@linux1s1s
2019-02-21T07:26:47.000000Z
字数 4787
阅读 2370
Base Time-Java
Base 2016-12
系列博文
Base Time-Http Protocol
Base Time-Bitmap
Base Time-Database
Base Time-Java
Base Time-Design Patterns
Base Time-Java Algorithms
内存模型
后续补充,请参考Java内存模型
Files&IO
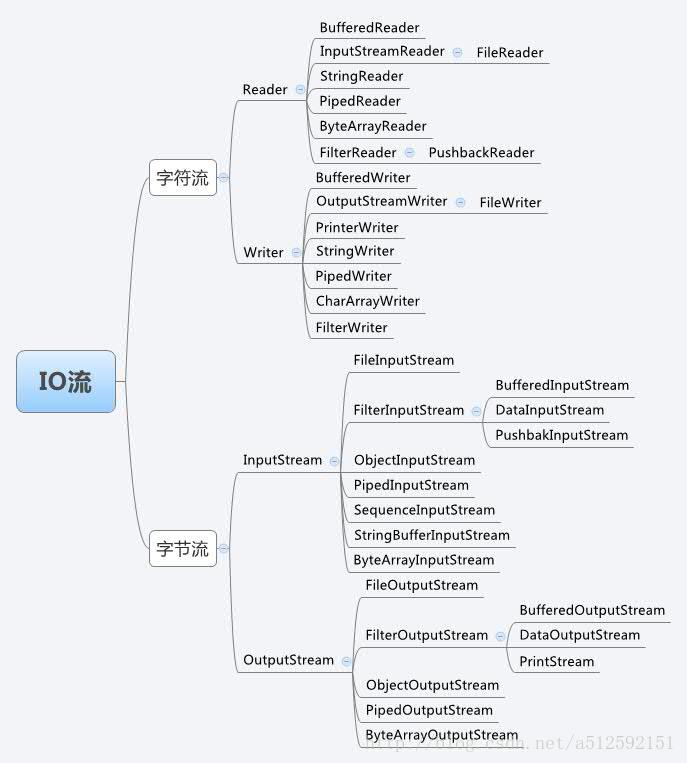
基本概念
举栗子
- 1.unicode存储“连通”。磁盘字节真实存储的其实是:
FF FE 8FDE 901A
前两个FF FE是标记,告诉电脑,这个文档的存储方式是unicode。
8FDE 是连
901A 是通
所以 每个汉字是 2个字节 (1个字节是8bit)
- 2.utf-8存储“连通”。磁盘字节真实存储的其实是:
EF BB BF E8 BF 9E E9 80 9A
前三个EF BB BF 告诉电脑 这个文档是utf-8存储的。
E8 BF 9E 是连
E9 80 9A 是通
所以 每个汉字是 3个字节 (1个字节是8bit)
字节流
字节输入流
- 对于输入流,我们可以看出。
- (01) InputStream 是以字节为单位的输入流的超类。InputStream提供了read()接口从输入流中读取字节数据。
- (02) ByteArrayInputStream 是字节数组输入流。它包含一个内部缓冲区,该缓冲区包含从流中读取的字节;通俗点说,它的内部缓冲区就是一个字节数组,而ByteArrayInputStream本质就是通过字节数组来实现的。
- (03) PipedInputStream 是管道输入流,它和PipedOutputStream一起使用,能实现多线程间的管道通信。
- (04) FilterInputStream 是过滤输入流。它是DataInputStream和BufferedInputStream的超类。
- (05) DataInputStream 是数据输入流。它是用来装饰其它输入流,它“允许应用程序以与机器无关方式从底层输入流中读取基本 Java 数据类型”。
- (06) BufferedInputStream 是缓冲输入流。它的作用是为另一个输入流添加缓冲功能。
- (07) File 是“文件”和“目录路径名”的抽象表示形式。关于File,注意两点:
- a), File不仅仅只是表示文件,它也可以表示目录!
