@levinzhang
2022-09-18T14:29:30.000000Z
字数 5730
阅读 1224
Kubernetes的未来
摘要
随着Kubernetes的流行,其传统的开发和运维模式也暴露除了一些问题。作者以开发人员的视角,讨论了Kubernetes在安全性、网络、存储等方面的发展趋势。
本文最初发表于eficode的博客站点,经原作者Michael Vittrup Larsen和eficode官方授权,由InfoQ中文站翻译分享。
Kubernetes在容器编排中无处不在,其受欢迎的程度依然没有减弱。但是,这并不意味着容器编排领域的演进处于停滞状态。本文将会提出一些观点,那就是为什么Kubernetes的用户,尤其是开发人员,应该超越我们过去几年里学习的传统Kubernetes,转而采用更适合云原生应用的范式。
Kubernetes的兴起
Kubernetes变得如此流行的原因之一就是它构建在Docker之上。在Linux和BSD变种中,容器有着很悠久的历史,然而,Docker通过专注用户体验,使容器的构建和运行变得非常容易,从而使容器变得流行了起来。Kubernetes建立在容器流行的基础之上,使得在计算机节点组成的集群上运行(又叫编排)容器变得非常容易。
Kubernetes流行和广泛采用的另外一个原因是它并没有过多改变软件运行的模式。从Kubernetes出现之前运行软件的方式到基于Kubernetes运行软件之间,设想一条发展路径是非常容易的。
我们无法教老范式学习新的技巧
构建容器镜像以冻结依赖,提供“到处可运行”的体验,再结合Kubernetes Deployment资源规范来管理容器副本的编排,这一套实践的功能是非常强大的。但是,它与我们在Docker和Kubernetes出现之前,操作虚拟机的方式并没有根本性的差异。这个很小的思维转变使我们很容易就能使用Kubernetes,这也是为何我们应该超越目前“传统”Kubernetes的原因。
本文将会从开发人员的角度展望Kubernetes的未来。概括来讲,我们现在熟知的Kubernetes将会消失,而开发人员并不会在意。这并不是说,Kubernetes不会出现在我们的技术栈中,而是我们会使用新的抽象来改善构建和运维应用的方式,这些新的抽象本身就是构建在Kubernetes之上的。应用会使用平台来构建,平台则基于Kubernetes来构建:

有意思的是,在十多年以前,Linux是我们构建一切的平台。Linux依然无处不在,是我们技术栈的一部分,但是很少有开发人员关注它,因为我们基于它添加了一些抽象。我们今天所熟知的传统Kubernetes也会面临这样的情况。
横扫一切的新范式
安全性:OIDC要优于Secret
Kubernetes提供了Secret资源来声明静态的secret,比如API秘钥、密码等。开发人员不应该再使用Secret资源了。
在Secret资源中,简单编码的secret可能会被泄露,而且密码的轮换和撤销也很困难。在GitOps工作流中,secret也需要特别注意,避免明文存储。应用应该使用基于角色的方式来进行认证和授权。这意味着,应用程序的认证和授权应该基于“我们是谁”,而不是“你知道什么(密码、API秘钥)”来进行。
强大的身份标识是所有安全性的基础。如果你不确定与你通信的服务器的身份,那么对网络流量进行加密是没有意义的。这就是证书和证书授权机构对HTTPS流量所发挥的作用,它保证了互联网的安全。
Kubernetes有一个强大的工作负载身份系统。所有工作负载都与服务账户(service account)相关联,它们拥有Kubernetes颁发的短暂有效的OpenID-Connect(OIDC)身份token。Kubernetes API服务器签发这些OIDC token,而其他工作负载可以通过Kubernetes API服务器验证token。这为在Kubernetes上运行的工作负载提供了强大的身份识别功能,可以作为基于角色的认证和授权的基础。
开发人员不应再使用Kubernetes Secret,而应基于OIDC token构建认证和授权。这意味着,我们不应在Secret资源中存储数据库密码,而应该确保我们的数据库只在收到有效的、未过期的token时才接受请求。
使用OIDC token与外部系统集成的例子是AWS IAM用于服务账户的角色和Hashicorp Vault Kubernetes auth。
网络:Ingress并不合适
