@SovietPower
2023-08-10T13:47:41.000000Z
字数 48267
阅读 1384
面试 应用:数据库
实习
Sql执行的的全流程
Sql优化器的执行过程
redis 线程模型
图数据库:https://zhuanlan.zhihu.com/p/373446678
数据库
链接池
B树 B+树
(见数据库 P445)
B/B+树索引并不能找到一个给定键值的具体行,只是找到数据行所在的页。然后数据库把页读入内存,在内存中进行查找,最后得到查找的数据。
B树:
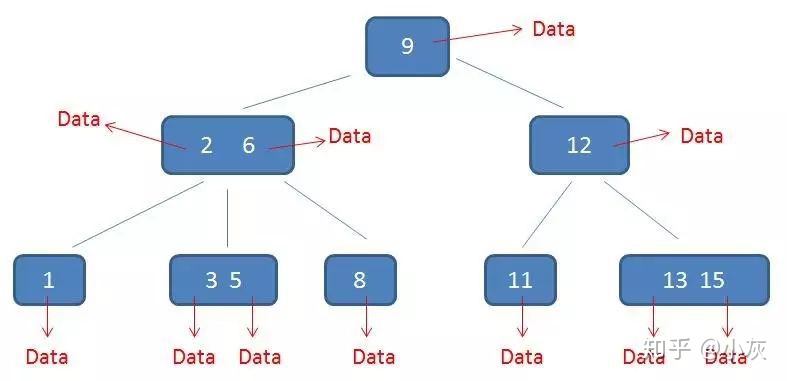
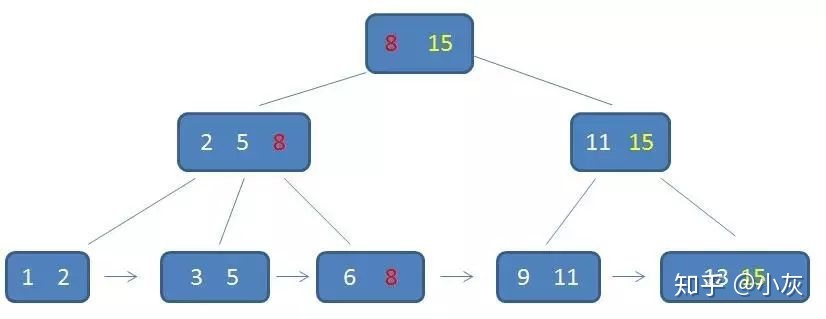
B+树:
为什么使用B+树
数据库要支持高效的插入、删除、查询操作,相关的数据结构只有平衡树(哈希也能,但不用的原因见下)。
对于 MySQL 而言,磁盘 IO 往往是性能的瓶颈,如果只在内存中进行操作是非常高效的。所以 MySQL 的索引最先考虑的 应该是减少 IO 次数。
常规平衡树都是二叉树,相比n叉树,高度更高,IO次数更多。
同时数据库使用页为读写单位,一次操作可以获取很多数据,即使使用n叉树也可一次读取整个节点的信息。所以n叉树所需的IO次数更少。
为什么不用B树:
B+树的非叶节点没有卫星数据(指向该键的文件记录或桶的指针),所以同样大小的磁盘页(一个节点)可以容纳更多元素,所以会比B树更矮更胖,高度低,所以最坏情况下查询 (IO) 次数更少,更稳定(稳定性一般是很重要的,即使平均性能略差)。
B+树的所有数据都在叶节点,每个叶节点有指向下一个叶节点的指针,所以更方便区间查询和遍历(不过 B 树也能做到?)。
为什么不用哈希表:
首先哈希表中的数据是无序的,不能按序遍历,不方便区间查找。
其次,哈希表本质上是空间换时间,如果负载因子过大,冲突率会很高,效率低;负载因子过小,对空间的占用就很大(映射数组的大小至少是元素数量的倍)。而且最常用的链式哈希连续性非常差,不适合用于硬盘。
还有哈希表的复杂度不能保证(只是期望复杂度),少数情况下可能很差,不够稳定。
数据库锁
数据库一般有表锁和行锁。对于mysql最常用的引擎InnoDb,默认使用行锁。但行锁需要指定索引,所以只有通过索引查找数据,才会使用行锁,否则使用表锁(要全表扫描)。
见 mysql - mysql 的锁。
数据库读取数据的过程
todo
- 预读:用估计信息,去硬盘读取数据到缓存。预读100次,也就是估计将要从硬盘中读取了100页数据到缓存。
- 物理读:查询计划生成好以后,如果缓存缺少所需要的数据,让缓存再次去读硬盘。物理读10页,从硬盘中读取10页数据到缓存。
- 逻辑读:从缓存中取出所有数据。逻辑读100次,也就是从缓存里取到100页数据。
mysql 缓存
https://spongecaptain.cool/post/mysql/zerocopyofmysql/
聚簇索引/聚集索引(clustering index)
聚簇索引就是索引 B+ 树的叶子节点直接存放了数据;而非聚簇索引的叶子节点存放了主键值,查询需要回表。
聚簇索引决定数据在磁盘上如何排列:按照聚簇索引的顺序排列。所以只能有一个聚簇索引,一般是主键。
数据在磁盘上会尽量物理相邻存放?从而连续读多条记录时可以顺序IO。但由于会有插入删除,不能保证数据页总是相邻的,还是会用链表链接。
以b树实现为例,聚簇索引的叶节点包含数据,用聚簇索引查找数据,访问到叶节点就可以读取到数据。
而非聚簇索引的叶节点不包含数据,而是数据的地址,所以非聚簇索引的查找要多一次IO(读到地址,再读地址位置)。由于数据位置可能变,所以一般不存地址,而是数据的主键(或者聚簇索引?),再多进行一次b树查询。
非聚簇索引(non-clustering index)也叫次要索引/辅助索引(secondary index),是聚集索引外的所有索引,需要额外的硬盘空间,但一般不大。是稠密索引。
不太懂聚簇索引怎么实现的,在插入时怎么做,如果没有空余位置,直接放到新页中,不管连续性?还是将页拆分,将后半部分拷贝到新页?但新页也不是连续的。
聚簇索引有些缺点,但不太懂为什么。应该是为了尽量维护物理顺序导致的。
Any update of record or change in the value of the indexed column in a clustered index might need the repositioning of the rows to maintain the sorted order. The UPDATE Query(应该指对聚簇索引的修改) can also be viewed as a DELETE Query followed by an INSERT statement, which lowers the performance. The clustered index of a table is, by default, created on a primary or foreign key column. It is because clustered index stores the physical order of the table that can be only one and unique like a primary key.
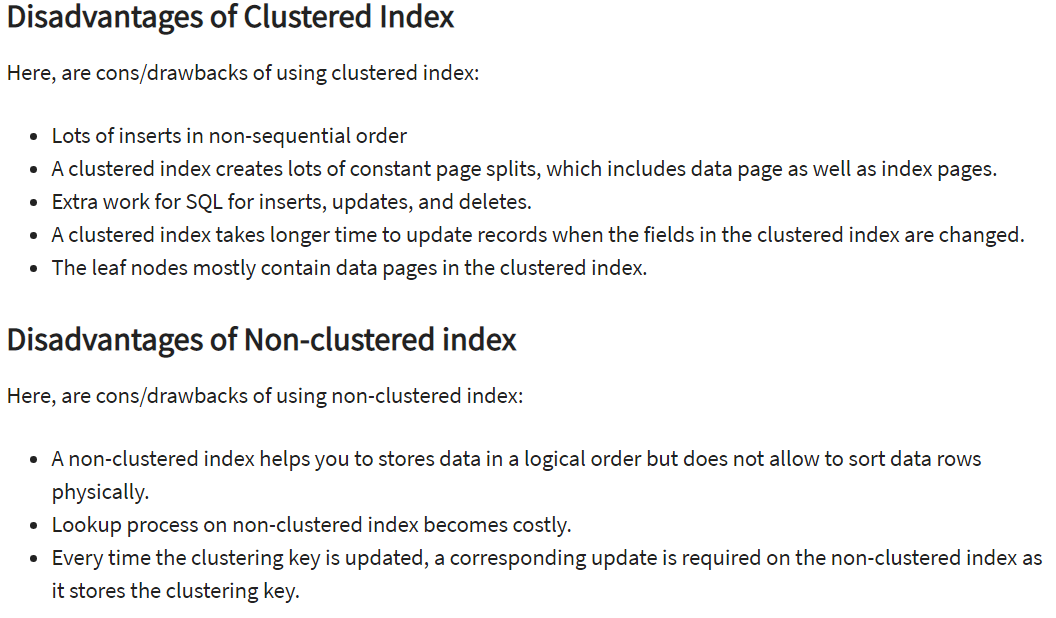
回表
非聚簇索引只能查到聚簇索引(和这个索引值),对于其它属性只能再进行一次聚簇索引。这个二次查询叫回表。
一种优化方式是使用 覆盖索引。
覆盖索引
在辅助索引的叶子上保存额外信息。
辅助索引的叶子上,一般只会保存该索引的值和主键值。
但我们可以在叶子上保存一些额外的常用属性,以便只使用一次辅助索引就能回答询问,不需要访问原本的记录。
在多个搜索键上创建索引能实现同样效果(保存其它属性值),但非叶节点会更大,度数更低,导致B+树变得更高。
稀疏索引 sparse index
只为某些键建立索引,搜索时先找到最近的键,然后顺序遍历。
只有数据按该键大小顺序存储时,即只有该键是聚集索引时,才能创建稀疏索引。
稠密索引(dense index) 就是为每个键都建立一个索引项。
多级索引
如果一个索引大到不能放入内存,那么只能通过多次硬盘读取索引(比如二分)。
为此,可以再建一个外层的稀疏索引,将原索引划分成多组,以便每组能读入内存(如果索引是有序存储的)。
外层的稀疏索引要比原索引小很多。如果外层索引仍不能放入内存,继续增加多级索引,但IO次数仍要比二分少很多。
倒排索引 inverted index
一般的数据库,将文档ID作为索引,指向文档内容。如果想检索某个关键词出现在哪个文档中,必须遍历所有内容,进行字符串比对。
但倒排索引,将文档内容的各词拆分作为索引,指向包含它们的文档ID。
与常用的方式颠倒,所以叫 inverted。但本质都是索引:为了通过关键词快速检索想要的数据。
Lucene/Elastic 索引的实现
索引是拆分后的各个词,由于词的数量可能相当多,不能用B+树做索引,因为要全部存在内存中;而且要尽可能减少空间占用,但B+树的多个节点和指针都会占用额外内存?
对一般数据库,一个表也就百万千万条数据?空间占用不是特别在意,更在意硬盘IO次数。而二分会进行次IO,B+树只有次。
单词和文档分别存储,前者为字典 (Term Dictionary),按顺序排放,用哈希表指向对应的文档。
索引通过字典树实现,每个节点是一个前缀,指向第一个包含该前缀的块,然后在该块内二分找到正确的单词,然后找到文档ID列表。
实际是用字典树做了一个稀疏索引,以便放入内存。
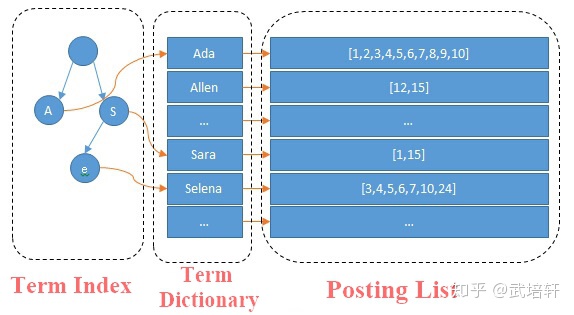
Posting List 的实现:
https://www.elastic.co/cn/blog/frame-of-reference-and-roaring-bitmaps
文档ID列表称为 Posting List,要解决两个问题:怎么压缩以尽可能节省空间;怎么快速求交并集。
Lucene 采用如下压缩方式:Frame Of Reference:
假设原IDs为:[73, 300, 302, 332, 343, 372],按序存储。
- Delta-encode:首先缩小值域最大值,将原ID变为相邻ID的增量:
[73, 227, 2, 30, 11, 29]。 - Split into blocks:将所有数据分块,比如每256个ID一个块,根据每块内元素的最大值,决定这个块的数据使用什么类型(几位)存储。
假设按3个数据一个块,则原ID变为:[73, 227, 2], [30, 11, 29],对于前者每个数据需要8位(允许最大值255),后者每个数据只需要5位(允许最大值32)。 - Bit packing:在每个块的开始用1字节,表示这个块的每个数据需要几位,然后连接各个块。
所以数据变为:8[73, 227, 2], 5[30, 11, 29],然后连在一起,占用1+3*8/8+1+3*5/8=7字节。
Lucene 快速求交并的实现:filter cache + roaring bitmaps:
一般的操作为:将压缩过的数据读到内存,解压,再进行求交并集。应该是逐块读取和操作的。
为了提高速度,可以对经常出现的 查询/筛选 做缓存,称为filter cache。缓存是一个哈希表,key 为(filter, segment/block),value 为对应的文档IDs(实际为下面的 roaring bitmaps)。
这个缓存的实现(存储结构)要与倒排索引不同,因为:
- 只对经常出现的筛选做缓存,涉及的数据不多,不需要那么高的压缩率。
- 要足够快,比如不能再像一般询问一样进行复杂的压缩和解压;但也不能完全不压缩,太占空间,因为要存在内存。
所以有几种选择:
- 整数数组:直接将对应的文档ID数组保存。如果每块只有65536个数据,即ID范围在
0~65535,每个ID要花2B。
如果一个块内有很多ID合适(密集),则要存大量的ID,占用大量内存。 - 位图:每块需要65536位=2^{13}B=8KB,每个数据用1位表示是否存在。
但如果一个块内只有1个ID合适(稀疏),则仍要存8KB,方法1只需要2B,内存消耗大,效率也不高。 - roaring bitmaps:数组与位图的混合。
限定每块的值域为0~65535后,如果块内的数据少于4096个,则用整数数组,否则用位图。
并集好像是通过跳表实现,交集通过位图交实现,没有再看。
全文索引
是 mysql 的一种索引,fulltext index。
使用场景与倒排索引类似:对内容的关键字查询,或全文检索。(其实实现方式也是倒排索引?)
