@adamhand
2019-04-02T01:42:24.000000Z
字数 7089
阅读 1397
LeetCode题解
基本算法
递归
105. Construct Binary Tree from Preorder and Inorder Traversal
动态规划
198. House Robber
描述:假如有一个专业盗贼计划在一条路上盗取房屋钱财,每一个房屋都藏着一些钱。但是相邻房屋之间有安全系统相连,安全系统与警察相连,所以在同一晚上不能偷盗相邻的房屋。
给一个非负整数代表每一个房屋的藏的钱数,求在没有惊动警察的情况下,能盗取的最多的钱数。
分析:很显然,当面对房屋i时,有两种选择:偷或不偷。这个选择会影响后面的选择,所以可以考虑使用动态规划。
如果面对房屋i时,选择:
- 偷。这时就不能偷取
i-1的房子,而i-2和之前的房子可以再次做选择 - 不偷。这时
i-1和之前的房子都可以再次做选择
状态转移方程为:
rob(i) = Math.max(rob(i - 2) +currentHousrValue, rob(i - 1))
rob(i)表示面对房屋i时能够偷得的最大钱数。
第一种写法,使用自顶向下的递归:
public int rob(int[] nums) {return rob(nums, nums.length - 1);}private int rob(int[] nums, int i){if (i <0){return 0;}return Math.max(rob(nums, i - 2) + nums[i], rob(nums, i - 1));}
这种方法的复杂度太高,说不定还有栈溢出。
第二种写法,使用自顶向下的递归+memo:
这种方法的时间和空间复杂度都为O(n)。
int[] memo;public int rob(int[] nums){memo = new int[nums.length + 1];Arrays.fill(memo, -1);return rob(nums, nums.length - 1);}private int rob(int[] nums, int i){if (i < 0){return 0;}if (memo[i] >= 0){return memo[i];}int result = Math.max(rob(nums, i - 2) + nums[i], rob(nums, i - 1));memo[i] = result;return result;}
第三种写法,自底向上的递推+memo:
public int rob(int[] nums){if (nums == null || nums.length == 0)return 0;int[] memo = new int[nums.length + 1];memo[0] = 0;memo[1] = nums[0];for (int i = 1; i < nums.length; i++){int value = nums[i];memo[i + 1] = Math.max(memo[i - 1] + value, memo[i]);}return memo[nums.length];}
第四种写法,继续对空间进行优化:
因为考虑到写法三种的memo其实只用了两个数,就不必申请一个数组。当前房屋为i,则pre2代表i-2的房屋,pre1代表i-1的房屋。
public int rob(int[] nums){if (nums == null || nums.length == 0)return 0;int pre1 = 0, pre2 = 0;for (int num : nums){int temp = pre1;pre1 = Math.max(pre2 + num, pre1);pre2 = temp;}return pre1;}
数据结构中的算法
链表
单链表
328. Odd Even Linked List
描述:
将单链表中索引为奇数的节点放在一链表的前半部分,索引为偶数的节点放在链表的后半部分。不改变原链表节点之间的顺序。
要求所有操作在原地进行,并且算法的时间复杂度和空间复杂度在O(nodes)和O(1)内。
Example 1:Input: 1->2->3->4->5->NULLOutput: 1->3->5->2->4->NULLExample 2:Input: 2->1->3->5->6->4->7->NULLOutput: 2->3->6->7->1->5->4->NULL
思路:
使用两个游标odd和even,分别指向第一个奇数节点和第一个偶数节点,然后交替向后移动,通过这种移动可以将链表分为两个分叉,一个分叉包含奇数节点,另一个分叉包含偶数节点。这种移动方法很向人的两条腿走路,所以可以形象地称之为“左右腿法”。
如下图所示:
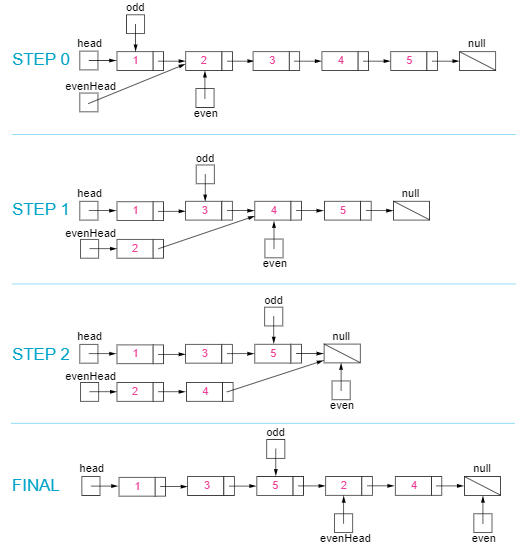
代码如下:
public class Solution {public ListNode oddEvenList(ListNode head) {if(head == null)return head;ListNode odd = head, even = head.next, evenHead = even;while (even != null && even.next != null){//像两条腿走路一样odd.next = even.next;odd = odd.next;even.next = odd.next;even = even.next;}odd.next = evenHead;return head;}}
287. Find the Duplicate Number
描述:
Given an array nums containing n + 1 integers where each integer is between 1 and n (inclusive), prove that at least one duplicate number must exist. Assume that there is only one duplicate number, find the duplicate one.
