@artman328
2017-09-04T03:52:38.000000Z
字数 10576
阅读 1245
Java 快速入门
未分类
一、计算机编程的一般知识
1、什么是计算机程序
计算机程序,就是用特定的语言编写的事务处理过程。一个计算机程序由多个语句组成。计算机逐条读取程序语句,做相应的动作(这些基本动作不外乎“数学运算”、“搬运数据”等)。
计算机内部只能识别“0”和“1”两个数字,我们生活中的所有信息——文字、图片、音频、视频等,到计算机里就变成了“0”和“1”的组合。这些信息平时保存在外部存储器上(如:硬盘、光盘、U盘等),需要使用时,会被“搬运”或“调入”至计算机内存(电子电路,俗称内存条),进行加工处理。
计算机程序,也是以文件的形式保存在外部设备中,需要时被“调入”计算机内存,然后逐条执行程序中的语句。
在 Windows 系统中,计算机程序主要是那些 “.exe" 为结尾的文件。当你在资源管理器中双击这样的文件,或者双击菜单或者桌面上的快捷方式(菜单或者快捷方式相当于一个指向具体文件的“路牌”)时,文件就会被调入内存,由CPU进行执行。你也可以在命令窗口直接键入这样的文件的文件名,然后回车来调入内存执行。
在 Windows 系统中,那些以“.dll”结尾的文件也是程序文件,只不过它们不能以以上方式执行,它们是公共的程序片断,由 “.exe” 结尾的程序在需要时去执行它们。在术语上,它们叫做“动态链接库”。
如果用文字编辑软件打开以上所说的程序文件,你不会看到有意义的文字内容,这些内容是一些由“0”或“1”构成的特殊代码,由计算机读取并执行。这种代码,在术语上叫做“机器码”,是计算机内部器件(如:CPU等)唯一能够识别的操作代码。
2、人类编写的计算机程序代码
机器码是由一系列“0”和“1”构成的代码,人类难以从字面理解它们的含义。因此,人类不直接用机器码编写程序,而是用人类能够理解的语句来编写,然后再把它“翻译”成机器码。
根据抽象程度的不同,我们把人类能够理解的语言分为低级语言和高级语言。低级语言更接近机器语言,对数据的处理要直接面对硬件。高级语言以“一言以蔽之”的方式做大量低层的事情,与具体硬件已经没有关系了。
让我们用一个例子来说明一下抽象程度。
如果我们说:“从厨房米缸里舀一碗米,洗米,将洗净的米倒入灶台上的电饭煲,按体积加入1.3倍的水,盖好电饭煲,按下煮饭开关。”
