@frank-shaw
2020-02-13T01:39:28.000000Z
字数 3791
阅读 1931
Web性能优化(六):浏览器是如何工作的?
web性能
在前端开发过程中,我们和浏览器打交道的时间可能是最多的。但是,很多时候我们只知道浏览器能够做什么,至于它内部是怎么工作的,我们却并不清楚。
甚至有时候会质疑:“了解浏览器的工作原理,对于前端而言,是必要的吗?学了之后有啥用?” 事实上,了解浏览器的工作原理(只需要了解其中的大致过程),对于我们日常开发的帮助很大,特别是性能优化这一块。
请听我慢慢说来。
1. 浏览器的“心”
浏览器的“心”,说的就是浏览器的内核,它是浏览器当中最为重要的模块。在研究浏览器微观的运行机制之前,我们首先要对浏览器内核有一个宏观的了解。
通常,浏览器内核也被称为渲染引擎。所谓的渲染,就是根据描述或者定义构建数学模型,通过模型生成图像的过程。

如今市面上常见的浏览器内核可以分为这四种:Trident(IE)、Gecko(火狐)、Blink(Chrome、Opera)、Webkit(Safari)。
其中,最为著名的就是 WebKit。它是苹果 Safari 浏览器的内核。在2005年,苹果将 WebKit 项目开源。2008年的 Google 以开源项目 WebKit 作为内核,创建了一个新的项目 Chromium。而后来的浏览器王者 Chrome 正是诞生自 Chromium 中。虽然在后来持续的迭代汇中 Chrome 将内核换成了 Blink,但 Blink 其实也是基于 WebKit 衍生的一个分支。从这个角度看,Webkit 内核是当下浏览器世界真正的霸主。
下面就以 WebKit 为例,深入了解浏览器内核(渲染引擎)包含的模块。
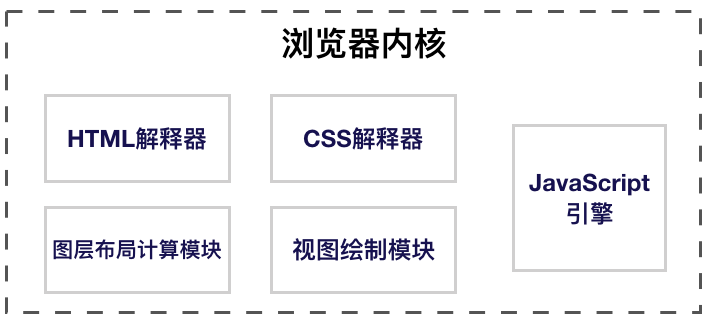
从上图可以看出,浏览器内核(渲染引擎)是由多个模块协同配合来进行工作的。其中我们最需要关注的,就是 HTML 解释器、CSS 解释器、图层布局计算模块、视图绘制模块与JavaScript 引擎这几大模块。
- HTML 解释器:将 HTML 文档经过词法分析输出 DOM 树。
- CSS 解释器:解析 CSS 文档, 生成样式规则。
- 图层布局计算模块:布局计算每个对象的精确位置和大小。
- 视图绘制模块:进行具体节点的图像绘制,将像素渲染到屏幕上。
- JavaScript 引擎:编译执行 Javascript 代码。
在浏览器内核中,由于 JavaScript 引擎越来越独立,我们倾向于将 JavaScript 引擎单独拎出来,而将剩余的部分统称为 WebCore。
2. 浏览器渲染过程
有了对组成模块的了解,我们就可以跑一遍浏览器的渲染流程了。浏览器的每一个页面,在首次渲染时都会经历如下的几个阶段(图中箭头不代表串行,有一些操作是并行进行的,仅为了方便理解):
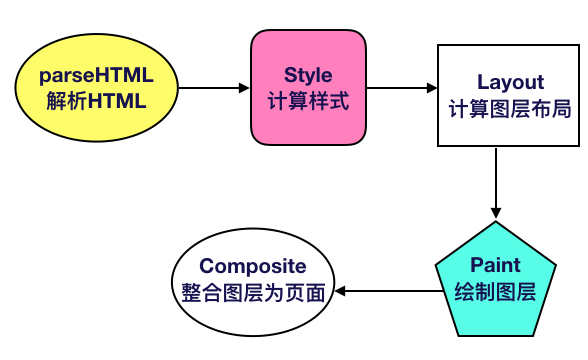
(以下步骤参考的是《WebKit 技术内幕》第二章)
2.1 解析 HTML
