@boothsun
2018-03-14T02:38:10.000000Z
字数 5231
阅读 2220
Zookeeper 入门第一篇
ZK
转载原文地址:
1. ZooKeeper学习总结 第一篇:ZooKeeper快速入门
2. ZooKeeper学习总结 第二篇:ZooKeeper深入探讨
3. ZooKeeper学习第一期---Zookeeper简单介绍
1. 概述
Zookeeper简单来说就是一个分布式协调技术的具体实现,所谓分布式协调技术就是在集群环境下,协调集群中多台机器并发访问控制,实现临界资源加锁和有序访问,防止造成“脏数据”的后果。所以Zookeeper最常见的应用就是:分布式锁。除此之外,基于Zookeerper提供的其他特性,还产生了更丰富的应用:配置信息维护、分组服务、分布式消息队列、分布式通知/协调等。
前面提到了那么多的服务,比如分布式锁、配置维护、组服务等,那它们是如何实现的呢,我相信这才是大家关心的东西。ZooKeeper在实现这些服务时,首先它设计一种新的数据结构——Znode,然后在该数据结构的基础上定义了一些原语,也就是一些关于该数据结构的一些操作。有了这些数据结构和原语还不够,因为我们的ZooKeeper是工作在一个分布式的环境下,我们的服务是通过消息以网络的形式发送给我们的分布式应用程序,所以还需要一个通知机制——Watcher机制。那么总结一下,ZooKeeper所提供的服务主要是通过:数据结构+原语+watcher机制,三个部分来实现的。
Zookeeper数据模型
Zookeeper数据模型Znode
Zookeeper拥有一个树形的层级结构,这和标准的文件系统非常相似,下图所示:

从图中我们可以看出Zookeeper的数据模型,在结构上和标准文件系统非常相似,都是采用了这种树形层次结构,Zookeeper树中的每个节点被称为——Znode。和文件系统的目录树一样,Zookeeper树中的每个节点可以拥有子节点。下面是Znode的特点:
Znode结构:
Zookeeper命名空间中的Znode,兼具文件(存储)和目录两种特点。既像文件一样维护着数据、元信息、ACL、时间戳等数据结构,又像目录一样可以作为路径标识的一部分。图中的每个节点称为一个Znode。每个Znode由3个部分组成:- stat:此为状态信息, 描述该Znode的版本, 权限等信息
- data:与该Znode关联的数据
- children:该Znode下的子节点
只适合存储小数据
ZooKeeper虽然可以关联一些数据,但并没有被设计为常规的数据库或者大数据存储,相反的是,它用来管理调度数据,比如分布式应用中的配置文件信息、状态信息、汇集位置等等。这些数据的共同特性就是它们都是很小的数据,通常以KB为大小单位。ZooKeeper的服务器和客户端都被设计为严格检查并限制每个Znode的数据大小至多1M,但常规使用中应该远小于此值。总而言之,Zookeeper是被设计用来协调服务的,znode只适合存储小数据Znode路径:
