@adamhand
2019-03-03T04:19:33.000000Z
字数 85781
阅读 2231
《剑指offer》题目小结
1. 数组中重复元素问题
1.1 Find All Duplicates in an Array
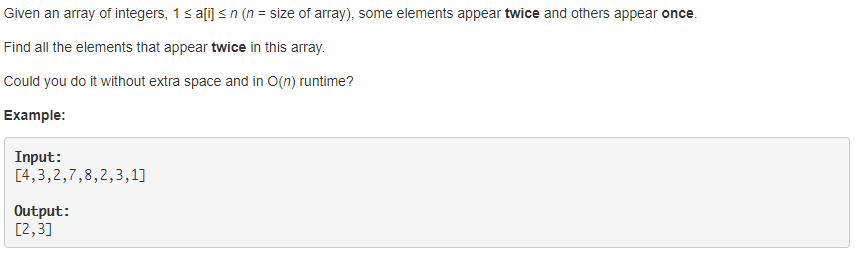
- 解法:采用“置相反数”的方法,每知道一个
nums[i],就将下标为nums[i]-1的元素置为相反数(因为数组中的数是从1开始的,不用担心数组越界;且数的最大值为n,即总能找到位置);然后判断下标为nums[i]-1处的数是否小于零,是的话,就表明该数之前已经出现过一次(如果没有重复的数,以其中一个数为下标只能找到一个位置,且仅有一个)。
如果还是想不通的话,把给定数组中的数按照从小到大排序后,就比较好理解了。比如将给定的数组数组排序[1,2,2,3,3,4,7,8]。
class Solution {public List<Integer> findDuplicates(int[] nums) {List<Integer> res = new ArrayList<>();for (int i = 0; i < nums.length; ++i) {int index = Math.abs(nums[i])-1;if (nums[index] < 0)res.add(Math.abs(index+1));nums[index] = -nums[index];}return res;}}
1.2 数组中的重复数字
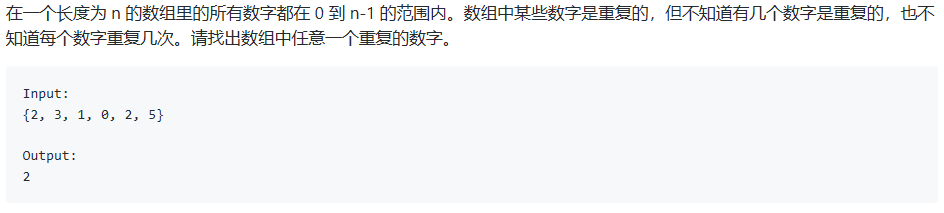
- 解法:这个题目就不能按照上面的解法来了,因为数组中的最小元素为0,最大元素为n-1,按照上述方法会产生越界问题。可以使用HashMap。
public boolean duplicate(int numbers[],int length,int [] duplication) {boolean flag = false;if(numbers==null || length==0){return flag;}HashMap<Integer, Integer> map = new HashMap<Integer, Integer>();for(int num: numbers){if(map.containsKey(num)){flag = true;duplication[0] = num;break;}map.put(num, 0);}return flag;}
2. 二维数组中的查找
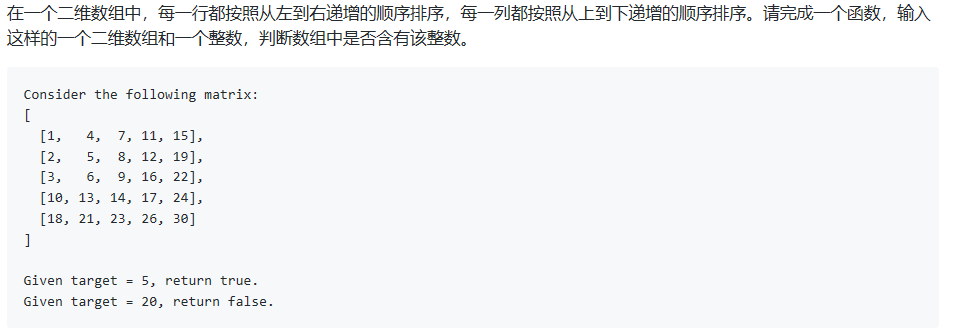
- 解法:从右上角开始查找。矩阵中的一个数,它左边的数都比它小,下边的数都比它大。因此,从右上角开始查找,就可以根据 target 和当前元素的大小关系来缩小查找区间。
public boolean Find(int target, int[][] matrix) {if (matrix == null || matrix.length == 0 || matrix[0].length == 0)return false;int rows = matrix.length, cols = matrix[0].length;int r = 0, c = cols - 1; // 从右上角开始while (r <= rows - 1 && c >= 0) {if (target == matrix[r][c])return true;else if (target > matrix[r][c])r++;elsec--;}return false;}
3. 替换空格

- 解法1:在字符串尾部填充任意字符,使得字符串的长度等于字符串替换之后的长度。因为一个空格要替换成三个字符(%20),因此当遍历到一个空格时,需要在尾部填充两个任意字符。
令 P1 指向字符串原来的末尾位置,P2 指向字符串现在的末尾位置。P1 和 P2从后向前遍历,当 P1 遍历到一个空格时,就需要令 P2 指向的位置依次填充 02%(注意是逆序的),否则就填充上 P1 指向字符的值。
从后向前遍是为了在改变 P2 所指向的内容时,不会影响到 P1 遍历原来字符串的内容。
public String replaceSpace(StringBuffer str) {int oldLen = str.length();for (int i = 0; i < oldLen; i++)if (str.charAt(i) == ' ')str.append(" ");int P1 = oldLen - 1, P2 = str.length() - 1;while (P1 >= 0 && P2 > P1) {char c = str.charAt(P1--);if (c == ' ') {str.setCharAt(P2--, '0');str.setCharAt(P2--, '2');str.setCharAt(P2--, '%');} else {str.setCharAt(P2--, c);}}return str.toString();}
- 解法2:利用Java自己的函数
replace(start, end, string)函数帮助我们替换字符串。我们只需要找到空格的位置即可。注意该函数在替换时包含start不包含end。例子如下:
StringBuilder sb = new StringBuilder("1234");sb.replace(1, 3, "nba");System.out.println(sb.toString());//结果为:1nba4
public String replaceSpace(StringBuffer str) {for(int i = 0; i < str.length(); i++){if(str.charAt(i) == ' '){str.replace(i, i+1, "%20");}}return str.toString();}
4. 从尾到头打印链表

- 解法1:使用栈
public class Solution {public ArrayList<Integer> printListFromTailToHead(ListNode listNode) {Stack<Integer> stack = new Stack<>();while(listNode != null){stack.add(listNode.val);listNode = listNode.next;}ArrayList<Integer> list = new ArrayList<>();while(!stack.isEmpty()){list.add(stack.pop());}return list;}}
- 解法2:由于递归在本质上就是一个栈结构,所以理所当然想到递归。但是如果链表非常长,使用递归容易造成栈溢出,不是一个好方法。
public class Solution {public ArrayList<Integer> printListFromTailToHead(ListNode listNode) {ArrayList<Integer> list = new ArrayList<>();if(listNode != null){list.addAll(printListFromTailToHead(listNode.next));list.add(listNode.val);}return list;}}
- 解法3:由给定的链表逆序构建一个新的链表,则新链表的元素和给定链表的元素相反。
public class Solution {public ArrayList<Integer> printListFromTailToHead(ListNode listNode) {//逆序构建链表ListNode head = new ListNode(-1);while(listNode != null){ListNode memo = listNode.next;listNode.next = head.next;head.next = listNode;listNode = memo;}ArrayList<Integer> list = new ArrayList<>();head = head.next;while(head != null){list.add(head.val);head = head.next;}return list;}}
- 解法4:使用
Collections.reverse()。
public class Solution {public ArrayList<Integer> printListFromTailToHead(ListNode listNode) {ArrayList<Integer> list = new ArrayList<>();while(listNode != null){list.add(listNode.val);listNode = listNode.next;}Collections.reverse(list);return list;}}
5. 重建二叉树
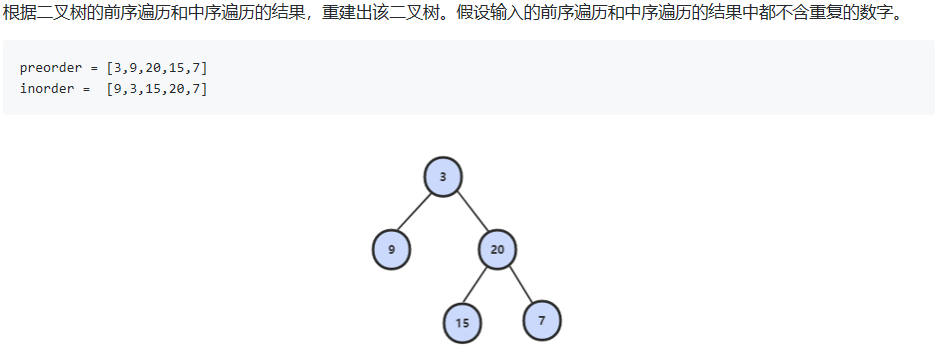
- 解法1:使用递归。
public class Solution {private Map<Integer, Integer> inOrderNumsIndex = new HashMap<>();public TreeNode reConstructBinaryTree(int [] pre,int [] in) {for(int i = 0; i < in.length; i++){inOrderNumsIndex.put(in[i], i);}return reBuildBinaryTreeCore(pre, 0, pre.length-1, 0, in.length-1);}private TreeNode reBuildBinaryTreeCore(int preorder[], int preStartIndex, int preEndIndex, int inStartIndex, int inEndIndex){//这种情况下说明左子树已经排完,返回继续排右子树。if(preStartIndex > preEndIndex){return null;}TreeNode root = new TreeNode(preorder[preStartIndex]);int rootIndex = inOrderNumsIndex.get(root.val);int leftTreeSize = rootIndex - inStartIndex;root.left = reBuildBinaryTreeCore(preorder, preStartIndex+1, preStartIndex+leftTreeSize, inStartIndex, inStartIndex+leftTreeSize-1);root.right = reBuildBinaryTreeCore(preorder, preStartIndex+leftTreeSize+1, preEndIndex, inStartIndex+leftTreeSize+1, inEndIndex);return root;}}
- 解法2:和解法一的思想一样,只是更清楚一些。
public class Solution {//存放中序遍历的值和索引Map<Integer, Integer> inIndex = new HashMap<>();public TreeNode reConstructBinaryTree(int [] pre,int [] in) {if(pre.length <= 0 || in.length <= 0 || pre.length != in.length){return null;}for(int i = 0; i < in.length; i++){inIndex.put(in[i], i);}int len = pre.length;return constructorCore(pre, in, 0, len-1, 0, len-1);}private TreeNode constructorCore(int[] pre, int[] in, int preStart, int preEnd, int inStart, int inEnd){TreeNode root = new TreeNode(pre[preStart]);root.left = null;root.right = null;if(preStart == preEnd){if(inStart == inEnd && pre[preStart] == in[inStart]){return root;}else{//如果输入错误,前序遍历和中序遍历结果不一致,则返回错误System.out.println("wrong input");return null;}}int index = inIndex.get(pre[preStart]);//int index = inIndex.get(root.val);int leftLen = index - inStart;if(leftLen > 0){root.left = constructorCore(pre, in, preStart+1, preStart+leftLen, inStart, index-1);}if(inEnd - index > 0){root.right = constructorCore(pre, in, preStart+leftLen+1, preEnd, index+1, inEnd);}return root;}}
对解法2的理解:由于递归可以转换为栈,所以可以用栈来解释一下,画出如下的栈图。


6. 二叉树的下一个节点
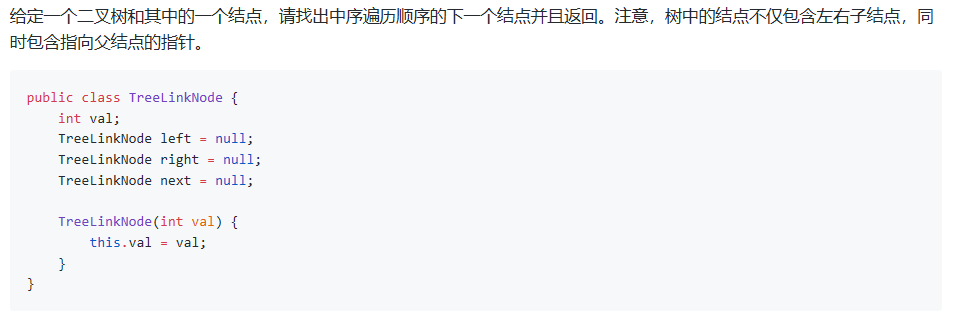
思路:
要找到中序遍历下的下一个节点。这个节点可以分为两种情况:
- 该节点有右子树。这种情况比较简单,直接将其右节点进行中序遍历即可,并将一个遍历到的最右节点返回。简单点说,该节点的下一个节点是右子树的最左节点。
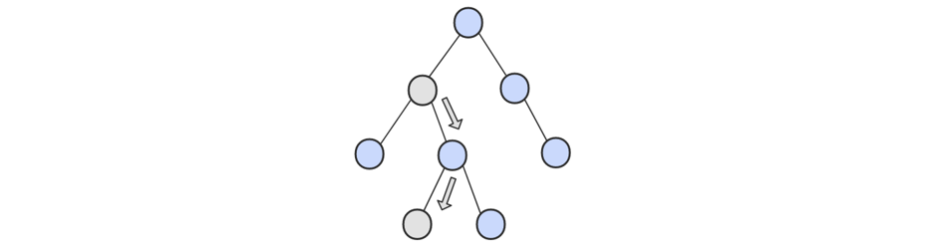
该节点没有右子树。这种情况又可以分为两种情况:
- 该节点是父节点的左子节点。直接将父节点返回即可。
- 该节点是父节点的右子节点。需要不断寻找当前节点父亲节点,直到当前节点是父亲节点的左子节点。这是因为中序遍历是是直先遍历节点的左子树,然后是节点本身,然后是节点的右子树,所以,如果一个节点是父节点的右子节点且该节点没有右子树,说明该节点是“当前树”的一个“最右节点”,所以我们就需要找到“当前树”的父节点。
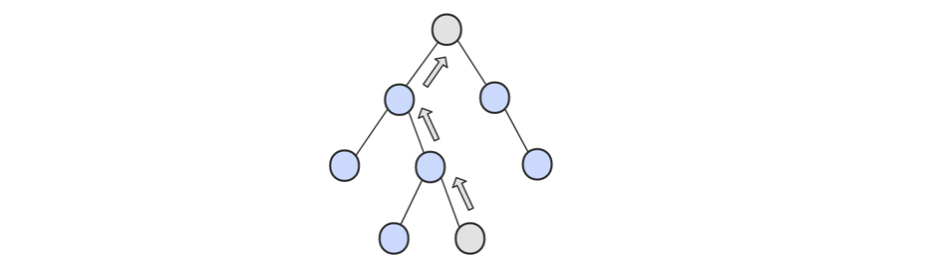
解法1:非递归法
public class Solution {public TreeLinkNode GetNext(TreeLinkNode pNode){if(pNode == null){return null;}if(pNode.right != null){pNode = pNode.right;while(pNode.left != null){pNode = pNode.left;}return pNode;}else{while(pNode.next != null){TreeLinkNode parent = pNode.next;if(parent.left == pNode){return parent;}pNode = pNode.next;}}return null;}}
- 解法2:递归法
public class Solution {public TreeLinkNode GetNext(TreeLinkNode pNode){if(pNode == null){return null;}if(pNode.right != null){return getNextNode(pNode.right);}else{if(pNode.next == null){return null;}else if(pNode.next.left == pNode){return pNode.next;}else{while(pNode.next.right == pNode){pNode = pNode.next;if(pNode.next == null){return null;}}return pNode.next;}}}private TreeLinkNode getNextNode(TreeLinkNode pNode){if(pNode == null){return null;}TreeLinkNode result = null;result = getNextNode(pNode.left);if(result == null){result = pNode;}return result;}}
7. 用两个栈实现队列
用两个栈来实现一个队列,完成队列的 Push 和 Pop 操作。
思路:stack1完成push操作,stack2完成pop操作。每次pop时,都要将stack1中的元素放入stack2中。
public class Solution {Stack<Integer> stack1 = new Stack<Integer>();Stack<Integer> stack2 = new Stack<Integer>();public void push(int node) {stack1.push(node);}public int pop() {if(stack2.isEmpty()){while(!stack1.isEmpty()){stack2.push(stack1.pop());}}return stack2.pop();}}
8.斐波那契数列
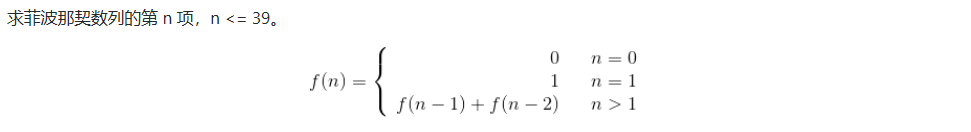
- 解法1:递归方法。不推荐
public class Solution {public int Fibonacci(int n) {if(n < 0){return -1;}else if(n <= 1){return n;}else{return Fibonacci(n - 1) + Fibonacci(n - 2);}}}
- 解法2:递推方法。
public class Solution {public int Fibonacci(int n) {if(n < 0){return -1;}else if(n <= 1){return n;}int pre2 = 0, pre1 = 1;int fib = 0;for(int i = 2; i <=n; i++){fib = pre2 + pre1;pre2 = pre1;pre1 = fib;}return fib;}}
- 解法3:使用一个不常用的公式。
具体见leetcode第70题,clibe stairs。
9. 跳台阶
一只青蛙一次可以跳上 1 级台阶,也可以跳上 2 级。求该青蛙跳上一个 n 级的台阶总共有多少种跳法。
解法:当n=1,只有一种跳法;当n=2,有两种跳法;当n>2,记f(n)为n阶台阶的跳法,则可以分为两种情况:第一次跳一个台阶,则跳法数为f(n-1);第一次跳两个台阶,则跳法数为f(n-2)。则f(n)=f(n-1)+f(n-2),不难看出,这是一个斐波那契数列问题。
public class Solution {public int JumpFloor(int target) {if(target < 0){return -1;}else if(target <= 2){return target;}int pre2 = 1, pre1 = 2;int result = 1;for(int i = 2; i < target; i++){result = pre2 + pre1;pre2 = pre1;pre1 = result;}return result;}}
10. 变态跳台阶
一只青蛙一次可以跳上 1 级台阶,也可以跳上 2 级... 它也可以跳上 n 级。求该青蛙跳上一个 n 级的台阶总共有多少种跳法。
- 解法1:
- 用f(n)表示跳上n阶台阶的方法数。如果按照定义,f(0)肯定需要为0,否则没有意义。但是我们设定f(0) = 1;n = 0是特殊情况,通过下面的分析就会知道,强制令f(0) = 1很有好处。ps. f(0)等于几都不影响我们解题,但是会影响我们下面的分析理解。
- 当n = 1 时, 只有一种跳法,即1阶跳:f(1) = 1;
当n = 2 时, 有两种跳的方式,一阶跳和二阶跳:f(2) = 2; 到这里为止,和普通跳台阶是一样的。
当n = 3 时,有三种跳的方式,第一次跳出一阶后,对应f(3-1)种跳法; 第一次跳出二阶后,对应f(3-2)种跳法;第一次跳出三阶后,只有这一种跳法。f(3) = f(2) + f(1)+ 1 = f(2) + f(1) + f(0) = 4;
当n = 4时,有四种方式:第一次跳出一阶,对应f(4-1)种跳法;第一次跳出二阶,对应f(4-2)种跳法;第一次跳出三阶,对应f(4-3)种跳法;第一次跳出四阶,只有这一种跳法。所以,f(4) = f(4-1) + f(4-2) + f(4-3) + 1 = f(4-1) + f(4-2) + f(4-3) + f(4-4) 种跳法。
当n = n 时,共有n种跳的方式,第一次跳出一阶后,后面还有f(n-1)中跳法; 第一次跳出二阶后,后面还有f(n-2)中跳法……………………..第一次跳出n阶后,后面还有 f(n-n)中跳法。f(n) = f(n-1)+f(n-2)+f(n-3)+……….+f(n-n) = f(0)+f(1)+f(2)+…….+f(n-1)。
通过上述分析,我们就得到了通项公式:
f(n) = f(0)+f(1)+f(2)+…….+ f(n-2) + f(n-1)
不难看出,这是一个斐波那契数列的变种问题。
public class Solution {public int JumpFloorII(int target) {if(target == 0 || target == 1){return 1;}else if(target == 2){return 2;}int result = 0;for(int i = 0; i < target; i++){result += JumpFloorII(i);}return result;}}
- 解法2:
- 思路1中得到通项公式 f(n) = f(0)+f(1)+f(2)+…….+ f(n-2) + f(n-1)
- 则 f(n-1) = f(0)+f(1)+f(2)+…….+ f(n-2) n>=2
- 两式相减,得
f(n)-f(n-1) = f(n-1),即f(n) = 2*f(n-1)
即得到如下递推公式:
public class Solution {public int JumpFloorII(int target) {int jumpFlo=1;while((--target) >0){jumpFlo*=2;}return jumpFlo;}}
- 解法3:每个台阶都有跳与不跳两种情况(除了最后一个台阶),最后一个台阶必须跳。所以共用种情况。
public class Solution {public int JumpFloorII(int target) {return 1<<--target;}}
11. 矩形覆盖问题
我们可以用 2*1 的小矩形横着或者竖着去覆盖更大的矩形。请问用 n 个 2*1 的小矩形无重叠地覆盖一个 2*n 的大矩形,总共有多少种方法?
