@adamhand
2019-03-11T00:56:48.000000Z
字数 14101
阅读 1671
若干面试题
25匹马的角逐
问题是这样的:一共有25匹马,有一个赛场,赛场有5个赛道,就是说最多同时可以有5匹马一起比赛。假设每匹马都跑的很稳定,不用任何其他工具,只通过马与马之间的比赛,试问最少得比多少场才能知道跑得最快的5匹马。
注意: "假设每匹马都跑的很稳定" 的意思是在上一场比赛中A马比B马快,则下一场比赛中A马依然比B马快。
稍微想一下,可以采用一种 竞标赛排序(Tournament Sort)的思路。
思路一:一般思路,非最优
1. 第一步
首先将25匹马分成5组,并分别进行5场比赛之后得到的名次排列如下:
A组: [A1 A2 A3 A4 A5]
B组: [B1 B2 B3 B4 B5]
C组: [C1 C2 C3 C4 C5]
D组: [D1 D2 D3 D4 D5]
E组: [E1 E2 E3 E4 E5]
其中,每个小组最快的马为[A1、B1、C1、D1、E1]。
2. 第二步
将[A1、B1、C1、D1、E1]进行第6场,选出第1名的马,不妨设 A1>B1>C1>D1>E1. 此时第1名的马为A1。
3. 第三步
将[A2、B1、C1、D1、E1]进行第7场,此时选择出来的必定是第2名的马,不妨假设为B1。因为这5匹马是除去A1之外每个小组当前最快的马。
4. 第四步
进行第8场,选择[A2、B2、C1、D1、E1]角逐出第3名的马。
依次类推,第9,10场可以分别决出第4,5名的马。
因此,依照这种竞标赛排序思想,需要10场比赛是一定可以取出前5名的。
思路二:简化思路
仔细想一下,如果需要减少比赛场次,就一定需要在某一次比赛中同时决出2个名次,而且每一场比赛之后,有一些不可能进入前5名的马可以提前出局。
当然要做到这一点,就必须小心选择每一场比赛的马匹。我们在上面的方法基础上进一步思考这个问题,希望能够得到解决。
1. 第一步
首先利用5场比赛角逐出每个小组的排名次序是绝对必要的。
2. 第二步
第6场比赛选出第1名的马也是必不可少的。假如仍然是A1马(A1>B1>C1>D1>E1)。那么此时我们可以得到一个重要的结论:有一些马在前6场比赛之后就决定出局的命运了(下面绿色字体标志出局)。

3. 第三步
第7场比赛是关键,能否同时决出第2,3名的马呢?我们首先做下分析:
在上面的方法中,第7场比赛[A2、B1、C1、D1、E1]是为了决定第2名的马。但是在第6场比赛中我们已经得到(B1>C1>D1>E1),试问,有B1在的比赛,C1、D1、E1还有可能争夺第2名吗? 当然不可能,也就是说第2名只能在A2、B1中出现。实际上只需要2条跑道就可以决出第2名,剩下C1、D1、E1的3条跑道都只能用来凑热闹的吗?