用来代替低效的like %(要全文检索与匹配),但有一点不精确,因为会拆分词组,可能改变原意。
使用方法见:https://zhuanlan.zhihu.com/p/35675553,用against匹配。
但这种全文检索这种功能,还是要用 ElasticSearch 这类搜索引擎(其实也是一种数据库)。
自己实现中文的检索,还需要定义一个分词器。如果有字典可以直接匹配字典,不然可以用二元分词。
二元分词和中文分词的区别:
二元分词不依赖词典,中文分词依赖词典。
二元分词分词速度要比中文分词快。
二元分词的索引大小要比中文分词大,分词字数约为原文字数的2倍。
二元分词的索引虽然比较大,但能保证搜索结果覆盖用户输入的关键词。
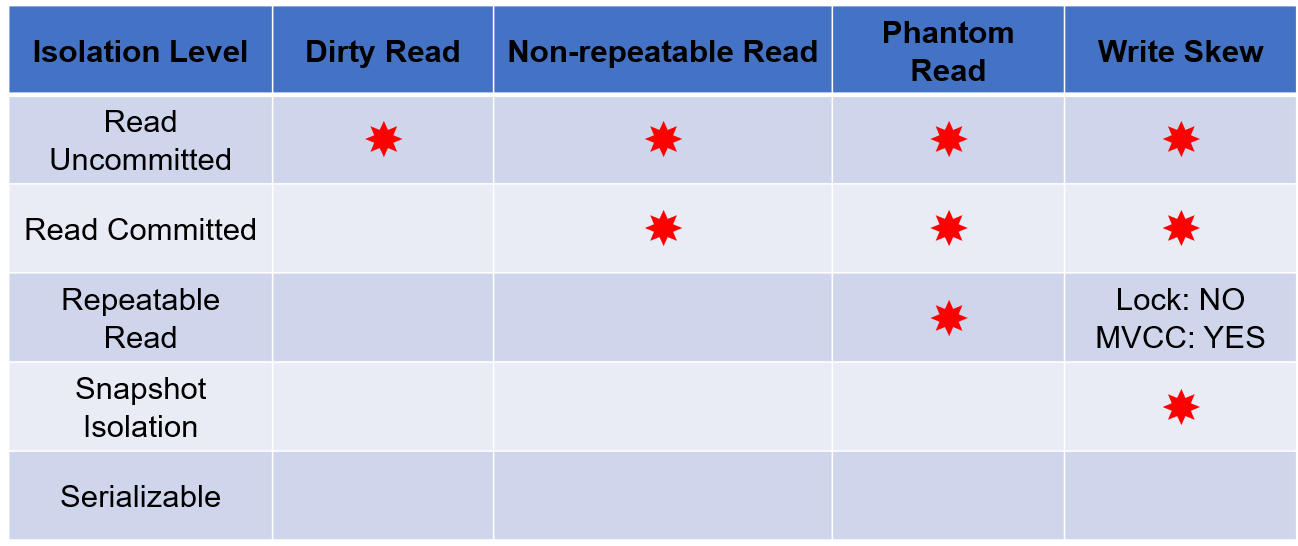
隔离级别
- 未提交读: 允许读取未提交数据。数据可能会回滚,也可能会进一步修改。会导致脏读。
一个事务正在对一条记录做修改,在这个事务并提交前,这条记录的数据就处于不一致状态;这时,另一个事务也来读取同一条记录,如果不加控制,第二个事务读取了这些“脏”的数据,并据此做进一步的处理,就会产生未提交的数据依赖关系。这种现象被形象地叫做“脏读”。 - 已提交读:只允许读取已提交数据,但不要求可重复读。
- 可重复读:只允许读取已提交数据,且同一事务两次读取同一数据时,读取结果必须相同。
- 可串行化:最强的要求。事务并行的结果与它们按某个顺序串行执行的结果一致。
可能存在的问题:
- 脏写 (dirty write):事务可以写一个 被尚未提交或中止的事务 写过的数据。
会丢失更新。上面的所有隔离级别均不允许脏写,写数据时只能覆盖已经提交了的数据。 - 脏读 (dirty read)。
- 不可重复读 (non-repeatable read):一个事务前后读取同一数据,结果不同。
- 幻读 (phantom read): 一个事务先后两次执行相同的范围查询,但得到不同结果。如发现了其他事务插入了满足查询条件的新数据。
- 写偏斜 (write skew):两个事务读取一个相交的集合,然后在不相交的数据集上分别进行修改,同时提交。双方都没有看到对方的修改,可能会违反一致性约束。
级联回滚
一个事务的失效回滚,导致一系列事务回滚。
可串行化调度
对于需要并发执行的事务,如果存在调度S,使得对于数据库的任何状态,其执行结果等价于另一个串行调度S’,称这样的调度S为可串行化调度(serializable schedule)。
冲突可串行化
冲突可串行化调度是可串行化调度的子集,它的意义在于相对于可串行化,冲突可串行化是一个更加容易验证的条件,因此更加适合作为事务并发控制的实现依据。
并发控制
锁的协议、死锁处理(与os类似,但要决定是部分回滚还是彻底回滚)、多粒度、基于时间戳的协议、基于有效性检查的协议、快照隔离。
两阶段封锁协议 (two-phase locking protocol)
要求每个事务分两个阶段提出加锁和解锁申请:
- 增长阶段(growing phase):事务可以获得锁,但不能释放锁。
- 缩减阶段(shrinking phase):事务可以释放锁,但不能获得锁。
事务最初处于增长阶段,可以按需获取锁。一旦它释放了锁,就进入缩减阶段,不能再获取锁。
两阶段封锁协议是冲突可串行化的。(?不理解这个冲突可串行化的意思)
称每个事务最后获得锁的位置为封锁点(lock point)。多个事务按封锁点排序,就是事务的应该可串行化顺序。
不能避免脏读(不能保证未提交读),不能保证可重复读!
不能保证不会死锁。会导致级联回滚。
可进一步优化:允许锁转换(lock conversion):
增长阶段可进行升级(upgrade):允许将共享锁升级为排他锁。
缩减阶段可进行降级(downgrade):允许将排他锁降级为共享锁。
严格两阶段封锁协议 (strict two-phase locking protocol)
除了两阶段封锁外,还要求事务持有的所有排他锁,只能在事务提交后才释放。
保证了未提交事务所写的任何数据,在它提交前都加的排他锁,防止其它事务读取。
因为写锁在提交前不会释放,所以不会脏读、可保证可重复读。
不会导致级联回滚。
强两阶段封锁协议 (rigorous two-phase locking protocol)
要求事务提交前不释放任何锁。
可串行化的实现
TODO
Oracle 和 PostgreSQL 使用快照隔离实现,事实上不是真正的可串行化,会有 write skew (写偏斜) 问题。
mysql 使用 MVCC+next key lock 实现(或严格两阶段封锁协议?不确定)。
MVCC
见 mysql - MVCC。
宕机恢复
检查点:在系统故障后,需要搜索整个日志来检查哪些事务需要重做或撤销、哪些事务不需要。
但搜索很麻烦,而且任意时刻还活跃的事务不会太多(如果某时刻崩溃,则只会影响该时刻活跃的事务)。
为了降低恢复开销,会定期生成检查点日志<checkpoint L>存储到硬盘,其中 L 是生成检查点时活跃的事务列表。
这样恢复数据时,只需找到最后一个检查点 L,只对 L 中的事务和该检查点之后开始的事务进行撤销或重做。
生成检查点时,不允许事务执行任何更新。(why?)
P616, 626
redolog工作原理
undolog在宕机时怎么保证原子性
对于没有执行完的事务,根据undolog把已经执行的语句回滚?
LSM tree (Log-Structured Merged Tree)
我感觉,LSM 就是多层的写缓存,通过顺序IO把最终的随机IO尽量延后到了 compact。
每个 SSTable 内要实现索引以检索数据。
事实上不是树,只像树,是一种数据组织方式。
类似 mysql 的写缓存,LSM 将最近更新的数据放在内存中(MemTable),数据按key有序。
因为内存不可靠,所以类似 redis,LSM 要在写数据前,将日志写到磁盘上,称为 WAL (write-ahead logging)。
当 MemTable 达到一定大小后,将其转为 Immutable MemTable,开始转储到硬盘上。这之后的写由新的 MemTable 处理。
Immutable MemTable 会被转储到硬盘上,称为 SSTable(Sorted String Table)。
转储的 MemTable 中的各数据,会以 append-only 的形式插入到第0层 SSTable 中(append-only 与日志结构类似,所以叫LS)。因为 append-only 是顺序写磁盘,所以性能很高。
MemTable 通过跳表实现。LSM 有多层 SSTable(每一层可以有1个,也可以有多个 SSTable)。
一次更新需要的操作为:
- 将更新日志(还是键值对?)写到日志文件。
- 更新 MemTable。
- 如果 MemTable 大小达到阈值,使用新的 MemTable,然后转储:将它的数据以 append-only 的形式插入到 L0 SSTable。
- 如果 L0 SSTable 大小达到阈值,将它与 L1 SSTable 通过 compact 操作合并。
- 如果 L1 SSTable 大小达到阈值,将它与 L2 SSTable 通过 compact 操作合并... 以此类推。
一个 SSTable 对每个 key 可能保存多个值,只有最新的可用。
compact 会删除重复的,保留最新值。
对于删除操作,只能加一个key标记操作,最终在 compact 时删除。
一次查询操作,可能要查多层:
- 首先查找内存的 MemTable。
- 如果没有,依次找 L0, L1, L2... 的 SSTable。
SSTable 的索引可以放在内存,提高效率。
所以读的代价可能很大。
LSM Tree compact 策略
TODO:
https://www.jianshu.com/p/e89cd503c9ae?utm_campaign=hugo
https://www.zhihu.com/question/446544471
https://www.modb.pro/db/237785
https://tidb.net/blog/eedf77ff
https://rocksdb.org.cn/doc/Leveled-Compaction.html
几个概念:
空间放大(space amplification):存储引擎中数据实际占用的磁盘空间比数据的真正大小多。
因为数据修改不是 in-place 的,SSTable 中会存重复冗余的 key(每个 key 会有多个 value);此外 compaction 过程中,原始数据在执行完成前要保留(避免失败丢失),导致这部分数据可能占用两倍(短暂的高内存占用)。
SSTable 内的索引/实现
数据库设计
点赞关系及点赞数同步
每条微博要存点赞数,但和微博的其它信息分开。
这个点赞数表用redis放到内存里,更新获取都用redis,每隔一段时间同步到数据库。
点赞关系是一个(user_id, post_id)表,因为不会展示(或不会展示太多)某一条微博的点赞用户,所以可以按user_id分片。用户查询时也是用一个user_id查询的。
行式存储和列式存储
数据库中数据的存储方式可分为行式存储和列式存储。
行式存储:传统的存储方式,同一记录各字段的数据连续存放。
特点:
- 按记录读写数据方便。
- 要一行一行的读数据,所以会读取不使用的字段。
- 即使某些记录的某些字段为空,也要给它们预留空间。
- 适合 OLTP(Online Transaction Processing)系统。
列式存储:不同记录的同一字段连续存储。
特点:
- 可以只读必须的字段,且对各列的运算可以并发执行。
- 对整行的记录读取、插入、更新、删除,都要多次操作。
对于修改,可以缓存多次操作,一起插入或更新;通过一行删除标记减少删除开销,定期统一删除。
不同列的数据会组织在不同地方。 - 各列独立存储,且数据类型已知,可以据此做数据压缩(如压缩连续的相同值),节省空间。
如果某些记录的某些字段为空,可以不存储。 - 每一列本身就相当于索引(给出该列的值可以找出对应记录),不需要再创建索引。(why?)
- 适合 OLAP(Online Analytical Processing)系统。
分库分表
垂直分表:将一个表按照字段分成多个表,每个表只存储部分字段。
常见方式:
将热门字段(访问频率高的)和冷门字段(不常用的)放在不同表中。
将text, blob 等大字段拆分放在另一个表中。
(行存储数据库中)不需要的字段也会在读取行时被访问,因为数据库对磁盘的访问以页为单位,无论读取几行,每次也要读整页到内存中?而且每行数据量越大,每页保存的数据就越少,当访问多行或全表扫描时,需要读取的页数就更多。块是一个逻辑单元,包含固定数目的连续扇区。数据在磁盘和主存储器间以块为单位传输。
页通常指块,或者块大小的倍数,不同数据库可以不一样。数据库读写的基本单位是页。
数据库的页通常比内存的页大,所以在数据库读确切位置的少量数据时,应该只需要调接口读那个位置,操作系统会将对应的页(内存页)读入内存,然后内存取出那部分数据给数据库?
