@heavysheep
2020-02-17T11:57:53.000000Z
字数 15454
阅读 1064
ms
未分类
系统
进程和线程
- 进程是操作系统资源分配的基本单位,而线程是任务调度和执行的基本单位
- 进程是线程的容器
- 进程的开销很大,线程开销相对小
- 系统能同时运行多个进程,一个进程在一个时刻是只有一个线程在运行
- 内存只会分配至进程,不会分配至线程
另外,线程的切换开销大约1500纳秒
协程
协程是一种用户态的轻量级线程,又称微线程。
协程拥有自己的寄存器上下文和栈,调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈。因此:协程能保留上一次调用时的状态(即所有局部状态的一个特定组合),每次过程重入时,就相当于进入上一次调用的状态,换种说法:进入上一次离开时所处逻辑流的位置。
优点:
1. 无需线程上下文切换的开销
2. 无需原子操作锁定及同步的开销
3. 方便切换控制流,简化编程模型
4. 高并发+高扩展性+低成本:一个CPU支持上万的协程都不是问题。所以很适合用于高并发处理。
缺点:
1. 无法利用多核资源:协程的本质是个单线程,它不能同时将单个CPU的多个核用上,协程需要和进程配合才能运行在多CPU上.
2. 进行阻塞(Blocking)操作(如IO时)会阻塞掉整个程序
import geventdef eat(name):print('%s eat 1' % name)gevent.sleep(2)print('%s eat 2' % name)def play(name):print('%s play 1' % name)gevent.sleep(1)print('%s play 2' % name)g1 = gevent.spawn(eat, 'egon')g2 = gevent.spawn(play, name='egon')g1.join()g2.join()# 或者gevent.joinall([g1,g2])print('主')
DOCKER
Docker 是一个开源的应用容器引擎,可以应用以及依赖包到一个轻量级、可移植的容器中,实现虚拟化沙箱环境。
优势
- 沙箱机制
- 容器性能开销极低
- 管理方便
架构
1.CAP
在一个分布式系统中,当涉及读写操作时,只能保证一致性(Consistence)、可用性(Availability)、分区容错性(Partition Tolerance)三者中的两个,另外一个必须被牺牲。
一致性:对某个指定的客户端来说,读操作保证能够返回最新的写操作结果。
可用性:非故障的节点在合理的时间内返回合理的响应(不是错误和超时的响应)。
分区容忍性:当出现网络分区后,系统能够继续“履行职责”。
在一个分布式系统中,由于分区容错一定要被保证,所以一般是CP架构和AP架构:
CP架构:保证一致性和分区容错性,牺牲部分可用性。(在不满足时报错)
AP架构:保证可用性和分区容错性,牺牲部分一致性。(在不满足时数据读写不一致)
2.配置中心
管理各个系统的配置。
3.注册中心(服务中心)
管理服务的运作和交互。
4.高性能
4.1读写分离
主要问题和解决方案:
复制延迟
- 写操作后的读操作由主机执行。
- 必须低延迟业务指向主机,允许高延迟业务指向从机。
分配机制
- 代码封装。
- 中间件封装
4.2数据分库
带来的问题:
- 无法join
- 无法使用事务
- 成本高
4.3数据分表
方法分为:
- 垂直分表
- 水平分表
存储高可用
存储集群分为两种:数据集中和数据分散
数据集中集群
主要是主机写,从机读,包括1主1从、1主1备,还是1主多备、1主多从。
难点
如何进行数据复制: 过多的数据复制通道增大主机压力,并造成备机数据不一致。
备机如何判断主机状态:不同备机的判断可能是不同的。
备机如何升级为主机:多备机时,备机集群如何升级为主机。
解决方式:zookeeper是ZAB算法解决。
数据分散集群
每台服务器都负责存储和备用一部分数据,典型以hadoop为主。
需要考虑
均衡性:服务器的数据分区基本是均衡的。
容错性:出现服务器故障时,算法需要将故障服务器的负载分配给其他服务器。
伸缩性:保障在新服务器的迁移。
数据分区
这里的数据分区是基于硬件故障考虑的数据分区。
需要考虑
数据量:保障可用性时,硬件能承载的数据量。
分区规则:例如地理位置等
复制规则:
集中式:有总的备份中心。设计简单,扩展容易,硬件成本高;
互备式:每个分区都备份另一分区内容。设计复杂,扩展繁琐,成本低。
独立式:各自分区建立各自的备份。设计简单,扩展容易,成本高
多数据库协调工具
MYSQL ROUTER
计算高可用
难点
- 哪些机器可以执行任务
- 任务如何重新执行
在这其中的设计中,必定存在一个任务分配器
常见架构
- 主备:主机执行所有运算任务,主机无法执行时需由人工执行切换。
- 主从:主机和从机各执行一部分任务,主机或从机无法执行时需由人工执行修复。
集群
由于主备和主从都需要人工手动处理切换和故障,因此衍生出了集群的概念。分为对称集群和非对称集群。
对称集群(负载均衡集群):
- 采取常规策略,均匀的分配至服务器(如轮询、随机)
- 某台故障时,不再分配至该台,直至该台服务器故障修复。
