@artman328
2021-03-17T00:23:18.000000Z
字数 58259
阅读 6341
程序员之路:关系数据库的应用
database 数据库 程序员之路
- 程序员之路:关系数据库的应用
- 绪论
- 第一部分 数据库基础
- 第二部分 数据库的使用
- 第三部分 数据库的设计
- 附录
绪论
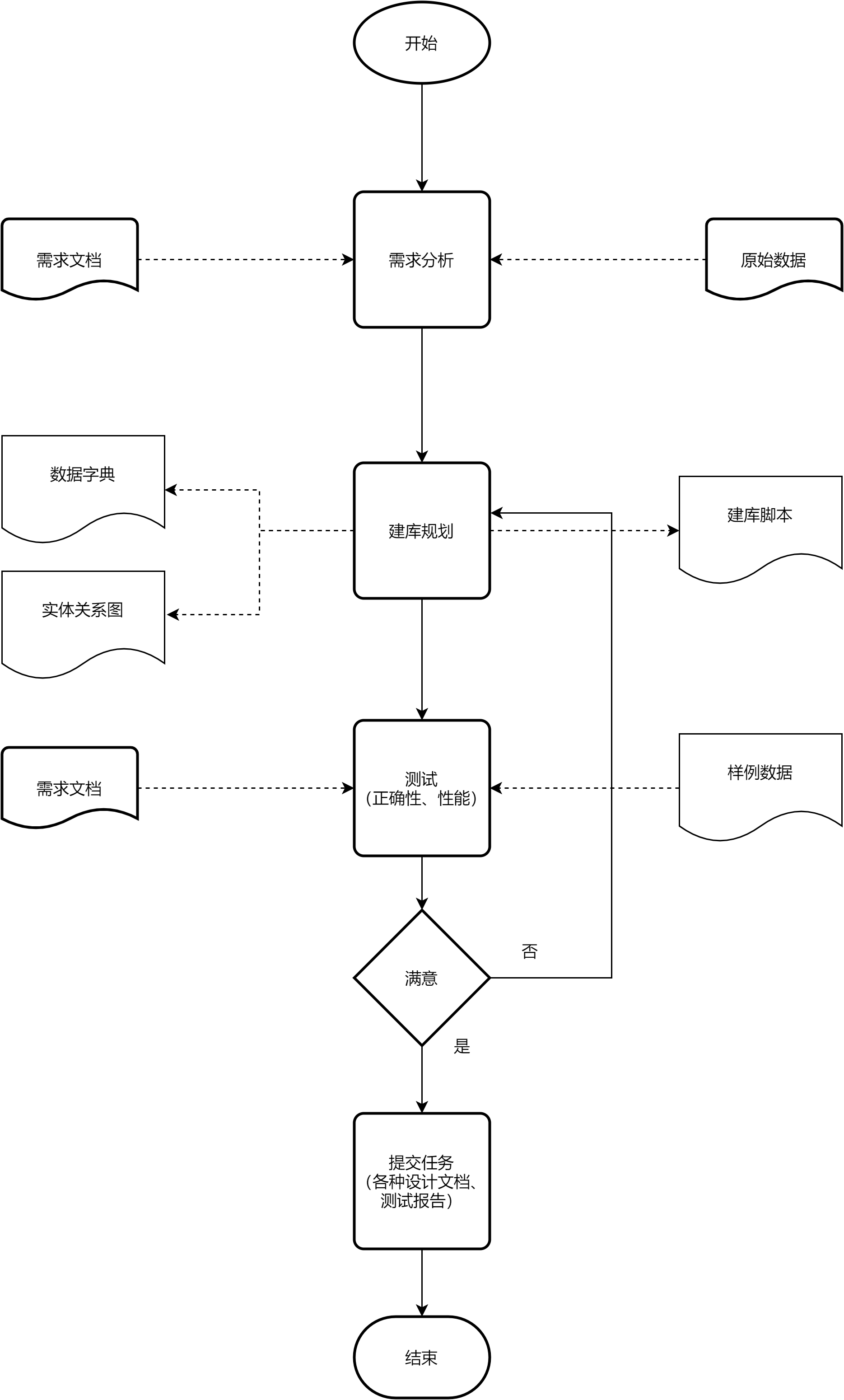
1、课程目的
掌握作为程序员所需要规划、设计和使用管理数据库的基本技能。
程序员为什么要学习数据库?
所有计算机程序都是用来处理信息数据(data)的,绝大多数程序的数据都用数据库来进行存储。不懂数据库,也就没有办法很好地开发计算机程序。可以说,数据库在信息管理类的应用程序中,是举足轻重的角色。因此可以说,很好地使用数据库来组织和管理信息,是程序员的必备技能之一。
2、课程对象
有志于软件开发或数据库管理的任何人,只要满足以下条件:
- 具备初中及以上文化程度;
- 会使用电脑……
3、课程内容
课程分为三个部分:
(1)数据库基础
了解数据库基本概念及搭建学习环境。
(2)数据库的使用
通过由简到繁的多个实际案例,达到以下目标:
- 掌握数据库相关的基本概念
- 读懂设计稿
- 掌握数据的增删改查
- 了解视图、存储过程、函数及触发器
(3)数据库的设计
通过由简到繁的多个实际案例,达到以下目标:
- 掌握相关的基本概念
- 根据业务需求和样例数据规划数据表
- 建库、建表、插入样例数据
根据业务需求测试处理和访问数据
规划和设计数据库过程
4、学习方法
- 认真观看视频,并跟随视频亲自动手实践
- 可根据学习效果调整自己的学习速度(视频教学的好处!)
- 认真思考,完成视频中的作业
- 借助互联网去学习同行们提供的知识和经验
- 主要学会“怎么做”,以后再去琢磨“为什么”
第一部分 数据库基础
第一章 数据库的基本概念与学习环境的建立
1、什么是数据库(Database)?
数据库的目的是存储并管理数据(data)。
2、什么是关系数据库(Relational Database)?
关系数据库里的数据以表(table)的形式存储,表和表之间可以建立相互参照(reference)的联系(relation)。
3、什么是关系数据库管理系统(RDBMS)?
RDBMS: Relational Database Management System.
关系数据库系统是一套计算机软件,用于管理数据库。
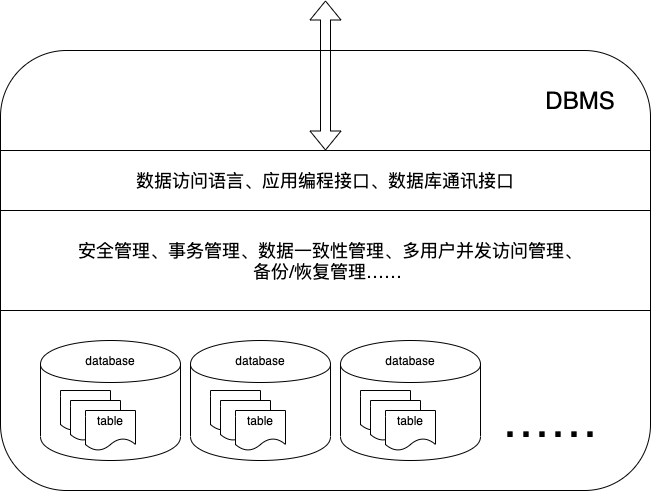
主要功能:
(1)安全管理
根据用户身份和权限限制用户对数据的访问。
(2)事务管理
对数据的操作都会得到一个稳定的最终状态——要么数据更改成功到达一个新的状态,要么撤消所有更改回到之前的状态。
(3)数据一致性管理
同样的数据如果出现在不同的地方,必须保持一致。
(4)多用户并发访问管理
多用户访问数据时的冲突控制。
(5)备份/恢复数据
备份数据,避免数据遗失。从备份中恢复数据。
4、什么是 SQL 语言?
SQL 语言,即结构化查询语言,是一种接近于人类自然语言的数据库专用语言。我们用它来定义数据库的各种元素,如库、表、关系、约束、触发器、存储过程、函数等等,用于这方面的语句又称作数据定义语言 DDL。我们也用它来完成数据的操纵,如对数据进行增加、删除、修改、查询等操作,用于这方面的语句又叫数据操纵语言 DML。当然,还有一类语句是用于管理数据库权限分配的,叫数据控制语言DCL,以及管理数据库事务的事务的控制语句,叫TCL。我们不用费心记住这些,这里只是做概念性的介绍,所有这些语句我们以后都会用到。
5、MySQL/MraiaDB 数据库管理系统应用架构
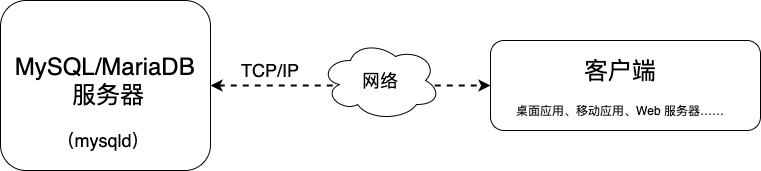
6、MySQL/MraiaDB 数据库管理系统管理界面
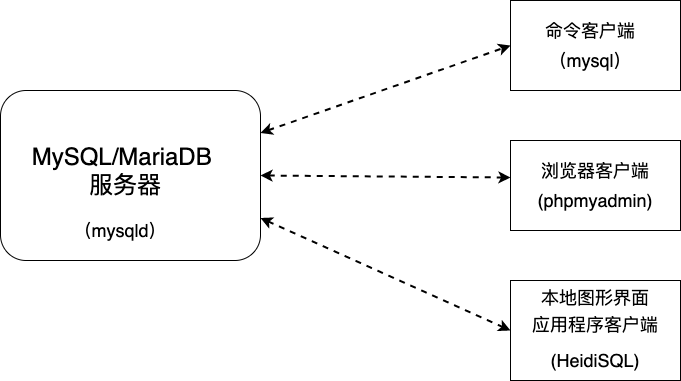
7、在 Windows 中安装 MySQL/MariaDB
(1)下载安装
(2)测试安装
如有需要,配置环境变量PATH。
第二章 管理 MySQL 数据库
1、配置文件
为服务器和客户端提供各类配置信息,以规定服务器和客户端的默认行为。
查看配置文件名及其读取顺序:
mysqladmin --help...Default options are read from the following files in the given order:C:\Windows\my.ini C:\Windows\my.cnf C:\my.ini C:\my.cnf C:\Program Files\MariaDB 10.4\my.ini C:\Program Files\MariaDB 10.4\my.cnf C:\Program Files\MariaDB 10.4\data\my.ini C:\Program Files\MariaDB 10.4\data\my.cnf...
2、管理服务
服务是一种特殊程序,它一般不提供与用户直接交互的界面,而是在后台运行,通过某种请求和响应协议来向客户端程序提供服务。
(1)服务的启动、停止
a) 通过 services.msc 服务管理程序来完成
b) 通过命令行来完成
net start mariadbnet stop mariadb
(2)用 mysqladmin 管理数据库系统
mysqladmin -h 服务器地址 -P 服务器端口 -u 用户名 -p 密码 管理命令
-h:忽略时使用本机地址;
-P: 忽略时使用配置文件里的端口(通常为3306);
-u: 忽略时使用当前操作系统的用户;
-p: 忽略时不使用密码,密码忽略时会提示输入。
例1:改变本机上的数据库管理系统(默认端口:3306)的 root 密码。
mysqladmin -uroot -p password
3、备份和恢复数据库
(1)备份
备份单个数据库:
mysqldump -u用户名 -p 数据库 > 备份文件名
举例:
C:\>mysql -uroot -p shop > shop.sql
备份多个数据库:
mysqldump -u 用户名 -p --databases 数据库1 数据库2 ... > 备份文件名
举例:
C:\>mysqldump -u root -p --databases test mysql > test_mysql_backup.sql
备份全部数据库:
mysqldump --all-databases --routines --single-transaction --quick --lock-tables=false > 备份文件名 -u root -p
举例:
C:\>mysqldump --all-databases --routines --single-transaction --quick --lock-tables=false > full-backup-2020-02-08.sql -u root -p
(2)恢复
恢复单个数据库:
mysql -u 用户名 -p 数据库名 < 备份文件
举例:
C:\>mysql -uroot -p shop < shop.sql
恢复多个数据库:
mysql -u 用户名 -p --default-character-set=数据库字符集编码 < 备份文件
举例:
C:\>mysql -uroot -p --default-character-set=utf8 < test_mysql_backup.sql
恢复全部数据库:
mysql -u 用户名 -p --default-character-set=数据库字符集编码 < 备份文件
举例:
C:\>mysql -uroot -p --default-character-set=utf8 < full-backup-2020-02-08.sql
第三章 了解 MariaDB 数据库系统
1、登录到数据库服务器
mysql [-h 服务器地址] [-P 服务器端口] [-u 用户名] [-p [密码]]
-h:忽略时使用本机地址;
-P: 忽略时使用配置文件里的端口(通常为3306);
-u: 忽略时使用当前操作系统的用户;
-p: 忽略时不使用密码,密码忽略时会提示输入。
例如:登录到运行于本机的数据库服务器,端口为配置文件指定的窗口,用户名为 root,需要登录时提示输入密码。
mysql -u root -p
2、列出系统中管理的数据库
MariaDB [(none)]> show databases;+--------------------+| Database |+--------------------+| information_schema || mysql || performance_schema || test |+--------------------+4 rows in set (0.001 sec)MariaDB [(none)]>
SQL语言用分号(;)表示一条语句的结束,换行并不会打断一条语句的完整性。在 MySQL/MariaDB 系统中,用 \g 来结束一条语句与分号作用一样,而用 \G 来结束一条语句,会把输出结果按竖式排列,便于显示查看过宽的输出结果。
information_schema, mysql, performance_schema 是三个数据库管理系统自用的数据库。
test 是一个用于测试的数据库,任何人都有足够权限对它操作,为安全起见,通常会被删除。
3、进入某个数据库
如:进入 mysql 数据库。
MariaDB [(none)]> use mysql;Database changedMariaDB [mysql]>
use: 使用
注意提示符的变化。
4、列出数据库中的数据表
如:列出 mysql 数据库中的数据表。
MariaDB [mysql]> show tables;+---------------------------+| Tables_in_mysql |+---------------------------+| column_stats || columns_priv || db || event || func || general_log || global_priv || gtid_slave_pos || help_category || help_keyword || help_relation || help_topic || index_stats || innodb_index_stats || innodb_table_stats || plugin || proc || procs_priv || proxies_priv || roles_mapping || servers || slow_log || table_stats || tables_priv || time_zone || time_zone_leap_second || time_zone_name || time_zone_transition || time_zone_transition_type || transaction_registry || user |+---------------------------+31 rows in set (0.001 sec)MariaDB [mysql]>
show: 显示,展示
5、查看数据库系统的用户
MariaDB [mysql]> select Host, User, Password from user;+-----------------+------+-------------------------------------------+| Host | User | Password |+-----------------+------+-------------------------------------------+| localhost | root | *032197AE5731D4664921A6CCAC7CFCE6A0698693 || desktop-f6ge8f3 | root | *032197AE5731D4664921A6CCAC7CFCE6A0698693 || 127.0.0.1 | root | *032197AE5731D4664921A6CCAC7CFCE6A0698693 || ::1 | root | *032197AE5731D4664921A6CCAC7CFCE6A0698693 || % | root | *032197AE5731D4664921A6CCAC7CFCE6A0698693 |+-----------------+------+-------------------------------------------+5 rows in set (0.001 sec)MariaDB [mysql]>
Host(主机): 用户可登录的地点(计算机网络地址)。
User(用户): 用户名。
Passowrd(密码): 密码(已加密)。
6、查看系统中的字符集编码的排序规则
show charset;show character set;show chaset like '%utf8%';show collation;show collation like '%utf8%';
character set: 字符集(在计算机内部把文字编码成数字的方案,同一个方案编码的字符,只能用同一种方案解码)
collation: 排序规则(如汉字在字典中就有按笔划排序、按拼音排序等规则)
7、查看系统使用的字符集
MariaDB [(none)]> show variables like 'char%';+--------------------------+-----------------------------------------------+| Variable_name | Value |+--------------------------+-----------------------------------------------+| character_set_client | gbk || character_set_connection | gbk || character_set_database | utf8 || character_set_filesystem | binary || character_set_results | gbk || character_set_server | utf8 || character_set_system | utf8 || character_sets_dir | C:\Program Files\MariaDB 10.4\share\charsets\ |+--------------------------+-----------------------------------------------+8 rows in set (0.001 sec)MariaDB [(none)]>
8、断开连接
MariaDB [(none)]>exit
第二部分 数据库的使用
在这一部分,我们将读懂别人的数据库设计,了解数据库内的各种元素:表及表间关系、视图、触发器、函数、存储过程等。更重要的是,我们将利用 SQL 语言去操纵数据库里的数据,实现数据库设计需求文档中所需要实现的各种业务操作。
充分了解特定场景下别人根据需求对数据库所做出的设计,熟练地操作别人数据库里的数据,对我们将来在类似场景下根据需求自行设计数据库具有重要的启发作用。
第四章 预备知识:对数据库表及其关系的认识
4.1 对数据库表的大致要求
为了正确地处理信息,数据库对表是有一定要求的。
4.1.1 每一列数据拥有自己的数据类型
在计算机内部,不同的数据类型表示的事物不同,运算方法也不同。为了正确处理信息,每一列都需要指明其数据类型。数据类型主要分四大类:表示数量多少的数值类型、表示文字信息的字符串类型、表示日期和时间的日期时间型以及表示二进制字节串的大二进制对象类型(图像、音频、视频等二进制字节串)。
参见:附录一 MySQL/MariaDB 常用数据类型速查表
4.1.2 每行记录都能和其它行区分开来
看看以下表格:
| 姓名 | 性别 | 出生日期 | 月薪 |
|---|---|---|---|
| 王小小 | 女 | 1998-03-22 | 3800.00 |
| 李强 | 男 | 1995-05-12 | 4500.00 |
| 王小小 | 女 | 1998-03-22 | 3900.00 |
请问,第一行和第三行是怎么回事儿?