其它时候是以数据库的页为单位(就读那么多),不会考虑也看不到操作系统的页的概念。将经常一起查询的字段放在同一张表中。
优点:
- 减少冲突,查看详情的用户与商品信息浏览互不影响。
- 大字段、冷门字段不会影响其它字段的查询效率。
水平分表:将同一个表中的数据(按一定规则)拆分到不同的表中。
垂直分库没有解决单一表数据量过大的问题。
优点:避免单一表数据量过大;减少锁表的性能损失。
垂直分库:按照业务将表进行分类,分布到不同的数据库上面,每个库可以放在不同的服务器上。
分表后数据还是限制在一台服务器中,每个表还是会竞争同一个物理机的各资源(CPU、内存、网络IO、磁盘)。
优点:
- 多个服务器可以共同分担压力。
- 能对不同业务的数据分别管理、维护、监控、扩展等。
- 划分业务,使逻辑更清晰。
水平分库:将同一个表中的数据(按一定规则)拆分到不同的数据库中,每个库可以放在不同的服务器上。
垂直分库没有解决单一表数据量过大的问题。
优点:避免单一表或单一数据库数据量过大;减少锁表的性能损失。
分表分库的问题
- 分库:分布式系统的一致性问题;同一表的数据被分布到不同库中,操作会更加复杂。
- 联合查询:原本简单的sql可能要操作更多表和更多库。跨节点查询时,可能要分多次对不同节点的请求,最后合并。
- 分页、排序:跨节点时,可能要在多个库中执行大量相应操作(取第n页要每个库都取前n页),最后合并。
- 主键判重:常用的递增主键在分表后无法判重,要设计全局主键。
- 对于数据量少、改动少、可能高频联合查询的表(如参数),可以在每个数据库中都存一份,更新时全部更新。
横表 纵表
常见的就是横表:每一行包括该数据的各个字段。
竖表:每一行只包括某条数据的一个字段(字段名和值)(再加上主键),同一条数据要用好多行表示。
横表中的数据很直观,方便联合查询和维护,但添加新字段时要重建表;纵表添加新字段只需插入记录,但不直观、不方便。
如果表结构经常改动,可以设计为纵表。但很少见这种设计?或者这抛弃了sql的一些优点,不如直接用nosql?见nosql。
大字段
对于不会用来搜索,但是会一起读取、修改的大量字段(如表单)(前提),可以用一个text段序列化后存储;主键或经常搜索的字段则正常分字段存储。
现在数据库一般也提供JSON格式,用JSON存更高效,还能读对应的键值。
这好像就是nosql的设计思路?见nosql。
mysql 深分页问题
mysql limit s,o的原理是:检查s+o条记录,舍弃前s条记录,返回最后o条记录。
因为只这样,是无法确定第s条是从哪开始的。所以当limit参数太大时,每次效率都很低。
例:
select * from orderwhere user_id > xlimit 1000000, 10;
如果查询条件为主键索引,要进行遍历:首先找到第一个user_id > x的节点,然后遍历1e6次,再取接下来的10个。
如果查询条件为辅助索引,理论上和主键索引一样,遍历1e6次,取10个。但由于 mysql 的实现/优化问题?会先将这1e6+10条数据的id回表查询(用id在主索引中查)出1e6+10条数据,然后再取10个。
也就是先回表,然后才取 limit。
当涉及order by a limit时,如果a没有索引或查的不是a的索引,还要将所有可能数据缓存,之后排序。
所以深分页主要问题为:遍历数据量大,回表次数多,排序代价高。
方法1 子查询限制回表
可以限制回表查询的数据量为10个,即用子查询先让它 limit,减少1e6次回表,再和表 join。
但优化效果有限。
select * from userinner join (select id from orderwhere user_id > xlimit 1000000, 10) as t on user.id = t.id;// 用 id in (select ... limit ...) 也行,但麻烦点。
方法2 记录上一页的最大/最小id
每次返回数据,都将当前页的最大id或最小id返回给前端。前端下次请求时带上这个数据。
用主键可以过滤一大部分数据,优化效果更好。
但是:不一定很有效;需要有自增id;只能支持上一页/下一页的查询,不能任意页跳转。
可用于瀑布流信息类的应用。
方法3 限制查询
限制offset的参数范围:不允许过多页的跳转或访问。
逻辑外键
创建表时,可以用 foreign key 指定一个物理外键,数据库会创建两张表之间的关联关系,并在使用过程中确保该外键的合法性。
不使用 foreign key 指定,但在逻辑上是一个外键的字段,叫逻辑外键。程序员需要自己保证外键引用的合法性。
通常都是用逻辑外键,因为数据库会对所有涉及物理外键的操作都进行额外检查,消耗资源;还会锁两张表?死锁的可能性更高?如果拆分开分别操作就不会。
范式
TODO
是关系型数据库中表的设计原则。可以避免数据冗余 和 一部分设计上的问题。
SQL
一句 SQL 的执行可以触发回滚吗
可以。如果 SQL 的执行发生了错误,或违反了一致性约束,它做出的操作会被回滚。
如果将它放到事务里,则执行成功也会被回滚。
开始一个事务后,如果不提交直接关闭会话,则事务被回滚;如果开始后,再开始另一个事务,则默认提交之前的事务。
replace
函数replace(str, s, t)将字符串 str 中的所有 s 替换为 t。
例:select replace(name, 'a', 'b') from user;。
replace into
与 insert into 类似,但如果因为主键或 unique 的字段冲突,导致插入失败,replace into 会删除原数据并成功插入,insert into 不能插入。所有 replace into = delete if conflict + insert。
is null 与 = null 的区别
null 不代表任何实际的值。
在 ANSI SQL 标准中,将涉及 null 的任何运算(如等于、不等于、大于小于 null、null = null)的结果都视为 unknown。
谓词 is null 和 is not null 则是判断数据是否为 null。
在非 ANSI SQL 标准中,= null 等价于 is null,<> null 等价于 is not null。
unknown 创建了 true false 外的第三种逻辑值。
任何布尔表达式 A and unknown 的结果还是 A;true or unknown 的结果是 true;false/unknown or unknown 的结果是 unknown;not unknown 的结果还是 unknown。is unknown 和 is not unknown 可以测试一个表达式结果是否为 unknown。
SQL 优化
select count(*)
对select count(*) from user where xxx;如果没有合适的索引,则数据多时,查询会非常慢(全表扫描)。
如果只是判断是否存在至少一个符合条件的行,可以select id from user where xxx limit 1;限制结果大小。
nosql
nosql 与 sql (或非关数据库与关系型数据库)
https://www.zhihu.com/question/547871453
其它可参考:
https://www.zhihu.com/question/547871453/answer/2868977616
为什么使用 sql:
关系型数据库的数据之间是有数学关系的,就是关系代数。
关系型数据库的所有操作都可以用那几种关系代数表示,关系代数运算可以看做是一种底层语言(比如汇编),我们写的sql(Structured Query Language) 可以看做一种高级语言,数据库帮我们将sql翻译为关系运算,同时能进行进一步优化。
此外,对关系运算的执行也可以进一步优化。
关系型数据库允许我们使用高层的 sql 语言描述操作,然后自动将其更高效的执行。
关系型数据库(的同一个表)中,每条记录(以及每个属性)基本是等长的,再找第x条数据时非常方便(但好像没有这种需求?)。
关系型数据库的数据在磁盘上的存储是有规律的,同时有主键和索引,就可以通过B+树去高效查询记录。
关系型数据库提供了事务、表锁、行锁等自动可靠的机制。
关系型数据库可以数据添加各种约束,保证一部分数据合理性。
关系型数据库基于数据特点,提供了高效的访问、可靠省心的机制。
但是,关系型数据库的数据特点本身,也限制了数据类型:数据的属性数、属性类型国定,长度也固定,一旦改动表的设计就要花费很大的代价。
这就要求很高的数据库设计能力:能预见业务特征,设计出非常合适的表。
各种范式的设计也是利用了数据间的关系。此外使用者必须对数据库有足够了解,才能正确使用它提供的各种机制。
为什么使用 nosql:
有大量的数据是无规范、无格式的(比如网页),很难对它做属性划分,最后只能做一个大文本存储,然后设置一个索引。
这基本就相当于文件系统。对此也是可以有各种优化的。
但是,nosql 只能提供一个 key-value,每次查询只能取得一整个value,然后扫描获取里面的信息(比如存json)。如果只是要value的一部分信息,这可能是非常低效的。
所以,sql 和 nosql 的使用完全看场景。比如关系型数据库用来做数据的存储与持久化,非关系型数据库用来做缓存。
nosql 通过降低数据的安全性,存储更少的数据,减少对事务、复杂查询、SQL 的支持,获取性能上的提升。
(但是现在的 集群+自带的可持久化 足够保证数据的安全性,所以 nosql 除了数据量受限外,几乎没有缺点,所以非常常用于缓存)
nosql 分为四类:键值存储,文档,列族存储,图形存储。各有特点,见这里。
总的来说,优点有:
数据模型灵活,可以处理非结构化/半结构化的大数据。
高扩展性:容易实现可伸缩性(向上扩展与水平扩展),能轻松地添加新的节点来扩展这个集群。
关系型数据库由于存在join这样的多表查询机制,使得数据库很难扩展。读写性能高:数据无关系性,数据库结构简单。而关系型数据库受限于磁盘IO。
缺点:
- 没有固定的查询标准,学习成本高。
- 大多数不支持事务。
- 大多数都是初创产品,不够成熟。
为什么 InnoDB 有 buffer pool,也还要用 redis
InnoDB 的各种模块都是面向磁盘设计的,包括 buffer pool、日志、事务、里面的各种算法(比如 b+树、缓存的 LRU 策略),主要目的是优化磁盘 IO,而不是内存。
所以即使所有数据都在内存中,InnoDB 还要在日志、锁、事务等机制上花 比内存数据库多很多的时间。
内存与磁盘的区别太大,软件设计必须针对性设计和取舍,才能充分发挥一种存储介质的作用。
此外 redis 也放弃了对 sql 的支持,换取了更高的性能。
见 mysql - InnoDB 的 LRU 策略
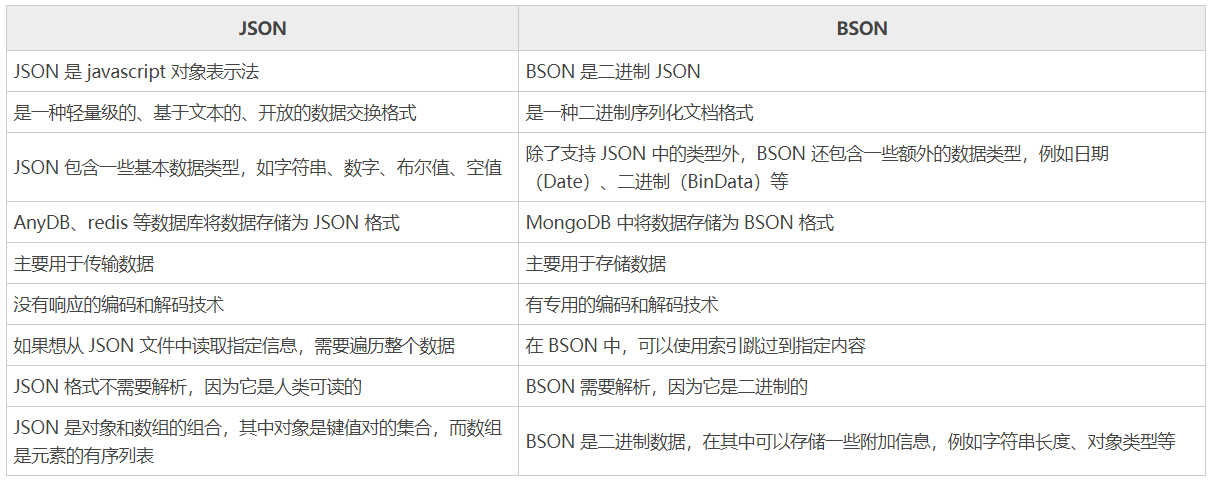
BSON
JSON 全称“JavaScript Object Notation”,是常用的可读的数据交换格式。
BSON 全称“Binary Serialized Document Format”,算是二进制 JSON,将对象序列化为二进制。
因为是用二进制的方式,在序列化、反序列化的速度上要优于JSON,但没有可读性。占用空间上,有说少于JSON的有说多于的。
mysql
mysql优化
TODO
https://my.oschina.net/u/142836/blog/169415#OSC_h4_7
(https://blog.csdn.net/shixiaoguo90/article/details/24176313)
mysql引擎
mysql> SHOW ENGINES;+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+| Engine | Support | Comment | Transactions | XA | Savepoints |+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+| MEMORY | YES | Hash based, stored in memory, useful for temporary tables | NO | NO | NO || MRG_MYISAM | YES | Collection of identical MyISAM tables | NO | NO | NO || CSV | YES | CSV storage engine | NO | NO | NO || FEDERATED | NO | Federated MySQL storage engine | NULL | NULL | NULL || PERFORMANCE_SCHEMA | YES | Performance Schema | NO | NO | NO || MyISAM | YES | MyISAM storage engine | NO | NO | NO || InnoDB | DEFAULT | Supports transactions, row-level locking, and foreign keys | YES | YES | YES || BLACKHOLE | YES | /dev/null storage engine (anything you write to it disappears) | NO | NO | NO || ARCHIVE | YES | Archive storage engine | NO | NO | NO |+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+9 rows in set (0.22 sec)
Support表示是否支持。DEFAULT为当前默认引擎。
MyISAM引擎
与InnoDB比较:https://blog.csdn.net/qq_35642036/article/details/82820178
https://zhuanlan.zhihu.com/p/500044669客户端直接与 MySQL 通信。MySQL 是 server 层,通过存储引擎的 API 与存储引擎层协作。存储引擎负责直接操作内存、磁盘。
server 层包括:管理数据库连接、认证、权限;缓存优化;分析器;优化器;执行器。
InnoDB 和 MyISAM 都是存储引擎层。
MyISAM适 合简单查询为主的应用,但很多功能没有(比如不支持 ACID,可靠性低)。
- 优点:因为要维护的东西少,查询更快一点;支持全文索引(但 InnoDB 之后也支持)。
保存了表中总记录数,对count(*)可以直接返回。
(清空整个表时,InnoDB 是一行一行的删除,效率低。MyISAM 则会重建表?) - 缺点:没有行级锁;不支持事务、外键;没有持久性保证,崩溃后不能恢复(而 InnoDB 有 redo log);不能实现 MVCC;没有缓存池。
- 其它特点:没有聚簇索引,所有索引都保存数据的地址。查询辅助索引时不需要回表。
但数据可能在插入删除时,地址发生改变(页合并或拆分),所有索引都必须进行更新。所以一次插入删除操作可能导致大量的索引更新。所以 InnoDB 是存的主键。 - MyISAM 不支持 XA 协议,不能用 XA 实现分布式事务。InnoDB 可以。见 分布式 - XA。
InnoDB 为什么不保存表中的总记录数,对
count(*)要重新数?