以上这段话明确地指示了煮饭的整个过程,其中涉及了厨房的米缸,灶台上的电饭煲等具体物件,是一段很详细的指令。如果把“厨房的米缸、灶台上的电饭煲等具体物件”看作计算机硬件的话,这段语言相当于指示计算机的低级语言。
如果我们说:“煮饭”,显然它并未涉及任何“米缸、电饭煲”等具体物件,但经过翻译后,计算机就把以上的事情全部都做了,那么,这句话就是相当于计算机语言的高级语言。
不论是高级语言还是低级语言,最终都将被正确“翻译”成机器语言。
3、人类编程语言到机器语言——翻译的几种形式
以上说过,按人类能看懂的语言来编写计算机程序,最终要被“翻译”成计算机能懂的机器语言来执行。那么,这种“翻译”有以下三种基本形式:
1)一次性翻译
一次性翻译,就是把人类写的程序代码一次性全部翻译成机器码,并保存成可执行程序文件,需要时由计算机载入内存执行。这种类型的翻译在术语上叫“编译”,英文是:compile。做此种编译的工作的软件就叫编译器。
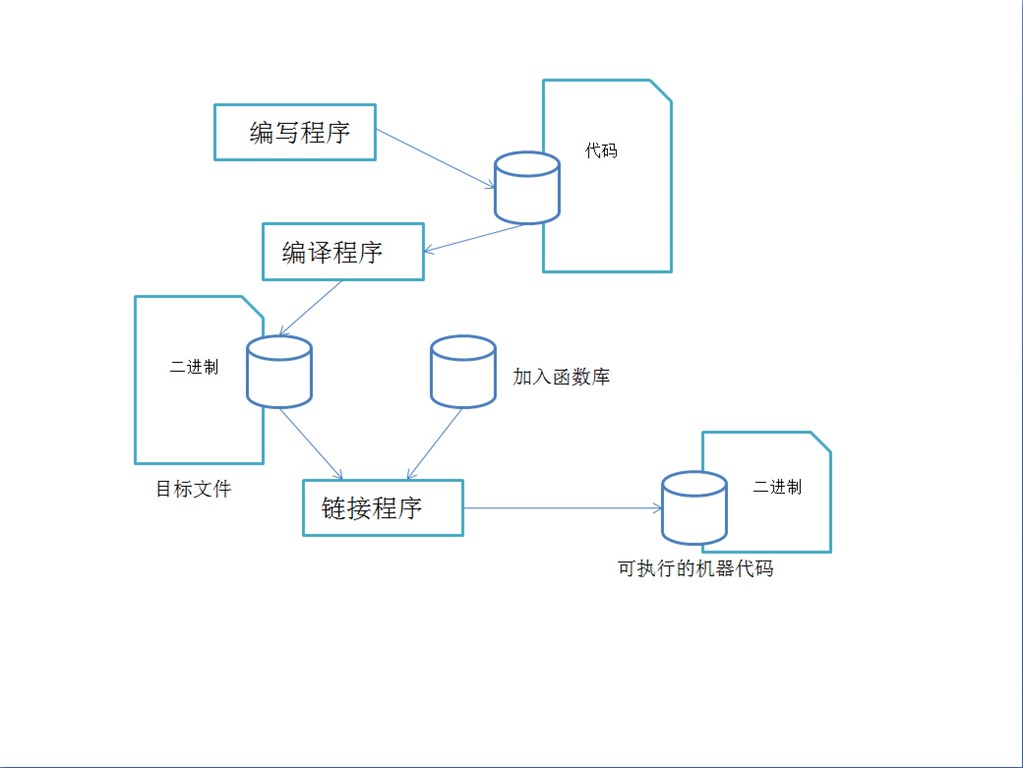
优点:编译时检查代码编写规则(语法、数据类型错误等),发现错误不继续进行编译,除非你把所有被检测到的错误都排除。编译后得到的程序执行效率高(速度快);程序被编译后无法阅读,保密性好。
缺点:编写较繁琐,编译后得到的程序与所在的操作系统密切相关,不能到其它操作系统下执行。如在 Windows 下编译得到的程序文件,不能到苹果的 MacOS 操作系统下执行。
典型的开发语言:汇编语言(低级)、C/C++(高级)等。
2)逐句翻译(或叫解释)
逐句解释,是指负责翻译的软件逐句读取人类编写的语句,把它翻译成计算机可识别的语言来执行,与一次性翻译不同,这种方法没有翻译完成的整个程序文件(比如那些文件名以“.dll”和“.exe”为结尾的文件)的存在,因为没有编译过程,自然也不会预先检查到一些程序的错误(执行时读到才知道是否正确)。这样的翻译过程在术语上叫“解释”,作“解译”的软件就叫“解释器”。
优点:不需要编译过程,可大大提高编写效率。程序语句表达简洁。解释器往往有多种不同版本,以运行在不同的操作系统(又叫平台)下。这样,人们编写的程序在不同平台下都能够得到正确解释执行,同一个程序就可在不同的平台上运行了,这一特点叫“跨平台”。
编译器难道就不可以做成多个不同平台的版本,从而把相同的程序编译成不同平台的程序运行,也实现“跨平台”吗?
