@frank-shaw
2015-11-04T00:20:48.000000Z
字数 3162
阅读 8019
hadoop伪分布下三个配置文件的参数含义说明core-site.xml、hdfs-site.xml mapred-site.xml
Hadoop
伪分布下需要设置这些文件的配置参数,但是不知从何下手,看到这篇文章:
http://www.iyunv.com/thread-17698-1-1.html
同时在看官方文档的时候,讲到了需要注意PID变量的设置,于是找到了这一篇较好的文章,http://www.micmiu.com/bigdata/hadoop/hadoop-hbase-pid-dir-config/ 这样的配置还算是比较齐全的考虑。具体如下:
第一步
配置位于$JAVA_HOME/etc/hadoop/里的hadoop-env.sh文件,需要在原来那个export JAVA_HOME={....}的地方修改为你安装java路径的地方:
export JAVA_HOME=/usr/local/jdk1.8.0_65
同时在文件的末尾处修改export HADOOP_PID_DIR={...}的地方修改为一个专门保持PID的文件夹,默认的HADOOP_PID_DIR存放在的是/tmp文件夹,这个文件夹会被定期清理,如果不修改在日后查找进程ID或者关闭进程的时候比较麻烦。在这里我把他设定为
export HADOOP_PID_DIR=/home/master/pid_dir
根据官方文档的指示,还需要在yarn-env.sh中修改JAVA_HOME信息,与hadoop-env.sh的修改类似。在此不重复了。
第二步
修改core-site.xml、hdfs-site.xml、mapred-site.xml文件。
看了文件/usr/local/hadoop/share/doc/hadoop/share/doc/hadoop/hadoop-project-dist/hadoop-common/core-default.xml里的默认配置,真的是吓坏了,一大坨都是个啥。这么多配置啊原来。看是看到开头有一句话:Do not modify this file directly. Instead, copy entries that you wish to modify from this file into core-site.xml and change them there. 这样子心里也就舒坦多了。不用这么纠结了。原来只需要配置一些需要用到的属性就可以了,未修改的部分就都是默认选项。那么我们也就可以按照网上的一些配置来设置即可。
由于我使用的版本是Hadoop2.5.2,查看了相关的一些配置上的指导:
http://www.yiibai.com/hadoop/hadoop_enviornment_setup.html
http://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-yarn/#_3.2_hadoop_0.23.0
清单 1.core-site.xml 配置
<configuration><property><name>fs.defaultFS</name><value>hdfs://master:9100</value></property></configuration>
hdfs-site.xml配置:
<configuration><property><name>dfs.replication</name><value>1</value></property><property><description>这里的/home/master/文件夹是当前用户master的主文件夹.</description><name>dfs.name.dir</name><value>file:/home/master/hadoopinfra/hdfs/namenode </value></property><property><name>dfs.data.dir</name><value>file:/home/master/hadoopinfra/hdfs/datanode </value></property></configuration>