解题思路:显然这又是一个斐波那契数列问题。
public class Solution {public int RectCover(int target) {if(target <= 2){return target;}int pre1 = 1, pre2 = 2;int result = 0;for(int i = 3; i <= target; i++){result = pre1 + pre2;pre1 = pre2;pre2 = result;}return result;}}
12. 旋转数组的最小数字
把一个数组最开始的若干个元素搬到数组的末尾,我们称之为数组的旋转。输入一个非递减排序的数组的一个旋转,输出旋转数组的最小元素。
例如数组 {3, 4, 5, 1, 2} 为 {1, 2, 3, 4, 5} 的一个旋转,该数组的最小值为 1。NOTE:给出的所有元素都大于 0,若数组大小为 0,请返回 0
解题思路:可以采用二分查找的方法。但是有一个问题,如果出现array[leftIndex]==array[minIndex]==array[rightIndex]的情况,无法确定解在哪个区间,需要切换到顺序查找。
public class Solution {public int minNumberInRotateArray(int [] array) {if(array == null || array.length <= 0){throw new RuntimeException("输入数组不符合要求");}int leftIndex = 0;int rightIndex = array.length - 1;int midIndex = 0;while(array[leftIndex] >= array[rightIndex]){if(rightIndex - leftIndex == 1){midIndex = rightIndex;break;}midIndex = (leftIndex + rightIndex) / 2;//如果leftIndex minIndex rightIndex指向的三个数的值相同,则只能采取顺序查找的方法。if(array[leftIndex] == array[midIndex] && array[midIndex] == array[rightIndex]){return minInOrder(array, leftIndex, rightIndex);}if(array[midIndex] >= array[leftIndex]){leftIndex = midIndex;}else if(array[midIndex] <= array[rightIndex]){rightIndex = midIndex;}}return array[midIndex];}//顺序查找private int minInOrder(int[] array, int index1, int index2){int result = array[index1];for(int i = index1+1; i < index2; i++){if(result > array[i]){result = array[i];}}return result;}}
13. 矩阵中的路径
14. 机器人的运动范围
15. 剪绳子
16. 二进制中1的个数
题目描述
输入一个整数,输出该数二进制表示中 1 的个数(符号位不算)。
- 解法1,可能引起死循环的解法:首先判断该数二进制表示中最右一位是不是1,接着把输入的整数右移一位,再次判断最右一位是不是1,直到该整数变为0位置。
这个方法对输入整数为整数的情况是有效的,但是如果输入一个负数,右移一位就会在最左侧补1,这样该数永远不为0,就会陷入死循环。
但是Java中有一个逻辑右移的概念,使用逻辑右移而不是算数右移,可以避免死循环。代码如下:
public static int numberOf1_1(int n){int count;if(n < 0) //去掉符号位count = -1;elsecount = 0;while(n != 0){if((n & 0x01) != 0){count++;}n >>>= 1; //使用逻辑右移,可以避免死循环//n >>= 1; //使用算数右移,输入为负数时会产生死循环}return count;}
- 解法2,常规解法:设置一个标志flag=1,每次将flag和给定的整数做与运算后,将flag左移一位,直到flag变为0,这样就能够判断输入数的每一位是不是为1。
这个算法循环的次数等于flag二进制的位数,如果flag是一个整数,则要循环32次。代码如下:
public static int numberOf1_2(int n){int count = 0;int flag = 1;while(flag > 0){if((n & flag) != 0){count++;}flag <<= 1;}return count;}
- 解法3,惊喜解法:这个解法运用了一个性质,把一个整数减去1,再和原整数做与运算,会把该整数最右边一个1变为0。那么一个整数的二进制表示中有多少个1,就能够进行多少次这样的操作。代码如下:
public static int numberOf1_3(int n){int count = 0;if(n < 0) //如果n小于0的话,要剪掉符号位的1count -= 1;while(n != 0){++count;n &= (n - 1);}return count;}
- 解法4,用Integer.bitCount()函数。代码如下:
public static int numberOf1_4(int n){if(n < 0) //去掉符号位return Integer.bitCount(n) - 1;elsereturn Integer.bitCount(n);}
小结:Java中的左移和右移
在计算机中,移位操作可以被总结如下:
对于其他语言比如C/C++,右移时选择逻辑右移还是算数右移是由编译器自己确定的,有符号数进行算数右移,无符号数进行逻辑右移。但是Java提供了一个逻辑右移运算符 >>>,可以人为指定右移方式。Java中的移位运算可以被总结为如下:
- <<:左移运算符,右边补0,num << 1,相当于num乘以2;
- >>:算数右移运算符,左边补符号位,num >> 1,相当于num除以2;
- >>>:逻辑右移运算符,左边补0;
补充1:Java中的左移
- java的左右移操作的对象是补码;
- byte、char会转成int再操作;
- long类型不转换;
- double、float不可进行移动操作;
看下列操作:
- System.out.println(1<<3);结果为8(1*2^3)
- System.out.println(1<<31);结果为-2147483648(符号位变为1,为什么变为1呢?因为这是个临界值)
- System.out.println(1<<32);结果为1(不是0,
<<n实际是<<(n%32),对于long<<n实际是<<n%64))
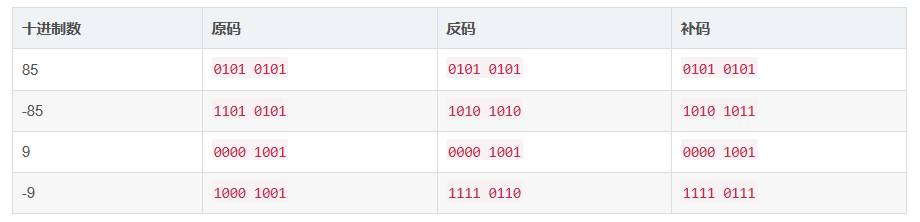
补充2:源码、反码和补码
- 原码就是符号位加上真值的绝对值, 即用第一位表示符号, 其余位表示值。
- 反码的表示方法是:正数的反码是其本身;负数的反码是在其原码的基础上, 符号位不变,其余各个位取反。
- 补码的表示方法是:正数的补码就是其本身;负数的补码是在其原码的基础上, 符号位不变, 其余各位取反, 最后+1。 (即在反码的基础上+1)
举例:
那么计算机为什么要使用补码呢?
首先,根据运算法则减去一个正数等于加上一个负数, 即: 1-1 = 1+(-1), 所以计算机被设计成只有加法而没有减法, 而让计算机辨别”符号位”会让计算机的基础电路设计变得十分复杂,于是就让符号位也参与运算,从而产生了反码。
用反码计算, 出现了”0”这个特殊的数值, 0带符号是没有任何意义的。 而且会有[0000 0000]和[1000 0000]两个编码表示0。于是设计了补码, 负数的补码就是反码+1,正数的补码就是正数本身,从而解决了0的符号以及两个编码的问题: 用[0000 0000]表示0,用[1000 0000]表示-128。
注意:-128实际上是使用以前的-0的补码来表示的, 所以-128并没有原码和反码。使用补码, 不仅仅修复了0的符号以及存在两个编码的问题, 而且还能够多表示一个最低数。 这就是为什么8位二进制, 使用补码表示的范围为[-128, 127]。
求补码的两种方式:
- 先写出对应的原码,然后符号位不变,除符号位外逐位取反,最后再加1;
- 先写出对应的原码,然后根据原码从右往左找出第一个1,这个1不变,符号位不变,1左边的全部去反,右边的也不变。;
补充3:循环左移
整数的循环移位:
- 确定要操作数据类型的位数L;(如
byte b的L=8) - 确定要循环左移的位数
n(n<L);(如循环左移3位) - 原数数据左移n 取或 原数据逻辑右移
L-n;(b=(byte)(b<<3|b>>>5))(循环右移的话就:>>>n|<<L-n)
代码如下:
public class LoopLeftShift {public static void main(String[] args) {int a=0xD6485F0F;//转为2进制是32位//循环左移7位int temp=a<<7|a>>>(32-7);//这里注意右移用的是无符号右移System.out.println(Integer.toHexString(temp));//正确答案是0x242F87EB//循环右移7位temp=a>>>7|a<<(32-7);//这里注意右移用的是无符号右移System.out.println(Integer.toHexString(temp));//正确答案是0x1fac90be}}
字符串的循环移位:
核心思想:三次翻转。
循环左移n位:
- 先整体反转:首先将原字符串进行反转;
- 再部分反转:把整个字符串分成 原字符串的长度-n和后n个字符并分别进行反转;
- 最后合并:合并两个字符串;
循环右移n位:
- 先部分反转:把原字符串分成 原字符串的长度-n和后n个字符并分别进行反转;
- 合并:合并两个字符串;
- 整体反转:再次进行反转;
//字符串翻转public static String reverse(String str){char[] strs = str.toCharArray();for(int i = 0; i < str.length() / 2; i++){char temp = strs[i];strs[i] = strs[str.length() - i - 1];strs[str.length() - i - 1] = temp;}return String.valueOf(strs);}//循环左移public static String loopLeftShift(String str, int index){str = reverse(str);String left = reverse(str.substring(0, str.length() - index)); //substring(int beginIndex, int endIndex)String right = reverse(str.substring(str.length() - index)); //substring(int beginIndex)str = left + right;return str;}//循环右移public static String loopRightShift(String str, int index){String left = reverse(str.substring(0, str.length() - index));String right = reverse(str.substring(str.length() - index));str = left + right;str = reverse(str);return str;}
16.1 相关题目1
题目描述:用一条语句判断一个整数是不是2的整数次方。
分析:一个整数如果是2的整数次方,那么它的二进制表示中有且只有一位是1,其它位都是0;那么将这个数减去1之后和自身做与运算,这个整数就会变为0。代码如下:
public static boolean isIntegerMultipleOf2(int num){if((num & (num - 1)) == 0)return true;elsereturn false;}
16.2 相关题目2
题目描述:输入两个整数m和n,计算需要改变m的二进制表示中的多少位才能得到n。比如10的二进制表示为1010,13的二进制表示为1101,需要改变1010中的3位才能得到1101。
分析:可以分两步解决这个问题,第一步求这两个数的异或,第二步统计异或结果中1的位数。代码如下:
public static int changeNumber(int m, int n){int count = 0; //需要改变的次数int xor = m ^ n;System.out.println(xor);while(xor != 0){count++;xor &= (xor - 1);}return count;}
注意:由于负数在计算机中是以补码的形式存储的,所以如果输入m=-1,n=10,输入结果为30。-7在计算机中的表示为
1111 1111 1111 1111 1111 1111 1111 1001,10表示为0000 0000 0000 0000 0000 0000 0000 1010。
17. 数值的整数次方
题目描述
实现函数double Power(double base, int exponent),求base的exponent次方。不得使用库函数,同时不要考虑大数问题。
思路:本体需要注意以下四点:
- 0的0次方在数学上是没有意义的,因此无论是输出1还是0都是可以接受的,本题选择输出1
- 0的负数次方相当于0作为除数,也是无意义的,非法输入
- base如果非0,如果指数exponent小于0,可以先求base的|exponent|次方,然后再求倒数
- 判断double类型的base是否等于0不能使用==号。因为计算机表述小树(包括float和double型小数)都有误差,不能直接使用等号(==)判断两个小数是否相等。如果两个数的差的绝对值很小,那么可以认为两个double类型的数相等。
根据以上的思考,可以写出如下程序:
- 解法1,普通解法:代码如下
private static double powerWithUnsignedExponent(double base, int exponent){double result = 1.0;for(int i = 1; i <= exponent; i++)result *= base;return result;}public static double power(double base, int exponent){boolean isNegtive = false;//底数为0且指数为负数,为了避免对0求导数出现的错误,直接返回0.0if(Math.abs(base - 0.0) < Double.MIN_VALUE && exponent < 0){return 0.0;}if(exponent < 0){exponent = -exponent;isNegtive = true;}double result = powerWithUnsignedExponent(base, exponent);return isNegtive ? 1.0 / result : result;}
- 解法2,高效解法:有这样一种思路,如果输入的指数为32,那么可以先求16次方,要求16次方可以先求8次方,同理,可以先求4次方,2次方,1次方。可以用如下公示表示:
上述公式中,a相当于base,n相当于exponent。这个公式很容易就能用递归来实现。代码如下
private static double powerWithUnsignedExponent(double base, int exponent) {//0的0次方也输出1if(exponent == 0)return 1;if(exponent == 1)return base;//result相当于base^n/2//用移位运算代替除以2,效率高double result = powerWithUnsignedExponent(base, exponent >> 1);result *= result;//如果exponent为奇数,还要乘以base//用位运算代替求余操作(%)来判断一个数是奇数还是偶数if((exponent & 0x01) == 1)result *= base;return result;}public static double power(double base, int exponent){boolean isNegtive = false;//底数为0且指数为负数,为了避免对0求导数出现的错误,直接返回0.0if(Math.abs(base - 0.0) < Double.MIN_VALUE && exponent < 0){return 0.0;}if(exponent < 0){exponent = -exponent;isNegtive = true;}double result = powerWithUnsignedExponent(base, exponent);return isNegtive ? 1.0 / result : result;}
18. 打印从 1 到最大的 n 位数
题目描述
输入数字 n,按顺序打印出从 1 到最大的 n 位十进制数。比如输入 3,则打印出 1、2、3 一直到最大的 3 位数即 999。
本题需要注意的是“大数问题”,如果n非常大,用int或long型变量存储会产生溢出。
- 解法1,没考虑大数问题:
public static void Print1ToMaxOfNDigit(int n){int number = 1;int i = 0;while(i++ < n){number *= 10;}//number-1是最大的n位数for(int j = 1; j < number; j++){System.out.println(j);}}
- 解法2,用字符串模拟加法,解决大数问题。首先把字符串中的每一个数字都初始化为'0',然后每一次为字符串表示的数字加1,。因此只需要做两件事:一是在字符串上模拟加法,二是吧字符串表达的数字打印出来。
//打印1到最大的n位数public class OneToN {public static void main(String[] args) {print1ToMaxOfN(2);}public static void print1ToMaxOfN(int n){if(n < 0)return;StringBuilder number = new StringBuilder();System.out.println(number.length());for(int i = 0; i < n; i++)number.append('0');while(!increment(number)){printNumber(number);}}public static boolean increment(StringBuilder sb){boolean isOverflow = false; //是否最高位溢出int nTakeOver = 0; //进位for(int i = sb.length() - 1; i >= 0; i--){int nSum = sb.charAt(i) - '0' + nTakeOver; //某位上的数加上进位if(i == sb.length() - 1) //如果当前位为最低位,最低位加一nSum++;if(nSum >= 10){ //要产生进位if(i == 0)isOverflow = true;else {nSum -= 10;nTakeOver = 1; //进位sb.setCharAt(i, (char)('0'+nSum));}}else {sb.setCharAt(i, (char)('0'+ nSum)); //不产生进位,也就不需要运算高位,直接跳出break;}}return isOverflow;}public static void printNumber(StringBuilder sb){boolean isBegin0 = true;//因为字符串前面补得是'0',打印时要跳过这些0for(int i = 0; i < sb.length(); i++){if(isBegin0 && sb.charAt(i) != '0')isBegin0 = false;if(!isBegin0)System.out.print(sb.charAt(i));}System.out.print(" ");}}
- 解法3,转化成排列问题,使用递归让代码更简洁。因为n位所有十进制数其实就是n个从0到9的全排列。也就是说,把数字的每一位都从0到9排列一遍,就得到了所有的十进制数。而全排列很容易用递归来表达。
public static void Print1ToMaxOfNDigits_3(int n){if(n < 0){return;}StringBuffer s = new StringBuffer(n);for(int i = 0; i < n; i++){s.append('0');}for(int i = 0; i < 10; i++){s.setCharAt(0, (char) (i+'0'));Print1ToMaxOfNDigits_3_Recursely(s, n, 0);}}public static void Print1ToMaxOfNDigits_3_Recursely(StringBuffer s, int n , int index){if(index == n - 1){PrintNumber(s);return;}for(int i = 0; i < 10; i++){//设置某一位的数s.setCharAt(index+1, (char) (i+'0'));//第一次递归设置十位数,第二次设置百位数......Print1ToMaxOfNDigits_3_Recursely(s, n, index+1);}}public static void PrintNumber(StringBuffer s){boolean isBeginning0 = true;for(int i = 0; i < s.length(); i++){if(isBeginning0 && s.charAt(i) != '0'){isBeginning0 = false;}if(!isBeginning0){System.out.print(s.charAt(i));}}System.out.println();}
补充:排列组合的递归实现
- 排列问题:输入一个字符串,打印出该字符串中字符的所有排列。例如输入字符串abc,则输出由字符a、b、c所能排列出来的所有字符串abc、acb、bac、bca、cab和cba。
可以这样想:固定第一个字符a,求后面两个字符bc的排列。当两个字符bc的排列求好之后,我们把第一个字符a和后面的b交换,得到bac,接着我们固定第一个字符b,求后面两个字符ac的排列。现在是把c放到第一位置的时候了。记住前面我们已经把原先的第一个字符a和后面的b做了交换,为了保证这次c仍然是和原先处在第一位置的a交换,我们在拿c和第一个字符交换之前,先要把b和a交换回来。在交换b和a之后,再拿c和处在第一位置的a进行交换,得到cba。我们再次固定第一个字符c,求后面两个字符b、a的排列。这样写成递归程序如下:
public static void permutation(char[] array, int index){if(index==array.length){System.out.println(array);return;}if(array.length==0||index<0||index>array.length){return;}for(int j=index;j<array.length;j++){char temp=array[j];array[j]=array[index];array[index]=temp;permutation(array, index+1);temp=array[j];array[j]=array[index];array[index]=temp;}}调用:permutation(chars, 0)
- 组合问题:输入一个字符串,输出该字符串中字符的所有组合。举个例子,如果输入abc,它的组合有a、b、c、ab、ac、bc、abc。
假设我们想在长度为n的字符串中求m个字符的组合。我们先从头扫描字符串的第一个字符。针对第一个字符,我们有两种选择:一是把这个字符放到组合中去,接下来我们需要在剩下的n-1个字符中选取m-1个字符;二是不把这个字符放到组合中去,接下来我们需要在剩下的n-1个字符中选择m个字符。这两种选择都很容易用递归实现。
public static void combiantion(char chs[]){if(chs==null||chs.length==0){return ;}List<Character> list=new ArrayList();for(int i=1;i<=chs.length;i++){combine(chs,0,i,list);}}//从字符数组中第begin个字符开始挑选number个字符加入list中public static void combine(char []cs,int begin,int number,List<Character> list){if(number==0){System.out.println(list.toString());return ;}if(begin==cs.length){return;}list.add(cs[begin]);combine(cs,begin+1,number-1,list);list.remove((Character)cs[begin]);combine(cs,begin+1,number,list);}
19. 在O(1)的时间内删除链表节点
题目描述:
给定单向链表的头指针和一个结点指针,定义一个函数在O(1)时间删除该结点。
思路:
- 如果该节点不是尾节点,那么可以直接将下一个节点的值赋给该节点,然后令该节点指向下下个节点,再删除下一个节点,时间复杂度为 O(1)。

- 否则,就需要先遍历链表,找到节点的前一个节点,然后让前一个节点指向 null,时间复杂度为 O(N)。

综上,如果进行 N 次操作,那么大约需要操作节点的次数为 N-1+N=2N-1,其中 N-1 表示 N-1 个不是尾节点的每个节点以 O(1) 的时间复杂度操作节点的总次数,N 表示 1 个尾节点以 O(N) 的时间复杂度操作节点的总次数。(2N-1)/N ~ 2,因此该算法的平均时间复杂度为 O(1)。
class ListNode{int value;ListNode nextNode;}public ListNode deleteNode(ListNode head, ListNode tobeDelete) {if (head == null || head.next == null || tobeDelete == null)return null;if (tobeDelete.next != null) {// 要删除的节点不是尾节点ListNode next = tobeDelete.next;tobeDelete.val = next.val;tobeDelete.next = next.next;} else {ListNode cur = head;while (cur.next != tobeDelete)cur = cur.next;cur.next = null;}return head;}