非对称集群
非对称集群指集群中服务器任务不同,典型的例如master/slave架构。
- 任务分别交于master和slave分散执行,
- master故障时,重新选举master;slave故障时,直接剔除slave
接口级故障的应对方式
产生原因
- 内部原因:BUG,慢查询,内存耗尽。
- 外部原因:黑客攻击,促销、抢购活动等。
应对思路
在无法迅速解决的情况下,主要思路围绕保障核心功能和保障大部分用户使用
降级:只保留核心功能,分为后门降级和独立降级两种。
熔断:当功能被其他功能拖慢时,停止其他功能的访问。
限流:保障部分用户或流程的完整使用,抛弃其他用户,分为资源限流、请求限流和排队限流。
高扩展服务
核心是进行拆分,拆分分为面向流程拆分,面向服务拆分,面向功能拆分。
负载均衡
网络层
DNS:主要针对地理位置进行负载均衡,但缓存久,不灵活。
内网级
Nginx:软件7层,5万/秒。
LVS:内核4层,10-80万/秒
F5:硬件5层,200-800万/秒
语言和工具的使用和理解
Python
高度抽象的动态强类型语言,学习容易,扩展库多,弊端是自带GIL,性能不高,越写越难。
tornado
单线程模型的异步非阻塞web框架库。跟其他的web框架相比,tornado是单线程的,并通过协程实现远超其他web框架的超高并发。tornado的使用是复杂的,业务中必须使用tornado特定的写法,并且不能使用导致阻塞的框架,开发和维护比较费力。
如何实现真正的高并发
- 全程使用tornado相关框架,例如tornado-mysql,tornadis,参考。
- 通过celery,分配任务至worker,不处理具体业务。
- 使用线程编程,但是会影响tornado主线程。
- 猴子补丁,更改阻塞的部分。
celery
broker
redis,rabbitMQ
交换模式
Direct Exchange:(全文匹配)直接交换,指定一个消息被谁接收。
Topic Exchange:(弱匹配)订阅交换,根据匹配规则,交由匹配的队列接受和执行。
Fanout Exchange:广播交换,一个消息生成多份,由所有队列执行。
监控
flower
Nginx
HTTP和反向代理服务器。在使用中主要完成负载均衡的作用。
Nginx为什么快
常规服务器的IO处理能力往往不高。Nginx有个好处是它会把Request在读取完整之前buffer住,这样交给后端的就是一个完整的HTTP请求,从而提高后端的效率,而不是断断续续的传递。同样,Nginx也可以把response给buffer住,同样也是减轻后端的压力。
举个栗子,餐厅门口挂个门铃(注册epoll模型的listen),一旦有客人(HTTP请求)到达,派一个服务员去接待(accept),之后服务员就去忙其他事情了(比如再去接待客人),等这位客人点好餐就叫服务员(数据到了read()),服务员过来拿走菜单到厨房(磁盘I/O),服务员又做其他事情去了,等厨房做好了菜也喊服务员(磁盘I/O结束),服务员再给客人上菜(send()),厨房做好一个菜就给客人上一个,中间服务员可以去干其他事情。整个过程被切分成很多个阶段,每个阶段都有相应的服务模块。
参数调优
worker进程
worker_processes:工作进程数量,和CPU设置相同即可。
worker_connections:每个进程连接数,全部 = 进程 * 连接,反向代理/4。默认1024,建议65536。
缓冲
防止nginx不停读写临时文件
client_body_buffer_size:允许客户端请求的最大单个文件字节数,建议10k。
client_header_buffer_size:用于设置客户端请求的Header头缓冲区大小,建议1k。
client_max_body_size:设置客户端能够上传的文件大小,默认为1m,建议8m。
超时
http {include mime.types;server_names_hash_bucket_size 512;default_type application/octet-stream;sendfile on;tcp_nodelay on;keepalive_timeout 65; # 用于设置客户端连接保持会话的超时时间。建议15秒。client_header_timeout 15; # 用于设置读取客户端请求头数据的超时时间,建议15秒。client_body_timeout 15; # 用于设置读取客户端请求主体数据的超时时间,建议15秒。send_timeout 25; # 用于指定响应客户端的超时时间,如果超过这个时间,客户端没有任何活动,Nginx 将会关闭连接。建议25秒include vhosts/*.conf;}
上传大小
http {client_max_body_size 8m; # 设置客户端最大的请求主体大小为 8 M}
gzip
