@levinzhang
2018-02-20T07:22:13.000000Z
字数 3442
阅读 1153
批处理ETL已经消亡,Apache Kafka才是数据处理的未来吗?
by
摘要:
在QCon旧金山2016会议上,Neha Narkhed做了“ETL已死,而实时流长存”的演讲,并讨论了企业级数据处理领域所面临的挑战。该演讲的核心前提是开源的Apache Kafka流处理平台能够提供灵活且统一的框架,支持数据转换和处理的现代需求。
核心要点
- 最近的一些数据发展趋势推动传统的批处理抽取-转换-加载(ETL)架构发生了巨大的变化:数据平台要在整个企业范围内运行;数据源的类型变得更多;流数据得到了普遍性增长
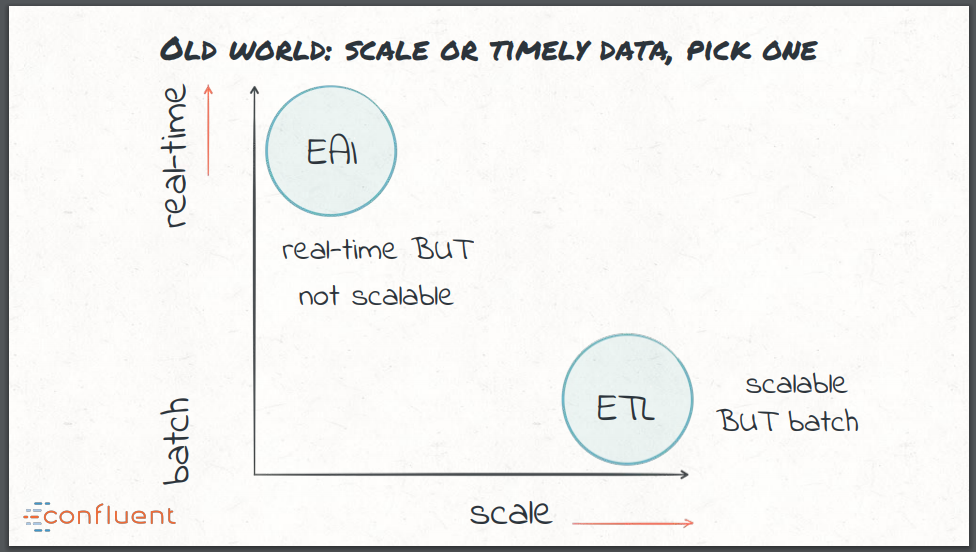
- 在实时ETL方面,早期采用的方式是企业应用集成(EAI),但是这里所用的技术通常是不可扩展的。这给传统的数据集成带来了两难的选择:实时但不可扩展,或者可扩展但采用的是批处理方案
- Apache Kafka是一个开源的流平台,它是七年前在LinkedIn开发的
- Kafka能够借助Kafka Connect API和Kafka Streams API构建从“source”到“sink”的流数据处理管道
- Log统一了批处理和流处理。log可以通过批处理的窗口(window)来消费,也可以在每个元素抵达时对其进行实时检查。
在QCon旧金山2016会议上,Neha Narkhede做了“ETL已死,而实时流长存”的演讲,并讨论了企业级数据处理领域所面临的挑战。该演讲的核心前提是开源的Apache Kafka流处理平台能够提供灵活且统一的框架,支持数据转换和处理的现代需求。
Narkhede是Confluent的联合创始人和CTO,在演讲中,他首先阐述了在过去的十年间,数据和数据系统的重要变化。该领域的传统功能包括提供联机事务处理(online transaction processing,OLTP)的操作性数据库以及提供在线分析处理(online analytical processing,OLAP)的关系型数据仓库。来自各种操作性数据库的数据会以批处理的方式加载到数据仓库的主模式中,批处理运行的周期可能是每天一次或两次。这种数据集成过程通常称为抽取-转换-加载(extract-transform-load,ETL)。