能够优化的关键出来了,我们是否能够通过剩下的3个跑道来决出第3名呢?当然可以,我们来进一步分析第3名的情况:
● 如果A2>B1(即第2名为A2),那么根据第6场比赛中的(B1>C1>D1>E1)。 可以断定第3名只能在A3和B1中产生。
● 如果B1>A2(即第2名为B1),那么可以断定的第3名只能在A2, B2,C1 中产生。
好了,结论也出来了,只要我们把[A2、B1、A3、B2、C1]作为第7场比赛的马,那么这场比赛的第2,3名一定是整个25匹马中的第2,3名。
我们在这里列举出第7场的2,3名次的所有可能情况:
① 第2名=A2,第3名=A3
② 第2名=A2,第3名=B1
③ 第2名=B1,第3名=A2
④ 第2名=B1,第3名=B2
⑤ 第2名=B1,第3名=C1
4. 第四步
第8场比赛很复杂,我们要根据第7场的所有可能的比赛情况进行分析。
① 第2名=A2,第3名=A3。那么此种情况下第4名只能在A4和B1中产生。
● 如果第4名=A4,那么第5名只能在A5、B1中产生。
● 如果第4名=B1,那么第5名只能在A4、B2、C1中产生。
不管结果如何,此种情况下,第4、5名都可以在第8场比赛中决出。其中比赛马匹为[A4、A5、B1、B2、C1]。
② 第2名=A2,第3名=B1。那么此种情况下第4名只能在A3、B2、C1中产生。
● 如果第4名=A3,那么第5名只能在A4、B2、C1中产生。
● 如果第4名=B2,那么第5名只能在A3、B3、C1中产生。
● 如果第4名=C1,那么第5名只能在A3、B2、C2、D1中产生。
那么,第4、5名需要在马匹[A3、B2、B3、C1、A4、C2、D1]七匹马中产生,则必须比赛两场才行,也就是到第9场角逐出全部的前5名。
③ 第2名=B1,第3名=A2。那么此种情况下第4名只能在A3、B2、C1中产生。
情况和②一样,必须角逐第9场
④ 第2名=B1,第3名=B2。 那么此种情况下第4名只能在A2、B3、C1中产生。
● 如果第4名=A2,那么第5名只能在A3、B3、C1中产生。
● 如果第4名=B3,那么第5名只能在A2、B4、C1中产生。
● 如果第4名=C1,那么第5名只能在A2、B3、C2、D1中产生。
那么,第4、5名需要在马匹[A2、B3、B4、C1、A3、C2、D1]七匹马中产 生,则必须比赛两场才行,也就是到第9场角逐出全部的前5名。
⑤ 第2名=B1,第3名=C1。那么此种情况下第4名只能在A2、B2、C2、D1中产生。
● 如果第4名=A2,那么第5名只能在A3、B2、C2、D1中产生。
● 如果第4名=B2,那么第5名只能在A2、B3、C2、D1中产生。
● 如果第4名=C2,那么第5名只能在A2、B2、C3、D1中产生。
● 如果第4名=D1,那么第5名只能在A2、B2、C2、D2、E2中产生。
那么,第4、5名需要在马匹[A2、B2、C2、D1、A3、B3、C3、D2、E1]九匹马中 产 生,因此也必须比赛两场,也就是到第9长决出胜负
总结:最好情况可以在第8场角逐出前5名,最差也可以在第9场搞定。
参考
微信扫二维码过程,后台的实现
- 第一步:用户 A 访问微信网页版,微信服务器为这个会话生成一个全局唯一的 ID,上面的 URL 中 obsbQ-Dzag== 就是这个 ID,此时系统并不知道访问者是谁。
- 第二步:用户A打开自己的手机微信并扫描这个二维码,并提示用户是否确认登录。
- 第三步:手机上的微信是登录状态,用户点击确认登录后,手机上的微信客户端将微信账号和这个扫描得到的 ID 一起提交到服务器
- 第四步:服务器将这个 ID 和用户 A 的微信号绑定在一起,并通知网页版微信,这个 ID 对应的微信号为用户 A,网页版微信加载用户 A 的微信信息,至此,扫码登录全部流程完成。
参考 微信扫码登录实现原理
电脑的开机过程
电脑的开机过程可以分为四个阶段:BIOS启动、主引导记录、硬盘启动和操作系统启动。
第一阶段:BIOS启动
BIOS是一种固件,被写在ROM中,计算机通电后,第一件事就是读取它。
硬件自检
BIOS程序首先检查,计算机硬件能否满足运行的基本条件,这叫做"硬件自检"(Power-On Self-Test),缩写为POST。
如果硬件出现问题,主板会发出不同含义的蜂鸣,启动中止。如果没有问题,屏幕就会显示出CPU、内存、硬盘等信息。
启动顺序
硬件自检完成后,BIOS把控制权转交给下一阶段的启动程序。
第二阶段:主引导记录
BIOS按照"启动顺序",把控制权转交给排在第一位的储存设备。
这时,计算机读取该设备的第一个扇区,也就是读取最前面的512个字节。如果这512个字节的最后两个字节是0x55和0xAA,表明这个设备可以用于启动;如果不是,表明设备不能用于启动,控制权于是被转交给"启动顺序"中的下一个设备。
这最前面的512个字节,就叫做"主引导记录"(Master boot record,缩写为MBR)。
第三阶段:硬盘启动
到了这个时期,计算机的控制权就要转交给硬盘的某个分区了,这里又分成三种情况。
第四阶段:操作系统
控制权转交给操作系统后,操作系统的内核首先被载入内存。
以Linux系统为例,先载入/boot目录下面的kernel。内核加载成功后,第一个运行的程序是/sbin/init。它根据配置文件(Debian系统是/etc/initab)产生init进程。这是Linux启动后的第一个进程,pid进程编号为1,其他进程都是它的后代。
然后,init线程加载系统的各个模块,比如窗口程序和网络程序,直至执行/bin/login程序,跳出登录界面,等待用户输入用户名和密码。
至此,全部启动过程完成。
参考:
计算机是如何启动的?