Znode通过路径引用,如同Unix中的文件路径。但路径必须是绝对的,不能使用../这种相对路径,因此路径开头都必须是斜杠来开头,也就是从根路径/开始。除此之外,他们必须是唯一的,也就是说每一个路径只有一个表示,因此这些路径不能改变(但不是数据不能改变)。在Zookeeper中,路径由Unicode字符串组成,并且有一些限制。字符串“/zookeeper”用以保存管理信息。比如关键配置信息。Znode的数据访问
Znode数据读写是原子的,也就是说读操作将获取与节点相关的所有数据,写操作也将替换掉节点的所有数据。另外,每一个节点都拥有自己的ACL(访问控制列表),这个列表规定了用户的权限,即限定了特定用户对目标节点可以执行的操作。Znode的节点类型
Zookeeper中的节点有两种,分别为临时节点和永久节点。节点的类型在创建时即被确定,并且不能改变。- 临时节点(EPHEMERAL):该节点的生命周期仅限于创建它的客户端和服务端之间的连接没有断开,客户端断开连接后,Znode将会被删除。虽然每个临时的Znode都会绑定到一个客户端会话,但它们对所有的客户端还是可见的。另外,Zookeeper的临时节点不允许拥有子节点。
- 永久节点(PERSISTENT):该节点的生命周期不依赖于客户端会话,并且只有在客户端显示执行删除操作的时候,它们才能被删除。
- 顺序节点:当创建Znode的时候,用户可以设置让Zookeeper自动在路径结尾添加一个递增的计数。这个计数值是由一个单调递增的计数器来生成的,且对此节点的父节点来说是唯一的,它的格式为“%10d”(10位数字,没有数值的数位用0补充),例如,创建节点时传入的path是“/aa”,创建后的则可能是“/aa0000000002"。
总结上面, Znode的节点类型有:永久(PERSISTENT)、永久顺序(PERSISTENT_SEQUENTIAL)、临时(EPHEMERAL)、临时顺序(EPHEMERAL_SEQUENTIAL) ,参见:org.apache.zookeeper.CreateMode
- 监视器(Watch)
客户端可以在节点上设置监视器(watch)。当节点状态发生改变时(Znode的增删改)将会触发watch所对应的操作。当watch被触发时,Zookeeper将会向客户端发送且仅发送一条通知,因为watch常常只能被触发一次。后面,将对此块知识点展开叙述。
Zookeeper中的时间
Zookeeper有多种记录时间的形式,其中包含以下几个重要属性:
Zxid
致使Zookeeper节点状态改变的每一个操作都将使节点接收到一个Zxid格式的时间戳,并且这个时间戳全局有序。也就是说,每个对节点的改变都将产生一个唯一的Zxid。如果Zxid1的值小于Zxid2的值,那么Zxid1所对应的事件发生在Zxid2所对应的事件之前。实际上,Zookeeper的每个节点维护着三个Zxid值,分别为:cZxid、mZxid、PZxid。- cZxid:是节点的创建时间所对应的Zxid格式时间戳。
- mZxid:是节点的修改时间所对应的Zxid格式时间戳。
实现中Zxid是一个64位的数字,它高32位是epoch(翻译:时期;纪元;世;新时代)用来标识leader关系是否改变,每次一个leader被选出来,它都会有一个新的epoch。低32位是个递增计数。
版本号