20. 删除链表中的重复元素
题目描述
给定排序的链表,删除重复元素,只保留重复元素第一次出现的结点;
- 思路一:两个指针分别指向链表的第一个结点及第二个结点,即 pre 指向第一个结点、cur 指向第二个结点;若 pre.value == cur.value,则 pre 的 next 指向 cur 的 next ,cur 指向 cur 的 next ;若不等,则 pre 指向 cur,cur 指向 cur 的 next;直到循环结束;
/*** 删除链表中重复的结点值,只保留第一个重复结点的值* @param head 链表的头结点*/public static void deleteRepeteNode(Node head) {Node pre = head.next;Node cur;while (pre != null) {cur = pre.next;if (cur != null && (pre.value == cur.value)) {pre.next = cur.next;} else {pre = cur;}}}
- 思路二:采用递归。注意,这种方法将所有的重复元素全部删除了,没有保留一个,所以严格来说不符合题目要求。
public static Node deleteDuplication(Node pHead){if(pHead == null||pHead.next == null)return pHead;if(pHead.value == pHead.next.value){//第一个节点是重复节点,则跳过重复节点Node node = pHead.next;while(node != null&&node.value == pHead.value)node = node.next;return deleteDuplication(node);}else{//第一个节点不是重复节点pHead.next = deleteDuplication(pHead.next);return pHead;}}
- 思路三:采用指针。
public static void deleteDuplication(Node head){Node pre = head.next;Node cur = pre.next;while(pre != null && cur != null){if(pre.value == cur.value){while(cur.value == cur.next.value)cur = cur.next;pre.next = cur.next;cur = pre.next;}else {pre = pre.next;cur = cur.next;}}}
测试函数和Node结构。
public static void test(){int[] num = { 2, 3, 3, 5, 7, 8, 8, 8, 9, 9, 10 };Node head = new Node();Node pre = head;for (int i = 0; i < num.length; i++) {Node node = new Node(num[i]);pre.next = node;pre = node;}System.out.print("删除重复结点前的链表:");print(head.next);deleteRepeteNode(head);// Node delete = deleteDuplication(head);System.out.print("删除重复结点后的链表:");print(head.next);}class Node {public int value;public Node next;public Node() {}public Node(int value) {this.value = value;}}
21. 正则表达式匹配
题目描述:
请实现一个函数用来匹配包含'.'和'*'的正则表达式。模式中的字符‘.’表示任意一个字符,而'*'表示它前面的字符可以出现任意次(含0次)。在本题中,匹配是指字符串的所有字符匹配整个模式。例如,字符串"aaa"与模式"a.a"和"ab*ac*a"匹配,但与"aa.a"及"ab*a"均不匹配。
分析:这道题的核心其实在于分析
'*',对于'.'来说,它和任意字符都匹配,可把其当做普通字符。对于'*'的分析,我们要进行分情况讨论,当所有的情况都搞清楚了以后,就可以写代码了。
- 在每轮匹配中,Patttern第二个字符是''时:
- 第一个字符不匹配('.'与任意字符视作匹配),那么''只能代表匹配0次,比如'ba'与'a*ba',字符串不变,模式向后移动两个字符,然后匹配剩余字符串和模式
- 第一个字符匹配,那么'*'可能代表匹配0次,1次,多次,比如'aaa'与'a*aaa'、'aba'与'a*ba'、'aaaba'与'a*ba'。匹配0次时,字符串不变,模式向后移动两个字符,然后匹配剩余字符串和模式;匹配1次时,字符串往后移动一个字符,模式向后移动2个字符;匹配多次时,字符串往后移动一个字符,模式不变;
- 而当Patttern第二个字符不是'*'时,情况就简单多了:
- 如果字符串的第一个字符和模式中的第一个字符匹配,那么在字符串和模式上都向后移动一个字符,然后匹配剩余字符串和模式。
- 如果字符串的第一个字符和模式中的第一个字符不匹配,那么直接返回false。
//正则表达式匹配public class Regex {public static boolean match(String input,String pattern){if(input==null||pattern==null) return false;return matchCore(input,0,pattern,0);}private static boolean matchCore(String input,int i,String pattern,int p){if((input.length()==i)&&(pattern.length()==p)){//出口1,input和pattern都到了字符串末尾return true;}if((i!=input.length())&&(pattern.length()==p)){//出口2,字符串input没有到末尾,pattern到了末尾return false;}if((input.length()==i)&&(pattern.length()!=p)){//出口3,字符串input到末尾,pattern还没有到末尾return false;}if((p+1<pattern.length())&&(pattern.charAt(p+1)=='*')){//pattern第二个字符为*if((input.charAt(i)==pattern.charAt(p))||(pattern.charAt(p)=='.')){//首字母相匹配return matchCore(input,i+1,pattern,p+2) //*表示出现1次||matchCore(input,i+1,pattern,p) //*表示出现多次||matchCore(input,i,pattern,p+2); //*表示出现0次 , a ... p* ...}else{//首字母不匹配return matchCore(input,i,pattern,p+2);}} //end pattern.charAt(p+1)=='*'if((input.charAt(i)==pattern.charAt(p))||(pattern.charAt(p)=='.')){//pattern第二个字母不是*,且首字母匹配return matchCore(input,i+1,pattern,p+1);}return false; //其余情况全部不匹配}public static void main(String[] args) {// TODO Auto-generated method stubScanner scanner = new Scanner(System.in); //扫描键盘输入System.out.println(" 请输入第一个字符串:");String str1 = scanner.nextLine();System.out.println(" 请输入第二个字符串:");String str2 = scanner.nextLine();scanner.close();System.out.print("匹配的结果为:");System.out.println(match(str1, str2));}}
22. 表示数值的字符串
题目描述:
请实现一个函数用来判断字符串是否表示数值(包括整数和小数)。例如,字符串"+100","5e2","-123","3.1416"和"-1E-16"都表示数值。 但是"12e","1a3.14","1.2.3","+-5"和"12e+4.3"都不是。
思路一:从头到尾比较。
private static int inx;public static void main(String[] args) {test("Test1", "100", true);test("Test2", "123.45e+6", true);test("Test3", "+500", true);test("Test4", "5e2", true);test("Test5", "3.1416", true);test("Test6", "600.", true);test("Test7", "-.123", true);test("Test8", "-1E-16", true);test("Test9", "1.79769313486232E+308", true);System.out.println();test("Test10", "12e", false);test("Test11", "1a3.14", false);test("Test12", "1+23", false);test("Test13", "1.2.3", false);test("Test14", "+-5", false);test("Test15", "12e+5.4", false);test("Test16", ".", false);test("Test17", ".e1", false);test("Test18", "+.", false);}public static void test(String testName, String str, boolean expected){if(isNumeric(str.toCharArray()) == expected)System.out.println(testName+"+Passed.");elseSystem.out.println(testName+"+Failed.");}public static boolean isNumeric(char[] str) {if(str==null || str.length==0){return false;}inx = 0;boolean flag = scanInteger(str);//判断小数部分if(inx<str.length && str[inx]=='.'){inx = inx+1;flag = scanUInteger(str)||flag; //解释a,见代码下方}//判断指数部分if(inx<str.length && (str[inx]=='e' || str[inx]=='E')){inx = inx+1;flag = flag && scanInteger(str);}return flag && inx>=str.length;}//判断是否是整数public static boolean scanInteger(char[] str){if(inx<str.length &&(str[inx]=='+' || str[inx]=='-')){inx = inx+1;}return scanUInteger(str);}//判断是否是无符号整数public static boolean scanUInteger(char[] str){int inx1=inx;while(inx<str.length && str[inx]>='0' && str[inx]<='9'){inx = inx + 1;}return inx>inx1;}
思路二:使用库函数
public static boolean isNumeric_1(char[] str){try {Double number = Double.parseDouble(new String(str));}catch (NumberFormatException e){return false;}return true;}
思路三:使用正则表达式。
[] : 字符集合
() : 分组
? : 重复 0 ~ 1
+ : 重复 1 ~ n
* : 重复 0 ~ n
. : 任意字符
\. : 转义后的 .
\d : 数字
public static boolean isNumeric_2(char[] str){if (str == null || str.length == 0)return false;return new String(str).matches("[+-]?\\d*(\\.\\d+)?([eE][+-]?\\d+)?");}
23. 字符流中第一个不重复的字符
题目描述:
请实现一个函数用来找出字符流中第一个只出现一次的字符。例如,当从字符流中只读出前两个字符”go”时,第一个只出现一次的字符是”g”。当从该字符流中读出前六个字符“google”时,第一个只出现一次的字符是”l”。
解题思路:可以使用HashMap存储字符和其出现的次数,但是因为HashMap遍历是无序的,还需要用用ArrayList来确定字符输入的顺序,从而得到第一个只初夏一次的字符。
static HashMap<Character, Integer> map = new HashMap<>();static ArrayList<Character> list = new ArrayList<>();public static void main(String[] args) {char[] chars = "google".toCharArray();for(int i = 0; i < chars.length; i++)insert(chars[i]);System.out.println(firstAppearOnce());}public static char firstAppearOnce(){for(char key : list){if(map.get(key) == 1)return key;}return '#';}public static void insert(char ch){if(map.containsKey(ch))map.put(ch, map.get(ch)+1);elsemap.put(ch, 1);list.add(ch);}
24. 调整数组顺序是奇数位于偶数前面
题目描述:
输入一个整数数组,实现一个函数来调整该数组中数字的顺序,使得所有奇数位于数组的前半部分,所有偶数位于数组的后半部分(两种情况的代码:不考虑调整后奇数的之间和偶数之间的相对位置;考虑调整后奇数之间和偶数之间的相对位置不变)。
思路一:使用双指针法。这种情况没有考虑调整后奇数之间和偶数之间的行对位置。
public static void reOrderArray(int[] arr){if(arr == null || arr.length < 0)return;int head = 0, tail = arr.length - 1;while(head < tail){while(head < tail && (arr[head] & 0x01) != 0)head++;while(head < tail && (arr[tail] & 0x01) == 0)tail--;if(head < tail){int temp = arr[head];arr[head] = arr[tail];arr[tail] = temp;}}}
思路二:要求保证调整后奇数之间和偶数之间的相对位置不变。需要一个辅助数组。
public static void reOrderArray_1(int[] nums) {// 奇数个数int oddCnt = 0;for (int val : nums)if ((val & 0x01) != 0)oddCnt++;int[] copy = nums.clone();int i = 0, j = oddCnt;for (int num : copy) {if ((num & 0x01) != 0)nums[i++] = num;elsenums[j++] = num;}}
25. 链表中倒数第k个节点
题目描述:
输入一个链表,输出该链表中倒数第K个节点。为了符合大多数人的习惯,本题从1开始计数,即链表的尾节点是倒数第一个节点。
思路:常规的方法是先遍历一次链表,得到链表的长度,然后再从头到尾遍历到n-k+1的地方就行了。但是这个方法显然不是最简单的方法,因为它遍历了两次。
当用一个指针遍历两次才能够完成工作的情况下,往往用两个指针遍历一次就能实现,这就是“双指针法”。这里定义连个指针,第一个指针从头到尾走k-1步,第二个指针保持不动。从第k步开始,第二个指针也从头指针开始遍历,它们之间的距离适中为k-1,当第一个指针走到链表尾部的时候,第二个指针指向的就是倒数第k个节点。
这里需要注意几个问题,保证代码的健壮性:
- 输入的链表为空。
- 输入的链表总的节点数小于k。
- 输入的参数k为0
public static ListNode Solution(ListNode head, int k){if(head == null || k == 0)return null;ListNode ahead = head;ListNode behind = null;for(int i = 0; i < k - 1; i++){if(ahead.next != null)ahead = ahead.next;elsereturn null;}behind = head;while(ahead.next != null){ahead = ahead.next;behind = behind.next;}return behind;}
25.1 相关题目1
题目描述:
求链表的中间节点。如果链表中节点的总数为奇数,返回中间节点;如果为偶数,返回中间两个节点的任意一个。
思路:参考双指针法,定义两个指针,同时从头结点开始遍历,一个指针一次走一步,一个指针一次走两步。当快指针走到链表末尾的时候,走得慢的指针正好在链表的中间。注意程序的健壮性。
public static ListNode findCenterNode(ListNode head){//链表为空或只有头结点if(head == null || head.next == null)return null;//链表只存在一个节点if(head.next.next == null)return head.next;ListNode fast = head;ListNode slow = head;while(fast.next != null){fast = fast.next.next;slow = slow.next;}return slow;}
25.2 相关题目2
题目描述:
判断一个单向链表是否形成了环形结构。
方法1:使用HashSet。设置一个Hashset,顺序读取链表中的节点,判断Hashset中是否有该节点的唯一标识(ID)。如果在Hashset中,说明有环;如果不在Hashset中,将节点的ID存入Hashset。
这种方法时间复杂度已经最优,但是因为额外申请了Hashset,所以空间复杂度不算最优。
//返回true说明没有环,否则说明有环。public static boolean hsCycleOrNot(ListNode head){if(head == null)return true;HashSet<Integer> set = new HashSet<>();ListNode cur = head;while(cur.next != null){if(set.contains(cur.next.value))return false;elseset.add(cur.next.value);cur = cur.next;}return true;}
方法2:使用双指针。定义一个快指针和一个慢指针同时从链表的头结点出发,快指针一次走两步,慢指针一次走一步。如果快指针能够追上慢指针,那么链表就是有环的;如果快指针走到链表末尾都没有追上慢指针,说明没有环。
public static boolean hasCycleOrNot(ListNode head){if(head == null)return true;ListNode fast = head;ListNode slow = head;while(fast.next != null){if(fast.next.next != null)fast = fast.next.next;elsereturn true;if(fast == slow)return false;slow = slow.next;}return true;}
26. 链表中环的入口节点
题目描述:
一个链表中包含环,请找出该链表的环的入口结点。
思路1:使用哈希表。参看上题。
思路2:看下图,如果链表中存在环,且环的长度为k,那么环的入口就是倒数第k个节点。现在,只要求得环的长度,就能够根据前面的链表中倒数第k个节点的思路进行求解,定义两个指针指向头结点,先让第一个指针在链表上移动n步,然后两个指针以相同的速度向前移动,当第二个指针指向环的入口结点时,第一个指针已经围绕着环走了一圈又回到了入口结点。
在前面的题目中判断链表中是否有环的时候,用到一快一慢两个指针,如果两个指针相遇,说明有环,且相遇的结点一定在环内。可以从这个结点出发,一边继续向前移动一边计数,当再次回到这个结点时,就可以得到环中的结点数了。

//找到相遇点public static ListNode meetingNode(ListNode head){if(head == null)return null;ListNode slow = head.next;if(slow == null)return null;ListNode fast = slow.next;while(fast != null && slow != null){if(fast == slow)return fast;slow = slow.next;fast = fast.next;if(fast != null)fast = fast.next;}return null;}public static ListNode findEntryNode(ListNode head){ListNode meetingNode = meetingNode(head);if(meetingNode == null)return null;int nodeInLoop = 1;ListNode node1 = meetingNode;while(node1.next != meetingNode){node1 = node1.next;nodeInLoop++;}node1 = head;for(int i = 0; i < nodeInLoop; i++)node1 = node1.next;ListNode node2 = head;while(node1 != node2){node1 = node1.next;node2 = node2.next;}return node1;}
思路三:不用求得环的长度,只需在相遇时,让一个指针在相遇点出发,另一个指针在链表首部出发,然后两个指针一次走一步,当它们相遇时,就是环的入口处。
证明如下:
- 假设存在环,fast以速度2运行,slow以速度1运行,在slow走到入口t时,如图(m1为在slow首次到t时fast的位置,a为h到t的距离,b为t到m1的距离,n为环的周长):
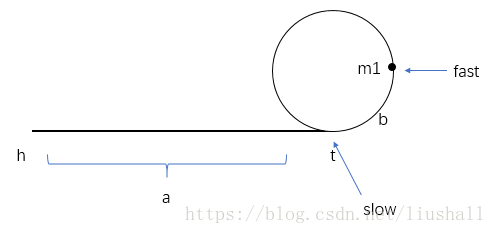
由图知fast走的距离为a+b+xn,slow走的距离为a,又v(fast) = 2*v(slow),所以x(fast) = 2*x(slow),即2a = a+b+xn,因此a = b+xn。
m1逆时针到t的距离为n-b。- 在首次相遇时,如图(m2为相遇点):
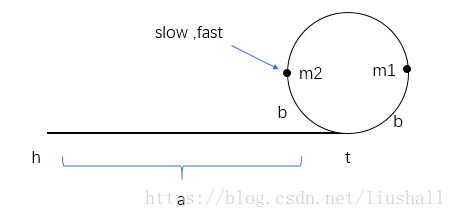
由于m1逆时针到t的距离为n-b,即要达到相遇需要追赶n-b的距离,由于两者速度差为1,因此需要n-b的时间才能相遇,此时slow再次向后n-b距离,即到达m2位置与fast相遇,因为一周长度为n,因此到t的距离为 n-(n-b) = b。- 为何令slow重新从pHead以速度1开始走,令fast从m2以速度1走?要想在入口t相遇,则需要从m2处再走b+xn的距离,刚好pHead处符合(由1)可知),所以令slow从pHead开始走。在相遇后就是入口t的位置。
public static ListNode findEntryNode_1(ListNode head){ListNode meetingNode = meetingNode(head);if(meetingNode == null)return null;ListNode node1 = meetingNode;ListNode node2 = head;while(node1 != node2){node1 = node1.next;node2 = node2.next;}return node1;}
27. 反转链表
题目描述:
定义一个函数,输入一个链表的头结点,反转该链表并输出反转后链表的头结点。
思路一:迭代。
public static ListNode reverseList(ListNode head){ListNode reverseHead = null;ListNode node = head;ListNode preNode = null;while(node != null){ListNode next = node.next;if(next == null)reverseHead = node;node.next = preNode;preNode = node;node = next;}return reverseHead;}
思路二:递归。
public ListNode ReverseList(ListNode head) {if (head == null || head.next == null)return head;ListNode next = head.next;head.next = null;ListNode newHead = ReverseList(next);next.next = head;return newHead;}
28. 合并两个排序的链表
题目描述:
输入两个递增排序的链表,合并这两个链表并使得新链表中的结点仍然是按照递增排序的。
