@boothsun
2017-10-26T04:54:05.000000Z
字数 952
阅读 2007
简述MapReduce计算框架原理
大数据
1. MapReduce基本编程模型和框架
1.1 MapReduce抽象模型
大数据计算的核心思想是:分而治之。如下图所示。把大量的数据划分开来,分配给各个子任务来完成。再将结果合并到一起输出。注:如果数据的耦合性很高,不能分离,那么这种并行计算就不合适了。
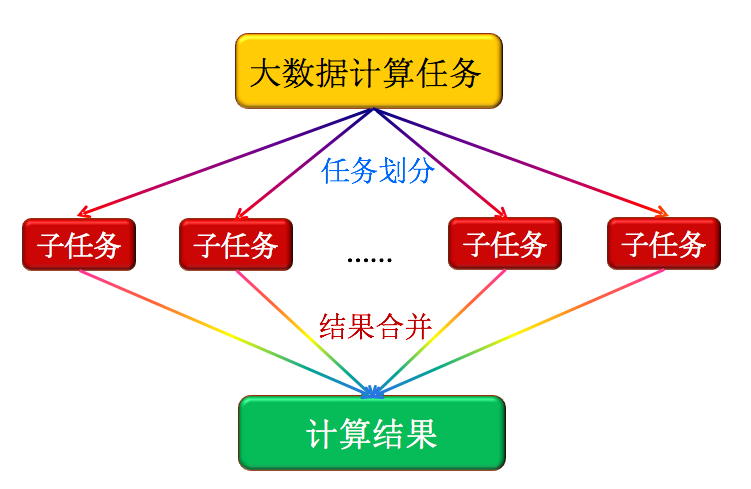
图1: MapReduce抽象模型
1.2 Hadoop的MapReduce的并行编程模型
如下图2所示,Hadoop的MapReduce先将数据划分为多个key/value键值对。然后输入Map框架来得到新的key/value对,这时候只是中间结果,这个时候的value值是个集合。再通过同步屏障(为了等待所有的Map处理完),这个阶段会把相同key的值收集整理(Aggregation&Shuffle)在一起,再交给Reduce框架做输出组合,如图2中每个Map输出的结果,有K1,K2,K3,通过同步屏障后,K2收集到一起,K2收集到一起,K3收集到一起,再分别交给Reduce,通过Reduce组合结果。
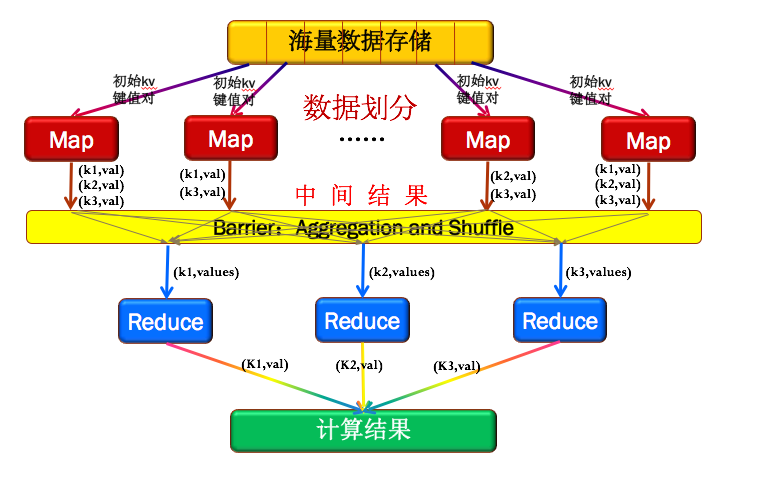
图2:Hadoop的MapReduce的框架
1.3 Hadoop的MapReduce的完整编程模和框架
图3是MapReduce的完整编程模型和框架,比模型上多加入了Combiner和Partitioner。
Combiner
Combiner可以理解为一个小的Reduce,就是把每个Map结果,先做一次整合。例如图3中第三列的Map结果中有2个good,通过Combiner之后,先将本地的2个goods组合到了一起(红色的(good,2))。好处是大大减少需要传输的中间结果数量,达到网络数据传输优化,这也是Combiner的主要作用。Partitioner
为了保证所有的主键相同的key值对能传输给同一个Reduce节点,如图3中所有的good传给第一个Reduce前,所有的is和has传给第二个Reduce前,所有的weather,the和today传到第三个Reduce前。MapReduce专门提供了一个Partitioner类来完成这个工作,主要目的就是消除数据传入的Reduce节点后带来不必要的相关性。
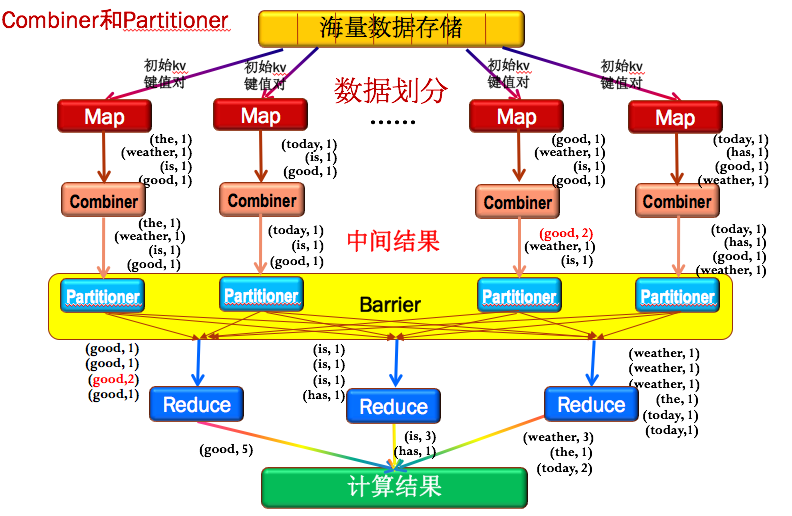
图3:Hadoop的MapReduce的完整编程模型和框架