0 1概率问题
给一个函数,返回 0 和 1,概率为 p 和 1-p,请你实现一个函数,使得返回 01 概率一样。
假如说给定的函数为random(),i=random(),j=random()。则i=0的概率为p,i=1的概率为1-p,j也是如此。如果想构造一个相等概率,可以考虑将p和1-p相乘。如下:
11 p*p 10 p*(1-p)01 (1-p)*p 00 (1-p)*(1-p)
public int random_1(){int i = random();int j = random();int result;while(true){if(i == 0 && j == 1){result = 0;break;}else if(i == 1 && j == 0){result = 1;break;}else{continue;}}return result;}
url去重
题目一:给定a、b两个文件,各存放50亿个url,每个url各占用64字节,内存限制是4G,如何找出a、b文件共同的url?
可以估计每个文件的大小为5G*64=300G,远大于4G。所以不可能将其完全加载到内存中处理。考虑采取分而治之的方法。
具体做法是:
- 遍历文件a,对每个url求取hash(url)%1000,然后根据所得值将url分别存储到1000个小文件(设为a0,a1,...a999)当中。这样每个小文件的大小约为300M。然后将这些文件存在硬盘上。
- 遍历文件b,采取和a相同的方法将url分别存储到1000个小文件(b0,b1....b999)中。
- 这时,所有可能相同的url都在对应的小文件(a0 vs b0, a1 vs b1....a999 vs b999)当中,不对应的小文件(比如a0 vs b99)不可能有相同的url。然后我们只要求出1000对小文件中相同的url即可。 比如对于a0 vs b0,我们可以遍历a0,将其中的url存储到hash_set当中(在内存中操作)。然后遍历b0,如果url在hash_map中,则说明此url在a和b中同时存在,保存到存放结果的文件中即可。
a文件有10 亿个 url,每个 url 大小小于 56B,要求去重,内存只给你4G
同样估算一下,需要的存储空间:10G*56B=56G,4G也是放不下的,所以开始考虑分治。
- 遍历文件a,对每个url求取hash(url)%1000,然后根据所得值将url分别存储到1000个小文件(设为a0,a1,...a999)当中。这样每个小文件的大小约为300M。然后将这些文件存在硬盘上。
- 依次将文件读取到内存中,遍历小文件,还是采用hashset来去重。
“软链接”和“硬链接”的区别
首先得看一下inode的概念,inode 是 UNIX 操作系统中的一种数据结构,其本质是结构体,可以将其类比做C语言中的指针,它指向了物理硬盘的一个区块,每当创建一个文件的时候,就会为文件创建一个inode,标志着该文件的物理位置。inode相同的节点被Unix视为同一个文件。
- 硬链接:创建硬链接的命令是
ln aa bb,此时,aa和bb之间就创建了硬链接,它们的inode是相同的,aa和bb是同一份文件的两个名字,修改其中一个文件,另个一个文件也会跟着改变。但是如果删除一个,另外一个不受影响,因为它 inode 所指向的区块由于有一个硬链接在指向它,所以这个区块仍然有效,并且可以访问到。 - 软链接,又叫符号链接。创建软连接的命令是
ln -s aa bb,此时,bb就是aa的软连接。此时aa和bb是两个文件,它们有不同的inode。软连接相当于一个快捷方式,它存储着其代表的文件的绝对路径。如果bb被删除了,aa仍然存在,但是它指向的是一个无效的链接。
参考:linux硬链接和软链接的区别 5分钟让你明白“软链接”和“硬链接”的区别 硬链接和软链接的区别
写一段程序连接数据库并查询一条语句
public class javaTest {public static void main(String[] args) throws ClassNotFoundException, SQLException {String URL="jdbc:mysql://127.0.0.1:3306/imooc?useUnicode=true&characterEncoding=utf-8";String USER="root";String PASSWORD="tiger";//1.加载驱动程序Class.forName("com.mysql.jdbc.Driver");//2.获得数据库链接Connection conn=DriverManager.getConnection(URL, USER, PASSWORD);//3.通过数据库的连接操作数据库,实现增删改查(使用Statement类)Statement st=conn.createStatement();ResultSet rs=st.executeQuery("select * from user");//4.处理数据库的返回结果(使用ResultSet类)while(rs.next()){System.out.println(rs.getString("user_name")+" "+rs.getString("user_password"));}//关闭资源rs.close();st.close();conn.close();}}