思路一:迭代。
//新建一个链表存放排序后的链表public ListNode Merge(ListNode list1, ListNode list2) {ListNode head = new ListNode(-1);ListNode cur = head;while (list1 != null && list2 != null) {if (list1.val <= list2.val) {cur.next = list1;list1 = list1.next;} else {cur.next = list2;list2 = list2.next;}cur = cur.next;}if (list1 != null)cur.next = list1;if (list2 != null)cur.next = list2;return head.next;}
思路二:递归。
public ListNode Merge(ListNode list1, ListNode list2) {if (list1 == null)return list2;if (list2 == null)return list1;if (list1.val <= list2.val) {list1.next = Merge(list1.next, list2);return list1;} else {list2.next = Merge(list1, list2.next);return list2;}}
29. 树的子结构
题目描述:
输入两个二叉树A和B,判断B是不是A的子结构。
思路:
- 首先我们的思路应该是从二叉树A的根结点开始递归遍历整棵树,每访问到一个结点,都要检查当前结点是否已经是子树的开始结点,否则传入该结点的左右孩子继续检查
- 在判断当前结点是否已经是子树的开始结点时,首先判断结点值是否相等,相等的话再判断各自的左右孩子是否也对应相等(此时要注意,子树可以先为空,但二叉树A不能先为空)
public boolean HasSubtree(TreeNode root1, TreeNode root2) {if(root1 == null || root2 == null)return false;//要么当前结点已经是子树 要么当前结点的左孩子或右孩子存在子树return IsSubtree(root1,root2) || HasSubtree(root1.left,root2) || HasSubtree(root1.right,root2);}public boolean IsSubtree(TreeNode root1,TreeNode root2){if(root2 == null)return true;if(root1 == null)return false;if(root1.val == root2.val)return IsSubtree(root1.left,root2.left) && IsSubtree(root1.right,root2.right);elsereturn false;}
30. 二叉树的镜像
题目描述:
请完成一个函数,输入一个二叉树,输出该二叉树的镜像。
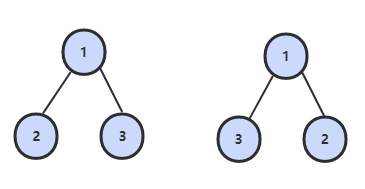
思路一:使用递归。先前序遍历树的每个节点,如果遍历到的节点有子节点,就交换它的两个子节点,当交换玩素有的非叶子结点的左右子节点知乎,就得到了树的镜像。
//递归public static void mirrorBiTreeRecursively(BiTreeNode root){if(root == null)return;if(root.getLeft() == null && root.getRight() == null)return;BiTreeNode node = root.getLeft();root.setLeft(root.getRight());root.setRight(node);if(root.getLeft() != null)mirrorBiTreeRecursively(root.getLeft());if(root.getRight() != null)mirrorBiTreeRecursively(root.getRight());}
思路二:非递归,使用栈。层次遍历,根节点不为 null 将根节点入队,判断队不为空时,节点出队,交换该节点的左右孩子,如果左右孩子不为空,将左右孩子入队。
//迭代。层次遍历public static void mirrorBiTreeLevel(BiTreeNode root){if(root == null)return;if(root.getLeft() == null && root.getRight() == null)return;Stack<BiTreeNode> stack = new Stack<>();stack.push(root);while(!stack.isEmpty()){BiTreeNode node = stack.pop();swapSonNode(node);if(node.getRight() != null)stack.push(node.getRight());if(node.getLeft() != null)stack.push(node.getLeft());}}public static void swapSonNode(BiTreeNode root){BiTreeNode node = root.getLeft();root.setLeft(root.getRight());root.setRight(node);}
树的节点结构如下:
public class BiTreeNode {private int value;private BiTreeNode left;private BiTreeNode right;public BiTreeNode(){}public BiTreeNode(int value){this.value = value;}public BiTreeNode(int value, BiTreeNode left, BiTreeNode right){this.value = value;this.left = left;this.right = right;}public int getValue() {return value;}public void setValue(int value) {this.value = value;}public BiTreeNode getLeft() {return left;}public void setLeft(BiTreeNode left) {this.left = left;}public BiTreeNode getRight() {return right;}public void setRight(BiTreeNode right) {this.right = right;}}
31. 二叉树的镜像
题目描述:
请实现一个函数,用来判断一棵二叉树是不是对称的。如果一棵二叉树和它的镜像一样,他就是对称的。
思路:可以通过比较二叉树的前序遍历序列和对称前序遍历序列(即先遍历父节点,然后右子树,最后左子树)来判断二叉树是不是对称的。
public static boolean isSymmetrical(BiTreeNode root1, BiTreeNode root2){if(root1 == null && root2 == null)return true;if(root1 == null || root2 == null)return false;if(root1.getValue() != root2.getValue())return false;return isSymmetrical(root1.getLeft(), root2.getRight()) &&isSymmetrical(root1.getRight(), root2.getLeft());}public static boolean isSymmetrical(BiTreeNode root){return isSymmetrical(root.getLeft(), root.getRight());}
32. 顺时针打印矩阵
题目描述:
输入一个矩阵,按照从外向里以顺时针的顺序依次打印出每一个数字。如下矩阵的打印结果为:1, 2, 3, 4, 8, 12, 16, 15, 14, 13, 9, 5, 6, 7, 11, 10
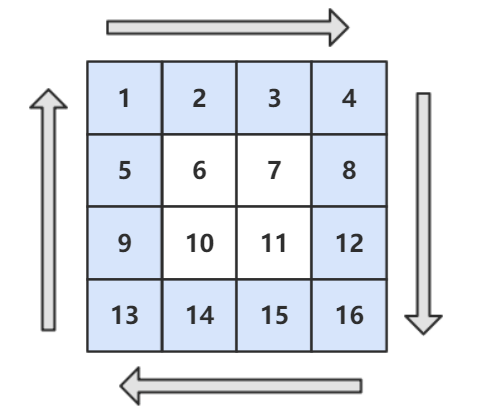
思路:注意边界条件的判断。
public ArrayList<Integer> printMatrix(int[][] matrix) {ArrayList<Integer> ret = new ArrayList<>();int r1 = 0, r2 = matrix.length - 1, c1 = 0, c2 = matrix[0].length - 1;while (r1 <= r2 && c1 <= c2) {for (int i = c1; i <= c2; i++)ret.add(matrix[r1][i]);for (int i = r1 + 1; i <= r2; i++)ret.add(matrix[i][c2]);if (r1 != r2)for (int i = c2 - 1; i >= c1; i--)ret.add(matrix[r2][i]);if (c1 != c2)for (int i = r2 - 1; i > r1; i--)ret.add(matrix[i][c1]);r1++; r2--; c1++; c2--;}return ret;}
33. 包含min函数的栈
题目描述:
定义栈的数据结构,请在该类型中实现一个能够得到栈最小元素的min函数。在该栈中,调用min、push、pop的时间复杂度都是o(1)。
思路:题目要求复杂度为O(1),所以遍历的话肯定满足不了需求,一个想法就是用空间来换取时间。定义一个辅助栈来存放最小值。
栈 3,4,2,5,1
辅助栈 3,3,2,2,1
每入栈一次,就与辅助栈顶比较大小,如果小就入栈,如果大就入栈当前的辅助栈顶
当出栈时,辅助栈也要出栈
这种做法可以保证辅助栈顶一定都当前栈的最小值
private Stack<Integer> dataStack = new Stack<>();private Stack<Integer> minStack = new Stack<>();public void push(int data){dataStack.push(data);minStack.push(minStack.isEmpty() ? data : Math.min(data, minStack.peek()));}public void pop(){if(!dataStack.isEmpty() && !minStack.isEmpty()){dataStack.pop();minStack.pop();}}public int top(){if(!dataStack.isEmpty())return dataStack.peek();return -1;}public int min(){if(!minStack.isEmpty())return minStack.peek();return -1;}
另一种思路,只使用一个栈。
Stack<Integer> stack;int min = Integer.MAX_VALUE;public MinStack() {stack = new Stack<>();}public void push(int x) {if(x <= min){stack.push(min);min = x;}stack.push(x);}public void pop() {if(stack.pop() == min)min = stack.pop();}public int top() {return stack.peek();}public int getMin() {return min;}
34. 栈的压入、弹出序列
题目描述:
输入两个整数序列,第一个序列表示栈的压入顺序,请判断第二个序列是否为该栈的弹出顺序。假设压入栈的所有数字均不相等。
例如序列 1,2,3,4,5 是某栈的压入顺序,序列 4,5,3,2,1 是该压栈序列对应的一个弹出序列,但 4,3,5,1,2 就不可能是该压栈序列的弹出序列。
思路:使用一个栈来模拟压入弹出操作。按照入栈的顺序将元素压入模拟栈中,每压入一个元素,都要将当前栈顶元素和下一个出栈数字比较,如果相等,直接弹出;如果不相等,把压栈顺序中还没有入栈的数字压入模拟栈,知道把下一个需要弹出的数字压入栈顶位置。如果所有的数字都压入栈了仍然没有找到下一个弹出数字,那么该序列不可能是一个弹栈序列。
public static boolean isAPopOrder(int[] pushSequence, int[] popSequence){if(pushSequence == null || popSequence == null)return false;Stack<Integer> stack = new Stack<>();int n = pushSequence.length;for(int pushInx = 0, popInx = 0; pushInx < n; pushInx++){stack.push(pushSequence[pushInx]);while(popInx < n && !stack.isEmpty() && stack.peek() == popSequence[popInx]){stack.pop();popInx++;}}return stack.isEmpty();}
35. 从上往下打印二叉树
题目描述:
从上往下打印出二叉树的每个节点,同层节点从左至右打印。
思路:二叉树的层次遍历。
public static void levelOrder(BiTreeNode root){Queue<BiTreeNode> queue = new LinkedList<>();BiTreeNode temp;if(root != null)queue.offer(root);while(!queue.isEmpty()){temp = queue.poll();System.out.print(temp.getValue()+" ");if(null != temp.getLeft())queue.offer(temp.getLeft());if(null != temp.getRight())queue.offer(temp.getRight());}}
36. 把二叉树打印成多行
题目描述:
从上到下按层打印二叉树,同一层的节点按从左到右的顺序打印,每一层打印到一行。
思路:和上一个题差不多,再定义两个变量toBePrinted和nextLevel,前者表示本层中还需打印的节点数,后者表示下一层的节点数。
public static void printWithMultiline(BiTreeNode root){Queue<BiTreeNode> queue = new LinkedList<>();BiTreeNode temp;int nextLevel = 0; //下一层需要打印的节点数int toBePrinted = 1; //本层还需要打印的节点数if(root != null)queue.offer(root);while(!queue.isEmpty()){temp = queue.poll();System.out.print(temp.getValue()+" ");if(null != temp.getLeft()){nextLevel++;queue.offer(temp.getLeft());}if(null != temp.getRight()){nextLevel++;queue.offer(temp.getRight());}toBePrinted--;if(toBePrinted == 0){System.out.println();toBePrinted = nextLevel;nextLevel = 0;}}}
另一种选择,不打印,而是存储起来。
ArrayList<ArrayList<Integer>> Print(TreeNode pRoot) {ArrayList<ArrayList<Integer>> ret = new ArrayList<>();Queue<TreeNode> queue = new LinkedList<>();queue.add(pRoot);while (!queue.isEmpty()) {ArrayList<Integer> list = new ArrayList<>();int cnt = queue.size();while (cnt-- > 0) {TreeNode node = queue.poll();if (node == null)continue;list.add(node.val);queue.add(node.left);queue.add(node.right);}if (list.size() != 0)ret.add(list);}return ret;}
37. 按之字形顺序打印二叉树
题目描述:
请实现一个函数按照之字形打印二叉树,即第一层按照从左到右的顺序打印,第二层按照从右至左的顺序打印,第三层按照从左到右的顺序打印,其他行以此类推。
思路一:使用两个栈。在打印某一行的结点时,把下一层的子节点保存到响应的栈里。如果当前打印的是奇数层,则先保存左子结点再保存右子结点到第一个栈里;如果当前打印的是偶数层,则先保存右子结点再保存左子结点到第二个栈里。
//用栈实现public static void printMultiline(BiTreeNode root){if(root == null)return;Stack<BiTreeNode>[] levels = new Stack[2];//注意:如果没有下面三行的话,levels[current].push(root);会报空指针异常,//因为只是定义了一个存放Stack的容器,并没有对其进行初始化Stack<BiTreeNode> stack1 = new Stack<>();Stack<BiTreeNode> stack2 = new Stack<>();levels[0] = stack1;levels[1] = stack2;int current = 0;int next = 1;levels[current].push(root);while(!levels[0].isEmpty() || !levels[1].isEmpty()){BiTreeNode node = levels[current].peek();levels[current].pop();System.out.print(node.getValue()+" ");if(current == 0){if(node.getLeft() != null)levels[next].push(node.getLeft());if(node.getRight() != null)levels[next].push(node.getRight());}else {if(node.getRight() != null)levels[next].push(node.getRight());if(node.getLeft() != null)levels[next].push(node.getLeft());}if(levels[current].isEmpty()){System.out.println();current = 1 - current;next = 1 - next;}}}
思路二:使用一个队列加一个ArrayList,调用Collections的reverse()方法对ArrayList中的元素进行翻。
public ArrayList<ArrayList<Integer>> Print(TreeNode pRoot) {ArrayList<ArrayList<Integer>> ret = new ArrayList<>();Queue<TreeNode> queue = new LinkedList<>();queue.add(pRoot);boolean reverse = false;while (!queue.isEmpty()) {ArrayList<Integer> list = new ArrayList<>();int cnt = queue.size();while (cnt-- > 0) {TreeNode node = queue.poll();if (node == null)continue;list.add(node.val);queue.add(node.left);queue.add(node.right);}if (reverse)Collections.reverse(list);reverse = !reverse;if (list.size() != 0)ret.add(list);}return ret;}
38. 二叉搜索树的后序遍历序列
题目描述:
输入一个整数数组,判断该数组是不是某二叉搜索树的后序遍历的结果。如果是则输出Yes,否则输出No。假设输入的数组的任意两个数字都互不相同。
在后序遍历序列中,最后一个数字是树的根节点的值。数组中前面的数字可以分为两部分:第一部分是左子树节点的值,它们都比根节点的值小;第二部分是右子树节点的值,它们都比根节点的值大。
所以先取数组中最后一个数,作为根节点。然后从数组开始计数比根节点小的数,并将这些记作左子树,然后判断后序的树是否比根节点大,如果有点不满足,则跳出,并判断为不成立。全满足的话,依次对左子树和右子树递归判断。
public static boolean VerifySquenceOfBST(int[] sequence) {if (sequence == null || sequence.length == 0)return false;return verify(sequence, 0, sequence.length - 1);}private static boolean verify(int[] sequence, int first, int last) {//递归终止条件if (last - first <= 1)return true;int rootVal = sequence[last];int cutIndex = first;while (cutIndex < last && sequence[cutIndex] <= rootVal)cutIndex++;for (int i = cutIndex; i < last; i++)if (sequence[i] < rootVal)return false;return verify(sequence, first, cutIndex - 1) && verify(sequence, cutIndex, last - 1);}
39. 二叉树中和为某一值的路径
题目描述:
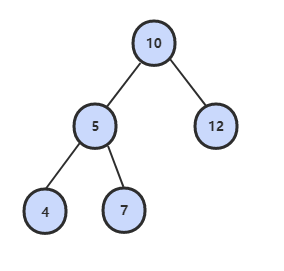
输入一颗二叉树和一个整数,打印出二叉树中结点值的和为输入整数的所有路径。路径定义为从树的根结点开始往下一直到叶结点所经过的结点形成一条路径。
下图的二叉树有两条和为 22 的路径:10, 5, 7 和 10, 12
思路一:当用前序遍历的方式访问到某一节点时,我们把该结点添加到路径上,并累加该结点的值。如果该结点为叶结点并且路径中结点值的和刚好为输入的整数,则当前的路径符合要求,我们把它打印出来。如果当前的结点不是叶结点,则继续访问它的子节点。当前结点访问结束后,递归函数将自动回到它的父节点。因此我们在函数退出之前要在路径上删除当前结点并减去当前结点的值,以确保返回父节点时路径刚好是从根节点到父节点的路径。我们不难看出保存路径的数据结构实际上是一个栈,因此路径要与递归调用状态一致,而递归调用的本质上是一个压栈和出栈的过程。
static Stack<Integer> path = new Stack<>();public static void findPath(BiTreeNode root, int sum){backtracking(root, sum, path);}public static void backtracking(BiTreeNode root, int target, Stack<Integer> stack){if(root == null)return;stack.push(root.getValue());target -= root.getValue();//符合条件就将路径输出if(target == 0 && root.getLeft() == null && root.getRight() == null){System.out.println("A path is found:");for(Integer i : stack)System.out.print(i+" ");System.out.println();}//如果不是叶子节点,则遍历它的子节点if(root.getLeft() != null)backtracking(root.getLeft(), target, stack);if(root.getRight() != null)backtracking(root.getRight(), target, stack);//返回父节点之前在路径上删除当前节点stack.pop();}
思路二:和思路一样,不过实现过程使用ArrayList。
private ArrayList<ArrayList<Integer>> ret = new ArrayList<>();public ArrayList<ArrayList<Integer>> FindPath(TreeNode root, int target) {backtracking(root, target, new ArrayList<>());return ret;}private void backtracking(TreeNode node, int target, ArrayList<Integer> path) {if (node == null)return;path.add(node.val);target -= node.val;if (target == 0 && node.left == null && node.right == null) {ret.add(new ArrayList<>(path));} else {backtracking(node.left, target, path);backtracking(node.right, target, path);}path.remove(path.size() - 1);}
40. 复杂链表的复制
题目描述:
输入一个复杂链表(每个节点中有节点值,以及两个指针,一个指向下一个节点,另一个特殊指针指向任意一个节点),返回结果为复制后复杂链表的 head。链表结构定义如下:
class RandomListNode{int value;RandomListNode next;RandomListNode random;public RandomListNode(int value) {this.value = value;}}
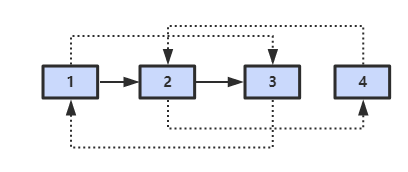