因为 InnoDB 有事务,且事务之间有隔离性要求,对不同事务能看到的数据不一样,count(*)的结果自然也不一样,不能直接保存。对于 count(*),InnoDB 会遍历尽可能小的索引(一个节点可能包含多条记录),获取记录总数。遍历的过程中不需要读取记录,所以还比较快。
对于 count(字段),遍历记录时,还要取出字段判断条件。
show table status命令会返回table_rows,该值确实记录了表的行数,而且查询很快,但对事务来说很可能是不准确的,误差可能很大。
如果准确性要求不高,可以用。如果想更快获得
count(*),要自己在表之外统计,用另一张表存放该值,在执行操作时更新。
InnoDB 推荐使用自增ID作为主键
自增ID可以保证每次插入B+树时,是在最右边插入的(可以使每个节点是满的),减少B+树合并或分裂的次数(与UUID相比)。如果使用字符串主键或随机主键,会使得数据随机插入,效率比较差。
所以插入大量数据时,最好按序插入。
Innodb引擎
支持行和表级别的锁。当一条语句指定到具体的索引时,使用行锁(行指索引);否则使用表锁。
innodb引擎的4大特性:插入缓冲(insert buffer),二次写(double write),自适应哈希索引(ahi),预读(read ahead)
插入缓冲 (insert/change buffer)
change buffer 是 buffer pool 的一部分。
在执行非聚集索引上的更新,且该索引是非唯一索引时,操作不会立刻更新到原表中,而是放到缓存。之后的某一时刻统一写入表中。查询时可以使用这个 buffer。
统一写表,需读取的页会更少,减少了 IO 次数。
不用于唯一索引,因为唯一索引需检查该索引是否出现,还是要查一次原表。
二次写 (double write)
Innodb 的页大小为16K,比较大,所以故障恢复特别重要。
- 内存中的脏页(dirty page)不会直接写回到磁盘,而是先写到double write buffer中。此时会将页顺序写到buffer中,效率高。
- 将buffer中的数据复制到一个共享表空间中。也是顺序拷贝过去。
- 将共享表空间的页写回到磁盘。此时不能做到连续写,会比较慢。
只有前一步写入成功,才进行下一步。
当 1 2 过程中出现故障时,只需分别从内存和buffer重新写入。
当 3 过程中出现故障时,只需从表空间中重新写。
buffer 和共享表空间的大小都为2MB。
自适应哈希索引 (Adaptive Hash Index, AHI)
InnoDB 会监控对表上索引的查询。如果检测到在某些索引上(内存中的B+树索引)建立 hash 索引可以提升性能,就会在缓冲池为其建立 hash 索引。
即根据访问的频率和模式自动地为某些热点索引页建立 hash 索引,以加快辅助索引的读取。
只适用于等值查询。
某些情况下,监视索引查询并维护哈希表的代价,超过了它能带来的价值(如 经常的 like 查询?)。可以考虑关闭 AHI 来提高性能。
不过这种情况不好判断,可以开、关 AHI 分别做个 benchmark。
**预读 (read ahead) **
预估之后要用到的磁盘页,并将其提前异步读取到 buffer pool 中。
使用两种预读算法:
- 线性预读(Linear read-ahead):认为被访问到的区块的临近块也会很快被访问到。
一个区块 (extent) 为 64 页。如果在一个区块内连续(?)读取的页数达到innodb_read_ahead_threshold,InnoDB 将下一个区块异步读入缓存。
该参数范围为0~64,默认为56。 - 随机预读(Random read-ahead):通过 buffer pool 中已有的页,预测哪些页可能很快会被访问。
当某个区块的连续 13 页都在缓存中,且这 13 页都在 LRU 热区域的前 1/4 位置时,会将该区块中剩余的页异步读入缓存。
需要innodb_random_read_ahead为ON。
InnoDB 的 LRU 策略
首先是预读,分为线性预读、随机预读。
LRU 也是哈希表+链表实现的,链表尾部的使用时间旧,头部的使用时间近,每次从尾部弹出,加入头部。
但传统的 LRU 有两个问题:缓存池污染、预读失效。(Linux 中的 LRU 有同样类似的策略)
预读失效:
预读会将可能用到的页读入缓存,但即使它们可能用不到,也会导致缓存中的原热点数据被替换掉,导致缓存的热点数据失效(和直接读硬盘一样)。
解决:将链表节点按 5:3 分成新生代和老年代 (new/old sublist)。通过预读加入的数据被放在老年代,优先丢弃。如果老年代的数据真的被访问到,才放入新生代,后丢弃。(用户操作导致的数据直接进入新生代)
通过在离链表尾 3/8 的位置(innodb_old_blocks_pct,默认37.5%)加入一个 midpoint 实现,老年代数据从这里开始插入,新生代从链表头插入。
新生代就是热数据,访问频率高;老年代是冷数据。
缓存池污染:
当进行全表扫描 或大量的查询时,LRU 会将整个表读入缓存,并成为新生代,将缓存中的原热点数据都替换掉。但读入的表很可能就用这一次,导致热点数据失效。
解决:提高数据成为新生代的门槛:老年代的数据,只有在第二次访问且距离上次访问超过一定时间后(innodb_old_blocks_time,默认1s),才能成为新生代。
InnoDB 的 buffer pool
缓存池里面的页分三类:
free page:未被使用的页。
clean page:被使用了,但没有更新的页。
dirty page:被使用了,且有修改的页,与硬盘不一致。
主要有三种管理页的链表结构:
free list:空闲页链表,管理 free page。
flush list:脏页链表,包含脏页,定期进行刷盘。
LRU list:正在使用的内存页链表,包含 clean page 和 dirty page,是 LRU 使用的链表。
(链表节点是页的信息,称为页的控制块,不是页本身。LRU 的哈希表使用页信息为 key,控制块为 value)
脏页刷盘由后台线程定期执行(或脏页的数量达到了缓存池的10%),主要有三种方式:
- BUF_FLUSH_LRU:从 LRU 链表的老年代刷部分脏页到磁盘。
- BUF_FLUSH_LIST:从 flush 链表中刷部分脏页。包含老年代和新生代数据。
- BUF_FLUSH_SINGLE_PAGE:当缓存不足时,刷新从缓存中淘汰的页。要尽可能避免。
buffer pool 还有预热机制:
机器重启时缓存会清空,所以 mysql 在关机时会把热数据写到 ib_buffer_pool 文件中,启动时加载到缓存。
mysql 的缓存
mysql 中主要有三类缓存,前两个是 InnoDB 的,第三个是 MyISAM 的:
- 缓存池 buffer pool:数据页和索引页的缓存。以页为单位。取数据时先检查这里。
- 查询缓存 query cache:见下。
- key buffer:MyISAM 的索引块缓存。数据块使用操作系统提供的缓存。使用 LRU 策略。
当然还有 redo log buffer 等。
query cache
在 5.7.20 后默认禁用,在 8.0 正式删除。
见这里。
查询缓存会将每次 select 语句和其结果保存。当之后遇到一个完全一致的 select 语句时,可以直接从缓存中返回。
如果一个表发生更新,则所有与该表相关的 select 缓存都会被清除(实际可以用版本号/更新时间比较有效性?)。
如果表不怎么发生修改,且某个查询经常出现,就能提高执行速度。
但是,这只适用于少数情况:比如 web 服务器根据请求返回指定页面。
其它情况可以在 select 中指定SQL_NO_CACHE不使用查询缓存。直接将query_cache_size设为0会禁用。
- 在 5.6 中,query cache 的效果没有随着多核机器上吞吐量的提升而提高。
- 大多数情况下,修改经常发生,查询不会相同,非常容易缓存不命中;反而过多次的对 select 的哈希会影响性能。
测试表明,QC 可能导致性能下降严重。
将缓存放到离客户更近的位置(比如客户端),才能更好的提升性能。 - 会导致响应时间不可预测。这可能效率更重要。
以下情况的结果不会被缓存:结果过大、嵌套子查询外部的查询、函数/过程/触发器中的查询、包含不定值的查询(比如使用了 now())。
InnoDB如何存储数据
TODO
MYSQL事务的ACID
A (Atomicity, 原子性):事务的所有操作要么都成功,要么都失败。
C (Consistency, 一致性):事务的运行不会改变数据库的一致性约束。(这个是外在业务的逻辑要求,与分布式系统的一致性不同)
I (Isolation, 独立性):并发的事务之间不会互相影响。一个事务只要还未提交,就不会影响其它事务,好像它没有在执行一样。
D (Durability, 持久性):一个事务提交后,它做出的修改就会永久储存在数据库上,不会丢失。
MySQL原子性怎么保证
TODO。
事务。事务提交前,会保证 WAL 日志被写入持久化存储设备。
WAL 日志 (write ahead log)
与其它使用 LSM 的引擎一样,InnoDB 对于数据的修改有两部分:将日志写到磁盘(就是redo log);将数据写到缓存,后续再写到磁盘。
redo log 是数据冗余,但保证了可靠性。
mysql 还有一个 binlog,与 redo log 类似,但 redo log 一般循环使用,只保留短期操作以节省空间;binlog 将很长时间的历史记录都保存下来。
因为 binlog 不是为当前这个机器上的数据库服务,而是为其他数据库服务的。比如主从模式下,可用于从数据库复制数据(类似 redis 的 RDB)。
如果一份数据在多个机器的内存中分布存储,且我们认为它们同时故障的概率几乎为0,我们可以不用 WAL 日志。
因为分布式环境下,一个机器的故障,可以由其它机器弥补。但是,数据恢复一般就是由日志完成,不能全量复制。
mysql 的锁
InnoDB 包含三种锁:
表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率高。
行级锁:开销大,加锁慢;会出现死锁;锁定粒度小,发生锁冲突的概率低。
间隙锁 (gap lock):处于表锁和行锁之间。加在索引上的锁,会覆盖一个开区间。
还有 next-key lock,见下。
读锁/共享锁 (share locks, S锁):加了读锁的记录,所有的事务都可以读取,但不能修改。可同时有多个事务对记录加读锁。
写锁/排他锁/独占锁 (exclusive locks, X锁):加了排他锁的记录,只有拥有该锁的事务可以读写。同一时间只能有一个事务加写锁。
意向锁 (intention lock):表级锁,分为读意向锁 (IS 锁) 和写意向锁 (IX 锁)。当事务要在记录上加上锁时,要先在表上加上意向锁。这样判断表中是否有记录加锁、是否能加表锁就很简单了,只需要看表上是否有意向锁。
自增锁 (auto_inc lock, AI 锁):当表中有自增列时会生成该锁。生成自增值时,会先加自增锁,阻止其它事务修改,来保证自增值唯一。一个表同时只能加1个自增锁。自增值+1后,就不会再减回去。
>
还有其它的意向锁:插入意向锁,一种特殊的间隙锁,是行锁。
锁的兼容矩阵:
意向锁之间互不冲突。
S 锁只和 S/IS 锁兼容,和其他锁都冲突。
X 锁和其他所有锁都冲突。
AI 锁只和意向锁兼容。
InnoDB 的行锁是通过给索引上的索引项加锁来实现的,所以只有通过索引检索数据,才使用行级锁,否则使用表锁。
意向锁在update, delete, insert操作时会自动添加,select默认不加任何锁。
事务通过select ... lock in share mode,可以显式地给记录加共享锁。注意事务不要再给该记录加写锁,会死锁。
事务通过select ... for update,可以显式地给记录加排他锁。
有一/二/三级封锁协议,应该是一种实现隔离级别的方式。
一级封锁协议:要求写数据要加写锁,在提交时释放。
但是读(或者select?好像select不一样,不确定)不加任何锁,所以即使一个数据有写锁,事务也能用select继续访问数据。
二级封锁协议:要求读前也加读锁,读完释放。
三级封锁协议:要求读/写均要加读/写锁,在提交时才能释放。
MySIAM 只有表锁,分为表共享读锁 (table read lock)、表独占写锁 (table write lock)。
next-key lock
一个间隙锁(范围为一条记录x到前一条记录px,开区间)和一个行锁(记录x)的结合,所以 next-key lock 的范围为,左开右闭。
用于在可重复读的前提下,避免幻读,实现可串行化:
以辅助索引 a 为例,主键为 id。a 的B+树中存储的值为(id, a)(注意,当 a 相等时,按 id 大小排序)。
当读写时,为了避免幻读,要给加锁,包括:所有的记录的 next-key lock (锁住当前记录,和与前一条记录的区间),最后一个的记录与它下一条记录之间的间隙锁。
即避免幻读,要用符合该区间的记录的 next-key 锁,和区间最后的一个间隙锁 实现。
同理。
一些例子:https://www.zhihu.com/question/334081090/answer/2265539386
mysql 的死锁处理
InnoDB 一般可以检测到死锁。但在涉及外部锁或表锁的情况下,不能完全检测到死锁,会通过锁等待超时参数innodb_lock_wait_timeout来解决。
在高并发系统上,锁检测可能影响效率,可关闭锁检测,只使用超时机制。
发生死锁后,InnoDB 使一个事务释放锁并回滚,另一个事务获得锁,继续完成事务。
MySIAM 会一次获取事务所需的所有锁,所以不会死锁。https://www.cnblogs.com/flashhu/p/8324551.html
InnoDB 的 MVCC
多版本并发控制(Multiversion Concurrency Control):通过 undo log 为每个数据保存多个版本,事务只使用版本合适的数据。
InnoDB 在每行数据加了两个隐藏字段:
- DB_TRX_ID:最近一次修改该数据的事务ID。包括增删改,删除不会立刻删除数据,而是进行标记。
- DB_ROLL_PTR:回滚指针,指向一个 undo log 链表。
一个 undo log 记录了这次修改前的原数据(或上次对该数据的修改操作?以便能进行回滚、看到旧版本的数据)。此外也包含 TRX_ID 和 ROLL_PTR,表示产生这个数据的事务ID,和再上一次的 undo log。
(还有一个 DB_ROW_ID,不重要,是单调递增的行 ID。如果没有主键和唯一非空索引,就使用这个 ID 建立聚簇索引)
Read View(读视图):一个对目前事务状态的快照。
包括:
- trx_ids:创建 read view 时,所有未提交的事务的 ID 列表(不包括当前事务自己)。
- creator_trx_id:执行 read view 的事务 ID,即自己的 ID。
- low_limit_id:当前出现过的最大事务 ID+1,即下一个可分配的事务 ID。
- up_limit_id: trx_ids 中最小的 ID。
设一个事务的 ID 为 x,称 x 对一个 read view 可见,当且仅当满足以下条件之一:
- x < up_limit_id,即一定不在 trx_ids 中。
- x >= up_limit_id,但 x < low_limit_id 时,如果 x 不在 trx_ids 中则可见。
换句话说,如果 x 在 trx_ids 中就为不可见。这个判断要通过二分完成,所以用 up_limit_id 和 low_limit_id 减少判断。
读数据时,只能读取 对当前 read view 可见的事务做出的修改。
所以读取某个数据 a 时,如果 a 的 TRX_ID 对 read view 不可见,则遍历 undo log 列表,直到找到最后一次 可见事务做出的修改。
在 读已提交 RC 级别下,每次 select 都会生成最新的 read view,从而保证不会读取未提交的数据。
在 可重复读 RR 级别下,只有第一次 select 会生成最新的 read view,后续还用这个视图,从而保证读取结果一致。
这里的 select 都是指快照读。如果直接加锁,肯定更能满足。
幻读
只通过 RR 级别下的 MVCC,只能避免一部分幻读问题(如 A select; B insert; A select;)。
因此 MySQL 提供了两种读语句:
当前读(current read, locking read):select ... in share mode、select ... for update。
快照读(snapshot read):RC, RR 级别下,普通的 select(与上一种区分)都是快照读,不会加锁,使用 read view 快照和 undo log 获得数据。
当前读会给读加锁,直到事务提交或回滚才释放,且保证了会读到最新的数据。其实就与update等操作相同。由于不使用读视图,所以和快照读混用时,会导致读取结果不同。
如果有未提交事务已更改数据,会阻塞然后加锁。share mode会加读锁,允许其它事务读;但for update与直接update类似,不允许其它事务读。
当前读的 select 中的子查询不会被自动加锁,除非也写为当前读。
当前读的锁不会阻止快照读通过 undo log 读取旧的数据。这提高了并发度。
在以下情况之一时,MVCC 会出现幻读:
- 事务 A 进行无条件的 select *;事务 B 开始、插入一条数据、提交;事务 A 进行无条件的 update 修改所有数据,再进行 select *。
由于 update 能看到最新的数据,包括 B 插入的数据,所以导致幻读。后续的 select * 也会看到 B 插入的数据。 - 事务 A 进行无条件的 select *;事务 B 开始、插入一条数据、提交;事务 A 进行无条件的当前读 select * for update。
当前读能看到最新的数据,即 B 的数据,导致幻读。
原因是,只有快照读才会使用 read view,DML 语句(包括 insert, update, delete, 当前读)不会,会加锁并获取最新数据,所以可能受其它刚刚提交的事务影响。见这里的 Note。
只有连续的快照读,或连续的当前读,才能保证前后结果一致。
为了解决幻读,必须给每个读操作都加锁(且显式?)变成当前读。加的锁即 next-key lock,行锁和间歇锁的组合。
但这样就相当于,每个读写操作前都要加锁,提交或回滚时才释放,这就是 S2PL,即可串行化隔离级别。且 read view、undo log 或者说 MVCC 都没太大用了。
Purge
为了实现多版本,数据不会被立刻删除。
Purge 线程维护了一个 read view(应该是当前未提交事务的 trx_ids 的并),如果某个数据被标记为删除,且做出删除操作的事务ID 对该 view 可见,则可安全删除该数据。
Purge 也会定期回收 被标记为已提交或已回滚、且不再用到的 undo log。
steal, force
steal:允许未提交事务将修改更新到磁盘。
force:强制事务提交前,修改一定要同步到磁盘。
steal + no force 是主流的做法,所以要:有 undo log,便于回滚;有 redo log,保证数据不丢失。
InnoDB undo log
每个修改操作会记录一条 undo log,包括修改前后的值、操作类型。
undo log 不仅用于实现 MVCC,还用于事务回滚。
undo log 有两类:
- insert undo log:当事务执行插入时产生。只用于事务回滚,在事务提交后就可以删除了。
- update undo log:当事务执行 修改、删除 时产生。不仅用于事务回滚,还用于 MVCC。会在不再需要时删除。
若干个 undo log 存储在一个 undo log segment 中?一个 segment 可能包含多个事务的 undo log,但同一时刻只能由一个事务持有。当不需要时,可删除整个 segment 的 log 供其它事务使用。
undo log 是记录在数据文件 .ibd 中的,而且 Innodb 将 undo log 内容看作是数据,因此对 undo log 本身的操作,都会记录在 redo log。所以 undo log 不需要立即写到磁盘上,可以写到缓存。即使丢失,也可以通过 redo log 恢复。
所以插入一条记录时:
- 向 undo log 中加入一条 undo log 记录。
- 向 redo log 中加入一条“加入某 undo log 的记录”的 redo log 记录。
- 修改数据。
- 向 redo log 中加入一条“修改了某数据”的 redo log 记录。
故障恢复时,要先执行 redo log,再执行 undo log,因为:
undo log 可能丢失,但会写到 redo log 中,可以通过 redo log 恢复;
MySQL 是 steal + no force 策略,所以事务提交前,数据也可能写到磁盘,必须 undo 恢复。
InnoDB redo log
redo log 是记录所有修改的日志(记录数据页发生的修改)。
是 InnoDB 保证持久性的方式,用于数据恢复 (crash-safe)。
事务提交前,必须先把对应的 redo log 写到磁盘,但是不需要立刻将数据写到磁盘。这就是 WAL (write-ahead log)。
数据刷盘是随机写,而更新 redo log 是顺序写,所以写日志会更快,既保证了持久性,也提高了响应速度。
内存与磁盘交换的单位是页,如果数据一修改就刷页也很浪费。
为提高性能,有以下特点:
- Redo log 也有缓存 redo log buffer,会在 事务提交、或每隔一段时间,批量写入磁盘(见下)。
- 并发的事务共享 Redo Log 的存储空间:它们的 Redo Log 按语句的执行顺序,依次交替的记录在一起。
- 只会对 Redo Log 进行追加。当一个事务回滚时,它的 Redo Log 记录也不会从 Redo Log 中删除。
- 会尽量保持 Redo Log 存储在一段连续的空间上。因此在系统第一次启动时就会将日志文件的空间完全分配。以追加的方式记录 Redo Log。
- 因为不需要一直保留,空间用完时,会覆盖最早的 log 继续写。
会维护一个 checkpoint,它之前的都是可以删除的日志(数据已刷盘);写入时不能超过 checkpoint(可能要等待它移动)。
用户空间中的缓冲区数据一般是不能写到磁盘的。需要先写到内核空间的缓冲区 os buffer,然后通过系统调用fsync()写入磁盘。
redo log buffer 写磁盘的策略有三种:
- 事务提交前,都将 redo log buffer 的更新写到 os buffer,然后写到磁盘。
- 每一秒,将 redo log buffer 的更新写到 os buffer,然后写到磁盘。
- 事务提交前,将 redo log buffer 的更新写到 os buffer,但不更新磁盘。每一秒,将 os buffer 写到磁盘。
2 和 3 都可能会丢失 1s 的数据。
3 相比 2,应该是将写 os buffer 的代价分摊到了每次提交,而不是写磁盘时一次完成。
redo log 使用递增的 LSN (log sequence number) 标记。
binary log
bin log 记录逻辑日志,用于主从同步和数据备份(可以用于增量恢复,恢复到指定时间点)。
是 MySQL (server 层) 自带的日志。
逻辑日志一般就是 SQL 语句,物理日志是数据页的修改。
类似 redo log,bin log 也有 buffer,根据sync_binlog的值有三种写磁盘策略:
- 值为0:不主动刷盘,由操作系统决定,比如内存页被换出时。
- 值为1:每次事务提交前,都写磁盘。
- 值为n:每 n 个事务提交后,才写磁盘。
与 redo log 不同的是,旧的 bin log 会保留,所以不会覆盖原日志。
bin log 有三种格式:
- statement:记录原始 SQL 语句。日志小,但用做同步时可能导致结果不一致。
MySQL 会给出警告:Statement may not be safe to log in statement format.。 - row:记录每行的数据变化。能保证数据一致,但会产生大量日志文件会很大。一般是用主键标识一个行。
对于某些数据定义语句 (DDL),仍使用 statement,如 create/alter/drop table。 - mixed:混合,默认采用 statement;如果使用 statement 不安全,则使用 row,记录结果,保证数据一致。
statement 什么时候不安全?