对节点的每一个操作都将致使这个节点的版本号增加。每个节点维护这三个版本号,它们分别为:- version: 节点数据版本号
- cversion:子节点版本号
- aversion:节点所拥有的ACL版本号
总结 --> Zookeeper节点的主要属性
一个节点拥有的表示其状态的主要属性如下图所示:
Znode节点属性结构

ACL(节点访问权限控制)
ACL(即:Access Control List) 访问权限控制列表,Zookeeper就是通过ACL机制来实现对Znode节点的权限控制,Znode在创建时可以带有一个ACL列表。 我们可以从三个方面理解ACL机制,分别是:权限模式(Scheme 权限验证过程中使用的检验策略)、授权对象(ID 权限将要被赋予的对象 )和权限(Permission 权限列表),通常使用“scheme:id:permission”来标识一个有效的ACL信息。
权限模式:Scheme
IP
Ip模式通过IP地址粒度来进行权限控制,例如配置了“ip:192.168.0.110”,即表示权限控制都是针对于这个IP地址的。同时,IP模式也支持按照网段的方式来进行配置,例如“ip:192.168.0.1/24”表示针对于192.168.0.*z这个IP段进行权限控制。Digest
用户名+密码的形式进行验证World
无任何权限校验,所有用户都可以在不进行任何权限校验的情况下操作Zookeeper上的数据。另外,World模式也可以看作是一个特殊的Digest模式,它只有一个权限标识,即“world:anyone”。Super
超级管理员,也是一种特殊的Digest,此用户角色可以对任意Zookeeper上的数据节点进行任何操作。
授权对象:ID
授权对象指的是权限赋予的用户或一个指定实体,例如IP地址或是机器等。在不同的权限模式下,授权对象是不同的。 详见下图:

权限列表

权限管理
在设置ACL时,可以给zk客户端和服务器端的连接设置ACL,也可以在创建znode时;给znode设置ACL,在创建znode后,如果后zk客户端来操作znode,只有满足权限要求时,才能完成相对应的操作。
API规定的权限列表具体可以参见:
1. org.apache.zookeeper.ZooDefs.Ids2. org.apache.zookeeper.ZooDefs.Perms
zk也可以实现自定义权限控制器,Zookeeper自定义的权限控制器需要实现:org.apache.zookeeper.server.auth.AuthenticationProvider
Zookeeper服务中操作
在Zookeeper中有9个基本操作,如下图所示:

更新Zookeeper操作是有限制的。delete或setData必须明确要更新的Znode的版本号,我们可以调用exists找到。如果版本号不匹配,更新将会失败。
更新Zookeeper操作是非阻塞式的。因此客户端如果失去了一个更新(由于另一个进程在同时更新这个Znode 即乐观锁失败),他可以在不阻塞其他进程执行的情况下,选择重新尝试或进行其他操作。
Watcher —— 数据变更的通知
ZooKeeper允许客户端向服务端注册一个Watcher监听,当服务端的一些指定事件触发了这个Watcher,那么就会向指定客户端发送一个事件通知来实现分布式的通知功能。
