@rg070836rg
2017-10-31T12:12:03.000000Z
字数 17022
阅读 2998
cuda实验报告
GPU并行计算课程实验与报告
陈实 SA17011008 计算机学院 2017年10月31日
一、实验环境描述
首先请参见实验环境的安装:
ubuntu实验环境的安装
二、ubuntu_samples测试
本课程的实验,将会以两个平台进行,分别是ubuntu下以及windows下,ubuntu是来自于学校的服务器,windows是自己的笔记本,记录遇到的问题,供大家分享。
2.1 deviceQuery
接下来,尝试几个例子:
首先cd到样例目录
ubuntu@ubuntu:~/NVIDIA_CUDA-8.0_Samples/1_Utilities/deviceQuery$
我们通过make编译文件,再执行./deviceQuery ,即可看到服务器GPU相关信息:
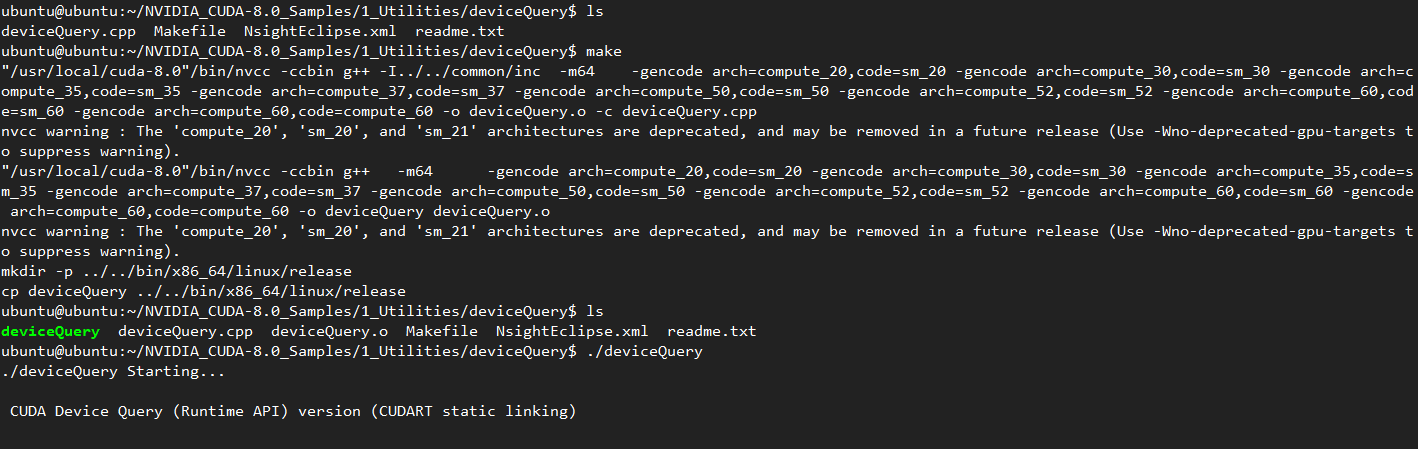
我们把结果剪贴下来:
Detected 4 CUDA Capable device(s)Device 0: "Tesla K80"CUDA Driver Version / Runtime Version 8.0 / 8.0CUDA Capability Major/Minor version number: 3.7Total amount of global memory: 11440 MBytes (11995578368 bytes)(13) Multiprocessors, (192) CUDA Cores/MP: 2496 CUDA CoresGPU Max Clock rate: 824 MHz (0.82 GHz)Memory Clock rate: 2505 MhzMemory Bus Width: 384-bitL2 Cache Size: 1572864 bytesMaximum Texture Dimension Size (x,y,z) 1D=(65536), 2D=(65536, 65536), 3D=(4096, 4096, 4096)Maximum Layered 1D Texture Size, (num) layers 1D=(16384), 2048 layersMaximum Layered 2D Texture Size, (num) layers 2D=(16384, 16384), 2048 layersTotal amount of constant memory: 65536 bytesTotal amount of shared memory per block: 49152 bytesTotal number of registers available per block: 65536Warp size: 32Maximum number of threads per multiprocessor: 2048Maximum number of threads per block: 1024Max dimension size of a thread block (x,y,z): (1024, 1024, 64)Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)Maximum memory pitch: 2147483647 bytesTexture alignment: 512 bytesConcurrent copy and kernel execution: Yes with 2 copy engine(s)Run time limit on kernels: NoIntegrated GPU sharing Host Memory: NoSupport host page-locked memory mapping: YesAlignment requirement for Surfaces: YesDevice has ECC support: EnabledDevice supports Unified Addressing (UVA): YesDevice PCI Domain ID / Bus ID / location ID: 0 / 5 / 0Compute Mode:< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >Device 1: "Tesla K80"CUDA Driver Version / Runtime Version 8.0 / 8.0CUDA Capability Major/Minor version number: 3.7Total amount of global memory: 11440 MBytes (11995578368 bytes)(13) Multiprocessors, (192) CUDA Cores/MP: 2496 CUDA CoresGPU Max Clock rate: 824 MHz (0.82 GHz)Memory Clock rate: 2505 MhzMemory Bus Width: 384-bitL2 Cache Size: 1572864 bytesMaximum Texture Dimension Size (x,y,z) 1D=(65536), 2D=(65536, 65536), 3D=(4096, 4096, 4096)Maximum Layered 1D Texture Size, (num) layers 1D=(16384), 2048 layersMaximum Layered 2D Texture