Example 1:
Input: [1,3,4,2,2]Output: 2
Example 2:
Input: [3,1,3,4,2]Output: 3
Note:
- You must not modify the array (assume the array is read only).
- You must use only constant, O(1) extra space.
- Your runtime complexity should be less than O(n2).
- There is only one duplicate number in the array, but it could be repeated more than once.
思路一:二分法+抽屉原理 时间 O(NlogN) 空间 O(1)
可以参考链接1 链接2 链接3
但是感觉解释的都不是特别正确,然而代码又是正确的。下面先贴出正确的代码,后面再看吧。、
public int findDuplicate(int[] nums) {int min = 0, max = nums.length - 1;while(min <= max){int mid = min + (max - min) / 2;int cnt = 0;for(int i = 0; i < nums.length; i++){if(nums[i] <= mid){cnt++;}}if(cnt > mid){max = mid - 1;} else {min = mid + 1;}}return min;}
思路二:链表找环法 时间 O(N) 空间 O(1)
假设数组中没有重复,那我们可以做到这么一点,就是将数组的下标和1到n每一个数一对一的映射起来。比如数组是[213],则映射关系为0->2, 1->1, 2->3。假设这个一对一映射关系是一个函数f(n),其中n是下标,f(n)是映射到的数。如果我们从下标为0出发,根据这个函数计算出一个值,以这个值为新的下标,再用这个函数计算,以此类推,直到下标超界。实际上可以产生一个类似链表一样的序列。比如在这个例子中有两个下标的序列,0->2->3。
但如果有重复的话,这中间就会产生多对一的映射,比如数组[2131],则映射关系为0->2, {1,3}->1, 2->3。这样,我们推演的序列就一定会有环路了,这里下标的序列是0->2->3->1->1->1->1->...,而环的起点就是重复的数。
所以该题实际上就是找环路起点的题。我们先用快慢两个下标都从0开始,快下标每轮映射两次,慢下标每轮映射一次,直到两个下标再次相同。这时候保持慢下标位置不变,再用一个新的下标从0开始,这两个下标都继续每轮映射一次,当这两个下标相遇时,就是环的起点,也就是重复的数。
注意,上面使用了一个环判定算法:floyd判环算法(Floyd cycle detection),就是通常所说的快慢指针法。
public int findDuplicate(int[] nums){int slow = 0;int fast = 0;//找到快慢指针相遇的地方do{slow = nums[slow];fast = nums[nums[fast]];}while (slow != fast);int find = 0;//找“环”的起点while (find != slow){slow = nums[slow];find = nums[find];}return find;}
参考链接1
202. Happy Number
描述:
Write an algorithm to determine if a number is "happy".A happy number is a number defined by the following process: Starting with any positive integer, replace the number by the sum of the squares of its digits, and repeat the process until the number equals 1 (where it will stay), or it loops endlessly in a cycle which does not include 1. Those numbers for which this process ends in 1 are happy numbers.
