@boothsun
2017-10-22T02:31:15.000000Z
字数 3948
阅读 2105
Windows + IDEA 手动开发MapReduce程序
大数据
- 参见马士兵老师的博文:map_reduce
环境配置
Windows本地解压Hadoop压缩包,然后像配置JDK环境变量一样在系统环境变量里配置HADOOP_HOME和path环境变量。注意:hadoop安装目录尽量不要包含空格或者中文字符。
形如:
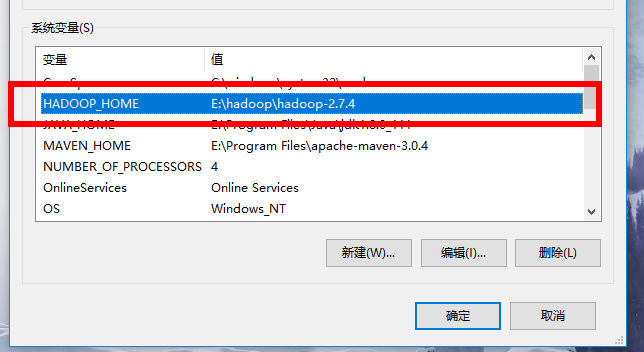
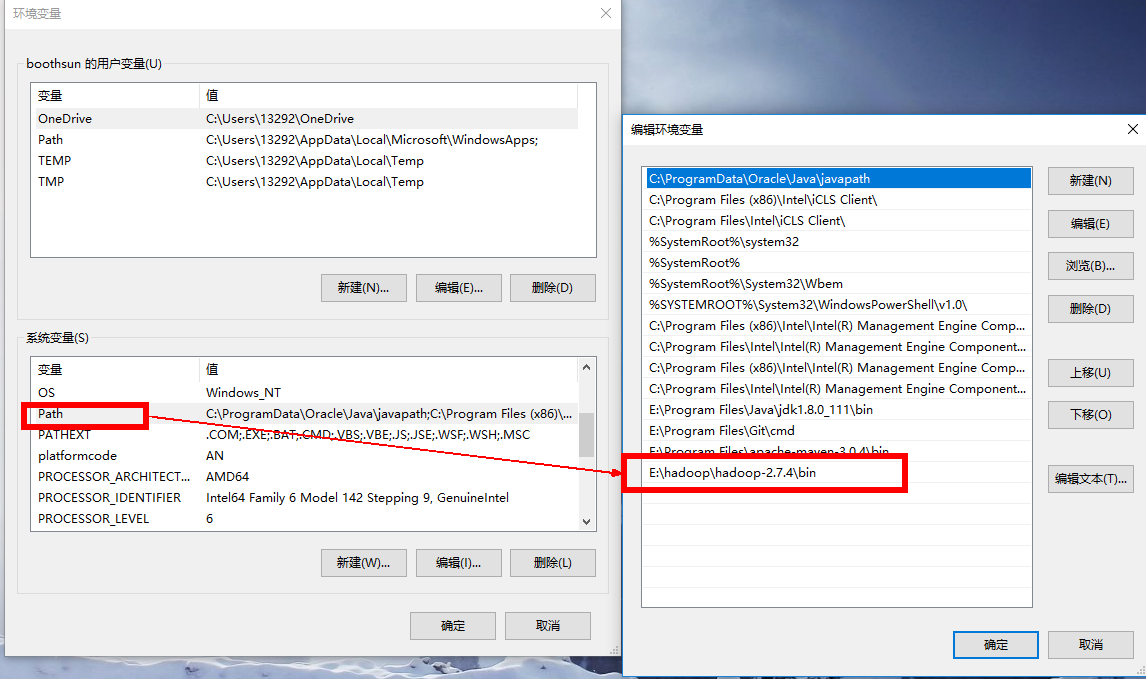
添加windows环境下依赖的库文件
- 把盘中(盘地址 提取码:s6uv)共享的bin目录覆盖HADOOP_HOME/bin目录下的文件。
- 如果还是不行,把其中hadoop.dll复制到C:\windows\system32目录下,可能需要重启机器。
- 注意:配置好之后不需要启动Windows上的Hadoop
pom.xml
<!-- hadoop start --><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-minicluster</artifactId><version>2.7.4</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>2.7.4</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-assemblies</artifactId><version>2.7.4</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-maven-plugins</artifactId><version>2.7.4</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>2.7.4</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>2.7.4</version></dependency><!-- hadoop end -->
代码
WordMapper:
public class WordMapper extends Mapper<Object,Text,Text,IntWritable> {private final static IntWritable one = new IntWritable(1);private Text word = new Text();@Overridepublic void map(Object key , Text value , Context context) throws IOException, InterruptedException{StringTokenizer itr = new StringTokenizer(value.toString()) ;while (itr.hasMoreTokens()) {word.set(itr.nextToken());context.write(word,one);}}}
WordReducer::
public class WordReducer extends Reducer<Text,IntWritable,Text,IntWritable> {private IntWritable result = new IntWritable() ;public void reduce(Text key , Iterable<IntWritable> values, Context context) throws IOException , InterruptedException {int sum = 0 ;for (IntWritable val : values) {sum += val.get();}result.set(sum);context.write(key,result);}}
本地计算 + 本地HDFS文件