当然可以。问题是你的大多数程序会有调用到操作系统相关服务的语句,这些服务在不同的操作系统中是不同的,调用的方式也不同。这样,你需要根据不同的平台来调整你的程序再做编译。对规模较大的软件来说,这可能是一个艰巨的任务。
缺点:因为没有编译过程,不能提前排除程序错误(但可通过合理测试进行解决),执行效率较编译型低,速度较慢(但随着机器运行速度的不断提升,速度已经不是主要问题,除非你要编写实时性要求很高的程序)。
典型的开发语言(全部属于高级语言):JavaScript、PHP、Python、Perl、Ruby等。
3)先一次性编译、后解释
将以上两种方法组合起来,从而排除原有缺点,集中原有优点。
方法:先编写一种具有多个平台版本的“虚拟计算机”,它可运行在 Windows、Mac OS、Linux 等不同的平台上。人们编写的程序,针对这个“虚拟计算机”进行编译,这样,可在编译过程中对程序进行检查,同时,编译后的程序在这台“虚拟计算机”上的运行效率也能得到提高。事实上,“虚拟计算机”在执行程序时,是将针对它编译好的程序进行逐条解释到真实计算机的操作系统中执行的,因此,它就能实现“跨平台”运行。

典型的开发语言:Java(高级语言)。
Java 的虚拟机叫 Java Virtual Machine,简称 JVM。编译后的程序是一种以字节表达的编码,叫字节码。JVM 对字节码进行解释执行。
Java 是历史上实现的第一种“一次编译、随处运行”的编程平台。
4、静态语言和动态语言
在人类使用的计算机语言中,除“翻译”方式的不同外,在对待“数据类型”的问题上还有所不同。
首先,我们来说明什么是数据类型。
在计算机内部,所有的信息都变成了“0”和“1”的组合。信息的最小单位是8位“0”和“1”的组合,叫做一个“字节”(Byte)。
1个字节有8位”0“和”1“的组合,西方文字及符号用一个字节(byte)表示,而一个汉字需要用两个字节表达。信息量的单位换算如下:
1KB = 1024 Byte
1MB = 1024 KB
1GB = 1Gigabyte = 1024 MB
1TB = 1TeraByte = 1024 GB = 1024*1024MB
1PB = 1PeraByte = 1024 TB = 1024 * 1024 * 1024 MB
1EB = 1ExaByte = 1024 PB = 1024 * 1024 *1024 *1024 MB
如果在内存里有两个字节,内容都是 “01000001”,它可能是一个数字,表示65,也可能是一个字母,表示“A”,也有可能是其它信息如图片、视频、音频文件的一部分。如果我们要求计算机把这两个字节的内容“相加”,结果会是什么?
如果把这两个字节的内容都认作是数字65,则相加的结果是10000010,也就是130;
如果把这两个字节在内容都认作是字母“A”,则得到的结果是0100000101000001,也就是“AA”;
如果这两个字节的内容一个认作是65,另一个认作是“A”或者其它信息的一部分,则计算机无法把它们“相加”!
因此,这些信息在计算机内部能否作某种运算,如何运算等,得由我们向计算机说明它们是些什么类型的信息。这样,计算机内部的信息就有“数据类型”之分。
常见的数据类型有:数值型(1、23、2.33等)、字符型('A'
、'&'等)、字符串型("Spring is coming"、"Syntax Error"等)、日期型("2016-12-31"、"3/28/1978"等)、逻辑型(表示真假的数据类型,'true','false'等)、自定义类型等。
在编程时,我们用一些名字来装数据,这些名字在术语上叫“变量”。正如我们说:
重量 = 100; 个数 = 8; 平均重量 = 重量/个数; (结果:平均重量是12.5)
在程序中可能写成这样:
weight = 100; count = 8; average_weight = weight / count; (结果:average_count 是 12.5)
以上的 weight、count、average_weight 等就叫变量。
1)静态语言
静态语言,其实叫做静态类型语言。在对待数据类型上有以下规则:
- 每个变量在使用前,必须声明它要装的数据是什么类型;
- 任何时候,实际装入变量的数据类型必须与声明的数据类型一致。
用汉语举例:
整数类型 重量; //声明了整数类型的变量:重量重量 = 100; //正确:把整数100装入变量,或者叫做给变量“重量”赋值100...重量 = "你好" //错误:给整数型变量赋予了字符串值,与声明不一致
用 Java 语言举例:
int weight;weight = 100;...weight = "Hello"; // error!!!