网上给的例子都是:涉及当前时间、日期的语句。
官网没有,给的一部分情况是(链接1,链接2):
- insert/replace/create table ... select ... :用指定查询的结果插入/替换/创建某表。
当 select 没有使用 order by 时,结果的顺序可能是不同的,有以下几种原因:节点的存储引擎不同;buffer 的大小不同;MySQL 或 优化器 的版本不同。 - 使用 UUID()(生成唯一字符串)、USER()、CURRENT_USER()、LOAD_FILE()、某些系统变量时。
- 一个触发器或函数导致了对自增列的更新时。
为什么 MySQL 的默认隔离级别是可重复读?
因为在 MySQL 5.0 之前,bin log 只有 statement 格式。如果使用读已提交级别,会导致主从节点数据不一致。
例:主节点上,先执行事务1 再执行事务2,但事务2 先完成,则日志的顺序、即从节点执行的顺序是先事务2 再事务1(没有 GTID 时是串行执行)。所以主从节点上的执行结果可能不同。
但这样会有什么问题?如果是可重复读,为什么可以避免?没搞清楚,外网没搜到(可能是不会搜)。
redo log 与 bin log
为了保证节点同步时数据一致,bin log 中的日志一般是 statement 即原 SQL 语句,恢复效率不高。
而 redo log 直接记录数据的修改,恢复效率高。
所以 bin log 是节点同步的手段,redo log 是本机故障恢复的主要手段。
主节点故障后,通过 redo log 恢复自己,通过 bin log 恢复其它节点的数据。
所以,如果要保证数据一致,redo log 与 bin log 必须一致。
为此,MySQL 使用两阶段提交,来保证 redo log 与 bin log 。分为3步:
- 事务提交前,写入 redo log,标记为 prepare,但不提交。
- 写入 bin log。
- 将 redo log 标记为 commit,提交事务。
数据恢复时,bin log 直接用,执行 redo log 时在提交前要进行检查:
- 如果 redo log 标记为 commit,提交。
- 如果 redo log 标记为 prepare,检查 bin log 中是否有对应的条目(有共同的属性 XID)如果有提交,否则回滚。
如果不用两阶段提交这3步,显然 redo log, bin log 无论哪个先写都是可能丢数据的(前者先写从节点丢,后者先写主节点丢)。
所以必须有一个日志等另一个写完。
relay log
中继日志 relay log 用于主从节点同步。从节点会拷贝主节点的 bin log 到 relay log,所以与 bin log 格式相同。
具体作用见下。
SQL thread 执行完后,会删除。
为什么要有 relay log,不能直接用 bin log 吗?
搜不到相关的解释。可能是因为,bin log 要求只有提交的数据修改才会被记录,这样才能用于节点同步。虽然可以做些修改,但语句执行时也会再记录一次 bin log,这个机制也没有必要再改。
如果引入一个临时的 relay log,不需要对 bin log 的实现做出任何修改。
MySQL 主从同步
主从同步是实现可用性的方式。有 4 种:
异步复制:主节点处理完请求后,就返回给客户端结果,不等待从节点执行。不保证数据一致。
分为两种:- 主节点通过 dump 线程异步通知从节点:主节点处理请求,提交前写入 bin log;然后主节点的 dump 线程将更新的 bin log 发送给从节点;从节点的 IO 线程将其写入 relay 并等待处理(从 master.info 中读取之前的同步进度?)。
- 从节点主动监听主节点的更新,将其写入 relay。
从节点的一个 IO 线程会连接到主节点,获取主节点的 bin log,将其写入 relay log;另一个 SQL 线程读取并执行 relay log(写 bin log 会在执行时进行)。
SQL 线程是单线程的。全同步复制:主节点处理完请求后,必须等待所有从节点都执行完毕,才返回给客户端结果。
半同步复制:主节点处理完请求后,必须等待一个或多个从节点执行完毕,才返回给客户端结果。
可以配置超时时间,如果该时间后没有从节点响应,直接返回(与异步复制一致)。GTID 异步复制(优化):从节点的 SQL 线程读取 relay log 并执行。它是单线程的,因为只凭 bin log 不能确定(同一个数据库中的)各事务能不能并行执行。
在 5.7 中引入异步复制,会将可以并行执行的事务的 GTID 划分到同一组中,允许多个 SQL 线程并行执行多个事务。
如何决定事务是否可以并行提交?
事务提交时,会记录上次提交的事务序号 last_committed。如果两个事务的 last_committed 相同,则表示它们之间没有依赖关系,可以放到同一组中并行执行。组复制:节点间采用 paxos 算法,来保持强一致性,但效率低。
GTID
GTID (Global Transaction ID) 是一个全局唯一的事务的标识符。
由 服务器的 UUID + gno 组成。gno 是一个用于 GTID 的计数器。
在 GTID 之前,主节点在给从节点发送 bin log 时,会根据 bin log 文件名 + 文件位置 来决定从哪里开始。
引入 GTID 后,就可以直接根据 GTID 决定同步开始的位置。且更加精确,可以用来实现异步复制中的并行执行。
主从的延迟怎么解决
- 不可避免,所以对一致性要求高的请求,只能读主节点。
- 读请求先经过一个中间件,如果数据在从节点中,就读从节点,否则读主节点。
中间件记录最近修改的数据,这些数据要读主节点。记录的数据可在一段时间后删除,认为从节点已更新完毕。 - 5.7 之后,从节点可以通过多线程并行执行 relay log,降低延迟。
故障恢复
数据库 P616
检查点:定期执行检查点,可提高故障恢复的效率。
过程:记录当前未提交事务的列表 L,将一条<checkpoint L>日志写入磁盘,并将当前写过的内存块都刷到磁盘。
下次故障恢复时,可以从检查点开始恢复。
分为两阶段进行:
- 重做阶段:从最后一个检查点开始,正向扫描并执行所有日志,重做所有事务的更新。
期间会维护一个所有未提交事务的列表 undo list,如果有事务提交,就将它从列表中删除;有事务开始,将将它加入列表。 - 撤销阶段:从尾部反向扫描所有日志,如果发现属于 undo list 的事务操作,就执行反向操作。
索引优化
TODO(不确定)
连接类型 type(对于之前连接结果的每一行,查询的方式,或索引的使用情况?)通常是影响性能最重要的因素,有几种,查找效率从高到低为:
- system:系统表,只有一行。
- const:表示通过 主键或唯一索引 查找。结果只有一条记录,所以它的属性值可以看做常数。
- eq_ref:多表连接中使用 主键或唯一索引 作为关联条件,也就是对于每个表,都只有一条记录匹配。
- ref:在匹配某个单独值的所有行中查询。比如前几个属性是等值查询、最后一个属性是范围查询。
- range:利用索引,只检查一定范围内的行。
- index:类似全表扫描,但只扫描一个索引树的叶子。
当查询的内容为覆盖索引(最左匹配了某个索引,即是某个索引的前缀)、且不能优化时,代替全表扫描使用。
索引一般都在内存,所以效率也高;就算在硬盘,数据小,占的页少,需要的IO次数也少。 - all:全表扫描。但不能利用索引优化、查询内容不是覆盖索引时,要扫描全表。
最左匹配原则
使用索引时的规则:
- 我们说,对建联合索引,相当于建了三个索引:,这三种查询只要满足最左匹配原则,都可以使用这个索引。
- 最左匹配原则:假如一个联合索引是,则只有等值查询、范围查询时,才可使用该索引。即最左边的部分要是等值的;如果出现了一个范围查询,则后面的属性都不能用索引。
换句话说,要想使用索引,必须从左到右依次匹配,直到遇到一个范围查询的属性。
原因就是 B+ 树的特点,前面确定时,下一个是有序的。
这种情况下使用的查询方式为ref,即在匹配某个单独值的所有行中查询。 - 如果 id 是字符串属性,对 id 建了索引,则前缀查询
id like 'A%'可以用索引,中缀、后缀查询'%A%', '%A'都要全表扫描。
explain 中的 extra
extra 给出了额外信息。
如果使用的索引已经包含了查询的所有属性(即覆盖索引),则会显示Using index,不需要回表。
(注意所有非覆盖索引中,也包含了主键索引的值用来回表)
索引下推 (Index Condition Pushdown)
MySQL 5.6 的优化。
假设我们有索引,查询select * from user where a<10 and b=1 and c=1;。按照最左匹配,因为是范围查询,所以是不能用索引的。MySQL 会将所有a<10的数据回表查询,然后检查b=1 and c=1的数据。
在优化之后,会在回表前同时检查,只会将所有a<10 and b=1的数据回表查询。
也就是联合索引中的各个属性,都可以参与 where 的过滤,减少回表次数,即使这个属性不符合最左匹配。
索引跳跃扫描 (Index Skip Scan)
MySQL 8.0 的优化,不满足最左匹配原则。
假设有联合索引,我们查询,理论上是不能用的。
但如果的取值类型很少,比如是性别、取值为,则也可以用到索引,相当于将查询分成了三部分,这三部分的都是有序的。
其实就是select * from user where b=1;是等价于select * from user where a in (0,1,2) and b=1;的,后者是对的枚举可以用联合索引。
索引合并 (Index Merge)
如果查询中使用到了不同的索引,可以对不同索引的条件分别进行范围扫描,然后将扫描结果合并得到最终的结果(再回表),以减少回表次数(回表需要查覆盖索引,涉及硬盘访问;但非覆盖索引只会访问内存)。
但是,只能合并同一个表查询结果,不能跨表合并。也不能对fulltext索引进行合并。
EXPLAIN 中 type 列的值为index_merge表示使用了索引合并。根据索引合并算法的不同,会在 Extra 列中显示Using intersect/union/sort_union。
索引合并有三种算法:
- intersect:通过 AND 组合的不同索引的查询条件时使用,各索引需要满足:如果非主键索引包含多个属性,则条件中要包含所有属性的等值查询(对于非主键索引,必须是等值查询)。
主键索引可以是范围查询,并且不会用来组合,而是在最后用来筛选。
对于Using intersect,可以通过建立联合索引来避免。 - union:通过 OR 组合的不同索引的查询条件时使用,各索引需要满足:如果非主键索引包含多个属性,则条件中要包含所有属性的等值查询(对于非主键索引,必须是等值查询)。
主键索引可以是范围查询,并且不会用来组合,而是在最后用来筛选。 - sort_union:通过 OR 组合的不同索引的查询条件时使用,但各索引不满足 union 的条件,即非主键索引是范围查询。
这种情况下,会对各索引的查询结果按主键进行排序,然后进行 union。
前两个的本质是,对每个非主键索引都是等值查询,只会得到一个主键结果,进行交、并都很简单。
后一个得到的也是主键结果,进行排序后进行交、并也很简单。
optimizer_switch中中有4个关于 index merge 的变量:index_merge, index_merge_intersection, index_merge_union, index_merge_sort_union,默认都是启用的。index_merge为 on 则表示启用所有算法。
使用索引/创建索引时要注意什么
- 利用最左匹配原则,可以减少索引的数量:
如果有两种查询,则只需要一个联合索引。
如果有三种查询,可以根据 a,b 属性的大小(单独建索引的代价)决定使用索引还是索引。 - 尽量使用区分度高的索引。区分度可以写为:
count(distinct index)/count(*),对性别加索引区分度就会非常低(不同值区分不了太多数据,导致需要扫描更多行) - 考虑在
order by, group by涉及的属性建索引。 - 不能滥用索引,索引是有代价的,每次更新表时也要更新索引,还有空间开销。
- 只有 or 两边都可用索引时,查询才会走索引。
例:有索引,查询,则不会走索引,因为只有左边可以匹配索引。 - 要尽量避免不使用索引、导致全表扫描的情况(索引失效):
对索引使用函数或运算(函数的结果会无序。考虑给右式做运算);使用 null;使用!=或<>;in后的参数非常多;中缀和后缀字符串查询%a、%a%。
写 sql 时要注意什么
- 少用
select *,要明确需要的字段。 - 避免太大的事务。比如查询的部分可以先查好。
- 避免频繁创建和删除临时表。
- 一次查询不要返回太多数据。可以分页。
- 属性尽量使用数字,少用字符串,比较代价大。
慢查询日志
慢查询日志是 mysql 的一种日志,可以记录响应时间超过一定值的语句,帮助我们分析优化。
mysql 提供了mysqldumpslow帮助分析该日志。
阈值通过long_query_time配置,默认是 10s。
默认不开启,因为也会影响性能。
redis
TODO
一些问题:
https://xiaolincoding.com/redis/architecture/mysql_redis_consistency.html#%E5%85%88%E6%9B%B4%E6%96%B0%E6%95%B0%E6%8D%AE%E5%BA%93-%E8%BF%98%E6%98%AF%E5%85%88%E6%9B%B4%E6%96%B0%E7%BC%93%E5%AD%98
https://xiaolincoding.com/redis/cluster/cache_problem.html#%E6%80%BB%E7%BB%93
https://www.zhihu.com/question/61315701/answer/2114087850
https://www.nowcoder.com/discuss/837063?channel=666&source_id=feed_index_nctrack
redis 为什么快(可以达到单机10wQPS)?