最近的一些数据发展趋势推动传统的ETL架构发生了巨大的变化:
- 单服务器的数据库正在被各种分布式数据平台所取代,这种平台在整个公司范围内运行;
- 除了事务性数据之外,现在有了类型更多的数据源,比如日志、传感器、指标数据等;
- 流数据得到了普遍性增长,在速度方面比每日的批处理有了更快的业务需求。
这些趋势所造成的后果就是传统的数据集成方式最终看起来像一团乱麻,比如组合自定义的转换脚本、使用企业级中间件如企业服务总线(ESB)和消息队列(MQ)以及像Hadoop这样的批处理技术。
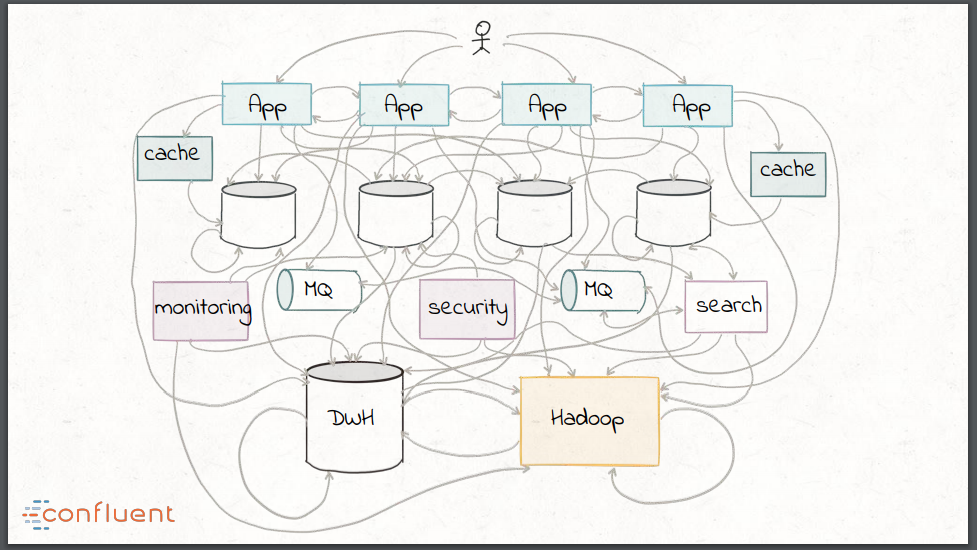
在探讨现代流处理技术如何缓解这些问题之前,Narkhede简要回顾了一下数据集成的历史。在上世纪90年代的零售行业中,业务得到了一些新形式的数据,所以对购买者行为趋势进行分析的需求迫切增长。存储在OLTP数据库中的操作性数据必须要进行抽取、转换为目标仓库模式,然后加载到中心数据仓库中。这项技术在过去二十年间不断成熟,但是数据仓库中的数据覆盖度依然相对非常低,这主要归因于ETL的如下缺点:
- 需要一个全局的模式;
- 数据的清洗和管理需要手工操作并且易于出错;
- ETL的操作成本很高:它通常很慢,并且是时间和资源密集型的;
- ETL所构建的范围非常有限,只关注于以批处理的方式连接数据库和数据仓库。
在实时ETL方面,早期采用的方式是企业应用集成(Enterprise application integration,EAI),并使用ESB和MQ实现数据集成。尽管这可以说是有效的实时处理,但这些技术通常很难广泛扩展。这给传统的数据集成带来了两难的选择:实时但不可扩展,或者可扩展但采用的是批处理方案。
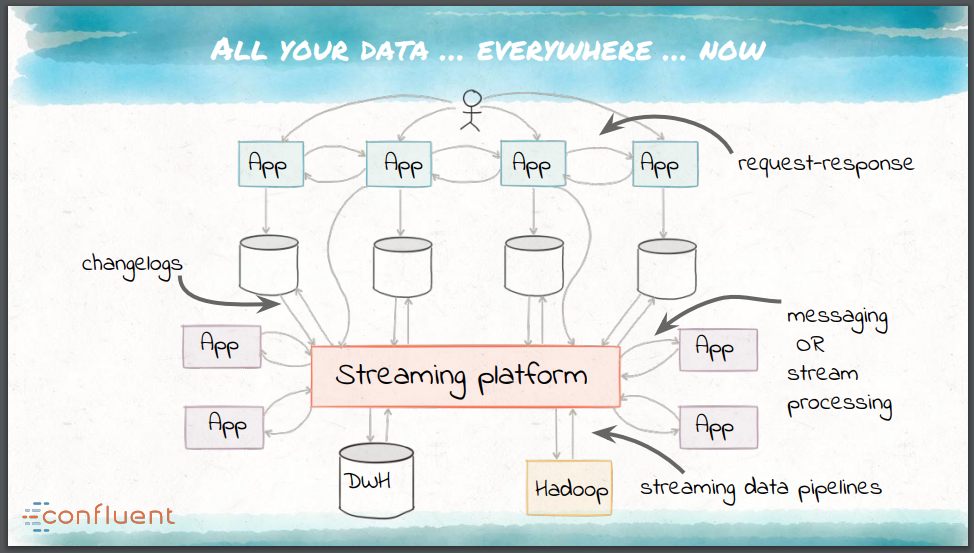
Narkhede指出现代流处理对数据集成有了新的需求:
- 能够处理大量且多样性的数据;
- 平台必须要从底层就支持实时处理,这会促进向以事件为中心的根本转变;
- 必须使用向前兼容的数据架构,必须能够支持添加新的应用,这些新的应用可能会以不同的方式来处理相同的数据。