可能的情况有:
(1)填写重复了,那么月薪必然有一处是错误的,需要重新确定,并删除一行;
(2)填写不重复,公司就有两个同名同姓同性别同出生年月的两个员工!
到底是哪种情况?
因此,数据库表需要杜绝这种情况。
造成这种情况的是员工的属性中没有可以用来唯一区别彼此的属性,甚至多个属性组合起来也不能区别彼此。
所以,为了解决此问题,就要找到一个能够区别彼此的员工属性,比如“身份证号”就是一个很好的属性,因为每个员工的身份证号是绝对不可能相同的。
| 身份证号 | 姓名 | 性别 | 出生日期 | 月薪 |
|---|---|---|---|---|
| 530101199803221124 | 王小小 | 女 | 1998-03-22 | 3800.00 |
| 551233199505126752 | 李强 | 男 | 1995-05-12 | 4500.00 |
| 313098199803220069 | 王小小 | 女 | 1998-03-22 | 3900.00 |
这样的一列(或者几列的组合)叫做主键(primary key)。
4.2 表的参照关系
我们把数据库表描述的事物叫实体(entity),在关系数据库中,实体之间具有参照关系。描述这种关系的图叫实体关系图(ER 图)。
本教程全程采用乌鸦脚画法绘制 ER 图。
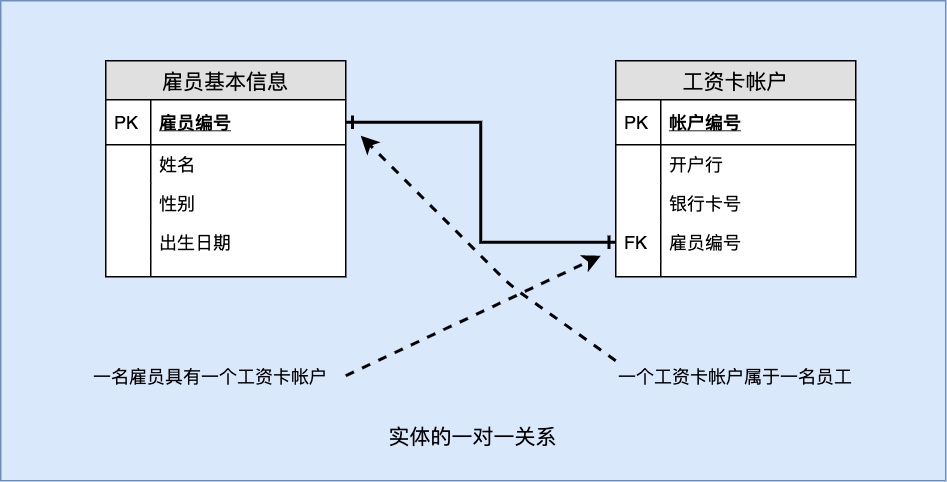
4.2.1 一对一关系
原表(每位员工记录其基本信息和一个银行帐号用于发放工资):
| 雇员编号 | 姓名 | 性别 | 出生日期 | 开户行 | 银行卡号 |
|---|---|---|---|---|---|
| 0706 | 周强 | 男 | 1996-02-15 | 中国银行周树支行 | 4562 3498 9876 9987 |
| 0789 | 李妙 | 女 | 1998-10-20 | 中国银行江河支行 | 4578 2565 2896 3376 |
按关注拆分表(因查看需求后,发现工资银行帐户只能由部分用户如财务处使用,而员工基本信息供所有用户使用)
雇员基本信息
| 雇员编号 | 姓名 | 性别 | 出生日期 |
|---|---|---|---|
| 0706 | 周强 | 男 | 1996-02-15 |
| 0789 | 李妙 | 女 | 1998-10-20 |
工资卡帐户
| 编号 | 开户行 | 银行卡号 | 雇员编号 |
|---|---|---|---|
| 1 | 中国银行周树支行 | 4562 3498 9876 9987 | 0706 |
| 2 | 中国银行江河支行 | 4578 2565 2896 3376 | 0789 |
这时,工资卡帐户中的“雇员编号”指向了雇员基本信息表中的“雇员编号”。我们说工资卡帐户的“雇员编号”是外键(foreign key),它参照(references)了雇员基本信息表中的“雇员编号”。表中的“雇员编号”要求必须有值且不能出现重复值。
在做各种查询和统计的时候,如果涉及到两张表上的数据,先用两张表结合起来得到“原表”那样的“结果集”,再在此“结果集”上做查询和统计。
ER 图:
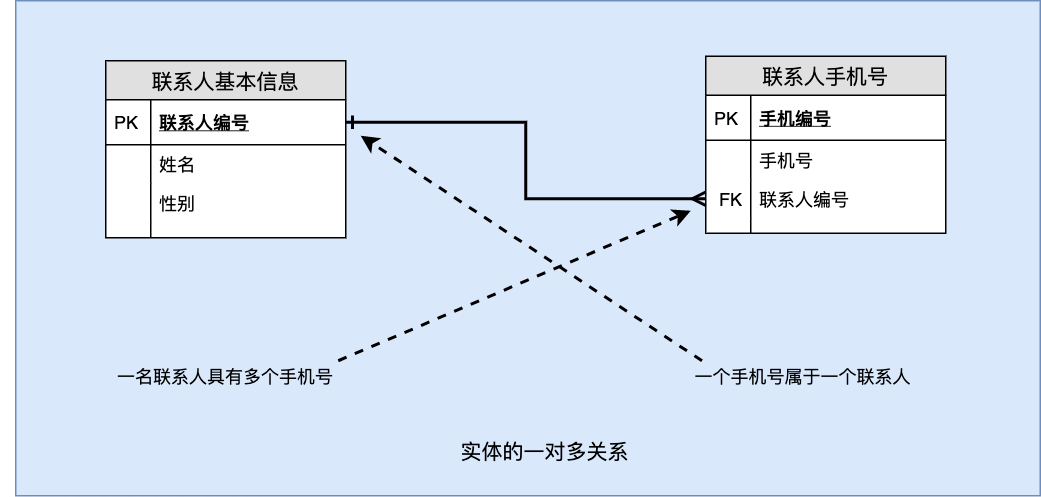
4.2.2 一对多关系
原表,借用以上联系人例子(需要记录一个联系人的所有手机号,即一个联系人拥有多个手机号,而一个手机号只属于一个联系人):
| 编号 | 姓名 | 性别 | 手机号 |
|---|---|---|---|
| 0356 | 张雷 | 男 | 13889876521 |
| 0356 | 张雷 | 男 | 13954387655 |
| 0356 | 张雷 | 男 | 13317685633 |
拆分为两张表:
联系人基本信息
| 编号 | 姓名 | 性别 |
|---|---|---|
| 0356 | 张雷 | 男 |
| 0388 | 李妙 | 女 |
联系人手机号
| 编号 | 手机号 | 联系人编号 |
|---|---|---|
| 1 | 13954387655 | 0356 |
| 2 | 13889876521 | 0356 |
| 3 | 18787675499 | 0388 |
| 4 | 13317685633 | 0356 |
此表中的“联系人编号”是外键,参照表“联系人”中的“编号(主键)”。此关系下的外键的值可以重复出现,是否可以为“空”要根据具体情况来决定。
在做各种查询和统计的时候,如果涉及到两张表上的数据,先用两张表结合起来得到“原表”那样的“结果集”,再在此“结果集”上做查询和统计。
ER 图:
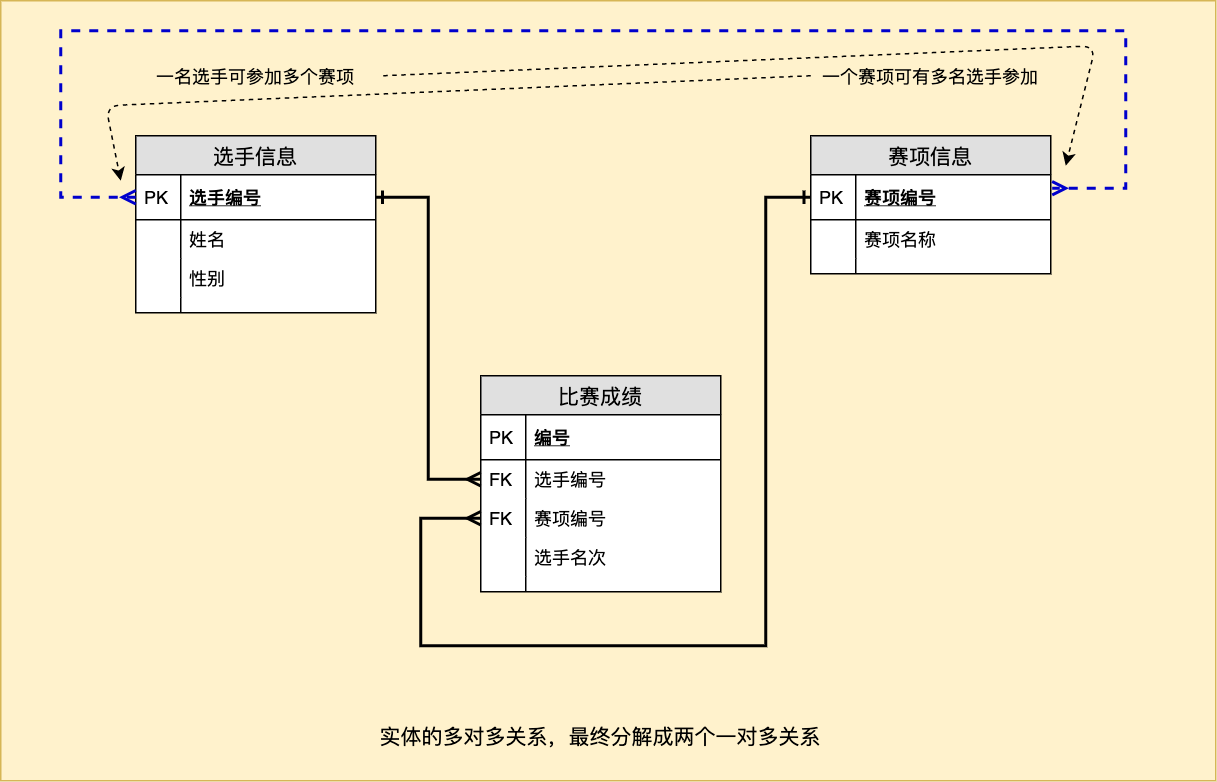
4.2.3 多对多关系
一个选手可以参加多个赛项,一个赛项可有多个选手参加。
原表(大量重复数据,占用存储空间,且有数据不一致的可能):
| 选手编号 | 姓名 | 性别 | 赛项编号 | 赛项名称 | 选手名次 |
|---|---|---|---|---|---|
| 0101 | 王明 | 男 | 001 | 100 米短跑男子组 | 3 |
| 0102 | 李超 | 男 | 005 | 跳高男子组 | 1 |
| 0101 | 王明 | 男 | 005 | 跳高男子组 | 3 |
| 0102 | 李超 | 男 | 001 | 100 米短跑男子组 | 2 |
拆分成三张表:
选手信息
| 选手编号 | 姓名 | 性别 |
|---|---|---|
| 0101 | 王明 | 男 |
| 0102 | 李超 | 男 |
赛项信息
| 赛项编号 | 赛项名称 |
|---|---|
| 001 | 100 米短跑男子组 |
| 005 | 跳高男子组 |
选手成绩
| 序号 | 选手编号 | 赛项编号 | 选手名次 |
|---|---|---|---|
| 1 | 0101 | 001 | 3 |
| 2 | 0102 | 005 | 1 |
| 3 | 0101 | 005 | 3 |
| 4 | 0102 | 001 | 2 |
上表中“选手编号”和“赛项编号”的组合值应该唯一(不能出现重复),且二者都是外键,都不应该出现“空值”。
在做各种查询和统计的时候,如果涉及到多张表上的数据,先用三张表结合起来得到“原表”那样的“结果集”,再在此“结果集”上做查询和统计。
ER图:
第五章 案例一 单表:雇员信息
数据库名称: c1_emp_db( 备份下载页面)
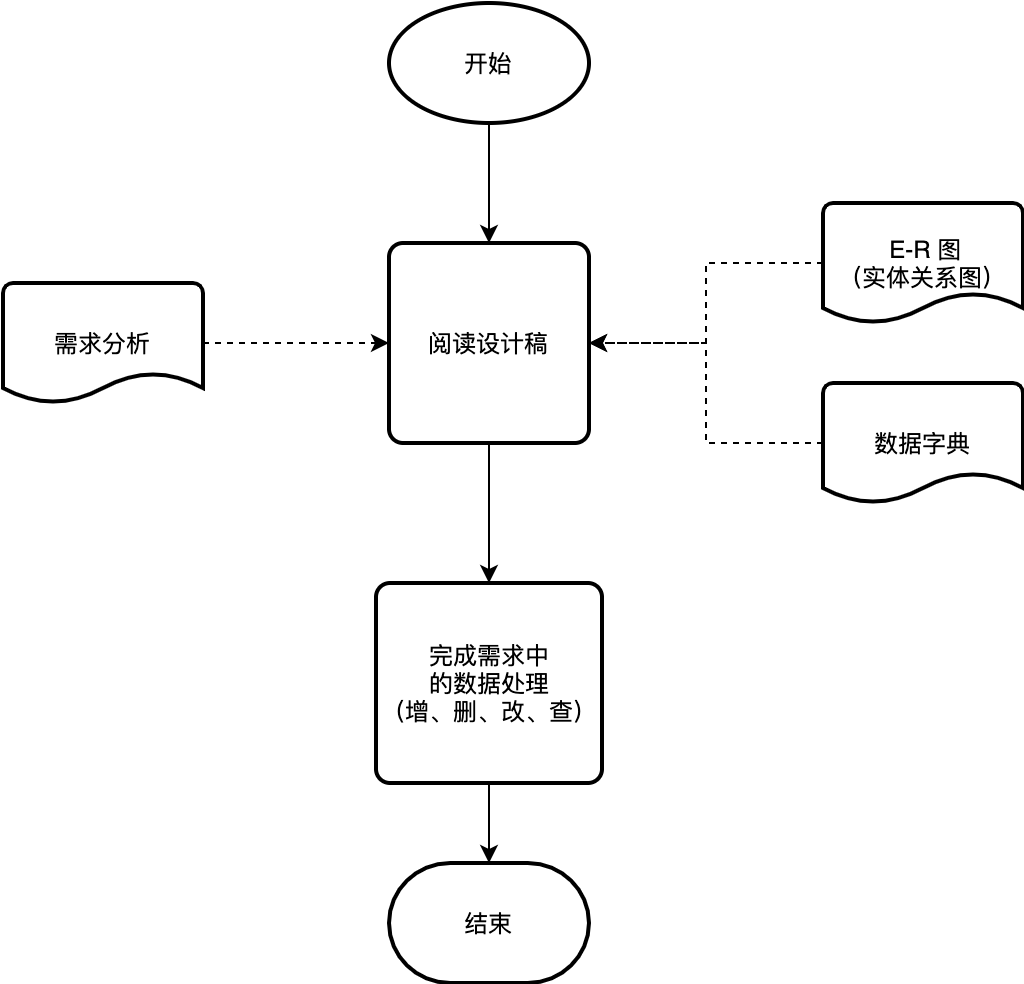
5.1 解读设计稿
5.1.1 E-R图(实体关系图)
实体(Entity)
数据库里的每一张表都存储了描述某个事物的信息,我们把这被描述的事物叫“实体”。
E-R 图
实体-关系图,用于描述各个实体之间的依赖关系。
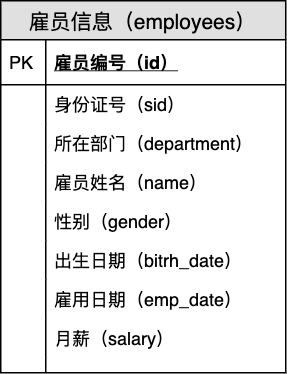
5.1.2 数据字典
数据字典
用于详细数据库中的各个元素,包括对实体、触发器、视图、函数与存储过程等的详细定义。
(1)表定义
表名:雇员信息( employees)
| 序号 | 列名 | 英文名 | 数据类型 | 必填? | 关键列 | 默认值 | 其它说明 |
|---|---|---|---|---|---|---|---|
| 1 | 雇员编号 | id | 无符号大整数 | BIGINT UNSIGNED | ✓ | 主要 | NULL | 自动增长 |
| 2 | 身份证号 | sid | 定长字符串(18)| CHAR(18) | ✓ | 唯一 | NULL | |
| 3 | 所在部门 | department | 变长字符串(50)| VARCHAR(50) | NULL | |||
| 4 | 雇员姓名 | name | 变长字符串(50)| VARCHAR(50) | ✓ | NULL | ||
| 5 | 性别 | gender | 定长字符串(1)| CHAR(1) | '男' | 取值限于「男」、「女」 | ||
| 6 | 出生日期 | birth_date | 日期 | date | NULL | |||
| 7 | 雇用日期 | emp_date | 日期 | date | NULL | |||
| 8 | 月薪 | salary | 无符号小数(8 位数字,其中两位小数)| decimal(10,2) unsigned | 0.00 |
(2)触发器
触发器(trigger)
是一段 SQL 语言程序,在表的数据变动时会被自动触发执行。常常用来保证数据的一致性。
表名:雇员信息( employees)
| 序号 | 名称 | 时机 | 功能 | 其它 |
|---|---|---|---|---|
| 1 | trigger_for_ins | 插入前 | 根据身份证号取出出生日期与性别信息填入相应列, 以保证出生日期和性别与身份证上的信息一致。 |
|
| 2 | trigger_for_upd | 更新前 | 同上 |
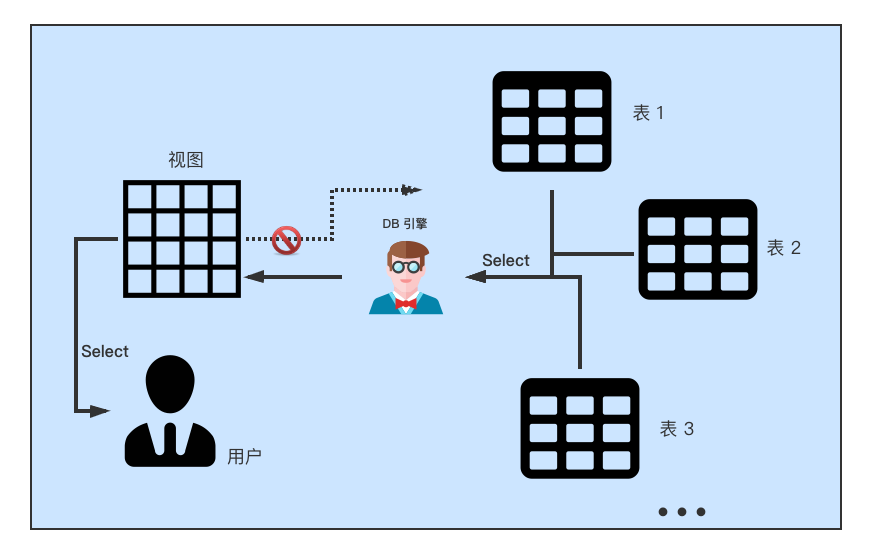
(3)视图
视图(view)
相当于一个查看数据的窗口,其中的列可以来自多个表。视图中的数据是只读的。视图一般用于组织来自多个表的数据的结果集供用户读取。
视图名称:
| 序号 | 列名 | 英文名 | 来自 | 其它说明 |
|---|---|---|---|---|
(4)存储过程与函数
存储过程(stored procedure)
被存储的一段 SQL 程序,在需要时可被执行完成特定任务。存储过程可返回结果集。
函数(function)
被存储的一段 SQL 程序,在需要时可被执行完成特定任务。函数只能返回单个结果数据。
| 序号 | 名称 | 功能 | 返回值 | 其它 |
|---|---|---|---|---|
(5)用户及权限
| 用户名 | 登录位置 | 初始密码 | 权限说明 |
|---|---|---|---|
| c1_emp_db_admin | 所有 | 000000 | 对数据库具有所有权限 |
| c1_emp_db_user | 所有 | 000000 | 对数据库表具有增、删、改、查权限 |
5.1.3 需求分析中的数据查询需求
- 能够按以下指定条件查询筛选记录;
- 列出公司的所有部门
- 按姓名查找员工
- 查找某年龄段的员工并按年龄进行升序、降序排序
- 查找某月薪段的员工并按月薪进行升序、降序排序
- 找出最近一年入职的所有员工
- 能够按以下指定条件统计信息
- 按部门统计员工人数、月薪总额及平均月薪;
- 按部门统计员工的平均年龄
5.2 查看数据
5.2.1 查看表的信息
列出当前数据库的所有表:
show tables;show full tables; -- 可区分普通表和视图
查看表(比如表: employees)的结构信息:
describe `employees`; -- 可用简短方式 desc
查看表(比如表:employees)的建立脚本:
show create table `employees`;
5.2.2 查看所有数据
语法:
select 逗号分隔的列名列表 from 表名;
其中,逗号“分隔的列名列表”可以是全部列也可以是部分列,全部列也可用 * 号代替。
select `id`,`sid`,`name`,`gender`,`birth_date`,`emp_date`,`salary`from `employees`;
select:选择,from: 从
或:
select * from `employees`;
5.2.3 记录排序
查看所有记录并按月薪从高到低排序。
select * from `employees` order by `salary` desc;
order: 排序
by: 依据
desc: descend 下降
查看所有记录并按月薪从低到高排序。
select * from `employees` order by `salary` asc;
asc: ascend, 上升。默认,可省略
查看所有记录并按姓名拼音升序(a~z)排序。
select *from `employees`order by convert(`name` using gbk);
convert: 转换
using: 使用
gbk: 汉字内码扩展规范名称
5.2.4 修改返回的列名
select `id` as `编号`, `name` as `姓名`, `department` as `部门`, `salary` as `月薪`from `employees`;
5.2.5 限定返回的记录数
select * from `employees` limit 10;
limit: 限定,极限
5.2.6 指定跨过的记录数
select * from `employees` limit 30, 10;
或:
select * from `employees` limit 10 offset 30;
5.2.7返回不重复的数据
查看表中的所有部门(不重复):
select distinct `departmen`t from `employees`;
distinct: 截然不同的
- 能够按以下指定条件查询筛选记录;
- 列出公司的所有部门
- 按姓名查找
- 查找某年龄段的员工并按年龄进行升序、降序排序
- 查找某月薪段的员工并按月薪进行升序、降序排序
- 找出最近一年入职的所有员工
- 能够按以下指定条件统计信息
- 按部门统计员工人数、月薪总额及平均月薪;
- 按部门统计员工的平均年龄
5.2.8 筛选符合条件的记录
找出姓名包含“志”字的员工。
select * from `employees` where `name` like '%志%';
找出姓名开始于“李”的员工。
select * from `employees` where `name` like '田%';
找出姓名结尾是“明”的员工。
select * from `employees` where `name` like '%明';
- 能够按以下指定条件查询筛选记录;
- 列出公司的所有部门
- 按姓名查找员工
- 查找某年龄段的员工并按年龄进行升序、降序排序
- 查找某月薪段的员工并按月薪进行升序、降序排序
- 找出最近一年入职的所有员工
- 能够按以下指定条件统计信息
- 按部门统计员工人数、月薪总额及平均月薪;
- 按部门统计员工的平均年龄
选出月薪不低于 3000 且不高于 5000 的雇员并按月薪降序排序。
select * from `employees`where `salary`>=3000 and `salary`<=5000order by `salary` desc;-- 或者select * from `employees`where `salary` between 3000 and 5000order by `salary` desc;
where: 哪里;在那里(在表那里)
- 能够按以下指定条件查询筛选记录;
- 列出公司的所有部门
- 按姓名查找员工
- 查找某年龄段的员工并按年龄进行升序、降序排序
- 查找某月薪段的员工并按月薪进行升序、降序排序
- 找出最近一年入职的所有员工
- 能够按以下指定条件统计信息
- 按部门统计员工人数、月薪总额及平均月薪;
- 按部门统计员工的平均年龄
选出月薪不低于 3000 的男性雇员。
select * from `employees`where `salary`>=3000 and `gender`='男';
5.3 统计与计算数据
5.3.1 统计
(1)统计雇员总数
select count(*) from `employees`;
count:计数
(2)统计月薪总额
select sum(`salary`) from `employees`;
sum:总计,总和
(3)计算月薪平均值
select avg(`salary`) from `employees`;
avg: average, 平均值
同时统计以上三项数据
select count(*) as `雇员数`, sum(`salary`) as `月薪总额`, avg(`salary`) as `平均月薪` from `employees`;
(4)按部门分组统计
select department as 部门, count(*) as 雇员数, sum(salary) as 月薪总额, avg(salary) as 平均月薪 from employees group by department;
- 能够按以下指定条件查询筛选记录;
- 列出公司的所有部门
- 按姓名查找员工
- 查找某年龄段的员工并按年龄进行升序、降序排序
- 查找某月薪段的员工并按月薪进行升序、降序排序
- 找出最近一年入职的所有员工
- 能够按以下指定条件统计信息
- 按部门统计员工人数、月薪总额及平均月薪;
- 按部门统计员工的平均年龄
5.3.2 计算
(1)在查询输出中显示员工的年龄
select id,name,department,birth_date,TIMESTAMPDIFF(YEAR, birth_date, CURDATE()) as age from employees;
当前日期:CURDATE(),Current Date(当前日期)。
计算两个日期之间的距离:
TIMESTAMPDIFF(时间单位, 日期时间 1, 日期时间 2)
时间单位:FRAC_SECOND(毫秒),SECOND(秒),MINUTE(分),HOUR(小时) ,DAY(天),WEEK(周),MONTH(月),QUARTER(季度), YEAR()。
(2)查找某年龄段的员工并按年龄进行降序排序
查找年龄介于 30 到 40 岁之间的员工并按年龄进行降序排序
select id,name,department,birth_date,TIMESTAMPDIFF(YEAR, birth_date, CURDATE()) as agefrom employeeswhere TIMESTAMPDIFF(YEAR, birth_date, CURDATE()) between 30 and 40order by age desc;
注意: where 子句中不能用列的别名。
- 能够按以下指定条件查询筛选记录;
- 列出公司的所有部门
- 按姓名查找员工
- 查找某年龄段的员工并按年龄进行升序、降序排序
- 查找某月薪段的员工并按月薪进行升序、降序排序
- 找出最近一年入职的所有员工
- 能够按以下指定条件统计信息
- 按部门统计员工人数、月薪总额及平均月薪;
- 按部门统计员工的平均年龄
(3)找出最近一年入职的员工
select * from employeeswhere timestampdiff(DAY,emp_date,curdate())<366;-- 或者select * from employeeswhere emp_date>=date_sub(now(),interval 1 year);
日期减法运算:
date_sub(日期时间,interval 数量 单位)
参见日期减法运算说明
- 能够按以下指定条件查询筛选记录;
- 列出公司的所有部门
- 按姓名查找员工
- 查找某年龄段的员工并按年龄进行升序、降序排序
- 查找某月薪段的员工并按月薪进行升序、降序排序
- 找出最近一年入职的所有员工
- 能够按以下指定条件统计信息
- 按部门统计员工人数、月薪总额及平均月薪;
- 按部门统计员工的平均年龄
(4)统计员工平均年龄
select avg(timestampdiff(YEAR,birth_date,now()))from employees;
- 能够按以下指定条件查询筛选记录;
- 列出公司的所有部门
- 按姓名查找员工
- 查找某年龄段的员工并按年龄进行升序、降序排序
- 查找某月薪段的员工并按月薪进行升序、降序排序
- 找出最近一年入职的所有员工
- 能够按以下指定条件统计信息
- 按部门统计员工人数、月薪总额及平均月薪;
- 按部门统计员工的平均年龄
5.4 增、删、改数据
5.4.1 增加记录
语法:
insert into 表名 [(列名 1,列名 2,...)] values (值 1,值 2,...)[,(值 1,值 2,...), ...];
- 表名后的列名可全部省略,省略时相当于按列自然顺序全部罗列出来了;
- 表名后的列名不用和表中列的自然顺序一致,也不需要全部罗列出来(那些必填的且没有默认值的列一般都要列出来);
- 自动增长的列不需要列出来,当然也可列出来并指定具体值(但值重复会出错),也可指定空值(NULL),这样它会自己填入增长的数值;
- 表名后的列名的顺序必须和 values 后的值的顺序一致,并且一一对应。
插入时可根据需要只罗列出部分列,必须罗列出来的列是:
- 不可为空(NULL)
- 且默认值是 NULL
- 且不是自动增长的列
insert into `employees` (sid, name, department,emp_date,salary) values ('530103198803221221','李倩倩','研发部','2020-02-08',3500), ('530101199511232312','赵全','研发部','2020-02-08',3000);
发现数据库中的性别和出生日期被正确填入了!