- 基于内存。
- 是单线程的,不会有上下文切换和解决并发冲突的开销:请求放到队列中,用一个线程依次执行。
有 IO 多路复用机制。 - 底层数据结构高效,并会根据实际长度或类型选择编码(数据类型)。
- (相比关系数据库,不支持 ACID,没有 sql 解析器和优化器,不保证强一致性)。
单线程使得 redis 不能充分利用机器资源。即使有些事情会用多线程做,但在多核计算机上,大部分时候也只有一个线程工作。
可以在一个机器上部署多个 redis 服务器,但会带来其它问题?
redis 适合的场景
适合所有数据都放在内存中的场景。虽然也能持久化,但意义更多是备份和同步。
与 memcached 相比,redis 不仅支持kv存储,还提供 list,set,hash table 等数据结构的存储。
例:会话缓存,消息队列(list),排行榜(zset),发布订阅。
为什么用 redis 不直接存在内存/用 map
主要:redis 可以作为分布式缓存,能在不同节点间同步数据,不必每个节点都存一份数据。也提供了集群,比较可靠。
redis 可用于非常大的内存,且执行效率高。
提供了多种高效的结构和多种功能,如事务、持久化、发布订阅。
如果是单机环境,可以用 map,并且直接读写内存会更高效:读 redis 可能是 ms/us 级别,而读一次内存在 ns 级别。
相关讨论见这里。
使用 redis 执行命令的过程:
- 把操作封装成 Redis 命令.
- 从 TCP 连接发送命令(将命令拷贝到网络协议栈的发送缓冲区)
- 等待网络协议栈处理这条数据
- Redis 从 TCP 连接读取命令(拷贝到 Redis 的 TCP 接收缓冲区)
- Redis 解析指令并执行
- Redis 返回执行结果(仍需要通过 TCP,还包括网络栈的两次拷贝及中间的等待)
即使在本地使用 redis,操作也需要通过网络请求完成和传输。
共同缺点:存储容量受内存限制;容易丢数据;缓存和数据库要保持一致;有缓存击穿等问题。
redis 的哈希表底层
链式哈希,同一个桶不够时再连接一个桶。
桶链表过长时,重构,增量更新到另一个哈希表(具体见 redis 源码 部分)。
增量方式:后台定期迁移部分数据;每次访问哈希表时,迁移少量数据。
TODO:其它结构:https://xiaolincoding.com/redis/data_struct/command.html#bitmap
redis 的数据类型
基本:string、hash、set、list、SortedSet。
特殊:bitmap、hyperloglog、geospatial。
redis 数据结构底层实现 - hash/map
也是链式哈希,同一个桶不够时再连接一个桶。
桶链表过长时,重构,增量更新到另一个哈希表。
增量方式:每次访问哈希表时,迁移少量数据。
链表使用的结构为 list,实现同。
redis 数据结构底层实现 - 普通set
无序不可重复的集合。value 为空的 hash/map。
redis 数据结构底层实现 - 整数set
要支持集合的交、并等操作。
实际就是按序保存了所有int。
包含encoding(指定元素类型),length(元素数量),int8_t contents[](数据)。contents的实际类型取决于encoding:encoding取值可为INTSET_ENC_INT16/32/64,contents的元素类型对应为int16_t, int32_t, int64_t。这样减少了内存浪费。
当 set 内的最大值较小时,使用小类型保存数据;当遇到新的较大值时,需要更改类型。
以int16_t扩容到int32_t为例(最大元素从65535(4?)变为):
首先对原contents大小加1,扩容一倍,然后从后往前,依次将原数据转为int32_t,放到正确位置上。
类型不会降级。
redis 数据结构底层实现 - list
双向链表。listNode通过void*保存值,所以可以保存不同类型。
因为链表节点内存不连续,且每个值都需要分配一个listNode结构,内存开销较大,所以当数据量较少时,会使用 ziplist。
由于 ziplist 效率不高,redis 3.2 改用了 quicklist,5.0 改用了 listpack (也不再使用双向链表)。
ziplist 压缩列表
链表与数组的结合:节点间内存是连续的,允许存储不同类型的数据,但不支持随机访问,只能从后往前遍历。
就是将数据放在连续的内存块上,用链表的方式连接。
ziplist 节省内存,且内存连续,但性能不高。只用于节点数量很少的情况。
ziplist 会用zltail记录尾部节点的位置,在遍历时从尾部向前遍历。
每个节点(entry)有三部分:prevlen(前一个节点的大小),encoding(数据的类型和大小),data(数据)。
与 SDS 类似,prevlen和encoding会根据数据的实际大小选择类型,尽可能少占用空间。
如长度小于255时prevlen用1B保存,否则用5B保存。
除了查找是O(n)的外,插入某个元素,或将某个元素替换为更大类型的值时,也需要O(n)时间,且可能导致n次的内存分配(由于prevlen变化导致连锁更新问题,见这里,但感觉没必要这种情况,因为数组本来就不好任意插入)。
quicklist
双向链表,但每个节点是一个压缩列表,以减少内存占用。
通过限定每个节点(压缩列表)能存储的元素数量,减少更新的开销。
listpack
好像与 ziplist 基本一致?只是改为从前往后遍历,所以只需保存当前节点的长度,避免了连锁更新问题。
redis 数据结构底层实现 - sorted set/zset
跳表。
将链表分为多层。最底层为原链表,每层的每个节点,有 p 的概率依旧出现在下一层。
插入、查询复杂度都为期望。
与平衡树相比,更易实现,但空间开销更大(事实上也是期望 O(n) 的)。
为什么使用跳表,见 算法 - 红黑树 与 跳表 的比较。
本质上就是因为简单、便于调试和扩展。
redis 数据结构底层实现 - 字符串
SDS(simple dynamic string) 是 redis 的默认字符串表示。
与C字符串区别:
- 保存了长度。
- 预分配空间:定义或扩充 SDS 时,会分配比所需空间更大的空间,减少内存分配次数。
- 惰性空间释放:字符串缩短的空间不释放,作为预分配的空间。
- 二进制安全:可存储二进制数据格式。
实现和 go 很像,有一个长度len和容量alloc,以及一个柔性数组char buf[]。
为了减少空间占用,redis 为不同长度的字符串定义了不同类型,分别使用不同类型的uint:对长度小于32的串,不存长度;否则,分别用uint8, uint16, uint32, uint64作为len和alloc的类型。
redis 的并发问题
TODO
redis 为单进程单线程模式,用队列将并发访问变为串行访问。redis 本身没有锁的概念。
redis 事务
事务中的所有命令都将会被串行化的顺序执行。在事务完成前,不会执行其它命令,以实现部分原子性。
事务可以当作一个批量执行脚本,但批量指令并非原子化的操作,中间某条指令的失败不会导致前面已做指令的回滚,也不会造成后续的指令不执行。
multi标记一个事务的开始,exec执行当前事务块的命令,discard取消事务。
watch key [key...]监视若干个key,如果事务执行之前,这些key被改动,则取消事务(需要在multi前进行;是一次性的)。unwatch取消所有watch的监视。
redis持久化的方式
为了高效率,redis 的数据都保存在内存中,需要其它方式持久化到磁盘上,才能重启后恢复数据。
有两种:AOF和RDB。具体见下。
两种方式的选择:
- 如果只用做缓存,或更改操作多、要求高性能、不在意短期数据丢失,用 RDB。
- 要求快速的数据恢复、方便的数据迁移,用 RDB。
- 对于一致性、可靠性要求高的数据,使用 AOF 或混用。可以只为某个或某些从服务器开启 AOF,master 不做持久化工作。
AOF 持久化 (append-only file)
对每条更新命令,以 append-only 的模式写入一个日志文件中。在 redis 重启时,可以通过重新执行 AOF 日志来恢复数据。
Redis 默认不使用 AOF。主要解决数据持久化的实时性问题。
通过rewriteaof和bgrewriteaof命令执行AOF 文件重写。会忽略过期的数据(也能部分达到删除过期数据的目的)。
redis 在执行完命令后才会记录日志,以保证不会在日志中记录语法错误的命令,且不会阻塞当前操作。
但是存在两个风险:执行完命令但未记录日志时,会导致数据丢失;不会阻塞当前操作,但可能阻塞后面的操作。
折中的方式是,选择 everysec 写回策略。
AOF 有三种日志写回策略(appendfsync):
- always:同步写回,命令执行完后,立刻将日志写到磁盘。可以保证数据基本不会丢失,但影响写日志的性能。
- everysec:命令执行完后,只将日志写到内存缓冲区,每隔一秒同步到磁盘(也可以通过子进程完成)。
- no:命令执行完后,只将日志写到内存缓冲区,由操作系统决定何时写回磁盘。性能高,但数据可能丢失。
优点:
- 比较可靠:设置 everysec 策略,即使宕机也只会丢失1s的数据。
- 生成的文件格式清晰,有可读性。
缺点:
- 性能较差:每次都创建日志,还要将日志写回到硬盘。
- 文件体积较大:需要记录每次操作的完整日志。
不过 AOF 有压缩机制,当 AOF 文件过大时,会执行 AOF 重写(可由子进程,后续的日志写到新的缓冲区)(如将对同一key的多个命令变为1条),并将新的日志写到新文件,删除旧文件。 - 恢复速度慢。
RDB 持久化
定期将内存数据以快照的形式保存到磁盘上:创建子进程,将当前数据保存为一个dump.rdb文件(Redis DataBase 文件)(并覆盖之前的)。重启时,可通过加载dump.rdb来恢复数据。
是 redis 默认的持久化方式。
可配置多种策略,如:save 900 1\n save 300 10\n save 60 10000。save t n表示如果t秒后至少有n个key发生变化,则dump到硬盘。
通过save和bgsave命令执行创建RDB文件。会忽略过期的数据(也能部分达到删除过期数据的目的)。
优点:
- 文件体积小:相同的数据量 RDB 数据比 AOF 小,因为 RDB 是紧凑型文件,只记录数据。
- 恢复快:直接恢复数据,不需要执行日志。
- 性能高:将内存保存为
rdb文件,不需要主进程进行操作,创建一个子进程即可。
缺点:
- 可靠性低:RDB 是全量的(涉及内存中的所有数据),一次快照代价较高,所以一般30分钟才进行一次快照,宕机时会损失很多数据。
- 性能消耗大:RDB 涉及的数据量大,快照时可能长期占用CPU和磁盘资源,导致短暂的停止服务(既然不影响内存,会吗?)。
RDB 是 fork 子进程后台进行的(bgsave),与父进程不共享数据,通过写时复制处理修改的数据,不会阻塞父进程。
如果是执行save命令,则由主进程执行。
全量同步与增量同步
全量同步:定期(可避开高峰期)或采用一个周期实现,将所有数据拷贝到数据仓库。
增量同步:每次只将新增和变化的数据同步到数据仓库。
比如采用对行为的操作实现对数据的同步,也就是AOF。
区别:
全量同步逻辑简单,但效率低(若改变的数据量很少)。
增量同步逻辑复杂,更消耗资源,但效率高。
两者类似 RDB 与 AOF(增量同步可通过日志实现)。
主从结构
多台服务器构成一个 redis 实例,以保证高可用性。主服务器处理写,会将数据同步给从服务器;其它从服务器都可以读。
当主服务器挂掉时,可以将从服务器切换为主,从而减少不可用时间。
切换一般为手动,使用哨兵模式可以自动。
其它服务器也可分担主服务器读的压力(如果不要求强一致性)。
主从结构有多种:一主一从,一主多从,树状结构(引入了中间层,减少主节点负担)。
主从复制/同步
新的master会和从服务器同步数据。同步使用psync命令。
有两种模式:完全重同步、部分重同步。当主从服务器差距过大,或从服务器没有数据时,使用完全重同步;如果只是暂时网络中断,采用部分重同步。
当主从服务器同步时,首先建立socket连接并进行身份认证。
然后从服务器发送psync,要求同步。如果从服务器有部分数据,则会附带服务器IDrunID与复制进度offset,主服务器据此确定同步方式。
后续主服务器会持续将写命令发给从服务器。
完全重同步:master生成RDB文件(子进程后台进行),发送给slave加载恢复。对于生成文件后的写命令,用缓存记录,在slave加载完后发送。
部分重同步:如果服务器IDrunID与主服务器一致,则说明同步过一部分,根据双方offset同步缺失的部分。
不过主服务器的buffer也是有限的,offset会在上限后绕回,然后覆盖之前的记录。应该再记录个绕回次数能判断,但只能进行完全重同步。
主从数据不一致
写只在主节点完成,读可以去从节点(但 redis 效率高,读写都在主节点,从节点只用于备份和恢复也没事)。
要想提高写效率,还是要做负载均衡、将请求分给不同的 redis 集群。
redis 不能保证各节点间的强一致性(最终一致性也做不到),主从库间的复制是异步的。
在主库收到新的写命令后,会发送给从库。但主库并不会等到从库实际执行完命令后,再把结果返回给客户端,而是主库自己在本地执行完命令后,就向客户端返回结果。如果从库还没有执行完主库同步过来的命令,主从库间的数据就会不一致;如果此时主库挂掉,就会有数据丢失(想要一致,需要客户端在 redis 挂掉后发补偿信息,可以用 mq)。
从库会滞后执行同步命令主要有两个原因:主从库间的网络有传输延迟;即使从库及时收到了主库的命令,也可能会因为正在处理其它复杂度高的命令(如集合操作)而阻塞。
应对的方法也有两个:尽量保证主从库间的网络连接状况良好;开发一个外部程序来监控主从库间的复制进度,如果某个从库的进度差大于预设的阈值,可以让客户端不再和这个从库连接进行数据读取,减少读到不一致数据的情况。
哨兵模式
自动的主从切换(故障恢复)。
一般的主从切换,是当主服务器宕机后,手动把一台从服务器切换为主服务器。这需要人工干预,费时费力,还会造成一段时间内服务不可用。
哨兵是一个独立的进程(特殊的 redis 服务器)。哨兵通过定期发送命令,接收主、从和哨兵服务器响应,以监控各服务器状态。当哨兵监测到master宕机,会自动将某个slave切换成master,然后通过发布订阅模式通知其它的从服务器,修改自己的配置,让它们能切换到新的master。
哨兵服务器相当于注册中心,每个客户端先从哨兵服务器获取master地址,然后链接到master。如果新master产生,哨兵通知客户端,客户端重新链接。
概括说就是:哨兵监控主服务器状态,如果主服务器挂了选举,然后通知从服务器,自己作为配置中心,提供当前主服务器的信息。
一个哨兵进程进行监控也可能会出问题,可以使用多个哨兵进行监控,且各个哨兵之间也会进行监控,这样就形成了多哨兵模式。
故障切换(failover):
如果主服务器宕机,哨兵1先检测到这个结果,系统并不会马上进行failover过程:仅仅是哨兵1主观的认为主服务器不可用(比如它们间的网络延迟),这个现象称为主观下线。
当后面的哨兵也检测到主服务器不可用,并且数量达到一定值时,那么哨兵之间就会进行一次投票,决定主服务器是否真的宕机,然后才进行failover(故障切换/转移)操作。这个过程称为客观下线。
哨兵会选举哨兵领导者,负责故障切换过程:
选择一个从节点让它成为新master(slaveof no one,有一定规则);通知其它节点新master的产生。