这些需求推动一个统一数据集成平台的出现,而不是一系列专门定制的工具。这个平台必须拥抱现代架构和基础设施的基本理念、能够容错、能够并行、支持多种投递语义、提供有效的运维和监控并且允许进行模式管理。Apache Kafka是七年前由LinkedIn开发的,它就是这样的一个开源流平台,能够作为组织中数据的中枢神经系统来运行,方式如下:
- 作为应用的实时、可扩展消息总线,不需要EAI;
- 为所有的消息处理目的地提供现实状况来源的管道;
- 作为有状态流处理微服务的基础构建块。
Apache Kafka在LinkedIn目前每天处理14万亿条的消息,并且已经部署到了世界范围内成千上万的组织之中,包括财富500强的公司,如Cisco、Netflix、PayPal和Verizon。Kafka已经快速成为流数据的存储方案,并且为应用集成提供了一个可扩展的消息支撑(backbone),能够跨多个数据中心。
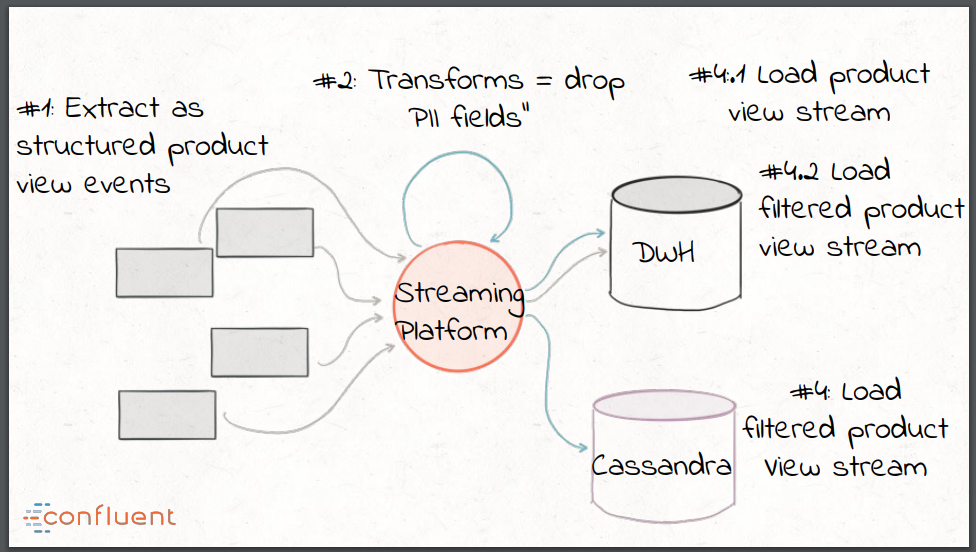
Kafka的基础是log的理念,log是只能往上追加(append),完全有序的数据结构。log本身采用了发布-订阅(publish-subscribe,pubsub)的语义,发布者能够非常容易地以不可变的形式往log上追加数据,订阅者可以维护自己的指针,以便指示当前正在处理的消息。
Kafka能够通过Kafka Connect API实现流数据管道的构建,也就是ETL中的E和L。Connect API利用了Kafka的可扩展性,基于Kafka的容错模型进行构建并且提供了一种统一的方式监控所有的连接器。流处理和转换可以通过Kafka Streams API来实现,这提供了ETL中的T。使用Kafka作为流处理平台能够消除为每个目标sink、数据存储或系统创建定制化(很可能是重复的)抽取、转换和加载组件的需求。来自source的数据经过抽取后可以作为结构化的事件放到平台中,然后可以通过流处理进行任意的转换。
在演讲的最后一部分,Narkhede详细讨论了流处理的概念,也就是流数据的转换,并且提出了两个相互对立的愿景:实时的MapReduce和事件驱动的微服务。实时的MapReduce适用于分析用例并且需要中心化的集群和自定义的打包、部署和监控。Apache Storm、Spark Streaming和Apache Flink实现了这种模式。Narkhede认为事件驱动微服务的方式(通过Kafka Streams API来实现)让任何用例都能访问流处理,这只需添加一个嵌入式库到Java应用中并搭建一个Kafka集群即可。
