@boothsun
2017-10-14T06:58:34.000000Z
字数 2543
阅读 1521
HDFS初识
大数据
- 参看原文【Hadoop】HDFS的运行原理
- 参看原文还不懂HDFS的工作原理?快来扫扫盲
简介
HDFS(Hadoop Distributed File System) Hadoop分布式文件系统。是根据google发表的论文实现的。论文为GFS( Google File System ) Google文件系统。(中文,英文)
HDFS有很多特点:
+ 保存多个副本,且提供容错机制,副本丢失或宕机自动恢复、自动切换。副本默认存3份。
+ 可以运行在廉价的机器上。
+ 适合大数据的处理。多大?多小?HDFS默认会将文件分割为block,64M为一个Block的大小。然后将block按键值对存储在HDFS上,并将键值对的映射存到内存中。如果小文件太多,那内存的负担会很重。

如上图所示,HDFS也是按照Master和Slave的结构。分NameNode、SecondaryNameNode、DataNode这几个角色。
NameNode:是Master节点,是大领导。管理数据块映射;处理客户端的读写请求;配置副本策略;管理HDFS的名称空间(文件目录结构,权限等);HDFS启动时接收DataNode上报的block存储信息(每块位置,分块情况等)。
SecondaryNameNode: 是一个小弟,分担大哥NameNode的工作量;是NameNode的冷备份;合并fsimage和fsedits然后再发给namenode。
DataNode: Slave节点,奴隶,干活的。负责存储client发来的数据块block;执行数据块的读写操作。
热备份: b是a的热备份,如果a坏掉。那么b马上代替a的工作。
冷备份: b是a的冷备份,如果a坏掉/那么b不能马上代替a工作。但是b上存储a的一些信息,减少a坏掉之后的损失。
fsimage: 存储metadata的磁盘文件。
edits: 元数据的操作日志(针对于文件系统做的修改操作记录)。
namenode内存中存储的是=fsimage + edits
SecondaryNameNode负责定时默认1小时,从namenode上,获取fsimage和edits来进行合并,然后再发送给namenode。减少namenode的工作量。
工作原理
写操作
NameNode负责管理存储在HDFS上所有文件的元数据,它会确认客户端的请求,并记录下文件的名字和存储这个文件的DataNode集合。它把该信息存储在内存中的文件分配表里。
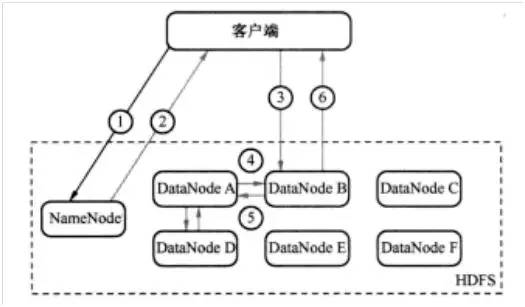
例如,客户端发送一个请求给NameNode,说它要将“zhou.log”文件写入到HDFS。那么,其执行流程如图1所示。具体为:
- 客户端发消息给NameNode,说要将“zhou.log”文件写入。(如图1中的1)
- NameNode发消息给客户端,交客户端写道DataNode A、B和D,并直接联系DataNode B。(如图1中的2)
- 客户端发消息给DataNode B,叫它保存一份“zhou.log”,并且发送一份副本给DataNode A和DataNode B。(如图1中的3)
- DataNode B 发消息给DataNode A ,叫它保存一份“zhou.log”文件,并且发送一份给副本给DataNode D。(如图1中的4)
- DataNode A 发消息给DataNode D,叫它保存一份“zhou.log”文件。(如图1中的5)
- DataNode D发确认消息给DataNode A。(如图1中的5)
- DataNode A发确认消息给DataNode B。(如图1中的4)
- DataNode B发确认消息给客户端,表示写入完成。(如图1中的6)
HDFS读过程
为了理解读的过程,可以认为一个文件是由存储在DataNode上的数据块组成的。客户端查看之前写入的内容的执行流程如图2所示,具体步骤为:
1. 客户端询问NameNode它应该从哪里读取文件。(如图2中的1)
2. NameNode发送数据块的信息给客户端。(数据块信息包含了保存着文件副本的DataNode的IP地址,以及DataNode在本地硬盘查找数据块所需要的数据块Id。)(如图2中的2)
3. 客户端检查数据块信息,联系相关的DataNode,请求数据块。(如图2中的3)
4. DataNode返回文件内容给客户端,然后关闭连接,完成读操作。(如图2中的3)
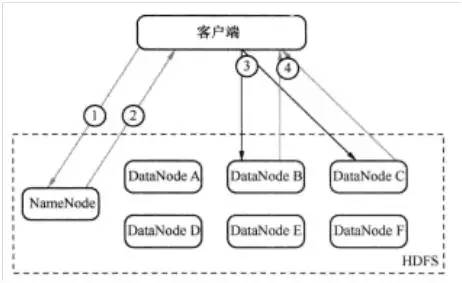
客户端并行从不同的DataNode中获取一个文件的数据块,然后联接这些数据块,拼成完整的文件。
通过副本快速恢复硬件故障
当一切运行正常时,DataNode会周期性发送心跳信息给NameNode(默认是每3秒钟一次)。如果NameNode在预定的时间内没有收到 心跳信息(默认是10分钟),它会认为DataNode出问题了,把它从集群中移除,并且启动一个进程去恢复数据。DataNode可能因为多种原因脱离 集群,如硬件故障、主板故障、电源老化和网络故障等。
对于HDFS来说,丢失一个DataNode意味着丢失了存储在它的硬盘上的数据块的副本。假如在任意时间总有超过一个副本存活,则故障就不会导致丢失数据。当一个硬盘故障时,HDFS会检测到存储在该硬盘的数据块的副本数量低于要求,然后主动创建需要的副本,以达到满副本数的状态。
跨多个DataNode切分文件
在HDFS里,文件被切分成数据块,通常每个数据块64MB~128MB,然后每个数据块被写到不同DataNode磁盘上。同一个文件中的不同数据块不一定保存在相同的DataNode上。这样做的好处是:当对这些文件执行运算时,能够通过并行方式读取和处理文件的不同部分。
当客户端准备写文件到HDFS时,会先向NameNode询问应该把文件写到哪里,NameNode会告诉客户端可以写入数据库的DataNode。
总结
- HDFS就是一个支持横向扩张的大硬盘,大的分布式文件管理系统。
- NameNode : 管家,管理HDFS文件。
- DataNode: 奴隶,存储和读取文件。
- SecondaryNameNode :NameNode的冷备份。
- 每个block默认3个副本,可调整。每个block 默认64M,可调整。
马士兵:HDFS就是“分冗展”的大印盘
- 分:分块
- 冗:冗余
- 展:支持动态扩展,只要向NameNode报告就行