Kubernetes提供了一个Ingress资源,以指定如何将HTTP流量路由到工作负载中。正如Tim Hockin(Kubernetes联合创始人)所承认的那样,Ingress资源有很多问题。主要的问题是,它只允许我们管理HTTP流量路由中最基本的东西。对于基础设施和网站可靠性工程(SRE)团队来说,允许开发人员使用Ingress资源将是一个令人头疼的问题,他们需要将大量的基础设施互连,并确保它能可靠地运行。Ingress资源太简单了,开发人员不应该用它来配置网络。
从服务网格的兴起中,我们可以看到业界对Kubernetes网络有着更多控制和可编程性的需求。它们将Ingress资源划分为多个资源,以便于更好地分离职责,并在路由、可观测性、安全性和容错方面提供额外的功能。
越来越多建立在Kubernetes之上的抽象都假设有一个可编程的网络,这超出了Ingress所能提供的可能性(如Knative、Kubeflow,以及像Argo Rollouts这样的持续部署工具)。这凸显了在Kubernetes中更强大的网络模型已经是一个事实标准。
Kubernetes已经演进出了“Ingress v2” 网关-API。虽然这解决了Ingress的一些问题,但是它只涵盖了大部分服务网格所能支持的一小部分特性。
Kubernetes支持ACL,用于限制哪些工作负载可以通过NetworkPolicy资源进行通信。该资源在Kubernetes的网络插件中实现,通常会转化为Linux的iptables过滤规则,即基于IP地址的解决方案,很像防火墙,这也是一种古老的范式。一些服务网格扩展了Kubernetes强大的基于OIDC的工作负载身份标识,以实现工作负载之间的双向TLS。这基于比IP地址更强大的原则,为Kubernetes网络通信带来了保密性和真实性。
在Kubernetes应用打包时,在如何包含网络配置方面存在一些分歧。许多Helm charts都带有Ingress资源模板。然而,随着我们转向更高级的网络模型,这些定义将不能再使用。展望未来,像Helm charts这样的应用部署应该把网络配置看作是一个正交性的问题,不应该包含在应用部署制品(artifact)中。关于应用的网络配置,可能没有一个放之四海而皆准的解决方案,组织很可能希望开发自己的“应用路由”部署制品。
Kubernetes通过在集群中的所有节点上创建一个同质(homogeneous)的网络,使网络变得更加简单。如果你的应用是多集群或多云部署的,它可能同样受益于跨集群或云的同质网络。Kubernetes的网络模型并不能做到这一点,我们需要一些能力更强的方案,比如服务网格。
因此,从组织和架构的角度来看,有多个原因可以证明开发者不应该用Ingress资源对网络进行编程。必须以整体的组织视角来考虑这些方案,以确保以可管理和长期可行的方式进行网络配置和管理。
工作负载定义:新的模式
实际上,所有Kubernetes应用的核心都是Deployment资源。Deployment资源定义了我们的工作负载应该如何以Pod内容器的形式来执行。
Deployment的扩展可以通过HorizontalPodAutoscaler(HPA)资源来控制,以适应不同的容量需求。HPA通常使用容器的CPU负载作为增加或删除Pod的标准。由于HPA算法通常的目标利用率在70%左右,这意味着我们在设计时要浪费30%的资源。使用保守的目标利用率的另一个原因是,HPA经常需要一分钟或更长的响应时间才能开始工作。为了处理不同的容量需求,我们需要一些备用容量,与此同时HPA会增加更多的Pod。
如果我们的应用会经历缓慢变化的容量需求,用Deployments和HPA管理工作负载效果很好。然而,随着向微服务、事件驱动架构和函数(处理一个或多个事件/请求,然后终止)转变,这种形式的工作负载管理就不够理想了。
Kubernetes Event-Driven Autocaler(KEDA)可以改善微服务和快速变化的工作负载(如函数)的扩展行为。KEDA定义了一套自己的Kubernetes资源来定义扩展行为,可以视为“HPA v3”(因为HPA资源已经是“v2”版本了)。
有一个结合了Kubernetes Deployment模型、扩展以及事件和网络路由的框架,即Knative。 Knative是一个建立在Kubernetes之上的平台,通过Knative-Service资源对工作负载进行有针对性的管理。Knative的核心是CloudEvents,Knative服务基本上是由CloudEvents或普通HTTP请求等事件触发和扩展的函数。Knative使用Pod sidecar来监控事件发生率,因此在事件发生率变化时可以快速扩展。Knative还支持扩展到零(scaling to zero),因此允许更细粒度的工作负载扩展,更适合于微服务和函数。