- b), File虽然在io保重定义,但是它的超类是Object,而不是InputStream。
- (08) FileDescriptor 是“文件描述符”。它可以被用来表示开放文件、开放套接字等。
- (09) FileInputStream 是文件输入流。它通常用于对文件进行读取操作。
- (10) ObjectInputStream 是对象输入流。它和ObjectOutputStream一起,用来提供对“基本数据或对象”的持久存储。
字节输出流
- 对于输出流,我们可以看出。以字节为单位的输出流的公共父类是OutputStream。
- (01) OutputStream 是以字节为单位的输出流的超类。OutputStream提供了write()接口从输出流中读取字节数据。
- (02) ByteArrayOutputStream 是字节数组输出流。写入ByteArrayOutputStream的数据被写入一个 byte 数组。缓冲区会随着数据的不断写入而自动增长。可使用 toByteArray() 和 toString() 获取数据。
- (03) PipedOutputStream 是管道输出流,它和PipedInputStream一起使用,能实现多线程间的管道通信。
- (04) FilterOutputStream 是过滤输出流。它是DataOutputStream,BufferedOutputStream和PrintStream的超类。
- (05) DataOutputStream 是数据输出流。它是用来装饰其它输出流,它“允许应用程序以与机器无关方式向底层写入基本 Java 数据类型”。
- (06) BufferedOutputStream 是缓冲输出流。它的作用是为另一个输出流添加缓冲功能。
- (07) PrintStream 是打印输出流。它是用来装饰其它输出流,能为其他输出流添加了功能,使它们能够方便地打印各种数据值表示形式。
- (08) FileOutputStream 是文件输出流。它通常用于向文件进行写入操作。
- (09) ObjectOutputStream 是对象输出流。它和ObjectInputStream一起,用来提供对“基本数据或对象”的持久存储。
字符流
字符输入流
- 对于输入流,我们可以看出。以字符为单位的输入流的公共父类是Reader。
- (01) Reader 是以字符为单位的输入流的超类。它提供了read()接口来取字符数据。
- (02) CharArrayReader 是字符数组输入流。它用于读取字符数组,它继承于Reader。操作的数据是以字符为单位!
- (03) PipedReader 是字符类型的管道输入流。它和PipedWriter一起是可以通过管道进行线程间的通讯。在使用管道通信时,必须将PipedWriter和PipedReader配套使用。
- (04) FilterReader 是字符类型的过滤输入流。
- (05) BufferedReader 是字符缓冲输入流。它的作用是为另一个输入流添加缓冲功能。
- (06) InputStreamReader 是字节转字符的输入流。它是字节流通向字符流的桥梁:它使用指定的 charset 读取字节并将其解码为字符。
- (07) FileReader 是字符类型的文件输入流。它通常用于对文件进行读取操作。
字符输出流
- 对于输出流,我们可以看出。以字符为单位的输出流的公共父类是Write。
- (01) Writer 是以字符为单位的输出流的超类。它提供了write()接口往其中写入数据。
- (02) CharArrayWriter 是字符数组输出流。它用于读取字符数组,它继承于Writer。操作的数据是以字符为单位!
- (03) PipedWriter 是字符类型的管道输出流。它和PipedReader一起是可以通过管道进行线程间的通讯。在使用管道通信时,必须将PipedWriter和PipedWriter配套使用。
- (04) FilterWriter 是字符类型的过滤输出流。
- (05) BufferedWriter 是字符缓冲输出流。它的作用是为另一个输出流添加缓冲功能。
- (06) OutputStreamWriter 是字节转字符的输出流。它是字节流通向字符流的桥梁:它使用指定的 charset 将字节转换为字符并写入。
- (07) FileWriter 是字符类型的文件输出流。它通常用于对文件进行读取操作。
- (08) PrintWriter 是字符类型的打印输出流。它是用来装饰其它输出流,能为其他输出流添加了功能,使它们能够方便地打印各种数据值表示形式。
集合
数据结构是以某种形式将数据组织在一起的集合,它不仅存储数据,还支持访问和处理数据的操作。Java提供了几个能有效地组织和操作数据的数据结构,这些数据结构通常称为Java集合框架。在平常的学习开发中,灵活熟练地使用这些集合框架,可以很明显地提高我们的开发效率,当然仅仅会用还是不够的,理解其中的设计思想与原理才能更好地提高我们的开发水平。
