@boothsun
2018-04-26T12:51:39.000000Z
字数 1753
阅读 5301
分库分表面试准备
面试题
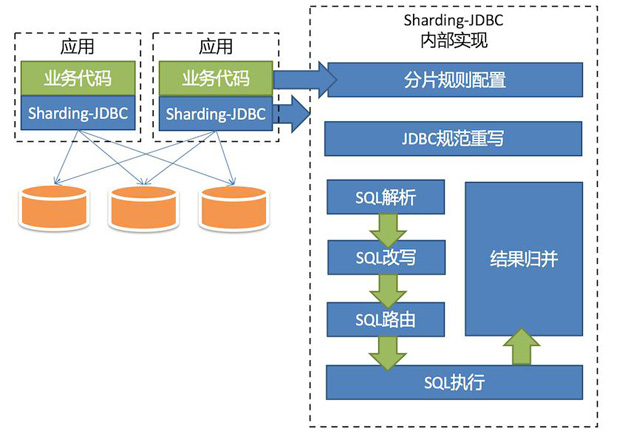
Sharding-JDBC 原理
常见的切分方案:
垂直拆分
垂直拆分包括垂直库拆分和垂直表拆分。垂直库拆分,是指按照业务拆分将原先单个库里的表进行分类,分布到不同的数据库上面,这样可以降低单个库的复杂度,减轻单个库的压力和数据量。垂直表拆分,是指将原先单表字段进行分类,不同的业务含义字段划分到不同的数据库里去。(按照数据列的拆分)
垂直拆分通常都是伴随着服务化改造,按照功能模块将原来强耦合的系统拆分为多个弱耦合的服务。
垂直拆分的优点:
- 库表职责单一,复杂度降低,易于维护。
- 单库或单表压力降低。 相互之间的影响也会降低。
垂直拆分的缺点:
- 部分表关联无法在数据库级别完成,需要在程序中完成。
- 单表大数据量仍然存在性能瓶颈。
- 单表或单库高热点访问依旧对DB压力非常大。
- 事务处理相对更为复杂。需要分布式事务的介入。
- 拆分达到一定程度之后,扩展性会遇到限制。
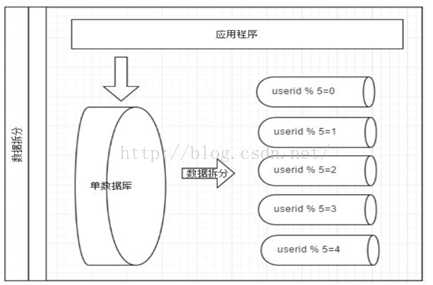
水平拆分
关键词:
- 分库分表。
- 按照行数据进行拆分。
- 单表数据按照某种规则划分到不同的库表中。
- 拆分规则:Hash取模、历史数据归档、范围切分比如年月等。
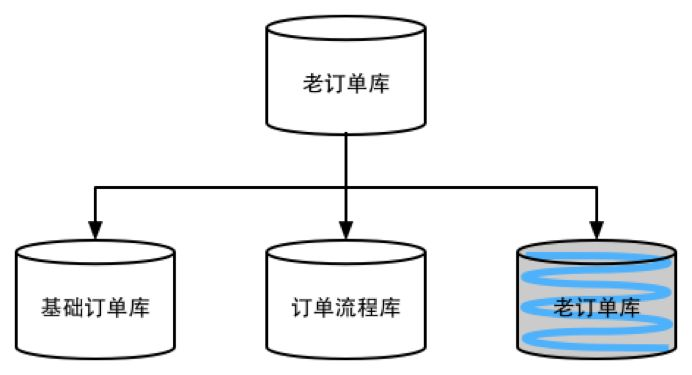
历史数据归档缺点:
- 查询入口改造,可以分成历史数据查询入口和最新数据查询入口。
- 简单。
范围切分:
比如按照时间区间或ID区间来切分。
优点:单表大小可控,天然水平扩展。
缺点:无法解决集中写入瓶颈的问题。
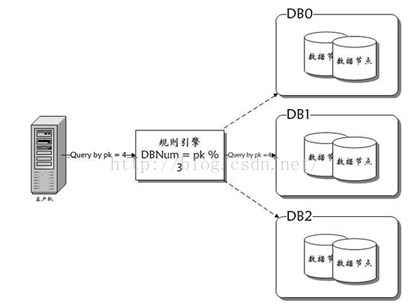
Hash切分:
一般采用取模的形式来划分,并且推荐采用 mod 这种一致性Hash。它是利用对2的倍数取余具有向前兼容的特性(如对4取余得1的数对2取余也是1)来分配数据,这样减少了水平扩展时数据迁移量。
水平拆分的优点:
- 解决单表单库大数据量和高热点访问性能遇到瓶颈的问题;
- 应用程序端整体架构改动相对较少。
- 事务处理相对简单。
- 只要切分规则能够定义好,基本上较难遇到扩展性限制。
水平拆分缺点:
- 拆分规则相对更复杂,很难抽象出一个能够满足整个数据库的切分规则。
- 后期数据的维护难度有所增加,人为手工定位数据更困难。
- 产品逻辑将变复杂。比如按年来进行历史数据归档拆分,这个时候在页面设计上就需要约束用户必须要先选择年,然后才能进行查询。
总而言之:
1. 数据表垂直拆分: 单表复杂度。
2. 数据库垂直拆分: 功能拆分。
3. 水平拆分:分表:解决单表大数据量问题。 分库:为了解决单库性能问题。
分库分表需要考虑的点:
- 容量规划:现有的数据量有多大,每天或者每月增长量是多少。现在需要分多少个库表,分完能够支撑多长时间。
- 分库分表策略确定:数据如何分布均匀,分多少库 分多少表。按范围分还是年月分还是HASH取模啥的。
- 扩容等问题。一旦现有容量到达极限,如果进行扩容?扩容过程中数据迁移量有多少?
