@richey
2016-04-15T12:16:25.000000Z
字数 6556
阅读 1786
机器学习笔记1-回归问题
机器学习 回归 梯度下降
1 线性回归(Linear Regression)
1.1 线性回归入门示例
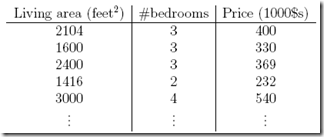
先看个例子,比如,想用面积和卧室个数来预测房屋的价格
训练集如下:
首先,我们假设为线性模型,那么hypotheses定义为
其中表示面积和#bedrooms(卧室)两个特征(feature)
那么对于线性模型,更为通用的写法为
其中把和看成向量,并且,就可以表示成最后那种,两个向量相乘的形式。
线性回归的目的,就是通过训练集找出使得误差最小的一组参数(称为学习),为了可以量化误差,定义代价函数(cost function)
比较好理解,就是训练集中所有样本点,真实值和预测值之间的误差的平方和,其中1/2是为了后面计算方便,求导时会消掉,所以我们目的就是找到使得最小,这就是最小二乘法(最小平方),很容易理解。
richey批注:这里的m代表m个训练样本,每个样本有n个特征(的纬度)。
1.2 梯度下降法(gradient descent)
为了求解这个最优化问题,即找到使得最小,可以有很多方法。
先介绍梯度下降法 ,这是一种迭代方法,先随意选取初始,比如,然后不断的以梯度的方向修正,最终使收敛到最小。
当然梯度下降找到的最优是局部最优,也就是说选取不同的初值,可能会找到不同的局部最优点,但是对于最小二乘的代价函数模型,比较简单只有一个最优点,所以局部最优即全局最优。
对于某个参数的梯度,其实就是对该参数求导的结果,所以对于某个参数每次调整的公式如下:
此处:=为赋值运算
称为“学习率”(learning rate),代表下降幅度,步长,小会导致收敛慢,大会导致错过最优点,所以公式含义就是,每次在梯度方向下降一步。
下面继续推导,假设训练集里面只有一个样本点,那么梯度推导为:
richey注解: 取, 是特征的纬度,注意到上式是对求偏导,因此第3个式子中只有,其他项对的偏导数为零。
1.2.1 批梯度下降法
就是求导过程,但是实际训练集中会有m个样本点,所以最终递推公式为:
重复迭代以下直至收敛{
}
因为 中有多个参数,所以每次迭代对于每个参数都需要进行梯度下降,直到收敛到最小值,这个方法称为批梯度下降(batch gradient descent),理由是每次计算梯度都需要遍历所有的样本点,这是因为梯度是的导数,而是需要考虑所有样本的误差和。
批梯度下降方法的问题就是当样本点很大的时候,基本就没法算了(每次迭代都遍历样本空间一遍)。
1.2.2 随机梯度下降法
所以提出一种stochastic gradient descent(随机梯度下降),想法很简单,即每次只考虑一个样本点,而不是所有样本点,那么公式就变为:
Loop{
for i in m,{
{
}
其实意思就是,每次迭代只是考虑让该样本点的趋向最小,而不管其他的样本点,这样算法会很快,但是收敛的过程会比较曲折,适合用于较大训练集的场景。
梯度下降法的缺点:
- 需要预先选定Learning rate;
- 需要多次iteration;
- 需要Feature Scaling;
1.3 最小二乘法(LMS)
其推导过程的思路:
推导得出的矩阵表达式,梯度为零时的取得最小值。
相当于通过求解矩阵方程得到的解析解。
1.4 加权线性回归
首先考虑下图中的几种曲线拟合情况:
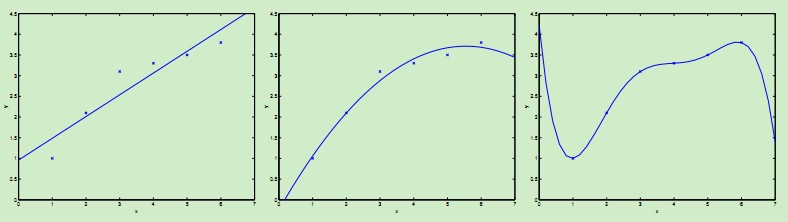
最左边的图使用线性拟合,但是可以看到数据点并不完全在一条直线上,因而拟合的效果并不好。如果我们加入项,得到,如中间图所示,该二次曲线可以更好的拟合数据点。
我们继续加入更高次项,可以得到最右边图所示的拟合曲线,可以完美地拟合数据点,最右边的图中曲线为5阶多项式,可是我们都很清醒地知道这个曲线过于完美了,对于新来的数据可能预测效果并不会那么好。
对于最左边的曲线,我们称之为欠拟合--过小的特征集合使得模型过于简单不能很好地表达数据的结构,最右边的曲线我们称之为过拟合--过大的特征集合使得模型过于复杂。
正如上述例子表明,在学习过程中,特征的选择对于最终学习到的模型的性能有很大影响,于是选择用哪个特征,每个特征的重要性如何就产生了加权的线性回归。在传统的线性回归中,学习过程如下:
- Fit to minimaize
- Output:
richey注解:以上求和将m个样本同等看待
而加权线性回归学习过程如下:
1. Fit to minimaize
2. Output:
二者的区别就在于对不同的样本赋予了不同的非负值权重,权重越大,对于代价函数的影响越大。一般选取的权重计算公式为:
总结一下:加权线性回归LWR算法是一种non-parametric(非参数)学习算法,而线性回归则是一种parametric(参数)学习算法。
所谓参数学习算法它有固定的明确的参数,参数一旦确定,就不会改变了,我们不需要在保留训练集中的训练样本。
而非参数学习算法,每进行一次预测,就需要重新学习一组,是变化的,所以需要一直保留训练样本。也就是说,当训练集的容量较大时,非参数学习算法需要占用更多的存储空间,计算速度也较慢。有得必有失,效果好当然要牺牲一些其他的东西。
1.5 代码实现
1.5.1 使用scikit-learn库
1.5.1.1 最小二乘法
1.5.2 不使用库