http {gzip on; # 开启压缩功能gzip_min_length 1k; # 允许压缩的对象的最小字节gzip_buffers 4 32k; # 压缩缓冲区大小,表示申请4个单位为32k的内存作为压缩结果的缓存gzip_http_version 1.1; # 压缩版本,用于设置识别HTTP协议版本gzip_comp_level 2; # 压缩级别,1级压缩比最小但处理速度最快,9级压缩比最高但处理速度最慢gzip_types text/plain application/x-javascript text/css application/xml; # 允许压缩的媒体类型gzip_vary on; # 该选项可以让前端的缓存服务器缓存经过gzip压缩的页面,例如用代理服务器缓存经过Nginx压缩的数据}
静态文件缓存
server {location ~ .*\.(gif|jpg|jpeg|png|bmp|swf|js|css)$ # 缓存的对象{expires 365d; # 缓存期限为 1 年}}
负载均衡
upstream name {ip_hash; # 分配器算法,包括weight轮询(默认),ip_hash按IPhash结果分配server 192.168.1.100:8000;server 192.168.1.100:8001 down;server 192.168.1.100:8002 max_fails=3;server 192.168.1.100:8003 fail_timeout=20s;server 192.168.1.100:8004 max_fails=3 fail_timeout=20s;# 此外,可以设置负载均衡状态,包括:down,表示当前的server暂时不参与负载均衡。backup,预留的备份机器。当其他所有的非backup机器出现故障或者忙的时候,才会请求backup机器,因此这台机器的压力最轻。max_fails,允许请求失败的次数,默认为1。当超过最大次数时,返回proxy_next_upstream 模块定义的错误。fail_timeout,在经历了max_fails次失败后,暂停服务的时间。max_fails可以和fail_timeout一起使用。注意:当负载调度算法为ip_hash时,后端服务器在负载均衡调度中的状态不能是weight和backup。}
Zookeeper
kafka
一个基于zookeeper协调的分布式消息系统。
价值
如队列通常的意义:缓冲、解耦、冗余、异步
优势:
高吞吐率:即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输。
隔离:消息分区和分布式消费。
离线处理
水平扩展
和celery的区别
- kafka是消息队列,celery是任务队列
- kafka专注高吞吐量快速消息信息,celery主要处理耗时任务,支持任务重试、状态记录等比较完善
- kafka是推送消息,celery 的work主动从broker里获取数据
rabbitMQ
采用AMQP高级消息队列协议的一种消息队列技术,最大的特点就是消费并不需要确保提供方存在。
rabbitMQ面试题
工作模式
简单模式:一个生产者,一个消费者
work模式:一个生产者,多个消费者,每个消费者获取到的消息唯一。
订阅模式:一个生产者发送的消息会被多个消费者获取。
路由模式:发送消息到交换机并且要指定路由key ,消费者将队列绑定到交换机时需要指定路由key
topic模式:将路由键和某模式进行匹配,此时队列需要绑定在一个模式上,“#”匹配一个词或多个词,“*”只匹配一个词。
确认模式
发送方确认模式:一旦消息被投递到目的队列后,或者消息被写入磁盘后(可持久化的消息),信道会发送一个确认给生产者(包含消息唯一ID)。
接收方确认机制:消费者接收每一条消息后都必须进行确认。只有消费者确认了消息,RabbitMQ才能安全地把消息从队列中删除。
信道
一个TCP连接带有N个线程,每个线程是一个信道,每个信道都有一个唯一ID,确保信道私有性。
Elasticsearch
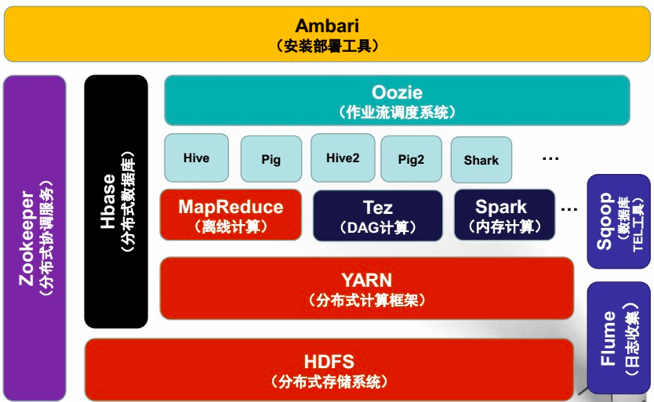
大数据相关
网络
HTTP
HTTP是超文本传输协议的缩写,是基于TCP/IP,是用于从万维网(WWW)服务器传输超文本到本地浏览器的传送协议。
几个特点:
无连接:限制每次连接只处理一个请求。
媒体独立:任何类型的数据都可以通过HTTP发送,只要客户端和服务器双方都知道如何处理此数据类型。
无状态:对任何事物没有上文的记忆能力。
http请求和响应由哪些部分组成
请求行:请求方法,url,http协议
请求头:
空行:分割
请求数据:body
rest api
- 每一个URI代表一种资源;
- 客户端和服务器之间,传递这种资源的某种表现层;
- 客户端通过四个HTTP动词,对服务器端资源进行操作,实现"表现层状态转化"。
浏览器从输入网址到显示出网页的全过程
浏览器补全/限制 -> 浏览器缓存 -> 系统缓存(hosts.txt) -> 路由缓存 -> dns缓存 -> 根域名服务器
三次握手四次挥手
第一次握手:客户端发送网络包,服务端收到了。这样服务端就能得出结论:客户端的发送能力、服务端的接收能力是正常的。
第二次握手:服务端发包,客户端收到了。这样客户端就能得出结论:服务端的接收、发送能力,客户端的接收、发送能力是正常的。不过此时服务器并不能确认客户端的接收能力是否正常。