典型的静态语言:C/C++、Java、C#等
2) 动态语言
动态语言,就是动态类型语言。变量在使用前不需要说明类型,并且随时可装入不同的数据类型,就像我们家中的盆子,可装入任何想装的东西。
同一个变量,装入什么类型的值,它就是什么类型的变量,如装入整型值时,它就是整型的,装入字符串时,它就是字符串型的。
因此,动态语言比较灵活,但也会增加出错几率(比如对不同数据类型的数据做了非法运算等)。
典型的动态语言:JavaScript、PHP、Python、Ruby等。
5、面向过程与面向对象编程
面向过程现面向对象,是编程的方法学问题。
面向过程的编程,强调事务的处理过程,它们常常用子程序或者函数来分解处理过程。面向过程的编程方法的最重要特点是处理过程与数据没有特定关联,它们是独立存在的。举例来说,一辆公共汽车将乘客从 A 地送到 B 地,运送过程是处理过程的话,运送的乘客就是数据。而这辆车的运送并不只针对哪几个的乘客,而是任何乘客。
面向过程的编程所面临的最大问题,恐怕是程序代码的复用问题。代码复用是指在一个软件项目中使用其它项目已有的代码来完成类似任务。面向过程的编程,在代码复用上显得比较困难。比如一段代码如果要想被直接使用的话,那么它现在要处理的数据就必须与它原来规定的数据在类型和数目上要一致。而我们面临的实际问题往往是相似而不相同的。
面向对象的编程,是对真实世界的模拟,它把处理过程和数据看作一个整体。代码复用很容易被实现。
Java 是一种编译-解释型的、静态类型的、面向对象的、跨平台的高级程序设计语言。
二、面向对象的编程
1、类和对象
如何写计算机程序?一行一行的代码指导计算机完成我们规定的工作。
在面向过程的编程中,代码和数据是分开的,数据存储在某个地方(数据库、内存等),代码对这些数据进行操作。这种编程方法会导致代码的重复使用很困难,代码的维护也不容易。
后来,人们认为可模仿自然界的事务处理行为,事务管理涉及多种事物——人、物、业务过程等。如果我们把它们都认为是“活”的,那么,事物管理就是它们之间的相互合作。就一个教务管理系统来说,班级是活的、学生是活的,班级有名称、入学年份、包含的学生等。学生有姓名、性别、出生年月等。这些分别是他们的“属性”,也是管理的数据。我们把它们叫“类(class)”,也就是参与管理的事务的各种类别。除了有数据外,我们还需要他们是“活”的,意思是自己负责自己数据的处理,这些处理过程就叫“方法(method)”或者“函数(function)”。因此,“类”就是数据和对数据的操作的集合体。
以下是用汉语描述的“班级”类,以后会有详细解释。
公开的 类 班级:属性(数据):公开或私有或保护的 字符串型 名称公开或私有或保护的 整数型 入学年份公开或私有或保护的 学生集合类型 学生们行为(方法、函数):公开的 不要结果 设置名称(传入所给名称):如果传入名称合法(不为空、命名符合要求等):把所给名称赋予自己否则:引发错误,给出错误信息公开的 字符串结果 获取名称(不传入任何数据):如果当前用户有此权利:把自己的名称给出否则:引发错误,给出错误信息公开的 不要结果 设置入学年份(传入所给入学年份):把所给入学年份赋予自己公开的 整型值结果 获取入学年份(不传入任何数据):把自己的入学年份给出公开的 不要结果 加入学生(传入学生):在学生们集合中加入传入的学生公开的 学生类型的结果 获取学生(传入学号):在学生集合中找到传入学号对应的学生,给出
“类”是对事物的描述,真正参与协作的是这些类的具体事务——“对象(object)”。例如:“班级”类规定,它的数据有名称、入学年份、包含的学生等,方法有指定名称、获取名称、添加学生到班级、从班级删除学生等。这只是对班级的描述。一个具体的班级就是对象,如:名称为“计算机程序设计”、入学年份为“2017”,包含的学生有“张强、男、2009-12-23;李斯、女、2001-1-1”的班级,就是一个“班级”类的具体“对象”。
以下代码“做”出一个班级对象:
班级类 班级1 = 从班级类新生成一个班级;班级1.设置名称(“计算机程序设计三年制高级01班”);班级1.设置往常年份(2017);
这样,这些带有数据及对自己数据的处理方法的事物,相互协作就可完成事务的管理。例如:
一个窗口类的对象(暂且把它叫做主窗口),把自己显示出来,它有一个“列表”对象,里边是很多的“班级”对象。同时,它上面还有一个“添加班级”的按钮,当操作者点击了这个按钮后,主窗口会“做”一个带有输入域的窗口对象(暂且把它叫做子窗口),让它显示出来。当我们输入信息完成后,点击“保存”,子窗口会为我们做一个班级对象,把我们输入的信息指定给它(事实上,是子窗口调用班级对象的方法进行指定的),然后,调用这个班级对象的一个方法,把班级对象的数据存储到数据库里。
2、对象之间的关系
类之间可能具有某种联系,比如:一个班级对象“有”多个学生对象,一个学生对象“属于”一个班级对象。这是一种“一对多”的包含关系。再比如:一个教师(对象)教多门课程(对象),一门课程(对象)被多名教师(对象)
讲授。这是一种“多对多”的关系。同样,还有一种“一对一”的关系。
以下是“一对多”关系的定义:
类 班级:属性:...学生集合类型 学生们...类 学生:属性:...班级类型 所属的班级...