Size, (num) layers 2D=(16384, 16384), 2048 layersTotal amount of constant memory: 65536 bytesTotal amount of shared memory per block: 49152 bytesTotal number of registers available per block: 65536Warp size: 32Maximum number of threads per multiprocessor: 2048Maximum number of threads per block: 1024Max dimension size of a thread block (x,y,z): (1024, 1024, 64)Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)Maximum memory pitch: 2147483647 bytesTexture alignment: 512 bytesConcurrent copy and kernel execution: Yes with 2 copy engine(s)Run time limit on kernels: NoIntegrated GPU sharing Host Memory: NoSupport host page-locked memory mapping: YesAlignment requirement for Surfaces: YesDevice has ECC support: EnabledDevice supports Unified Addressing (UVA): YesDevice PCI Domain ID / Bus ID / location ID: 0 / 6 / 0Compute Mode:< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >Device 2: "Tesla K80"CUDA Driver Version / Runtime Version 8.0 / 8.0CUDA Capability Major/Minor version number: 3.7Total amount of global memory: 11440 MBytes (11995578368 bytes)(13) Multiprocessors, (192) CUDA Cores/MP: 2496 CUDA CoresGPU Max Clock rate: 824 MHz (0.82 GHz)Memory Clock rate: 2505 MhzMemory Bus Width: 384-bitL2 Cache Size: 1572864 bytesMaximum Texture Dimension Size (x,y,z) 1D=(65536), 2D=(65536, 65536), 3D=(4096, 4096, 4096)Maximum Layered 1D Texture Size, (num) layers 1D=(16384), 2048 layersMaximum Layered 2D Texture Size, (num) layers 2D=(16384, 16384), 2048 layersTotal amount of constant memory: 65536 bytesTotal amount of shared memory per block: 49152 bytesTotal number of registers available per block: 65536Warp size: 32Maximum number of threads per multiprocessor: 2048Maximum number of threads per block: 1024Max dimension size of a thread block (x,y,z): (1024, 1024, 64)Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)Maximum memory pitch: 2147483647 bytesTexture alignment: 512 bytesConcurrent copy and kernel execution: Yes with 2 copy engine(s)Run time limit on kernels: NoIntegrated GPU sharing Host Memory: NoSupport host page-locked memory mapping: YesAlignment requirement for Surfaces: YesDevice has ECC support: EnabledDevice supports Unified Addressing (UVA): YesDevice PCI Domain ID / Bus ID / location ID: 0 / 133 / 0Compute Mode:< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >Device 3: "Tesla K80"CUDA Driver Version / Runtime Version 8.0 / 8.0CUDA Capability Major/Minor version number: 3.7Total amount of global memory: 11440 