@boothsun
2018-05-22T11:26:12.000000Z
字数 10914
阅读 1767
Java Stream API
Java
参考优秀博文:
1. Java 8 中的 Streams API 详解
2. 尚硅谷JDK1.8 视频教程
3. 尚硅谷JDK1.8 视频教程对应PPT地址
方法引用 & 构造器引用
方法引用
方法引用如Lambda表达式一样也是一个语法糖,可以用来简化开发。
在我们使用Lambda表达式的时候,->右边部分是要执行的代码,即要完成的功能,我们可以把这部分称作Lambda体。有时,我们想要当做Lambda体的函数式接口已经有能满足我们需求的实现了,我们就可以用方法引用来直接复用这个具体实现。
但需要注意一个规则:
实现抽象方法的参数列表,必须与方法引用的方法参数列表保持一致!
方法引用:使用操作符::将方法名和对象或类的名字分隔开来。 主要有以下三种使用情况:
对象::实例方法
//Consumer<String> consumer = x -> System.out.println(x);Consumer<String> consumer = System.out::println;consumer.accept("This is Major Tom");
类::静态方法
//Function<Long, Long> f = x -> Math.abs(x);Function<Long, Long> f = Math::abs;Long result = f.apply(-3L);
Math是一个类而abs为该类的静态方法。Function中的唯一抽象方法apply方法参数列表与abs方法的参数列表相同,都是接收一个Long类型参数。类::实例方法
若Lambda表达式的参数列表中第一个参数,是实例方法的调用者,第二个参数(或无参)是实例方法的参数时,就可以使用这种方法,如:
//BiPredicate<String, String> b = (x,y) -> x.equals(y);BiPredicate<String, String> b = String::equals;b.test("abc", "abcd");
构造器引用
格式:ClassName::new
与函数式接口相结合,自动与函数式接口中方法兼容。可以把构造器引用赋值给定义的方法。在引用构造器的时候,构造器参数列表要与接口中抽象方法的参数列表一致。
Function<Integer,Integer> fun = integer -> new Integer("1");Function<Integer,Integer> fun2 = Integer::new;
数组引用
格式:type[]::new
// 1. 原始写法Function<Integer,Integer[]> fun = new Function<Integer, Integer[]>() {@Overridepublic Integer[] apply(Integer n) {return new Integer[n];}};// 2. 普通LambdaFunction<Integer,Integer[]> fun2 = n -> new Integer[n];// 3. 方法引用Function<Integer,Integer[]> fun3 = Integer[]::new ;
Stream API
什么是Stream
Stream不是集合元素,它也不是数据结构并不保存数据,它是有关集合元素计算和算法,它更像一个高级版本的Iterator。原始版本的Iterator,用户只能显示地一个一个遍历元素并对其执行某些操作;高级版本的Stream,用户只要给出需要对其包含的元素执行什么操作,比如“过滤掉长度大于10的字符串”、“获取每个字符串的首字母”等,Stream会隐式地在内部进行遍历,做出相应的数据转换。
Stream就如同一个迭代器(Iterator),单向,不可往复,数据只能遍历一次,遍历过一次后即用尽了,就好比流水从面前流过,一去不复返。
而和迭代器又不同的是,Stream可以并行化操作,迭代器只能命令式地、串行化操作。顾名思义,当使用串行方式去遍历时,每个item读完后再读下一个item。而使用并行去遍历时,数据会被分为多个段,其中每一个都在不同的线程中处理,然后将结果一起输出。Stream的并行操作依赖于1.7中引入的Fork/Join来拆分任务和加速处理过程。
并行流与串行流