这是触发器的作用。
初识触发器:触发器是一段 SQL 程序,它会被设定在某种情况下自动执行,如插入记录前、插入记录后、更新记录前、更新记录后、删除记录前、删除记录后等,用于在这些时间点做一些特定的工作来保证数据的完整性、联动性等。
查看触发器:
-- 列出数据库中的所有触发器show triggers \G-- 查看某个触发器的详细 SQL 定义-- show create trigger 触发器名\GMariaDB [c1_emp_db]> show create trigger trigger_for_ins\G...CREATE DEFINER=`root`@`localhost` TRIGGER trigger_for_insBEFORE INSERTON `employees`FOR EACH ROWBEGINSET NEW.birth_date=CONCAT(SUBSTRING(NEW.sid,7,4),'-',SUBSTRING(NEW.sid,11,2),'-',SUBSTRING(NEW.sid,13,2));IF CAST(SUBSTRING(NEW.sid,17,1) AS INT) % 2 = 0 THENSET NEW.gender = '女';ELSESET NEW.gender = '男';END IF;END...
concat(字符串1, 字符串2, ...) 函数:将逗号分隔的字符串串接起来,构成更长的字符串。如:concat('I ','am ','so ','happy','!') 将构成新的长字符串:'I am so happy!'。
sunstring(字符串, 起始位置, 字符个数) 函数,从字符串中取子串,第一个参数是字符串,第二个参数是起始位置(从1开始),第三个参数是要几个字符,省略则取到末尾。如:substring('I am so happy!', 3, 2) 会取得 'am', substring('I am so happy!', 3) 会取得 'am so happy!'
cast(值 as 类型) 函数,将其中的值转换成其它数据类型,如:cast('123' as integer), 会把字符串 '123' 变成整数数值的 123。
% 运算符,取余数。如 81%2 得到 1,8%3 得到 2。
5.4.2 修改记录
update `employees` set name='杨兰', gender='女' where id=...;
update: 更新
5.4.3 删除记录
(1)删除全部记录
没有确认机会,慎重!慎重!!慎重!!!
delete from employees;
delete: 删除
(2)按条件删除记录
delete from employees where ...;
第六章 案例二 一对多关系:部门与员工管理
数据库: c2_dept_db (备份下载)
6.1 基础知识:表的连接查询
如何解读 E-R图中的连接。
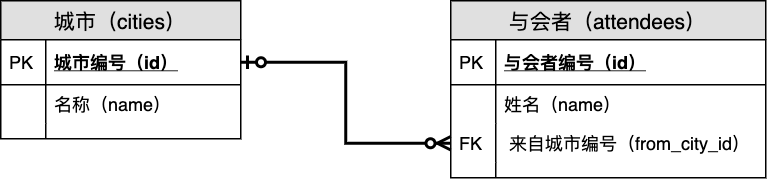
涉及数据库: misc (请用 root 登录使用)
use misc;
城市列表:
MariaDB [misc]> select * from cities;+----+--------+| id | name |+----+--------+| 1 | 昆明 || 2 | 上海 || 3 | 北京 |+----+--------+3 rows in set (0.000 sec)MariaDB [misc]>
与会者列表:
MariaDB [misc]> select * from attendees;+----+-----------+--------------+| id | name | from_city_id |+----+-----------+--------------+| 1 | 李强 | 1 || 2 | 周小妮 | 1 || 3 | 吴汉明 | 2 || 4 | 郑治国 | NULL |+----+-----------+--------------+4 rows in set (0.000 sec)MariaDB [misc]>
与会者的 from_city_id 填的是某个城市的编号(id)。
所以,与会者表参照了城市表。
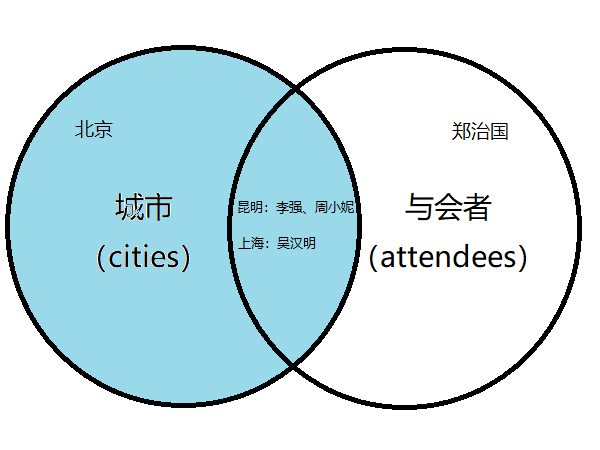
从数据可以看出,一名与会者可对应一个城市(来自一个城市),而一个城市可有多名与会者。城市与与会者二者是一对多的关系。同时我们也看到,有的与会者尚不知来自何处,有的城市根本没有与会者。
一名与会者可有零到一个城市与之对应,而一个城市可有零到多个与会者。我们把城市和与会者的关系叫做:一对多的关系。
现在有四种方法把两个表连接起来显示信息。
注意,以下将用到 left join(左连接) 和 right join(右连接) 来连接两张表。
对应左右连接,谁是左边的表或右边的表?
谁是左边或右边的表?
出现在查询语句中的 from 后第一张表就是左表,后一张表就是右表(因为语句是从左向右写的!!!)。
因此,如果在 from 后把表的位置变动一下,结果就不一样了。
(1)显示所有城市及与会者
注意: 只有昆明、上海有与会者,北京没有。
MariaDB [misc]> select cities.*, attendees.*-> from cities left join attendees-> on cities.id=attendees.from_city_id;+----+--------+------+-----------+--------------+| id | name | id | name | from_city_id |+----+--------+------+-----------+--------------+| 1 | 昆明 | 1 | 李强 | 1 || 1 | 昆明 | 2 | 周小妮 | 1 || 2 | 上海 | 3 | 吴汉明 | 2 || 3 | 北京 | NULL | NULL | NULL |+----+--------+------+-----------+--------------+4 rows in set (0.000 sec)MariaDB [misc]>
from 后有两张表,
citiesleft joinattendees。left join,左边连接,意思是列出所有左边的表(cities)的记录,和对应右边的表(attendees)的记录,没有对应的就填空值(NULL)。
注意结果:
1、城市全部罗列出来了,尽管有的城市(北京)尚没有与会者;
2、与会者并没有全部罗列出来,因为有的与会者尚不知来自何方(郑治国)。
(2)显示城市及所有与会者
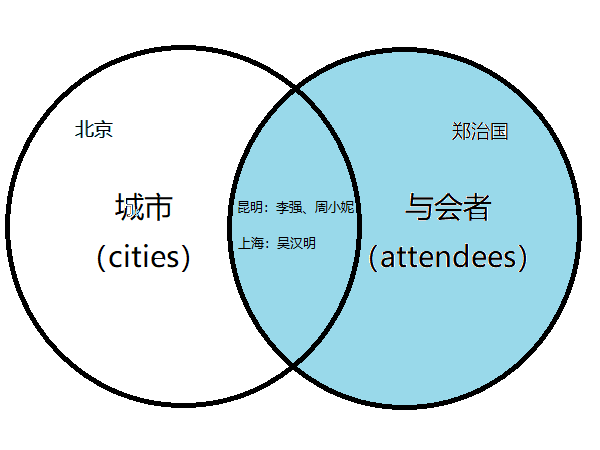
注意: 与会者“郑治国”尚不知来自哪个城市。
以下查询使用了表的别名简化输入。
MariaDB [misc]> select c.*, a.*-> from cities c right join attendees a-> on c.id=a.from_city_id;+------+--------+----+-----------+--------------+| id | name | id | name | from_city_id |+------+--------+----+-----------+--------------+| 1 | 昆明 | 1 | 李强 | 1 || 1 | 昆明 | 2 | 周小妮 | 1 || 2 | 上海 | 3 | 吴汉明 | 2 || NULL | NULL | 4 | 郑治国 | NULL |+------+--------+----+-----------+--------------+4 rows in set (0.000 sec)MariaDB [misc]>
from 后有两张表,cities rigth join attendees。rigth join,右边连接,意思是列出所有右边的表(cities)的记录,和对应左边的表(attendees)的记录,没有对应的就填空值(NULL)。
注意结果:
1、与会者全部罗列出来了,尽管有的与会者(郑治国)尚不知来自何处;
2、城市并没有全部罗列出来,因为有的城市尚没有与会者(北京)。
(3)只显示来自已知城市的与会者
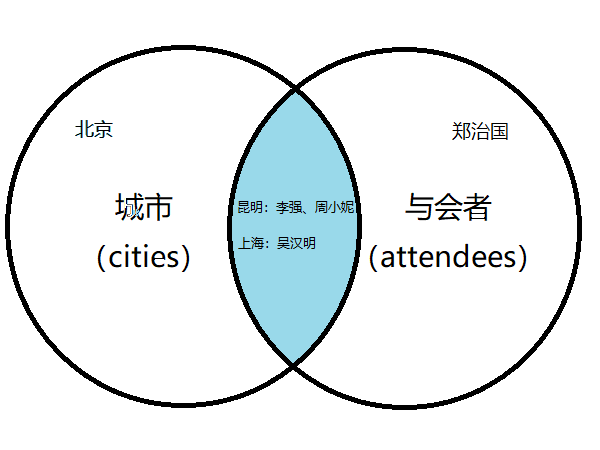
MariaDB [misc]> select c.*, a.*-> from cities c inner join attendees a-> on c.id=a.from_city_id;+----+--------+----+-----------+--------------+| id | name | id | name | from_city_id |+----+--------+----+-----------+--------------+| 1 | 昆明 | 1 | 李强 | 1 || 1 | 昆明 | 2 | 周小妮 | 1 || 2 | 上海 | 3 | 吴汉明 | 2 |+----+--------+----+-----------+--------------+3 rows in set (0.000 sec)MariaDB [misc]>
from 后有两张表,cities inner join attendees。inner join, 内部连接,意思是列出左右边能够连接起来的记录。
注意结果:
1、未知来自何处的与会者(郑治国 )没有被列出来;
2、没有与会者的城市(北京)没有被列出来。
(4)全部城市和与会者都需要显示
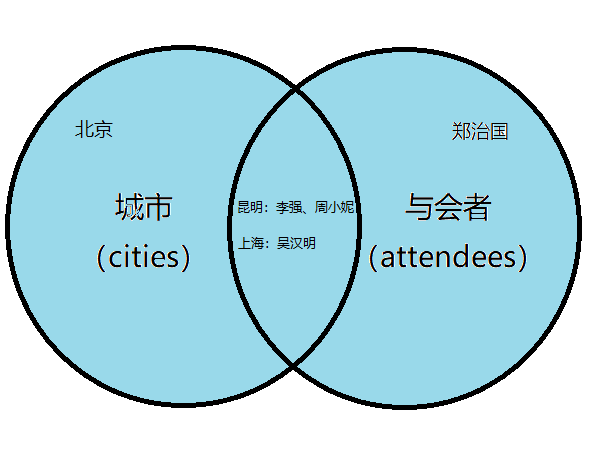
MariaDB [misc]> select c.*,a.*->from cities c left join attendees a on c.id=a.from_city_id->union->select c.*,a.*->from cities c right join attendees a on c.id=a.from_city_id;+------+--------+------+-----------+--------------+| id | name | id | name | from_city_id |+------+--------+------+-----------+--------------+| 1 | 昆明 | 1 | 李强 | 1 || 1 | 昆明 | 2 | 周小妮 | 1 || 2 | 上海 | 3 | 吴汉明 | 2 || 3 | 北京 | NULL | NULL | NULL || NULL | NULL | 4 | 郑治国 | NULL |+------+--------+------+-----------+--------------+5 rows in set (0.001 sec)
6.2 解读设计稿
6.2.1 E-R 图
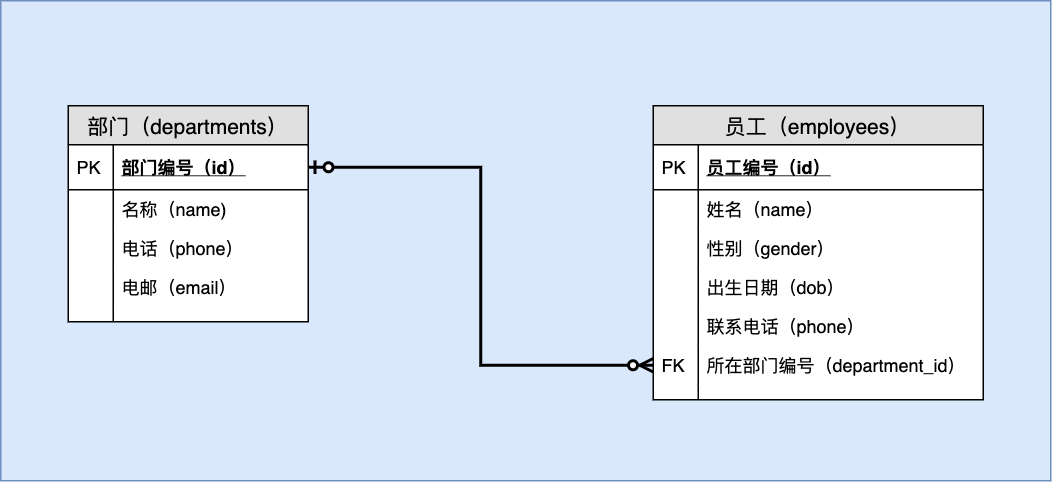
6.2.2 数据字典
(1)表定义
表名:部门( departments)
| 序号 | 列名 | 英文名 | 数据类型 | 必填? | 关键列 | 默认值 | 其它说明 |
|---|---|---|---|---|---|---|---|
| 1 | 部门编号 | id | BIGINT UNSIGNED | ✓ | PK | NULL | AUTO_INCREMENT |
| 2 | 名称 | name | VARCHAR(50) | ✓ | UNI | NULL | |
| 3 | 电话 | phone | VARCHAR(50) | ✓ | NULL | ||
| 4 | 电邮 | VARCHAR(100) | NULL |
表名:员工(employees)
| 序号 | 列名 | 英文名 | 数据类型 | 必填? | 关键列 | 默认值 | 其它说明 |
|---|---|---|---|---|---|---|---|
| 1 | 员工编号 | id | BIGINT UNSIGNED | ✓ | PK | NULL | AUTO_INCREMENT |
| 2 | 姓名 | name | VARCHAR(50) | ✓ | NULL | ||
| 3 | 性别 | gender | CHAR(1) | ✓ | NULL | 限于“男”和“女” | |
| 4 | 出生日期 | birth_date | DATE | NULL | |||
| 5 | 联系电话 | phone | VARCHAR(50) | ✓ | NULL | ||
| 6 | 部门编号 | department_id | BIGINT UNSIGNED | FK | NULL | 参照 departments.id 主表更新时:级联 主表删除时:设置空值 |
(2)触发器