MBytes (11995578368 bytes)(13) Multiprocessors, (192) CUDA Cores/MP: 2496 CUDA CoresGPU Max Clock rate: 824 MHz (0.82 GHz)Memory Clock rate: 2505 MhzMemory Bus Width: 384-bitL2 Cache Size: 1572864 bytesMaximum Texture Dimension Size (x,y,z) 1D=(65536), 2D=(65536, 65536), 3D=(4096, 4096, 4096)Maximum Layered 1D Texture Size, (num) layers 1D=(16384), 2048 layersMaximum Layered 2D Texture Size, (num) layers 2D=(16384, 16384), 2048 layersTotal amount of constant memory: 65536 bytesTotal amount of shared memory per block: 49152 bytesTotal number of registers available per block: 65536Warp size: 32Maximum number of threads per multiprocessor: 2048Maximum number of threads per block: 1024Max dimension size of a thread block (x,y,z): (1024, 1024, 64)Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)Maximum memory pitch: 2147483647 bytesTexture alignment: 512 bytesConcurrent copy and kernel execution: Yes with 2 copy engine(s)Run time limit on kernels: NoIntegrated GPU sharing Host Memory: NoSupport host page-locked memory mapping: YesAlignment requirement for Surfaces: YesDevice has ECC support: EnabledDevice supports Unified Addressing (UVA): YesDevice PCI Domain ID / Bus ID / location ID: 0 / 134 / 0Compute Mode:< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >> Peer access from Tesla K80 (GPU0) -> Tesla K80 (GPU1) : Yes> Peer access from Tesla K80 (GPU0) -> Tesla K80 (GPU2) : No> Peer access from Tesla K80 (GPU0) -> Tesla K80 (GPU3) : No> Peer access from Tesla K80 (GPU1) -> Tesla K80 (GPU0) : Yes> Peer access from Tesla K80 (GPU1) -> Tesla K80 (GPU2) : No> Peer access from Tesla K80 (GPU1) -> Tesla K80 (GPU3) : No> Peer access from Tesla K80 (GPU2) -> Tesla K80 (GPU0) : No> Peer access from Tesla K80 (GPU2) -> Tesla K80 (GPU1) : No> Peer access from Tesla K80 (GPU2) -> Tesla K80 (GPU3) : Yes> Peer access from Tesla K80 (GPU3) -> Tesla K80 (GPU0) : No> Peer access from Tesla K80 (GPU3) -> Tesla K80 (GPU1) : No> Peer access from Tesla K80 (GPU3) -> Tesla K80 (GPU2) : YesdeviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 8.0, CUDA Runtime Version = 8.0, NumDevs = 4, Device0 = Tesla K80, Device1 = Tesla K80, Device2 = Tesla K80, Device3 = Tesla K80Result = PASS
从上面这一段,发现有四张显卡设备,不过记得当时拿到机器的时候,记得只分了两块K80,经查询,Tesla K80一块拥有俩GK210核心,从程序返回的结果来看,原配的2880个流处理器分成的15个阵列,也仅仅被打开了13组,这样,单核心,也就有2496个流处理器了,单卡的话就是两倍的核心,同时,单卡24G内存,确实为一块性能不错的GPU处理器。其他的参数也没有仔细看,用到了再说。
为了后续例子方便,我们在上级目录下,make整个sample,这样,就会为为子目录下面每一个程序,生存可执行文件了。

