level-two></level-one></body></html>//app.js文件var app = angular.module('plunker', []);function createDirective(name){return function(){return {restrict: 'E',compile: function(tElem, tAttrs){console.log(name + ': compile');return {pre: function(scope, iElem, iAttrs){console.log(name + ': pre link');},post: function(scope, iElem, iAttrs){console.log(name + ': post link');}}}}}}app.directive('levelOne', createDirective('levelOne'));app.directive('levelTwo', createDirective('levelTwo'));app.directive('levelThree', createDirective('levelThree'));
结果输出如下图:
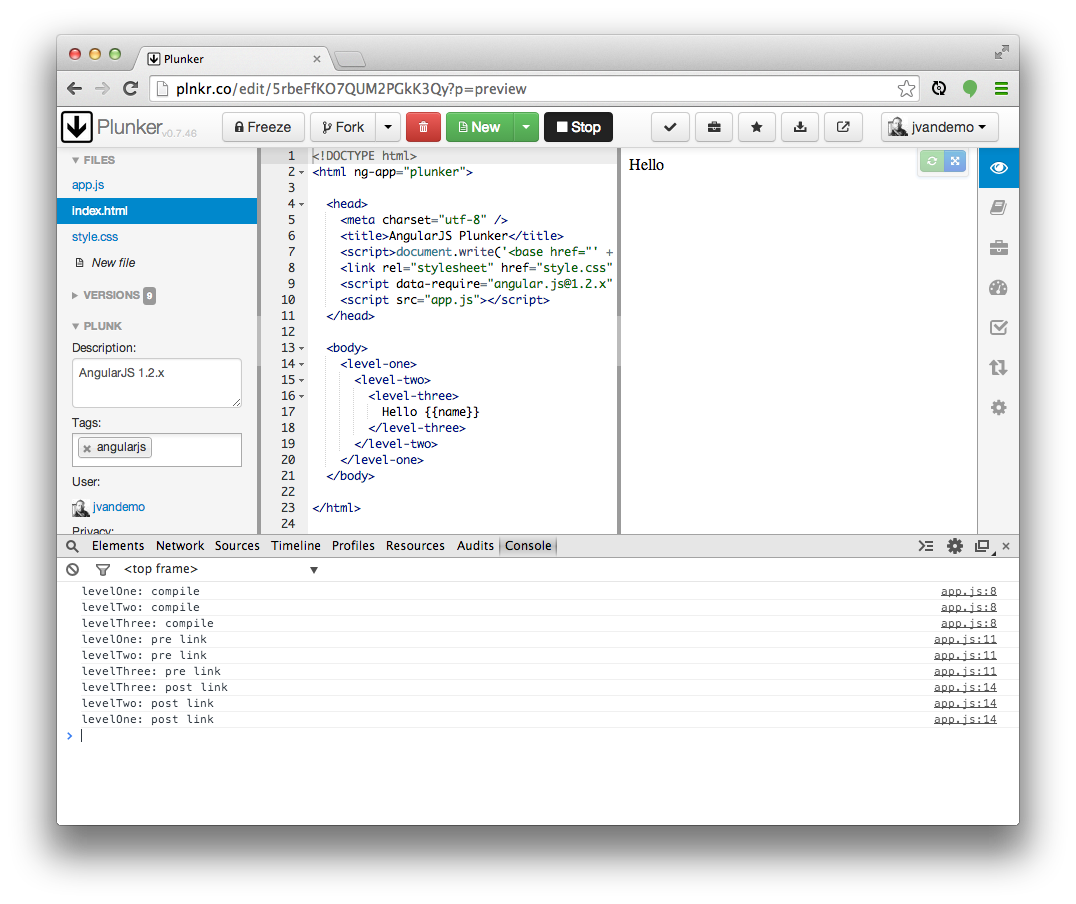
可以看到compile阶段与pre-link阶段是DOM结点层层深入的正向过程,post-link阶段是反向过程。为什么要这样子呢?
