@boothsun
2018-03-26T11:54:23.000000Z
字数 14496
阅读 2590
Java AQS 学习
Java多线程
参考原文:
Java并发之AQS详解
《Java并发编程的艺术》
AQS 概述
AQS简介
AQS(AbstractQueuedSynchronizer)就是一个抽象的队列同步器,它是用来构建锁或者其他同步组件的基础框架,它维护了一个volatile int state来表示同步状态,通过内置的FIFO队列来完成线程等待排队。仅仅是定义了若干同步状态获取和释放,线程排队,等待与唤醒等底层操作的方法来供自定义同步组件使用或者重写。
AQS的设计是基于模板方法设计的,可供实现的模板方法基本上可以分为三类:独占式获取与释放同步状态、共享式获取与释放同步状态和查询同步队列中的等待线程情况。
子类通常被推荐定义为自定义同步组件的静态内部类,子类通过继承AQS并实现它的抽象模板方法来管理同步状态,而这些模板方法内部就是真正管理同步状态的地方(主要有tryAcquire、tryRelease、tryAcquireShared、tryReleaseShared等)。
AQS既可以支持独占式地获取同步状态,也支持共享式地获取同步状态,这样就可以方便实现不同类型的同步组件(ReentrantLock、ReentrantReadWriteLock和CountDownLatch等)。
AQS常见的接口
AQS中state状态的变更也是基于CAS实现的,主要有三种方法:
- getState()
- setState()
- compareAndSetState()
AQS定义两种资源共享方式:Exclusive(独占,同一时刻只有一个线程能执行,如ReentrantLock)和Share(共享式,多个线程可同时进行访问,如Semaphore/CountDownLatch)。
不同的自定义同步器争用共享资源的方式也不同。自定义同步器在实现时需要实现共享资源state的获取和释放方式即可,至于具体实现等待队列的维护(如获取资源失败入队\唤醒队列等),AQS在底层已经实现好了。自定义同步器实现时主要需要实现以下几种方法:
- isHeldExclusively():该线程是否正在独占资源。只有用到condition才需要去实现它。
- tryAcquire(int):独占方式。尝试获取资源,成功则返回true,失败则返回false。
- tryRelease(int):独占方式。尝试释放资源,成功则返回true,失败则返回false。
- tryAcquireShared(int):共享方式。尝试获取资源。负数表示失败;0表示成功,但没有剩余可用资源;正数表示成功,且有剩余资源。
- tryReleaseShared(int):共享方式。尝试释放资源,成功则返回true,失败则返回false。
以ReentrantLock为例,state初始化为0,表示未锁定状态。A线程lock()时,会调用tryAcqure()独占该锁并将state+1。以后,其他线程再tryAcquire()时就会失败,直到A线程unlock()到state=0(即释放锁)为止,其他线程才有机会获取该锁。当然,释放锁之前,A线程自己是可以重复获取此锁的(state累加),这就是可重入的概念。但要注意,获取多少次就要释放多少次,这样才能保证state是能回到0态的。
再以CountDownLatch为例,任务分为N个线程进行执行,state也初始化为N(注意N要与线程个数一致)。这N个子线程是并行执行的,每个子线程执行完后countDown()一次,state会CAS减1。等到所有子线程都执行完后(即state=0),会unpark()住调用线程主调用线程,然后主调用线程就会从await()函数中返回,继续后余动作。
一般来说,自定义同步器要么是独占式,要么是共享式,他们也只需要实现tryAcquire-tryRelease、tryAcquireShared-tryReleaseShared中的一种即可。但AQS也支持自定义同步器同时实现独占和共享两种方式,如:ReentrantReadWriteLock。
AQS源码详解
源码分析维度:同步队列、独占式同步状态获取与释放、共享式同步状态获取与释放以及超时获取同步状态等同步器的核心数据结构与模板方法。