死锁和银行家算法
死锁
要想说银行家,首先得说死锁问题,因为银行家算法就是为了死锁避免提出的。那么,什么是死锁?简单的举个例子:俩人吃饺子,一个人手里拿着酱油,一个人手里拿着醋,拿酱油的对拿着醋的人说:“你把醋给我,我就把酱油给你”;拿醋的对拿着酱油的人说:“不,你把酱油给我,我把醋给你。”
于是,俩人就这样杠上了,永远吃不上饺子了。这就是死锁。
说的学术化一点,发生死锁必须满足四个条件:
- 互斥:至少有一个资源必须处于非共享模式,即一次只有一个进程使用。如果另一进程申请该资源,那么申请进程必须等到该资源被释放为止。
- 占有并等待:一个进程必须占有至少一个资源,并等待另一资源,而该资源为其他进程所占有。
- 非抢占:资源不能被抢占,即资源只能在进程完成任务后自动释放。
- 循环等待:有一组等待进程{P0,P1,···,Pn},P0等待的资源为P1所占有,P1等待的资源为P2所占有,...,Pn-1等待的资源为Pn所占有,Pn等待的资源为P0所占有。
注:所有4个条件必须同时满足才会出现死锁。循环等待意味着占有并等待,这样四个条件并不完全独立。
那么,为啥这个算法叫银行家算法?因为这个算法同样可以用于银行的贷款业务。让我们考虑下面的情况。
一个银行家共有20亿财产
第一个开发商:已贷款15亿,资金紧张还需3亿。
第二个开发商:已贷款5亿,运转良好能收回。
第三个开发商:欲贷款18亿
一个常规的想法就是先等着第二个开发商把钱收回来,然后手里有了5个亿,再把3个亿贷款给第一个开发商,等第一个开发商收回来18个亿,然后再把钱贷款给第三个开发商。
第一个例子中:醋和酱油是资源,这俩吃饺子的是进程;第二个例子中:银行家是资源,开发商是进程。在操作系统中,有内存,硬盘等等资源被众多进程渴求着,那么这些资源怎么分配给他们才能避免“银行家破产”的风险?
银行家算法
当一个进程申请使用资源的时候,银行家算法通过先 试探 分配给该进程资源,然后通过安全性算法判断分配后的系统是否处于安全状态,若不安全则试探分配作废,让该进程继续等待。
安全序列
安全序列是指对当前申请资源的进程排出一个序列,保证按照这个序列分配资源完成进程,不会发生“酱油和醋”的尴尬问题。
假设有进程P1,P2,.....Pn,则安全序列要求满足:Pi(1<=i<=n)需要资源 <= 剩余资源 + 分配给Pj(1 <= j < i)资源
为什么等号右边还有已经被分配出去的资源?想想银行家那个问题,分配出去的资源就好比第二个开发商,人家能还回来钱,咱得把这个考虑在内。
定义下面的数据结构
int n,m; //系统中进程总数n和资源种类总数mint Available[1..m]; //资源当前可用总量int Allocation[1..n,1..m]; //当前给分配给每个进程的各种资源数量int Need[1..n,1..m]; //当前每个进程还需分配的各种资源数量int Work[1..m]; //当前可分配的资源bool Finish[1..n]; //进程是否结束
安全判定算法
- 初始化
Work = Available(动态记录当前剩余资源)Finish[i] = false(设定所有进程均未完成)
- 查找可执行进程Pi(未完成但目前剩余资源可满足其需要,这样的进程是能够完成的)
Finish[i] = falseNeed[i] <= Work如果没有这样的进程Pi,则跳转到第4步
- (若有则)Pi一定能完成,并归还其占用的资源,即:
Finish[i] = trueWork = Work +Allocation[i]GOTO 第2步,继续查找
- 如果所有进程Pi都是能完成的,即Finish[i]=ture则系统处于安全状态,否则系统处于不安全状态
伪代码:
Boolean Found;Work = Available; Finish[1..n] = false;while(true){//不断的找可执行进程Found = false;for(i=1; i<=n; i++){if(Finish[i]==false && Need[i]<=Work){Work = Work + Allocation[i];//把放出去的贷款也当做自己的资产Finish[i] = true;Found = true;}}if(Found==false)break;}for(i=1;i<=n;i++)if(Finish[i]==false)return “deadlock”; //如果有进程是完不成的,那么就是有死锁
例子
举个实际例子,假设下面的初始状态:
| process | Allocation | Need | Available |
|---|---|---|---|
| A B C | A B C | A B C | |
| P0 | 0 1 0 | 7 4 3 | 3 3 2 |
| P1 | 2 0 0 | 1 2 2 | |
| P2 | 3 0 2 | 6 0 0 | |
| P3 | 2 1 1 | 0 1 1 | |
| P4 | 0 0 2 | 4 3 1 |
上表中process表示需要申请资源的进程,allocation表示已经分配的资源,need表示进程还需要的资源,available表示可用的资源。一共有三个资源A、B、C,五个进程P0、P1、P2、P3、P4。
- 首先,进入算法第一步,初始化。Work = Available = [3 3 2]
- 看P0:P0的Need为[7 4 3],Available不能满足,于是跳过去
- P1的Need为[1 2 2]可以满足,我们令Work = Allocation[P1] + Work。此时Work = [5 3 2]
- 再看P2,P2的Need为[6 0 0],那么现有资源不满足。跳过去。
- 看P3,那么看P3,Work可以满足。那么令Work = Allocation[P3] + Work,此时Work = [7 4 3]
- 再看P4,Work可以满足。令Work = Allocation[P4] + Work ,此时Work = [7 4 5]
- 到此第一轮循环完毕,由于找到了可用进程,那么进入第二轮循环。
- 看P0,Work此时可以满足。令Work = Allocation[P0] + Work ,此时Work = [7 5 5]
- 再看P2,此时Work可以满足P2。令Work = Allocation[P2] + Work , 此时Work = [10 5 7]
至此,算法运行完毕。找到安全序列<P1,P3,P4,P0,P2>,证明此时没有死锁危险。(安全序列未必唯一)
资源请求算法
之前说完了怎么判定当前情况是否安全,下面就是说当有进程新申请资源的时候如何处理。我们将第i个进程请求的资源数记为Requests[i]
算法流程:
- 如果Requests[i]<=Need[i],则转到第二步。否则,返回异常。这一步是控制进程申请的资源不得大于需要的资源
- 如果Requests[i]<=Available,则转到第三步,否则Pi等待资源。
- 如果满足前两步,那么做如下操作:
Available = Available -Requests[i]Allocation = Allocation[i]+Requests[i]Need[i]=Need[i]-Requests[i]调用安全判定算法,检查是否安全if(安全){申请成功,资源分配}else{申请失败,资源撤回。第三步前几个操作进行逆操作}
参考 一句话+一张图说清楚——银行家算法 银行家算法学习笔记 银行家算法---------概念&举例 [OS] 死锁相关知识点以及银行家算法详解
TCP SYN洪泛攻击的原理及防御方法
SYN Flood (SYN洪水) 是种典型的DoS (Denial of Service,拒绝服务,攻击者使用某种方式让目标机器停止提供服务;还有一种DDoS(Distributed Denial of Service)) 攻击。SYN洪泛攻击的基础是依靠TCP建立连接时三次握手的设计。
描述如下:
假设B通过某TCP端口提供服务,B在收到A的SYN消息时,积极的反馈了SYN-ACK消息,使连接进入半开状态,因为B不确定自己发给A的SYN-ACK消息或A反馈的ACK消息是否会丢在半路,所以会给每个待完成的半开连接都设一个Timer,如果超过时间还没有收到A的ACK消息,则重新发送一次SYN-ACK消息给A,直到重试超过一定次数时才会放弃。
B为帮助A能顺利连接,需要分配内核资源维护半开连接,那么当B面临海量的大忽悠A时,SYN Flood攻击就形成了。攻击方A可以控制肉鸡向B发送大量SYN消息但不响应ACK消息,或者干脆伪造SYN消息中的Source IP,使B反馈的SYN-ACK消息石沉大海,导致B被大量注定不能完成的半开连接占据,直到资源耗尽,停止响应正常的连接请求。
可行的解决方案:
- 修改重试次数
- 限制单IP并发数
参考 服务器遭到SYN攻击怎么办?如何防御SYN攻击? 什么是SYN Flood攻击? TCP SYN洪泛攻击的原理及防御方法
mybatis缓存
mybatis和mysql8.0之前的缓存机制有点像。
mybatis的缓存分为两级:一级缓存、二级缓存
- 一级缓存是SqlSession级别的缓存,缓存的数据只在SqlSession(SqlSession是MyBatis的关键对象,是执行持久化操作的独享,类似于JDBC中的Connection)内有效
- 二级缓存是mapper级别的缓存,同一个namespace公用这一个缓存,所以对SqlSession是共享的
一级缓存:
mybatis的一级缓存是SqlSession级别的缓存,在操作数据库的时候需要先创建SqlSession会话对象,在对象中有一个HashMap用于存储缓存数据,此HashMap是当前会话对象私有的,别的SqlSession会话对象无法访问。
public class PerpetualCache implements Cache{private String id;private Map<Object, Object> cache = new HashMap<Object, Object>();...}
具体流程:
- 第一次执行select完毕会将查到的数据写入SqlSession内的HashMap中缓存起来
- 第二次执行select会从缓存中查数据,如果select相同切传参数一样,那么就能从缓存中返回数据,不用去数据库了,从而提高了效率
注意事项:
- 如果SqlSession执行了DML操作(insert、update、delete),并commit了,那么mybatis就会清空当前SqlSession缓存中的所有缓存数据,这样可以保证缓存中的存的数据永远和数据库中一致,避免出现脏读
- 当一个SqlSession结束后那么他里面的一级缓存也就不存在了,mybatis默认是开启一级缓存,不需要配置
- mybatis的缓存是基于[namespace:sql语句:参数]来进行缓存的,意思就是,SqlSession的HashMap存储缓存数据时,是使用[namespace:sql:参数]作为key,查询返回的语句作为value保存的。例如:-1242243203:1146242777:winclpt.bean.userMapper.getUser:0:2147483647:select * from user where id=?:19
二级缓存:
二级缓存是mapper级别的缓存,也就是同一个namespace的mappe.xml,当多个SqlSession使用同一个Mapper操作数据库的时候,得到的数据会缓存在同一个二级缓存区域
二级缓存默认是没有开启的。需要在setting全局参数中配置开启二级缓存
conf.xml:<settings><setting name="cacheEnabled" value="true"/>默认是false:关闭二级缓存<settings>
在userMapper.xml中配置:
<cache eviction="LRU" flushInterval="60000" size="512" readOnly="true"/>当前mapper下所有语句开启二级缓存
这里配置了一个LRU缓存,并每隔60秒刷新,最大存储512个对象,而却返回的对象是只读的
若想禁用当前select语句的二级缓存,添加useCache="false"修改如下:
<select id="getCountByName" parameterType="java.util.Map" resultType="INTEGER" statementType="CALLABLE" useCache="false">
具体流程:
- 当一个sqlseesion执行了一次select后,在关闭此session的时候,会将查询结果缓存到二级缓存
- 当另一个sqlsession执行select时,首先会在他自己的一级缓存中找,如果没找到,就回去二级缓存中找,找到了就返回,就不用去数据库了,从而减少了数据库压力提高了性能
注意事项:
- 如果SqlSession执行了DML操作(insert、update、delete),并commit了,那么mybatis就会清空当前mapper缓存中的所有缓存数据,这样可以保证缓存中的存的数据永远和数据库中一致,避免出现脏读
- mybatis的缓存是基于[namespace:sql语句:参数]来进行缓存的,意思就是,SqlSession的HashMap存储缓存数据时,是使用[namespace:sql:参数]作为key,查询返回的语句作为value保存的。例如:-1242243203:1146242777:winclpt.bean.userMapper.getUser:0:2147483647:select * from user where id=?:19
Redis 与 Memcached的区别
- 数据类型:Memcached 仅支持字符串类型,而 Redis 支持五种不同的数据类型,可以更灵活地解决问题。
- 数据持久化:Redis 支持两种持久化策略:RDB 快照和 AOF 日志,而 Memcached 不支持持久化。
- 分布式:Memcached 不支持分布式,只能通过在客户端使用一致性哈希来实现分布式存储,这种方式在存储和查询时都需要先在客户端计算一次数据所在的节点。Redis Cluster 实现了分布式的支持。
正向代理和反向代理的区别
为什么使用代理服务器?
