@levinzhang
2022-10-06T01:15:04.000000Z
字数 6184
阅读 1215
为什么说Kubernetes重塑了虚拟机?
摘要
Kubernetes在应用的打包和部署方面取代了传统的基于虚拟机的方式,但是如果从理念上来看,两者是一脉相承的。作者通过梳理容器和Kubernetes的发展历程,探寻了架构发展的内在逻辑。
本文最初发表于作者的个人站点,经原作者Ivan Velichko授权由InfoQ中文站翻译分享。
有很多文章都是试图说明要入门Kubernetes有多么简单。但是,很多文章都使用了很复杂的Kubernetes术语,所以即便是具有服务器端知识的人可能也会感到困惑。那么,我们尝试一下不同的方式。与其使用某个大家不熟悉的东西(如何在Kubernetes上运行web服务?)去阐述另外一个不熟悉的东西(你只需要一个清单文件,三个sidecar还有一堆神奇的咒语),我将会从另一个角度阐述一个观点,那就是Kubernetes实际上是良好的旧部署技术的自然发展。
如果你已经知道如何使用虚拟机来运行服务(希望如此),你会发现最终并没有太大的区别。如果你对如何运行大规模的服务完全没有经验,那么通过了解技术的演进,对理解当前的实现方式也会有一定帮助。
像往常一样,本文不会是综合性教程。相反,我只是总结了自己的经验,以及对该领域是如何发展的个人理解。
如何使用虚拟机部署服务
早在2010年,当我刚刚开始软件工程师的职业生涯时,使用虚拟机(或裸机)部署应用是非常普遍的。
我们可能会从一个Linux虚拟机开始,将PHP web应用放进去,在应用的前面放置Nginx或Apache反向代理,然后再运行一些辅助性的守护进程和cronjob。
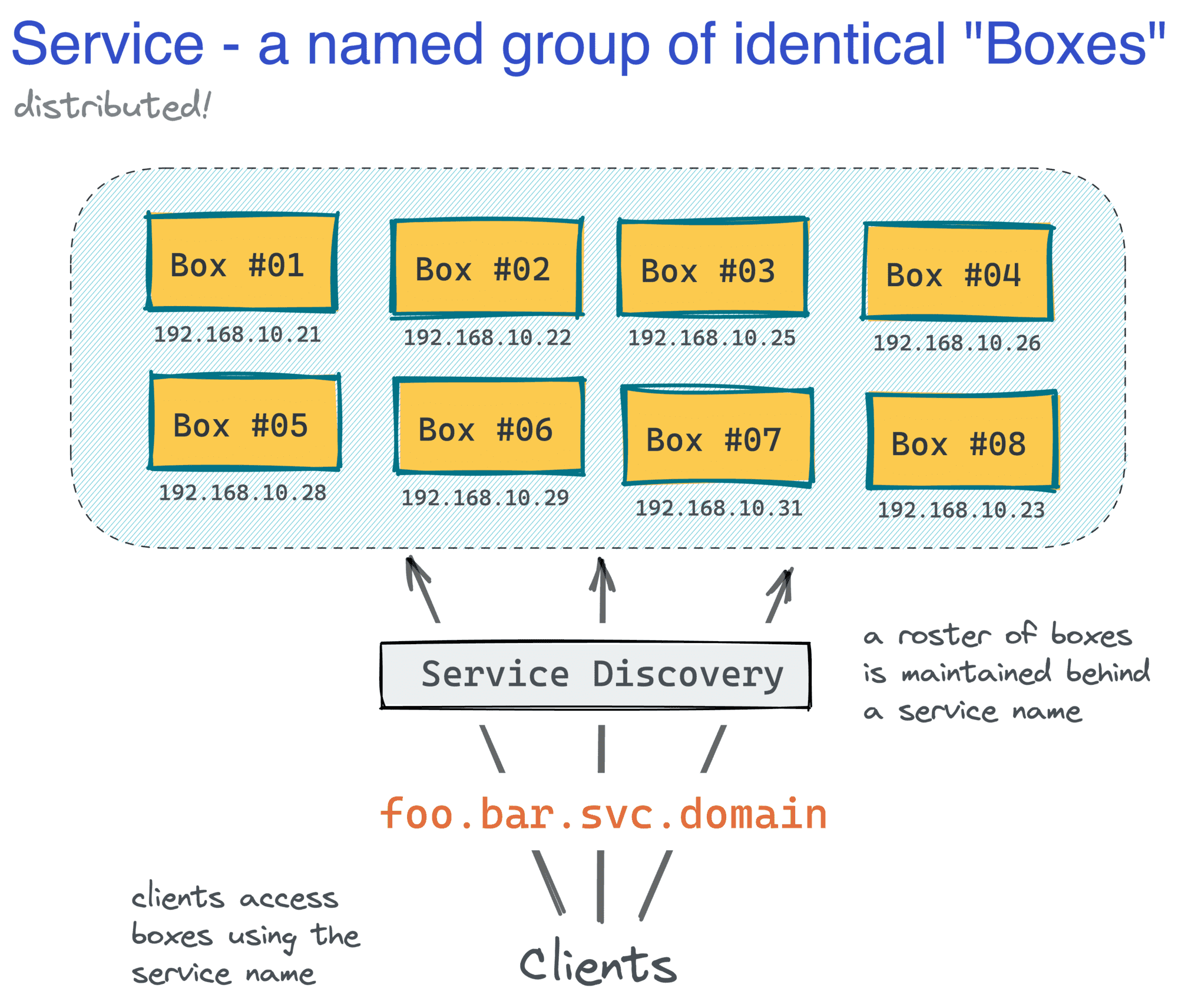
这样的机器代表了应用的一个实例,简单来说,也可以叫做一个box,服务本身就是分布在网络上的一组相同的机器。根据业务的规模,我们可能有几个、几十个、几百个,甚至几千个这样的box,分布在服务于生产环境的多个服务中。