public static void main(String[] args) throws Exception{//如果配置好环境变量,没有重启机器,然后报错找不到hadoop.home 可以手动指定// System.setProperty("hadoop.home.dir","E:\\hadoop\\hadoop-2.7.4");List<String> lists = Arrays.asList("E:\\input","E:\\output");Configuration configuration = new Configuration();Job job = new Job(configuration,"word count") ;job.setJarByClass(WordMain.class); // 主类job.setMapperClass(WordMapper.class); // Mapperjob.setCombinerClass(WordReducer.class); //作业合成类job.setReducerClass(WordReducer.class); // reducerjob.setOutputKeyClass(Text.class); // 设置作业输出数据的关键类job.setOutputValueClass(IntWritable.class); // 设置作业输出值类FileInputFormat.addInputPath(job,new Path(lists.get(0))); //文件输入FileOutputFormat.setOutputPath(job,new Path(lists.get(1))); // 文件输出System.exit(job.waitForCompletion(true) ? 0 : 1); //等待完成退出}
本地计算 + 远程HDFS文件
把远程HDFS文件系统中的文件拉到本地来运行。
相比上面的改动点:
FileInputFormat.setInputPaths(job, "hdfs://master:9000/wcinput/");FileOutputFormat.setOutputPath(job, new Path("hdfs://master:9000/wcoutput2/"));
注意这里是把HDFS文件拉到本地来运行,如果观察输出的话会观察到jobID带有local字样,同时这样的运行方式是不需要yarn的(自己停掉jarn服务做实验)。
远程计算 + 远程HDFS文件
这个方式是将文件打成一个jar文件,通过Hadoop Client自动上传到Hadoop集群,然后使用远程HDFS文件进行计算。
java代码:
public static void main(String[] args) throws Exception{Configuration configuration = new Configuration();configuration.set("fs.defaultFS", "hdfs://master:9000/");configuration.set("mapreduce.job.jar", "target/wc.jar");configuration.set("mapreduce.framework.name", "yarn");configuration.set("yarn.resourcemanager.hostname", "master");configuration.set("mapreduce.app-submission.cross-platform", "true");Job job = new Job(configuration,"word count") ;job.setJarByClass(WordMain2.class); // 主类job.setMapperClass(WordMapper.class); // Mapperjob.setCombinerClass(WordReducer.class); //作业合成类job.setReducerClass(WordReducer.class); // reducerjob.setCombinerClass(WordReducer.class); //作业合成类job.setOutputKeyClass(Text.class); // 设置作业输出数据的关键类job.setOutputValueClass(IntWritable.class); // 设置作业输出值类FileInputFormat.setInputPaths(job, "/opt/learning/hadoop/wordcount/*.txt");FileOutputFormat.setOutputPath(job, new Path("/opt/learning/output7/"));System.exit(job.waitForCompletion(true) ? 0 : 1); //等待完成退出}
如果运行过程中遇到权限问题,配置执行时的虚拟机参数 -DHADOOP_USER_NAME=root 。
形如下图:

