@ybtang21c
2025-10-19T02:22:12.000000Z
字数 42614
阅读 10092
6.2 参数估计
高等工程数学 讲义 2025AU
参数估计的数学描述
- 设总体 的分布函数为 ,其中 是 未知参数.
- 的取值范围已知,即已知 .
- 称为 参数空间.
- 从总体中抽取样本 .
- 根据该样本对未知参数 做出估计.
参数的点估计(Point Estimation)
- 矩估计
- 最大似然估计
- Bayes估计
- 最小二乘估计
6.2.1 矩估计(Method of Moments)
基本思想:
- 用样本矩近似总体矩,进而求解其中的参数(估计)值.
- 最初由俄国数学家 Pafnuty Chebyshev 在 1887 年提出.
理论基础:Khinchin大数定律
- 设 是独立同分布的随机变量列,若 的数学期望 存在,则 服从大数定律.
- 即:对任意的 , .
- 随着样本容量的增加,样本矩将越来越接近于总体矩.
Pafnuty Chebyshev
- Пафну́тий Льво́вич Чебышёв (1821-1894)
- considered to be a
founding father of Russian mathematics. Among his well-known students were the mathematicians Dmitry Grave, Aleksandr Korkin,Aleksandr Lyapunov, andAndrei Markov. - Chebyshev Inequality:
矩
设 是来自总体 的样本
- 总体 阶矩:.
- 样本 阶矩:.
- 理论上,总体 阶矩和样本 阶矩并不相等.
- 前者是未知的常数,是确定的.
- 后者是变量,是存在波动的.
- 但由 Khinchin 大数定律,.
矩估计的求解
设 是来自总体 的简单随机样本,其中 是待估的未知参数.
- 求总体 的前 阶矩
- 求样本的前 阶矩 .
- 解方程(组):,
- 得 .
- 称 为 的 矩估计量 (Moment Estimator).
- 称 为 的 矩估计值 (Moment Estimate).
Poisson 强度的矩估计
例 设 是来自总体 的样本,求参数 的矩估计.
解:Poisson分布的分布律 .- 总体一阶矩和样本一阶矩分别为 ,.
- 令 ,求得参数 的矩估计(量)为 .
总体方差的矩估计
引理 设 是来自总体 的样本,设总体 的二阶矩存在,则
- 样本均值是总体均值 的矩估计.
- 样本方差 是总体方差 的矩估计.
例 袋中有红球和黑球共 只. 现从袋中有放回地次取个球出来观测其颜色,直到取到红球为止,此时记取球的总次数为 . 若这样的试验一共进行了 次,得到的数据分别是
试求袋中红球数的矩估计.
解: 设袋中共有 个红球. 表示第一次摸到红球时摸球的总次数. 则
进而 .
样本矩 .
令 ,即 ,解得 .
综上,袋中的红球数约为 .
对矩估计法的评价
- 原理直观,是一种古老的参数估计方法.
- 只用到总体矩,方法简单.
- 如果总体矩不存在,则无法求参数的点估计.
- 例如,设总体服从Cauchy分布,其密度函数为 ,因为总体的数学期望不存在,故 的矩估计不存在!
没有用到总体的分布形式,总体包含的信息没有得到充分利用.基于大数定律,在大样本下矩估计才有较好的效果.
均匀分布参数的矩估计
例 设 是来自总体 的简单随机样本,其中 是未知参数,求 的矩估计.
提示:,.- 令 , 解得
讨论: 假设有如下来自 的观测值
- 计算得到 ,.
- 进而得到 .
- 数据中的最大和最小值分别是 和 ,对均匀分布而言,似乎这才是更合理的参数估计值.
问题:是否有比矩估计更加“合理”的估计?
6.2.2 最大似然估计
最大似然
基本思想
- 随机事件 的概率 由 的分布 确定, 而分布又由参数 决定.
- 在已经掌握了样本,也即具体发生的事件的情况下,有理由相信这个已经发生的事件就是最有可能发生的事件.
- 基于“
最大可能”的思想来确定参数的估值,就是要找一个估计值 ,使得已发生事件的概率最大.
- The logic of maximum likelihood is both intuitive and flexible, and as such the method has become a dominant means of statistical inference.[1]
最大似然估计(Maximum Likelihood Estimation)
- Early users of maximum likelihood were
C.F. Gauss,P.S. Laplace, etc. - However, its widespread use rose between
1912 and 1922when Ronald Fisher recommended, widely popularized, and carefully analyzed maximum-likelihood estimation.
R. A. Fisher
- Sir Ronald Aylmer Fisher (1890-1962)
- 英国统计学家、演化生物学家与遗传学家,
现代统计学与现代进化论的奠基者之一.
- 英国统计学家、演化生物学家与遗传学家,
- "a genius who almost single-handedly created the foundations for modern statistical science".
- "the single most important figure in 20th century statistics".
- "the greatest of Darwin’s successors".
例 一老战士与一新战士的射击命中率分别为 和 ,在射击训练中每人各打三枪. 训练结束后现场留有一张靶纸. 如果靶纸上有 个弹孔,试问这张靶纸最有可能是谁的?如果靶纸上只有 个弹孔,试问这张靶纸又最有可能是谁的?
分析: 设靶纸上出现的弹孔数为 ,则 服从二项分布
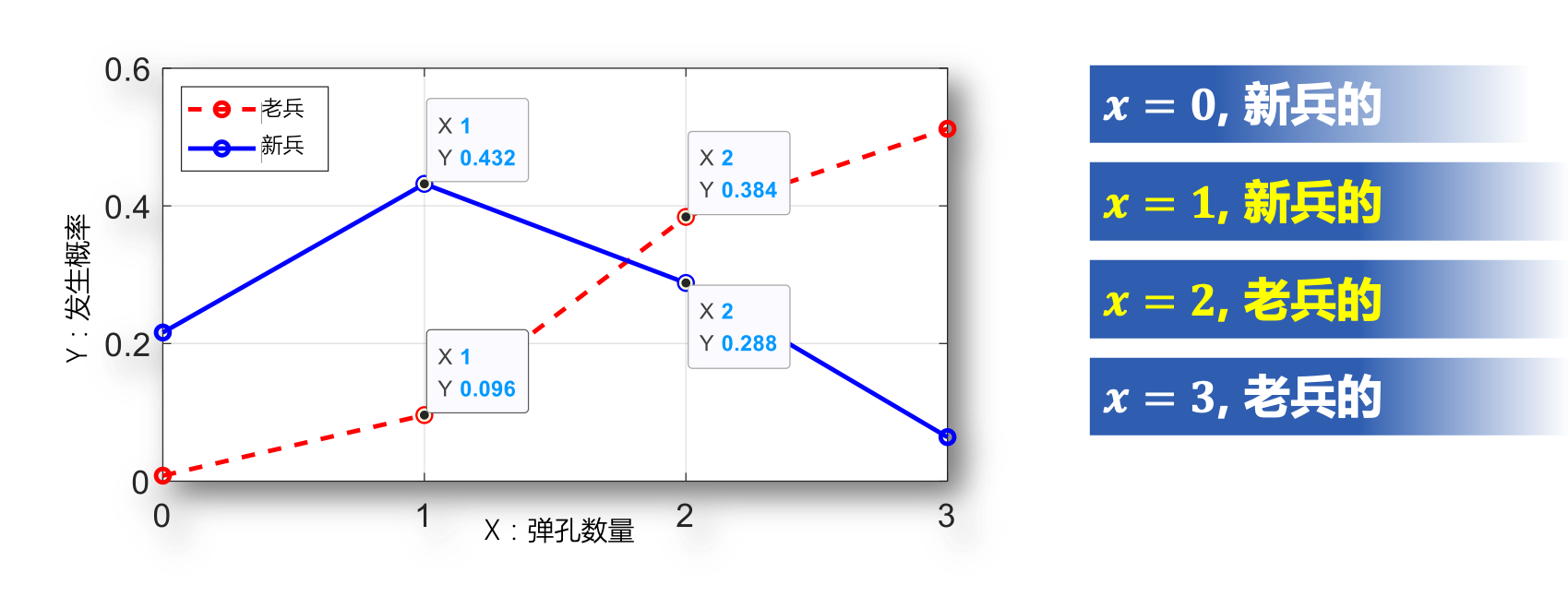
最大似然估计
设 是来自总体 的样本, 为其观测值,记
称 是 似然函数 (Likelihood).
- 若统计量 满足 ,则称其为 的 最大似然估计(量) (Maximun Likelihood Estimator,简写:MLE).
- 最大似然的思想用一句话可以概括为:
参数看上去最像什么值,就用这个值作为参数的估计.
- 最大似然的思想用一句话可以概括为:
均匀分布参数的极大似然估计
例 设 是总体 的简单随机样本,试求参数 和 的 MLE.
提示:
- 似然函数,
- 其中 .
- 令 ,从该方程显然无法直接求得 MLE.
- 考虑到参数的取值范围, 的 MLE 应该是 .
指数分布参数的最大似然估计
例 设 是来自总体 的简单随机样本,其中 是未知参数,试求 的 MLE.
提示:
- 的密度函数 .
- 似然函数 .
- 考虑到 和 的极值点相同,故令.
- 求解该方程(
对数似然方程),可得 .
正态总体参数的最大似然估计
例 设 是来自总体 的简单随机样本,求 和 的 MLE.
提示:
- .
- 令
- 解得 ,.
求 MLE 的一般步骤
- 根据总体的分布,写出似然函数 ;
- 写出 对数似然函数 ;
- 写出 对数似然方程(组)
- .
- 解出 即为 的MLE.
- 如果由对数似然方程(组)无法确定 MLE,则结合参数取值的边界条件,对似然函数进行讨论.
例 设 是来自总体 的简单随机样本,其中 为未知参数,求 的矩估计 和最大似然估计 .
提示:
- .
- 由矩估计法,令 ,即 .
- 解得 .
- 故 的矩估计为 .
- 的分布律为
- ,.
- 似然函数
- .
- 对数似然函数
- 令 , 即:.
- 由此解得 .
- 从而 的最大似然估计 .
- 二项分布的参数 的矩估计和 MLE 相同.
例 设总体 的密度函数为
其中 为未知参数. 设 是来自总体 的简单随机样本,求 的矩估计 和最大似然估计 .
提示
- .
- 令 , 解得 的矩估计 .
- 设 为抽样结果落在 中的次数.
- 似然函数 .
- 对数似然函数 .
- 令 , 即:.
- 由此解得 的最大似然估计 .
例 设总体 的分布律为
设 是来自总体 的样本,试求 的矩估计和最大似然估计.
提示:
- .
- 令 , 解得 的矩估计 .
- 设 取 的次数分别为 , .
- 似然函数 .
- 令 ,解得 .
- 注意到 ,由此可得 .
- 综上, 的 MLE 为 .
例 假设某电子器件的寿命 (单位:小时)服从参数为 的指数分布,现从这批器件中任取了 只进行独立寿命试验,试验进行到预定时间 时结束,此时恰好有 只器件失效,试求 的MLE.
提示:
- 的密度函数
- 设随机变量
- .
- 似然函数 .
- 对数似然函数 .
- 令 , 解得 的 MLE 为 .
6.2.3 参数估计的评判标准
一个“好的”估计应该满足什么条件?
- 无偏性 (Unbiasedness)
- 估计量的波动应以真值 为中心.
- 有效性 (Efficiency)
- 估计量与真值的距离总体来说应该较小.
- 相合性/一致性 (Consistency)
- 估计量的精度随样本容量 的增加而不断提高.
1. 无偏性
若估计量 的数学期望存在,且对任意 有
则称 是 的 无偏估计 (Unbiased Estimation), 否则称为 有偏估计 (Biased Estimation).
例 是取自总体 的样本, 总体 的数学期望 未知, 则下列统计量均为 的无偏估计:
- .
- ,其中 .
- .
定理 设 是来自总体 的简单随机样本,则
- 样本均值 是总体均值的无偏估计;
- 修正的样本方差 是总体方差的无偏估计.
注:
- 无偏性只有在大量试验的情况下才有意义!
- 若 , 则称 为 的 偏差 (Bias).
- 若 ,则称 是 的 渐进无偏估计 (Asymptotic Ubiased Estimation).
- 例: 分别是 和 的渐进无偏估计.
- 这个例子说明, 是 的无偏估计,不一定能推出 的函数 是 的无偏估计.
例 设 是来自总体 的简单随机样本,其中 是未知参数.
- 试求 的矩估计 与最大似然估计 ;
- 与 是否是 的无偏估计;
- 证明 是 的无偏估计.
分析:
- .
- 令 , 解得 的矩估计为 .
- .
- 故 是 的无偏估计.
- 似然函数 .
- 的 MLE 为 .
- 的密度函数 .
- .
- 由此可知 是 的有偏估计.
- 经修正后, 是 的无偏估计.
军力评估问题
例 在“二战”中, 盟军在多个战场缴获德军共计 辆虎式坦克. 这些坦克都带有数字编号, 假定坦克编号 在 上的等可能取值, 问如何估计虎式坦克总数 ?
- 矩估计:.
- 极大似然估计:.
- 修正的 MLE:.
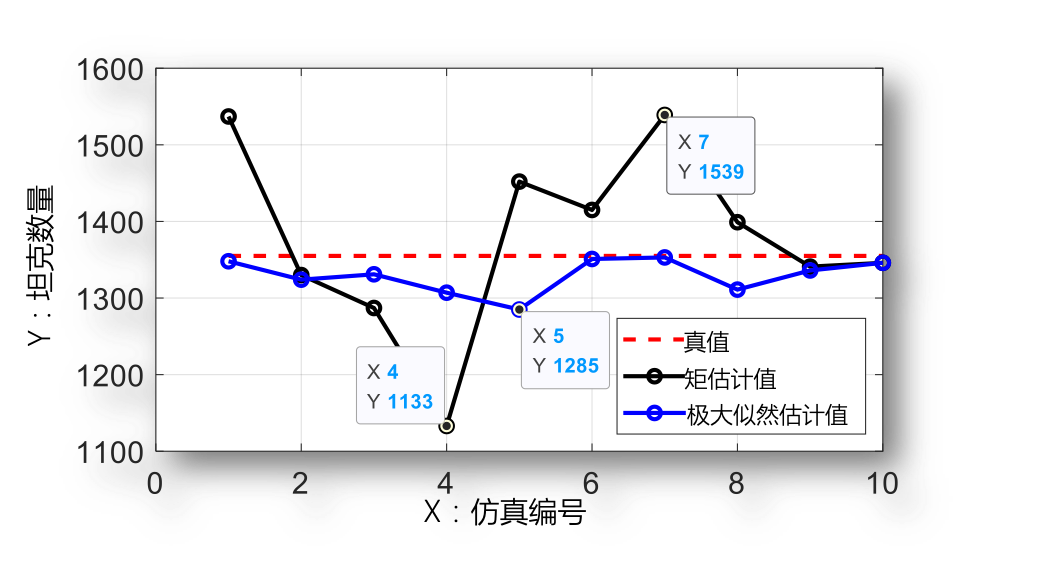
取真值 , 次仿真的结果显示,修正的 MLE 具有最好的精确度和稳定性.
2. 有效性
若估计量 的方差存在,称
为估计量 的 均方误差 (Mean Square Error, MSE).
- 若存在 的一个估计量 ,使得对 的任意估计量 ,都有 ,则称 是 的 最小均方误差估计 (MMSEE).
估计量的“波动”与“偏差”
- 系统误差(System Error) .
- 反映了估计量的波动中心与真值的差异.
- 绝对误差(Absolute Error) .
- 反映了估计量与真值的均方误差.
随机误差(Random Error) .
- 反映了估计量自身的波动.
定理 .
- 推论 若 是 的无偏估计,则方差小的估计量应该更有效.
定理证明:
无偏估计的有效性
设 均为 的无偏估计量,若
则称估计量 较 更为 有效.
例 设 是来自总体 的简单随机样本.
- 证明 都是 的无偏估计;
- 判断 哪个更有效.
分析
- 总体 的密度函数 .
- ,故 是 的无偏估计.
- , 密度函数 .
- 由此可得 , 故 也是 的无偏估计.
- .
- .
- .
- .
- 由此可见 作为 的估计,相对于 更有效.
最小方差无偏估计(MVUE)
设 是未知参数 的无偏估计量,若对 的任一无偏估计量 有
则称无偏估计量 是 的 最小方差无偏估计 (Minimum Variance Unbiased Estimate).
Cramér–Rao 下界
设总体 的密度函数为 , 是来自总体 的简单随机样本, 为待估变量,其中 是未知参数,统计量 是 的无偏估计.
问:有没有可能完美地逼近 ?
- 即:是否可能 ?
- 不可能!给定样本容量,无偏估计的方差存在非零下界!
记 ,,
定理 设 , 为总体 的密度函数, 为似然函数,若
- .
- 几乎处处存在,且 .
几乎处处存在,且
- 则 .
证明:
- 的联合密度 .
-
-
- (Cauchy-Schwarz 不等式)
- 整理后即得 .
Cramér–Rao 下界
- 称为无偏估计量的 Cramér–Rao 下界 (C-R 下界).
- 称为 Fisher 信息(量).[^2]
- 例:未知参数 的任意无偏估计(相当于取 )的 C-R 下界为 .
Fisher 信息
- C-R 下界的存在,意味着
统计量对参数的估计能力是有限的,由待估参数的形式、分布的 Fisher 信息和样本容量共同决定. - Wikipedia: The Fisher information is a way of measuring the amount of information that an observable random variable carries about an unknown parameter of a distribution that models .
- 对于要估计的参数,采样的数据量越大,意味着数据提供的信息量越大,从而 C-R 下界就越小,那么就能越准确地估计出该参数的值.
推论 在前述定理条件下,若还有 ,则
证明思路
例:均匀分布参数的 C-R 下界
求均匀分布 中未知参数 的无偏估计的 C-R 下界.
提示:的密度- 故 的无偏估计的 C-R 下界为 .
讨论
- 中参数 的函数 的无偏估计的 C-R 下界为
- 注意到 是 的无偏估计,
- 但
- 这就与定理结论相矛盾了!
- 造成这一问题的原因是什么?
事实上, 的密度函数不满足 C-R 下界的条件2:
- 本例中,
- 所以,结论是因为 这个总体不满足 C-R 下界的条件,因此导致了以上相互矛盾的结果.
证明某个统计量是未知參数的 MVUE 的一般过程
- 证明估计量 是 的无偏估计量;
- 计算估计量 的方差 ;
- 计算 Fisher 信息量 ;
若 ,则 是 的 MVUE.
- 注:有时候,C-R 下界是无法达到的.
- 例如:对于 , 是 的 MVUE.
- 但是,.
例 设 是来自总体 的简单随机样本,证明 是 的 MVUE.
提示:的密度函数:.- .
- .
- 的无偏估计的 C-R 下界为 .
- ,由此可知 就是 的 MVUE.
例 设 是来自总体 的简单随机样本,总体 的密度函数为
证明 是 的最小方差无偏估计.
提示:.- .
- .
- .
优效估计
设 是待估参数 的一个无偏估计量.
- 称为 的 估计效率 (Estimation Efficiency).
- 如果 ,则称 是 的 优效(完全高效)估计 (Optimal Estimation).
- 如果 满足 ,则称 为 的 渐进优效估计 (Asmptotic Optimal Estimation).
- 例:对于正态总体 , 是 的渐进优效估计.
例 设 是取自总体 的简单随机样本 ( 未知). 试以均方误差的大小为准则,比较 的估计 和 中哪一个较优?
提示:
- ,故 是 的无偏估计,即 .
- .
- .
- 故 .
- ,故 是 的有偏估计.
- .
- .
- .
- 故 .
- 是 的无偏估计,.
- .
- 时,
- 综上,给定的三个估计量中 最有效.
3. 相合性
设 是未知参数 的点估计,若对任意 ,有
则称 是 的 相合估计 (Consistent Estimator).
- 随着 的增加, 估计量与参数真值的绝对偏差较大的可能性越来越小.
- 由 Khinchin 大数定律可知,样本 阶矩是总体 阶矩的相合估计量,因此
矩估计量一般是相合估计量.
无偏估计必是相合估计吗?
- 不一定!
- 无偏性只能说明估计的中心与真值一致,但估计值的分布仍然可能比较分散;
- 相合性则能保证随着 的增大,估计值越来越像真值.
- 相合估计一定是无偏估计吗?
- 不一定,但
相合估计一定是渐进无偏估计!
- 不一定,但
Chebyshev 不等式
设 是随机变量 的非负连续函数,如果 存在,则对于任一正常数 ,均有
证明:
- 推论 若随机变量 的期望和方差存在,则对任意 ,总有
相合估计的判定
设 是未知参数 的估计量,
.
如果 ,则 是 的相合估计.
- 特别地,若 是无偏估计,则 .
定理 无论总体 服从什么分布,若
都存在,则
- 样本均值 是总体均值 的相合估计;
- 样本方差 与修正的样本方差 都是总体方差 的相合估计.
证明思路
- 样本均值 是总体均值 的无偏估计.
- 对任意 ,由 Chebyshev 不等式,
- .
- 因此 , 故样本均值 是总体均值 的相合估计.
- 修正的样本方差 是总体方差 的无偏估计.
- .
- 当 充分大时,
近似服从. - 故 ,进而可得 .
- 综上,由夹逼准则 .
非正态总体的极限分布[2]
设 为来自总体 的简单随机样本, 均存在,则当 充分大时:
- 近似服从 .
- 近似服从 .
例 设总体 服从 上的均匀分布,其中 未知,证明 的 MLE 是相合估计量.
提示:
- 是 的有偏估计.
- 因此 , 即 是 的相合估计量.
6.2.4 Bayes 估计
统计的经典学派与 Bayes 学派
- 经典学派 的统计推断主要依赖于
- 样本信息 抽取样本所得观测值所提供的信息.
- 总体信息 总体的分布或总体所属的分布族.
- 例如:总体为正态分布、总体的密度函数关于均值对称、总体的前两阶矩均存在.
- Bayes 学派 认为利用先验信息可以使统计推断更具合理性.
- 先验信息 抽样(试验)之前关于统计问题的一些信息.
- 例如:过去一段时间的产品合格率、总体均值的分布.
- 先验信息 抽样(试验)之前关于统计问题的一些信息.
先验分布
例 每天抽检 件产品以确定质量是否满足要求. 产品质量可用不合格品率 来度量,也可用 件产品中的不合格品件数 表示.
由于生产过程有连续性,可以认为每天的产品质量是有关联的.- 在估计现在的 时,以前积累的资料应该能提供帮助.
- 积累的历史资料就是 先验信息.
- 例如:经过一段时间后,可以对过去 件产品中的不合格品件数 构造一个分布: .
- 对先验信息进行加工所获得的分布称为 先验分布 (Prior Distribution).
Bayes 学派
- 任一未知量 都可以看作随机变量,从而可用一个概率分布(先验分布)去描述.
- 获得样本后,
将总体分布、样本与先验分布通过 Bayes 公式结合起来,可得到一个关于未知量 的新分布,称为 后验分布 (Posterior Distribution). - 任何关于 的统计推断都应该基于 的后验分布进行.
- 例如:在求参数 的点估计时,可以取其基于后验分布的期望值、最大值或者中位数.
- 如何利用各种先验信息合理地确定先验分布,是 Bayes 估计中的关键问题.
Bayes 公式的概率函数形式
设 为样本, 为未知参数,则
- : 的后验概率函数.[3]
- : 取定为某个值时的条件概率函数.
- : 的先验概率函数.
- : 的边缘概率函数.
Bayes 估计
由后验分布 估计 有三种常用的方法.
- 最大后验估计 使用后验分布概率函数的最大值点作为 的点估计.
- 后验中位数估计 使用由后验分布概率函数确定的中位数作为 的点估计.
- 后验期望估计 使用由后验分布概率函数确定的均值(期望)作为 的点估计.
例:成功率的估计
设事件 在一次试验中发生的概率为 ,为估计 ,对试验进行了 次独立观测,其中事件 发生了 次. 试给出 估计值.