Example:
Input: 19Output: trueExplanation:12 + 92 = 8282 + 22 = 6862 + 82 = 10012 + 02 + 02 = 1
思路一:
如果按照上述方法,最后停止时结果为1,就是快乐数,否则,就会先放入一个循环,也就是说,前面出现过的数在后面又会重复出现。这就想到可以使用Java的HashSet,因为它其中存放的元素是不能重复的,如果将某个数放入HashSet中时,发现其中已经有了,说明陷入了循环,该数不是快乐数。
public boolean isHappy(int n) {Set<Integer> set = new HashSet<>();while (n != 1 && !set.contains(n)){set.add(n);int sum = 0;while (n > 0){int remain = n % 10;sum += remain * remain;n /= 10;}n = sum;}return n == 1;}
思路二:
由上面的思路,容易联想到“链表找环法”,可以将这个问题转换为一个链表问题,使用287题中的弗洛伊德判环法。
public boolean isHappy(int n) {int slow, fast;slow = fast = n;do{slow = digit(slow);fast = digit(digit(fast));}while (slow != fast);return slow == 1;}public int digit(int n){int sum = 0;while (n > 0){int remain = n % 10;sum += remain * remain;n /= 10;}return sum;}
树
BST
108. Convert Sorted Array to Binary Search Tree
描述:
将一个给定的有序数组转变成一个平衡二叉搜索树。
Given the sorted array: [-10,-3,0,5,9],One possible answer is: [0,-3,9,-10,null,5], which represents the following height balanced BST:0/ \-3 9/ /-10 5
思路:二叉查找树之所以叫“二叉”是因为它使用二叉搜索的方法来进行查找。中序遍历二叉查找树会得到一个有序数组。所以,如果将一个有序数组看成一棵树(以中点为根,左右为左右子树,依次下去),数组就相当于一棵二叉查找树。如果要构造这棵树,那就是把中间元素转化为根,然后递归构造左右子树。
public TreeNode sortedArrayToBST(int[] nums) {int left = 0, right = nums.length - 1;return helper(nums, left, right);}private TreeNode helper(int[] nums, int left, int right){if(left > right)return null;int mid = left + (right - left) / 2;TreeNode node = new TreeNode(nums[mid]);node.left = helper(nums, left, mid - 1);node.right = helper(nums, mid + 1, right);return node;}
109. Convert Sorted List to Binary Search Tree
描述:
将一个给定的有序数组转变成一个平衡二叉搜索树。
Given the sorted linked list: [-10,-3,0,5,9],One possible answer is: [0,-3,9,-10,null,5], which represents the following height balanced BST:0/ \-3 9/ /-10 5
思路:和上面的题目思路一样,不同之处是对于链表无法用下标的方式访问中间元素。可以按照中序遍历的顺序对链表进行访问,访问的顺序就是二叉搜索树中序遍历的顺序。
private ListNode head;private int countSize(ListNode head){int count = 0;ListNode cur = head;while (cur != null){cur = cur.next;count++;}return count;}private TreeNode convertListToBST(int l, int r){if(l > r)return null;int mid = (l + r) / 2;//左子树TreeNode left = convertListToBST(l, mid - 1);//根TreeNode root = new TreeNode(head.val);System.out.println(head.val);root.left = left;head = head.next;//右子树root.right = convertListToBST(mid + 1, r);return root;}public TreeNode sortedListToBST(ListNode head) {int size = countSize(head);this.head = head;return convertListToBST(0, size - 1);}
数学
172. Factorial Trailing Zeroes
描述:
Given an integer n, return the number of trailing zeroes in n!.
Example 1:
Input: 3Output: 0Explanation: 3! = 6, no trailing zero.
Example 2:
Input: 5Output: 1Explanation: 5! = 120, one trailing zero.
Note: Your solution should be in logarithmic time complexity.
思路一:
直接求阶乘。这种做法可能出现大数问题,可能溢出。
public int trailingZeroes(int n) {int sum = 1;for (int i = 1; i <= n; i++) {sum *= i;}int count = 0;while ((sum % 10) == 0) {sum /= 10;count++;}return count;}
思路二:
根据数学原理。
考虑n!的质数因子。后缀0总是由质因子2和质因子5相乘得来的,如果我们可以计数2和5的个数,问题就解决了。
考虑例子:n = 5时,5!的质因子中(2 * 2 * 2 * 3 * 5)包含一个5和三个2。因而后缀0的个数是1。
n = 11时,11!的质因子中((2 ^ 8) * (3 ^ 4) * (5 ^ 2) * 7)包含两个5和八个2。于是后缀0的个数就是2。
很容易观察到质因子中2的个数总是大于等于5的个数,因此只要计数5的个数即可。如何计算5的个数呢?
比如,n=25。计算n/5,得到5,即包含5个5,分别来自其中的5, 10, 15, 20, 25,但是在25中其实是包含2个5的,所以除了计算n/5, 还要计算n/5/5, n/5/5/5, n/5/5/5/5, ..., n/5/5/5,,,/5直到商为0,然后就和,就是最后的结果。
可以使用递归的方法或普通方法求解:
//递归方法public int trailingZeroes(int n) {return n == 0 ? 0 : n / 5 + trailingZeroes(n / 5);}//普通方法public int trailingZeroes(int n) {int count = 0;while (n != 0) {count += n / 5;n /= 5;}return count;}