表名:
| 序号 | 名称 | 时机 | 功能 | 其它 |
|---|---|---|---|---|
(3)视图
视图名称:
| 序号 | 列名 | 英文名 | 来自 | 其它说明 |
|---|---|---|---|---|
(4)存储过程与函数
| 序号 | 名称 | 功能 | 输入 | 返回值 | 其它 |
|---|---|---|---|---|---|
(5)用户及权限
| 用户名 | 登录位置 | 初始密码 | 权限说明 |
|---|---|---|---|
| c2_dept_db_admin | 所有 | 000000 | 对数据库具有所有权限 |
| c2_dept_db_user | 所有 | 000000 | 对数据库表具有增、删、改、查权限 |
6.2.3 从需求文档整理的数据查询需求
- 能够按以下指定条件查询筛选记录;
- 列出所有部门及其员工,全部部门都要列出
- 列出所有员工及其所在部门,全部员工都要列出
- 列出所有部门的所有员工,忽略无员工部门及无部门员工
- 合并列出所有部门和所有员工,包括无员工部门及无部门员工
- 列出没尚不属于任何部门的员工
- 列出尚无员工的部门
- 找出“公关部”的所有年龄在 25 到 35 岁的员工,结果中显示年龄并按年龄升序排序
- 列出员工人数在 3 人以上的部门及其员工
- 能够按以下指定条件统计信息
- 按性别分组统计员工人数
- 按出生年月分组统计员工人数
- 按部门统计员工人数(需要显示部门名称)
6.3 数据查询、统计与维护
6.3.1 查询
(1)列出所有部门及其员工,全部部门都要列出
全部部门都要列出,如果部门在 from 子句中位于左边,则是左连接:
select d.*, e.*from departments d left join employees eon d.id=e.department_id;
如果部门在 from 子句中位于右边,则是右连接:
select d.*, e.*from employees e right join departments don d.id=e.department_id;
- 能够按以下指定条件查询筛选记录;
- 列出所有部门及其员工,全部部门都要列出
- 列出所有员工及其所在部门,全部员工都要列出
- 列出所有部门的所有员工,忽略无员工部门及无部门员工
- 合并列出所有部门和所有员工,包括无员工部门及无部门员工
- 列出没尚不属于任何部门的员工
- 列出尚无员工的部门
- 找出“公关部”的所有年龄在 25 到 35 岁的员工,结果中显示年龄并按年龄升序排序
- 列出员工人数在 3 人以上的部门及其员工
- 能够按以下指定条件统计信息
- 按性别分组统计员工人数
- 按出生年月分组统计员工人数
- 按部门统计员工人数(需要显示部门名称)
(2)列出所有员工及其所在部门,全部员工都要列出
全部员工都要列出,如果员工在 from 子句中位于左边,则是左连接:
select d.*, e.*from employees e left join departments don d.id=e.department_id;
如果员工在 from 子句中位于右边,则是右连接:
select d.*, e.*from departments d right join employees eon d.id=e.department_id;
- 能够按以下指定条件查询筛选记录;
- 列出所有部门及其员工,全部部门都要列出
- 列出所有员工及其所在部门,全部员工都要列出
- 列出所有部门的所有员工,忽略无员工部门及无部门员工
- 合并列出所有部门和所有员工,包括无员工部门及无部门员工
- 列出没尚不属于任何部门的员工
- 列出尚无员工的部门
- 找出“公关部”的所有年龄在 25 到 35 岁的员工,结果中显示年龄并按年龄升序排序
- 列出员工人数在 3 人以上的部门及其员工
- 能够按以下指定条件统计信息
- 按性别分组统计员工人数
- 按出生年月分组统计员工人数
- 按部门统计员工人数(需要显示部门名称)
(3)列出所有部门的所有员工,忽略无员工部门及无部门员工
因为只列出有员工的部门和有部门的员工,采用内连接,表的出现顺序无关。
select d.*, e.*from departments d inner join employees eon d.id=e.department_id;
- 能够按以下指定条件查询筛选记录;
- 列出所有部门及其员工,全部部门都要列出
- 列出所有员工及其所在部门,全部员工都要列出
- 列出所有部门的所有员工,忽略无员工部门及无部门员工
- 合并列出所有部门和所有员工,包括无员工部门及无部门员工
- 列出没尚不属于任何部门的员工
- 列出尚无员工的部门
- 找出“公关部”的所有年龄在 25 到 35 岁的员工,结果中显示年龄并按年龄升序排序
- 列出员工人数在 3 人以上的部门及其员工
- 能够按以下指定条件统计信息
- 按性别分组统计员工人数
- 按出生年月分组统计员工人数
- 按部门统计员工人数(需要显示部门名称)
(4)合并列出所有部门和所有员工,包括无员工部门及无部门员工
合并列出,双方内容都需要完全列出,要用完整外连接。在有的数据库系统里,有完整外连接的语句,如:
select d.*, e.*from departments d full outer join employees eon d.id=e.department_id;
在 MariaDB/MySQL 中我们可以用以下语句来实现:
select d.*, e.*from departments d left join employees eon d.id=e.department_idunionselect d.*, e.*from departments d right join employees eon d.id=e.department_id;
- 能够按以下指定条件查询筛选记录;
- 列出所有部门及其员工,全部部门都要列出
- 列出所有员工及其所在部门,全部员工都要列出
- 列出所有部门的所有员工,忽略无员工部门及无部门员工
- 合并列出所有部门和所有员工,包括无员工部门及无部门员工
- 列出没尚不属于任何部门的员工
- 列出尚无员工的部门
- 找出“公关部”的所有年龄在 25 到 35 岁的员工,结果中显示年龄并按年龄升序排序
- 列出员工人数在 3 人以上的部门及其员工
- 能够按以下指定条件统计信息
- 按性别分组统计员工人数
- 按出生年月分组统计员工人数
- 按部门统计员工人数(需要显示部门名称)
(5)列出没尚不属于任何部门的员工
select * from employees where department_id is null;
- 能够按以下指定条件查询筛选记录;
- 列出所有部门及其员工,全部部门都要列出
- 列出所有员工及其所在部门,全部员工都要列出
- 列出所有部门的所有员工,忽略无员工部门及无部门员工
- 合并列出所有部门和所有员工,包括无员工部门及无部门员工
- 列出没尚不属于任何部门的员工
- 列出尚无员工的部门
- 找出“公关部”的所有年龄在 25 到 35 岁的员工,结果中显示年龄并按年龄升序排序
- 列出员工人数在 3 人以上的部门及其员工
- 能够按以下指定条件统计信息
- 按性别分组统计员工人数
- 按出生年月分组统计员工人数
- 按部门统计员工人数(需要显示部门名称)
(6)列出尚无员工的部门
select * from departmentswhere (select count(*) from employees where department_id=departments.id)=0;
- 能够按以下指定条件查询筛选记录;
- 列出所有部门及其员工,全部部门都要列出
- 列出所有员工及其所在部门,全部员工都要列出
- 列出所有部门的所有员工,忽略无员工部门及无部门员工
- 合并列出所有部门和所有员工,包括无员工部门及无部门员工
- 列出没尚不属于任何部门的员工
- 列出尚无员工的部门
- 找出“公关部”的所有年龄在 25 到 35 岁的员工,结果中显示年龄并按年龄升序排序
- 列出员工人数在 3 人以上的部门及其员工
- 能够按以下指定条件统计信息
- 按性别分组统计员工人数
- 按出生年月分组统计员工人数
- 按部门统计员工人数(需要显示部门名称)
(7)找出“公关部”的所有年龄在 25 到 35 岁的员工,结果中显示年龄并按年龄升序排序
因为查询涉及两张表的内容,查询中需要将两张表连接得到一个结果集,再从结果集中筛选记录。两步是并到同一语句中的。
select e.id, e.name, e.birth_date,timestampdiff(YEAR, e.birth_date, curdate()) as age, d.namefrom departments d inner join employees eon e.department_id=d.id -- 到此为止为连接两表得到一个结果集where d.name='公关部' and -- 过滤结果集timestampdiff(YEAR, e.birth_date, curdate()) between 25 and 35order by age asc -- 排序;
- 能够按以下指定条件查询筛选记录;
- 列出所有部门及其员工,全部部门都要列出
- 列出所有员工及其所在部门,全部员工都要列出
- 列出所有部门的所有员工,忽略无员工部门及无部门员工
- 合并列出所有部门和所有员工,包括无员工部门及无部门员工
- 列出没尚不属于任何部门的员工
- 列出尚无员工的部门
- 找出“公关部”的所有年龄在 25 到 35 岁的员工,结果中显示年龄并按年龄升序排序
- 列出员工人数在 3 人以上的部门及其员工
- 能够按以下指定条件统计信息
- 按性别分组统计员工人数
- 按出生年月分组统计员工人数
- 按部门统计员工人数(需要显示部门名称)
(8)列出员工人数在 3 人以上的部门及其员工
因为查询涉及两张表的内容,查询方法同上。
select e.*, d.namefrom departments d inner join employees eon e.department_id=d.id -- 到此为止为连接两表得到一个结果集where (select count(*) from employees e1 where e1.department_id=d.id) > 3;
- 能够按以下指定条件查询筛选记录;
- 列出所有部门及其员工,全部部门都要列出
- 列出所有员工及其所在部门,全部员工都要列出
- 列出所有部门的所有员工,忽略无员工部门及无部门员工
- 合并列出所有部门和所有员工,包括无员工部门及无部门员工
- 列出没尚不属于任何部门的员工
- 列出尚无员工的部门
- 找出“公关部”的所有年龄在 25 到 35 岁的员工,结果中显示年龄并按年龄升序排序
- 列出员工人数在 3 人以上的部门及其员工
- 能够按以下指定条件统计信息
- 按性别分组统计员工人数
- 按出生年月分组统计员工人数
- 按部门统计员工人数(需要显示部门名称)
6.3.2 统计
(1)按性别分组统计员工人数
select gender, count(*)from employeesgroup by gender;
- 能够按以下指定条件查询筛选记录;
- 列出所有部门及其员工,全部部门都要列出
- 列出所有员工及其所在部门,全部员工都要列出
- 列出所有部门的所有员工,忽略无员工部门及无部门员工
- 合并列出所有部门和所有员工,包括无员工部门及无部门员工
- 列出没尚不属于任何部门的员工
- 列出尚无员工的部门
- 找出“公关部”的所有年龄在 25 到 35 岁的员工,结果中显示年龄并按年龄升序排序
- 列出员工人数在 3 人以上的部门及其员工
- 能够按以下指定条件统计信息
- 按性别分组统计员工人数
- 按出生年月分组统计员工人数
- 按部门统计员工人数(需要显示部门名称)
(2)按出生年月分组统计员工人数
select concat(year(birth_date),'-',month(birth_date)) as 出生年月, count(*) as 人数from employeesgroup by 出生年月;
- 能够按以下指定条件查询筛选记录;
- 列出所有部门及其员工,全部部门都要列出
- 列出所有员工及其所在部门,全部员工都要列出
- 列出所有部门的所有员工,忽略无员工部门及无部门员工
- 合并列出所有部门和所有员工,包括无员工部门及无部门员工
- 列出没尚不属于任何部门的员工
- 列出尚无员工的部门
- 找出“公关部”的所有年龄在 25 到 35 岁的员工,结果中显示年龄并按年龄升序排序
- 列出员工人数在 3 人以上的部门及其员工
- 能够按以下指定条件统计信息
- 按性别分组统计员工人数
- 按出生年月分组统计员工人数
- 按部门统计员工人数(需要显示部门名称)
(3) 按部门统计员工人数(需要显示部门名称)
因为统计涉及两张表的内容,需要将两张表连接得到一个结果集,再从结果集中进行统计。两步是并到同一语句中的。