等到刷出Finished building CUDA samples,即安装完成。
2.2 nvcc问题
想自行编译windows上的一个例子,不过输入nvcc,发现没有安装?

不过转念一想,通过make可以编译,那没道理没装nvcc,后来一想,可能是没有配置环境变量,转到cuda安装目录,一看nvcc好好的在那边。
cd /usr/local/cuda/bin/

转去配置环境变量:
vim ~/.bashrc#发现已经配置过环境变量,不过检查了一下,cuda路径不对,修改一下,顺便加上bin目录,#在最后加上这几行export LD_LIBRARY_PATH="$LD_LIBRARY_PATH:/usr/local/cuda/lib64:/usr/local/cuda/extras/CUPTI/lib64"export CUDA_HOME=/usr/local/cudaexport PATH=$PATH:/usr/local/cuda/bin#保存并刷新环境变量source ~/.bashrc
再次测试nvcc,发现找到了:
三、安装vnc server
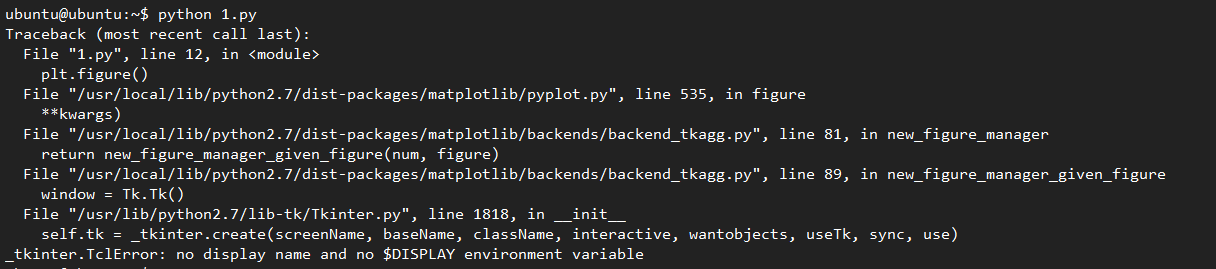
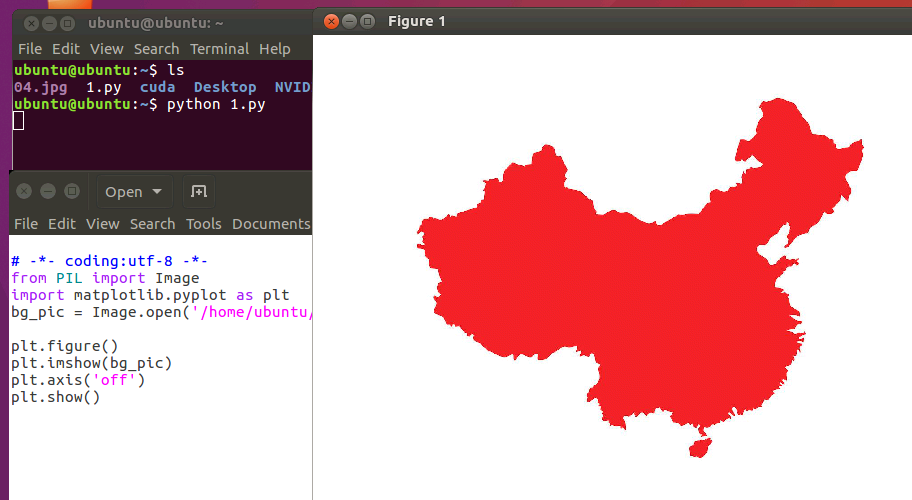
因为server不能直接运行带有图形界面的代码,比如这一段简单的python代码:
# -*- coding:utf-8 -*-from PIL import Imageimport matplotlib.pyplot as pltbg_pic = Image.open('01.jpg')plt.figure()plt.imshow(bg_pic)plt.axis('off')plt.show()
由于可能需要用到图形界面,在此装个vnc,简单记录下
安装服务:
sudo apt-get install vnc4server
编辑下方文件的内容加上自己的信息:
vim /etc/sysconfig/vncserversVNCSERVERS="3:ubuntu"VNCSERVERARGS[3]="-geometry 1920x1080 -alwaysshared"
在自己的用户名下运行命令,启动vnc进程
nvcserver输入2次密码即可
在自己的用户下,修改/home/ubuntu/.vnc/xstartup
配置xsrartup内容如下:
#!/bin/sh# Uncomment the following two lines for normal desktop:# unset SESSION_MANAGER# exec /etc/X11/xinit/xinitrcdefexport XKL_XMODMAP_DISABLE=1unset SESSION_MANAGERunset DBUS_SESSION_BUS_ADDRESSgnome-panel &gnome-settings-daemon &metacity &nautilus &gnome-terminal &
维护方法:
关闭:vncserver -kill :3启动:vncserver :3
这样通过,windows上面的vncviewer连接,就可以运行带有图形界面的程序了。
四、windows测试
本机的电脑,由于毕业设计时候做的是强化学习的相关课题,已经装过了cuda环境,来加速tensorflow-gpu等环境的加速,由于当时没有做记录笔记,并且,没有什么安装难度,这边省略安装步骤。
4.1 deviceQuery
在win下面我们利用vs进行cuda编程,本文windows实验环境为vs2013,首先运行例子deviceQuery,结果如下:
CUDA Device Query (Runtime API) version (CUDART static linking)Detected 1 CUDA Capable device(s)Device 0: "GeForce GT 755M"CUDA Driver Version / Runtime Version 8.0 / 8.0CUDA Capability Major/Minor version number: 3.0Total amount of global memory: 2048 MBytes (2147483648 bytes)( 2) Multiprocessors, (192) CUDA Cores/MP: 384 CUDA CoresGPU Max Clock rate: 1020 MHz (1.02 GHz)Memory Clock rate: 2700 MhzMemory Bus Width: 128-bitL2 Cache Size: 262144 bytesMaximum Texture Dimension Size (x,y,z) 1D=(65536), 2D=(65536, 65536), 3D=(4096, 4096, 4096)Maximum Layered 1D Texture Size, (num) layers 1D=(16384), 2048 layersMaximum Layered 2D Texture Size, (num) layers 2D=(16384, 16384), 2048 layersTotal amount of constant memory: 65536 bytesTotal amount of shared memory per block: 49152 bytesTotal number of registers available per block: 65536Warp size: 32Maximum number of threads per