并行流就是把一个内容分成多个数据块,并用不同的线程分别处理每个数据块的流。Java 8中将并行进行了优化,我们可以很容易的对数据进行并行操作。Stream API可以声明性地通过parallel()与sequential()在并行流与顺序流之间进行切换。
Java 8的Stream底层是通过Fork/Join框架实现的。Fork/Join框架的原理就是在必要的情况下,将一个大任务进行拆分(fork)成若干个小任务(拆到不可再拆时),再将一个个的小任务运算的结果进行join汇总。
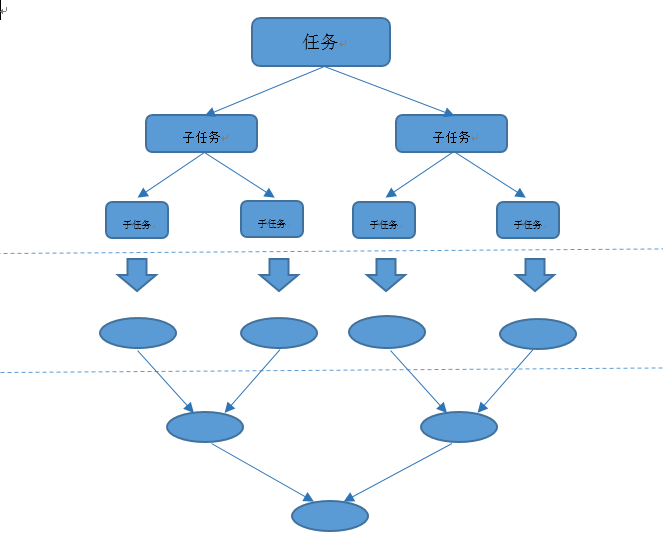
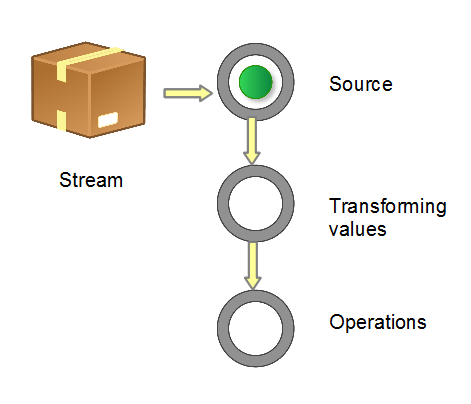
Stream的操作步骤
- 创建Stream:从一个数据源(如:集合、数组等),获取一个流。
- 中间转换操作:一个中间操作链,对数据源的数据进行处理。
- 终止操作(终端操作):终止操作会执行之前全部的中间操作链,并产生最终的结果。

一个Stream可以跟上n个中间操作和唯一一个终端操作,中间操作的主要目的就是构建流,并对流中数据进行某种程度上的数据映射和过滤,然后返回一个新的流,交给下一个中间操作使用。这个过程中,原有Stream对象都不会发生改变,每次中间操作都是返回一个新的Stream对象。这些中间操作都是惰性化的(lazy),也就是说仅仅调用到这类方法,并没有真正开始流的遍历过滤筛选。
一个流只能有唯一一个终端操作(Terminal),当这个操作开始执行后,流就被使用“光”了,无法再被操作。所以终端操作必定是流的最后一个操作。在终端操作开始执行前,才会真正开始流的遍历筛选过滤。
在对于一个Stream进行多次中间操作,那是不是每个中间操作都对Stream中的每个元素进行转换,这样时间复杂度是不是就是N(转换次数)个for循环里把所有操作都做掉的总和呢?其实不是这样的,转换操作都是lazy的,多个转换操作只会在中断操作的时候一起进行调用,一次循环完成全部中间操作调用。我们可以这么简单的理解,Stream里有个操作函数的集合,每次中间操作就是把中间操作函数放入到这个集合中,在终端操作的时候循环Stream对应的集合,然后对每个元素执行所有的函数。
Stream流的使用
构建Stream
从collection构建Stream:
Java8中的Collection接口被扩展,提供了两个获取流的方法:Collection.stream(); // 返回一个顺序流Collection.parallelStream(); //返回一个并行流
由数组创建流:
Java8中Arrays类中有静态方法stream()可以获取数组流:static <T> Stream<T> stream(T[] array); //返回一个流// 重载形式,能够处理对应基本类型的数组:public static IntStream stream(int[] array)public static LongStream stream(long[] array)public static DoubleStream stream(double[] array)
由普通值创建流
可以使用静态方法Stream.of(),从普通值创建一个流。它可以接收任意数量的参数。public static<T> Stream<T> of(T... values); // 返回一个流
使用函数创建无限流:
可以使用静态方法Stream.oterate()和Stream.generate()来创建无限流。// 1.迭代public static<T> Stream<T> iterate(final T seed, final UnaryOperator<T> f);// 2. 生成public static<T> Stream<T> generate(Supplier<T> s);
Stream的中间操作:
多个中间操作可以连接起来形成一个流水线,除非流水线上触发终端操作,否则中间操作不会执行任何的处理!而在终端操作时一次性全部处理,这种行为被称为“惰性请值”。
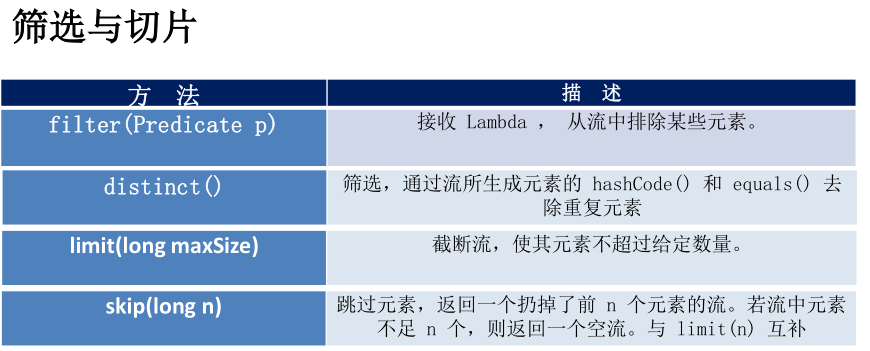
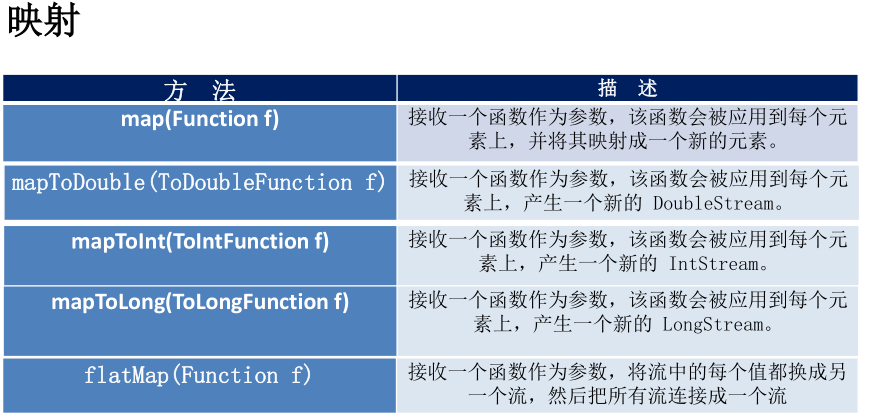

终端操作:
终端操作会从流的中间流水操作生成结果。其结果可以是任何不适流的值,例如:List、Integer,甚至是void。
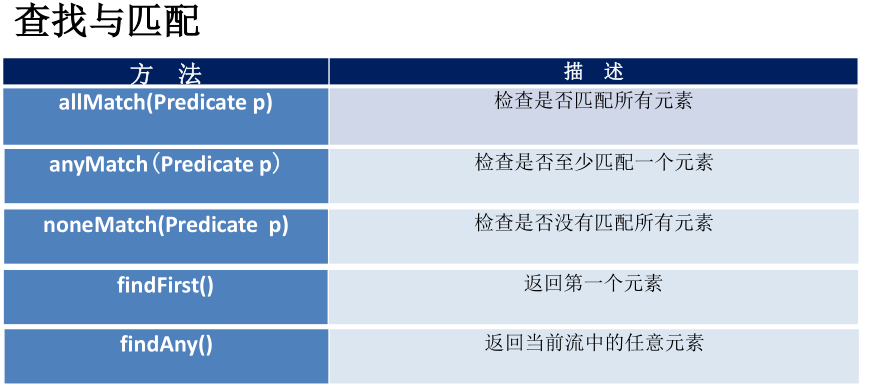



Collector接口中方法的实现决定了如何对流执行收集操作(如收到List、Set、Map)。但是Collectors工具类提供了很多静态方法,可以方便地创建常见收集器实例,具体方法与实例如下表:


Stream使用 实例讲解
简单说,对Stream的使用就是实现一个filter-map-reduce过程,产生一个最终结果,或者导致一个副作用(side effect)。
1. 构造Stream
// 来源:单值Stream<Integer> stream1 = Stream.of(1,2,3,4,45);stream1.forEach(System.out::println);// 来源:数组Integer[] arr2 = {1,2,3,4,45};Stream<Integer> stream2 = Stream.of(arr2);stream2.forEach(System.out::println);Stream<Integer> stream3 = Arrays.stream(arr2) ;stream3.forEach(System.out::println);// 来源:集合Stream<Integer> stream4 = Arrays.asList(1,2,3,4,45).stream();
需要注意的是,对于基本数值类型,目前有三种对应的包装类型Stream:
IntStream、LongStream、DoubleStream。当然我们也可以用Stream、Stream、Stream,但是boxing和unboxing会很耗时,所以特别为这三种基本数值类型提供了对应的Stream。
Java8中还没有提供其它数值型Stream,因为这将导致扩增的内容较多。而常规的数值型聚合运算可以通过三面三种Stream进行。
数值流的构造:
IntStream.of(new int[]{1, 2, 3}).forEach(System.out::println);IntStream.range(1, 3).forEach(System.out::println);IntStream.rangeClosed(1, 3).forEach(System.out::println);
2. Stream转换为其他数据结构:
// 1. ArrayString[] strArray1 = Stream.of("A", "B", "C", "D", "E", "F").toArray(String[]::new);// 2. CollectionList<Integer> list1 = Stream.of(1,2,3,4,5,6).collect(Collectors.toList());List<Integer> list2 = Stream.of(1,2,3,4,5,6).collect(Collectors.toCollection(ArrayList::new));Set set = Stream.of(1,2,3,4,5,6).collect(Collectors.toSet());Stack stack = Stream.of(1,2,3,4,5,6).collect(Collectors.toCollection(Stack::new));// 3. StringString str = Stream.of("A", "B", "C", "D", "E", "F").collect(Collectors.joining());
一个Stream只能有一个终端操作。
3. 流的中间操作:
map/flatMap
map函数的作用类似于MapReduce中的map操作,作用就是把input Stream中的每一个元素,映射成 output Stream中的另一个元素。这样的转换操作是1对1的对应转换映射,每个输入元素,都按照map中的定义规则转换为另一个元素。
// 全部转换为小写Stream.of("A", "B", "C", "D", "E", "F").map(String::toLowerCase).forEach(System.out::println);// 平方数Stream.of(1,2,3,4,5,6).map(n->n*n).forEach(System.out::println);
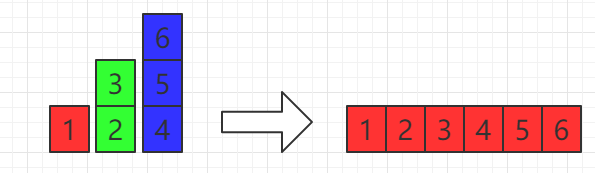
flatMap是把input Stream中的数据进行扁平化操作,我们先看个例子:
Stream<List<Integer>> inputStream = Stream.of(Arrays.asList(1),Arrays.asList(2, 3),Arrays.asList(4, 5, 6));List<Integer> n = inputStream.flatMap((childList) -> childList.stream()).collect(Collectors.toList());