那么,我还想要知道,compile阶段与link阶段的区别是什么?而pre-link阶段与post-link阶段的区别又是什么?我们再来看看更加详细的这三者的输出区别,将app.js文件修改一下,打印不同阶段的element变量的原始html标记:
var app = angular.module('plunker', []);function createDirective(name){return function(){return {restrict: 'E',compile: function(tElem, tAttrs){console.log(name + ': compile => ' + tElem.html());return {pre: function(scope, iElem, iAttrs){console.log(name + ': pre link => ' + iElem.html());},post: function(scope, iElem, iAttrs){console.log(name + ': post link => ' + iElem.html());}}}}}}app.directive('levelOne', createDirective('levelOne'));app.directive('levelTwo', createDirective('levelTwo'));app.directive('levelThree', createDirective('levelThree'));
结果如下图:
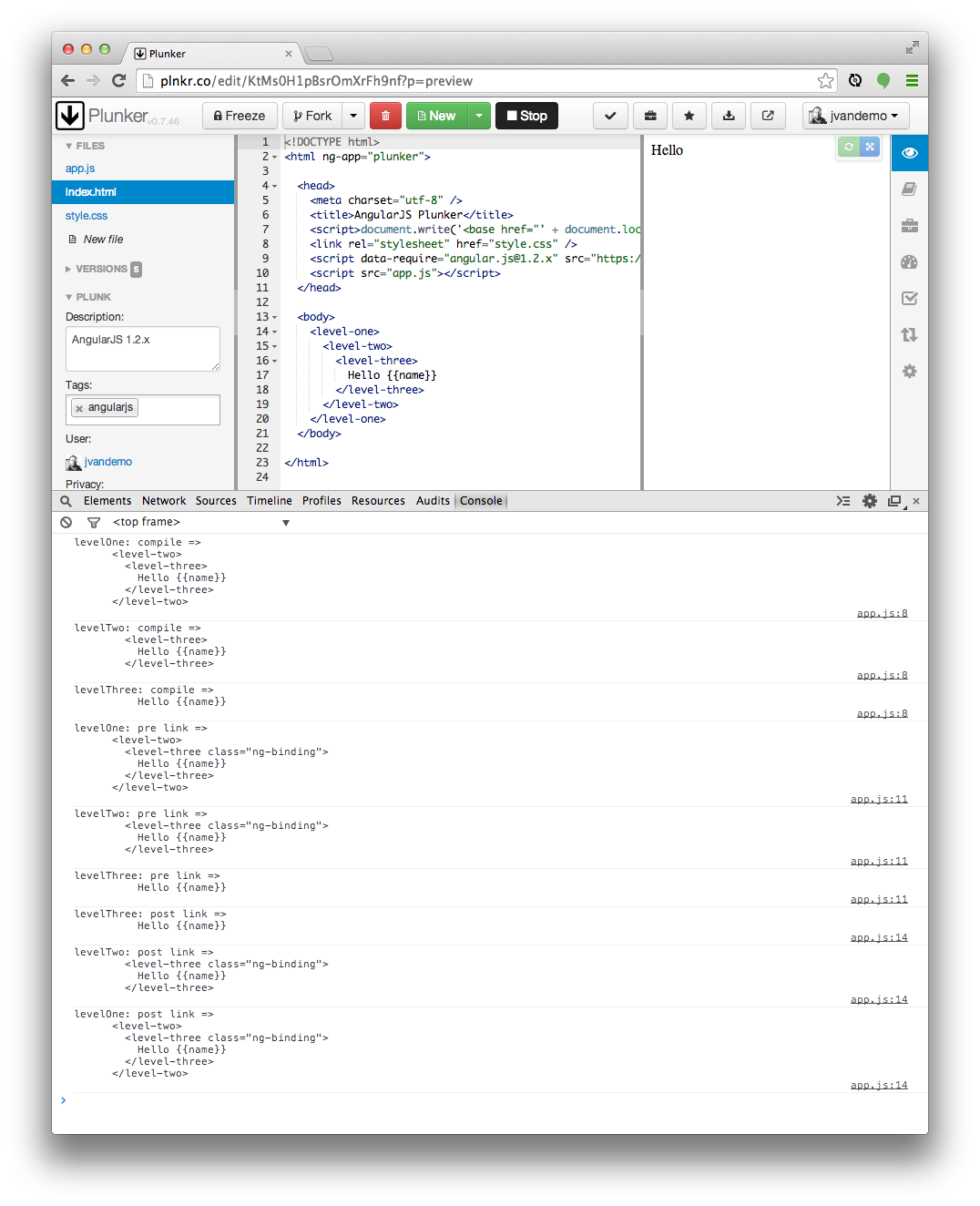
(对tElem.html()不理解?它实际上是一种借鉴jQuery直接对DOM元素操作的手法。请查看网页https://hairui219.gitbooks.io/learning_angular/content/zh/chapter05_5.html 以及API文档 https://docs.angularjs.org/api/ng/function/angular.element 的具体内容)
这个时候,我们就可以更加清晰地看到,compile阶段的DOM内容与link阶段的有了一定的区别。为什么会有这样的区别呢?