Kafka Streams API提供了一个便利的fluent DSL,具有像join、map、filter和window这样的操作符。

这是真正的每次一个事件(event-at-a-time)的流处理,没有任何微小的批处理,它使用数据流(dataflow)风格的窗口(window)方式,基于事件的时间来处理后续到达的数据。Kafka Streams内置了对本地状态的支持,并且支持快速的状态化和容错处理。它还支持流的重新处理,在更新应用、迁移数据或执行A/B测试的时候,这是非常有用的。
Narkhede总结说,log统一了批处理和流处理,log可以通过批处理的窗口方式进行消费,也能在每个元素抵达的时候进行检查以实现实时处理,Apache Kafka能够提供“ETL的崭新未来”。
Narkhede在旧金山QCon的完整视频可以在InfoQ上通过“ETL Is Dead; Long Live Streams”查看。
关于作者
 Daniel Bryant一直在组织内和技术方面引领变化。他目前的工作包括通过引入更好的需求收集和计划技术推进企业内部的敏捷性,关注于敏捷开发中的架构关联性,并搭建持续集成/交付环境。Daniel现在的技术专长是“DevOps”工具、云/容器平台和微服务实现。他还是伦敦Java社区(LJC)的领导者,参与多个开源项目,为InfoQ、DZone和Voxxed技术网站撰写文章,并且经常在QCon、JavaOne和Devoxx这样的国际会议上发表演讲。
Daniel Bryant一直在组织内和技术方面引领变化。他目前的工作包括通过引入更好的需求收集和计划技术推进企业内部的敏捷性,关注于敏捷开发中的架构关联性,并搭建持续集成/交付环境。Daniel现在的技术专长是“DevOps”工具、云/容器平台和微服务实现。他还是伦敦Java社区(LJC)的领导者,参与多个开源项目,为InfoQ、DZone和Voxxed技术网站撰写文章,并且经常在QCon、JavaOne和Devoxx这样的国际会议上发表演讲。
查看英文原文:Is Batch ETL Dead, and is Apache Kafka the Future of Data Processing?