filter
filter对原始Stream进行过滤筛选,通过筛选留下的元素会被生成一个新Stream。// 筛选留下偶数Integer[] sixNums = {1, 2, 3, 4, 5, 6};Integer[] evens =Stream.of(sixNums).filter(n -> n%2 == 0).toArray(Integer[]::new);
forEach
forEach 方法接收一个 Lambda 表达式,然后在 Stream 的每一个元素上执行该表达式。IntStream.of(new int[]{1, 2, 3}).forEach(System.out::println);
findFirst
这个函数总是返回Stream的第一个元素,或者空。 这里比较重点的是它的返回值类型:Optional。这也是一个模仿Scala语言中的概念,作为一个容器,它可能含有某值,或者不包含。使用它的目的是尽可能避免NullPointerException。public static void print(String text) {// Java 8Optional.ofNullable(text).ifPresent(System.out::println);// Pre-Java 8if (text != null) {System.out.println(text);}}public static int getLength(String text) {// Java 8return Optional.ofNullable(text).map(String::length).orElse(-1);// Pre-Java 8// return if (text != null) ? text.length() : -1;}
在更复杂的
if(xx != null)的情况下,使用Optional代码的可读性更好,而且它提供的是编译时检查,能极大的降低NullPointerException这种Runtime Exception对程序的影响,或者迫使程序猿更早的在编码阶段处理空值问题,而不是留到运行时再发现和调试。Stream中的
findAny、max/min、reduce等方法都返回Optional值。还有例如IntStream.average()返回OptionalDouble等等。reduce
reduce函数的作用是返回Stream中元素在运算规则(BinaryOperator)作用下的计算结果。当我们使用reduce函数时,需要传入BinaryOperator的具体实现类,然后重写apply(T t, U u)方法,该方法中第一个参数t为上次函数计算的返回值,如果是第一次计算,且提供了初始值,则是初始值,第二个参数u为Stream中的元素,然后应用apply方法体对参数t和u进行计算操作,得到的结果集会被赋值给下次执行这个方法的第一个参数。 常见的reduce方法列表如下:
//由于没有提供初始值,有可能返回null,所以使用Optional去做null处理Optional<T> reduce(BinaryOperator<T> accumulator);T reduce(T identity, BinaryOperator<T> accumulator);<U> U reduce(U identity,BiFunction<U, ? super T, U> accumulator,BinaryOperator<U> combiner);
字符串拼接、数值的sum、min、max、average都是特殊的reduce。
// 字符串连接,concat = "ABCD"String concat = Stream.of("A", "B", "C", "D").reduce("", String::concat);// 求最小值,minValue = -3.0double minValue = Stream.of(-1.5, 1.0, -3.0, -2.0).reduce(Double.MAX_VALUE, Double::min);// 求和,sumValue = 10, 有起始值int sumValue = Stream.of(1, 2, 3, 4).reduce(0, Integer::sum);// 求和,sumValue = 10, 无起始值sumValue = Stream.of(1, 2, 3, 4).reduce(Integer::sum).get();// 过滤,字符串连接,concat = "ace"concat = Stream.of("a", "B", "c", "D", "e", "F").filter(x -> x.compareTo("Z") > 0).reduce("", String::concat);