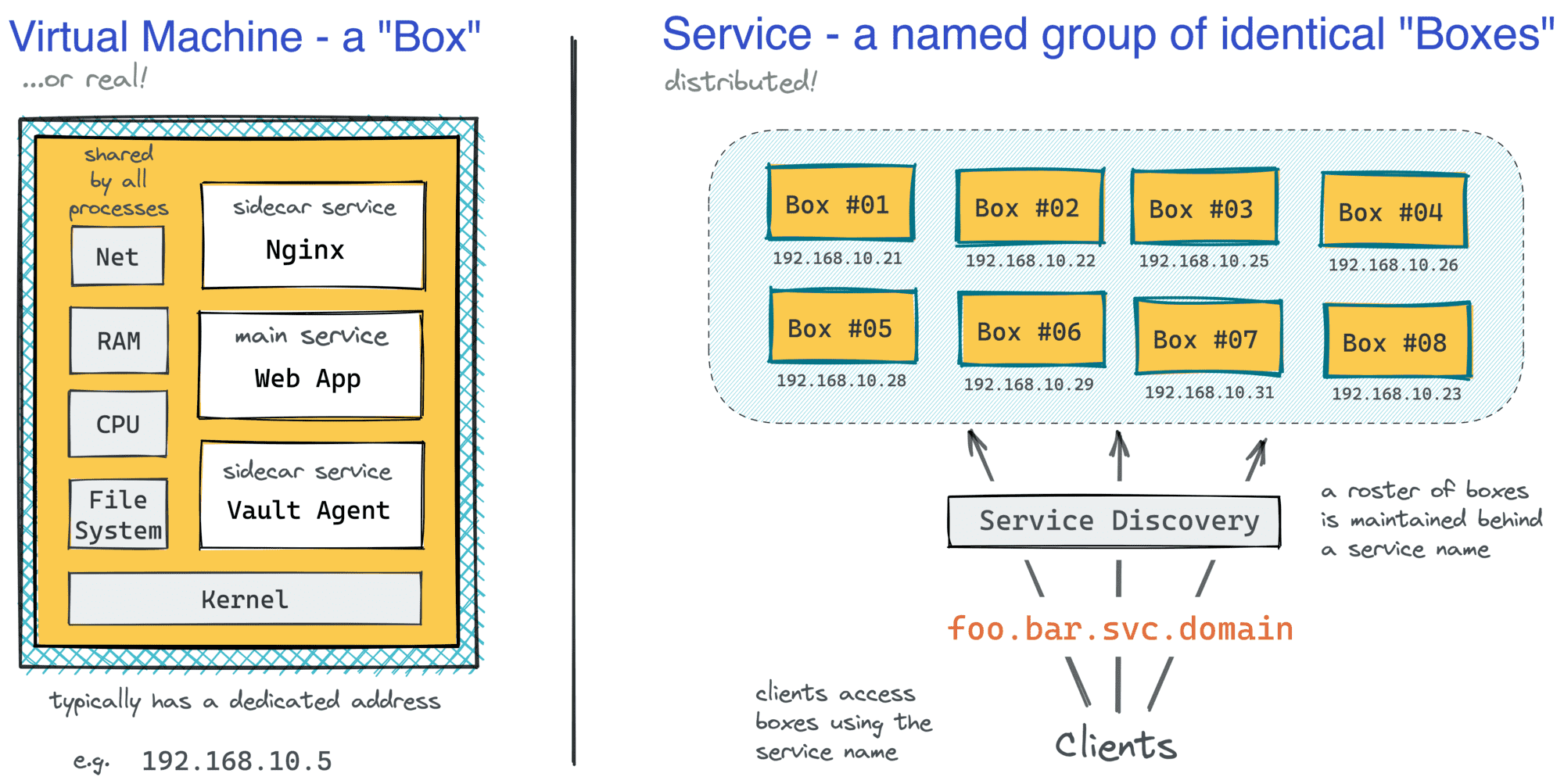
服务抽象将应用的复杂性隐藏在单一的入口后面。
使用虚拟机部署服务的挑战
通常情况下,机器群的规模决定了如何实现资源供应(安装OS和包)、扩展(生成相同的box)、服务发现(将box池隐藏的一个共同的名字后面)和部署(将新版本的代码交付到box中)。
如果你是小规模公司,可能只有几个类似宠物的box(在本文中,宠物和牲畜分别对应单词pet和cattle,按照Randy Bias的定义,宠物指的是需要仔细照料,不能停机的服务器,而牲畜指的是基于自动化服务器构建的多台服务器,它们为可能出现的故障进行了专门的设计,可以被安全地取代。——译者注),你会发现自己很少会供应新的box,而且都是半手工完成的。这通常意味着巴士系数较低(由于缺少自动化)(巴士系数,bus factor,指的是团队中有多少人被巴士撞到,才会导致项目无法正常正常运行下去——译者注)、安全态势差(由于缺乏定期打补丁的机制)以及更长的灾难恢复时间。从好的方面来看,这样的管理成本会比较低,因为不需要扩展,部署会很容易(只需要几个box就能交付代码)并且服务发现会非常简单(由于地址池是相对静态的)。
对于具有大量box的公司来说,情况会有所不同。大量的机器通常会导致更频繁地供应新的box(更多的box意味着更多的损坏)。我们需要在自动化方面进行投资(投资回报率会非常高)并且最终会形成众多像牲畜一样的box。随着box不断被重新创建,一个因此带来的副作用就是提升巴士系数(至少脚本不会被巴士撞到)并提升安全态势(将会自动进行更新和打补丁)。而糟糕的一面在于,低效的扩展(由于每天/每年的流量分布并不均匀),过于复杂的部署(快速向数量众多的box交付代码会非常困难)以及脆弱的服务发现(你试过运行大规模的consul或zookeeper吗),这都会带来更高的运维成本。