select d.name, count(*)from departments d left join employees eon e.department_id=d.id -- 连接两表得到一个结果集group by d.id -- 分组统计;
- 能够按以下指定条件查询筛选记录;
- 列出所有部门及其员工,全部部门都要列出
- 列出所有员工及其所在部门,全部员工都要列出
- 列出所有部门的所有员工,忽略无员工部门及无部门员工
- 合并列出所有部门和所有员工,包括无员工部门及无部门员工
- 列出没尚不属于任何部门的员工
- 列出尚无员工的部门
- 找出“公关部”的所有年龄在 25 到 35 岁的员工,结果中显示年龄并按年龄升序排序
- 列出员工人数在 3 人以上的部门及其员工
- 能够按以下指定条件统计信息
- 按性别分组统计员工人数
- 按出生年月分组统计员工人数
- 按部门统计员工人数(需要显示部门名称)
6.3.3 数据维护
添加一名员工到“市场部”。
insert into employees(name,gender,birth_date,phone,department_id)values ('王小小','女','1998-12-20','13087676754',(select id from department where name='市场部'));
练习:
(1)列出员工人数在 5 人以下的部门。
(2)更新一条部门的 id 号,观察所属员工的部门 id 是否一起发生了变化。
(3)用一条语句新增两个部门,"信息技术部"和"采购部"。
(4)各添加一名员工到“信息技术部”和“采购部”。
(5)把第 10 号员工的姓名改成'顾晓',出生年月改成'1988-10-10'。
第七章 案例三 一对多关系特例:一对一 会员管理
数据库: c3_member_db (备份下载)
一对一关系是一对多关系的一个特例,它是通过限定外键为唯一值来达到的。一对一关系的两个实体通常用于描述同一事物的不同侧面,便于分离业务关注点及针对用户分配不同的处理和访问权限。
7.1 解读设计稿
7.1.1 E-R 图
连接示意图

标准 E-R 图

7.1.2 数据字典
(1)表定义
表名:会员信息( members)
| 序号 | 列名 | 英文名 | 数据类型 | 必填? | 关键列 | 默认值 | 其它说明 |
|---|---|---|---|---|---|---|---|
| 1 | 会员编号 | id | BIGINT UNSIGNED | ✓ | PK | NULL | AUTO_INCREMENT |
| 2 | 姓名 | name | VARCHAR(50) | ✓ | IDX | NULL | |
| 3 | 性别 | gender | CHAR(1) | ✓ | '女' | 限于“男”、“女” | |
| 4 | 联系电话 | phone | VARCHAR(50) | ✓ | |||
| 5 | 入会日期 | join_date | DATE | ✓ |
表名:会员详情( member_details)
| 序号 | 列名 | 英文名 | 数据类型 | 必填? | 关键列 | 默认值 | 其它说明 |
|---|---|---|---|---|---|---|---|
| 1 | 详情编号 | id | BIGINT UNSIGNED | ✓ | PK | NULL | AUTO_INCREMENT |
| 2 | 身份证号 | sid | CHAR(18) | ✓ | NULL | ||
| 3 | 住址 | address | VARCHAR(100) | NULL | |||
| 4 | 联系人 | contact | VARCHAR(50) | NULL | |||
| 5 | 联系人电话 | contact_phone | VARCHAR(50) | NULL | |||
| 6 | 会员编号 | member_id | BIGINT UNSIGNED | ✓ | FK UNI |
NULL | 参照 members.id 主表更新时:级联 主表删除时:级联 |
(2)触发器
表名:雇员信息(member_details)
| 序号 | 名称 | 时机 | 功能 | 其它 |
|---|---|---|---|---|
| 1 | ins_upd_gender | 插入后 | 根据身份证号取出性别信息填入members 表的相应列 | |
| 2 | upd_upd_gender | 更新后 | 根据身份证号取出性别信息填入members 表的相应列 |
(3)视图
视图名称:member_infos
| 序号 | 列名 | 英文名 | 来自 | 其它说明 |
|---|---|---|---|---|
| 1 | 会员编号 | id | 表:members | |
| 2 | 身份证号 | sid | 表:member_details | |
| 2 | 姓名 | name | 表:member | |
| 3 | 性别 | gender | 表:members | |
| 4 | 年龄 | age | 函数:get_member_age | 根据 member_deatils.sid 计算 |
| 5 | 住址 | adderss | 表:member_details | |
| 6 | 电话 | phone | 表:members | |
| 7 | 入会日期 | join_date | 表:members | |
| 8 | 联系人 | contact | 表:member_details | |
| 9 | 联系人电话 | contact_phone | 表:member_details |
(4)存储过程与函数
| 序号 | 名称 | 功能 | 输入 | 返回值 | 其它 |
|---|---|---|---|---|---|
| 1 | get_member_age | 获取会员年龄 | 身份证号:CHAR(18) | 年龄:TINYINT UNDSIGNED | 函数 |
(5)用户及权限
| 用户名 | 登录位置 | 初始密码 | 权限说明 |
|---|---|---|---|
| c3_member_db_admin | 所有 | 000000 | 对数据库具有所有权限 |
| c3_member_db_user | 所有 | 000000 | 对数据库表具有增、删、改、查权限 |
7.1.3 整理的数据查询需求
- 能够按以下指定条件查询筛选记录;
- 根据性别列出所有会员,并列出其详情
- 按姓名查找会员,并列出其详情
- 查找某年龄段的会员(含详情)并按年龄进行升序、降序排序
- 找出入会一年以上的会员(含详情)
- 找出尚没有“会员详情”的会员
- 能够按以下指定条件统计信息
- 按性别分组统计会员人数
- 按年龄(10+,20+,30+,40+ ...)分组统计会员人数
- 按入会年份统计会员人数
7.2 查询记录
7.2.1 根据性别列出所有会员,并列出其详情
select m.*, d.*from members m left join member_details don m.id=d.member_idwhere m.gender='男';
- 能够按以下指定条件查询筛选记录;
- 根据性别列出所有会员,并列出其详情
- 按姓名查找会员,并列出其详情
- 查找某年龄段的会员(含详情)并按年龄进行升序、降序排序
- 找出入会一年以上的会员(含详情)
- 找出尚没有“会员详情”的会员
- 能够按以下指定条件统计信息
- 按性别分组统计会员人数
- 按年龄(10+,20+,30+,40+ ...)分组统计会员人数
- 按入会年份统计会员人数
7.2.2 按姓名查找会员,并列出其详情
select m.*, d.*from members m left join member_details don m.id=d.member_idwhere m.name like '%志%';
- 能够按以下指定条件查询筛选记录;
- 根据性别列出所有会员,并列出其详情
- 按姓名查找会员,并列出其详情
- 查找某年龄段的会员(含详情)并按年龄进行升序、降序排序
- 找出入会一年以上的会员(含详情)
- 找出尚没有“会员详情”的会员
- 能够按以下指定条件统计信息
- 按性别分组统计会员人数
- 按年龄(10+,20+,30+,40+ ...)分组统计会员人数
- 按入会年份统计会员人数
7.2.3 查找某年龄段的会员(含详情)并按年龄进行升序、降序排序
查找 30到 40 岁之间的会员并按年龄升序排序。
使用函数 get_member_age()
select m.*, d.*, get_member_age(d.sid) as agefrom members m left join member_details don m.id=d.member_idwhere get_member_age(d.sid) between 30 and 40;
使用视图 member_infos
select * from member_infos where age between 30 and 40;
- 能够按以下指定条件查询筛选记录;
- 根据性别列出所有会员,并列出其详情
- 按姓名查找会员,并列出其详情
- 查找某年龄段的会员(含详情)并按年龄进行升序、降序排序
- 找出入会一年以上的会员(含详情)
- 找出尚没有“会员详情”的会员
- 能够按以下指定条件统计信息
- 按性别分组统计会员人数
- 按年龄(10+,20+,30+,40+ ...)分组统计会员人数
- 按入会年份统计会员人数
7.2.4 找出入会一年以上的会员(含详情)
利用视力 member_infos
select * from member_infoswhere join_date < date_sub(now(), interval 1 year);
- 能够按以下指定条件查询筛选记录;
- 根据性别列出所有会员,并列出其详情
- 按姓名查找会员,并列出其详情
- 查找某年龄段的会员(含详情)并按年龄进行升序、降序排序
- 找出入会一年以上的会员(含详情)
- 找出尚没有“会员详情”的会员
- 能够按以下指定条件统计信息
- 按性别分组统计会员人数
- 按年龄段(10+,20+,30+,40+ ...)分组统计会员人数
- 按入会年份统计会员人数
7.2.5 找出尚没有“会员详情”的会员
子查询
出现在查询语句里作为查询语句的一部分的一条完整的查询语句。
select * from memberswhere (select count(*) from member_details where member_id=members.id)=0;
- 能够按以下指定条件查询筛选记录;
- 根据性别列出所有会员,并列出其详情
- 按姓名查找会员,并列出其详情
- 查找某年龄段的会员(含详情)并按年龄进行升序、降序排序
- 找出入会一年以上的会员(含详情)
- 找出尚没有“会员详情”的会员
- 能够按以下指定条件统计信息
- 按性别分组统计会员人数
- 按年龄段(10+,20+,30+,40+ ...)分组统计会员人数
- 按入会年份统计会员人数
练习
1、找出入会一个月内的会员(含详情)
2、找出年龄在 30 岁以上的女性会员(含详情)
7.3 统计与计算
7.3.1 按性别分组统计会员人数
select gender, count(*) from membersgroup by gender;
- 能够按以下指定条件查询筛选记录;
- 根据性别列出所有会员,并列出其详情
- 按姓名查找会员,并列出其详情
- 查找某年龄段的会员(含详情)并按年龄进行升序、降序排序
- 找出入会一年以上的会员(含详情)
- 找出尚没有“会员详情”的会员
- 能够按以下指定条件统计信息
- 按性别分组统计会员人数
- 按年龄(10+,20+,30+,40+ ...)分组统计会员人数
- 按入会年份统计会员人数
7.3.2 按年龄段(10+,20+,30+,40+ ...)分组统计会员人数
利用视图 member_infos:
select floor(age/10)*10 as age_range, count(*) from member_infosgroup by age_range;
- 能够按以下指定条件查询筛选记录;
- 根据性别列出所有会员,并列出其详情
- 按姓名查找会员,并列出其详情
- 查找某年龄段的会员(含详情)并按年龄进行升序、降序排序
- 找出入会一年以上的会员(含详情)
- 找出尚没有“会员详情”的会员
- 能够按以下指定条件统计信息
- 按性别分组统计会员人数
- 按年龄(10+,20+,30+,40+ ...)分组统计会员人数
- 按入会年份统计会员人数
7.3.3 按入会年份统计会员人数
select year(join_date) as year, count(*)from membersgroup by year;
- 能够按以下指定条件查询筛选记录;