在这一步,网页被交给HTML 解释器转变为一系列的词(Token)。解释器根据词(Token)构建节点(Node),形成 DOM 树。如果节点是 JavaScript 代码的话,调用 JavaScript 引擎解释并执行。
如果节点需要依赖其他资源(非 JavaScript 资源),例如图片、CSS、视频等,调用资源加载器来加载它们。但它们是异步加载的,不会阻碍当前 DOM 树的继续创建。如果是 JavaScript 资源URL(没有标记异步方式),则需要停止当前 DOM 树的构建,直到 JavaScript 的资源加载并被 JavaScript 引擎执行后才继续 DOM 树的创建。
网页在加载和渲染过程红鞥中会发出“DOMContent”事件和 DOM 的“onLoad”事件。其中,“DOMContent”事件发生在 DOM 树构建完之后;而 DOM 的“onLoad”事件发生在 DOM 树构建完并且网页所依赖的资源都加载完之后。
2.2 计算样式
值得注意的是:只有当 CSS 文件被加载进来之后,CSS 解释器才能够开始工作。
被加载进来的 CSS 文件 被 CSS 解释器解析为内部表示结构(可以理解为一个样式规则列表)。CSS 解析器工作的过程是与 HTML 解析器是并行工作的。
2.3 计算图层布局
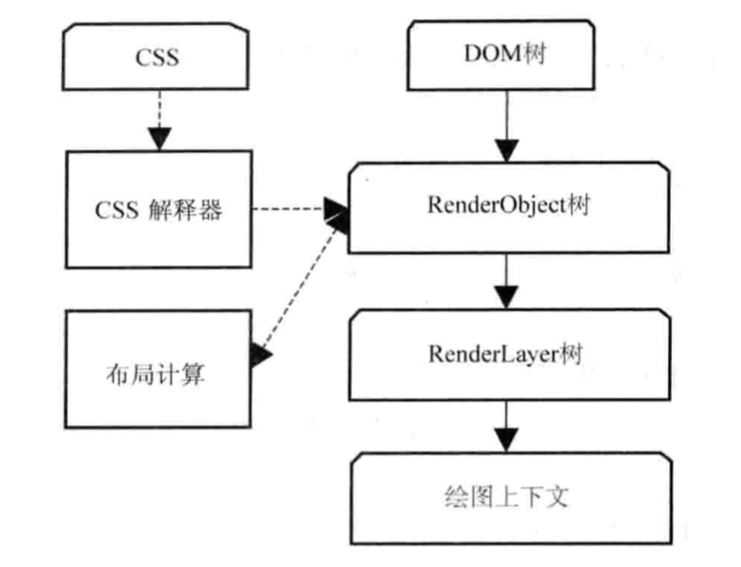
当步骤 2.1 的 DOM 树与步骤 2.2 的样式规则列表都生成完成之后,两者就会结合起来构建 RenderObject 树。 具体做法是根据已知的 DOM 树结构,从样式规则列表中选择出合适的规则附加在 DOM 树中,这就是 RenderObject 树。
RenderObject 树的建立并不表示 DOM 树会被销毁。事实上,整个过程中的多种表示结构(包括 DOM 树、CSS 解析后的样式规则列表、RenderObject 树以及下面提到的 RenderLayer 树、绘图上下文)会一直存在,直到网页被销毁。
2.4 绘制图层
RenderObject 节点在创建的同时, WebKit 会根据网页的层次结构构建 RenderLayer 树,同时构建一个虚拟的绘图上下文。
2.5 整合图层,得到页面
最终会根据绘图上下文来生成最终的图像,这个过程主要依赖 2D 和 3D 图形库。
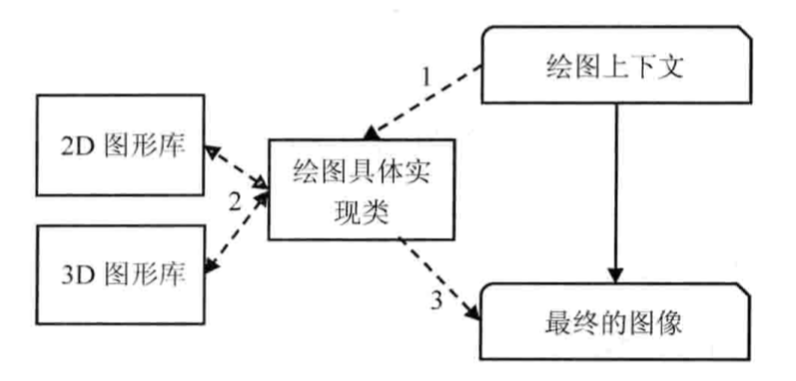
整个渲染过程看过了之后,我们就能够明白:首先是基于 HTML 构建一个 DOM 树,这棵 DOM 树与 CSS 解释器解析出的样式规则列表相结合,就有了 RenderObject 树。最后浏览器以 RenderObject 树为蓝本,去计算布局并绘制图像,我们页面的初次渲染就大功告成了。
之后每当一个新元素加入到这个 DOM 树当中,浏览器便会通过 CSS 引擎查遍 CSS 解释器解析出的样式规则列表,找到符合该元素的样式规则应用到这个元素上,然后再重新去绘制它。
3. 基于渲染过程的优化建议
实际的渲染过程其实比上文所描述的要复杂,后面的文章还会提到 CSS 中的回流(Reflow)与重绘(Repaint)。不过现在,让我们先基于已了解的这个渲染过程,看看有什么可以优化的点吧!