早期的云产品,如亚马逊云科技的Elastic Compute Cloud(EC2),能够更快地启动(和关闭)机器;使用packer制作机器镜像并使用cloud-init进行自定义将会使机器的供应更简便一些;像puppet和ansible这样的自动化工具可以大规模地进行基础设施变更并交付软件的新版本。但是,仍有很多需要改进的空间。
Docker容器解决了什么问题
过去,生产和开发使用不同的环境是很常见的。这就导致了这样一种情况,应用可能在本地的Debian机器上正常运行,但是由于缺少某个依赖项,在生成环境的vanilla CentOS上将无法启动。相反,你可能在本地安装依赖时困难重重,但是由于资源要求很高,在开发时使用预先供应的虚拟机则是不现实的。
即使在生产环境中,大量使用虚拟机也会带来问题。每个服务都要求使用一个虚拟机可能会导致无法达到最佳的资源使用率,以及相当大的存储和计算开销,但是将多个服务放到同一个box里面又会导致冲突。动辄花费几分钟的启动时间也需要改进。
我们的世界显然需要一个更轻量级的box。
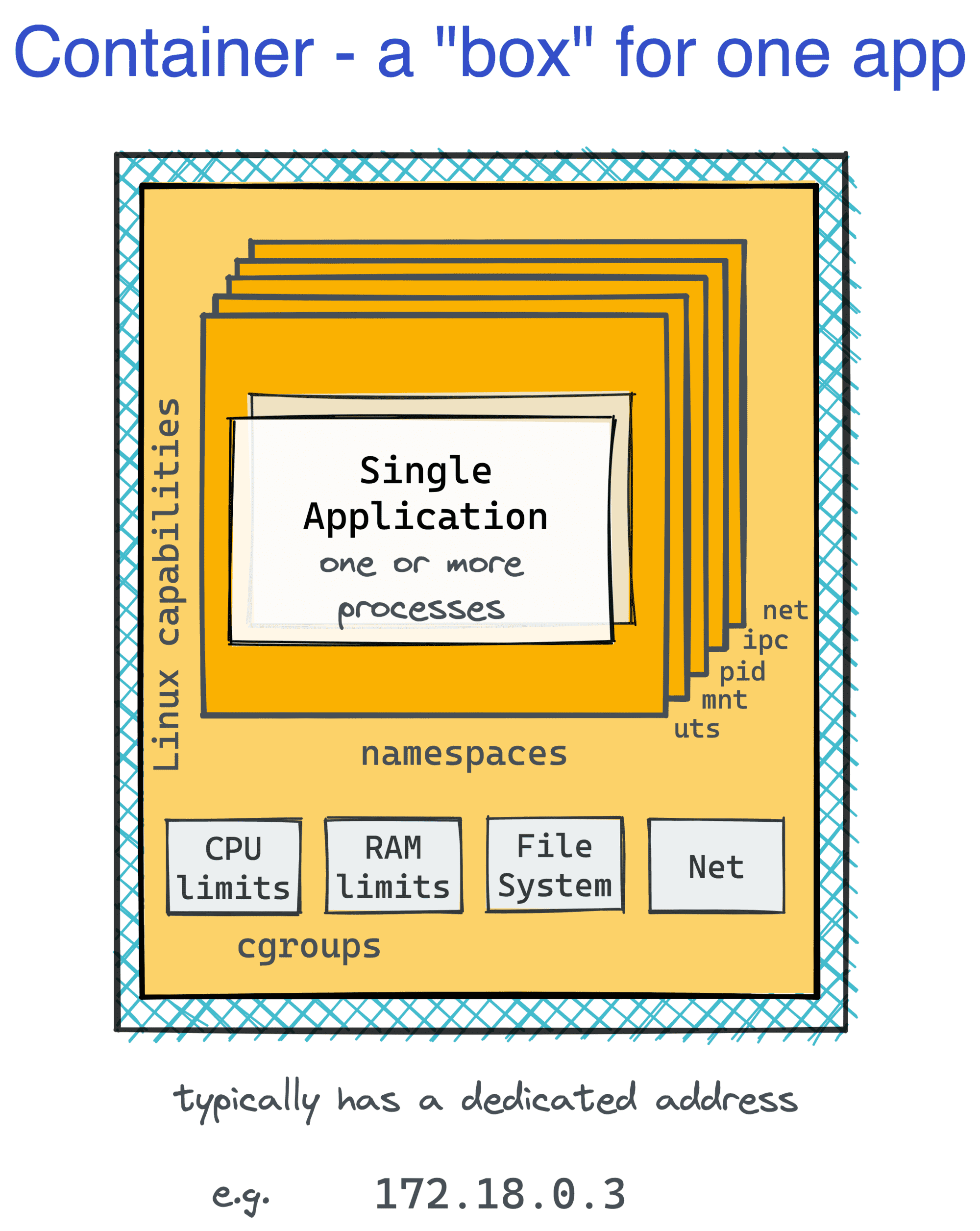
这就是容器出现的原因。就像虚拟机允许将一台裸机服务器切成几个更小(更便宜)的机器一样,容器能够将一个Linux的box分成几十个甚至几百个独立的环境。
在容器中,你可能会觉得你有一个专属于自己的虚拟机,这里有你最喜欢的Linux发行版。好吧,至少在第一眼看到的时候是这样。但从外面看,容器只是在主机操作系统上运行的普通进程,并共享其内核。
👉延伸阅读:并非每个容器内部都有一个操作系统。
将应用与其所有的依赖关系打包(包括特定版本的操作系统用户空间和库),将其作为容器镜像进行交付,并在安装了Docker(或类似的容器运行时)的机器上在标准化的执行环境中运行,上述这些能力都大大改善了工作负载的可重复性。