multiprocessor: 2048Maximum number of threads per block: 1024Max dimension size of a thread block (x,y,z): (1024, 1024, 64)Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)Maximum memory pitch: 2147483647 bytesTexture alignment: 512 bytesConcurrent copy and kernel execution: Yes with 1 copy engine(s)Run time limit on kernels: YesIntegrated GPU sharing Host Memory: NoSupport host page-locked memory mapping: YesAlignment requirement for Surfaces: YesDevice has ECC support: DisabledCUDA Device Driver Mode (TCC or WDDM): WDDM (Windows Display Driver Model)Device supports Unified Addressing (UVA): YesDevice PCI Domain ID / Bus ID / location ID: 0 / 1 / 0Compute Mode:< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 8.0, CUDA Runtime Version = 8.0, NumDevs = 1, Device0 = GeForce GT 755MResult = PASS
4.2 新建cuda项目&测试环境
如果安装过程正常无误,那么在vs中应该已经有了cuda模板,我们选择并新建一个cuda工程:
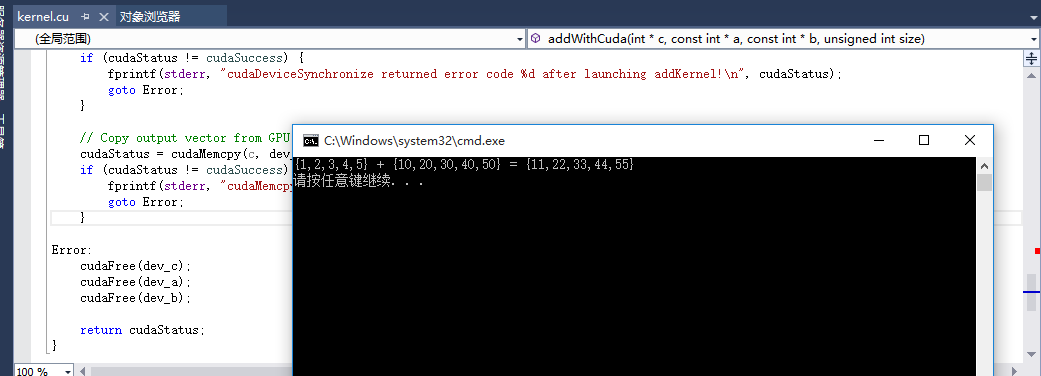
创建完之后,发现自带了一个cuda例子,我们运行,发现可以出结果,至此,cuda运行环境检查完毕
五、cuda实验
5.1 第一个程序 init.cu
首先了解cuda程序初始化的方式,于是先新建一个新的cudafile,开始编写,资料来自于课堂的ppt,并加以理解:
课堂PPT中的代码,没有详细说明每一行的作用,现在对其中的部分进行修改,以更深刻的理解。
先贴上代码:
#include <cuda_runtime.h>#include<iostream>using namespace std;//2017年10月23日//陈实 SA17011008//CUDA 初始化bool InitCUDA(){int count;//取得支持Cuda的装置的数目cudaGetDeviceCount(&count);//没有符合的硬件if (count == 0) {cout << "无可用的设备";return false;}int i;//检查每个设备支持的参数,如果获得的版本号大于1 ,认为找到设备for (i = 0; i < count; i++) {cudaDeviceProp prop;if (cudaGetDeviceProperties(&prop, i) == cudaSuccess) {if (prop.major >= 1) {//输入 并打断点,调试观察cout << "设备" << i << ":" << prop.major << "." << prop.minor << endl;break;}}}if (i == count) {cout << "未找到能支持1.x以上的cuda设备" << endl;return false;}cudaSetDevice(i);return true;}int main(){if (InitCUDA())cout << "初始化成功!" << endl;return 0;}
通过查看prop变量,我们可以观察到很多的参数,并输出自己的设备支持的cuda版本:
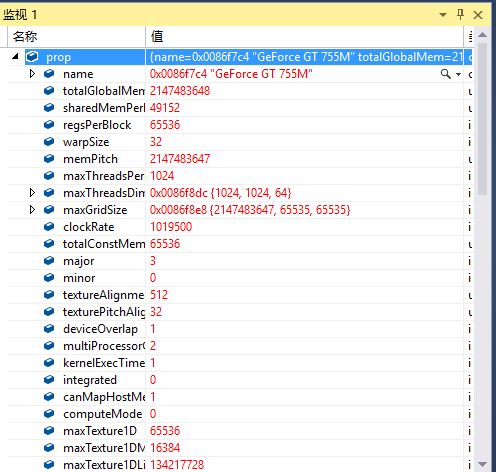
windows上的运行结果是这样:(计算能力3.0)
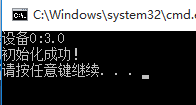
通过winscp 传到服务器,编译并运行
nvcc init.cu -o init.out
ubuntu服务器:(计算能力3.7)

5.2 素数测试
5.2.1 初始测试
本次实验准备以素数测试作为实验题材,进行一个素数的测试,采用不优化的全算法,测试时间。
实验预计采用int范围内最大的素数:2147483647
写了一份简单的代码,其中,核函数如下:
__global__ static void is_prime_g(int *x, bool *result){if (*x == 0 || *x == 1){*result = false;return;}for (int j = 2; j < *x; j++){if (*x%j == 0){*result = false;return;}}*result = true;}
通过cudaApi获得gpu运行时间:
cudaEvent_t start, stop;float Gpu_time;cudaEventCreate(&start);cudaEventCreate(&stop);cudaEventRecord(start, 0);//核函数//........cudaEventRecord(stop, 0);cudaEventSynchronize(stop);cudaEventElapsedTime(&Gpu_time, start, stop); //GPU 测时cudaEventDestroy(start);cudaEventDestroy(stop);printf("Gpu time is: %f ms\n", Gpu_time);