第三次握手:客户端发包,服务端收到了。这样服务端就能得出结论:客户端的接收、发送能力正常,服务器自己的发送、接收能力也正常。因此,需要三次握手才能确认双方的接收与发送能力是否正常。
如果握手两次:如果先后有两次请求,第一次请求出于节点时长等意外原因滞留,第二次请求只经过两次握手就可建立连接,在连接结束后,第一次请求到达后,会被服务端误以为是一次新的链接,这样会浪费资源。
三次握手是否可以携带数据:前两次不可以,第三次可以。这是因为前两次如果带了数据容易被攻击。
为什么挥手四次:关闭需要双方同时关闭节约资源,因此需要双方共同二次确认。
IP协议将请求拆为多个数据包,经由不同线路到达指定IP,TCP协议保证包的顺序传输
TCP是如何保证包的顺序传输
- 发送包前,为每个包分配一个序列号;
- 同时为了保证数据包的可靠传递,发送方必须把已发送的数据包保留在缓冲区;
- 并为每个已发送的数据包启动一个超时定时器;
- 如在定时器超时之前收到了对方发来的应答信息(可能是对本包的应答,也可以是对本包后续包的应答),则释放该数据包占用的缓冲区;
- 否则,重传该数据包,直到收到应答或重传次数超过规定的最大次数为止。
- 接收方收到数据包后,先进行CRC校验,如果正确则把数据交给上层协议,然后给发送方发送一个累计应答包,表明该数据已收到,如果接收方正好也有数据要发给发送方,应答包也可方在数据包中捎带过去。
cookie和session的区别是什么
由于HTTP协议是无状态的协议,所以服务端需要记录用户的状态时,就需要用某种机制来识具体的用户
cookie存在本地的上的
session是存在服务器上的
python
元祖、列表、字典的底层实现
元祖:定长的指针数组,指向的内存地址不变即视为不变。
列表:在CPython中,由指向元素内容的的指针数组组成,申请的内存容量会稍大,避免频繁的内存分配。
字典:hash table,需要在遍历时,会找最大元素数次,所以频繁遍历应该创建一个新字典
元祖列表的区别
- 定长和不定长
- 可变和不可变
- 元祖有free_list,在频繁销毁使用的情况下更有性能优势
asyncio
定义
asyncio是一个使用协程构建并发应用的工具,asyncio的应用需要显示的处理上下文切换。
调用协程函数
函数前需要加async,调用时需要显示的await调用
不可显示的传参,如需传参,可以用function.partial封装
调用普通函数
call_soon:立即调用,首参是函数,后面可以跟函数的参数。
call_later:后续调用,首参是函数,第二参数是开始后几秒,后面可以跟函数的参数。
call_at:本质是call_later的底层,从持续第几秒开始,注意协程async内时间和普通时间不一致。
future
future表示还没有完成的工作结果。事件循环可以通过监视一个future对象的状态来指示它已经完成。future对象有几个状态:
pending:创建future对象后未运行
running:事件循环调用中
done:调用完毕
cancel:未完成被停止
task
task是封装的有状态的协程任务,是future的子类。task有两种等待方法
await: 等待所有任务完成,中途可以取消;对象是set,任务处理顺序是无序的。
gather:强制等待所有任务完成,任务处理顺序是有序的,结束时间取决于时间最长的任务。
import asyncioasync def num(n):try:await asyncio.sleep(n*0.1)return nexcept asyncio.CancelledError:print(f"数字{n}被取消")raiseasync def main():tasks = [num(i) for i in range(10)]complete, pending = await asyncio.wait(tasks, timeout=0.5)for i in complete:print("当前数字",i.result())if pending:print("取消未完成的任务")for p in pending:p.cancel()if __name__ == '__main__':loop = asyncio.get_event_loop()try:loop.run_until_complete(main())finally:loop.close()
协程生产消费模型
def consumer():while True:count = yieldprint("consuming count {}".format(count))def productor():for i in range(10):yield iprint("producing {}".format(i))if __name__ == '__main__':c = consumer()c.__next__()for i in productor():c.send(i)
和requests结合的爬虫
通过双层的get_event_loop()实现
