@heavysheep
2019-03-04T01:26:00.000000Z
字数 1603
阅读 1301
20190303需求分析
需求分析
需求

说明
评估标准:在以下的说明中,我们使用COCO数据集作为评估数据集,以COCO mAP作为精度评价标准,以所有帧的平均mAP作为预估准确率率之一,其计算方式可以参考这里。
并预估一个常规场景中,大多数人理解的“准确率”作为参考指标。
模型速度:在提出的模型参考中,均以TITAN XP(京东价格约10000元)在单一图片的运算速度作为参考指标。
fps:即每秒帧数,2fps即为每0.5秒检测一张图片。这个指标和硬件成本相互关联,可以简单理解为fps翻倍时,硬件成本翻倍;fps减半时,硬件成本减半。
技术方案
编号1 监控上下楼梯是否使用扶手
涉及技术领域
图像分割
技术实现
- 图形分割技术像素级识别扶手;
- 图像分割技术像素级识别人和手;
- 当检测到人出现时,检测1、2目标交点和连续性。
难点
- 此业务必须时刻检测到手和扶手,否则无法确定手与扶手是否交错,从角度(比如楼梯旋转人会挡住)和实际情况(比如排队下楼,前人挡住后人手的位置),严苛的要求不太可能在实际情况处处实现。
- 由于手和扶手接触是独立较小点,不可使用bounding box正矩形进行检测,必须使用图像分割进行像素级识别和判断,由此带来较大的算量。
以下是tensorflow中的图像分割模型下每帧运算时长(第二列)(单位:毫秒)和精度(第三列):

可见,仅一个摄像头下,以目前的技术在此业务中,不仅速度不达标(1.2fps),精度也不足够(例如我们的面包识别商用的mAP保证在90以上)。
3. 手部在人员非主动展示的情况下,作为较小单位,检测中略有难度。
预期硬件成本
硬件:0.5fps下: 10000 + 10000元 * 摄像头
软件:200000元
预期精度
mAP:20-30
准确率:30%-35%
编号2 识别员工在进入制造区域是否在洗手区域洗手
涉及技术领域
视频姿态跟踪
跟踪结果自定义算法识别“洗手”行为
技术实现
- 跟踪、识别人体姿势;
- 根据1的结果,自研行为算法预测“洗手”行为。
难点