在设置mapred-site.xml之前,它本来并不存在,需要从另一个文件copy一份,执行指令:
copy mapred-site.xml.template mapred-site.xml
mapred-site.xml 配置如下:
<configuration><property><name>mapreduce.framework.name</name><value>Yarn</value></property></configuration>
Yarn-site.xml 配置
<?xml version="1.0"?><configuration><!-- Site specific YARN configuration properties --><property><name>Yarn.nodemanager.aux-services</name><value>mapreduce.shuffle</value></property><property><description>The address of the applications manager interface in the RM.</description><name>Yarn.resourcemanager.address</name><value>master:18040</value></property><property><description>The address of the scheduler interface.这里可以使用master是因为已经将其与ip地址挂钩啦</description><name>Yarn.resourcemanager.scheduler.address</name><value>master:18030</value></property><property><description>The address of the RM web application.</description><name>Yarn.resourcemanager.webapp.address</name><value>master:18088</value></property><property><description>The address of the resource tracker interface.</description><name>Yarn.resourcemanager.resource-tracker.address</name><value>master:8025</value></property></configuration>
至此,已经将Hadoop初步的环境配置好了,在启动之前还需要格式化namenode。
输入命令“hadoop namenode -format”;
启动命令:
start-dfs.sh
start-yarn.sh
可以再虚拟机上查看到当前集群的状态:
网址为:http://192.168.137.80:50070
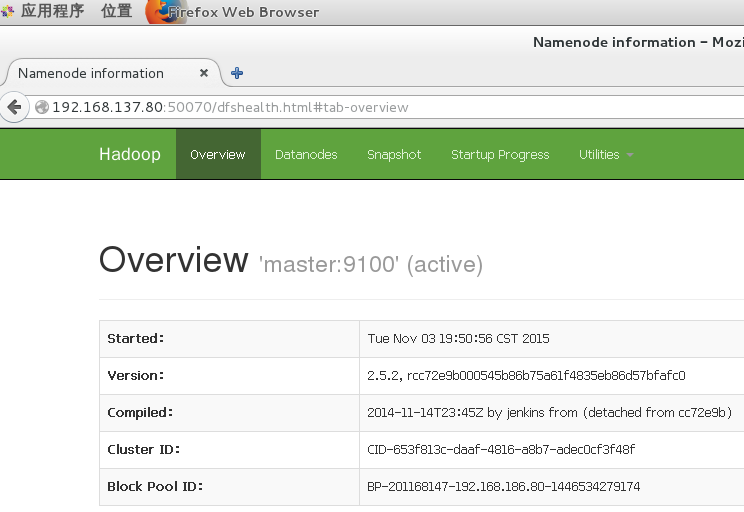
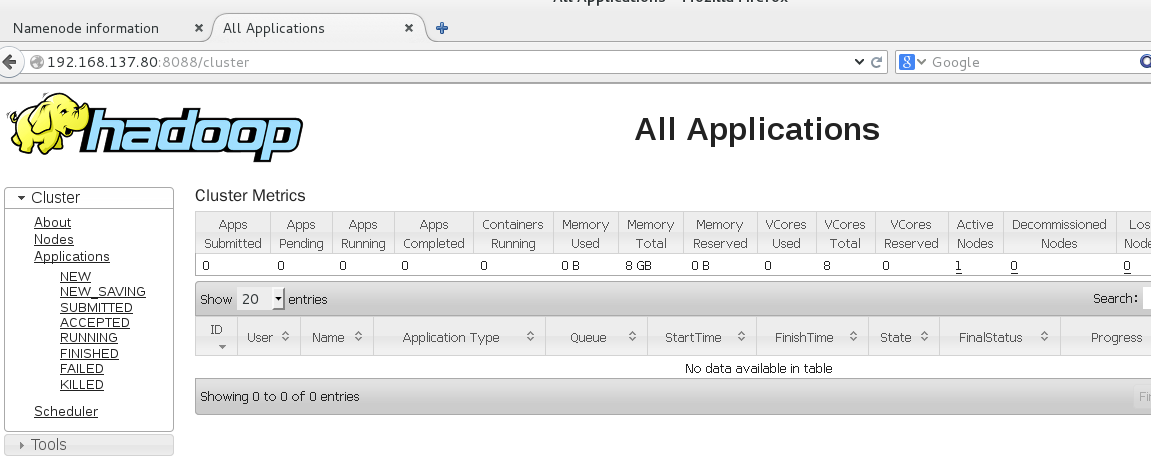
查看yarn的状态:
网址为:192.168.137.80:8088
停止命令:
stop-yarn.sh
stop-dfs.sh
在这个过程中并没有这么顺利,会遇到各种问题,只需要看着出现的错误,一步一步来就可以了。网上别人也遇到了很多的错误,这个时候需要有耐心,参考别人的做法(并不是全部抄过来,他人也有错的)。最后能够看到两个画面真的是挺激动的。