import asyncioimport requestsasync def main():loop = asyncio.get_event_loop()future1 = loop.run_in_executor(None, requests.get, 'http://www.google.com')future2 = loop.run_in_executor(None, requests.get, 'http://www.google.co.uk')response1 = await future1response2 = await future2print(response1.text)print(response2.text)loop = asyncio.get_event_loop()loop.run_until_complete(main())
GIL
全局解释器锁,每个线程在执行时候都需要先获取GIL,保证同一时刻只有一个线程可以执行代码。
GIL是Cpython问题,导致了python在多线程切换中的效率非常低。
__slots__
Python用一个字典来保存一个对象的实例属性,它允许我们在运行时去设置任意的新属性。但对大量创建的类来说,使用字典会扩大内存占用空间。
而__slots__使用元组来保存对象属性,减小了内存使用空间
class MyClass(object):__slots__ = ['name', 'identifier']def __init__(self, name, identifier):self.name = nameself.identifier = identifierself.set_up()# ...
垃圾回收
python的垃圾回收机制是引用计数,每个对象都有个一个字段记录对象被引用的次数,一旦引用为0,该对象立刻被回收,释放内存。
为了应对循环引用问题,Python引入了标记-清除和分代回收两种GC机制,分为年轻、中年、老年三代,年轻对象满时,可回收的回收,不可回收的移至中年,以此类推。
示例方法、类方法和静态方法区别
实例方法
定义:第一个参数必须是实例对象,该参数名一般约定为“self”,通过它来传递实例的属性和方法(也可以传类的属性和方法);
调用:只能由实例对象调用。
类方法
定义:使用装饰器@classmethod。第一个参数必须是当前类对象,该参数名一般约定为“cls”,通过它来传递类的属性和方法(不能传实例的属性和方法);
调用:实例对象和类对象都可以调用。
静态方法
定义:使用装饰器@staticmethod。参数随意,没有“self”和“cls”参数,但是方法体中不能使用类或实例的任何属性和方法;
调用:实例对象和类对象都可以调用。
python不同对象时间算法复杂度
O(1) O(n) 和 O(k)
StringIO和BytesIO
是Python在内存中读写数据的模块,分别使用文本数据和二进制数据
__getattribute__和__getattr__
访问任何属性会先调用__getattribute__,没有找到对应的方法时,再调用__getattr__
可变和不可变对象
不可变对象
对象所指向的内存中的值不能被改变,当改变这个变量的时候,原来指向的内存中的值不变,变量不再指向原来的值,而是开辟一块新的内存,变量指向新的内存。
可变对象
对象指向的内存中的值会改变,当更改这个变量的时候,还是指向原来内存中的值,并且在原来的内存值进行原地修改,并没有开辟新的内存。
global和nonlocal的区别
global是全局变量,任何地方均可以访问,声明和访问都需要加关键字
nonlocal是嵌套变量,在python3中加入,只能使用
闭包变量迟绑定
因为Python解释器,遇到lambda(类似于def),只是定义了一个匿名函数对象,并保存在内存中,只有等到调用这个匿名函数的时候,才会运行内部的表达式。
filter,map,reduce
filter
x = [1,2,3,4,5]list(filter(lambda x:x%2==0,x)) # 找出偶数。python3.*之后filter函数返回的不再是列表而是迭代器,所以需要用list转换。# 输出:[2, 4]
map
x = [1,2,3,4,5]y = [2,3,4,5,6]list(map(lambda x,y:(x*y)+2,x,y))# 输出:[4, 8, 14, 22, 32]
reduce
from functools import reducey = [2,3,4,5,6]reduce(lambda x,y: x + y,y) # 直接返回一个值
MYSQL
语句顺序
where、group by、having、order by、limit
ACID
原子性、一致性、隔离性、永久性
单标数量最优值
1000万条左右
数据库
最佳表存储经验值:建议不超过1000个,常规大小200张表左右
库的意义:
- 分类表的存储
- 定义字符集
- 数据库是线程查询的基本单位
死锁产生和解决
定义:两个事务都持有对方需要的锁,并且在等待对方释放,并且双方都不会释放自己的锁。
解决:等待超时或发起死锁检测,主动回滚一条事务,让其他事务继续执行(innodb_deadlock_detect=on)
避免:最简单的是:
- 创建索引
- 使用事务而不是锁表
- 杜绝长事务
索引是什么?为什么需要索引?