同步队列介绍
同步器依赖内部的同步队列(一个FIFO双向队列)来完成同步状态的管理,当前线程获取同步状态失败时,同步器会将当前线程以及等待状态等信息构建成为一个节点(Node)并将其加入同步队列,同时会阻塞当前线程,当同步状态释放时,会把首节点中的线程唤醒,使其再次尝试获取同步状态。
同步队列中的节点(Node)是用来保存获取同步状态失败的线程引用、等待状态以及前驱和后继节点,节点的属性类型与名称以及描述见下图:

同步队列的基本结构如下图所示:
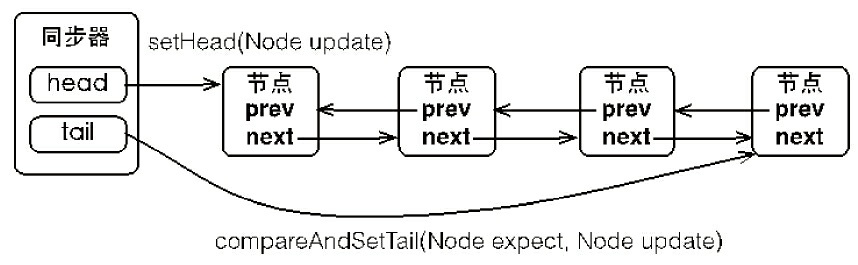
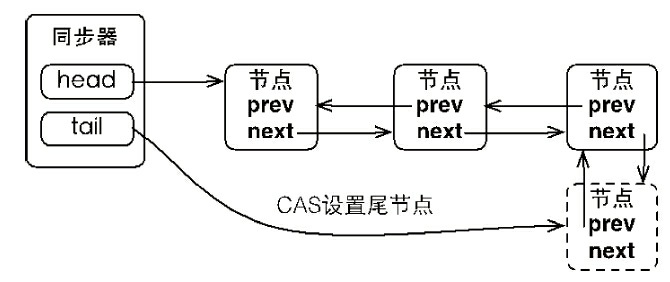
同步器包含了两个节点类型的引用,一个指向头节点,而另一个指向尾节点。当一个线程成功地获取了同步状态(或者锁),其他线程将无法获取到同步状态,转而被构造成为节点并加入到同步队列中,而这个加入队列的过程必须要保证线程安全,因此同步器提供了一个基于CAS的设置尾节点的方法:compareAndSetTail(Node expect , Node update),它需要传递当前线程“认为”的尾节点和当前节点,只有设置成功后,当前节点才正式与之前的尾节点建立关联。
同步器将节点加入到同步队列的过程如图5-2所示:
同步队列遵循FIFO,首节点是获取同步状态成功的节点,首节点的线程在释放同步状态时,将会唤醒后继节点,而后续节点将会在获取同步状态成功时将自己设置为首节点,该过程如下图:
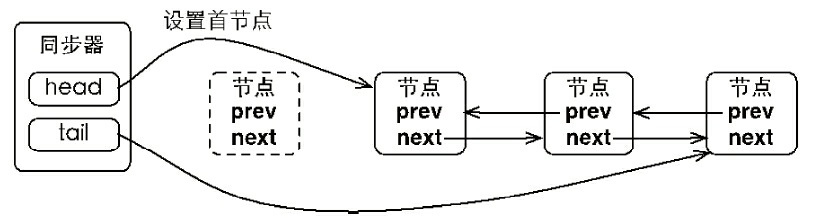
设置首节点是通过获取同步状态成功的线程来完成的,由于只有一个线程能够成功获取到同步状态,因此设置头节点的方法并不需要使用CAS来保证,它只需要将首节点设置成为原首节点的后继节点并断开原首节点的next引用即可。
同步队列维护 源码阅读
队列初始化&入队列:
private Node addWaiter(Node mode) {Node node = new Node(Thread.currentThread(), mode);// 先直接快速尝试将Node放到队尾。Node pred = tail;if (pred != null) {node.prev = pred;if (compareAndSetTail(pred, node)) {pred.next = node;return node;}}// 因队列尚未初始化或者CAS将当前Node设置为尾节点操作失败// 则进入初始化或者自旋阶段enq(node);return node;}private Node enq(final Node node) {for (;;) {Node t = tail;if (t == null) { //初始化阶段if (compareAndSetHead(new Node()))tail = head;} else {node.prev = t;if (compareAndSetTail(t, node)) {t.next = node;return t;}}}}private final boolean compareAndSetHead(Node update) {return unsafe.compareAndSwapObject(this, headOffset, null, update);}private final boolean compareAndSetTail(Node expect, Node update) {return unsafe.compareAndSwapObject(this, tailOffset, expect, update);}
首先,我们从addWaiter方法开始看起,此方法是通过自旋的形式来实现无锁情况下并发处理问题。假设初始化时,有多个线程进入此方法,此时head和tail都尚未初始化,都为null,则第一个线程一定会进入到enq(node)方法里。在进入到enq(node)方法后,如果此时head和tail节点依旧尚未初始化,则会进入初始化head结点和tail节点的阶段,即t == null的if块里。此代码段是通过CAS的形式将head的值赋予new Node()返回的引用地址,再执行tail=head ,则此时同步队列的情况如下图:
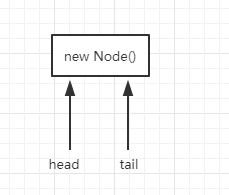
第一个线程进入到enq(final Node node)方法的线程执行完初始化操作后,后续的线程或者第一个线程的后续循环操作都会进入到enq方法的 else 代码段里。
1. 执行完Node t = tail; node.prev = t FIFO队列的情况如下图
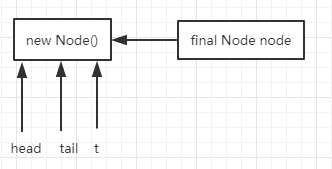
2. 执行完compareAndSetTail(t, node)后 FIFO队列的情况如下图:
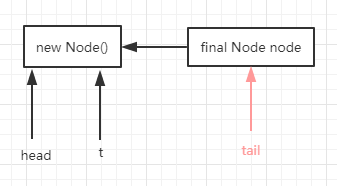
3. 执行完t.next = node;后 FIFO队列的情况如下图:
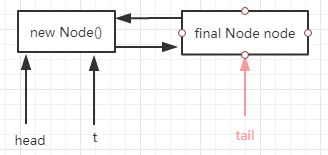
4. 如果是还有另一个线程进入到enq(final Node node)方法中时 FIFO队列的情况如下图:
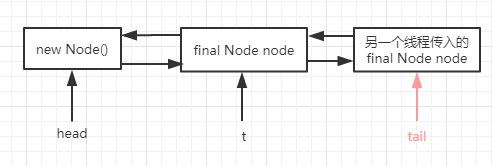
出队列过程:
这部分只讲同步队列中节点的出队列过程,而不讲同步状态的释放过程。
// 非共享 非中断模式下 在同步队列中争抢同步状态逻辑final boolean acquireQueued(final Node node, int arg) {//.......for (;;) {final Node p = node.predecessor();if (p == head && tryAcquire(arg)) {setHead(node);p.next = null; // help GCfailed = false;return interrupted;}// ......}// ......}// 可中断模式下 在同步队列中争抢同步状态逻辑private void doAcquireInterruptibly(int arg)throws InterruptedException {//......for (;;) {final Node p = node.predecessor();if (p == head && tryAcquire(arg)) {setHead(node);p.next = null; // help GCfailed = false;return;}//......}//......}//共享模式下,在同步队列中争抢同步状态逻辑private void doAcquireShared(int arg) {//.......for (;;) {final Node p = node.predecessor();if (p == head) {int r = tryAcquireShared(arg);if (r >= 0) {setHeadAndPropagate(node, r);p.next = null; // help GCif (interrupted)selfInterrupt();failed = false;return;}}//.......}//....}private void setHeadAndPropagate(Node node, int propagate) {Node h = head; // Record old head for check belowsetHead(node);// .....}private void setHead(Node node) {head = node;node.thread = null;node.prev = null;}
上面的方法都是在同步队列中争抢同步状态的逻辑,当某个节点在自旋过程中发现其前驱节点为head节点,则会尝试去获得同步状态,如果获取成功,则会走到setHead(node);方法,这个方法将当前节点置为头节点,然后执行node.prev = null;将当前节点的前驱指针置为null,断开和原头结点的连接。后面继续执行类似于p.next = null; // help GC代码片段,将原头结点的next指针置为NULL,断开原头结点和后继节点的连接,这整个过程就完成了节点出队列的全部过程。
独占式同步状态获取
