@boothsun
2017-11-30T12:46:04.000000Z
字数 1079
阅读 7683
Hive分组取第一条记录
大数据
需求
交易系统,财务要求维护每个用户首个交易完成的订单数据(首单,可取交易完成时间最老的数据)。举例:
简写版的表结构:
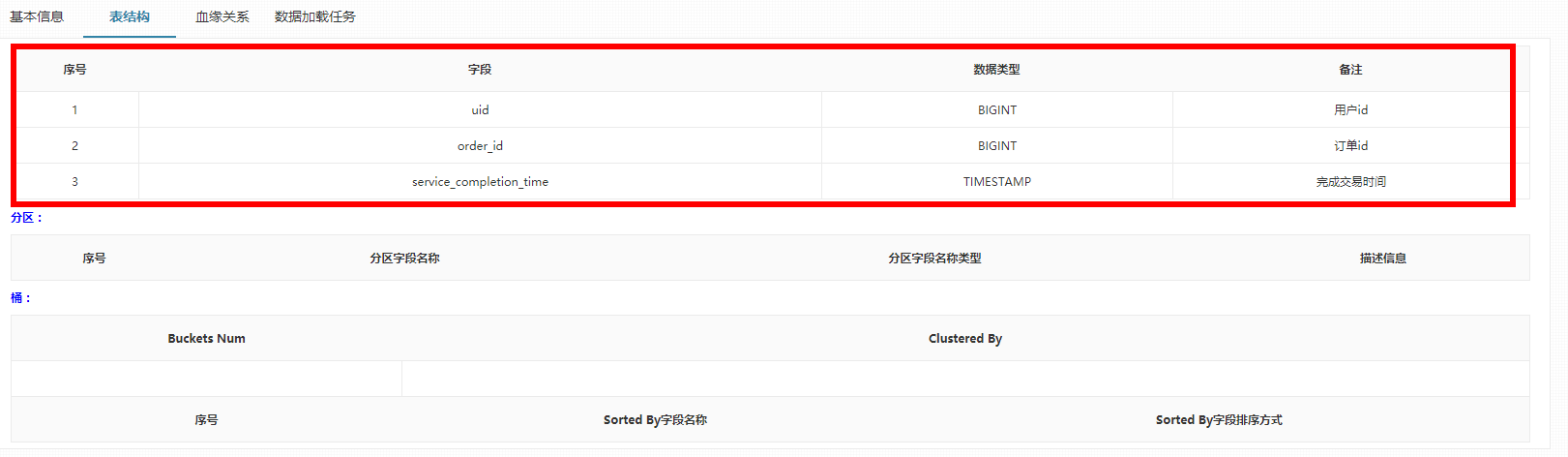
表数据:

则 财务希望汇总记录如下:
| uid | order_id | service_completion_time |
|---|---|---|
| 2 | 44 | 2017-02-03 12:23:01.0 |
| 3 | 33 | 2017-11-30 12:23:01.0 |
hive分组排序函数
语法:row_number() over (partion by fieldA order by fieldB desc) rank
含义:表示根据fieldA分组,在分组内部根据fieldB排序,而row_number() 函数计算的值就表示每组内部排序后的行编号(该编号在组内是连续并且唯一的)。
注意: rank 在这里是别名,可任意
partition by:类似于Hive的建表,分区的意思。
order by : 排序,默认是升序,加desc降序。
需求实现
汇总首单:
select * from (selectuid , order_id ,service_completion_time ,row_number() over ( partition by uid order by service_completion_time asc ) numfromdj_mart_zfpt.test) lastwhere last.num = 1 ;
按uid分组,服务完成时间排序,给每个用户的订单编号。编号最新的(也就是1)就是该用户的首单。
分批汇总:
由于订单越来越多,所以每次不可能全量汇总,为了性能考虑,可以汇总每天每个用户当天的首单,然后往历史首单表插入,如果该uid在历史首单表里已存在,就不插入;否则,说明是该用户真正的首单,则录入历史首单表。
实现:
可以通过历史首单表与本日首单表做右连接或者左连接来插入新的首单记录到历史首单表:
右连接文氏图:

insert into table dj_mart_zfpt.t_trade_new_customerselect new.* from dj_mart_zfpt.t_trade_new_customer old right join (select * from (selectuid , order_id ,service_completion_time ,row_number() over ( partition by uid order by service_completion_time asc ) numfromdj_mart_zfpt.test) last where last.num = 1) new on old.uid = new.uid where old.uid is null;