思路一:分为两步:
- 第一步是复制原始链表上的每个结点N创建N',然后把这些创建出来的结点用next链接起来。同时我们把的配对信息放到一个哈希表中。
- 第二步还是设置复制链表上的每个结点的random。如果在原始链表中结点N的random指向结点S,那么在复制链表中,对应的N'应该指向S'。由于有了哈希表,我们可以在O(1)的时间根据S找到S’。
public static RandomListNode cloneRandomList(RandomListNode root){if(root == null)return null;HashMap<RandomListNode, RandomListNode> map = new HashMap<>();RandomListNode cloneRoot = new RandomListNode(root.value);RandomListNode node = root, cloneNode = cloneRoot;map.put(node, cloneNode);while(node.next != null){cloneNode.next = new RandomListNode(node.next.value);node = node.next;cloneNode = cloneNode.next;map.put(node, cloneNode);}node = root;cloneNode = cloneRoot;while(cloneNode != null){cloneNode.random = map.get(node.random);node = node.next;cloneNode = cloneNode.next;}return cloneRoot;}
思路二:分为三步:
- 第一步:根据原始链表的每个结点N创建对应的N'。不过我们把N’链接在N的后面。
- 第二步:设置复制出来的结点的random。原始链表上的A的random指向结点C,那么其对应复制出来的A’是A的next指向的结点,同样C’也是C的next指向的结点。即A' = A.next,A'.random = A.random.next;故像这样就可以把每个结点的random设置完毕。
- 第三步:将这个长链表拆分成两个链表:把奇数位置的结点用next链接起来就是原始链表,把偶数位置的结点用next链接起来就是复制出来的链表。
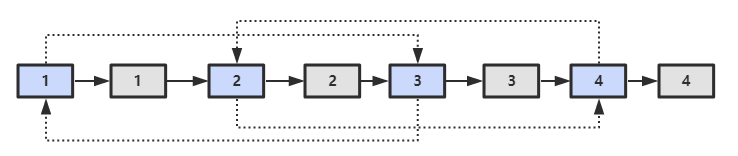
public static RandomListNode cloneRandomList(RandomListNode pHead) {if (pHead == null)return null;// 插入新节点RandomListNode cur = pHead;while (cur != null) {RandomListNode clone = new RandomListNode(cur.value);clone.next = cur.next;cur.next = clone;cur = clone.next;}// 建立 random 链接cur = pHead;while (cur != null) {RandomListNode clone = cur.next;if (cur.random != null)clone.random = cur.random.next;cur = clone.next;}// 拆分cur = pHead;RandomListNode pCloneHead = pHead.next;while (cur.next != null) {RandomListNode next = cur.next;cur.next = next.next;cur = next;}return pCloneHead;}
41. 二叉搜索树与双向链表
题目描述:
输入一棵二叉搜索树,将该二叉搜索树转换成一个排序的双向链表。要求不能创建任何新的结点,只能调整树中结点指针的指向。
思路一:由于要求转化后的链表是一个排序的链表,而二叉搜索树的中序遍历结果是排序的,所以自然而然想到> 中序遍历二叉树的方法,而遍历最简单的方法就是递归。步骤如下:
- 将左子树构造成双链表,并返回链表头节点。
- 定位至左子树双链表最后一个节点。
- 如果左子树链表不为空的话,将当前root追加到左子树链表。
- 将右子树构造成双链表,并返回链表头节点。
- 如果右子树链表不为空的话,将该链表追加到root节点之后。
- 根据左子树链表是否为空确定返回的节点。
public static BiTreeNode Convert(BiTreeNode root) {if(root==null)return null;if(root.getLeft()==null&&root.getRight()==null)return root;// 1.将左子树构造成双链表,并返回链表头节点BiTreeNode left = Convert(root.getLeft());BiTreeNode p = left;// 2.定位至左子树双链表最后一个节点while(p!=null&&p.getRight()!=null){p = p.getRight();}// 3.如果左子树链表不为空的话,将当前root追加到左子树链表if(left!=null){p.setRight(root);root.setLeft(p);}// 4.将右子树构造成双链表,并返回链表头节点BiTreeNode right = Convert(root.getRight());// 5.如果右子树链表不为空的话,将该链表追加到root节点之后if(right!=null){right.setLeft(root);root.setRight(right);}return left!=null?left:root;}
思路二:改进递归版。思路与方法二中的递归版一致,仅对第2点中的定位作了修改,新增一个全局变量记录左子树的最后一个节点。
// 记录子树链表的最后一个节点,终结点只可能为只含左子树的非叶节点与叶节点protected static BiTreeNode leftLast = null;public static BiTreeNode Convert_1(BiTreeNode root) {if(root==null)return null;if(root.getLeft()==null&&root.getRight()==null){leftLast = root;// 最后的一个节点可能为最右侧的叶节点return root;}// 1.将左子树构造成双链表,并返回链表头节点BiTreeNode left = Convert_1(root.getLeft());// 3.如果左子树链表不为空的话,将当前root追加到左子树链表if(left!=null){leftLast.setRight(root);root.setLeft(leftLast);}leftLast = root;// 当根节点只含左子树时,则该根节点为最后一个节点// 4.将右子树构造成双链表,并返回链表头节点BiTreeNode right = Convert_1(root.getRight());// 5.如果右子树链表不为空的话,将该链表追加到root节点之后if(right!=null){right.setLeft(root);root.setRight(right);}return left!=null?left:root;}
思路三:递归简化版,直接用中序遍历。
static BiTreeNode head = null;static BiTreeNode realHead = null;public static BiTreeNode Convert(BiTreeNode pRootOfTree) {ConvertSub(pRootOfTree);return realHead;}private static void ConvertSub(BiTreeNode pRootOfTree) {if(pRootOfTree==null) return;ConvertSub(pRootOfTree.getLeft());if (head == null) {head = pRootOfTree;realHead = pRootOfTree;} else {head.setRight(pRootOfTree);pRootOfTree.setLeft(head);head = pRootOfTree;}ConvertSub(pRootOfTree.getRight());}
思路四:非递归版。中序遍历既可以使用递归实现也可以使用非递归实现。
public static BiTreeNode ConvertBSTToBiList(BiTreeNode root) {if(root==null)return null;Stack<BiTreeNode> stack = new Stack<BiTreeNode>();BiTreeNode p = root;BiTreeNode pre = null;// 用于保存中序遍历序列的上一节点boolean isFirst = true;while(p != null || !stack.isEmpty()){while(p != null){stack.push(p);p = p.getLeft();}p = stack.pop();if(isFirst){root = p;// 将中序遍历序列中的第一个节点记为rootpre = root;isFirst = false;}else{pre.setRight(p);p.setLeft(pre);pre = p;}p = p.getRight();}return root;}
42. 序列化二叉树
题目描述:
请实现两个函数,分别用来序列化和反序列化二叉树
思路:序列化的过程其实就是前序遍历的过程,将二叉树序列化为一个字符串,null节点用特殊字符(比如#来代替);反序列化的过程其实就是先序构建二叉树的过程,将序列化后字符串中的字符依次读入,就可以构建成一个二叉树。
/*** 序列化*///递归法序列化private static void serializeBiTree(BiTreeNode root, StringBuilder sb){if(root == null){sb.append("# ");return;}sb.append(root.getValue());serializeBiTree(root.getLeft(), sb);serializeBiTree(root.getRight(), sb);}public static String serializeBiTree(BiTreeNode root){StringBuilder sb = new StringBuilder("");serializeBiTree(root, sb);return sb.toString();}//非递归法序列化private static void nrSerializeBiTree(BiTreeNode root, StringBuilder sb){if(root == null)return;Stack<BiTreeNode> stack = new Stack<>();BiTreeNode pNode = root;stack.push(pNode);while(!stack.isEmpty()){BiTreeNode temp = stack.pop();if(temp == null)sb.append("# ");else {sb.append(temp.getValue()).append(" ");nrSerializeBiTree(root.getLeft(), sb);nrSerializeBiTree(root.getRight(), sb);}}}
/*** 反序列化*///递归法反序列化private String deserializeStr;public BiTreeNode deserialize(String str) {deserializeStr = str;return deserialize();}private BiTreeNode deserialize() {if (deserializeStr.length() == 0)return null;int index = deserializeStr.indexOf(" ");String node = index == -1 ? deserializeStr : deserializeStr.substring(0, index);deserializeStr = index == -1 ? "" : deserializeStr.substring(index + 1);if (node.equals("#"))return null;int val = Integer.valueOf(node);BiTreeNode t = new BiTreeNode(val);t.setLeft(deserialize());t.setRight(deserialize());return t;}
43. 字符串的排列
题目描述:
输入一个字符串,按字典序打印出该字符串中字符的所有排列。例如输入字符串 abc,则打印出由字符 a, b, c 所能排列出来的所有字符串 abc, acb, bac, bca, cab 和 cba。
思路:字符串的排列问题,可以使用递归来完成,这个之前已经总结过了。但是这个题目的要求是按照字典顺序进行排列,所以需要对输入的字符串数组进行一次排序。
private ArrayList<String> ret = new ArrayList<>();public ArrayList<String> permutation(String str) {if (str.length() == 0)return ret;char[] chars = str.toCharArray();//对输入的数组进行排序Arrays.sort(chars);backtracking(chars, new boolean[chars.length], new StringBuilder());return ret;}private void backtracking(char[] chars, boolean[] hasUsed, StringBuilder s) {if (s.length() == chars.length) {ret.add(s.toString());return;}for (int i = 0; i < chars.length; i++) {if (hasUsed[i])continue;if (i != 0 && chars[i] == chars[i - 1] && !hasUsed[i - 1]) /* 保证不重复 */continue;hasUsed[i] = true;s.append(chars[i]);backtracking(chars, hasUsed, s);s.deleteCharAt(s.length() - 1);hasUsed[i] = false;}}
44. 数组中超过一半的数
题目描述:
题目:数组中有一个数字出现的次数超过数组长度的一半,请找出这个数字。例如输入一个长度为9的数组{1,2,3,2,2,2,5,4,2}。由于数字2在数组中出现5次,超过数组长度的一半,因此输出2
思路一:数组排序,然后中间值肯定是要查找的值。排序最小的时间复杂度(快速排序)O(NlogN),加上遍历。
public static int moreThanHalf(int[] nums){if(nums == null || nums.length <= 0)return 0;Arrays.sort(nums);int result = nums[nums.length >> 1]; //用右移代替除法int count = 0;//判断数组中是不是存在出现次数超过一半的数for(int i : nums){if(i == result)count++;}return count > (nums.length >> 1) ? result : 0;}
思路二:使用散列表的方式,也就是统计每个数组出现的次数,输出出现次数大于数组长度的数字。
public static int moreThanHalf(int[] nums){if(nums == null || nums.length <= 0)return 0;HashMap<Integer, Integer> map = new HashMap<>();for(int i = 0; i < nums.length; i++){if(map.containsKey(nums[i]))map.put(nums[i], map.get(nums[i]) + 1);elsemap.put(nums[i], 1);}for(int key : map.keySet()){if(map.get(key) > (nums.length >> 1))return key;}return 0;}
思路三:出现的次数超过数组长度的一半,表明这个数字出现的次数比其他数出现的次数的总和还多。
考虑每次删除两个不同的数,那么在剩下的数中,出现的次数仍然超过总数的一般,不断重复该过程,排除掉其他的数,最终找到那个出现次数超过一半的数字。这个方法的时间复杂度是O(N),空间复杂度是O(1)。
换个思路,这个可以通过计数实现,而不是真正物理删除。在遍历数组的过程中,保存两个值,一个是数组中数字,一个是出现次数。当遍历到下一个数字时,如果这个数字跟之前保存的数字相同,则次数加1,如果不同,则次数减1。如果次数为0,则保存下一个数字并把次数设置为1,由于我们要找的数字出现的次数比其他所有数字出现的次数之和还要多,那么要找的数字肯定是最后一次把次数设为1时对应的数字。
public static int moreThanHalf(int[] nums){if(nums == null || nums.length <= 0)return 0;int result = nums[0];//如果times==0,说明遍历过的数中,有一半的数是相同的。int times = 1;for(int i = 1; i < nums.length; i++){if(times == 0){result = nums[i];times = 1;}else if(result == nums[i])times++;elsetimes--;}int count = 0;for(int i : nums){if(i == result)count++;}return count > (nums.length >> 1) ? result : 0;}
思路四:排序算法的改进。如果对一个数组进行排序,位于中间位置的那个数字肯定是所求的值。对数组排序的时间复杂度是O(nlog(n)),但是对于这道题目,还有更好的算法,能够在时间复杂度O(n)内求出。
借鉴快速排序算法,其中的Partition()方法是一个最重要的方法,该方法返回一个index,能够保证index位置的数是已排序完成的,在index左边的数都比index所在的数小,在index右边的数都比index所在的数大。那么本题就可以利用这样的思路来解。
通过Partition()返回index,如果index==mid,那么就表明找到了数组的中位数;如果indexmid,表明中位数在[start,index-1]之间。知道最后求得index==mid循环结束。
private static int partition(int[] nums,int start,int end){int pivotkey = nums[start];int origin = start;while(start < end){while(start < end && nums[end] >= pivotkey) end--;while(start < end && nums[start] < pivotkey) start++;swap(nums, start, end);}swap(nums, start, end);swap(nums, origin, end);return end;}private static int[] swap(int[] ints, int x, int y) {int temp = ints[x];ints[x] = ints[y];ints[y] = temp;return ints;}public static int moreThanHalf(int[] nums){if(nums == null || nums.length == 0)return -1;int start = 0;int end = nums.length-1;int index = partition(nums, start, end);int mid = nums.length / 2;while(index != mid){if(index > mid)//如果调整数组以后获得的index大于middle,则继续调整start到index-1区段的数组index = partition(nums, start, index-1);else{//否则调整index+1到end区段的数组index = partition(nums, index+1, end);}}int count = 0;for(int i : nums){if(i == nums[index])count++;}return count > (nums.length >> 1) ? nums[index] : -1;}
45. 最小的K个数
题目描述:
输入n数字,找出其中最小k个数字,例如输入4,5,1,6,2,7,3,8这8个数字,则最小的4个数字是1,2,3,4
思路一:最容易想到的方法就是全排序,然后取前K个数,但是这显然不是最简单的方法。借鉴快速排序的思想,快速排序的 partition() 方法,会返回一个整数 j 使得 a[l..j-1] 小于等于 a[j],且 a[j+1..h] 大于等于 a[j],此时 a[j] 就是数组的第 j 大元素。可以利用这个特性找出数组的第 K 个元素。复杂度:O(N) + O(1)
且只有当允许修改数组元素时才可以使用。
public ArrayList<Integer> GetLeastNumbers_Solution(int[] nums, int k) {ArrayList<Integer> ret = new ArrayList<>();if (k > nums.length || k <= 0)return ret;findKthSmallest(nums, k - 1);/* findKthSmallest 会改变数组,使得前 k 个数都是最小的 k 个数 */for (int i = 0; i < k; i++)ret.add(nums[i]);return ret;}public void findKthSmallest(int[] nums, int k) {int l = 0, h = nums.length - 1;while (l < h) {int j = partition(nums, l, h);if (j == k)break;if (j > k)h = j - 1;elsel = j + 1;}}private int partition(int[] nums, int l, int h) {int p = nums[l]; /* 切分元素 */int i = l, j = h + 1;while (true) {while (i != h && nums[++i] < p) ;while (j != l && nums[--j] > p) ;if (i >= j)break;swap(nums, i, j);}swap(nums, l, j);return j;}private void swap(int[] nums, int i, int j) {int t = nums[i];nums[i] = nums[j];nums[j] = t;}
思路二:使用堆。构建一个大小为K的大顶堆,堆不满时,就往堆里放数据;当堆满,放数据之前要和堆顶元素比较,如果大于堆顶元素就不放,否则取出堆顶元素,并将新元素放入。时间复杂度为O(nlogk)。
public ArrayList<Integer> GetLeastNumbers_Solution(int[] input, int k) {ArrayList<Integer> result = new ArrayList<Integer>();int length = input.length;if(k > length || k == 0){return result;}PriorityQueue<Integer> maxHeap = new PriorityQueue<Integer>(k, new Comparator<Integer>() {@Overridepublic int compare(Integer o1, Integer o2) {return o2.compareTo(o1);}});for (int i = 0; i < length; i++) {if (maxHeap.size() != k) {maxHeap.offer(input[i]);} else if (maxHeap.peek() > input[i]) {Integer temp = maxHeap.poll();temp = null;maxHeap.offer(input[i]);}}for (Integer integer : maxHeap) {result.add(integer);}return result;}
思路三:使用红黑树(java可以使用TreeSet实现),和使用堆的思想一样。
public ArrayList<Integer> GetLeastKNumbers(int[] input, int k) {ArrayList<Integer> result = new ArrayList<>();TreeSet<Integer> treeset = new TreeSet<>();treeset.clear();if(input == null || input.length == 0)return null;if (k < 1 || input.length < k)return result;for (int i = 0; i < input.length; i++) {if (treeset.size() < k)treeset.add(input[i]);else {int a = treeset.last();if (input[i] < a) {treeset.remove(a);treeset.add(input[i]);}}}Iterator<Integer> it = treeset.iterator();while (it.hasNext()) {result.add(it.next());}return result;}
46. 数据流的中位数
题目描述:
如何得到一个数据流中的中位数?如果从数据流中读出奇数个数值,那么中位数就是所有数值排序之后位于中间的数值。如果从数据流中读出偶数个数值,那么中位数就是所有数值排序之后中间两个数的平均值。
思路:用两个推保存数据,保持两个堆的数据保持平衡(元素个数相差不超过1)。大顶堆存放的数据要比小顶堆的数据小。当两个推中元素为奇数个,将新加入元素加入到大顶堆,如果要加入的数据,比小顶堆的最小元素大,先将该元素插入小顶堆,然后将小顶堆的最小元素插入到大顶堆。当两个推中元素为偶数个,将新加入元素加入到小顶堆,如果要加入的数据,比大顶堆的最大元素小,先将该元素插入大顶堆,然后将大顶堆的最大元素插入到小顶堆。