通过调用同步器的acquire(int arg)方法可以在独占模式下同步状态,该方法对中断不敏感,也就是由于线程获取同步状态失败后进入同步队列中,后续对线程进行中断操作时,线程不会从同步队列中移出。并且没有超时设置,该方法调用后线程将一直自旋或者睡眠直到获取锁成功。
public final void acquire(int arg) {if (!tryAcquire(arg) &&acquireQueued(addWaiter(Node.EXCLUSIVE), arg))selfInterrupt();}
上述代码主要完成了同步状态获取、节点构造、加入同步队列以及在同步队列中自旋等待的相关工作,其主要逻辑是:
- 首先调用自定义同步器实现的
tryAcquire(int arg)方法,该方法保证线程安全的获取同步状态,如果获取成功,则该方法直接返回。 - 如果获取失败,则通过
addoWaiter(Node node)方法将当前线程包装成一个独占式的节点(Node.EXCLUSIVE:同一时刻只能有一个线程成功获取同步状态),并把该节点加入到同步队列的尾部。 - 调用
acquireQueued()方法使得addoWaiter(Node node)返回的节点以“死循环”的方式获取同步状态。 acquireQueued()方法返回在获取同步状态过程中,当前线程是否被中断,如果被中断,则在获取同步状态成功后,再进行自我中断selfInterrupt(),将这个中断补上。
上面简述了整个获取独占式同步状态的过程,下面我们对涉及到的方法进行详细的研究。
1. addWaiter():
这个方法我们在上面关于同步队列的队列初始化&入队列篇已经详细说明过了,这里我们不再重复,主要说一下该方法的作用:将当前线程构造成一个独占式的同步节点,然后将该节点加入到同步队列的尾部。
2. acquireQueued():
通过上面的addWaiter()已经将处理获取同步状态失败的节点加入到等待队列的尾部,后面的操作就是:自旋的过程,每个节点(或者说每个线程)都在自旋并观察,当自己的前驱节点是头结点时(白话就是排队排到自己时),则再次尝试去获取同步状态,如果获取成功,则进入头节点出队列流程并返回。如果获取失败则进入睡眠或者再次自旋。
如果当前节点的前驱节点不是头节点,则当前线程会进入到shouldParkAfterFailedAcquire方法和parkAndCheckInterrupt方法。
final boolean acquireQueued(final Node node, int arg) {boolean failed = true;try {boolean interrupted = false;for (;;) {final Node p = node.predecessor();if (p == head && tryAcquire(arg)) {// 如果当前节点的前驱节点是头节点,则尝试获取同步状态。// 获取成功,则将当前节点置为头结点,并把原头结点出队列,以便GC回收setHead(node);p.next = null; // help GCfailed = false;return interrupted;}if (shouldParkAfterFailedAcquire(p, node) &&parkAndCheckInterrupt())interrupted = true;}} finally {if (failed)cancelAcquire(node);}}
3. shouldParkAfterFailedAcquire和parkAndCheckInterrupt方法
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {int ws = pred.waitStatus; // 拿到前驱的状态if (ws == Node.SIGNAL)//如果已经告诉前驱释放同步状态时告诉自己,则进入睡眠return true;if (ws > 0) {//如果前驱已经放弃,那就一直往前找,直到找到最近一个正常处于等待状态的线程并排在它的后边。do {node.prev = pred = pred.prev;} while (pred.waitStatus > 0);pred.next = node;} else {// 如果前驱正常,那就把前驱的状态CAS设置为SIGNAL,告诉他释放同步状态时通知一下自己。