通过clock记录cpu函数时间,循环执行多次,取得平均值:
begin = clock();//开始计时for (int i = 0; i < n; i++){//......}end = clock();//结束计时printf("%d次总耗时%d ms 平均耗时:%f ms\n",n, end - begin, (end - begin)*1.0/n);//差为时间,单位毫秒
实验记录如下:
windows:
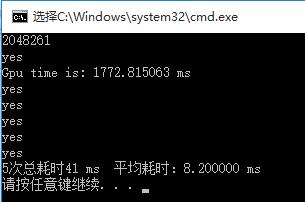
K20:
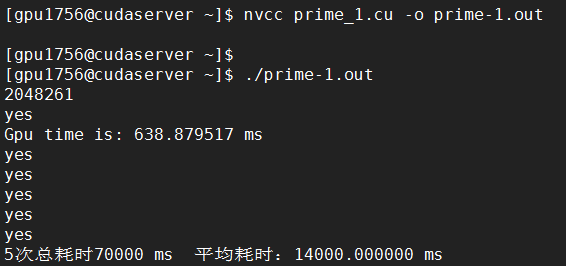
K80:
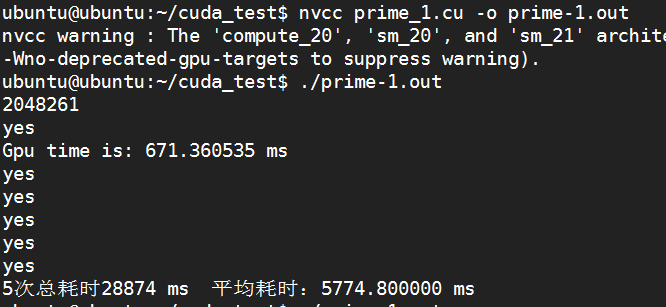
将数字规模扩大10倍:
windows:(出错)
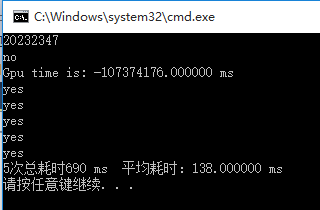
K20:
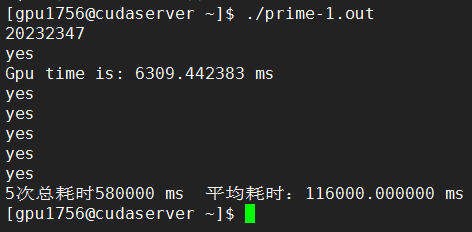
K80:
由于windows显卡出错,下面的实验,仅在服务器上运行:
修改线程数为256:
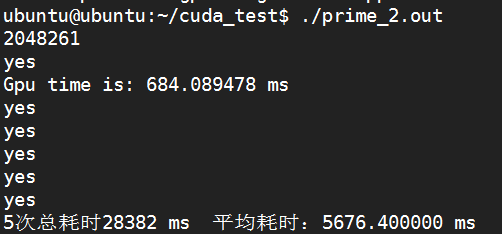
素数为2048261
K20:
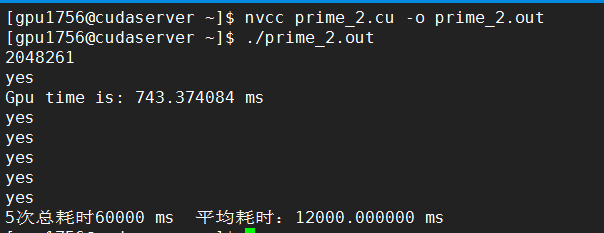
K80:
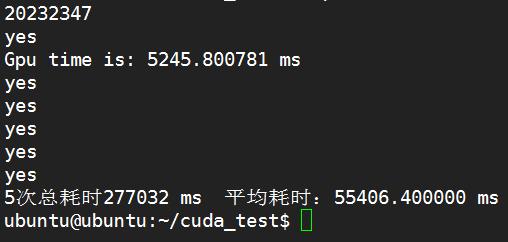
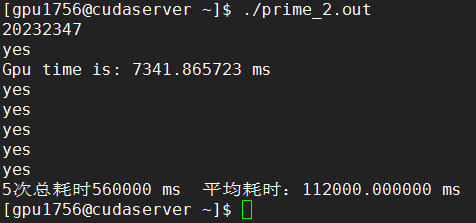
素数为20232347
K20:
K80:
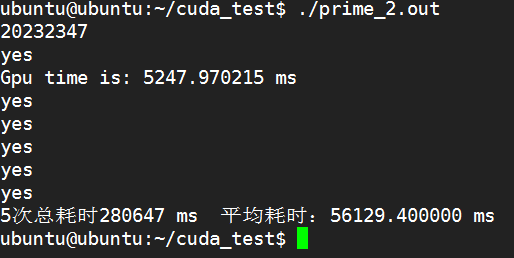
发现,效率并没有提高,继续修改线程为1024,重新编译,经过测试,时间反而还提高了,估计是程序处理的有问题,看到老师PPT,由于是做的东西不太相同,所以没法按PPT上的方法,对线程数进行修改处理。
5.2.2 优化测试
所以换一个思考方式:每个线程判断一个数是否可以被整除,将每线程判断结果写入shared memory内,然后统计结果,如果全部不能被整除,那就是素数。其中计时方式不参考老师ppt,仍然采用cudaApi。cpu不再记录时间(无意义),仅仅用于验证数据是否正确。
仿照老师上课讲的内容,进行修改,代码如下:
#include <stdio.h>#include <stdlib.h>#include <cuda_runtime.h>#include<iostream>#include<time.h>//time.h头文件using namespace std;#define THREAD_NUM 1#define BLOCK_NUM 1//host code//产生一个要被测试的数组//void GenerateNumbers(long *number, int size){for (int i = 0; i < size - 2; i++) {number[i] = i + 2;}}//device code//内核函数//__global__ static void IsPrime(long *num, bool* result, int TEST){extern __shared__ bool shared[];const int tid = threadIdx.x; //块内线程索引const int bid = blockIdx.x; //网格中线程块索引result[bid] = false;int i;for (i = bid * THREAD_NUM + tid; i < TEST; i += BLOCK_NUM * THREAD_NUM){if (TEST % num[bid*bid * THREAD_NUM + tid] == 0) //能整除{shared[tid] = true;}else{shared[tid] = false;}}__syncthreads(); //同步函数if (tid == 0){for (i = 0; i<THREAD_NUM; i++){if (shared[i]){result[bid] = true;}}}}//原始素数求法bool is_prime(int x){if (x == 0 || x == 1)return false;for (int j = 2; j < x; j++){if (x%j == 0)return false;}return true;}//host code//主函数//int main(){int TEST;cin >> TEST;long *data = new long[TEST];GenerateNumbers(data, TEST); //产生要测试的数组//定义并分配内存long* gpudata;bool* result;cudaMalloc((void**)&gpudata, sizeof(long)* TEST);cudaMalloc((void**)&result, sizeof(bool)*BLOCK_NUM);//数据拷贝cudaMemcpy(gpudata, data, sizeof(long)* TEST, cudaMemcpyHostToDevice);//api计时cudaEvent_t start, stop;float