//右边是小顶堆private static PriorityQueue<Integer> minHeap = new PriorityQueue<>();//左边是大顶堆,右半边元素全部大于左半边元素。private static PriorityQueue<Integer> maxHeap = new PriorityQueue<>(15, new Comparator<Integer>() {@Overridepublic int compare(Integer o1, Integer o2) {return o2 - o1;}});//当前数据流中读入的元素个数private static int count = 0;public static void insert(int value){if((count & 0x01) == 0){/* count 为偶数的情况下插入到右半边。* 因为右半边元素都要大于左半边,但是新插入的元素不一定比左半边元素来的大,* 因此需要先将元素插入左半边,然后利用左半边为大顶堆的特点,取出堆顶元素即为最大元素,此时插入右半边 */maxHeap.add(value);minHeap.add(maxHeap.poll());}else {minHeap.add(value);maxHeap.add(minHeap.poll());}count++;}public static double getMidian(){if((count & 0x01) == 0)return (minHeap.peek() + maxHeap.peek()) / 2.0; //偶数个,返回平均数elsereturn (double)minHeap.peek(); //奇数个,返回小顶堆堆顶元素。因为一开始先插入的是小顶堆,小顶堆多一个元素}
47. 连续子数组的最大和
题目描述:
{6, -3, -2, 7, -15, 1, 2, 2},连续子数组的最大和为 8(从第 0 个开始,到第 3 个为止)。
思路一:累加法。首先,我们需要定义一个变量curSum,用for循环来记录前i项的和,curSum每次都会更改,如果curSum的值小于0,我们再往后加只有减小最大和,所以我们需要将array[i+1]项的值重新赋值给curSum。
另外,我们需要定义一个最大值greatestSum,每次改变curSum的值时,我们都需要将greatestSum和curSum进行比较,如果curSum大于greatestSum,我们则将curSum的值赋值给greatestSum。
public static int greatestSumOfSubArray(int[] nums){if(nums == null || nums.length <= 0){System.out.println("Invalid input");return -1;}int curSum = 0;//0x80000000 = -2147483648int greatestSum = 0x80000000;for(int i = 0; i < nums.length; i++){if(curSum <= 0)curSum = nums[i];elsecurSum += nums[i];if(curSum > greatestSum)greatestSum = curSum;}return greatestSum;}
思路二:分治法。考虑将数组从中间分为两个子数组,则最大子数组必然出现在以下三种情况之一:
1、完全位于左边的数组中。
2、完全位于右边的数组中。
3、跨越中点,包含左右数组中靠近中点的部分。 递归将左右子数组再分别分成两个数组,直到子数组中只含有一个元素,退出每层递归前,返回上面三种情况中的最大值。
public static int greatestSum(int[] nums){return greatestSumSub(nums, 0, nums.length - 1);}private static int greatestSumSub(int[] nums, int left, int right){if(nums == null || nums.length < 0)return -1;if(left == right)return Math.max(0, nums[left]);int maxLeftSum = 0, maxRightSum = 0; //左右边不包含中间的最大和int maxLeftBorderSum = 0, maxRightBorderSum = 0; //包含中间边界的左右边最大和int curLeftBorderSum = 0, curRightBorderSum = 0; //包含中间边界的左右边当前和//求含中间边界的左右部分的最大值int mid = (left + right) >> 1;for(int i = mid; i >= left; i--){curLeftBorderSum += nums[i];maxLeftBorderSum = Math.max(curLeftBorderSum, maxLeftBorderSum);}for(int i = mid + 1; i <= right; i++){curRightBorderSum += nums[i];maxRightBorderSum = Math.max(curRightBorderSum, maxRightBorderSum);}//递归求左右部分最大值maxLeftSum = greatestSumSub(nums, left, mid);maxRightSum = greatestSumSub(nums, mid + 1, right);//返回三者中的最大值return maxOfThree(maxLeftSum, maxRightSum, maxLeftBorderSum + maxRightBorderSum);}private static int maxOfThree(int a, int b, int c){int max = a;if(b > max)max = b;if(c > max)max = c;return max;}
48. 从 1 到 n 整数中 1 出现的次数
题目描述:
输入一个整数n,求1到n这n个整数的十进制表示中1出现的次数。例如输入12,从1到12这些整数中包含1的数字有1,10,11,12,1一共出现了5次。
思路一:不考虑时间效率的做法。循环查找1~n中每一个数的每一位。如果输入数字为n,n有O(logn)位,该算法的时间复杂度为O(n*logn)。
public static int numOfOneFrom1ToN(int n){int number = 0;//检查不大于n的所有整数for(int i = 1; i <= n; i++)number += numOf1(i);return number;}private static int numOf1(int n){int number = 0;//检查数的每一位是不是为1while (n != 0) {if ((n % 10) == 1)number++;n /= 10;}return number;}
思路二:分析数字的规律。考虑将n的十进制的每一位单独拿出讨论,每一位的值记为weight。
- 个位:从1到n,每增加1,weight就会加1,当weight加到9时,再加1又会回到0重新开始。那么weight从0-9的这种周期会出现多少次呢?这取决于n的高位是多少,看图:
以534为例,在从1增长到n的过程中,534的个位从0-9变化了53次,记为round。每一轮变化中,1在个位出现一次,所以一共出现了53次。
再来看weight的值。weight为4,大于0,说明第54轮变化是从0-4,1又出现了1次。我们记1出现的次数为count,所以:
count = round+1 = 53 + 1 = 54
如果此时weight为0(n=530),说明第54轮到0就停止了,那么:
count = round = 53- 十位:对于10位来说,其0-9周期的出现次数与个位的统计方式是相同的,见图:
不同点在于:从1到n,每增加10,十位的weight才会增加1,所以,如果十位出现1,就会连续出现10次,并且,只有当个位数从0到9变化10圈,即个位数加100次,十位才得到一次出现1的机会。所以,十位出现1的次数为(534 / 100 * 10),即(5 / 100 *10),也即round * 10。
再来看weight的值。当此时weight为3,大于1,说明第6轮出现了10次1,则:
count = round*10+10 = 5*10+10 = 60
如果此时weight的值等于0(n=504),说明第6轮到0就停止了,所以:
count = round*10+10 = 5*10 = 50
如果此时weight的值等于1(n=514),那么第6轮中1出现了多少次呢?很明显,这与个位数的值有关,个位数为k,第6轮中1就出现了k+1次(可以把0~534的数字依次打印出来,比较容易找规律)。我们记个位数为former,则:
count = round*10+former +1= 5*10+4 = 55- 更高位:更高位的计算方式其实与十位是一致的,不再阐述。
- 总结:
将n的各个位分为两类:个位与其它位。
对个位来说:
- 若个位大于0,1出现的次数为round*1+1
- 若个位等于0,1出现的次数为round*1
对其它位来说,记每一位的权值为base,位值为weight,该位之前的数是former,举例如图:
则:- 若weight为0,则1出现次数为round*base
- 若weight为1,则1出现次数为round*base+former+1
- 若weight大于1,则1出现次数为rount*base+base
参考:https://blog.csdn.net/yi_afly/article/details/52012593
public static int numOfOneFrom1ToN(int n){if(n < 1)return 0;int count = 0;int base = 1;int round = n;while(round > 0){int weight = round % 10;round /= 10;count += round * base;if(weight == 1)count+=(n % base) + 1;else if(weight > 1)count += base;base *= 10;}return count;}
思路三:也是分析规律,不过代码更简洁。参考:https://www.cnblogs.com/xuanxufeng/p/6854105.html。后面细看。
public int NumberOf1Between1AndN_Solution(int n) {int cnt = 0;for (int m = 1; m <= n; m *= 10) {int a = n / m, b = n % m;cnt += (a + 8) / 10 * m + (a % 10 == 1 ? b + 1 : 0);}return cnt;}
49. 数字序列中的某一位数字
题目描述:
数字以0123456789101112131415…的格式序列化到一个字符序列中。在这个序列中,第5位(从0开始计数)是5,第13位是1,第19位是4,等等。请写一个函数求任意位对应的数字。
思路:举例分析,比如找第1001位数字,
- 1位数的数值有10个:0~9,数字为10×1=10个,显然1001>10,跳过这10个数值,在后面找第991(1001-10)位数字。
- 2位数的数值有90个:10~99,数字为90×2=180个,且991>180,继续在后面找第811(991-180)位数字。
- 3位数的数值有900个:100~999,数字为900×3=2700个,且811<2700,说明第811位数字在位数为3的数值中。由于811=270×3+1,所以第811位是从100开始的第270个数值即370的第二个数字,就是7。
按此规律,可求出其他数字。时间复杂度为O(logn)。
private static int digitAtIndex(int index){if (index < 0) return -1;int digits = 1;while (true){int digitNumbers = countOfNumbersFor(digits); //当前位数的数值个数//数值乘上它的位数等于数字个数,//比如,两位数有90个(10~99),每个数值有2个数字,总数字个数为180int countOfNumbers = digitNumbers * digits;if (index < countOfNumbers){return digitAtIndex(index, digits);} else{//在下一位中查找index -= countOfNumbers;digits++;}}}//digits位数的数字个数,//两位数有9*10=90个(10~99),三位数有9*100=900个(100~999)private static int countOfNumbersFor(int digits){if (digits == 1)return 10;int count = (int) Math.pow(10, digits - 1);return 9 * count;}private static int digitAtIndex(int index, int digits){//对应的数值int number = beginNumberFor(digits) + index / digits;//从数值右边开始算的位置int indexFromRight = digits - index % digits;//去除右边的indexFromRight-1个数字for (int i = 1; i < indexFromRight; i++)number /= 10;//求个位数字return number % 10;}//digits位数的第一个数字,两位数从10开始,三位数从100开始private static int beginNumberFor(int digits) {if (digits == 1)return 0;return (int) Math.pow(10, digits - 1);}
50. 把数组排成最小的数
题目描述:
输入一个正整数数组,把数组里所有数字拼接起来排成一个数,打印能拼接出的所有数字中最小的一个。例如输入数组{3,32,321},则打印出这三个数字能排成的最小数字为321323。
思路一:最容易想到的方法就是求出数组中所有数的全排列,然后将每个排列拼接起来(需要注意的是,两个整数拼接的结果可能超过整数的范围,所以这里隐藏着一个大数问题),最后比较拼接后的数字大小。这显然不是最简单的方法,这里不再介绍。
思路二:可以联想到字符串的字典排,将数字问题转化成字符串问题,也是解决大数问题的一个好方法。
public static String minNumber(int[] nums){if(nums == null || nums.length == 0)return "";String[] strs = new String[nums.length];for(int i = 0; i < nums.length; i++){strs[i] = String.valueOf(nums[i]);}//重写compareTo方法Arrays.sort(strs, new Comparator<String>() {@Overridepublic int compare(String o1, String o2) {return (o1 + o2).compareTo(o2 + o1);}});StringBuilder sb = new StringBuilder();for(String str : strs)sb.append(str);return sb.toString();}
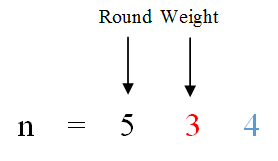
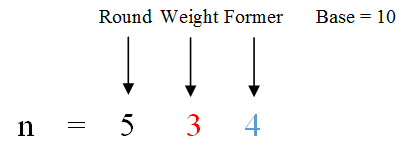
51. 把数字翻译成字符串
题目描述:
给定一个数字,按照如下规则翻译成字符串:0翻译成“a”,1翻译成“b”...25翻译成“z”。一个数字有多种翻译可能,例如12258一共有5种,分别是bccfi,bwfi,bczi,mcfi,mzi。实现一个函数,用来计算一个数字有多少种不同的翻译方法。
思路:用递归自顶向下分析,用动态规划自低向上求解(因为递归的解法有很多重复计算的情况)。
自上而下,从最大的问题开始,递归 :
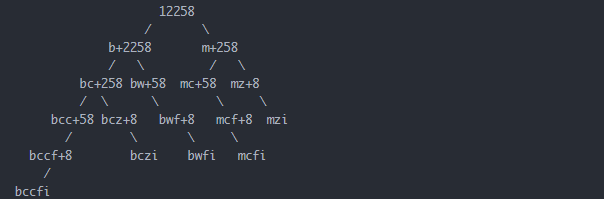
有很多子问题被多次计算,比如258被翻译成几种这个子问题就被计算了两次。
自下而上,动态规划,从最小的问题开始 :
f(r)表示以r为开始(r最小取0)到最右端所组成的数字能够翻译成字符串的种数。对于长度为n的数字,f(n)=0,f(n-1)=1,求f(0)。
递推公式为 f(r-2) = f(r-1)+g(r-2,r-1)*f(r);
其中,如果(r-2),(r-1)处的数字连接起来能够翻译成字符,则g(r-2,r-1)=1,否则为0。
因此,对于12258:
f(5) = 0
f(4) = 1
f(3) = f(4)+0 = 1
f(2) = f(3)+f(4) = 2
f(1) = f(2)+f(3) = 3
f(0) = f(1)+f(2) = 5
public static int getTranslationCount(int number){if(number < 0)return 0;if(number == 1)return 1;return getTranslationCount(Integer.toString(number));}/*** 动态规划,从右到左计算。* f(r-2) = f(r-1)+g(r-2,r-1)*f(r);* 如果r-2,r-1能够翻译成字符,则g(r-2,r-1)=1,否则为0* @param number* @return*/public static int getTranslationCount(String number) {int f1 = 0, f2 = 1,g = 0;int temp;for(int i = number.length()-2; i >= 0; i--){if(Integer.parseInt(number.charAt(i)+""+number.charAt(i+1)) < 26)g = 1;elseg = 0;temp = f2;f2 = f2 + g * f1;f1 = temp;}return f2;}
52. 礼物的最大值
题目描述:
在一个m*n的棋盘的每一个格都放有一个礼物,每个礼物都有一定价值(大于0)。从左上角开始拿礼物,每次向右或向下移动一格,直到右下角结束。给定一个棋盘,求拿到礼物的最大价值。例如,对于如下棋盘:
1 10 3 812 2 9 65 7 4 113 7 16 5
礼物的最大价值为1+12+5+7+7+16+5=53。
思路一:图的广度优先遍历。这个棋盘其实可以看成一个有向图,起点为左上角,终点为右下角,每一点仅仅指向右侧和下侧。因此我们可以从左上角开始进行广度优先遍历。此外,遍历过程中可以进行剪枝,最终移动到右下角时会仅剩下一个枝,该路径所经的点的数值之和即为所求。
//有向图的遍历(广度优先,可再剪枝进行优化)public static int getMaxVaule2(int[][] data){if(data == null || data.length == 0 || data[0].length == 0)return 0;int maxRowIndex = data.length - 1;int maxColIndex = data[0].length - 1;Queue<Node> queue = new LinkedList<>();queue.offer(new Node(0,0,data[0][0]));Node nodeCur = null;while (!(queue.peek().row == maxRowIndex && queue.peek().col == maxColIndex)){nodeCur = queue.poll();if(nodeCur.row != maxRowIndex)queue.offer(new Node(nodeCur.row + 1,nodeCur.col,nodeCur.sum + data[nodeCur.row + 1][nodeCur.col]));if(nodeCur.col!=maxColIndex)queue.offer(new Node(nodeCur.row,nodeCur.col + 1,nodeCur.sum+data[nodeCur.row][nodeCur.col + 1]));}int maxSum = 0,temp = 0;while (!queue.isEmpty()){temp = queue.poll().sum;if(temp > maxSum)maxSum = temp;}return maxSum;}public static class Node{int row;int col;int sum;public Node(int r,int c,int s){row = r;col = c;sum = s;}}
思路二:动态规划,使用二维数组进行辅助。
定义f(i,j)表示到达坐标为(i,j)的格子时能拿到的礼物总和的最大值;有两种路径到达(i,j):(i-1,j)或者(i,j-1);f(i,j) = max(f(i-1,j), f(i,j-1)) + gift[i,j];使用循环来计算避免重复子问题。
public int getMaxValue(int[][] arr) {if (arr == null || arr.length == 0) {return 0;}int rows = arr.length;int cols = arr[0].length;int[][] maxValue = new int[rows][cols];for (int i = 0; i < rows; i++) {for (int j = 0; j < cols; j++) {int left = 0;int up = 0;if(i>0){up = maxValue[i-1][j];}if(j>0){left = maxValue[i][j-1];}maxValue[i][j] = Math.max(up, left) + arr[i][j];}}return maxValue[rows-1][cols-1];}
思路三:动态规划,使用一维数组进行辅助。
题目中可知,坐标(i,j)的最大礼物价值仅仅取决于坐标为(i-1,j)和(i,j-1)两个格子;因此第i-2行以上的最大价值没有必要保存下来。使用一维数组保存:(0,0)…(0,j-1)保存的是(i,0)…(i,j-1)的最大价值;(0,j)…(0,cols-1)保存的是(i-1,j)…(i-1,cols-1)的最大价值。每次计算新的(i,j)时,使用数组下标j-1和j的最大值加当前礼物值即可。
public int getMaxValue(int[][] arr) {if (arr == null || arr.length == 0) {return 0;}int rows = arr.length;int cols = arr[0].length;int[][] maxValue = new int[rows][cols];for (int i = 0; i < rows; i++) {for (int j = 0; j < cols; j++) {int left = 0;int up = 0;if(i>0){up = maxValue[i-1][j];}if(j>0){left = maxValue[i][j-1];}maxValue[i][j] = Math.max(up, left) + arr[i][j];}}return maxValue[rows-1][cols-1];}
53. 最长不含重复字符的子字符串
题目描述:
请从字符串中找出一个最长的不包含重复字符的子字符串,计算该最长子字符串的长度。假设字符串中只包含从’a’到’z’的字符。例如,在字符串中”arabcacfr”,最长非重复子字符串为”acfr”,长度为4。
思路一:使用额外空间ArrayList,如果字符第一次出现,就将其加入ArrayList中,如果ArrayList中已经包含该字符,找到该字符的位置,将该位置以及之前的字符全部丢弃。
public static int longestSubstringWithoutDuplication(String str){if(str == null || str.length() == 0)return -1;int maxLength = 1;List<Character> list = new ArrayList<>();list.add(str.charAt(0));for(int i = 0; i < str.length(); i++){if(list.contains(str.charAt(i))){int index = list.indexOf(str.charAt(i));list = list.subList(index + 1, list.size());list.add(str.charAt(i));maxLength = Math.max(maxLength, list.size());}else {list.add(str.charAt(i));//maxLength++;maxLength = Math.max(maxLength, list.size());}}return maxLength;}
思路二:使用动态规划。记录当前字符之前的最长非重复子字符串长度f(i-1),其中i为当前字符的位置。每次遍历当前字符时,分两种情况:
1)若当前字符第一次出现,则最长非重复子字符串长度f(i) = f(i-1)+1。
2)若当前字符不是第一次出现,则首先计算当前字符与它上次出现位置之间的距离d。若d大于f(i-1),即说明前一个非重复子字符串中没有包含当前字符,则可以添加当前字符到前一个非重复子字符串中,所以,f(i) = f(i-1)+1。若d小于或等于f(i-1),即说明前一个非重复子字符串中已经包含当前字符,则不可以添加当前字符,所以,f(i) = d。
public static int longestSubString(String str){if(str == null || str.length() == 0)return -1;int curLength = 0, maxLength = 0;int[] position = new int[26];//初始化为-1,负数表示没出现过Arrays.fill(position, -1);for(int i = 0; i < str.length(); i++){int c = str.charAt(i) - 'a';int preIndex = position[c];//当前字符第一次出现,或者前一个非重复子字符串中没有包含当前字符if(preIndex == -1 || i - preIndex > curLength){curLength++;}else {//更新最长非重复子字符串的长度if(maxLength < curLength)maxLength = curLength;curLength = i - preIndex;}position[c] = i; //更新字符出现的位置}maxLength = Math.max(maxLength, curLength);return maxLength;}