哨兵间会选择一个哨兵来完成故障转移。选举规则与raft类似:一个哨兵主观认为下线后,请求投票;一个哨兵如果没投过票,则投给收到的第一个请求;当一个哨兵获得超过半数的票后,成为哨兵领导者,负责故障恢复。
从服务器需要和新的主服务器进行主从复制。原来的主服务器重连后,会变成从服务器。
可以发现,当主服务器挂掉后,只能保证可用性,但可能会丢失数据:如果有自己执行完,但没有给从服务器发送完的命令(比如命令多但延迟高,或是新的主服务器在进行大量复制),这些数据就会丢失。这与raft的强一致性是不同的。
只能尽可能减少数据丢失,比如主从服务器数据相差过大时,禁止主服务器接收写请求。
手动故障切换:https://www.jianshu.com/p/5fd2b6de6bfe
分片集群
主从结构和哨兵模式保证了一个 redis 集群内的可靠性和并发读能力。
但没有解决:1. 数据量过大时的存储问题(一个节点的内存有限;数据过大时每次 RDB 代价很高);2. 写请求只能由 master 处理,不能并发。
类似负载均衡,可以将数据分散到多个哨兵集群中。这样系统会包含多个 master,master 之间会定期检查对方的状态。
master 之间还会互相告诉,自己负责的槽有哪些。所以无论请求发给哪个 master,会被重定向到拥有该数据的指定集群。
客户端也可以缓存定向信息(哪个 key 在哪个集群中)。
当节点变动时,某个槽的数据可能会发生迁移。如果该槽没有迁移完成,则对该槽数据的请求会返回ASK,包含请求数据所在的地址(由于该槽的数据可能包含在不同节点,所以ASK不会让客户端更新缓存);如果该槽迁移完成,返回MOVED,告知该槽所属的新的集群,并更新客户端的缓存。
数据分配使用的是一致性哈希。每个键值对会根据它的 key,计算一个哈希值,然后模决定它所在的槽。每个 master 会处理一段区间的槽中的所有键值对。
哈希算法为 CRC16。
为什么槽的数量是 ,不是更大?
因为 master 之间在发送心跳时,会同时发送属于自己的槽集合,来实现请求重定向。
槽集合是以位图的形式发送的,所以每个心跳都要附带一个位,也就是大小的位图。如果槽数量是或更大,心跳时发送位图的消耗会大4倍或更多(而且心跳是很频繁的)。
所以槽数越多,心跳消息越大,占用的带宽越大(也很难取得更好的效果)。
此外,位图中连续的0是可以压缩来减少代价的。但槽数越多,位图中1的个数越多,越难压缩。
所以槽数应尽量小。考虑到集群的个数一般不会超过 1000 个,所以取 16384 个是足够的。为什么槽的数量是 ,不是更小?
可能是因为槽过少时,会很难均匀的分配节点,因为槽的位置是离散的。
比如 6 个槽、4 个节点,节点在环上的位置不可能分布均匀;槽与节点的比例越小,节点就越难分布均匀。直接根据 key 的哈希值分散可能不太好,因为有时候想让很多特定数据都在同一个集群上。
为此,可以在 key 中添加{xxx},redis 会用大括号内的值计算哈希值,而不是 key。
protected-mode
限定哨兵实例能否被其他服务器访问。为 yes 时,哨兵实例只能在部署的服务器本地进行访问;为 no 时,其他服务器也可以访问这个哨兵实例。
如果 protected-mode 被设置为 yes,而其余哨兵实例部署在其它服务器,那么这些哨兵实例间就无法通信。当主库故障时,哨兵无法判断主库下线,也无法进行主从切换,最终导致 Redis 服务不可用。
cluster-node-timeout
设置 redis 集群实例响应心跳消息的超时时间。
集群的每个实例需定期回复心跳,如果某个实例超过该时间未回复,则认为该实例异常。当半数实例异常时,则 redis 集群异常。
如果为每个实例配置一主一从模式(如果主实例发生故障,从实例切换为主,该实例依然正常),且从实例切换为主实例的时间较长(网络延迟,切换操作等)并超出了 timeout,则集群会认为该实例异常,但它其实是正常的。
如果有半数实例在进行主从切换,会导致集群认为半数实例异常,导致集群不可用。
所以 cluster-node-timeout 可以调大些(如 10 到 20 秒)。
redis 删除策略
使用 redis 时,不会读取到过期数据,因为 redis 使用 惰性删除、定期删除 两种策略来删除过期数据。
被动删除:当一个数据过期时,不会被立刻删除,而是在之后的第一次访问时被检查,再删除。
这会减少CPU的占用,但大量的过期数据可能会占用过多内存。
主动删除:Redis 每隔一段时间(默认 100ms,即 serverCron()),在 expire 的数据中随机检查20个 key 是否过期,然后删除过期的。如果里面过期的 key 超过 25%,则重复该过程。
可以释放一部分内存。
https://redis.io/commands/expire/
主动删除将随机采样的 key 中过期 key 的分布当作所有数据的分布,使得所有数据中过期 key 的数量尽量在 25% 以下。
读取过期数据
但即使使用数据前数据会检查,在集群中还是可能访问过期数据:
设置过期时间的命令有4个,分为两类(每类的前者单位为s,后者为ms):
expire/pexpire key time:设置命令执行后,数据能存活的时间。
expireat/pexpireat key timestamp:设置数据过期的具体时间点。
(如果前两个命令的时间为非正数、后两个命令的时间戳是过去的,则不设置过期,直接删除该数据,减少内存占用)
(本质都是用 pexpireat 实现的,所以如果设置10s后,将电脑时间改为20s后,key 会立刻过期)
当主库收到expire命令后,会直接执行,并发给从库。如果通信延迟较大,或主从库为全量同步,从库执行该命令的时间会更晚,通过当前时间+expire计算出的过期时间会晚于主库,导致主库上过期的数据在从库没有过期。
所以应使用expireat, pexpireat来设置具体时间点,避免读到过期数据。
注意主从节点上的时钟要保持一致,可以让主从节点和相同的 NTP 服务器(时间服务器)进行时钟同步。
默认设置的 key 就是永不过期的。
通过persist key移除一个 key 的过期时间,使它永不过期。
通过ttl/pttl key检查一个 key 还有多久过期(单位为s/ms)。不会过期时,返回 -1;key 不存在返回 -2。
redis 的大 key 问题
大 key 实际指它的 value 太大,一般为:string 大于5MB;集合/容器的元素个数超过一万或两万个(不固定,只是看的这里)。
会导致的问题:
- 影响响应速度:因为 redis 单线程执行,如果大 key 的处理太耗时,会延缓后续操作,长时间不响应客户端,就好像 redis 挂掉了。其它正在使用 redis 的服务也会感到响应变慢。
- 数据分布不均:分片集群下,会出现数据倾斜的情况。因为即使 key 分布均匀,部分有大 key 的 Redis 节点压力也会很大,导致整个集群的性能也达到瓶颈。
真正的“大 key”问题:
redis 中的 key 可以最大到512MB,但是设置很大的 key 会影响 redis 的性能,因为在哈希冲突时需要对 key 进行比较;还会占用更多内存。
但是 key 也没必要太小,否则含义会不直观。
删除大 key:
回收大量内存需要时间,如果由主进程执行,可能导致请求超时。
一般是分批删除,或流量少时删除,或异步删除(由子进程处理,redis 4.0支持)。
分批删除:
对于大的映射,使用hscan每次获取少量数据删除,用hdel每次删除一个数据。
对于大的集合,使用sscan或srandmember每次获取少量数据删除,用srem每次删除一个数据。
对于大的有序集合,使用zremrangebyrank每次删除少量数据。
对于大的 list,使用ltrim每次删除少量数据,或直接pop。
避免大 key:
将大 key 拆分成多个键值对,访问时分批获取,删除时异步分批删除。
对大的 value 进行压缩。
查找大 key:
方法1 通过redis-cli --bigkeys查找大key(redis-cli -h 127.0.0.1 -p6379 -a "password" --bigkeys)。
缺点:
- 扫描全表,可能执行很久阻塞节点,所以最好在从节点执行,或流量小时执行。参数
-i控制扫描间隔,避免影响性能。 - 只能返回每种类型中最大的那个 bigkey,无法得到最大的若干个。
- 更适合 string,不太适合集合类型:只能统计集合元素的个数,而不是实际占用的内存量。
方法2 scan。也是全表扫描。--bigkeys就是用的scan?
方法3 用第三方工具扫描 rdb 文件。
redis 的热点 key 怎么处理
热点 key 问题:短时间内有大量请求去访问特定的 key,导致流量过于集中,可能使集群性能下降,甚至使某台服务器不可用;如果热点 key 过多超出缓存,或热点 key 过期,或被其它业务驱逐出缓存,会导致缓存击穿。
原因:可能是因为业务问题,也可能是数据分片做得不好,数据分布不均匀。
发现热点 key:
方法1:凭借业务经验,预估哪些是热点 key。
方法2:在客户端进行统计。但要修改客户端。
方法3:在代理(proxy)层统计。代理层处于客户端和服务器之间。但有的没有代理层。
方法4:利用 redis 自带命令,但可能影响性能:monitor监视命令,或redis-cli -hotkeys发现热点。
处理热点 key 方法:
方法1:创建一个本地缓存(二级缓存),对热点 key 先检查缓存,没有再请求 redis 和数据库。
方法2:发现热点 key 时,将其备份或分摊到多个服务器,分担请求。比如可以在热点 key 后随机后缀。
方法3:请求合并,每隔一定时间(如100ms)统一处理一次请求,相同 key 的请求可很快返回。
如何保证redis中的数据都是热点数据
缓存雪崩
当大量缓存在同一时间过期,或 redis 节点宕机时,如果此时有大量请求,就无法在 redis 中处理,会直接访问数据库,导致数据库短时间内压力过大。
因为原因有两种,所以解决方式也有两类:
- 为了避免大量缓存在同一时间过期,可以:
- 均匀设置过期时间,至少不要太接近,比如给过期时间加一个随机值。
- 对同一个键值对,设置两个 key,一个设置过期时间,用来更新数据;一个设置不会过期,用来快速响应。
当第一个 key 过期时,可以直接返回第二个 key 的数据,将更新键值对的请求异步处理(不需要立刻处理)。 - 不设置过期时间,不再主动更新缓存。缓存的更新由后台线程定期执行。但这无法根据不同数据的需求决定更新时间。
- 减少 redis 宕机造成的影响:
- 加节点,构建哨兵集群。
- 可以在故障时,直接返回错误,不再访问数据库。或者限流,只允许一部分请求访问数据库,其它的拒绝服务。或者只允许执行压力较小的请求,比如只允许读,但不允许写。
缓存击穿
业务中会存在某些热点数据。如果某个热点数据过期了,且此时有大量请求访问该数据,就无法在 redis 中处理,会大量请求数据库。
缓存击穿是雪崩的一个子集,解决方法类似:
- 均匀设置过期时间;不设置过期时间。
- 加锁,保证同一时刻 同一个数据,只允许一个请求去数据库中查询、更新缓存。如果结果不存在,在缓存中设置一个空值。
击穿强调热点数据,所以会大量访问少量数据,加锁会更值得。
缓存穿透
如果有大量请求,同时访问既不在缓存、也不在数据库中的数据,会导致 redis 总是不可用、每个请求都会访问数据库。
这个问题通常不会出现,一般是因为:误删除了某些数据,或有恶意攻击。
解决方法:
- 限制非法请求,尽早过滤掉不合法的请求,提前返回错误。
- 对大量查询的某个数据,在缓存中设一个空值或默认值。
- 使用布隆过滤器快速判断某个数据是否存在,减少对数据库的访问。
缓存穿透中涉及大量不同数据,加锁的意义可能不大。
如果已经发生了缓存雪崩等,导致节点宕机,怎么快速恢复
节点重新启动后,首先要限制请求数量,以便更快恢复、不会再挂掉。
可以在故障时,直接返回错误,不再访问数据库。或者限流,只允许一部分请求访问数据库,其它的拒绝服务。或者只允许执行压力较小的请求,比如只允许读,但不允许写。
见 分布式 - 如何实现限流。
二级缓存
redis 缓存与服务端不一定在同一个节点上,所以如果服务器本地有缓存,会比去 redis 读更快。
所以服务器可以用本地内存实现一个 redis 的缓存,提高响应效率。同步机制和 MySQL 与 redis 类似。
内存满了怎么办 / redis 内存淘汰策略
对于使用者来说,应做好对剩余容量的监控,及时处理或扩容。
redis 的最大内存由maxmemory配置决定。
当可用内存不足时,redis 会删除某些键值,规则由maxmemory-policy决定(默认为noeviction)。
redis提供6(8)种数据淘汰策略:
- no-eviction:默认,不删除数据,只返回错误。
- voltile-lru:使用LRU淘汰某些数据(只针对设置了过期时间的数据)。
- allkeys-lru:使用LRU淘汰某些数据。
- volatile-random:随机删除数据(只针对设置了过期时间的数据)。
- allkeys-random:随机删除数据。
- volatile-ttl:删除过期时间最近的数据(只针对设置了过期时间的数据)。
- volatile-lfu:使用LFU淘汰某些数据(只针对设置了过期时间的数据)。
在 redis 4.0 中添加。LFU 记录了频率,比 LRU 更能反映一个数据的热度。 - allkeys-lfu:使用LFU淘汰某些数据。
在 redis 4.0 中添加。
对于volatile-xx,如果没有可删除数据,则不删除,返回错误。
redis 中的 LRU
LRU 实际是近似 LRU:redis 不会准确找出最久未使用的键,而是随机抽取5个键,删除这5个键中最久未使用的键(默认为5,通过maxmeory-samples设置;越大效果越好,但更消耗性能)。
redis 会为每个键值对增加一个属性,表示最后一次被访问的时间,占用3B。
redis 3.0 对近似 LRU 做了优化:redis 会维护一个大小为16 的候选池。
当候选池为空时,随机采样的数据会全部放入,否则只有访问时间小于池内最早访问时间的数据才会被放入。如果在池满时放入元素,则淘汰访问时间最大的数据。
当淘汰数据时,直接淘汰池中访问时间最早的数据。
这相当于将原样本(5个数据)扩大到了很多样本。
redis 与 mysql 共同使用
一般请求都由 redis 处理,如果 redis 集群都挂了,可以让 mysql 处理一部分请求,但 mysql 也处理不了多少,大部分都是直接服务不可用。
redis 的事件处理机制
事件主要分为两种,处理文件事件(命令请求和应答等等)和时间事件(RDB定时持久化、清理过期的Key等的)。
对于时间事件,主进程可以 fork 一个子进程玩出。
在新的版本中,有些操作可通过多线程进行。但核心的处理请求与相应还是单线程。
redis 使用单线程还是多线程
工作线程总是 1 个。
redis 6.0 后,增加了多线程模型,但多线程是用来处理网络 IO 的(读写 socket、解析请求),不是用来处理操作,所有的操作还是由单线程完成的。所以是线程安全的。
这个多线程模型可以充分利用网卡和CPU等硬件,提高网络吞吐量(网卡收发速度也很快,但收到后/发送前需要对数据处理或解析)。
在 6.0 之前,redis 也会使用多线程处理某些耗时的异步事件,如大键值对的删除。
这些操作的耗时确实比较多,而且通过比较简单的机制就可以安全的用多线程处理。
为什么之前不使用多线程?