索引(Index)是帮助MySQL高效获取数据的数据结构,索引是为了加快查询速度,在MYSQL中,主键包含索引。INNODB默认B+树索引。
B和B+树区别
共同点
- 都是多路搜索树,非二叉树
- 搜索时相当于二分查找
不同点
- B+树查询时间复杂度固定是logn,B树查询复杂度最好是 O(1)。
- B树叶子节点保存索引和数据,B+根节点保存索引,叶子节点保存数据(增强区间访问性)。
- B+树更适合磁盘存储。由于内节点无 data 域,每个节点能索引的范围更大更精确
- B树每个节点即保存数据又保存索引,所以磁盘IO的次数很少,B+树只有叶子节点保存,磁盘IO多,但是区间访问比较好。
为什么MYSQL使用B+树,而MongoDB使用B树
MongoDB使用B树,所有节点都有Data域,只要找到指定索引就可以进行访问,无需回标,无疑单次查询平均快于Mysql。
关系型数据库的数据关联性强,区间访问是常见的一种情况,B+树由于数据全部存储在叶子节点,并且通过指针串在一起,这样就很容易的进行区间遍历甚至全部遍历。
B+和hash索引的区别
hash索引:通过hash函数直接找到目标,进行回表查询,速度更快。
B+索引:每次从根节点出发,找到合适的叶子节点,再判断是否进行回表查询,速度稍慢,但是支持范围。
所以:
- hash索引不支持索引排序
- hash索引不支持模糊查询和最短前端匹配,因为hash函数不可预测
- hash索引避免不了回表查询
- hash索引虽然等值更快,但是在高并发下可能产生hash碰撞,性能更不可预测
聚簇索引和非簇索引
聚簇索引是物理地址连续存放的索引。InnoDB中,数据的主键是聚簇索引,数据在聚簇索引的叶子节点中。
聚簇索引的特点是读取区间速度快,但更新速度慢。
二级索引(非聚簇索引)的叶子节点存放主键值(而不是数据)。InnoDB中,唯一索引、普通索引、前缀索引都是二级索引。
联合索引的索引顺序
需要注意使用频率从高到低排序。另外联合索引ABC会生成A、AB、ABC三个索引,因此需要将查询频繁的放在前面。
如何判断是否命中索引
explain命令
什么时候无法使用索引
- 列参与了数学运算或者函数
- where子句中,使用了in/not in/or/参数/表达式
- 在字符串like时左边是通配符.类似于'%aaa'.这是因为最左匹配原则
- 当mysql分析全表扫描比使用索引快的时候不使用索引.
- 当使用联合索引,前面一个条件为范围查询,后面的即使符合最左前缀原则,也无法使用索引.
可以使用多少列创建索引?