54. 丑数
题目描述:
我们把只包含因子2,3,5的数称为丑数(Ugly Number)。求按从小到大的顺序的第1500个丑数。例如6,8都是丑数,但14不是,因为它含有因子7.习惯上我们把1当作第一个丑数。
思路一:逐个判断每个整数是不是丑数的解法,直观但不够高效:
所谓一个数m是另一个数n的因子,是指n能被m整除,也就是说n%m==0.根据丑数的定义,丑数只能被2,3,5整除。也就是说如果一个数能被2整除,我们把它连续除以2;如果能被3整除,就连续除以3;如果能被5整除,就除以5.如果最后我们得到的是1,那么这个数就是丑数,否则不是。
private static boolean isUgly(int num){if(num <= 0)return false;while (num % 2 == 0)num /= 2;while (num % 3 == 0)num /= 3;while (num % 5 == 0)num /= 5;return (num == 1) ? true : false;}//输入1500,找到第1500个丑数public static int getUglyNumber(int num){if(num <= 0)return 0;int number = 0;int uglyFound = 0; //第几个丑数while(uglyFound < num){++number;if(isUgly(number))++uglyFound;}return number;}
思路二:用空间换时间。前面的算法之所以效率低,很大程度上是因为不管一个数是不是丑数我们对它都要作计算。接下来我们试着找到一种只要计算丑数的方法,而不在非丑数的整数上花费时间。根据丑数的定义,丑数应该是另一个丑数乘以2,3,5的结果。因此我们可以创建一个数组,里面的数字是排序好的丑数,每一个丑数都是前面的丑数乘以2,3,5得到的。
这种思路的关键在于怎样确定数组里面的丑数是排序好的。假设数组中已经有若干个丑数排好后存放在数组中,并且把已有的最大的丑数记作M,我们接下来分析如何生成下一个丑数。该丑数肯定是前面某个丑数乘以2,3,5的结果。所以我们首先考虑把已有的每个丑数乘以2.在乘以2的时候,能得到若干个小于或等于M的结果。由于是按照顺序生成的,小于或者等于M肯定已经在数组中了,我们不需要再次考虑;还会得到若干个大于M的结果,但我们只需要第一个大于M的结果,因为我们希望丑数是指按从小到大的顺序生成的,其他更大的结果以后再说。我们把得到的第一个乘以2后大于M的结果即为M2.同样,我们把已有的每一个丑数乘以3,5,能得到第一个大于M的结果M3和M5.那么下一个丑数应该是M2,M3,M5。这3个数的最小者。
前面分析的时候,提到把已有的每个丑数分别都乘以2,3,5.事实上这不是必须的,因为已有的丑数都是按顺序存放在数组中的。对乘以2而言,肯定存在某一个丑数T2,排在它之前的每一个丑数乘以2得到的结果都会小于已有的最大丑数,在它之后的每一个丑数乘以2得到的结果都会太大。我们只需记下这个丑数的位置,同时每次生成新的丑数的时候,去更新这个T2.对乘以3和5而言,也存在这同样的T3和T5。
public static int getUglyNumber(int index){if(index <= 0)return 0;int[] uglynumbers = new int[index];uglynumbers[0] = 1;int nextUglyNumber = 1;int pMultiply2 = 0;int pMultiply3 = 0;int pMultiply5 = 0;while(nextUglyNumber < index){int minUglyNumber = minOfThree(uglynumbers[pMultiply2] * 2, uglynumbers[pMultiply3] * 3, uglynumbers[pMultiply5] * 5);uglynumbers[nextUglyNumber] = minUglyNumber;while(uglynumbers[pMultiply2] * 2 <= uglynumbers[nextUglyNumber])pMultiply2++;while(uglynumbers[pMultiply3] * 3 <= uglynumbers[nextUglyNumber])pMultiply3++;while(uglynumbers[pMultiply5] * 5 <= uglynumbers[nextUglyNumber])pMultiply5++;nextUglyNumber++;}return uglynumbers[index - 1];}private static int minOfThree(int a, int b, int c){int min = (a < b) ? a : b;min = (min < c) ? min : c;return min;}
55. 第一个值出现一次的字符
题目描述:
在一个字符串中找到第一个只出现一次的字符,并返回该字符。
方法一:使用HashMap。需要注意的是,HashMap存入和输出元素的顺序可能并不相同,所以,在找第一个出现一次的字符时还得根据给定字符串的顺序依次查找。
public static char firstNotRepeatChar(String str){if(str == null || str.length() == 0)return '\0';HashMap<Character, Integer> map = new HashMap<>();for(int i = 0; i < str.length(); i++){if(map.containsKey(str.charAt(i)))map.put(str.charAt(i), map.get(str.charAt(i)) + 1);elsemap.put(str.charAt(i), 1);}for(int i = 0; i < str.length(); i++){if(map.get(str.charAt(i)) == 1)return str.charAt(i);}return '\0'; //没找到,返回空字符}
思路二:考虑到要统计的字符范围有限,因此可以使用整型数组代替 HashMap。这种方法其实是使用了ASCII码的编码十进制值做数组的下标。ASCII码标准码有128个,十进制为0~127;后来扩展为256个,新加的128个字符十进制为128~255(也有说是-1~-128)。于是用é(后128个字符中的一个)验证了一下,没有出现数组越界的情况,说明后128个字符的十进制是整数,这种算法没有问题。
public static char firstNotRepeatingChar(String str) {int[] cnts = new int[256];for (int i = 0; i < str.length(); i++)cnts[str.charAt(i)]++;for (int i = 0; i < str.length(); i++)if (cnts[str.charAt(i)] == 1)return str.charAt(i);return '\0';}
思路三:使用位集。考虑到只需要找到只出现一次的字符,那么需要统计的次数信息只有 0,1,更大,使用两个比特位就能存储这些信息。
public static char firstNotRepeatingChar(String str) {if(str == null || str.length() == 0)return '\0';BitSet bs1 = new BitSet(256);BitSet bs2 = new BitSet(256);for (char c : str.toCharArray()) {//如果两个位集都没有,就放到bs1中if (!bs1.get(c) && !bs2.get(c))bs1.set(c); // 0 0 -> 0 1//如果只有bs1中有,bs2中也会放一个。经过这两步,只出现一次的字符放在bs1中,出现多次的字符bs1和bs2中都有else if (bs1.get(c) && !bs2.get(c))bs2.set(c); // 0 1 -> 1 1}for (int i = 0; i < str.length(); i++) {char c = str.charAt(i);if (bs1.get(c) && !bs2.get(c)) // 0 1return c;}return '\0';}
56. 数组中的逆序对
57. 两个链表的第一个公共结点
题目描述:
输入两个链表,找到它们第一个公共接节点。

思路一:使用栈。定义连个栈,分别存放两个链表的元素。然后同时出栈,寻找最后一个相同节点。
public static ListNode findFirstCommonNode(ListNode head1, ListNode head2){if(head1 == null || head2 == null)return null;ListNode pHead1 = head1, pHead2 = head2;Stack<ListNode> stack1 = new Stack<>();Stack<ListNode> stack2 = new Stack<>();while(pHead1 != null && pHead2 != null){stack1.push(pHead1);stack2.push(pHead2);pHead1 = pHead1.next;pHead2 = pHead2.next;}while(pHead1 != null){stack1.push(pHead1);pHead1 = pHead1.next;}while(pHead2 != null){stack2.push(pHead2);pHead2 = pHead2.next;}ListNode commonNode = null;while(!stack1.isEmpty() && !stack2.isEmpty()){if(stack1.peek() == stack2.peek()){commonNode = stack1.pop();stack2.pop();}elsereturn commonNode;}//两个栈都空,说明两个链表完全重合if(stack1.isEmpty() && stack2.isEmpty())return commonNode;return null;}
思路二:不使用栈,遍历两次链表。第一次遍历得到两条链表的长度即其差值,然后进行第二次遍历,长链表先遍历差值步,接着两个链表同时开始遍历,找到第一个相同节点即为所求。
public static ListNode findFirstCommonNode(ListNode head1, ListNode head2){if(head1 == null || head2 == null)return null;int length1 = getListLength(head1);int length2 = getListLength(head2);int lengthDif = length1 > length2 ? (length1 - length2) : (length2 - length1);ListNode longList = null, shortList = null;if(length1 > length2){longList = head1;shortList = head2;}else {longList = head2;shortList = head1;}for(int i = 0; i < lengthDif; i++)longList = longList.next;while(longList != null && shortList != null && longList != shortList){longList = longList.next;shortList = shortList.next;}ListNode commondNode = longList;return commondNode;}private static int getListLength(ListNode head){if(head == null)return -1;ListNode pHead = head;int length = 0;while(pHead != null){length++;pHead = pHead.next;}return length;}
思路三:设 A 的长度为 a + c,B 的长度为 b + c,其中 c 为尾部公共部分长度,可知 a + c + b = b + c + a。
当访问链表 A 的指针访问到链表尾部时,令它从链表 B 的头部重新开始访问链表 B;同样地,当访问链表 B 的指针访问到链表尾部时,令它从链表 A 的头部重新开始访问链表 A。这样就能控制访问 A 和 B 两个链表的指针能同时访问到交点。
public static ListNode findFirstCommonNode(ListNode pHead1, ListNode pHead2) {ListNode l1 = pHead1, l2 = pHead2;while (l1 != l2) {l1 = (l1 == null) ? pHead2 : l1.next;l2 = (l2 == null) ? pHead1 : l2.next;}return l1;}
58. 数字在排序数组中出现的次数
题目描述:
统计一个数字在排序数组中出现的次数,比如排序数组为{1,2,3,3,3,4,5},那么数字3出现的次数就是3。
思路一:二分查找。假设我们需要找的数字是k,那么就需要找到数组中的第一个k和最后一个k出现的位置。如何通过二分查找得到第一个k的位置呢?取数组中间的数字与k作比较,如果该数字比k大,那么k只能出现在前半部分,那么下一轮只能在前半部分找;如果该数字比k小,那么k只能出现在后半部分,那么下一轮只能在后半部分找;如果该数字等于k,需要判断这是不是第一个k,如果该数字的前一个数字不是k,那么该数字就是第一个k,否则需要在前半部分继续寻找第一个k;寻找最后一个k的方法与寻找第一个k的方法一样。
private static int getFirstK(int[] nums, int k, int start, int end){if(start > end)return -1;int mid = (start + end) >> 1;int midValue = nums[mid];if(midValue == k){if((mid > 0 && nums[mid - 1] != k) || mid == 0)return mid;elseend = mid - 1;}else if(midValue > k)end = mid - 1;elsestart = mid + 1;return getFirstK(nums, k, start, end);}private static int getLastK(int[] nums, int k, int start, int end){if(start > end)return -1;int mid = (start + end) >> 1;int midValue = nums[mid];if(midValue == k){if((mid < nums.length - 1 && nums[mid + 1] != k) || mid == nums.length - 1)return mid;elsestart = mid + 1;}else if(midValue < k)start = mid + 1;elseend = mid - 1;return getLastK(nums, k, start, end);}public static int getNumberOfK(int[] nums, int k){if(nums == null || nums.length == 0)return -1;int number = 0;int first = getFirstK(nums, k, 0, nums.length - 1);int last = getLastK(nums, k, 0, nums.length - 1);if(first > -1 && last > -1)number = last - first + 1;return number;}
思路二:不难发现,思路一种有很多重复的代码,其实可以简化一下,合并起来。
public static int getNumberOfK(int[] nums, int K) {int first = binarySearch(nums, K);int last = binarySearch(nums, K + 1); //能找到最右边的K的右边的元素//return (first == nums.length || first == -1 || nums[first] != K) ? 0 : last - first;int number = 0;if(first > -1 && last > -1)number = last - first;return number;}private static int binarySearch(int[] nums, int K) {if(nums == null || nums.length == 0)return -1;int l = 0, h = nums.length;while (l < h) {int m = l + (h - l) / 2;//最终能找到最左边的K;如果不存在K,会找到比K小的一个数if (nums[m] >= K)h = m;elsel = m + 1;}return l;}
59. 二叉搜索树的第K个节点
题目描述:
给定一棵二叉搜索树,请找出其中的第K大的节点。
思路:利用二叉搜索树中序遍历有序的特点。
private TreeNode ret;private int cnt = 0;public TreeNode KthNode(TreeNode pRoot, int k) {inOrder(pRoot, k);return ret;}private void inOrder(TreeNode root, int k) {if (root == null || cnt >= k)return;inOrder(root.left, k);cnt++;if (cnt == k)ret = root;inOrder(root.right, k);}
60. 二叉树的深度
题目描述:
输入一棵二叉树的根节点,求二叉树的深度。从根结点到叶结点依次经过的结点(含根、叶结点)形成树的一条路径,最长路径的长度为树的深度。

思路:如果只有根节点,则深度为1;如果只有左子树,则深度为左子树的深度加一;如果只有右子树,则深度为右子树的深度加一;如果既有左子树又有右子树,则深度为两者深度较大者加一。递归的思想。
public static int biTreeDeepth(BiTreeNode root){if(root == null)return -1;int nLeft = biTreeDeepth(root.getLeft());int nRight = biTreeDeepth(root.getRight());return (nLeft > nRight) ? (nLeft + 1) : (nRight + 1);}
61. 二叉树的深度
题目描述:
输入一棵二叉树,判断该二叉树是否是平衡二叉树。
思路:采用后序遍历的思想,可以避免重复遍历的问题。在遍历某节点的左右子节点之后,可以根据它的左右子节点的深度判断它是不是平衡的,并得到当前节点的深度。当最后遍历到树的根节点的时候,也就判断了整棵二叉树是不是平衡二叉树。
private boolean isBalanced = true;public boolean IsBalanced_Solution(TreeNode root) {height(root);return isBalanced;}private int height(TreeNode root) {if (root == null || !isBalanced)return 0;int left = height(root.left);int right = height(root.right);if (Math.abs(left - right) > 1)isBalanced = false;return 1 + Math.max(left, right);}
62. 数组中只出现一次的数字
题目描述:
一个整型数组里除了两个数字之外,其他的数字都出现了两次。请写程序找出这两个只出现一次的数字。要求时间复杂度为O(n),空间复杂度为O(1)
思路一:使用HashMap,但是空间复杂度不是O(1)。
public static int[] findNumberAppendOnce(int[] nums){if(nums == null || nums.length == 0)return null;HashMap<Integer, Integer> map = new HashMap<>();int[] result = new int[2];for(int i = 0; i < nums.length; i++){if(map.containsKey(nums[i]))map.put(nums[i], map.get(nums[i]) + 1);elsemap.put(nums[i], 1);}int i = 0;for(Integer key : map.keySet()){if(map.get(key) == 1)result[i++] = key;if(i >= 2) //题目中说是有两个,但还是判断一下,避免有错误输出break;}return result;}
思路二:使用异或的性质。如果只有一个数字出现一次,要找出这个数字,那直接依次异或,因为两个相同的数字亦或结果为0,0与任何数字异或结果还是那个数字。
现在出现两个,那么考虑分成两个子数组,但是要求成对的数字分在一起,那两个不同的数字分别在两个子数组里。
- 所有数字依次异或,结果为那两个不同的数字异或的结果,并且结果一定非0,记为a
- 从左至右找出a第一个bit位非0的index,以此为依据将原数组分为两个子数组(这样的分类标准可以达到上述的目的:1)相同的数字一定落在同一个子数组里 2)那两个不同的数字分布在不同的子数组里)
- 分成两个子数组后,分别异或即可。
public static int[] findNumberAppendOnce(int[] nums){if(nums == null || nums.length < 2)throw new IllegalArgumentException("nums size must bigger than 2");int resultExclusiveOR = 0; //数组中所有值异或一次的结果for(int i = 0; i < nums.length; i++)resultExclusiveOR ^= nums[i];int indexOf1 = findFirstBitIs1(resultExclusiveOR); //最右边的1的位数int num1 = 0, num2 = 0;for(int i = 0; i < nums.length; i++){if(isBit1(nums[i], indexOf1))num1 ^= nums[i];elsenum2 ^= nums[i];}return new int[] {num1, num2};}//找到整数num的二进制表示中最右边是1的位private static int findFirstBitIs1(int num){int indexBit = 0;//8 * Integer.SIZE是整型数转化为二进制后最多有多少位while((num & 0x01) == 0 && (indexBit < 8 * Integer.SIZE)){num >>= 1;indexBit++;}return indexBit;}//判断整数num的二进制表示中从右边起的indexBit位是不是1private static boolean isBit1(int num, int indexBit){num >>= indexBit;return (num & 0x01) == 1;}
思路三:异或的简写。diff &= -diff 得到 diff 最右侧不为 0 的位,也就是不存在重复的两个元素在位级表示上最右侧不同的那一位
public void findNumsAppearOnce(int[] nums, int num1[], int num2[]) {int diff = 0;for (int num : nums)diff ^= num;diff &= -diff;for (int num : nums) {if ((num & diff) == 0)num1[0] ^= num;elsenum2[0] ^= num;}}
63. 和为 S 的两个数字
题目描述:
输入一个递增排序的数组和一个数字 S,在数组中查找两个数,使得他们的和正好是 S。如果有多对数字的和等于 S,输出两个数的乘积最小的。
思路:使用双指针,一个指针指向元素较小的值,一个指针指向元素较大的值。指向较小元素的指针从头向尾遍历,指向较大元素的指针从尾向头遍历。
- 如果两个指针指向元素的和 sum == target,那么得到要求的结果;
- 如果 sum > target,移动较大的元素,使 sum 变小一些;
- 如果 sum < target,移动较小的元素,使 sum 变大一些。
public static int[] findNumberWithSum(int[] nums, int sum){if(nums == null || nums.length < 2)throw new IllegalArgumentException("nums size is not correct");int head = 0, tail = nums.length - 1;while(head < tail){if(nums[head] + nums[tail] == sum)return new int[]{nums[head], nums[tail]};else if(nums[head] + nums[tail] < sum)head++;elsetail--;}return null;}
63.1 和为 S 的连续正数序列
题目描述:输入一个正数s,打印出所有和为s的连续正数序列(至少含有两个数)。例如输入15,由于1+2+3+4+5=4+5+6=7+8=15,所以结果打印出3个连续序列1-5,,4-6和7-8。
思路:
- 延续题目“和为S的两个数字”的思想。设置一大一小两个指针。
- 初始状态下,small指向1,big指向2。如果从small到big的和大于S,则从序列中去掉较小的值,也就是small向后移动一个位置。若从small到big的序列和小于S,则big向后移动一个位置,以便序列包含更多的数字。