Gpu_time;cudaEventCreate(&start);cudaEventCreate(&stop);cudaEventRecord(start, 0);//调用内核函数IsPrime << <BLOCK_NUM, THREAD_NUM, THREAD_NUM * sizeof(bool) >> >(gpudata, result,TEST);//api计时结束cudaEventRecord(stop, 0);cudaEventSynchronize(stop);cudaEventElapsedTime(&Gpu_time, start, stop); //GPU 测时cudaEventDestroy(start);cudaEventDestroy(stop);printf("Gpu time is: %f ms\n", Gpu_time);bool sum[BLOCK_NUM];//结果拷贝cudaMemcpy(&sum, result, sizeof(bool)*BLOCK_NUM, cudaMemcpyDeviceToHost);//释放空间cudaFree(gpudata);cudaFree(result);//验证结果(不参与计时)bool isprime = true;for (int i = 0; i < BLOCK_NUM; i++){if (sum[i]){isprime = false;break;}}//gpuif (isprime){printf("GPU:%d is a prime\n", TEST);}else{printf("GPU:%d is not a prime\n", TEST);}//cpuint begin, end;//定义开始和结束标志位begin = clock();//开始计时if (is_prime(TEST))printf("CPU:%d is a prime\n", TEST);elseprintf("CPU:%d is not a prime\n", TEST);end = clock();//结束计时printf("Cpu time is: %d\n", end-begin);return 0;}
每个具体的线程,即blockid的某个threadid的线程,所计算的是一个数或者好几个数,总共有block_NUM*THREAD_NUM这么多的线程,假设要计算素数test,则必须对所有从2,3,4...到test-1这么多数做除法运算,总共应该是test-1个数,这些数就按顺序安排到block_NUM*THREAD_NUM这些线程上运行,多出来的再次重复的安排也就是说i和i += BLOCK_NUM * THREAD_NUM都应该是安排在同一个线程块的同一个线程id上运行。
测试1:
#define THREAD_NUM 1#define BLOCK_NUM 1
K20:
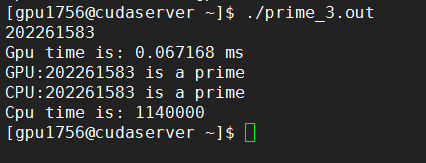
K80:
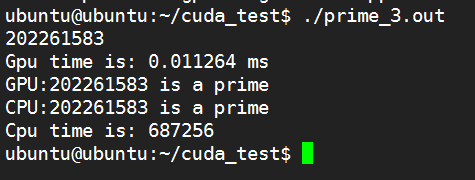
测试2:
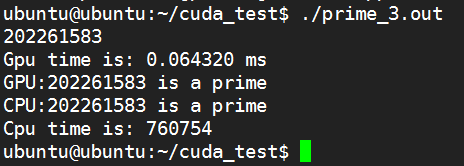
#define THREAD_NUM 1024#define BLOCK_NUM 1
K20:
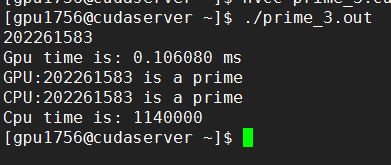
K80:
从实验结果来看,提升块并没有加速时间,怀疑用错了GPU计时,所以利用nvprof查看:
ubuntu@ubuntu:~/cuda_test$ nvprof ./prime_3.out202261583==1365== NVPROF is profiling process 1365, command: ./prime_3.outGpu time is: 0.072064 msGPU:202261583 is a primeCPU:202261583 is a primeCpu time is: 811364==1365== Profiling application: ./prime_3.out==1365== Profiling result:Time(%) Time Calls Avg Min Max Name99.97% 236.60ms 1 236.60ms 236.60ms 236.60ms [CUDA memcpy HtoD]0.03% 62.752us 1 62.752us 62.752us 62.752us IsPrime(long*, bool*, int)0.00% 3.3600us 1 3.3600us 3.3600us 3.3600us [CUDA memcpy DtoH]==1365== API calls:Time(%) Time Calls Avg Min Max Name58.06% 337.27ms 2 168.64ms 375.87us 336.90ms cudaMalloc40.76% 236.75ms 2 118.37ms 37.190us 236.71ms cudaMemcpy0.52% 3.0149ms 364 8.2820us 246ns 279.56us cuDeviceGetAttribute0.43% 2.5004ms 4 625.10us 615.91us 629.75us cuDeviceTotalMem0.15% 878.57us 2 439.28us 170.20us 708.37us cudaFree0.04% 232.24us 4 58.060us 56.043us 60.786us cuDeviceGetName0.02% 124.54us 1 124.54us 124.54us 124.54us cudaEventSynchronize0.01% 43.690us 1 