标准表最多可以创建16个索引列,但经验值一般是6个。
简述在MySQL数据库中MyISAM和InnoDB的区别
MyISAM
- 不支持事务,但是每次查询都是原子的;
- 崩溃后无法安全回复
- 支持表级锁,即每次操作是对整个表加锁;
- 存储表的总行数;
- 一个MYISAM表有三个文件:索引文件、表结构文件、数据文件;
- 采用非聚集索引,索引文件的数据域存储指向数据文件的指针。
- 辅索引与主索引基本一致,但是辅索引不用保证唯一性。
InnoDb
- 支持ACID的事务,支持事务的四种隔离级别;
- 支持行级锁及外键约束:因此可以支持写并发;
- 不存储总行数;
- 一个InnoDb引擎存储在一个文件空间(共享表空间,表大小不受操作系统控制,一个表可能分布在多个文件里),也有可能为多个(设置为独立表空,表大小受操作系统文件大小限制,一般为2G),受操作系统文件大小的限制;
- 主键索引采用聚集索引(索引的数据域存储数据文件本身),辅索引的数据域存储主键的值;
- 因此从辅索引查找数据,需要先通过辅索引找到主键值,再访问辅索引;
- 最好使用自增主键,防止插入数据时,为维持B+树结构,文件的大调整。
主键、外键和索引的区别、作用、个数
区别
- 主键–唯一标识一条记录,不能有重复的,不允许为空
- 外键–表的外键是另一表的主键, 外键可以有重复的, 可以是空值
- 索引–该字段没有重复值,但可以有一个空值
作用:
- 主键–用来保证数据唯一性
- 外键–用来和其他表建立联系用的
- 索引–是提高查询排序的速度
个数
- 主键–主键只能有一个
- 外键–一个表可以有多个外键
- 索引–一个表可以有多个唯一索引
为什么not null
null值会占用更多的字节, 并在优化该列(加索引)产生额外的问题
多事务同时存在的问题
- 脏读: A事务读取到了B事务未提交的内容,而B事务后面进行了回滚.
- 不可重复读: 当设置A事务只能读取B事务已经提交的部分,会造成在A事务内的两次查询,结果竟然不一样,因为在此期间B事务进行了提交操作.
- 幻读: A事务读取了一个范围的内容,而同时B事务在此期间插入了一条数据.造成"幻觉".
四种隔离级别
未提交读(READ UNCOMMITTED):其他事务可看到事务未提交数据。
已提交读(READ COMMITTED):由于其他事务修改,本次事务两次读的数据不一样,即产生脏读
REPEATABLE READ(可重复读):解决未提交度和已提交度,但带来幻读问题。
SERIALIZABLE(可串行化):解决所有问题,但并发性能大幅下降
数据选型
整形 > date,time > enum,char > varchar > blob,text
优化
慢查询优化
- 分析语句,查看语句是否合理,是否有优化空间
- 分析索引,查看是否命中,是否需要添加
- 通过缓存和分表进行数据库优化
语句优化
- Where子句中:where表之间的连接必须写在其他Where条件之前
- 对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
- 应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描
redis
redis是什么
运行在内存上速度非常快的NOSQL,有5中数据类型:字符串、列表、散列、集合(无序不可重复)、有序集合(有序不可重复)
redis为什么快
- IO多路复用
- 结构简单
- 运行在内存中
什么是IO多路复用
当某个socket可读或者可写时,系统才会执行相应操作,可以保证每次读写都能读写有效数据而不是无用功。
其实通过函数都可以同时监视多个描述符的读写就绪状况(epoll),这样,多个描述符的I/O操作都能在一个线程内并发交替地顺序完成。
这里的“复用”指的是复用同一个线程。
redis应用场景
缓存和队列
缓存穿透、缓存击穿和缓存雪崩
缓存穿透:客户持续向服务器发起对不存在服务器中数据的请求。客户先在Redis中查询,查询不到后去数据库中查询。
缓存击穿:一个很热门的数据,突然失效,大量请求到服务器数据库中。
缓存雪崩:大量数据同一时间失效。
处理方法
缓存穿透:查询前增加校验
缓存击穿:数据永不过期
缓存雪崩:设置过期时间随机,或使用分布式部署
memcaches和redis
区别
性能: 于Redis只使用单核,而Memcached可以使用多核,所以平均每一个核上Redis在存储小数据时比Memcached性能更高。而在100k以上的数据中,Memcached性能要高于Redis。
内存空间和数据量大小:MemCached可以修改最大内存,采用LRU算法。Redis增加了VM的特性,突破了物理内存的限制。
操作: MemCached数据结构单一,,而Redis支持更加丰富的数据类型,也可以在服务器端直接对数据进行丰富的操作,这样可以减少网络IO次数和数据体积。
可靠性 MemCached不支持数据持久的。Redis支持数据持久化和数据恢复,但是同时也会付出性能的代价。
应用场景:
- Memcached:适合动态系统中减轻数据库负载,提升性能;做缓存,适合多读少写,大数据量的情况。
- Redis:适用于对读写效率要求都很高,数据处理业务复杂和对安全性要求较高的系统。
需要考虑的
- Memcached单个key-value大小有限,一个value最大只支持1MB,而Redis最大支持512MB
- Memcached只是个内存缓存,对可靠性无要求;而Redis更倾向于内存数据库,因此对对可靠性方面要求比较高
- 从本质上讲,Memcached只是一个单一key-value内存Cache;而Redis则是一个数据结构内存数据库,支持五种数据类型,因此Redis除单纯缓存作用外,还可以处理一些简单的逻辑运算,Redis不仅可以缓存,而且还可以作为数据库用
- 新版本(3.0)的Redis是指集群分布式,也就是说集群本身均衡客户端请求,各个节点可以交流,可拓展行、可维护性更强大。
深度学习
深度学习是什么
广义上:是指在机器学习中,从有限样例,通过算法总结出一般性的规律,并可以应用到新的未知数据上。
数理上:指样本的原始输入到输出目标之间的通过组件进行信息去燥(去除噪音)数据流。因为每个组件都会对信息进行加工,并进而影响后续的组件,组件以卷积为主进行信息去燥,组件层层组合成为模型。此时问题转换为贡献度分配问题,模型通过反复计算输入样例和样例分类,得到偏差最小的贡献度作为可用模型。
CNN
通常包含数据输入层、卷积计算层、ReLU激活层、池化层、全连接层,是由卷积运算来代替传统矩阵乘法运算的神经网络。
主要框架
Faster-RCNN: backbone、rpn、roi组成。
backbone: 计算feature_map,常见resnet、googlenet、densenet、cornetnet。
rpn: 以不同的比例切分anchor,计算目标是否在anchor中的分数,每个目标筛选出大约2000个最高可能性proposals,再进行IOU进一步融合,并和真实目标对比以改进loss
roi:对比真实数据得到正负样本;进一步缩小feature_map获得对应信息;回归出更精准的的位置信息;计算loss改进roi。
预处理
随机水平、垂直翻转,随机亮度,随机对比度,随机角度
卷积的本质是什么?卷积层由什么组成?
信息去噪,保留高频信号的同时降低噪音,类似于信息接近无损的转换。
卷积层包括什么
kernel_size:卷积核大小
stride:步长
padding:填补
bias:偏移,引入随机
Bottleneck结构是什么
Conv1x1 - BN - ReLUConv3x3(padding=1, num_groups=32) - BN - ReLUConv1x1 - BN - add identify(down_sample) - ReLU
FPN
如果有FPN网络,则在resnet中,保留每个res_stage的结果,全部放入FPN网络中。
在FPN网络,从最小(最后)的Res_stage结果开始,不断进行上采样(尺寸翻倍),再加和上层结果,进行最大池化。
最终得到多个level的feature_map,切chanel统一(为64)
强化小图片的信息,加强整体信噪比。
RELU优缺点?
优点:简单,计算快,效果好,导数大不容易梯度弥散。
缺点:在训练中变为0,无法继续迭代。解决方案:用leakey relu。
RESNET本质
REZNET做为一个历程碑的模型,解决的是以往模型中层数较深时出现的梯度爆炸/梯度弥散的问题。
本质:保持信噪比的情况下,降低数据中信息的冗余度,提取出效率足够优秀的信息。
做法:
1. 通过skip connection跃层连接resdual block进行线性激活,保证信息完整度。
2. 通过RELU的非线性激活压缩信息。
3. 通过BN进行归一化,保证较高深度不会发生梯度爆炸和弥散。
map
在目标检测中,要处理两个维度的准确率,一个是目标分类是否正确,一个是目标范围是否精确。
在每个predication中,分数大的优先分配GT,且每个GT只分配一个perdition,以此检查每个类别的精确度和召回度。
精确率precision:TP/(TP+FP)
召回率recall:TP/(TP+FN)
以Recall为横轴,Precision为纵轴,在不同类别求PR曲线面积为AP
将IOU从0.5-0.95,每0.05为一个点,求11个IOU阈值下的AP并做平均,为MAP
简述Batch Normalization。
出现原因:在训练中,分布逐渐发生偏移或者变动,一般是向非线性函数取值上下限两端靠近。产生梯度消失问题,使得网络越深,参数越小,收敛变慢,逐渐导致无法学习。
解决方法:通过规范化手段,强行将卷积后激活前的分布转变为均值为0方差为1的标准正态分布。
效果:
1. 避免了梯度消失问题,使得分布总是落在非线性函数敏感的输入区间,大大加快了训练速度。
2. 增强分类效果,不用dropout也不容易过拟合。
3. 降低了初始化的随机性,调参更加稳定。
额外做了什么
在原有框架下加了tensorboardX
每个epoch的coco评分