由于容器边界的实现是轻量级的,所以计算开销会大大减少,一台生产环境的服务器能够运行几十个属于多个(微)服务的不同容器。当然,这是以降低安全性为代价的。
借助不可变性以及共享的镜像层,镜像的存储和分发也变得更加高效。
👉 延伸阅读:要运行容器并不需要镜像。
在某种程度上,容器也改变了资源供应的方式。有了Dockerfiles以及像ko和Jib这样的工具,责任大大转移到了开发者身上,简化了对生产环境虚拟机的要求。从开发者的角度来看,你只需要一个兼容Docker(或者后来的OCI)的运行时来运行应用即可,不需要再去麻烦系统管理员帮忙安装特定版本的Linux或系统包。
除此之外,容器加速了其他运行服务的方式的发展。现在有17种方法可以在AWS上运行容器,其中大部分是完全Serverless的,在足够简单的情况下,你可以直接使用Lambda或Fargate,从牲畜类型的box中受益。
容器没有解决哪些问题
事实证明,容器是一个相当方便的开发工具。构建容器镜像也比构建虚拟机更简单、更迅速。在加上如何在团队间高效划分责任的这一古老的组织问题,这导致了典型企业所拥有的平均服务数量大幅增加,每个服务对应的box数量也随之大幅增加。
但对于没有搭上AWS Fargate/Lambda快车的人来说,容器使扩展、服务发现和部署变得更加复杂了。
由Docker推广开来的容器形式实际上是很具有欺骗性的。乍看上去,你可能会觉得服务的每个实例都有一个很便宜的专用虚拟机。然而,如果这样的实例需要sidecar(比如,在web应用前面运行本地反向代理以终止TLS连接,或者使用一个加密secret和/或预热缓存的守护程序),你立刻就会感受到容器与虚拟机的区别。
按照专门的设计,Docker容器只应该包含一个应用。我们面临的情况就会是这样的,一个容器用于Nginx,一个容器用于Python web服务器,还用一个容器用于守护程序。容器的生命周期将与该应用的生命周期绑定。而且,强烈不建议运行像systemd这样的初始进程作为最高级别的入口点。