3、类的继承
有时候,一种类和另一种类很相似,只比另一种类多了一些东西。这时,没有必要重新完整定义这个类,而是只定义自己独有的部分,同时说明自己要“继承”另一个类就行了。被继承的类叫“父类”,继承来的类叫“子类”。
比如:
//文件:Vehicle.javapublic class Vehicle{ //交通工具//属性protected String name; //名称protected String brand; //厂牌//构造函数public Vehicle(String name, String brand){this.name = name;this.brand = brand;}//getter和setterpublic void setName(String name){this.name = name;}public String getName(){return this.name;}public void setBrand(String brand){this.brand = brand;}public String getBrand(){return this.brand;}public void Tell(){return this.name + " " + this.brand;}}//文件:Car.javapublic class Car extends Vehicle{ //小型客车//属性protected String plate_no; // 车牌号protected int seat_count; //座位数//构造函数public Car(String name, String brand, String plate_no, int seat_count){super(name,brand); //调用父类构造函数设置自己的名称和厂牌this.plate_no = plate_no;this.seat_count = seat_count;}public void setPlateNo(String plate_no){this.plate_no = plate_no;}public String getPlateNo(){return this.plate_no;}public void setSeatCount(String plate_no){this.seat_count = seat_count;}public String getSeatCount(){return this.seat_count;}@Overridepublic void Tell(){return this.name + " " + this.brand + " " + this.plate_no;}}// 使用以上的小客车类Car car = new Car("桑塔纳","大众","云A-77665",5); //“做”一个小客车对象car.getName(); //得到“桑塔纳”car.getSeatCount(); //得到5
如果要在子类里重新写父类里的方法,要加上@Override
既然可通过继承丰富一个类,那末,继承多个类岂不是可得到更加丰富的类了?Java规定,类只能继承一个类。
4、封装
类的属性和方法,都有处理权限问题。对于公开的属性,属性可被直接设置和获取。如:
public class Vehicle{ //交通工具//属性public String name; //名称protected String brand; //厂牌...}...Vehucle v = new Vehicle();v.name = "桑塔纳"; //将名称设置为“桑塔纳”System.out.println(v.name); //显示“桑塔纳”
对于属性来说,public(公开),表示可被外部直接存取; private(私有
),表示只能在自己的方法内部存取; protected(被保护的),表示只可在自己的和子类的方法内部存取。
对于方法来说,public(公开),表示可被外部直接调用; private(私有
),表示只能在自己的方法内部调用; protected(被保护的),表示只可在自己的和子类的方法内部调用。
对于类来说,public(公开),表示可被外部直接使用; private(私有
),表示只能在自己的外部类内部使用; protected(被保护的),表示只可在自己的外部类内部和外部类的子类内部使用。default(默认),表示只可在同包内的类里使用。
将类的所有属性都定义成private或者protected的,然后通过定义的public的方法进行存取,可以很好地保护对象数据不被随意更改,这就是类的封装。
5、接口(interface)
和类差不多,接口也规定了一些行为。但在接口里,并不实现这些行为,它们只能在类里实现。接口就像契约,声明要“实现”某个(或多个)接口的类,必须实现这些接口里规定的行为。
public interface Itec{int Add(int a, int b);int Sub(int a, int b);}public interface YourMethod{String Concat(String s1, String s2);}....class MyClass implements Itec, YourMethod{...public int Add(int a, int b){...}public int Sub(int a, int b){...}public String Concat(String s1, String s2){...}}
6、类型
Java属于静态类型语言,在使用变量时,要声明变量所能装的数据类型。
String s; //声明一个只能装字符串的变量 ss = "Welcome you!"; //把 Welcomeyou! 装到变量 s 里(给s赋值)String s = "Welcome you!" //声明同时赋值