提示:的矩估计和最大似然估计均为 .
Bayes 方法
解:显然 ,于是 .- 基于 同等无知原则,假设 的先验分布为 ,即
- 于是 与 的联合概率函数
- 的边缘概率函数
-
- .
-
- 于是 的后验概率函数
- .
- 即 .
使用 的后验期望估计得到
例 通过抽检考察产品的不合格率
- 抽检 个均合格:.
- 抽检 个均合格:.
Bayes 估计的结果能够反映出两次抽样的差异,在该场合下相对于最大似然估计更具合理性.
6.2.5 区间估计
区间估计 (Interval Estimation)
- 参数的点估计,能够给出未知参数的近似值.
- 但在很多实际问题中,更加关心的是参数的取值范围.
区间估计:根据样本数据,确定 未知参数可能的取值范围,使得能以较高的 可信度 保证该范围包含了未知参数的真值.
- 例如:正常人的血糖范围、某地区人的寿命区间、大学生的月消费额度、... ...
置信区间
设 是来自某个总体的样本,分布函数为 ,其中 未知.
给定 ,若存在统计量 和 , 使得
则称区间 为参数 的一个 (双侧)置信区间 (confident interval,缩写 CI), 分别称为 的 双侧置信上、下限. 称为该区间的置信度.
单侧置信区间
给定 , 若存在统计量 , 使得
则称区间 为参数 的一个 单侧置信区间, 称为 的 单侧置信上限.
- 同理可以定义 的单侧置信下限.
例:理想的键盘高度
- 为了设计出一款工作效率和舒适度最理想的键盘,设计师将关注的重点放在了键盘托架的高度上.
- 为了得到最理想的高度范围,设计师邀请了 31 位熟练的打字员,分别获取了对他们来说最为理想的托架高度.
- 结果得到的平均值为 cm. 假设打字员所钟意的托架高度服从方差为 4 均值为 的正态分布.
- 试给出 的一个 置信区间.
分析:
- 设 为来自总体 的样本.
- 于是 , 进而 .
- 注意到 .
- 即 .
- 代入本例中的数值计算,可得 是 的一个 置信区间.
置信区间的含义
上面的例子中,
- 因为 是一个常数(但取值未知),以上求得的置信区间的意义并不能理解为 .
- 而只能理解为 ,
- 即该随机区间中包含 的概率为 .
置信区间不具有唯一性
前例中, 的 置信区间为
- 为了方便,可以简写为
- 显然,置信区间并不具有唯一性,也不一定要求两侧具有对称性.
- 事实上,对于本例而言,对任何一个 , 都是满足要求的置信区间.
例:双侧置信区间的宽度
- 某计算机系统上特定的编辑指令的响应时间服从标准差为 25 毫秒的正态分布.
- 安装新的操作系统后,希望对其平均响应时间的均值 重新进行估计.
- 假设安装新的操作系统后,响应时间仍服从正态分布,且标准差不变.
- 为了使得 的 置信区间宽度不超过 10,样本的容量至少要有多大?
分析: 参考前例,置信区间为 ,依题意须满足
即 ,故 .
- 注: 在样本容量不变的前提下,如果提高置信水平,置信区间的宽度将会增加. 此时,可以说:估计的可靠性 (reliability) 提高了,但估计的精确度 (precision) 有所下降.
Jerzy Neyman (1894-1981)
- 现今的区间估计理论是由原籍波兰的美国统计学家 Jerzy Neyman 于 20 世纪 30 年代建立起来的.
- Neyman 被称为”来自生活的统计学家“,毕生热心于且精通于应用的,后半生的工作更是遍历了生物学、宇宙学、气象学等等诸多领域.
- 求区间估计一般方法:依据波动理论的 枢轴变量法.
枢轴变量
设 为对未知参数 进行区间估计所需的样本. 所谓枢轴变量 (pivotal quantity) ,是指:
- 是 和 的函数.
- 不是统计量.
的分布与 或其他的任何未知参数均无关.
无论 如何取值, 的分布不变.
利用枢轴变量推导参数置信区间的方法称为枢轴变量法.
