@frank-shaw
2015-11-05T11:40:02.000000Z
字数 2784
阅读 2306
linux下安装Hadoopeclipse插件以及编写第一个简单的MapReduce程序
Hadoop
安装eclipse这个不难。网上太多的教程,一找一大把。熟悉了之后也不再需要看教程就可以自己安装成功。注意这里选择eclipse版本也是有讲究的,选择keptler版比较好,在之后的eclipse Hadoop插件的兼容性上表现较好。
这里的难点在于想要在eclipse上面能够运行编写好mapreduce程序之后能够直接通过Hadoop来运行,并且能够实时在eclipse上实时查看HDFS上的资源的情况(对于熟悉了在eclipse上开发的java程序员来说,这真的是一种福音啊),这就难了。
难点在哪?需要自己编译plugin插件。从Github网站下载源码,地址为:https://github.com/winghc/hadoop2x-eclipse-plugin 在自己摸索的同时参考了网上很多的资料,如何编译的问题。由于我的Hadoop版本是2.5.2,查看了资料有:
http://www.2cto.com/database/201412/358909.html
上面的资料详细,我自己跟着一步一步修改,调试。但是也有不足,最后都没有说清楚就没了。自己一直编译都过不去,很是郁闷。到后来又是一直查资料的过程,很累。最后又回到了Github源代码的出处上来了。有很多下载了的人都会讨论遇到的问题,而源代码的贡献者也直接回复这些问题,本质上源码需要修改的部分也不是很多,这里就可以找到很多你的疑惑相关的解决方案。我自己终于醒悟:万事还是要从源头找答案才可以,这样做才是根本。学习是这样,生活也是这样。
最后都没有编译成功。下载的源码当中是有直接编译好的插件的,但是版本和我正在使用的版本不同,分别是2.2、2.4、2.6,由于我的是2.5.2,所以一开始没有去尝试直接运行这些插件,而是先自己编译。这样做的原因是想要通过自己努力得到最符合自己的,另一个原因是网上说不同版本之间的兼容性并不是那么好,不够稳定。
但是编译不成功也是没有办法,只有试试这些已经编译好的插件了,我选择了2.6,结果发现竟然可行。真的是惊喜。不过这里我自己并不清楚怎样是可行,怎样是不可行的。这个认知上的欠缺让我费了不少时间,应该是我第一次尝试使用2.6插件的时候就成功了的,但是我自己以为还不成功,于是又去折腾2.4 ,2.4不行了之后再试2.6,唉,真的是笨啊。
现在就来说说怎样的才是可行的插件,其实不难。不过要自己意识到不是那么容易。把下载下来的源码中有一个release文件夹,将该文件夹下的文件 复制到你安装的eclipse文件夹的plugins文件夹下面。

我算是比较幸运的,这个2.6.0版本竟然可以直接在我的Hadoop2.5.2上面直接使用,感觉还是很爽的。希望你也有这样的运气。在进行接下来的步骤以前,先开启HDFS,使用指令
start-dfs.sh
即可。这样做的原因是,验证下面的location连接是否成功的前提是你必须先把HDFS开启。
重启eclipse,这个时候点击window -> show view -> other -> 输入map之后就直接会出来这个淘气的小象啦:
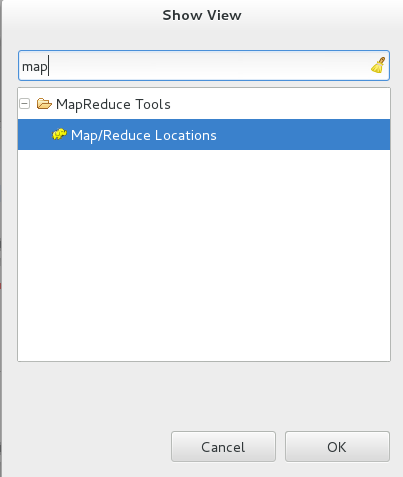
点击它,然后OK。这样子就有了这个画面:
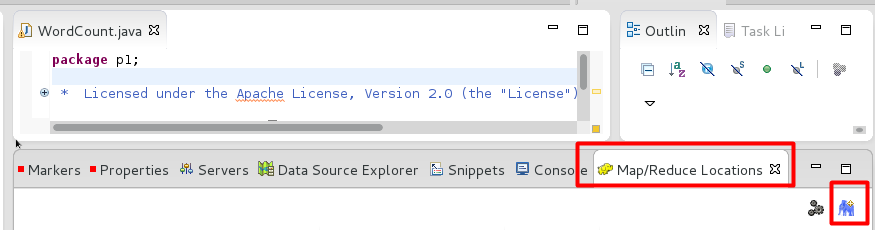
点击右下角的蓝色小象,会出现配置的画面:
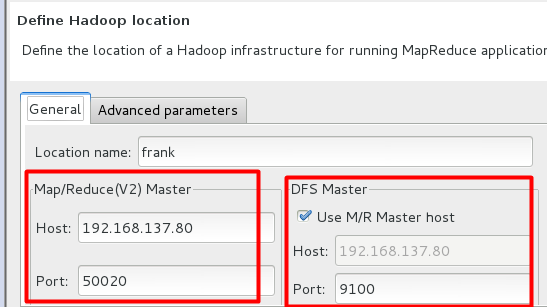