- 因为题目中要求最少是两个数字,所以small最大为(s+1)/2。
public static void findContinuousSequence(int sum){if(sum < 3)return;int left = 1;int right = 2;int mid = (1 + sum) >> 1;int curSum = left + right;while(left < mid){if(sum == curSum)printSequence(left, right);while(curSum > sum && left < mid){curSum -= left;left++;if(curSum == sum)printSequence(left, right);}right++;curSum += right;}}private static void printSequence(int left, int right){for(int i = left; i <= right; i++)System.out.print(i+" ");System.out.println();}
64. 翻转单词顺序
题目描述:输入一个英文句子,翻转句子中单词的顺序,但单词内字符串的顺序不变。例如输入字符串:“I am a student”,则输出“student a am I”。
思路:先翻转整个句子,然后翻转每个单词。按照题目要求,如果输入的字符串只包含一个单词,输出结果为该字符串本身。
public static String reverseSequence(String str){if(str == null || str.length() == 0)return null;char[] chars = str.toCharArray();//翻转整个句子reverse(chars, 0, chars.length - 1);int i = 0, j = 0;while(j <= chars.length){if(j == str.length() || chars[j] == ' '){reverse(chars, i, j - 1);i = j + 1;}j++;}// return chars.toString();return new String(chars);}public static void reverse(char[] chars, int i, int j){if(chars == null || chars.length == 0)return;while(i < j){char ch = chars[i];chars[i] = chars[j];chars[j] = ch;i++;j--;}}
64.1 左旋转字符串
题目描述:定义字符串的左旋转操作:把字符串前面的若干个字符移动到字符串的尾部。如把字符串abcdef左旋转2位得到字符串cdefab。请实现字符串左旋转的函数。
思路:字符串的左右旋转其实就是将字符串循环左右移,前面在总结左移和右移的时候总结了方法:两次翻转一次合并。这里提出了另一种方法:三次翻转。
//左旋转字符串,index表示左旋转的数量public static String leftRotateString(String str, int index){if(str == null || str.length() == 0)return null;if(index <= 0 || index > str.length())return str;char[] chars = str.toCharArray();//翻转字符串前index个字符reverse(chars, 0, index - 1);//翻转字符串后面的部分reverse(chars, index, str.length() - 1);//翻转整个字符串reverse(chars, 0, str.length() - 1);return String.valueOf(chars);}//右旋转字符串,index右旋转的数量public static String rightRotateString(String str, int index){if(str == null || str.length() == 0)return null;if(index <= 0 || index > str.length())return str;char[] chars = str.toCharArray();//翻转字符串后index个字符reverse(chars, str.length() - index, str.length() - 1);//翻转前面的字符reverse(chars, 0, str.length() - index - 1);//翻转整个字符串reverse(chars, 0, str.length() - 1);return String.valueOf(chars);}//字符串反转public static void reverse(char[] chars, int i, int j){if(chars == null || chars.length == 0)return;while(i < j){char ch = chars[i];chars[i] = chars[j];chars[j] = ch;i++;j--;}}
65. 滑动窗口的最大值
题目描述:给定一个数组和滑动窗口的大小,请找出所有滑动窗口里的最大值。
例如,如果输入数组{2,3,4,2,6,2,5,1}及滑动窗口的大小3,那么一共存在6个滑动窗口,它们的最大值分别为{4,4,6,6,6,5}。
思路一:构建一个窗口w大小的最大堆,每次从堆中取出窗口的最大值,随着窗口往右滑动,需要将堆中不属于窗口的堆顶元素删除。
时间复杂度:正常情况下,往堆中插入数据为O(lgw),如果数组有序,则为O(lgn),因为滑动过程中没有元素从堆中被删除,滑动n-w+1次,复杂度为O(nlgn)。
public ArrayList<Integer> maxInWindows(int[] num, int size) {ArrayList<Integer> ret = new ArrayList<>();if (size > num.length || size < 1)return ret;PriorityQueue<Integer> heap = new PriorityQueue<>((o1, o2) -> o2 - o1); /* 大顶堆 */for (int i = 0; i < size; i++)heap.add(num[i]);ret.add(heap.peek());for (int i = 1, j = i + size - 1; j < num.length; i++, j++) { /* 维护一个大小为 size 的大顶堆 */heap.remove(num[i - 1]);heap.add(num[j]);ret.add(heap.peek());}return ret;}
思路二:使用双向队列。最大堆解法在堆中保存有冗余的元素,比如原来堆中元素为[10 5 3],新的元素为11,则此时堆中会保存有[11 5 3]。其实此时可以清空整个队列,然后再将11加入到队列即可,即只在队列中保持[11]。使用双向队列可以满足要求,滑动窗口的最大值总是保存在队列首部,队列里面的数据总是从大到小排列。当遇到比当前滑动窗口最大值更大的值时,则将队列清空,并将新的最大值插入到队列中。如果遇到的值比当前最大值小,则直接插入到队列尾部。每次移动的时候需要判断当前的最大值是否在有效范围,如果不在,则需要将其从队列中删除。由于每个元素最多进队和出队各一次,因此该算法时间复杂度为O(N)。
public ArrayList<Integer> maxInWindows(int [] num, int size) {ArrayList<Integer> arr = new ArrayList<>();if (num == null)return arr;if (num.length < size || size <= 0)return arr;Deque<Integer> queue = new LinkedList<>();for (int i=0; i<num.length; i++){while (!queue.isEmpty() && num[i] >= num[queue.getLast()])queue.pollLast();while (!queue.isEmpty() && queue.getFirst() < i - (size-1))queue.pollFirst();queue.offerLast(i);if (i + 1 >= size)arr.add(num[queue.getFirst()]);}return arr;}
66. n 个骰子的点数
题目描述:把n个骰子扔到地上,所有骰子朝上一面的点数之后为s. 输入n,打印出s所有可能的值出现的概率。(每个骰子6个面,点数从1到6)
思路一:使用递归。递归的思想一般是分而治之,把n个骰子分为第一个和剩下的n-1个。先计算第一个骰子每个点数出现的次数,再计算剩余n-1个骰子出现的点数之和。求n-1个骰子的点数之的方法和前面讲的一样,即再次把n-1个骰子分成两堆------第一个和剩下的n-2个。n个骰子,每个骰子6个面,总共有6n个组合。这6n个组合之中肯定有重复的,我们知道其范围是n~6n,对于每种情况我们可以用缓存机制记录下来,每当其发生一次我们令其对应的单元加1。
我们定义一个长度为6n-n+1的数组,和为s的点数出现的次数保存到数组第s-n个元素里。为什么是6n-n+1呢?因为n个骰子的和最少是n,最大是6n,介于这两者之间的每一个情况都可能会发生,总共6n-n+1种情况。
这种方法思路非常简洁,但是递归实现会存在子问题重复求解的情况发生,所以当number很大的时候,其性能会慢的让人不能接受。
private static final int gMaxValue = 6;//number表示骰子的数量public static void printProbability(int number){if(number < 1)return;int maxSum = number * gMaxValue; //number个骰子点数的最大值int[] pProbabilities = new int[maxSum - number + 1];Arrays.fill(pProbabilities, 0);double total = Math.pow(gMaxValue, number);probability(number, pProbabilities); //这个函数计算n~6n每种情况出现的次数for(int i = number; i <= maxSum; i++){double ratio = pProbabilities[i - number] / total;System.out.println("sum: "+ i + ", ratio: "+ ratio);}}private static void probability(int number, int[] pProbabilities){for(int i = 1; i <= gMaxValue; i++) //从第一个骰子开始probability(number, number, i, pProbabilities);}//总共original个骰子,当前第 current个骰子,当前的和,贯穿始终的数组private static void probability(int original, int current, int sum, int[] pProbabilities){if(current == 1)pProbabilities[sum - original]++;else{for(int i = 1; i <= gMaxValue; i++)probability(original, current - 1, sum + i, pProbabilities);}}
思路二:使用循环。可以考虑用两个数组来存储骰子点数的每一个总数出现的次数。在一次循环中,每一个数组中的第n个数字表示骰子和为n出现的次数。在下一轮循环中,我们加上一个新的骰子,此时和为n的骰子出现的次数应该等于上一次循环中骰子点数和为n-1,n-2,n-3,n-4,n-5的次数之和,所以我们把另一个数组的第n个数字设为前一个数组对应的第n-1,n-2,n-3,n-4,n-5。
private static final int gMaxValue = 6;public static void printProbability_1(int number){if(number<1)return;int[][] pProbabilities = new int[2][gMaxValue*number +1];for(int i = 0;i < gMaxValue; i++){//初始化数组pProbabilities[0][i] = 0;pProbabilities[1][i] = 0;}int flag = 0;for(int i = 1;i <= gMaxValue; i++){//当第一次抛掷骰子时,有6种可能,每种可能出现一次pProbabilities[flag][i] = 1;}//从第二次开始掷骰子,假设第一个数组中的第n个数字表示骰子和为n出现的次数,//在下一循环中,我们加上一个新骰子,此时和为n的骰子出现次数应该等于上一次循环中骰子点数和为n-1,n-2,n-3,n-4,n-5,//n-6的次数总和,所以我们把另一个数组的第n个数字设为前一个数组对应的n-1,n-2,n-3,n-4,n-5,n-6之和for(int k = 2; k <= number; k++){for(int i = 0; i < k; i++){//第k次掷骰子,和最小为k,小于k的情况是不可能发生的!所以另不可能发生的次数设置为0!pProbabilities[1 - flag][i] = 0;}for(int i = k;i <= gMaxValue * k; i++){//第k次掷骰子,和最小为k,最大为g_maxValue*kpProbabilities[1 - flag][i] = 0;//初始化,因为这个数组要重复使用,上一次的值要清0for(int j = 1;j <= i && j <= gMaxValue; j++){pProbabilities[1 - flag][i] += pProbabilities[flag][i - j];}}flag = 1 - flag;}double total = Math.pow(gMaxValue, number);for(int i=number; i <= gMaxValue * number; i++){double ratio = pProbabilities[flag][i] / total;System.out.println("sum: "+i+", ratio: "+ ratio);}}
67. 扑克牌的顺子
题目描述:从扑克牌中随机抽出5张牌,判断是不是一个顺子,即这五张牌是不是连续的。2——10为数字本身,A为1,J为11,Q为12,K为13,而大小王为任意数字。
思路:因为大小王为特殊数字,不妨把它们统一看成0。首先把数组进行排序,再统计数组中0的个数,最后统计排序后的数组中相邻数字之间的空缺总数。如果空缺的总数小于或者等于0的个数,那么这个数组就是连续的,否则就是不连续的。
public static boolean isContinuous(int[] nums){if(nums == null || nums.length < 1)return false;Arrays.sort(nums);int numberOfZero = 0;int numberOfGap = 0;//统计0的个数for(int i = 0; i < nums.length && nums[i] == 0; i++)numberOfZero++;//统计间隔的个数int left = numberOfZero; //跳过前面的0int right = left + 1;while(right < nums.length){if(nums[left] == nums[right])return false;numberOfGap += nums[right] - nums[left] - 1;left = right;right++;}return (numberOfGap > numberOfZero) ? false : true;}
68. 圆圈中最后剩下的数(有待测试)
题目描述:让小朋友们围成一个大圈。然后,随机指定一个数 m,让编号为 0 的小朋友开始报数。每次喊到 m-1 的那个小朋友要出列唱首歌,然后可以在礼品箱中任意的挑选礼物,并且不再回到圈中,从他的下一个小朋友开始,继续 0...m-1 报数 .... 这样下去 .... 直到剩下最后一个小朋友,可以不用表演。
思路一:使用模拟链表。
public static void lastRemaining(int n, int m){if(n < 1 || m < 1)return;List<Integer> list = new ArrayList<>();for(int i = 0; i < n; i++)list.add(i);int k = 0;while(list.size() > 1){k = k + m;k = k % (list.size()) - 1;if(k < 0){System.out.print(list.get(list.size() - 1)+" ");list.remove(list.size() - 1);k = 0;}else {System.out.print(list.get(k)+" " +"");list.remove(list.get(k));}}}
思路二:分析法
//https://blog.csdn.net/abc7845129630/article/details/52823135public static int lastRemaining_Solution(int n, int m) {if(n <= 0)return -1;int res = 0;for(int i = 2; i <= n; i++){res = (res + m) % i;// System.out.print(res + " ");}return res;}
69. 股票的最大利润
题目描述:假设把某股票的价格按照时间先后顺序存储在数组中,请问买卖交易该股票可能获得的利润是多少?例如一只股票在某些时间节点的价格为{9, 11, 8, 5,7, 12, 16, 14}。如果我们能在价格为5的时候买入并在价格为16时卖出,则能收获最大的利润11。
思路:使用贪心策略,假设第 i 轮进行卖出操作,买入操作价格应该在 i 之前并且价格最低。
public int maxProfit(int[] prices) {if (prices == null || prices.length == 0)return 0;int soFarMin = prices[0];int maxProfit = 0;for (int i = 1; i < prices.length; i++) {soFarMin = Math.min(soFarMin, prices[i]);maxProfit = Math.max(maxProfit, prices[i] - soFarMin);}return maxProfit;}
补充:多次买入和卖出详见LeetCode笔记。
70. 求1+2+3+...+n
题目描述:求1+2+3+...+n,要求不能使用乘除法、for、while、if、else、switch、case等关键字及条件判断语句(A?B:C)。
思路一:利用逻辑与的短路特性实现递归终止。当n==0时,(n>0)&&((sum+=sumSolution(n-1))>0)只执行前面的判断,为false,然后直接返回0;当n>0时,执行sum+=sumSolution(n-1),实现递归计算Sum_Solution(n)。
/*** 使用逻辑与的短路特性*/public static int sumSolution(int num){int sum = num;boolean b = (num > 0) && ((sum += sumSolution(num - 1)) > 0);return sum;}
思路二:利用异常退出递归。利用“除数不能为0”的机制,当num=0的时候,i = 1 / num的除数会变为0,就会抛出异常。
/*** 使用异常机制退出递归*/public static int sumSolution_1(int num){try {int i = 1 / num;return num + sumSolution_1(num - 1);}catch (Exception e){return 0;}}
71. 不用加减乘除做加法
&emtp; 题目描述:写一个函数,求两个整数之和,要求在函数体内不得使用+、-、*、/四则运算符号。
思路:
首先看十进制是如何做的: 5+7=12,三步走:
- 第一步:相加各位的值,不算进位,得到2。
- 第二步:计算进位值,得到10. 如果这一步的进位值为0,那么第一步得到的值就是最终结果。
- 第三步:重复上述两步,只是相加的值变成上述两步的得到的结果2和10,得到12。
同样我们可以用三步走的方式计算二进制值相加: 5-101,7-111- 第一步:相加各位的值,不算进位,得到010,二进制每位相加就相当于各位做异或操作,101^111。
- 第二步:计算进位值,得到1010,相当于各位做与操作得到101,再向左移一位得到1010,(101&111)<<1。
- 第三步重复上述两步, 各位相加 010^1010=1000,进位值为100=(010&1010)<<1。
继续重复上述两步:1000^100 = 1100,进位值为0,跳出循环,1100为最终结果。
/*** 使用循环*/public static int addTowNumber(int a, int b){int sum = 0;int carry = 0;do{sum = a ^ b;carry = (a & b) << 1;a = sum;b = carry;}while (b != 0);return a;}/*** 使用递归。递归会终止的原因是 (a & b) << 1 最右边会多一个 0,那么继续递归,进位最右边的 0 会慢慢增多,最后进位会变为 0,递归终止。*/public static int addTowNumbers_1(int a, int b) {return b == 0 ? a : addTowNumbers_1(a ^ b, (a & b) << 1);}
72. 构建乘积数组(待测试)
题目描述:给定一个数组A[0,1,...,n-1],请构建一个数组B[0,1,...,n-1],其中B中的元素B[i]=A[0]A[1]...*A[i-1]A[i+1]...*A[n-1]。不能使用除法。
思路一:矩阵法。
public int[] multiply(int[] A) {if(A == null || A.length < 2)return null;int length = A.length;int[] B = new int[length];B[0] = 1;//计算左三角for(int i = 1; i < length; i++){B[i] = B[i - 1] * A[i - 1];}//计算右三角 temp用来记录有三角每一行的值int temp = 1;for(int i = length - 2; i >= 0; i--){temp *= A[i + 1];B[i] *= temp;}return B;}//https://blog.csdn.net/zjkc050818/article/details/72800856
思路二:两次连乘法。
public int[] multiply(int[] A) {int n = A.length;int[] B = new int[n];for (int i = 0, product = 1; i < n; product *= A[i], i++) /* 从左往右累乘 */B[i] = product;for (int i = n - 1, product = 1; i >= 0; product *= A[i], i--) /* 从右往左累乘 */B[i] *= product;return B;}
73. 将字符串转换为整数(待验证)
题目描述:将一个字符串转换成一个整数,字符串不是一个合法的数值则返回 0,要求不能使用字符串转换整数的库函数。
思路:可能的输入:
- 带符号数
- 无符号数
- 零
- 空指针
- 超出表示范围 – 暂时仅仅是直接退出且设置最小 – 可以考虑此时抛个异常
- 非法输入,比如并不是一个0-9或者+ -组成的字符串
public static int strToInt(String str){if (str == null || str.length() == 0)return 0;boolean isNegative = str.charAt(0) == '-';int ret = 0;for (int i = 0; i < str.length(); i++) {char c = str.charAt(i);if (i == 0 && (c == '+' || c == '-')) /* 符号判定 */continue;if (c < '0' || c > '9') /* 非法输入 */return 0;ret = ret * 10 + (c - '0');}return isNegative ? -ret : ret;}
74. 树中两个节点的最低公共祖先(待验证)
题目描述:输入两个树节点,求它们的最低公共祖先。
思路:二叉查找树中,两个节点 p, q 的公共祖先 root 满足 root.val >= p.val && root.val <= q.val。

普通二叉树中,在左右子树中查找是否存在 p 或者 q,如果 p 和 q 分别在两个子树中,那么就说明根节点就是最低公共祖先。

/*** 二叉查找树*/public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {if (root == null)return root;if (root.val > p.val && root.val > q.val)return lowestCommonAncestor(root.left, p, q);if (root.val < p.val && root.val < q.val)return lowestCommonAncestor(root.right, p, q);return root;}/*** 普通二叉树*/public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {if (root == null || root == p || root == q)return root;TreeNode left = lowestCommonAncestor(root.left, p, q);TreeNode right = lowestCommonAncestor(root.right, p, q);return left == null ? right : right == null ? left : root;}