limit/skip
limit返回Stream的前n个元素;skip则是跳过前n个元素。List<Integer> list = Stream.of(1,2,3,4,5,6,7,8,9,10).limit(5).skip(2).collect(Collectors.toList());
sorted
对Stream的排序通过sorted进行,它比数组的排序更强大之处在于你可以首先对Stream进行各类map、filter、limit、skip甚至distinct来减少元素数量后,再排序,这能帮助程序明显缩短执行时间。int longest = Stream.of("aa","bbb","cccc","ddddd","eeeeee").mapToInt(String::length).max().getAsInt();System.out.println(longest);
min/max/distinct
min和max的功能也可以通过对Stream元素先排序,再findFirst来实现,但前者的性能会更好,为O(n),而 sorted 的成本是O()。同时它们作为特殊的reduce方法被独立出来也是因为求最大最小值是很常见的操作。int longest = Stream.of("aa","bbb","cccc","ddddd","eeeeee").mapToInt(String::length).max().getAsInt();System.out.println(longest);int shortest = Stream.of("aa","bbb","cccc","ddddd","eeeeee","f").mapToInt(String::length).min().getAsInt();System.out.println(shortest);List<String> list = Stream.of("aa","ddddd","cccc","ddddd","aa","f","cccc","www","aa").distinct().collect(Collectors.toList()) ;System.out.println(JSONObject.toJSONString(list));
Match
Stream 有三个 match 方法,从语义上说:- allMatch:Stream 中全部元素都符合传入的 predicate,则返回true。
- anyMatch:Stream 中只要有一个元素符合传入的 predicate,就返回true。
- noneMatch:Stream 中所有元素都不符合传入的 predicate,则返回true。
boolean isAllAdult = Stream.of(1,2,3,3,4).allMatch((t) -> t > 0);System.out.println(isAllAdult);boolean sThereAnyChild = Stream.of(1,2,3,3,4).anyMatch((t) -> t > 3);System.out.println(isAllAdult);boolean noneMatch = Stream.of(1,2,3,3,4).noneMatch((t) -> t > 4);System.out.println(noneMatch);
进阶:自己生成流
Stream.generate
通过实现Supplier接口,你可以自己来控制流的生成。这种情形通常用于随机数、常量的Stream,或者需要前后元素间维持着某种状态信息的Stream。把Supplier实例传递给
Stream.generate()生成的Stream,默认是串行(相对parallel而言)但无序的(相对ordered而言)。由于它是无限的,在管道中,必须利用limit之类的操作限制 Stream 大小。// 生成 10 个随机整数Random seed = new Random();Supplier<Integer> random = seed::nextInt;Stream.generate(random).limit(10).forEach(System.out::println);//Another wayIntStream.generate(() -> (int) (System.nanoTime() % 100)).limit(10).forEach(System.out::println);