提高访问速度
由于目标主机返回的数据会存放在代理服务器的硬盘中,因此下一次客户再访问相同的站点数据时,会直接从代理服务器的硬盘中读取,起到了缓存的作用,尤其对于热门网站能明显提高访问速度。防火墙作用
由于所有的客户机请求都必须通过代理服务器访问远程站点,因此可以在代理服务器上设限,过滤掉某些不安全信息。同时正向代理中上网者可以隐藏自己的IP,免受攻击。突破访问限制
互联网上有许多开发的代理服务器,客户机在访问受限时,可通过不受限的代理服务器访问目标站点,通俗说,我们使用的翻墙浏览器就是利用了代理服务器,可以直接访问外网。
正向代理
正向代理(forward proxy),一个位于客户端和原始服务器之间的服务器,为了从原始服务器取得内容,客户端向代理发送一个请求并制定目标(原始服务器),然后代理向原始服务器转发请求并将获得的内容返回给客户端,客户端才能使用正向代理。我们平时说的代理就是指正向代理。
简单一点:A向C借钱,由于一些情况不能直接向C借钱,于是A想了一个办法,他让B去向C借钱,这样B就代替A向C借钱,A就得到了C的钱,C并不知道A的存在,B就充当了A的代理人的角色。
反向代理
反向代理(Reverse Proxy),以代理服务器来接受internet上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给internet上请求的客户端,此时代理服务器对外表现为一个反向代理服务器。
理解起来有些抽象,可以这么说:A向B借钱,B没有拿自己的钱,而是悄悄地向C借钱,拿到钱之后再交给A,A以为是B的钱,他并不知道C的存在。
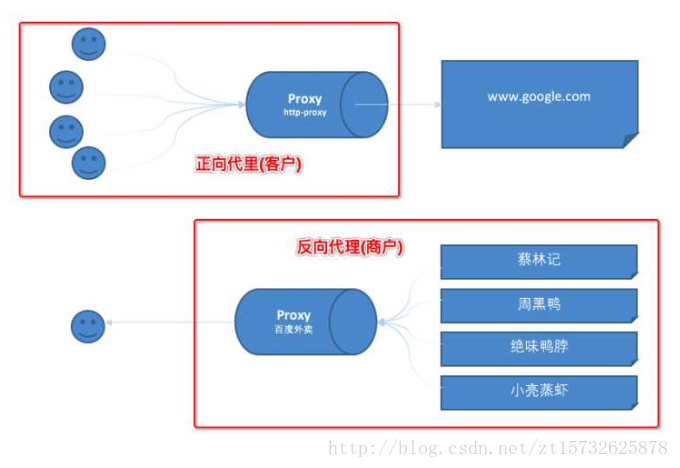
正向代理–HTTP代理为多个人提供翻墙服务;反向代理–百度外卖为多个商户提供平台给某个用户提供外卖服务。
正向代理和反向代理的区别
- 位置不同
正向代理,架设在客户机和目标主机之间;
反向代理,架设在服务器端; - 代理对象不同
正向代理,代理客户端,服务端不知道实际发起请求的客户端;
反向代理,代理服务端,客户端不知道实际提供服务的服务端; - 用途不同
正向代理,为在防火墙内的局域网客户端提供访问Internet的途径;
反向代理,将防火墙后面的服务器提供给Internet访问; - 安全性不同
正向代理允许客户端通过它访问任意网站并且隐藏客户端自身,因此必须采取安全措施以确保仅为授权的客户端提供服务;
反向代理都对外都是透明的,访问者并不知道自己访问的是哪一个代理。
正向代理的应用
- 访问原来无法访问的资源
- 用作缓存,加速访问速度
- 对客户端访问授权,上网进行认证
- 代理可以记录用户访问记录(上网行为管理),对外隐藏用户信息
反向代理的应用
- 保护内网安全
- 负载均衡
- 缓存,减少服务器的压力。Nginx作为最近较火的反向代理服务器,安装在目的主机端,主要用于转发客户机请求,后台有多个http服务器提供服务,nginx的功能就是把请求转发给后台的服务器,决定哪台目标主机来处理当前请求。
参考:谈一谈正向代理和反向代理
sql注入
什么是sql注入
所谓SQL注入式攻击,就是攻击者把SQL命令插入到Web表单的输入域或页面请求的查询字符串,欺骗服务器执行恶意的SQL命令。
举个例子,假如有一个网站登录时需要用户名和密码,不难想象后台查询的sql语法为:
select * from table where name='xx' and password='xxx';
这时,如果在用户名栏中填入' or 1=1; --,密码栏随便填,后台语法将变为:
select * from table where name='' or 1=1; --and password='xxx';