因此,要重新创建本文开头图中的VM-box,我们至少需要有三个互相协作的container-box和一个共享的网络栈(好吧,至少localhost需要相同)。如果要运行两个服务实例,我们就需要6个容器,分成两组,每组3个!
从扩展的角度来看,这意味着我们需要同时扩展(和收缩)一批容器。部署也需要同步进行。新版本的web应用容器开始可能会使用一个新的端口号,并与旧版本的反向代理容器不兼容。
显然,在这里我们漏掉了一个抽象,它可以像容器一样轻量级,但又像原来的虚拟机box一样富有表现力。
此外,容器本身也没有提供任何方式将box分组为服务。但是,他们带来了box数量的增加。Docker本想通过其Swarm产品来解决这些问题,但是另外一个系统赢得了这场竞争的胜利。
Kubernetes解决了所有的问题吗?
Kubernetes的设计者没有发明新的方法来运行容器,而是决定重新创建良好的、基于虚拟机的服务架构,只不过使用容器作为构建基块。至少,我是这么认为的。
当然,对我来说,作为一个曾经有虚拟机经验的人,只要掌握新的术语并弄清楚类似的概念,就会发现Kubernetes最初的很多想法看起来似曾相识。
Kubernetes Pod是新的虚拟机
让我们从Pod的抽象开始。Pod是在Kubernetes中运行的最小单元。最简单的Pod定义如下。
apiVersion: v1kind: Podmetadata:name: nginxspec:containers:- name: nginximage: nginx:1.20.1ports:- containerPort: 80
乍看上去,上面的清单只是说明要运行什么镜像(以及如何命名)。但是请注意,containers属性是一个列表。现在,回到nginx+web app的样例中,在Kubernetes中,我们可以简单地将反向代理和应用本身放在一个box里,而不是为web应用容器运行一个额外的Pod。