// 这里是有可能失败的,因为可能在if (ws > 0) 判断后,当前线程的状态正好改变了,比如释放锁或者直接取消了。compareAndSetWaitStatus(pred, ws, Node.SIGNAL);}return false; // 返回false,则当前节点不会进入睡眠}private final boolean parkAndCheckInterrupt() {LockSupport.park(this);// 当前线程进入阻塞状态return Thread.interrupted();//当前线程被唤醒时,返回是否已被中断标志}
shouldParkAfterFailedAcquire的流程中,只有当已经告诉前驱节点在释放同步状态时告诉自己一声,当前线程才会进入睡眠,也就是parkAndCheckInterrupt方法。否则继续自旋。
线程被唤醒时,则将继续进入之前说的自旋或者睡眠流程。
小结:
- 进入到同步队列的节点,只有前驱节点是头节点的节点才能进行尝试获取锁。
- 同步队列中的所有节点,并不是在不停的自旋,如果已经告知前驱节点,再释放同步状态时通知自己,则该节点就将进入wait状态。
- 被阻塞节点的唤醒是依靠前驱节点的出队列操作或被阻塞节点被中断来实现的。
- 阻塞节点被状态后,并不抛出异常,而是记录中断状态,然后继续尝试获取锁,自旋或者阻塞。
整个流程图如下:
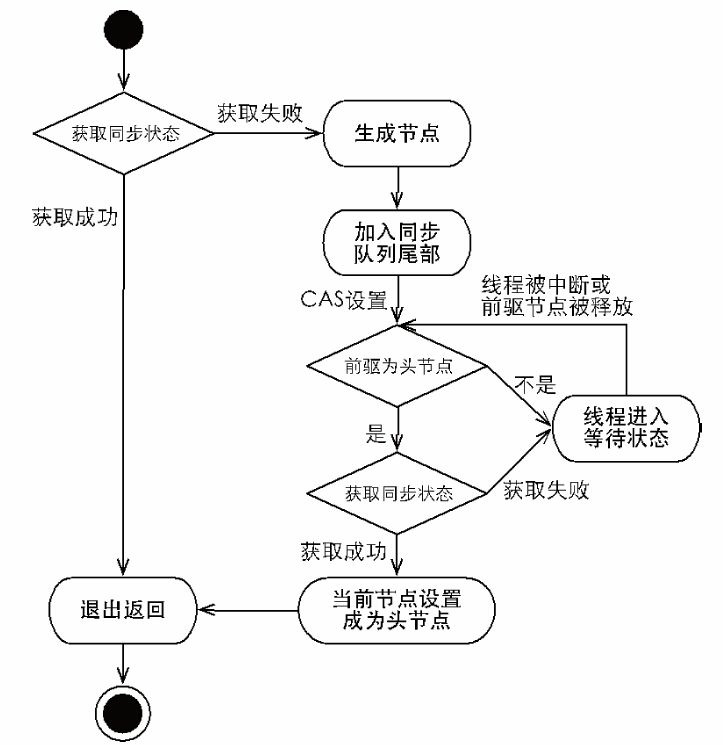
独占式同步状态释放
release()方法是独占模式下线程释放同步状态的顶层入口。它会释放指定量的资源,如果彻底释放了(即state=0,这是为了支持可重入),则会再唤醒等待队列里的其他线程来获取资源。
public final boolean release(int arg) {if (tryRelease(arg)) { //调用具体同步类尝试释放同步状态Node h = head;if (h != null && h.waitStatus != 0)unparkSuccessor(h);return true;}return false;}// 唤醒当前节点(Node node)的后继节点private void unparkSuccessor(Node node) {int ws = node.waitStatus;if (ws < 0)/*** 1. 当前*/compareAndSetWaitStatus(node, ws, 0);/*** 1. 此块逻辑的目的:找到第一个还处于有效等待状态的节点,然后将它唤醒。* 2. 先取头结点的下一个节点,如果该节点为null或者已经取消,则从尾节点开始向前遍历找到需要唤醒的节点。*/Node s = node.next;if (s == null || s.waitStatus > 0) {s = null;for (Node t = tail; t != null && t != node; t = t.prev)if (t.waitStatus <= 0)s = t;}if (s != null)LockSupport.unpark(s.thread); // 借助于LockSupport唤醒后继节点}
unparkSuccessor的作用是唤醒后继节点,这是当获取同步状态的线程退出临界区后,与后继未放弃线程通信,告诉他们可以争抢同步状态的方式。
LockSupport.unpark(s.thread)操作是parkAndCheckInterrupt中LockSupport.park(this);相反的操作。此时,再和acquireQueued()联系起来,s被唤醒后,进入if (p == head &&tryAcquire(arg))的判断(此时依旧有可能p!=head,这是因为原获取同步状态的节点的后继节点可能已经放弃,但是没有出队列,这时会再进入shouldParkAfterFailedAcquire()调整,调整完S也必然会跑到head的next结点,下一次自旋p==head就成立啦),然后S线程把自己设置成head结点,表示自己已经获取到资源了,同时原头结点已经完成工作,退出同步状态。
看到这里大家可能有疑问:为什么是从尾到头,而不是从头到尾遍历?