--在是sql语句的注释符号,同样#也是,所以上述语句其实就等同于:
select * from table where name='' or 1=1;
即使name字段为空,但是1=1总是成立的,所以总能返回数据,此时如果程序员在程序中根据结果是否为空来作为用户是否存在的判断,那么势必会出错。
防sql注入原理
使用转义字符
Mysql特殊字符指在mysql中具有特殊含义的字符,除了%和_是mysql特有的外,其他的和我们在C语句中接触的特殊字符一样。
| 特殊字符 | 转义字符 | 特殊意义 |
|---|---|---|
| \0 | \0 | 字符串结束符NUL |
| ' | \' | 单引号 |
| " | \" | 双引号 |
| \b | \b | 退格 |
| \n | \n | 换行 |
| \r | \r | 回车 |
| \Z | \Z | Control+Z |
| \ | \ | 反斜杠 |
| % | \% | 百分号,模糊查询中匹配任意个任意字符 |
| _ | _ | 下划线,模糊查询中匹配单个任意字符 |
对于%和_这2个只在模糊查询条件中有特殊含义,而在普通字符串中没有其他含义的字符,需要根据字符使用在SQL语句中的具体位置来决定是否需要处理。如我们要查询memberName包含t_st的用户信息:
select * from member where memberName like '%t_st%;
如果不对_进行转义处理则会查询出:
testtasttbstt_st
Prepared SQL Statement(预处理语句)
语:法
# 定义预处理语句PREPARE stmt_name FROM preparable_stmt;# 执行预处理语句EXECUTE stmt_name [USING @var_name [, @var_name] ...];# 删除(释放)定义{DEALLOCATE | DROP} PREPARE stmt_name;
PREPARE用来发送一条sql给mysql服务器,mysql服务器会解析这条sql。
EXECUTE用来将参数传递给PREPARE语句,mysql服务器不会解析这条sql,只会把execute的参数当做纯参数赋值给语句一。哪怕参数中有sql命令也不会被执行,从而实现防治sql注入。
SET @sql = "SELECT * FROM member WHERE memberName like ?";SET @param = '%t_st%';PREPARE stmt FROM @sql;EXECUTE stmt using @param;DEALLOCATE PREPARE stmt;
使用这种方法需要注意以下2点:
?占位符不能用在字符串中,上面例子如果写成下面这样是错误的。
SET @sql = "SELECT * FROM member WHERE memberName like '%?%'";SET @param = 't_st';PREPARE stmt FROM @sql;EXECUTE stmt using @param;DEALLOCATE PREPARE stmt;
EXECUTE stmt USING @param;中使用的@param变量,是会话(session)级别的变量。该变量的作用域至整个连接,连接断开之后该变量才会释放。重复使用相同变量时要留意了。
参考:
sql注入,一个例子让你知道什么是sql注入
什么是SQL注入
MySQL数据库防SQL注入原理
SQL注入原理及防范
MySQL的SQL预处理(Prepared)
MySQL pdo预处理能防止sql注入的原因