apiVersion: v1kind: Podmetadata:name: foo-instance-1spec:containers:- name: nginx # <-- sidecar containerimage: nginx:1.20.1ports:- containerPort: 80- name: app # <-- main containerimage: app:0.3.2
然而,Pod并不只是容器组。在Pod中,容器之间的隔离边界被削弱了。就像在虚拟机上运行的常规进程一样,Pod中的容器可以通过localhost或使用传统的IPC方式自由通信。同时,每个容器仍然有一个隔离的根文件系统,以保持将应用与它们的依赖打包在一起所带来的收益。对我来说,它看起来像是兼具虚拟机和容器的最佳特性。
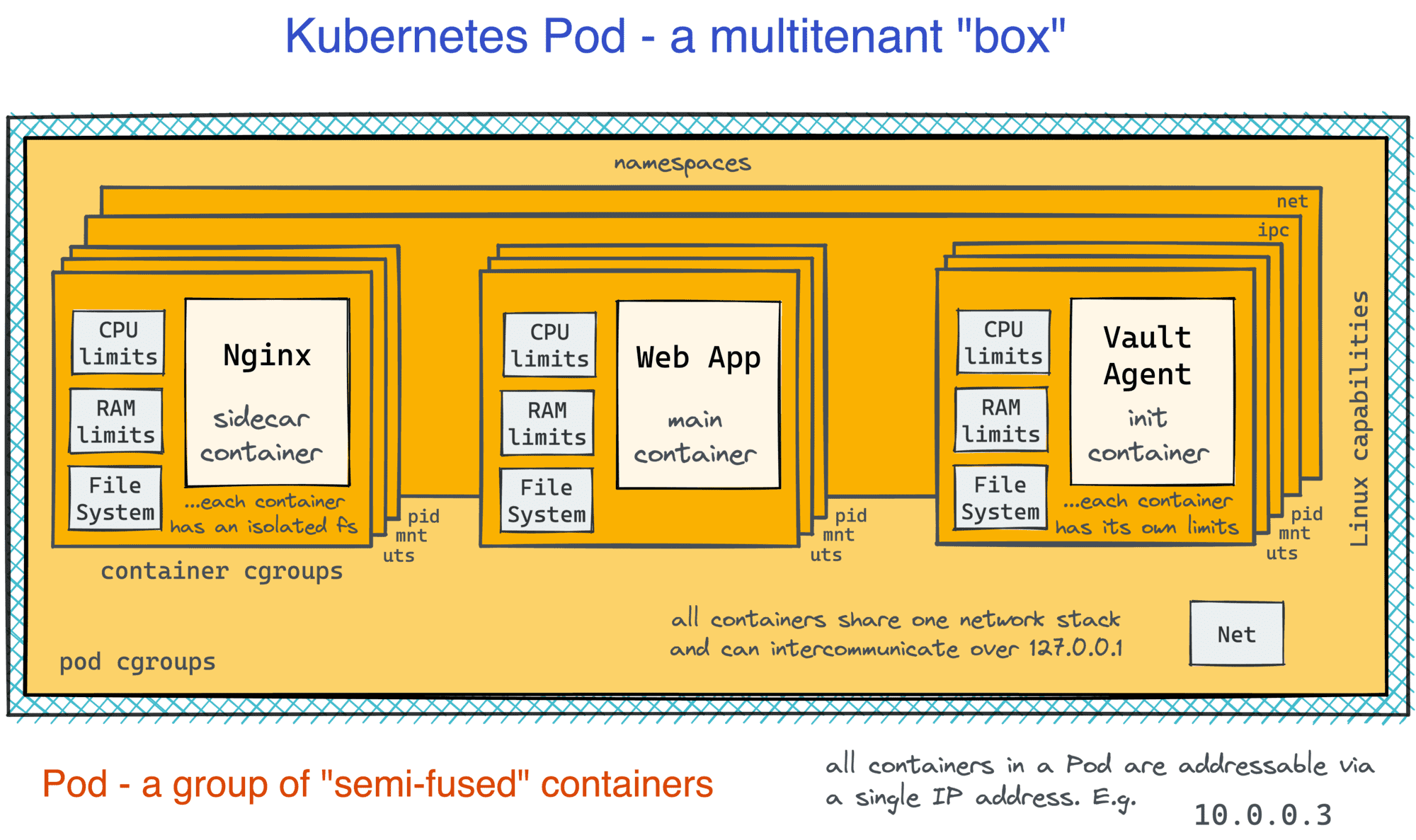
👉延伸阅读:深入了解容器与Pod。
Pod的扩展和部署非常简单
现在,我们得到了新的box,那么怎样才能运行多个box来组成一个服务呢?换句话说,如何在Kubernetes中进行扩展和部署?
事实证明,这很简单,至少在基本场景下是这样的。Kubernetes引入了一个很便利的抽象,叫做Deployment。一个最小的Deployment定义由名称和Pod模板组成,但指定所需的Pod副本数量也是很常见的。
apiVersion: apps/v1kind: Deploymentmetadata:name: foo-deployment-1labels:app: foospec:replicas: 10selector:matchLabels:app: footemplate:metadata:labels:app: foospec:<...Pod definition comes here>