此问题,我们可以先看节点入队列中部分代码片段,这里我们以enq方法为例讲(addWaiter方法也存在同样问题),enq里有如下代码片段:
node.prev = t;if (compareAndSetTail(t, node)) {t.next = node;return t;}
这里是首先通过CAS的形式将tail指向尾节点,因为是通过CAS+自旋的形式设置的,所以不会出现并发问题,但是有可能在一个同步节点执行完if (compareAndSetTail(t, node)) {代码段还没执行t.next = node;时,头节点释放同步状态开始从头到尾遍历同步队列,但此时新建节点node还没有和前驱关联上(t.next = node;还没执行),这时的从头到尾遍历,可能到了t节点就中断了。因为已经安全地保证了尾节点设置不会有问题,而且是先关联后继节点再关联前驱节点,所以从后往前遍历一定不会有问题。
具体参见知乎解释:Java AQS unparkSuccessor 方法中for循环从tail开始而不是head的疑问?
共享式同步状态获取
共享式同步状态获取是指在同一时刻允许多个线程获取同步状态进入临界区,比如ReentrantReadWriteLock 读写锁中的ReadLock,CountDownLatch等
1. acquireShared:
此方法是共享模式下线程获取共享资源的底层入口。它会获取指定量的资源,获取成功则直接返回,获取失败,则同样也需要进入等待队列,直到获取到资源为止,整个过程也忽略中断。
public final void acquireShared(int arg) {if (tryAcquireShared(arg) < 0) // tryAcquireShared(arg)由子类实现具体的同步状态获取与释放doAcquireShared(arg);}
这里tryAcquireShared()依然需要自定义同步器去实现。但是AQS已经把其返回值的语义定义好了:负值代表获取失败;0代表获取成功,但已没有剩余资源;正数表示获取成功,还有剩余资源,其他线程还可以去获取。所以,是否获取同步状态的结果,就可以根据返回值是否大于等于0来判断。
2. doAcquireShared和setHeadAndPropagate
private void doAcquireShared(int arg) {final Node node = addWaiter(Node.SHARED);boolean failed = true;try {boolean interrupted = false;for (;;) {final Node p = node.predecessor();if (p == head) {int r = tryAcquireShared(arg);if (r >= 0) {setHeadAndPropagate(node, r);p.next = null; // help GCif (interrupted)selfInterrupt();failed = false;return;}}if (shouldParkAfterFailedAcquire(p, node) &&parkAndCheckInterrupt())interrupted = true;}} finally {if (failed)cancelAcquire(node);}}private void setHeadAndPropagate(Node node, int propagate) {Node h = head; // Record old head for check belowsetHead(node);if (propagate > 0 || h == null || h.waitStatus < 0 ||(h = head) == null || h.waitStatus < 0) {Node s = node.next;if (s == null || s.isShared())doReleaseShared();}}
共享式同步状态获取与独占式同步状态获取大致类似,都是判断自己的前驱节点是否是头节点,如果是头节点则尝试获取锁,如果获取锁失败或者自己前驱节点不是头节点,则尝试告诉前驱释放同步状态时唤醒自己,通知完后进入阻塞状态。
不同的是,在成功获取同步状态后,共享式同步状态获取操作会判断当前剩余的共享同步状态是否大于0,也就是同步状态是否还没用完,如果同步状态还没有用完且后继节点是SHARED模式,那么将继续通过doReleaseShared方法尝试唤醒后继节点,实现同步状态的向后传播。后继节点被唤醒后,则会再次尝试获取同步状态,如果再次获取失败,还是再会通知前驱节点,然后睡眠。
假如老大用完后释放了5个资源,而老二需要6个,老三需要1个,老四需要2个。老大先唤醒老二,老二一看资源不够,他是把资源让给老三呢,还是不让?答案是否定的!老二会继续park()等待其他线程释放资源,也更不会去唤醒老三和老四了。独占模式,同一时刻只有一个线程去执行,这样做未尝不可;但共享模式下,多个线程是可以同时执行的,现在因为老二的资源需求量大,而把后面量小的老三和老四也都卡住了。当然,这并不是问题,只是AQS保证严格按照入队顺序唤醒罢了(保证公平,但降低了并发)。