- 姿态跟踪现今最先进模型精度标准
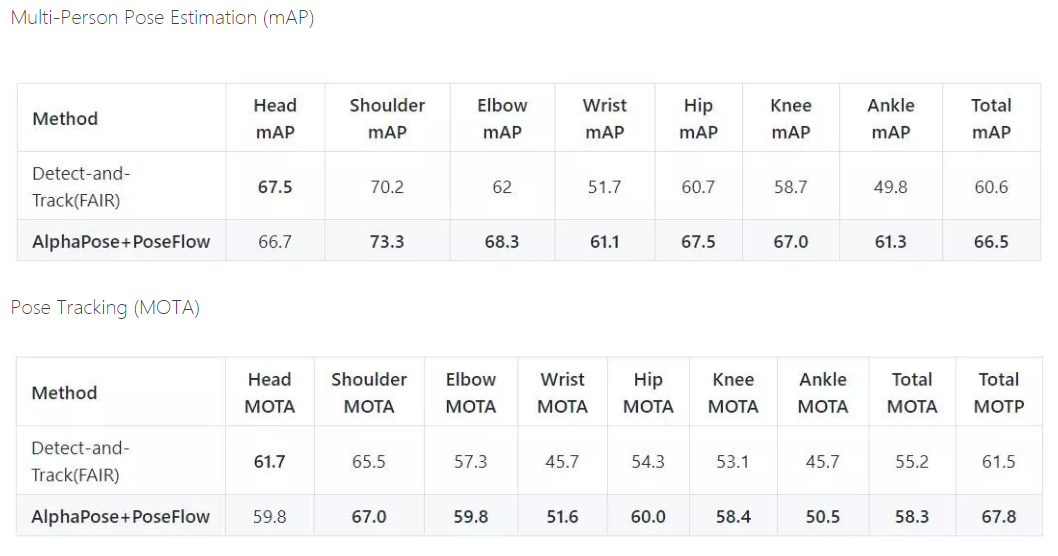
可见,精度在商用中依旧困难。
2. 根据姿态结果,识别“洗手”行为亦是先进和复杂的算法。在1的结果上进行开发更降低了精准度。
3. 人员在洗手时一般较难获得质量足够的图像(比如从后方拍摄,背部挡住了手部),就会出现难以识别的情况
4. 在多人进入洗手区域时,此时的跟踪在人员交错中容易跟踪错误,即不能识别A洗手后,B也进行了洗手。另外,在一个视频中,对A、B洗手完毕的界定也较难。
预期成本
硬件:4fps下: 10000元 + 10000 * 摄像头
软件: 350000元
预期精度
mAP:30-35
准确率:30-35%
编号3、4 识别员工在进入制造区域时是否穿戴防护服装;
涉及技术领域
图像识别
技术实现
- 标注制造区域;
- 标注并训练“未穿防护服装的人”的多个类样本,和“穿防护服装的人”一个类样本;
- 在多帧的MA的平滑中,如果“未穿防护服装的人”出现且高于一个信心分数,则报警。
难点
- 以下是tensorflow中的图像识别模型下每帧运算时长(第二列)(单位:毫秒)和精度(第三列)
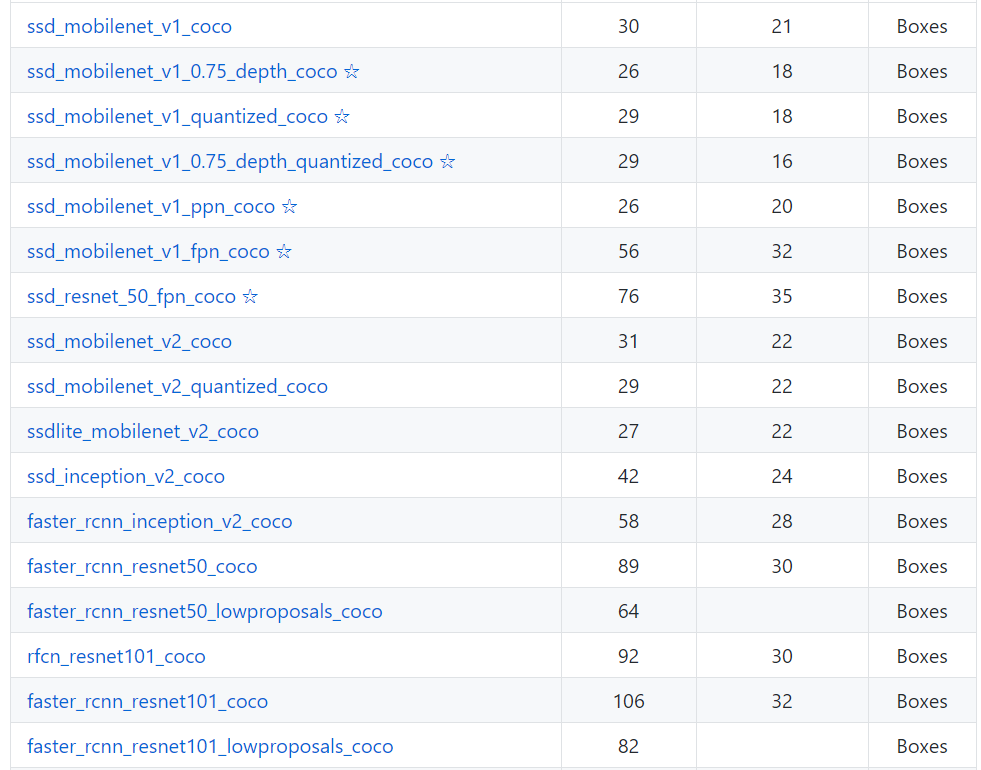
模型标准虽然不高,但首先,我们的技术积累比tensorf的指标高不少;其次,在动态视频中MA所有的平均分数,能较大的提升检测准确率。 - “未穿防护服装”有着多种可能性(不戴头盔、不戴手套),如果没有合适的数据枚举并训练,可能多类的识别分数比较平均的情况。
- 目标较小的情况,较难检测。
预期成本
硬件:2fps下: 10000 + 2000元 * 摄像头
软件: 150000元
预期精度
mAP:70-80
准确率:95%
后记
你可能会想问,在业务3中,虽然先进模型在COCO数据集的精度并不高,但是我们可以做到较高的准确率,那是否其他领域也有机会做到如此可能?事实上是不行的,业务1、2是在一个时间区间内,识别一个结果,这是一个开阔的边界。而业务3是因为我们用MA作平滑后,通过较高的平均精度,压制错误样本的均值,这是两个不同的实现方式。