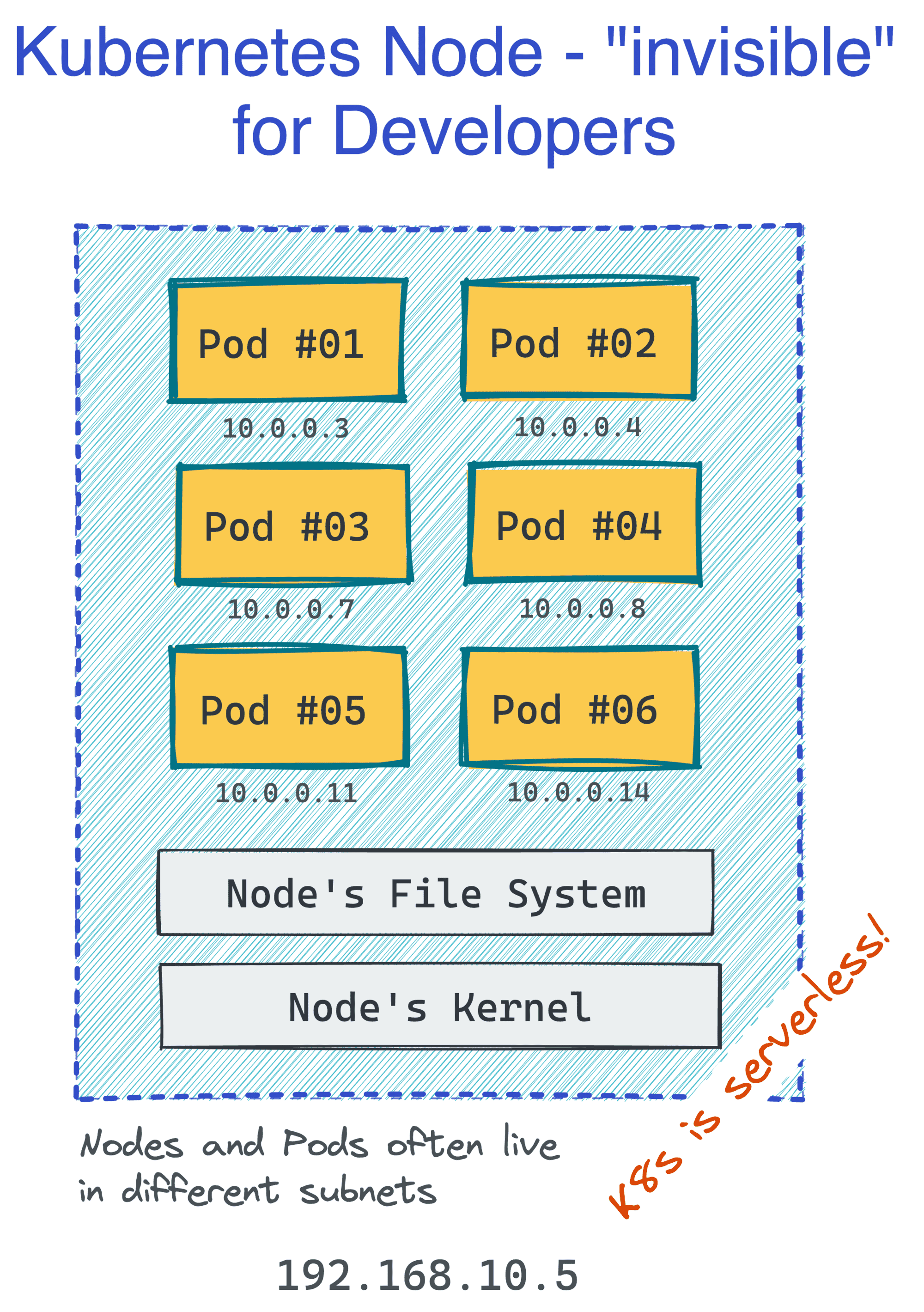
Kubernetes最棒的地方在于,作为一个开发人员,我们并不需要关心服务器(或Kubernetes术语中的Node)。我们只需以Pod组为单位进行思考和运维即可,它们会自动分布(和重新分布)到集群的Node上。
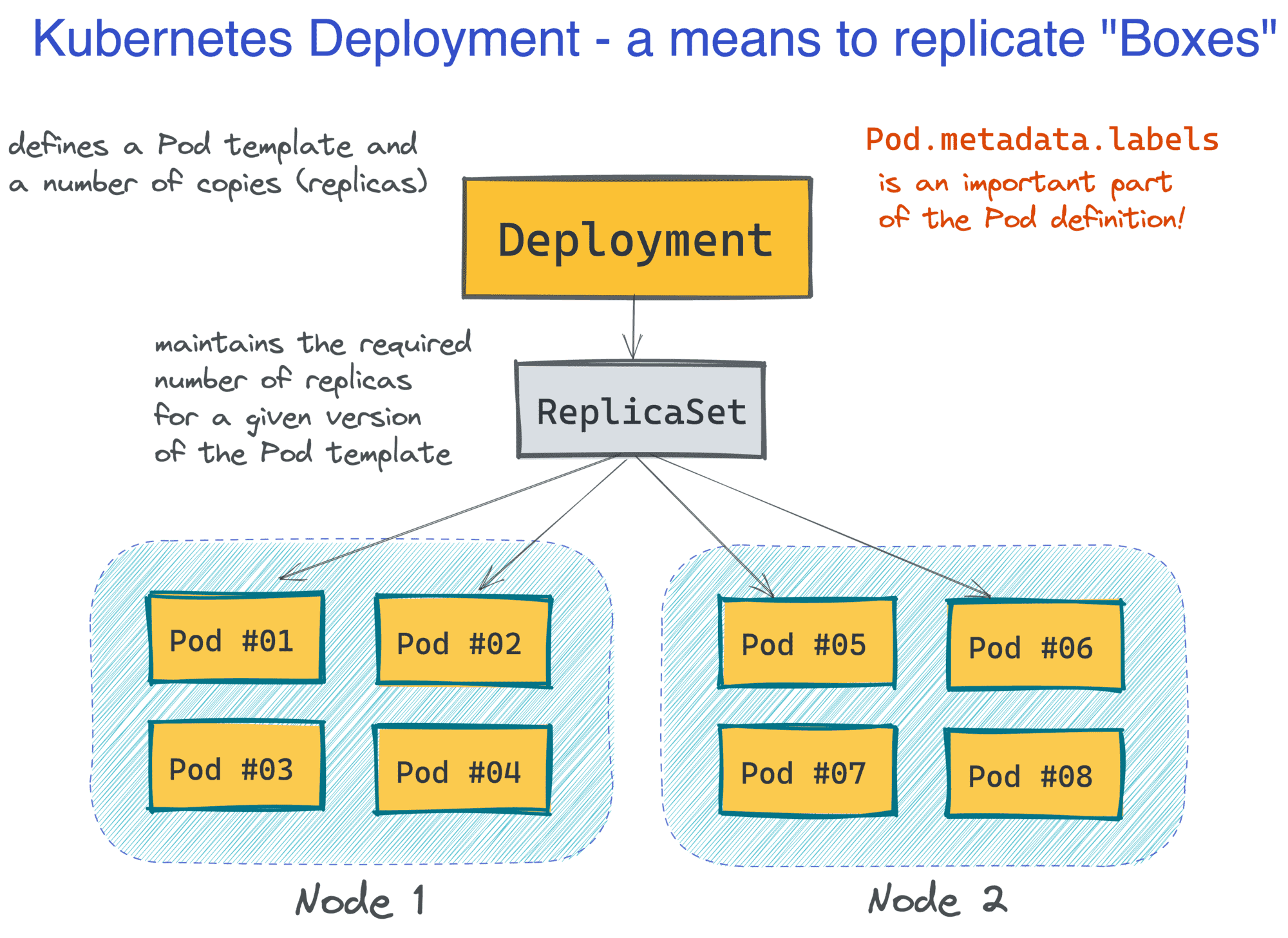
这使得Kubernetes成为一项Serverless的技术。但同时,Pod的外观和行为很像过去我们熟悉的虚拟机(只不过我们不需要管理它们),所以你可以用熟悉的抽象来设计和构建应用。
内置的服务发现
Kubernetes的设计者肯定知道,仅仅生成box的N个副本并称其为服务是远远不够的。客户端应该能够使用一个名字(可能逻辑名称)来访问服务,而服务发现系统应该能够将这个名称转换成某个IP地址(不管是在box上设置的负载均衡器还是服务的具体实例)。
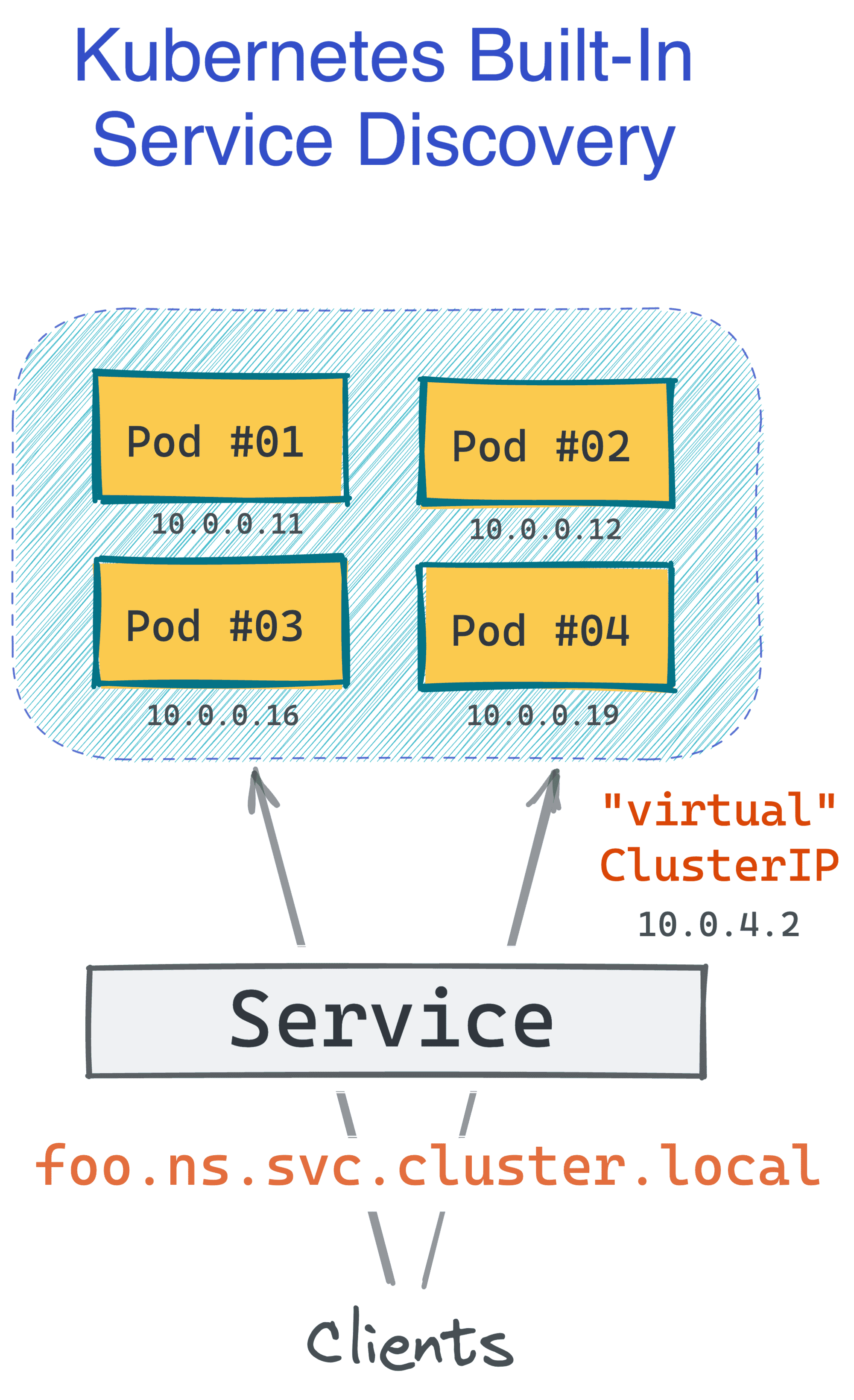
过去,我们需要一个单独的(而且是要求相当高的)解决方案来实现这一点。然而,Kubernetes已经内置了这一功能,而且默认的实现方式很不错。它还支持使用Linkerd或Istio这样的服务网格来进行扩展,使其更加强大。
👉延伸阅读:Kubernetes中的服务发现
要把一组Pod变成一个服务,唯一需要做的就是创建一个Service对象。
下面是一个简单的Kubernetes Service定义。
apiVersion: v1kind: Servicemetadata:name: foospec:selector:app: fooports:- protocol: TCPport: 80
上述清单允许使用DNS名称(如foo.default.svc.cluster.local)访问任何标记为app=foo的Pod(且在default命名空间运行)。而这一切都不需要在集群中安装任何额外的软件!