共享式同步状态释放
//1. 共享式public final boolean releaseShared(int arg) {if (tryReleaseShared(arg)) { //调用子类的实现,让子类决定是否释放指定量同步状态doReleaseShared();return true;}return false;}private void doReleaseShared() {for (;;) {Node h = head;if (h != null && h != tail) { // 如果自己是尾节点,就没有必要执行唤醒后继节点的工作int ws = h.waitStatus;if (ws == Node.SIGNAL) { // 如果当前头节点状态为SIGNAL(暗示后续节点需要唤醒)if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0))continue; // loop to recheck casesunparkSuccessor(h); // 唤醒头结点后第一个需要唤醒的节点}else if (ws == 0 &&!compareAndSetWaitStatus(h, 0, Node.PROPAGATE))continue; // loop on failed CAS}if (h == head) // loop if head changedbreak;}}
共享式同步状态释放与独占式同步状态释放类似,都是:释放掉占用的资源后,唤醒后继节点。但不同的是:
1. 独占模式下的tryRelease()在完全释放掉资源(state=0)后,才会返回true去唤醒其他线程,这主要是基于独占下可重入的考量;而共享模式下的releaseShared()则没有这种要求,共享模式实质就是控制一定量的线程并发执行,那么拥有资源的线程在释放掉部分资源时就可以唤醒后继等待结点。例如,资源总量是13,A(5)和B(7)分别获取到资源并发运行,C(4)来时只剩1个资源就需要等待。A在运行过程中释放掉2个资源量,然后tryReleaseShared(2)返回true唤醒C,C一看只有3个仍不够继续等待;随后B又释放2个,tryReleaseShared(2)返回true唤醒C,C一看有5个够自己用了,然后C就可以跟A和B一起运行。
2. 在于tryReleaseShared(int arg)方法必须确保同步状态(或者资源数)线程安全释放,一般是通过循环和CAS来保证的,因为释放同步状态的操作会同时来自多个线程。
前文,已经对AQS获取共享式同步状态和独占式获取同步状态全部过程进行了细致讲解,下面的流程主要是讲一下AQS 如何响应中断和如果超时获取同步状态两种,传统synchronized不支持的特性。
响应中断获取同步状态实现原理
acquireInterruptibly(int arg)和acquireSharedInterruptibly是AQS提供的两种响应中断式获取同步状态方法。这里我们以acquireInterruptibly(int arg)为例讲解它是如何响应中断的。
public final void acquireInterruptibly(int arg)throws InterruptedException {// 感知到中断,立刻抛出中断异常。if (Thread.interrupted())throw new InterruptedException();if (!tryAcquire(arg))doAcquireInterruptibly(arg);}private void doAcquireInterruptibly(int arg)throws InterruptedException {final Node node = addWaiter(Node.EXCLUSIVE);boolean failed = true;try {for (;;) {final Node p = node.predecessor();if (p == head && tryAcquire(arg)) {setHead(node);p.next = null; // help GCfailed = false;return;}if (shouldParkAfterFailedAcquire(p, node) &&parkAndCheckInterrupt())// 如果线程在睡眠过程中被中断,立刻抛出中断异常throw new InterruptedException();}} finally {if (failed)cancelAcquire(node);}}