用枢轴变量法求置信区间
- 构造样本的函数 ,也即 枢轴变量 (Pivotal Quantity).
- 对置信度 ,确定 的分布的两个分位点 和 , 使得
- 注: 在没有事先声明的情况下,默认地按以上方式取两侧的分位点,所得到的的置信区间称为 等尾置信区间.
- 解不等式 , 得到置信区间:.
例:理想的键盘高度
已知 , 理想高度服从 的正态分布,求 的 置信区间.
- 枢轴变量:.
- 思考: 如果本例中 也是未知的,以上的 还是枢轴变量吗?
- 如果不是,应该如何定义枢轴变量?
- 枢轴变量的选择是唯一的吗?
单个正态总体的区间估计
已知 为来自正态总体 的样本, 分别考虑如下四个区间估计问题:
- 已知,求 的置信区间.
- 未知,求 的置信区间.
- 已知,求 的置信区间.
- 未知,求 的置信区间.
单正态总体的 1-α 置信区间
提示: 求 的 置信区间(假设 已知)
1. 求双侧置信区间
- 枢轴变量 .
- 设 ,也即
- .
- 取 ,.
- 解得 ,.
2. 求单侧置信下限
- 枢轴变量 .
- 设 ,也即
- .
- 取 ,解得 .
例:飞机的飞行高度
为了提高可靠性和测量精度,飞机通常安装了若干个高度仪. 设飞机实际飞行高度为 时每个高度仪时测量值 ,而飞机仪表上显示的飞行高度是所有的高度测量值的平均值. 在置信水平 下,求解下列问题:
- 若要保证飞行仪表上显示的飞信高度的绝对误差不超过 m,问飞机上至少安装多少个高度仪?
- 若飞机装有 个高度仪,飞行仪表上显示的飞行高度是 m,问飞机实际飞行在什么高度范围?
提示:
- 假设有 个高度仪,高度测量值分别为 ,则 .
- 问题等价于,要使 , 至少需要取多大?
- 上式也即 .
- 由此可得 ,即 .
结论:安装至少 个高度仪就可以满足要求.
- 此时 ,进而 .
- 置信区间为 .
- 或
- 已知 ,故此时飞机的实际高度范围为 .
例:灯泡的寿命
从灯泡厂随机抽取 只灯泡,进行寿命试验,测得数据如下(单位:小时)
设灯泡寿命服从正态分布,给出这批灯泡的平均寿命及方差的置信度为 的置信区间.
解:
- 设 为灯泡的寿命,设 ,其中 均未知.
- 的置信度为 置信区间是 .
- 利用抽样数据进行计算,.
- .
- 查表 ,故 的置信度为 的置信区间为 .
- 的置信度为 的置信区间为 .
- .
- .
- .
- 的置信度为 的置信区间为
双正态总体的区间估计
- 设 和 分别为来自 和 的样本,且二者相互独立.
- 试对其均值的差 和方差的比值 给出区间估计.
双正态总体的 1-α 置信区间
例:比较子弹的初速度
- 随机地取 I 型子弹 发, 得到枪口速度的平均值为 (m/s), 修正的标准差 (m/s).
- 随机地取 II 型子弹 发, 得到枪口速度的平均值为 (m/s), 修正的标准差 (m/s).
- 假设两总体都可认为近似地服从正态分布, 且由生产过程可认为它们的方差相等.
- 求两总体均值差 的置信度为 的置信区间.
解:
- 由实际情况,可认为分别来自两个总体的样本是相互独立的.
- 由于它们的方差相等且未知,故 的置信度 的置信区间为 .
- 其中 , , .
- 故两总体均值差 的置信度为 的置信区间为 .
小结
- 点估计
- 矩估计与最大似然估计
- 点估计的评估准则
- 无偏性、有效性、相合性
- 区间估计
- 枢轴变量法
- 单正态和双正态总体的区间估计
- 单侧置信区间
[1] https://en.wikipedia.org/wiki/Maximum_likelihood_estimation ↩
[2] 参见:何迎晖,闵华玲,《数理统计》,北京:高等教育出版社,1989. ↩
[3] 概率函数即指离散型随机变量的分布律(列)或连续型随机变量的密度函数 ↩