43.690us 43.690us 43.690us cudaLaunch0.00% 9.5710us 2 4.7850us 1.7290us 7.8420us cudaEventCreate0.00% 9.3820us 2 4.6910us 2.9250us 6.4570us cudaEventRecord0.00% 7.5690us 3 2.5230us 270ns 6.7980us cudaSetupArgument0.00% 5.0280us 12 419ns 245ns 762ns cuDeviceGet0.00% 4.3560us 1 4.3560us 4.3560us 4.3560us cudaEventElapsedTime0.00% 2.9730us 3 991ns 281ns 2.0150us cuDeviceGetCount0.00% 2.8080us 2 1.4040us 740ns 2.0680us cudaEventDestroy0.00% 1.9640us 1 1.9640us 1.9640us 1.9640us cudaConfigureCall
发现,计算时间确实很短,所以基本不需要优化。
5.2.3 其他优化
由于选题有问题,导致并不能测出优化前后的结果对比,但还是照着PPT上的其他思路进行优化,使用block与grid内建对象,进行重新改写kernel函数,并通过标记一个值进行返回,这样可以做到较好的效果,代码如下:
#include "stdio.h"#include "stdlib.h"#include<iostream>#include <cuda_runtime.h>using namespace std;//define kernel__global__ void prime_kernel(int *d_mark, int N){int i = blockIdx.x * 256 + threadIdx.x + 16 + threadIdx.y;//threadIdx.x*16if (i >= 2 && N%i == 0)//判断条件正确*d_mark = 0;}//原始素数求法bool is_prime(int x){if (x == 0 || x == 1)return false;for (int j = 2; j < x; j++){if (x%j == 0)return false;}return true;}int main(){int N;cin >> N;int *h_mark;h_mark = (int *)malloc(sizeof(int)* 1);*h_mark = 1;//if *h_mark == 1 N is a prime number; else N is not a prime number//分配空间int *d_mark;cudaMalloc((void **)&d_mark, sizeof(int));// 拷贝数据cudaMemcpy(d_mark, h_mark, sizeof(int), cudaMemcpyHostToDevice);// 设置执行参数dim3 block(16, 16); //可以用一维实现,(256,1)dim3 grid(4, 1);//api计时cudaEvent_t start, stop;float Gpu_time;cudaEventCreate(&start);cudaEventCreate(&stop);cudaEventRecord(start, 0);//执行kernelprime_kernel << <block, grid >> >(d_mark, N);//block和grid位置反了//api计时结束cudaEventRecord(stop, 0);cudaEventSynchronize(stop);cudaEventElapsedTime(&Gpu_time, start, stop); //GPU 测时cudaEventDestroy(start);cudaEventDestroy(stop);printf("Gpu time is: %f ms\n", Gpu_time);// 结果拷贝cudaMemcpy(h_mark, d_mark, sizeof(int), cudaMemcpyDeviceToHost);//GPU输出if (*h_mark == 1)printf( "%d is a prime number\n", N);elseprintf( "%d is not a prime number\n", N);//释放cudaFree(d_mark);//cpu输出if (is_prime(N))printf("CPU:%d is a prime\n", N);elseprintf("CPU:%d is not a prime\n", N);return 0;}
k20:
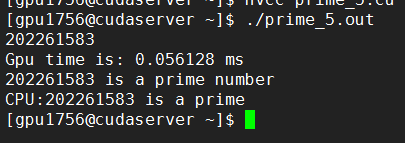
k80:
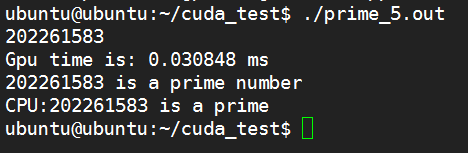
5.3 总结
本次实验,分成下面几步:
1.串行:cpu上,测试一个数是否为素数
2.丢在GPU上:改写成kernel函数
3.基本并行化:每个线程判断一个数是否可以被整除,将每线程判断结果写入shared memory内,然后统计结果,如果全部不能被整除,那就是素数。
4、优化:使用block与grid内建对象,进行重新改写kernel函数
六、实验心得
1.学会了CUDA编程的基本原理,能够编写简单的CUDA程序并且比未优化的CPU版本运行速度快。
2.初步了解了CUDA并行化的基本知识。
3.对cuda编程工具有了较好的了解,对liunx的使用有了提升。