在前面的分析中,我们知道,非响应中断式获取同步状态,都是在第一个获取同步状态失败后,进入同步队列中等待直到成功获取同步状态后,才对中断进行响应,那怕自己在LockSupport.park(this);时被打断,也只是记录下中断状态,然后继续尝试获取锁,失败后可能还会再次进入睡眠。整个同步状态获取的过程中,没有对中断进行任何响应,比如抛出异常。即使,在成功获取同步状态后,也只是进行selfInterrupt();操作,操作的结果也是指设置当前线程的中断状态为true,并没有抛出任何异常或者其他中断式响应。
而对于响应中断式获取同步状态,则在第一次尝试获取同步状态前就对中断状态进行检查,如果当前线程已经被中断,立刻抛出中断异常。在进入同步队列中等待获取同步状态时,如果LockSupport.park(this);时被打断,也直接抛出异常,然后通过cancelAcquire(node);取消排队等待。
总而言之,非响应中断获取同步状态就是感知到中断,也不响应,而是等待成功获得同步状态后,再进行自我中断。 响应式中断,则是感知到中断,即可抛出中断异常,退出同步状态等待操作。
超时获取同步状态实现原理
通过调用同步器的doAcquireNanos(int arg , long nanosTimeout)和tryAcquireSharedNanos(int arg, long nanosTimeout)两个方法可以超时获取同步状态,即在指定的时间段内获取同步状态,如果获取到同步状态在返回true,否则,返回false。该方法提供了传统Java同步操作(比如synchronized关键字)所不具备的特性。
超时获取同步状态过程可以被视为响应中断获取同步方法过程的“增强版”,doAcquireNanos(int arg,long nanosTimeout)方法在支持响应中断的基础上,增加了超时获取的特性。针对超时获取,主要需要计算出需要睡眠的时间间隔nanosTimeout,为了防止过早通知,nanosTimeout计算公式为:nanosTimeout-=now-lastTime,其中now为当前唤醒时间,lastTime为上次唤醒时间,如果nanosTimeout大于0则表示超时时间未到,需要继续睡眠nanosTimeout纳秒,反之,表示已经超时。这里,我们以doAcquireNanos(int arg , long nanosTimeout)为例,讲解AQS是是如何实现获取超时的。
private boolean doAcquireNanos(int arg, long nanosTimeout)throws InterruptedException {if (nanosTimeout <= 0L)return false;// 计算过期时间,当前时间 + 最大等待时长 = 过期时间final long deadline = System.nanoTime() + nanosTimeout;final Node node = addWaiter(Node.EXCLUSIVE);boolean failed = true;try {for (;;) {final Node p = node.predecessor();if (p == head && tryAcquire(arg)) {setHead(node);p.next = null; // help GCfailed = false;return true;}nanosTimeout = deadline - System.nanoTime();// 计算剩余时间if (nanosTimeout <= 0L) //超时,返回获取锁失败return false;if (shouldParkAfterFailedAcquire(p, node) &&nanosTimeout > spinForTimeoutThreshold)LockSupport.parkNanos(this, nanosTimeout); //获取锁失败,通知前驱节点后,睡眠if (Thread.interrupted())throw new InterruptedException();}} finally {if (failed)cancelAcquire(node);}}
该方法在自旋过程中,当节点的前驱节点为头节点时尝试获取同步状态,如果获取成功则从该方法返回,这个过程和独占式同步获取的过程类似,但是在同步状态获取失败的处理上有所不同。如果当前线程获取同步状态失败,则判断是否超时(nanosTimeout小于等于0表示已经超时),如果没有超时,重新计算超时间隔nanosTimeout,然后使当前线程等待nanosTimeout纳秒(当已到设置的超时时间,该线程会从LockSupport.parkNanos(Object
blocker,long nanos)方法返回,这是LockSupport控制的)。
如果nanosTimeout小于等于spinForTimeoutThreshold(1000纳秒)时,将不会使该线程进行超时等待,而是进入快速的自旋过程。原因在于,非常短的超时等待无法做到十分精确,如果这时再进行超时等待,相反会让nanosTimeout的超时从整体上表现得反而不精确。因此,在超时非常短的场景下,同步器会进入无条件的快速自旋。