3.1 CSS 与 JS 的加载顺序优化
CSS 文件加载顺序提前
在步骤 2.3 我们提到:“当步骤 2.1 的 DOM 树与步骤 2.2 的样式规则列表都生成完成之后,两者就会结合起来构建 RenderObject 树”。而 CSS 样式规则列表的生成,依赖 CSS 源文件的加载。也就是说,RenderObject 树的构建依赖 CSS 源文件的加载。即:
CSS 是阻塞渲染的资源。需要将它尽早、尽快地下载到客户端,以便缩短首次渲染的时间。
事实上,现在很多团队都已经做到了尽早(将 CSS 放在 head 标签里)和尽快(启用 CDN 实现静态资源加载速度的优化)。这个“把 CSS 往前放”的动作,对很多同学来说已经内化为一种编码习惯。那么现在我们还应该知道,这个“习惯”不是空穴来风,它是由 CSS 的特性决定的。
JS 加载方式的合理选择
在步骤 2.1 中我们提到了 JavaScript 文件对 HTML 解析的影响。只要遇到了节点为 JavaScript 代码或者JavaScript 资源(没有标明异步方式)需要加载的时候,渲染线程就要将执行权交给 JavaScript 引擎。这就直接导致了整个渲染过程的阻塞。
浏览器之所以让 JavaScript 阻塞其它的活动,是因为它不知道 JavaScript 会做什么改变,担心如果不阻止后续的操作,会造成混乱(因为 JavaScript 代码可以通过对应的 Web API 去修改 DOM 与 CSS)。
但是我们是写代码的人,我们知道代码会做什么改变。假如我们可以确认一个 JavaScript 文件的执行时机并不一定非要是此时此刻,我们就可以通过对它使用 defer 和 async 来避免不必要的阻塞,这里我们就引出了外部 JavaScript文件 的三种加载方式。
JS 文件的三种加载方式
- 正常模式:
<script src="index.js"></script>
这种情况下 JS 会阻塞浏览器,浏览器必须等待 index.js 加载和执行完毕才能去做其它事情。

- async 模式:
<script async src="index.js"></script>
async 模式下,JS 不会阻塞浏览器做任何其它的事情。它的加载是异步的,当它加载结束,JS 脚本会立即执行。

defer 模式:
defer 模式下,JS 的加载是异步的,执行是被推迟的。等整个HTML文档解析完成,被标记了 defer 的 JS 文件才会开始依次执行。

从应用的角度来说,一般当我们的脚本与 DOM 元素和其它脚本之间的依赖关系不强时,我们会选用 async;当脚本依赖于 DOM 元素和其它脚本的执行结果时,我们会选用 defer。
在 async 模式 和 defer 模式中,我们还可以选择将 JS 文件放到 HTML 的 head 中,这样可以更进一步地提高效率。
通过审时度势地向 script 标签添加 async/defer,我们就可以告诉浏览器在等待脚本可用期间不阻止渲染的工作,这样可以显著提升性能。
3.2 CSS 样式表规则的优化
渲染过程中多次提到了 CSS 解释器以及它解析出来的样式规则列表:首次生成 RenderObject 树的时候需要用到它,当页面有更新的时候也要再次用到它。这个从样式规则列表中匹配相应样式规则的操作,会是频繁发生的。
(针对 CSS 样式表规则的匹配,有资料说是“从右向左”,也有说是“从左往右”。笔者暂时无法找到确切资料来论证。顾在此不表态。)
为了让这个匹配的过程的消耗尽可能少,我们至少可以总结出如下性能提升的方案:
- 避免使用通配符,只对需要用到的元素进行选择。
- 关注可以通过继承实现的属性,避免重复匹配重复定义。
- 少用标签选择器。如果可以,用类选择器替代。
- 减少嵌套。尽量不要超过三层。
4. 小结
本文讲述了浏览器内核的渲染过程,并给出了实用性的优化建议。希望有用~