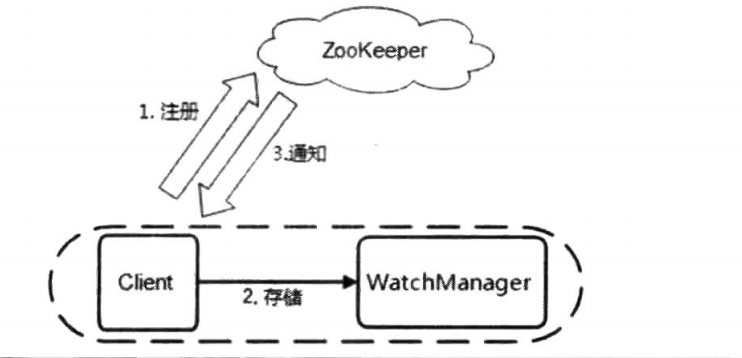
Watcher工作原理
ZooKeeper的Watcher机制主要包括客户端线程、客户端WatchManager和ZooKeeper服务器三部分。在客户端向ZooKeeper服务器注册Watcher的同时,会将Watcher对象存储在客户端的WatchManager中。当ZooKeeper服务器触发Watcher事件后,会向客户端发送通知,客户端线程从WatcherManager中取出对应的Watcher对象来执行回调逻辑。
Watcher事件
Watcher事件= 通知状态(KeeperState) + 事件类型(EventType)。
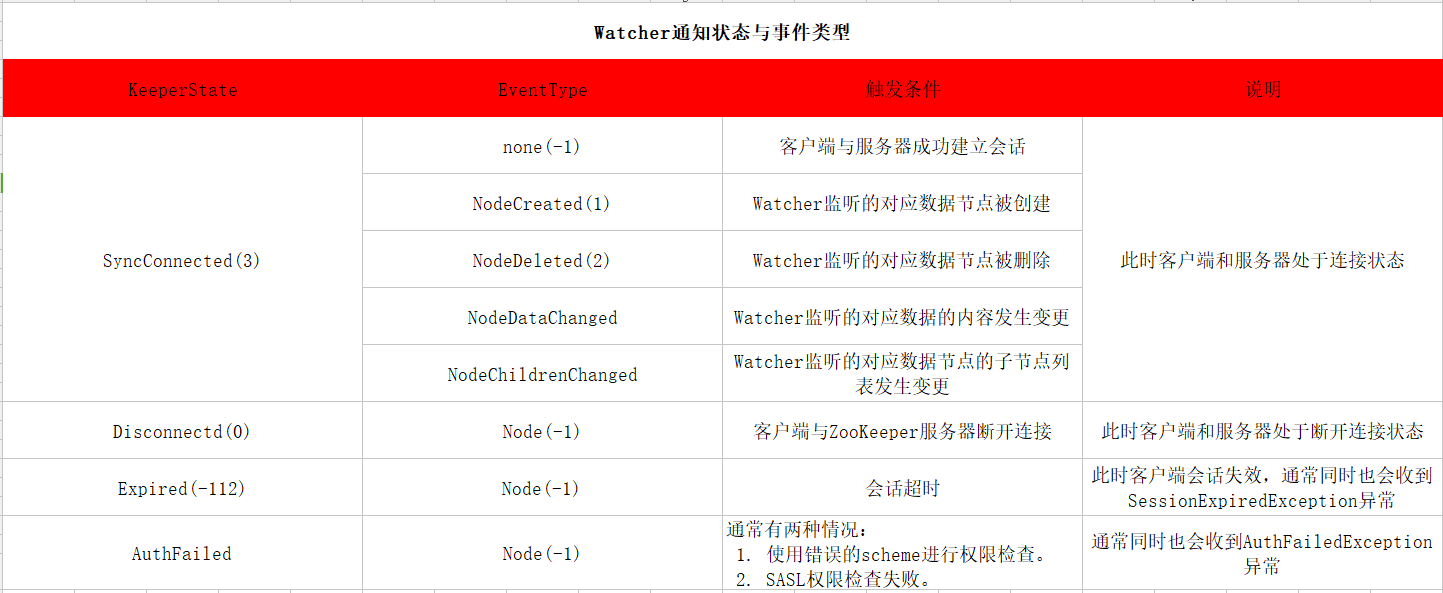
针对于NodeDataChanged事件,Node变更包括节点的数据内容和数据的版本号dataVersion。因此,即使使用相同的数据内容来更新,还是会触发这个事件通知,因为对于ZooKeeper来说,无论数据内容是否变更,一旦有客户端调用了数据更新的接口,且更新成功,就会更新dataVersion值。
NodeChildrenChanged事件会在数据节点的子节点列表发生变更的时候被触发,这里说的子节点列表变化特指子节点个数和组成情况的变更,即新增子节点或删除子节点,而子节点内容的变化是不会触发这个事件。
Watcher的使用
- 在创建ZooKeeper客户端对象实例事,可以向构造方法中传入一个默认的Watcher:
org.apache.zookeeper.ZooKeeper#ZooKeeper(java.lang.String, int, org.apache.zookeeper.Watcher)
此时这个Watcher将作为整个ZooKeeper会话期间的默认Watcher,会一直被保存在客户端ZKWathcerManager的defaultWatcher中。
- 查询方法注册触发器
getData、getChildren、exist三个接口来向ZooKeeper服务器注册Watcher。

- exists操作上的watch,在被见识的Znode创建、删除或数据更新时被触发。
- getData操作上的watch,在被监视的Znode删除或数据更新时被触发。在被创建时不能被触发,因为只有Znode一定存在,getData操作才会成功。
- getChildren操作上的watch,在被监视的Znode的子节点创建或删除,或是这个Znode自身被删除时触发。可以通过查看watch事件类型来区分是Znode,还是他的子节点被删除:NodeDelete表示Znode被删除,NodeDeletedChanged表示子节点被删除。
Watch由客户端所连接的ZooKeeper服务器在本地维护,因此watch可以非常容易地设置、管理和分派。当客户端连接到一个新的服务器时,任何的会话事件都将可能触发watch。另外,当从服务器断开连接的时候,watch将不会被接收。但是,当一个客户端重新建立连接的时候,任何先前注册过的watch都会被重新注册。