- 根据性别列出所有会员,并列出其详情
- 按姓名查找会员,并列出其详情
- 查找某年龄段的会员(含详情)并按年龄进行升序、降序排序
- 找出入会一年以上的会员(含详情)
- 找出尚没有“会员详情”的会员
- 能够按以下指定条件统计信息
- 按性别分组统计会员人数
- 按年龄(10+,20+,30+,40+ ...)分组统计会员人数
- 按入会年份统计会员人数
练习
1、列出所有会员编号、身份证号、姓名、性别、年龄(用函数及相关表、用视图各实现一次)。
7.4 增、改、删
7.4.1 增加:确认一对一关系
给已经有会员详情的会员记录再添加一条会员详情。
MariaDB [db_2_2]> select * from member_details where member_id=10\G*************************** 1. row ***************************id: 7sid: 44132319940218504Xaddress: 贵阳秀英区contact: 何辉contact_phone: 13165155723member_id: 101 row in set (0.000 sec)MariaDB [db_2_2]> insert into member_details(sid,address,member_id)-> values('520101198012212451','昆明五华区',10);ERROR 1062 (23000): Duplicate entry '10' for key 'member_details_member_id_unique'MariaDB [db_2_2]>
ERROR: 错误
Duplicate entry: 重复的条目
unique: 独一的,唯一的
7.4.2 增加:确认增加一条会员详情给一位不存在的会员失败
MariaDB [db_2_2]> insert into member_details(sid,address,member_id)-> values('520101198012212451','昆明五华区',1000);ERROR 1452 (23000): Cannot add or update a child row: a foreign key constraint fails (`db_2_2`.`member_details`, CONSTRAINT `member_details_member_id_foreign` FOREIGN KEY (`member_id`) REFERENCES `members` (`id`) ON DELETE CASCADE ON UPDATE CASCADE)MariaDB [db_2_2]>
7.4.3 修改身份证号:确认更新时触发器产生了作用
select * from members m inner join member_details don m.id = d.member_id;
选其中一条记录进行修改。
update member_details set sid='(身份证号)' where id=编号;
7.4.4 删除会员信息:确认会员详情会被级联删除
select * from members m inner join member_details don m.id = d.member_id;
选其中一条记录进行删除。
delete from members where id=编号;
练习
1、自行增加一条会员记录,并为其添加对应的详情记录。
2、修改一条会员基本信息记录的 ID 号,观察其详情记录的外键变化。
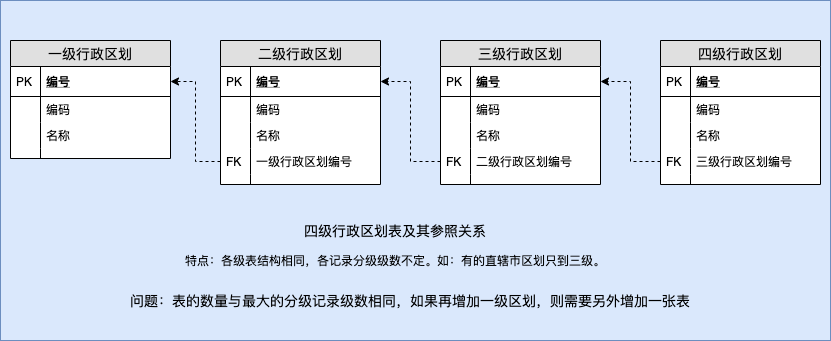
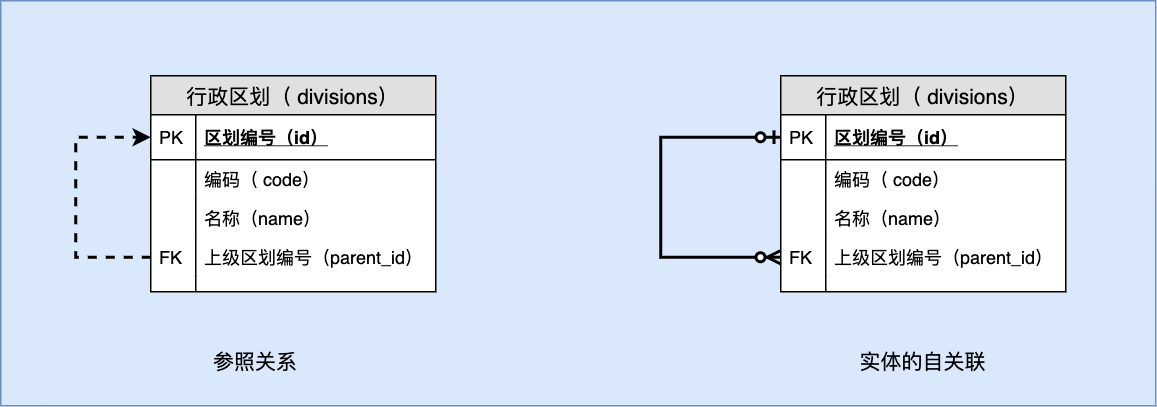
第八章 案例四 一对多自关联:行政区划管理
数据库: c4_division_db 数据库备份
8.1 解读设计稿
8.1.1 E-R 图
8.1.2 数据字典
(1)表定义
表名:区划行政( divisions)
| 序号 | 列名 | 英文名 | 数据类型 | 必填? | 关键列 | 默认值 | 其它说明 |
|---|---|---|---|---|---|---|---|
| 1 | 区划编号 | id | BIGINT UNSIGNED | ✓ | PK | NULL | AUTO_INCREMENT |
| 3 | 编码 | code | CHAR(12) | ✓ | NULL | ||
| 2 | 名称 | name | VARCHAR(100) | ✓ | NULL | ||
| 4 | 上级区划编号 | parent_id | BIGINT UNSIGNED | NULL |
(2)触发器
表名:区划行政( divisions)
| 序号 | 名称 | 时机 | 功能 | 其它 |
|---|---|---|---|---|
(3)视图
视图名称:
| 序号 | 列名 | 英文名 | 来自 | 其它说明 |
|---|---|---|---|---|
(4)存储过程与函数
| 序号 | 名称 | 功能 | 输入 | 返回值 | 其它 |
|---|---|---|---|---|---|
| 1 | get_addr_by_id | 获取地名级联名称 | 区划 ID | VARCHAR(200), 级联名称,如: 云南省>昆明市>盘龙区 |
函数 |
| 2 | get_addr_by_name | 获取一组地名级联名称 | 区划关键字 | 结果集:一组地名级联名称 | 过程 |
(5)用户及权限
| 用户名 | 登录位置 | 初始密码 | 权限说明 |
|---|---|---|---|
| c4_division_db_admin | 所有 | 000000 | 对数据库具有所有权限 |
| c4_division_db_user | 所有 | 000000 | 对数据库表具有增、删、改、查权限 |
8.1.3 从需求文档整理的数据查询需求
能够按以下指定条件查询筛选记录;
- 获取所有顶级行政区划
- 获取所有最末节行政区划
- 根据区划 ID 获取完整的地名级联名称
- 根据区划关键字获取所有相关的地名级联名称
能够按以下指定条件统计信息
- 统计共有几个顶级行政
- 统计共有几个末级行政区划
8.2 数据查询、统计与维护
8.2.1 数据查询
(1)获取所有顶级行政区划
select * from divisions where parent_id is null;
- 能够按以下指定条件查询筛选记录;
- 获取所有顶级行政区划
- 获取所有最末节行政区划
- 根据区划 ID 获取完整的地名级联名称
- 根据区划关键字获取所有相关的地名级联名称
- 能够按以下指定条件统计信息
- 统计共有几个顶级行政
- 统计共有几个末级行政区划
(2)获取所有最末节行政区划
select * from divisions d1where (select count(*) from divisions d2 where d2.parent_id=d1.id)=0;
- 能够按以下指定条件查询筛选记录;
- 获取所有顶级行政区划
- 获取所有最末节行政区划
- 根据区划 ID 获取完整的地名级联名称
- 根据区划关键字获取所有相关的地名级联名称
- 能够按以下指定条件统计信息
- 统计共有几个顶级行政
- 统计共有几个末级行政区划
(3)根据分类 ID 获取完整的地名级联名称
使用函数:get_addr_by_id()
MariaDB [db_2_4]> select get_addr_by_id(30001);+-----------------------------------------+| get_addr_by_id(30001) |+-----------------------------------------+| 广东省>韶关市>曲江区>乌石镇 |+-----------------------------------------+1 row in set (0.000 sec)MariaDB [db_2_4]>
- 能够按以下指定条件查询筛选记录;
- 获取所有顶级行政区划
- 获取所有最末节行政区划
- 根据区划 ID 获取完整的地名级联名称
- 根据区划关键字获取所有相关的地名级联名称
- 能够按以下指定条件统计信息
- 统计共有几个顶级行政
- 统计共有几个末级行政区划
(4)根据类别关键字获取所有相关的地名级联名称
使用存储过程:get_addr_by_name()
MariaDB [db_2_4]> call get_addr_by_name('盘龙');+-------+-----------------------------------------------------------------+| id | address |+-------+-----------------------------------------------------------------+| 42509 | 河南省>驻马店市>确山县>盘龙街道办事处 || 42509 | 湖北省>武汉市>黄陂区>盘龙城经济开发区 || 42509 | 四川省>广元市>利州区>盘龙镇 || 42509 | 四川省>南充市>南部县>盘龙镇 || 42509 | 云南省>昆明市>盘龙区 || 42509 | 云南省>昆明市>盘龙区>盘龙区阿子营街道办事处 || 42509 | 云南省>昆明市>盘龙区>盘龙区滇源街道办事处 || 42509 | 云南省>文山壮族苗族自治州>砚山县>盘龙彝族乡 || 42509 | 重庆市>荣昌区>盘龙镇 || 42509 | 重庆市>云阳县>盘龙街道办事处 |+-------+-----------------------------------------------------------------+10 rows in set (0.011 sec)Query OK, 47 rows affected (0.011 sec)MariaDB [db_2_4]>
- 能够按以下指定条件查询筛选记录;
- 获取所有顶级行政区划
- 获取所有最末节行政区划
- 根据区划 ID 获取完整的地名级联名称
- 根据区划关键字获取所有相关的地名级联名称
- 能够按以下指定条件统计信息
- 统计共有几个顶级行政
- 统计共有几个末级行政区划
8.2.2 统计
(1)统计共有几个顶级行政
select count(*) from divisions where parent_id is null;
- 能够按以下指定条件查询筛选记录;
- 获取所有顶级行政区划
- 获取所有最末节行政区划
- 根据区划 ID 获取完整的地名级联名称
- 根据区划关键字获取所有相关的地名级联名称
- 能够按以下指定条件统计信息
- 统计共有几个顶级行政
- 统计共有几个末级行政区划
(2)统计共有几个末级行政区划
select count(*) from divisions d1where (select count(*) from divisions d2 where d2.parent_id=d1.id)=0;
- 能够按以下指定条件查询筛选记录;
- 获取所有顶级行政区划
- 获取所有最末节行政区划
- 根据区划 ID 获取完整的地名级联名称
- 根据区划关键字获取所有相关的地名级联名称
- 能够按以下指定条件统计信息
- 统计共有几个顶级行政
- 统计共有几个末级行政区划
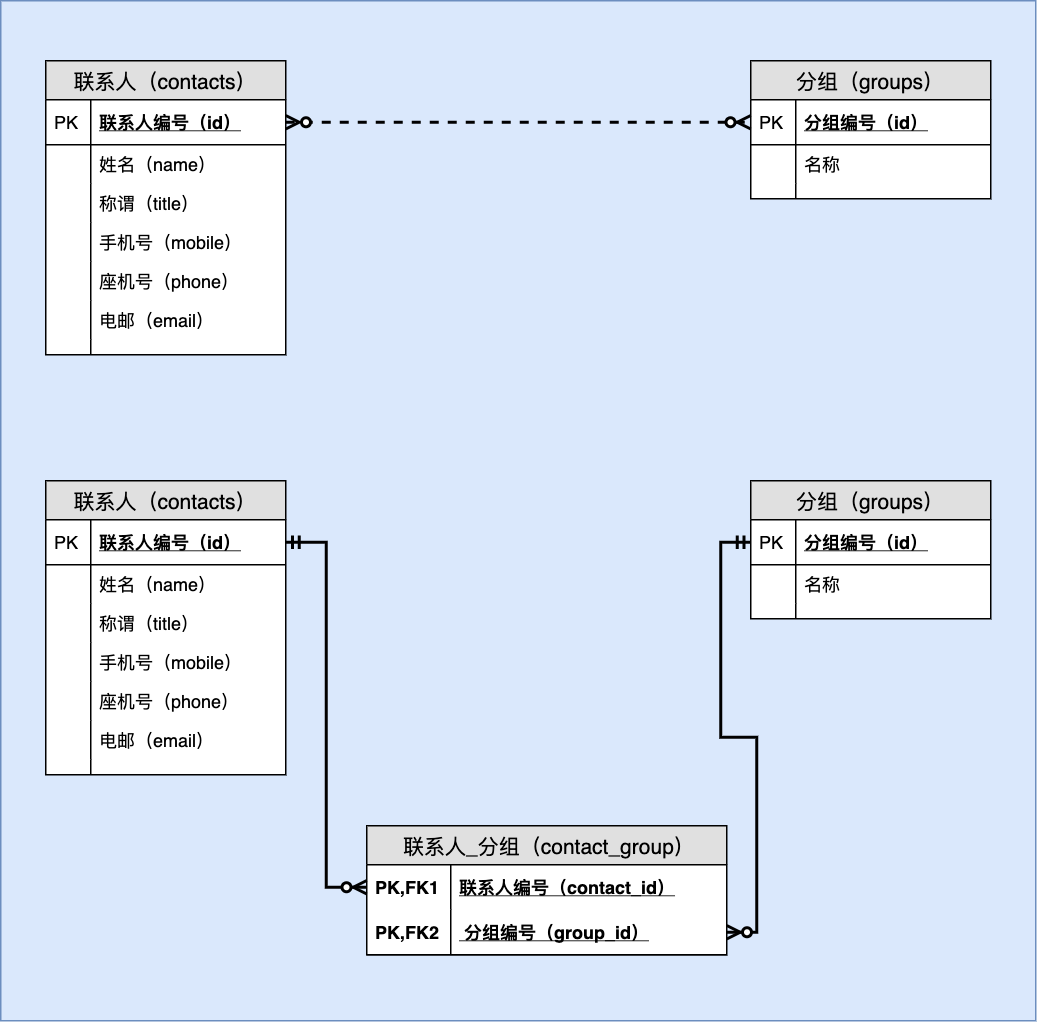
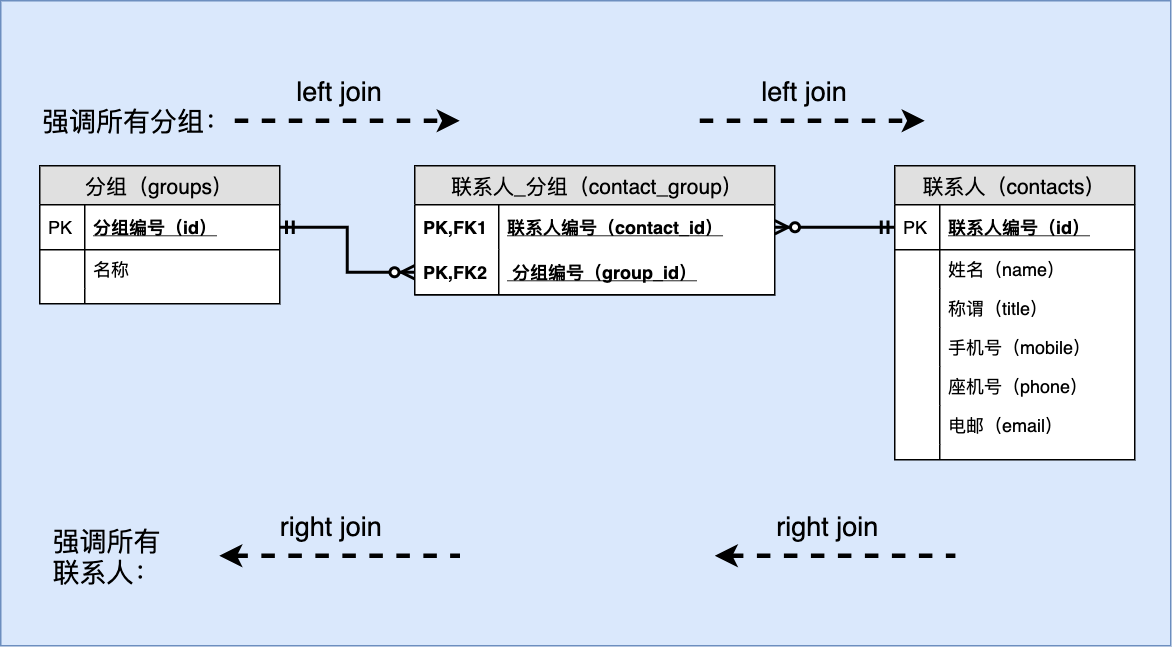
第九章 案例五 多对多关系:通讯录管理
数据库: c5_contact_db 下载数据库备份
9.1 解读设计稿
9.1.1 E-R 图


9.1.2 数据字典
(1)表定义
表名:联系人(contacts)
| 序号 | 列名 | 英文名 | 数据类型 | 必填? | 关键列 | 默认值 | 其它说明 |
|---|---|---|---|---|---|---|---|
| 1 | 联系人编号 | id | BIGINT UNSIGNED | ✓ | PK | NULL | AUTO_INCREMENT |
| 2 | 姓名 | name | VARCHAR(50) | ✓ | UNI | NULL | |
| 3 | 称谓 | title | VARCHAR(50) | NULL | |||
| 4 | 手机 | mobile | VARCHAR(50) | ✓ | NULL | ||
| 5 | 座机 | phone | VARCHAR(50) | NULL | |||
| 6 | 电邮 | VARCHAR(100) | NULL |
表名:分组(groups)
| 序号 | 列名 | 英文名 | 数据类型 | 必填? | 关键列 | 默认值 | 其它说明 |
|---|---|---|---|---|---|---|---|