Knative服务使用了传统的Kubernetes Deployment/Service,Knative服务的更新(例如,一个新的容器镜像)会创建并行的Kubernetes Deployment/Service资源。Knative利用这一点来实现蓝/绿和金丝雀部署模式,HTTP流量的路由是Knative服务资源定义的一部分。
因此,Knative服务资源及其定义事件路由的相关资源将成为开发者在Kubernetes上定义应用部署时所使用的主要资源。 就像我们今天经常通过Deployment资源与Kubernetes互动,让Kubernetes处理Pod一样,使用Knative意味着开发人员将主要关注Knative服务,而Deployment则由Knative平台处理。
虽然我希望Knative模型能适合大多数的使用场景,但你的场景可能会有所不同。如果你是做机器学习的,那么Kubeflow可能是更好的抽象。如果你更专注于DevOps和交付流水线,那么kpack、Tekton或Cartographer可能是适合你的抽象形式。无论你在Kubernetes上做什么,都有相应的抽象。
存储:远离持久化卷
Kubernetes提供了PersistentVolume和PersistentVolumeClaim资源来管理工作负载的存储问题。这可能是我最不喜欢的资源了,除了短暂的缓存数据外,它允许开发人员将其用于任何目的。
从高层次的角度来看,PersistentVolume(PV)的问题在于,它将应用程序的主要关注点与存储问题结合在了一起,这不是一个理想的云原生设计模式。12-factors应用方法论告诉我们要将所有支撑服务视为网络附加资源。这要归因于我们在Kubernetes中水平扩展工作负载和管理数据的方式(请想一下CAP理论)。
PV代表了文件和目录的文件系统,我们用POSIX文件系统接口对数据进行操作。访问权限也是基于POSIX模型的,允许通过用户和组进行读/写访问控制。这种模式不仅与云原生应用的设计不匹配,而且在实际使用中也有很多的问题,这意味着大多数情况下,PV是以“容器可以访问所有数据”的模式mount的。
开发人员构建的有状态应用其实应该是无状态的。这意味着数据应该在应用外部进行处理,使用除文件系统外的其他抽象形式,如数据库或对象存储。数据库和对象存储应用可以使用PV来满足其存储需求,但这些系统应该由基础设施/SRE团队来管理,并由开发人员以服务的形式进行消费。
当我们将存储视为网络附加资源时,数据安全问题就可能得到极大的改善,例如,我们可以考虑通过REST API进行对象存储。借助REST API的形式,我们就可以通过上述基于Kubernetes工作负载身份标识的短期访问token实现认证和授权。
随着Serverless工作负载模式的不断采用,我们应该预期出现更多的动态和更短生命周期的工作负载(例如,Serverless函数处理每个Pod的一个事件)。在这种情况下,工作负载和“老式磁盘”之间的不匹配变得更加明显。
在Kubernetes中,容器存储接口(container storage interface,CSI)一直是通过PV向工作负载添加文件系统和块存储的接口。Kubernetes对象存储特别兴趣小组正在研究容器对象存储接口(COSI),这可能会使对象存储成为Kubernetes中的一等公民。
美好的新世界
在本文中,我认为在定义Kubernetes应用时,有充分的理由超越“传统”的Kubernetes资源。这并不是说,我们永远都不会使用传统的资源类型。仍然会有一些我们无法轻易转换的遗留应用,SRE团队可能仍然需要运行有状态的服务,这些服务会被开发人员构建的应用所消费。对于私有云基础设施来说,情况更是如此。
Kubernetes的未来在于自定义资源定义(custom resource definition,CRD)和抽象,我们会在Kubernetes之上构建它们,并通过CRD提供给用户。Kubernetes会成为抽象的控制平面,而开发人员应该关注的正是这些抽象的CRD。Kubernetes控制平面可以管理Kubernetes内部的资源,甚至是Kubernetes外部的资源,例如Crossplane管理云基础设施。
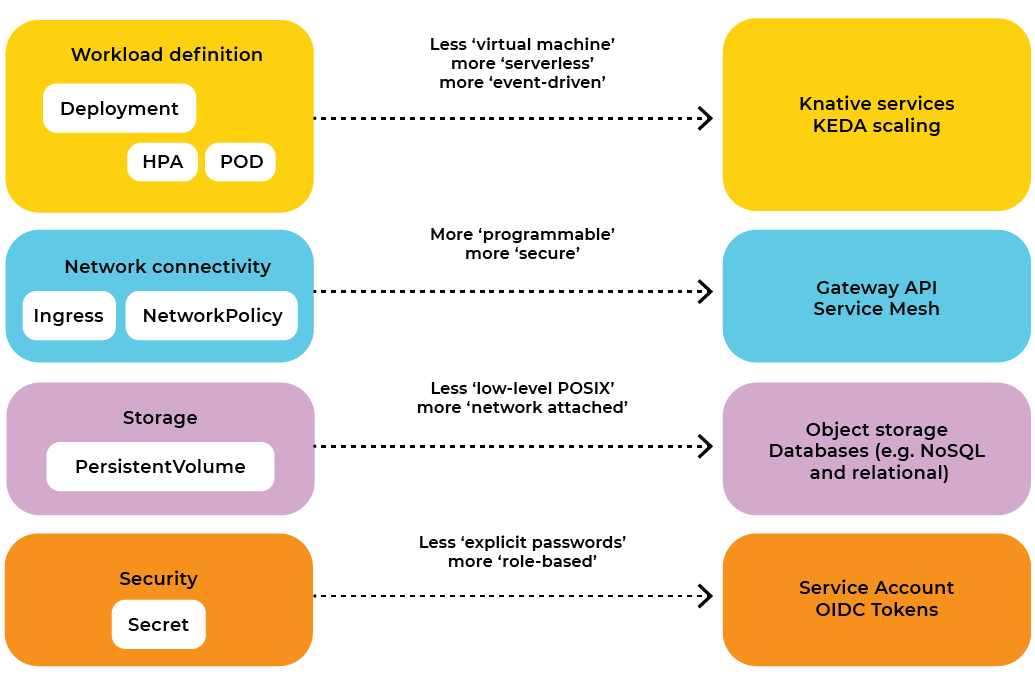
正如上面所总结的,大多数传统的Kubernetes资源对开发人员来说可能有更好的替代方案。使用这些替代方案将改善我们在未来几年内开发和运维云原生应用程序的方式。毕竟,Kubernetes是一个构建平台的平台。它并不是终点!