- 如果进行历史数据迁移。
分库分表后带来的问题
- 事务问题:分布式事务 补偿 或者最终一致性 最大努力送达型
- 跨节点join的问题:
- 换条技术栈:使用ES后者其他NOSQL数据库。
- 分两次查询实现。在第一次查询的结果集中找出关联数据的id,然后根据这些id发起第二次请求得到关联数据。
- 跨表或跨库的count、order by、group by以及聚合函数问题。
这些是一类问题,因为它们都需要基于全部数据集合进行计算。解决方案:与解决跨节点join问题的类似,分别在各个节点上得到结果后在应用程序端进行合并。和join不同的是每个结点的查询可以并行执行,因此很多时候它的速度要比单一大表快很多。但如果结果集很大,对应用程序内存的消耗是一个问题。 - 非分表字段查询问题:再加一张中间表;换条技术栈。
跨分片的排序分页
一般来讲,分页时需要按照指定字段进行排序。当排序字段就是分片字段的时候,我们通过分片规则可以比较容易定位到指定的分片,而当排序字段非分片字段的时候,情况就会变得比较复杂了。为了最终结果的准确性,我们需要在不同的分片节点中将数据进行排序并返回,并将不同分片返回的结果集进行汇总和再次排序,最终再返回给用户。如下图所示: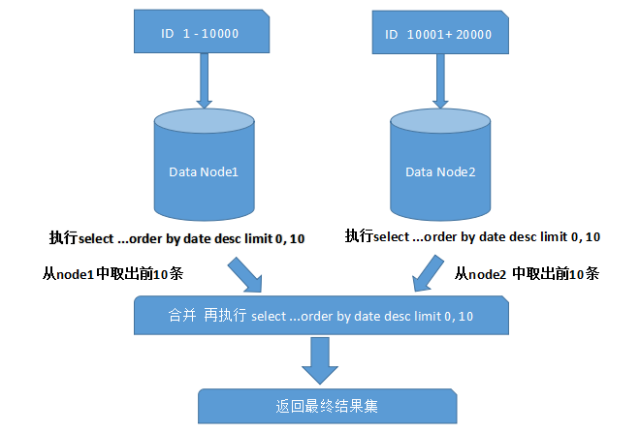
上面图中所描述的只是最简单的一种情况(取第一页数据),看起来对性能的影响并不大。但是,如果想取出第10页数据,情况又将变得复杂很多,如下图所示:
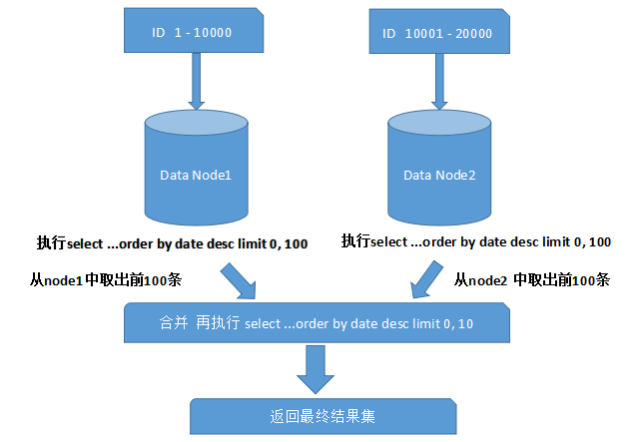
换条技术栈!
分库分表后数据迁移问题
- 双写 以老库为主。读操作还是读老库老表,写操作是双写到新老表。
- 历史数据迁移 dts + 新数据对账校验(job) + 历史数据校验。
- 切读:读写以新表为主,新表成功就成功了。
- 观察几天 下掉写老库操作。