from numpy import *import matplotlib.pyplot as pltdef loadDataSet(filename):numFeat = len(open(filename).readline().split('\t'))-1dataMat = []labelMat = []fr = open(filename)for line in fr.readlines():lineArr = []curLine = line.strip('\n').split('\t')for i in range(numFeat):lineArr.append(float(curLine[i]))dataMat.append(lineArr)labelMat.append(float(curLine[-1]))return dataMat, labelMatdef standMaReg(xArr, yArr):xMat = mat(xArr)yMat = mat(yArr).TxTx = xMat.T*xMatif linalg.det(xTx)==0.0:print 'This matrix is singular, connot do inverse'returnws = xTx.I*(xMat.T*yMat)return wsdef standBaGradReg(xArr, yArr, alpha=0.001, iter_num=15):xMat = mat(xArr)yMat = mat(yArr).Tm,n=shape(xMat)weights = mat(ones((n,1)))for i in range(iter_num):yPredict = mat(xMat*weights)tmp=mat(zeros((n,1)))for j in range(n):tmp[j,:] += alpha*sum(multiply((yMat-yPredict),xMat[:,j]))weights = weights + tmpreturn weightsdef lwlr(testPoint, xArr, yArr, k=1.0):xMat = mat(xArr)yMat = mat(yArr).Tm = shape(xMat)[0]weights = mat(eye((m)))for j in range(m):diffMat = testPoint - xMat[j,:]weights[j,j] = exp(diffMat*diffMat.T/(-2.0*k**2))xTx = xMat.T*(weights*xMat)if linalg.det(xTx) == 0.0:print "This matrix is singular, cannot do inverse"returnws = xTx.I*(xMat.T*(weights*yMat))return testPoint*wsdef lwlrTest(testArr, xArr, yArr, k=1.0):m = shape(testArr)[0]yPre = zeros(m)for i in range(m):yPre[i] = lwlr(testArr[i], xArr, yArr, k)return yPredef ridgeRegres(xMat, yMat, lam=0.2):xTx = xMat.T*xMatdenom = xTx + eye(shape(xMat)[1])*lamif linalg.det(denom) == 0.0:print "This matrix is singular, cannot do inverse"ws = denom.I*(xMat.T*yMat)return wsdef ridgeTest(xArr, yArr, numIter=30):xMat = mat(xArr)yMat = mat(yArr).TyMean = mean(yMat,0)yMat = yMat - yMeanxMeans = mean(xMat, 0)xVar = var(xMat, 0)xMat = (xMat - xMeans)/xVarwMat = zeros((numIter,shape(xMat)[1]))lamList = []for i in range(numIter):lamList.append(exp(i-10))ws = ridgeRegres(xMat, yMat, exp(i-10))wMat[i,:]=ws.Treturn wMat, lamListdef plotReg(weights, xArr, yArr, xIndex=0):xMat = mat(xArr)yMat = mat(yArr)fig = plt.figure()ax = fig.add_subplot(111)ax.scatter(xMat[:,xIndex].flatten().A[0], yMat.T[:,0].flatten().A[0])yPredict = xMat*weightsax.plot(xMat[:,xIndex], yPredict)plt.show()xArr, yArr = loadDataSet("ex0.txt")ws1 = standMaReg(xArr, yArr)print "ws1", ws1plotReg(ws1, xArr, yArr, 1)ws2 = standBaGradReg(xArr, yArr, 0.001, 1000)print "ws2", ws2yPre = lwlrTest(xArr, xArr, yArr, 0.01)xMat = mat(xArr)srtInde = xMat[:,1].argsort(0)xSort = xMat[srtInde][:,0,:]fig = plt.figure()ax = fig.add_subplot(111)ax.plot(xSort[:,1], yPre[srtInde])ax.scatter(xMat[:,1].flatten().A[0], mat(yArr).T.flatten().A[0], s=2, c='red')plt.show()abX, abY = loadDataSet('abalone.txt')weights, lam = ridgeTest(abX, abY)plt.plot(weights)plt.show()
2 逻辑回归
3 Softmax回归
1 http://www.cnblogs.com/fxjwind/p/3626173.html?utm_source=tuicool&utm_medium=referral
2 http://blog.csdn.net/moodytong/article/details/10041547
3 http://www.cnblogs.com/fanyabo/p/4060498.html