- (因为 redis 指令的操作一般比较简单,涉及的计算少,CPU 每秒能执行的操作比网络读取的都多很多)redis 的主要瓶颈在于网络或内存,而不是 CPU,所以即使用多线程处理指令,也很难有太大提升。反而会引入加锁、调度的开销和问题(如死锁)。
(redis 可以看做是 IO 密集型程序,主线程需要经常等待 IO,就可以多线程处理其它不冲突的事情,提高 CPU 利用率) - 单线程的实现、调试、维护和扩展都容易很多。
- 很多设计都是基于单线程的,如果要改多线程会很麻烦。
后来加入的多线程,是为了提高网络 IO 的效率,而不是提高指令执行速度,不是在执行指令时使用多线程(瓶颈不在这里)。
如果有更高的效率需求,可以使用多个 redis 实例,而不是在一个 redis 中进行大量多线程操作。
redis 的多线程模型
4.0 新增的后台线程,会执行 unlink key / flushdb async / flushall async 等命令,不会阻塞主线程。
可异步执行的后台任务有三类,由三个后台线程处理、三个任务队列保存:
- BIO_CLOSE_FILE,关闭文件 任务队列:当队列有任务后,后台线程调用 close(fd),将文件关闭。
- BIO_AOF_FSYNC,AOF刷盘 任务队列:当 AOF 配置为 everysec 后,主线程会把写日志操作封装成一个任务,放到队列中。当发现队列有任务后,后台线程调用 fsyn(fd),将AOF文件写到磁盘。
- BIO_LAZY_FREE,lazy free 任务队列:当队列有任务后,后台线程会 释放对象、删除数据库所有对象、释放跳表对象等。
另一部分处理网络 IO:
- 主线程在等待队列中轮询,将里面的 socket 分配给 IO 线程组。
- 线程组中的线程与一个 socket 绑定后,读取并解析,再有主线程执行命令。
- 主线程执行完后,将数据写到缓存,IO 线程将其写到 socket,解除绑定。
redis 的页面交换
当内存不足以容纳所有数据时,类似 OS,redis 会将部分数据交换到磁盘上,但不同点是:
- redis 的交换机制是自己实现的,不是用 OS 提供的。
OS 是以内存页为单位,对 redis 来说很大。 - redis 会将放入磁盘的数据进行压缩,大大减少硬盘 IO。
- 可以将冷数据放到磁盘,热数据留在内存。
- OS 的内存交换会阻塞当前线程,但 redis 的交换可以由其它线程完成,不影响主线程。
redis 的数据库
Redis支持多个数据库,并且每个数据库的数据是隔离的、不能共享,且基于单机才有数据库,如果是集群就没有数据库的概念。
可以理解为 每个数据库就是一个独立的字典。
每个数据库用从 0 开始的递增数字命名。Redis 默认有16个数据库,可通过配置databases来修改,无上限。
与 Redis 建立连接后会默认选择0号数据库,可通过select n切换。
这些以数字命名的数据库与真正的数据库有所不同:
1. Redis 不能自定义数据库的名字,每个数据库都以编号命名,开发者必须自己记录哪些数据库存储了哪些数据。
2. Redis 不能为每个数据库设置不同的密码,所以一个客户端要么可以访问全部数据库,要么一个数据库都不能访问。
3. 多个数据库之间并不是完全隔离的,比如FLUSHALL命令可以清空一个 Redis 实例中所有数据库的数据。
综上,redis 的数据库更像是一种命名空间,不适宜存储不同应用程序的数据。
比如可以用0号数据库存储某个应用生产环境中的数据,使用1号数据库存储该应用测试环境的数据;但不适宜使用0号数据库存储应用 A 的数据,使用1号数据库存储应用 B 的数据。
不同的应用应该使用不同的 Redis 实例来存储数据。由于 Redis 非常轻量级,一个空 Redis 实例占用的内存很小(1M左右),所以不用担心多个 Redis 实例会额外占用很多内存。
redis 与 memcached
- memcached 的 value 只能是 String,Redis 的 value 支持多类型。
- memCached 不支持数据持久化。
- memcached 是多线程,有锁;更慢。
- memcached 使用多线程的非阻塞 IO 模型,redis 为单线程的多路 IO 复用模型。
redis 多路复用
epoll,见 OS - 多路复用。
redis 应用场景
- 很常用且不会很大的数据,如:排行榜,热点新闻。
- 很常用但没那么重要的数据缓存,定期同步到数据库。比如热门文章的阅读量,视频点击量。
- 记录 IP 地址、登录信息和访问次数,实现限流。
- 热点或做活动的一些商品列表。
- 计数器。更新方式:
incr key(加1,没有则新建并初始化为0),incrby key value(加 value,没有新建)。 - 实现分布式锁。见 分布式 - 分布式锁。
redis 怎么实现排行榜
用 zset。
如果数据量多,可以定期更新;可以将用户分区,最后合并。
zset 一般存 id,如果经常访问 id 外的信息,也可以缓存下来。比如定期更新排名时,将信息写到 list。
在 score 相同时,会按字典序排序。如果想指定多关键字,只能修改 score 值。
比如按(得分,达成时间)排序,可以将 score 写成得分.完成时间。如果完成时间早的在前,可以定义一个最大值(如9999年12月31日23时59分59秒),写成得分.(MAX-完成时间)。
但是,double 有精度限制,且时间戳的位数很多,可能会有精度问题。
可以减少 MAX 的值,比如日榜就将 MAX 设为明天的时间;可以减少时间精度,以分钟为单位。
也可写成整数,更清楚,如得分*MAX + (MAX-完成时间)。double 整数的上限为,最大得分和最大时间要受此限制。
对于周榜或合并榜单,zunionstore可以合并若干个 zset 并设置权重,也可以自己写。
如果读过多,可设置一写多读,允许一点不一致性;可设置入榜门槛,未入榜的个人排名大概估计或不返回。
redis 怎么实现消息队列
TODO
https://www.zhihu.com/question/20795043
https://blog.csdn.net/weixin_45690465/article/details/124566098
https://zhuanlan.zhihu.com/p/344269737
redis 和 mysql 如何保证数据一致 / 缓存与数据库的一致性
redis 用来提高读性能和写的响应速度。
读取数据时,先检查 redis,如果有就返回,否则在 mysql 中查找,然后将值写回 redis。写需要在 redis 和 mysql 中都写入。
但很难做到数据完全一致,只能尽量实现顺序一致性。
首先,更新一个数据时,要在 redis 和 mysql 中都进行更新。
通常使用的方式是,只更新 mysql,然后在 redis 中删除该数据(如果读的时候发现 redis 中没有数据,会去 mysql 中读最新的)。其它方式更容易导致数据不一致。
假设先写数据库,然后更新缓存:
线程 A 修改 x=1,然后线程 B 修改 x=2,有 4 步:首先 A 写 mysql x=1,然后 B 写 mysql x=2,再写 redis x=2,结束,然后 A 去写 redis x=1,就会导致数据不满足顺序一致性(如果只是不一样也还好)。如果 A,B 都只是在 redis 中删除 x,就没问题了,就是要多读一次。
如果是先写缓存,再更新数据库,也会有问题(B 的请求晚,但数据库的最新数据是 A 的)。
所以一般是删缓存而非写缓存。有几种方式 :
假设先删除缓存,再修改数据库。会导致数据不一致。
例:设 x=1,线程 A 想修改 x=2,先删除缓存中的 x;然后线程 B 查询 x,发现缓存没有,就去 mysql 查 x=1 然后写回 redis x=1;然后 A 写 mysql x=2。
出现不一致的条件是:如果一个线程删除了缓存,但还没改完数据库,另一个线程来查询,就会发生该问题。
这是很可能发生的,因为数据库的修改可能比较复杂,耗时很多,如果期间出现查询都会产生该问题。假设先修改数据库,再删除缓存。也会导致数据不一致。
例:设 x=1,线程 A 想查询 x,如果缓存没有,就去 mysql 查到 x=1;线程 B 想修改 x=2,先写 mysql x=2,然后删除缓存中的 x;然后 A 写 redis x=1。
出现不一致的条件是:如果一个线程查询 x,发现缓存中没有,然后去 mysql 中查到,但还没写回缓存,此时另一个线程修改 x 并完成了删除缓存,就会发生该问题。
这种情况很难发生,因为写回 redis 是非常快的,在 mysql 中修改 x 则相对很慢;而且要满足 x 不在缓存中。所以这是最常用的方案。
先删除缓存,再修改数据库,再删除缓存。意义不大,还是会有2的问题,会导致数据不一致。
所以修改一般是先写数据库,再删除缓存。
为了减少不一致的可能,可以要求 写数据库后 等待一定时间 (如0.5s) 再删除缓存(这个时间只要能大于写 redis 的时间就可,不需要特别大),或者放入消息队列之后异步删除缓存。如果删除失败要定时重试(删除是幂等的,随便重试)。
如果删除缓存要等待,那这段时间内其它服务是读不到最新的数据库数据的。如果更关注实时性,可以删两次:一次写完就删,一次定时删。(延迟双删就是这样,但是删除是在数据库更新前进行,感觉没有意义)
还有一种方式:直接写 mysql。redis 监听 mysql 的 binlog,将里面的更新放到消息队列异步处理。
也比较常用,但显然也只能顺序一致。
实际情况下,应该根据需求选择方案:
- 先写数据库,再删缓存,会导致多一次数据库访问。如果类似的请求特别多、并发量比较大,缓存不命中(访问数据库)带来的影响就特别大,就不适合删缓存。
- 如果更新的信息不常被使用,没必要经常留在缓存(比如某些不经常改的个人信息),直接删缓存还可以节省内存空间。
- 如果数据一致性要求很低,就算 redis 宕机、读到旧数据,影响也不大(比如发表评论、修改用户信息等大部分普通服务),可以先更新 redis,然后异步写数据库。此外这种服务非常多,延迟会影响用户的体验。
- 如果对一致性要求高、完全避免脏数据,要不直接用数据库,要不加分布式锁,先锁住 redis 中的这个 key,然后修改数据库,但效率肯定不高。
- 如果删除或更新缓存可能失败,要考虑如何补救、影响大不大。
如果数据库更新了,但 redis 故障了没有更新,怎么恢复
利用数据库的 bin log,把故障期间涉及的 key 存下来(可用队列),然后定期、不断尝试删除这些 key,直到操作成功(删除是幂等的,随便重试)。
如果长时间或很多次的尝试都无法成功,那就是 redis 节点直接不可用了。
redis 源码
异步、定期处理的事件由src/server.c中的serverCron()处理。
serverCron()每秒执行server.hz次,执行异步事件,如:删除部分过期 key;哈希表的扩缩容;触发 RDB(BGSAVE) 或 AOF 重写。
如果不想事件随serverCron()被一秒执行多次,可用run_with_period(milliseconds) { .... }表示。
rehash
rehash 触发条件
由函数databasesCron()检查和扩容。该函数还处理部分过期 key 的删除(随机采样)。
。(好像同时计算了ht[0]和ht[1])
当负载因子到达10%,且没有活跃子进程时,触发扩容。
rehash 过程
有两个哈希表,ht[0]存放数据,ht[1]用于扩容。
首先给ht[1]分配空间,然后逐步将原哈希表ht[0]迁移到ht[1](增量扩容):
- active rehashing
server.c中的serverCron()周期性被调用,执行各类需要异步处理的事。
每次调用serverCron()时,进行一次incrementallyRehash(),花费约 1ms 执行一部分迁移(迁移100个桶或遍历了1000个空桶后结束) - lazy rehashing
哈希表执行基本的增删改查(dictAddRaw、dictGenericDelete、dictFind、dictGetRandomKey、dictGetSomeKeys)时,调用_dictRehashStep()进行少量扩容(迁移1个桶或遍历了10个空桶后结束)。
迁移完成后,释放ht[0],将ht[1]赋给ht[0]。
rehash 可以扩容也可缩容。
注意,当进行数据库备份到硬盘时,不会进行rehash。因为持久化会使用子进程实现,通过写时复制与父进程共享数据,但几乎没有开销(只要父进程不在此期间做大量更改)。
但rehash会修改数据,导致os为子进程拷贝新的内存页。
直接通过hasActiveChildProcess()判断。