同一类类型的变量只能装同一类的对象(但父类类型的变量可装子类的对象,接口类型的变量可装实现了此种接口的类的对象)。
Student student = new Student();Vehicle v = new Car(); //Vehicle 是 Car 的父类TheMethod op = new Doit(); // Doit 类实现了 TheMethod 接口
类型可以被转换:
Car car = (Car) GetVehicle();//我们明确知道 GetVehicle()会返回一个Object对象,Object是所有类的隐含顶级父类,但它确实是一个Car对象,我们需要明确地把它转换为Car类,才能赋值给Car类型的变量。
三、Java语言基础
1、Java的数据类型
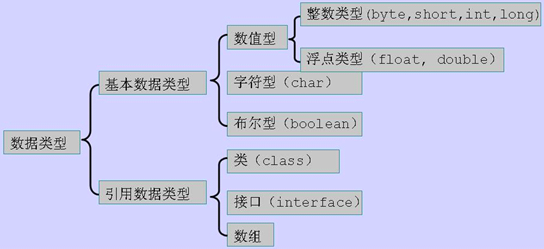
1)基本数据类型
a. 数值型
byte 整型,长度为8位二进制数(1字节);
short 整型,长度为16位二进制数(2字节);
int 整型,长度为32位二进制数(4字节);
long 整型,长度为64位二进制数(8字节);
float 浮点型(小数);
double 双精度型(小数)。
b. 字符型
char 字符型,单个字符。
c. 布尔型(逻辑型)
boolean 逻辑型,只有“真(true)”和“假(false)”两个取值。
2)引用数据类型
a. 类
各种类的定义都是自己类别的数据类型。
类的定义:
[存取修饰符] class 类名 { //存取修饰符:public, protected//属性声明[存取修饰符] 变量类型 变量名; //存取修饰符:public, protected, private...//构造函数声明[存取修饰符] 类名([参数列表]){ //存取修饰符:public, protected, private//把参数值赋予对应属性}//方法定义[存取修饰符] 返回值类型 方法名([参数列表]){...}}
例如:
public class Product{ //定义公开类型的类 Product (产品)//属性定义protected String name; //受保护的字符串类型的属性nameprotected String brand; //受保护的字符串类型的属性brand(品牌)// 构造函数// 当 new Student("打印机","四通") 时,会生成一个名称为“打印机”、品牌为“四通”的产品对象。public Product(name,brand){//以下把参数的值给对应的属性,this 表示生成的对象自己this.name = name;this.brand = brand;}//方法定义//方法分两类,一类用于存取私有或受保护的属性(按惯例,存数据的方法一般以set开头,所以又叫setter,取数据的方法一般以get开头,所以又叫getter),一类是基于数据的其它业务算法(如果有的话)。//存名称public void setName(String name){//这里可以加入检测传入参数是否符合要求的代码//如果不合要求,可引发错误this.name = name;}//取名称public String getName(){//这里可以加入其它代码,以决定是否返回名称(比如用户是否有权获取名称)return this.name;}...//业务算法函数,获取产品描述public String description(){return "产品信息:" + this.name + " " + this.brand;}}
b. 接口
各种接口的定义都是自己类别的数据类型。
接口定义:
[存取修饰符] interface 接口名 {//函数声明返回值类型 函数名([参数列表]);}
如:
public interface Calc {int Add(int a, int b);int Sub(int a, int b);}
c. 数组
数组是一种集合类型,它可以装载同一种类型的基本数据或引用型数据。
//声明一个可装载浮点类型数据的一个数组rates并装入数据int[] rates = {1.1,3.0,2.2,2.1,3.1};//声明一个可装载50个字符的数组变量strchar[] str = new char[50];
2、Java变量
变量是装在数据的容器。在像Java的静态类型的语言中,变量必须声明用于装载什么类型的数据。在声明变量时,可同时给其赋值。
变量名必须以字母或者下划线开头,有字母、数字、下划线等构成,但不能与Java语言的关键字相同。
Java语言是字母大小写敏感的。即:Car、car是不同的变量名。
变量名最好用英文取名,便于编程的国际合作。
int rate = 10; //正确int price = 1.2; //错误,试图把小数装入整型变量long data = 100L; //最后的L表示是长整型的100Student s = new Student(); //正确Vehicle v = new Car(); //如果Car类是Vehicle的子类,则正确IOperator iop = new MyClass();//如果 MyClass类实现了IOperator接口,则正确
3、Java的语句
1)声明变量
//变量类型 变量名;String name;
2)变量赋值
//变量名 = 值;name = "Billy";
3)条件判断
基本:
if(条件表达式){//满足条件时执行的语句}
加上不满足时的行为:
if(条件表达式){//满足条件时执行的语句}else{//不满足条件时执行的语句}
复杂的结构:
if(...){ //如果...}else if(...){ //否则如果...}else if(...){ //否则如果...}else{ //否则...}