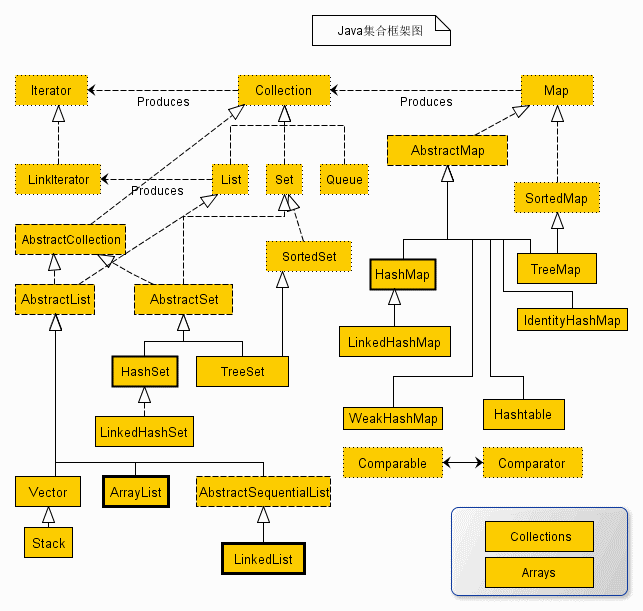
小结
Java集合框架主要包括Collection和Map两种类型。其中Collection又有3种子类型,分别是List、Set、Queue。Map中存储的主要是键值对映射。
规则集Set中存储的是不重复的元素,线性表中存储可以包括重复的元素,Queue队列描述的是先进先出的数据结构,可以用LinkedList来实现队列。
效率上,规则集比线性表更高效。
ArrayList主要是用数组来存储元素,LinkedList主要是用链表来存储元素,HashMap的底层实现主要是借助数组+链表+红黑树来实现。
Vector、HashTable等集合类效率比较低但都是线程安全的。包java.util.concurrent下包含了大量线程安全的集合类,效率上有较大提升。
更多细节请参考Java - 集合框架完全解析
多线程
线程状态图
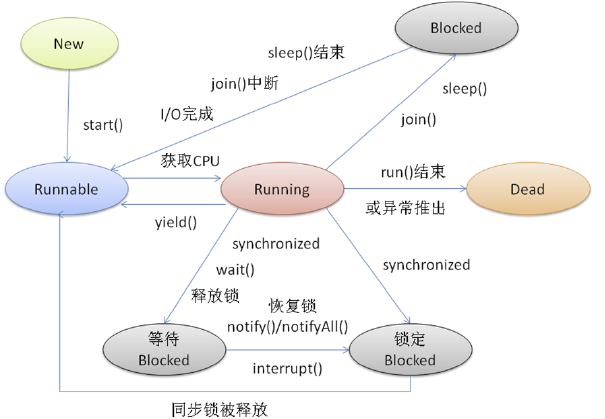
synchronized, wait, notify
synchronized用法:
- 单独用
public class Thread1 implements Runnable {Object lock = new Object();public void run() {synchronized(lock){..do something}}}
这里锁住的明显是lock实例。
- 直接用于方法: 相当于上面代码中用lock来锁定的效果,实际获取的是Thread1类的monitor。更进一步,如果修饰的是static方法,则锁定该类所有实例。
public class Thread1 implements Runnable {public synchronized void run() {..do something}}
这里锁住的是Thread1的实例,如果是static方法,则锁住的是该类的所有实例。
- synchronized, wait, notify结合:典型场景生产者消费者问题
/*** 生产者生产出来的产品交给店员*/public synchronized void produce(){if(this.product >= MAX_PRODUCT){try{wait();System.out.println("产品已满,请稍候再生产");}catch(InterruptedException e){e.printStackTrace();}return;}this.product++;System.out.println("生产者生产第" + this.product + "个产品.");notifyAll(); //通知等待区的消费者可以取出产品了}/*** 消费者从店员取产品*/public synchronized void consume(){if(this.product <= MIN_PRODUCT){try{wait();System.out.println("缺货,稍候再取");}catch (InterruptedException e){e.printStackTrace();}return;}System.out.println("消费者取走了第" + this.product + "个产品.");this.product--;notifyAll(); //通知等待去的生产者可以生产产品了}
这里锁住的是这两个方法所属的实例,记住锁只有作用在同样一个实例上才有作用,否则无效。
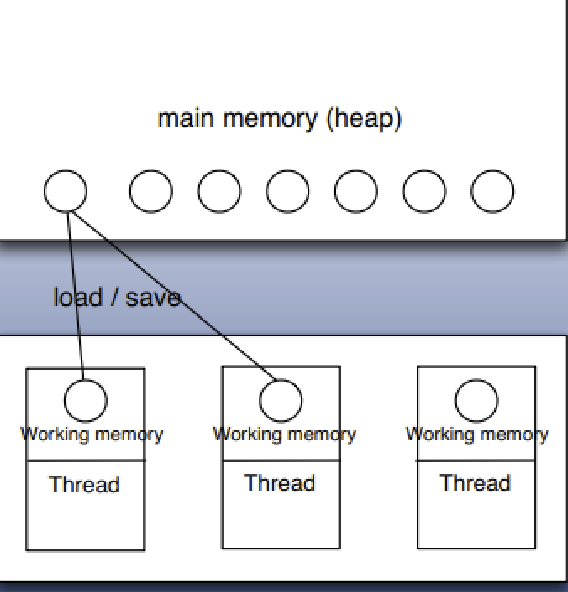
volatile
多线程的内存模型:main memory(主存)、working memory(线程栈),在处理数据时,线程会把值从主存load到本地栈,完成操作后再save回去(volatile关键词的作用:每次针对该变量的操作都激发一次load and save)。
典型使用场景
volatile最适用一个线程写,多个线程读的场合。
如果有多个线程并发写操作,仍然需要使用锁或者线程安全的容器或者原子变量来代替。(摘自Netty权威指南)
疑问:如果只是赋值的原子操作,是否可以多个线程写?(答案:可以,但是一般没有这样的必要,即没有这样的应用场景)
最典型的适用场景
volatile boolean shutdownRequested;...public void shutdown() { shutdownRequested = true; }public void doWork() {while (!shutdownRequested) {// do stuff}}
- 关于多线程请移步Java 并发编程框架(一)系列博客。
反射
- 请移步Java 反射基础
参考博文:
Java - 集合框架完全解析
java io系列01之 "目录"
Java IO最详解
随笔分类 - Java