这里的配置其实也是挺纠结的。location name这个没有难度,Host这里只需要填写你的主机的ip就可以,Use M/R Master host:前面的勾上(因为我们的NameNode和JobTracker都在一个机器上)。难点在于Port怎么填。DFS Master的Port可以参照配置文件core-site.xml里面的fs.defaultFS的值来写。而Map/Reduce Master里的这个Port,网上有人说依照hdfs-site.xml里面的配置来写,可惜的是我的hdfs-site.xml里面没有配置相应的值。想到的是某些值如果没有人工配置的话,是有默认值的,去找了一下Hadoop文件夹下的一个hdfs-default.xml文件,找到了里面的默认参数,经过确定之后填写了50020。点击确定。会有下面的画面出现:

这个时候就已经有了成功的征兆了。
那么,怎样才算是真的成功了呢?点击DFS Locations,会出现这个:
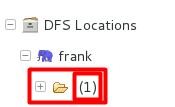
这里的DFS Locations就是Hadoop文件系统存储的目录树。值得注意的是这里的1是因为我自己添加了文件进去才有1,如果在第一次得到这个图像的时候,应该是0.(我之前看别人博客上显示的都是1,我以为自己出现的0就是没有连接上,哭死。。)
但是,如果出现了下面这个图:
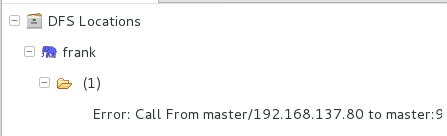
说明你的HDFS没有打开或者没有连接成功,需要打开HDFS再试试。
你可以对着这个文件夹,右击,有各种选项,可以增加文件夹,可以从本地上传文件到Hadoop文件系统里。在增加文件夹或者从本地上传文件之后,右击该文件夹,选择“刷新”选项,如果能够出来你希望的文件夹或文件,那么就表示成功配置好了。就这么简单。
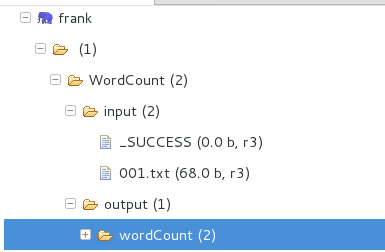
很高兴啊。折腾了这么久终于得到了想要的结果~~~
我的另一个疑问又来了,这个HDFS locations在文件中具体在文件夹的哪里呢?我怎么知道怎样获取这些文件呢?如果不是界面,而是命令行,我该怎样通过指令来获取HDFS上的文件呢?
其实啊,刚刚讲了这个HDFS locations其实是一颗目录树,那么这个根就是htfs://192.168.137.80:9100(当然,因人而异啊,不过想要表达的意思你懂得)。那么我们在填写的时候想要上图的001.txt文件,那么就是需要写上htfs://192.168.137.80:9100/WordCount/input/001.txt就可以了。
如果你非要问这个文件到底在内存的什么地方,我只能告诉你,在配置文件的时候,你有配置过datanode文件所在的文件位置,那么它就在相应位置的current文件夹里,里面的信息似乎还不是最终的文件位置。你可以找到配置信息然后去目录中找找。不过由于HDFS是分块存放,所以实际上它放在哪里我也不敢确定。
wordCount程序编写的注意事项:
1.程序到处都有,这里自己去找啊~
2.我不仅仅要运行wordCount程序,还希望它在Hadoop上运行,输入文件和输出文件都是在HDFS上的,这个时候的设置是这样的:
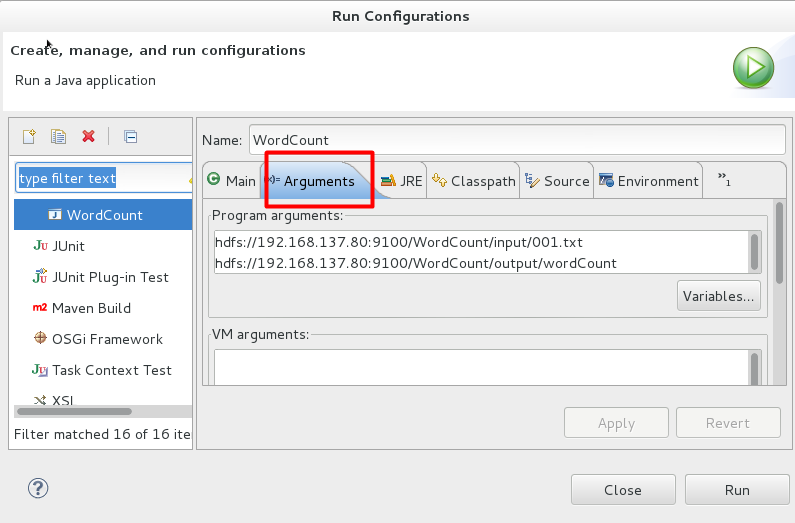
具体参数为:hdfs://192.168.137.80:9100/WordCount/input/001.txt hdfs://192.168.137.80:9100/WordCount/output/wordCount
然后你就可以点击运行了。如果不出意外,在HDFS locations对应的output文件夹里面会有两个文件,就是你要的结果啦~~