详细分析
angularJS解析指令的过程概述
当浏览器渲染一个页面时,本质上是读html标识,然后建立DOM节点,当DOM树创建完毕之后广播一个事件给我们。
当你在页面中使用script标签加载ng应用程序代码时,ng监听上面的DOM完成事件,查找带有ng-app属性的元素。
当找到这样的元素之后,ng开始处理DOM以这个元素的起点,所以假如ng-app被添加到html元素上,则ng就会从html元素开始处理DOM。
从这个起点开始,ng开始递归查找所有子元素里面,符合应用程序里定义好的指令规则。
ng怎样处理指令其实是依赖于指令被定义时的对象属性的,你可以定义一个compile函数或者一个link函数,或者用pre-link和post-link函数来代替link函数。
compile阶段
我们已经知道当ng发现DOM构建完成时就开始处理DOM。所以当ng在遍历DOM的时候,碰到level-one元素,从它的定义那里了解到,要执行一些必要的函数。
因为compile函数定义在level-one指令的指令对象里,所以它会被调用并传递一个element对象作为它的参数。如果你仔细观察,就会看到,浏览器创建这个element对象时,仍然是最原始的html标记。element对象的理解可以参考:https://docs.angularjs.org/api/ng/function/angular.element。
在ng中,原始DOM通常用来标识template element,所以在定义compile函数参数时就用到了tElem名字,这个变量指向的就是template element。一旦运行levelone指令中的compile函数,ng就会递归深度遍历它的DOM节点,然后在level-two与level-three上面重复这些操作。
即compile阶段处理的DOM是原始的DOM(template element),compile阶段可以修改template element。这是非常重要的一个认知。从参数列表中也可以看到,它并没有scope这个参数,并没有与作用域绑定在一起。
compile阶段可以修改template element,这也是其一个非常重要的应用:可以应用于当需要生成多个element实例,只有一个template element的情况。ng-repeat内置指令就是一个最好的例子,它就在是compile函数阶段改变原始的DOM生成多个原始DOM节点,然后每个又生成element实例。因为这个阶段DOM并没有与任何作用域数据进行绑定,意味着此时对DOM进行操作只会有很少的性能开销。
post-link阶段
深入了解pre-link函数之前,让我们来看看post-link函数。如果在定义指令的时候只使用了一个link函数,那么ng会把这个函数当成post-link来处理,因此我们要先讨论这个函数。
当ng遍历完所有的dom并运行完所有的compile函数之后,就反向调用相关联的post-link函数。具体过程我们来看下图:
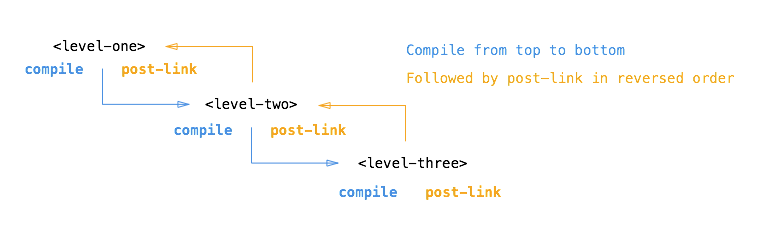
DOM现在开始反向,并执行post-link函数,在之前这种反向的调用看起来有点奇怪,其实这样做是非常有意义的:当运行包含子指令的指令post-link时,反向的post-link规则可以保证它的子指令的post-link是已经运行过的。在我们的例子中,当运行level-one指令的post-link函数的时候,我们能够保证level-two和level-three的post-link其实都已经运行过了。这就是为什么人们都认为post-link是最安全或者默认的写业务逻辑的地方。
但是为什么这里的element跟compile相比为什么会有不同呢?从例子中我们已经看到了不同。
原因在于:一旦ng调用过指令的compile函数,就会创建一个template element的element实例对象,并且为它提供一个scope对象。这个scope有可能是新实例,也有可能是已经存在,可能是子scope,也有可能是独立的scope,这些都得依赖指令定义对象里的scope属性值(相关内容可以查看:https://www.zybuluo.com/frank-shaw/note/482388)。
所以当linking发生时,这个实例element以及scope对象已经是可用的了,并且被ng作为参数传递到post-link函数的参数列表中去。
关键点在于:post-link(pre-link)函数的element参数对象是一个element实例而不是一个template element,而且作用域与DOM已经发生了绑定。所以你会看到例子中输出的不一样。
pre-link阶段
当写了一个post-link函数,你可以保证在执行post-link函数的时候,它的所有子级指令的post-link函数是已经执行过的。在大部分的情况下,它都可以做的更好,因此通常我们都会使用它来编写指令代码。
然而,ng为我们提供了一个附加的hook机制,那就是pre-link函数,它能够保证在执行所有子指令的post-link函数之前运行一些别的代码。
这句话是值得反复推敲的:pre-link函数能够保证在element实例上以及它的所有子指令的post-link运行之前执行。
个人理解:pre-link函数的存在主要是为了共享作用域scope的变量的。假设一种情况:子指令的post-link是在父指令的post-link之前执行的,如果子指令的post-link要用到父指令作用域的某些变量呢?这个时候pre-link函数就可以派上用场了。这方面的理解还不够,以后添加吧。
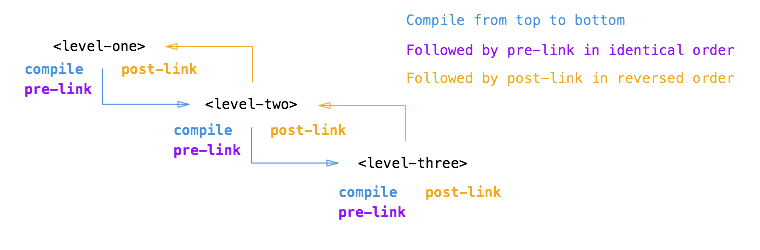
下面是整个过程的流程图:
Notice
compile与link选项是互斥的。如果同时设置了这两个选项,那么会把compile所返回的函数当做link函数,而link选项本身则会被忽略。这也就是为什么之前的例子中在compile函数内部设置link的原因。两者的作用区分:
compile函数负责对template element做一定的修改,而link函数负责将作用域与DOM进行连接,在link内部可以设置事件监听器、监视数据变化和实时操作DOM。