请注意,Service定义中没有在任何地方提到Deployment。和Deployment本身一样,它以Pod和标签的形式运作,这使它变得相当强大 例如,在Kubernetes中,蓝/绿或金丝雀部署可以通过让两个Deployment对象运行不同版本的应用镜像来实现,我们只需在一个Service后面选择具有相同标签的Pod即可。
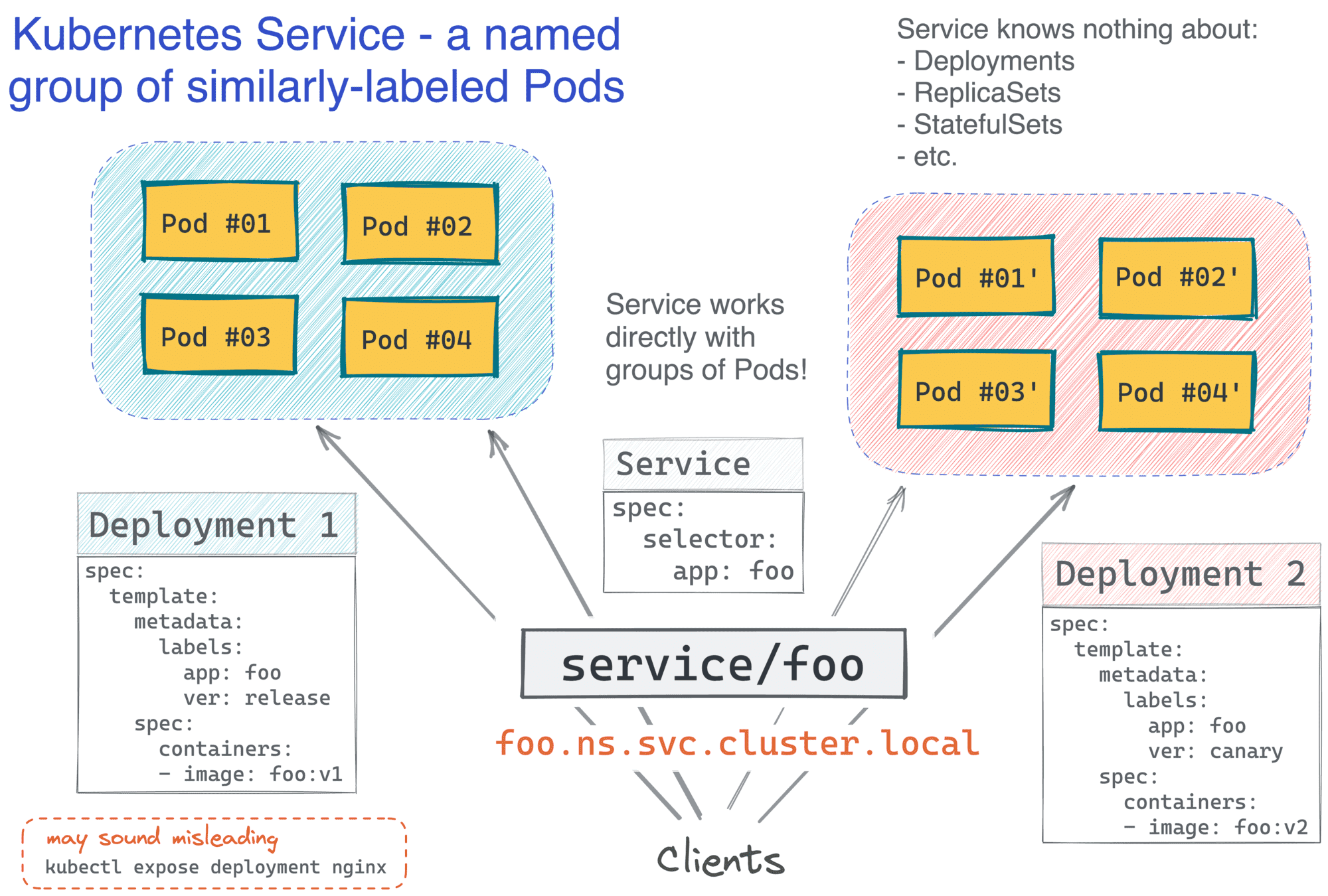
现在,最有趣的部分在于,你是否注意到Kubernetes服务与我们以前基于虚拟机的服务并没有太大的区别?我敢肯定,这是有意为之的,以利用现有的知识体系,而且整个行业都具有这样的知识体系。
Kubernetes即服务
那么,是不是可以说Kubernetes就像虚拟机一样,但它更简单?嗯,并不全是。借用Kelsey Hightower的话来说,我们应该区分驾驶汽车的复杂性和维修汽车的复杂性。我们很多人都会开车,但很少有人擅长修理发动机。幸运的是,会有专门的店铺来做这件事。这同样适用于Kubernetes。
如果你使用EKS或GKE这样的托管Kubernetes产品来运行服务的话,确实非常类似,但比使用虚拟机要简单得多。但是,如果你需要维护Kubernetes集群背后的实际服务器,那就完全是另外一回事了。
总结
容器试图改善在虚拟机上运行服务的体验,它改变了我们打包软件的方式,大大降低了对服务器配置的要求,并实现了部署工作负载的替代方案。容器本身并没有成为大规模运行服务的解决方案,在它上面仍然需要一层额外的编排。
Kubernetes作为容器原生的编排系统之一,使用容器作为基本构件,重新创建了我们过去熟悉的架构模式。Kubernetes还通过提供内置的扩展、部署和服务发现等手段,解决了系统中的一些边缘问题。如果你现在使用Kubernetes,那基本上依靠的还是在虚拟机作为主流的时代所使用的相同抽象(实例和服务)。