Stream.generate()还接受自己实现的Supplier。例如在构造海量测试数据的时候,用某种自动的规则给每一个变量赋值;或者依据公式计算Stream的每个元素值。这些都是维持状态信息的情形。Stream.generate(new MySupplier()).limit(10).forEach(System.out::println);private class MySupplier implements Supplier<String> {private Random random = new Random();@Overridepublic String get() {return "boothsun" + random.nextInt();}}
Stream.iterate
iterate跟reduce操作很像,接受一个种子值,和一个UnaryOperator(例如 f)。然后种子值成为 Stream的第一个元素,f(seed)为第二个,f(f(seed))第三个,以此类推。// 生成一个等差数列Stream.iterate(0, n -> n + 3).limit(10). forEach(x -> System.out.print(x + " "));
与
Stream.generate相似,在iterate时候管道必须由limit这样的操作来限制Stream大小。
进阶:用Collectors来进行reduction操作
java.util.stream.Collectors类的主要作用就是辅助进行各类有用的reduction操作,例如转变输出为Collection,把 Stream 元素进行归组。
groupingBy/partitioningBy
用groupingBy实现按照年龄分组:// 按照年龄归组Map<Integer, List<Person>> personGroups = Stream.generate(new PersonSupplier()).limit(100).collect(Collectors.groupingBy(Person::getAge));for (Object o : personGroups.entrySet()) {Map.Entry<Integer, List<Person>> persons = (Map.Entry) o;System.out.println("Age " + persons.getKey() + " = " + persons.getValue().size());}private class PersonSupplier implements Supplier<Person> {private int index = 0;private Random random = new Random();@Overridepublic Person get() {return new Person(random.nextInt(10), "StreamTestUser-" + index++);}}class Person {private int age ;private String name ;Person(int age, String name) {this.age = age;this.name = name;}int getAge() {return age;}public void setAge(int age) {this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}}
用
partitioningBy实现按照未成年人和成年人分区:Map<Boolean, List<Person>> children = Stream.generate(new PersonSupplier()).limit(100).collect(Collectors.partitioningBy(p -> p.getAge() < 18));System.out.println("Children number: " + children.get(true).size());System.out.println("Adult number: " + children.get(false).size());