| 1 | 分组编号 | id | BIGINT UNSIGNED | ✓ | PK | NULL | AUTO_INCREMENT |
| 2 | 名称 | name | VARCHAR(50) | ✓ | UNI | NULL |
表名:联系人-分组(contact_group)
| 序号 | 列名 | 英文名 | 数据类型 | 必填? | 关键列 | 默认值 | 其它说明 |
|---|---|---|---|---|---|---|---|
| 1 | 分组编号 | group_id | BIGINT UNSIGNED | ✓ | PK,FK | NULL | 参照groups.id 更新:级联 删除:级联 |
| 2 | 联系人编号 | contact_id | BIGINT UNSIGNED | ✓ | PK,FK | NULL | 参照contacts.id 更新:级联 删除:级联 |
(2)触发器
表名:
| 序号 | 名称 | 时机 | 功能 | 其它 |
|---|---|---|---|---|
(3)视图
视图名称:
| 序号 | 列名 | 英文名 | 来自 | 其它说明 |
|---|---|---|---|---|
(4)存储过程与函数
| 序号 | 名称 | 功能 | 输入 | 返回值 | 其它 |
|---|---|---|---|---|---|
(5)用户及权限
| 用户名 | 登录位置 | 初始密码 | 权限说明 |
|---|---|---|---|
| c5_contact_db_admin | 所有 | 000000 | 对数据库具有所有权限 |
| c5_contact_db_user | 所有 | 000000 | 对数据库表具有增、删、改、查权限 |
9.1.3 从需求文档整理的数据查询需求
能够按以下指定条件查询筛选记录;
- 列出某个分组的所有联系人
- 列出某个联系人所在的分组
- 按“联系人编号、姓名、手机号、所在分组”列出所有联系人(一列显示多个分组,逗号分隔)
- 列出尚不属于任何分组的联系人
- 列出尚无联系人的分组
- 能够按以下指定条件统计信息
- 按分组统计联系人人数
- 列出每个联系人的分组数
9.2 数据查询
9.2.1 列出某个分组的所有联系人
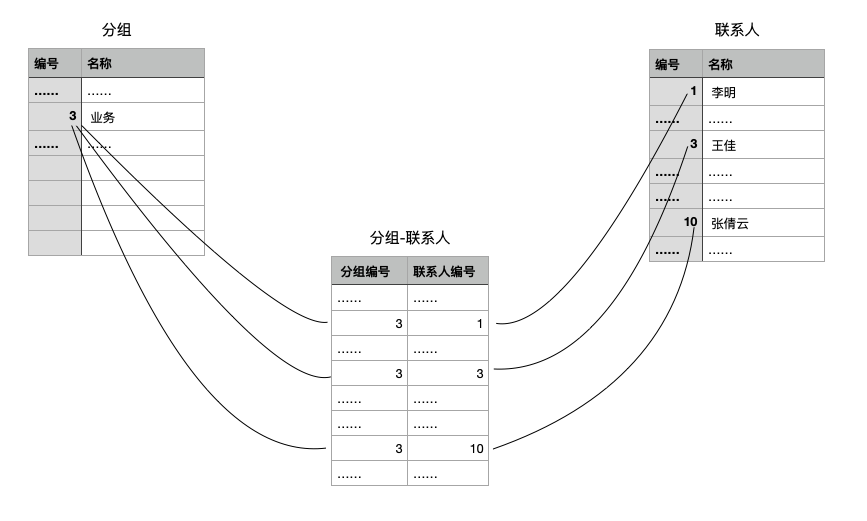
select g.name,c.name,c.mobile,c.emailfrom contacts c inner join contact_group cgon c.id=cg.contact_idinner join groups gon cg.group_id=g.idwhere g.name='业务';
简洁写法:
select g.name,c.name,c.mobile,c.emailfrom contacts c, contact_group cg, groups gwherec.id=cg.contact_id andcg.group_id=g.id andg.name='业务';
- 能够按以下指定条件查询筛选记录;
- 列出某个分组的所有联系人
- 列出某个联系人所在的分组
- 按“联系人编号、姓名、手机号、所在分组”列出所有联系人(一列显示多个分组,逗号分隔)
- 列出尚不属于任何分组的联系人
- 列出尚无联系人的分组
- 能够按以下指定条件统计信息
- 按分组统计联系人人数
- 列出每个联系人的分组数
9.2.2 列出某个联系人所在的分组
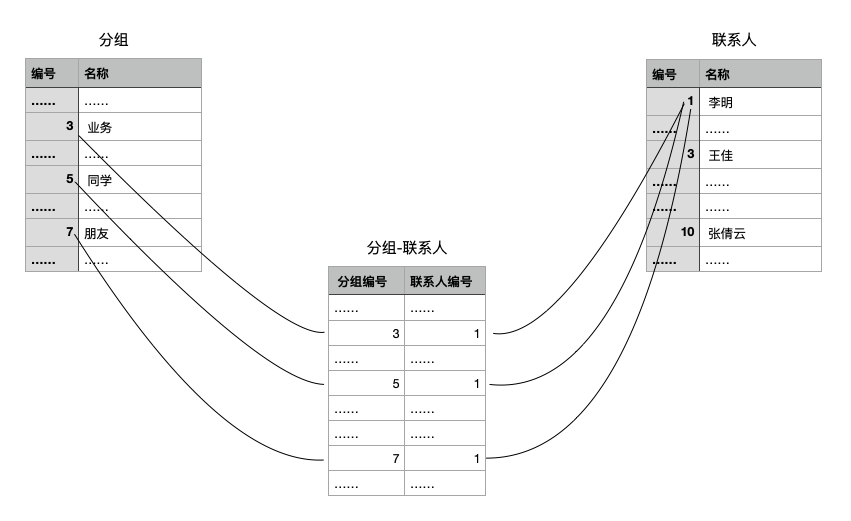
select g.name,c.name,c.mobile,c.emailfrom groups g inner join contact_group cgon g.id=cg.group_idinner join contacts con cg.contact_id=c.idwhere c.name='李明';
简洁写法:
select g.name,c.name,c.mobile,c.emailfrom groups g, contact_group cg, contacts cwhereg.id=cg.group_id andcg.contact_id=c.id andc.name='李明';
- 能够按以下指定条件查询筛选记录;
- 列出某个分组的所有联系人
- 列出某个联系人所在的分组
- 按“联系人编号、姓名、手机号、所在分组”列出所有联系人(一列显示多个分组,逗号分隔)
- 列出尚不属于任何分组的联系人
- 列出尚无联系人的分组
- 能够按以下指定条件统计信息
- 按分组统计联系人人数
- 列出每个联系人的分组数
9.2.3 按“联系人编号、姓名、手机号、所在分组”列出所有联系人
select c.id,c.name,c.mobile,(select group_concat(distinct g.name separator ', ') from groups g, contact_group cg where g.id=cg.group_id and cg.contact_id=c.id) as groupsfrom contacts c;
- 能够按以下指定条件查询筛选记录;
- 列出某个分组的所有联系人
- 列出某个联系人所在的分组
- 按“联系人编号、姓名、手机号、所在分组”列出所有联系人(一列显示多个分组,逗号分隔)
- 列出尚不属于任何分组的联系人
- 列出尚无联系人的分组
- 能够按以下指定条件统计信息
- 按分组统计联系人人数
- 列出每个联系人的分组数
9.2.4 列出尚不属于任何分组的联系人
select c.id, c.name, c.mobilefrom contacts cwhere(select count(*) from contact_group cg where cg.contact_id=c.id)=0;
- 能够按以下指定条件查询筛选记录;
- 列出某个分组的所有联系人
- 列出某个联系人所在的分组
- 按“联系人编号、姓名、手机号、所在分组”列出所有联系人(一列显示多个分组,逗号分隔)
- 列出尚不属于任何分组的联系人
- 列出尚无联系人的分组
- 能够按以下指定条件统计信息
- 按分组统计联系人人数
- 列出每个联系人的分组数
9.2.5 列出尚无联系人的分组
select g.id,g.name from groups gwhere(select count(*) from contact_group cg where cg.group_id=g.id)=0;
- 能够按以下指定条件查询筛选记录;
- 列出某个分组的所有联系人
- 列出某个联系人所在的分组
- 按“联系人编号、姓名、手机号、所在分组”列出所有联系人(一列显示多个分组,逗号分隔)
- 列出尚不属于任何分组的联系人
- 列出尚无联系人的分组
- 能够按以下指定条件统计信息
- 按分组统计联系人人数
- 列出每个联系人的分组数
9.3 数据统计与维护
9.3.1 统计
(1)按分组统计联系人人数
select g.id, g.name, count(c.id)from groups g left join contact_group cgon g.id=cg.group_idleft join contacts con cg.contact_id=c.idgroup by g.id;
- 能够按以下指定条件查询筛选记录;
- 列出某个分组的所有联系人
- 列出某个联系人所在的分组
- 按“联系人编号、姓名、手机号、所在分组”列出所有联系人(一列显示多个分组,逗号分隔)
- 列出尚不属于任何分组的联系人
- 列出尚无联系人的分组
- 能够按以下指定条件统计信息
- 按分组统计联系人人数
- 列出每个联系人的分组数
(2)列出每个联系人的分组数
select c.id, c.name, count(g.id)from groups g right join contact_group cgon g.id=cg.group_idright join contacts con cg.contact_id=c.idgroup by c.id;
- 能够按以下指定条件查询筛选记录;
- 列出某个分组的所有联系人
- 列出某个联系人所在的分组
- 按“联系人编号、姓名、手机号、所在分组”列出所有联系人(一列显示多个分组,逗号分隔)
- 列出尚不属于任何分组的联系人
- 列出尚无联系人的分组
- 能够按以下指定条件统计信息
- 按分组统计联系人人数
- 列出每个联系人的分组数
9.3.2 数据维护
新增一个联系人,并把他加到“同事”组。
insert into contacts (name,mobile) values('张洁1','13887879090');insert into contact_group(contact_id,group_id)values((select last_insert_id()),(select id from groups where name='同事'));
last_insert_id(): 最后一次插入或更新操作对应的自动增长列的值。
练习
1、新建一个与现有分组同名的分组,查看出错情况。
2、新建一个分组,把一个现有的联系人加入这个分组,并列出这个分组的所有联系人进行确认。
3、删除一个分组,确信这个分组的编号不再在 contact_group 表中出现。
4、删除一个联系人,确信这个联系人的编号不再在 contact_group 表中出现。
5、列出所有分组及所有联系人(全连接)。
第十章 案例六 具有关联属性的多对多关系:订单管理
10.1 解读设计稿
10.1 E-R 图
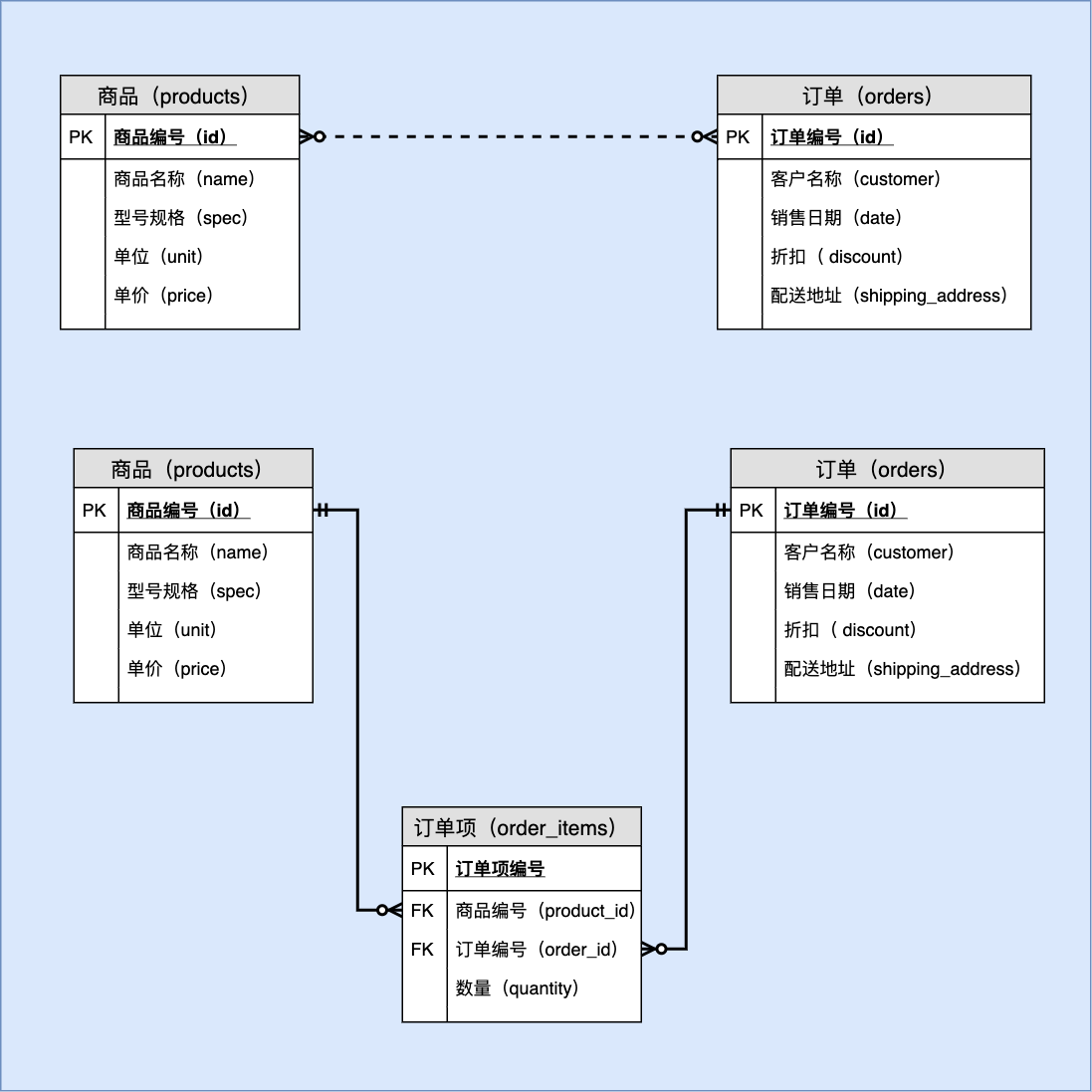
10.1.2 数据字典
(1)表定义
表名: 商品( products)
| 序号 | 列名 | 英文名 | 数据类型 | 必填? | 关键列 | 默认值 | 其它说明 |
|---|---|---|---|---|---|---|---|
| 1 | 商品编号 | id | BIGINT UNSIGNED | ✓ | PK | NULL | AUTO_INCREMENT |
| 2 | 名称 | name | VARCHAR(50) | ✓ | UNI | NULL | 与型号规格组合唯一 |
| 3 | 型号规格 | spec | VARCHAR(200) | ✓ | NULL | 与名称组合唯一 | |
| 4 | 单位 | unit | VARCHAR(10) | ✓ | NULL | ||
| 5 | 单价 | price | DECIMAL(10,2) UNSIGNED | ✓ | NULL |
表名: 订单(orders)
| 序号 | 列名 | 英文名 | 数据类型 | 必填? | 关键列 | 默认值 | 其它说明 |
|---|---|---|---|---|---|---|---|
| 1 | 订单编号 | id | BIGINT UNSIGNED | ✓ | PK | NULL | AUTO_INCREMENT |
| 2 | 客户名称 | customer | VARCHAR(50) | ✓ | NULL | ||
| 3 | 销售日期 | date | DATE | NOW() | |||
| 4 | 折扣 | discount | DECIMAL(3,2) UNSIGNED | 1.00 | 不大于 1.00 | ||
| 5 | 配送地址 | shipping_address | VARCHAR(200) | '' |
表名:订单项( order_items)
| 序号 | 列名 | 英文名 | 数据类型 | 必填? | 关键列 | 默认值 | 其它说明 |
|---|---|---|---|---|---|---|---|
| 1 | 订单编号 | order_id | BIGINT UNSIGNED | ✓ | PK,FK | NULL | 参照 orders.id 更新:级联 删除:级联 |
| 2 | 商品编号 | product_id | BIGINT UNSIGNED | ✓ | PK,FK | NULL | 参照 products.id 更新:级联 删除:限制 |
| 3 | 数量 | quantity | INT | 1 |
(2)触发器
表名:
| 序号 | 名称 | 时机 | 功能 | 其它 |
|---|---|---|---|---|
(3)视图
视图名称:
| 序号 | 列名 | 英文名 | 来自 | 其它说明 |
|---|---|---|---|---|
(4)存储过程与函数
| 序号 | 名称 | 功能 | 输入 | 返回值 | 其它 |
|---|---|---|---|---|---|
(5)用户及权限
| 用户名 | 登录位置 | 初始密码 | 权限说明 |
|---|---|---|---|
| db_2_6_admin | 所有 | 000000 | 对数据库具有所有权限 |
| db_2_6_user | 所有 | 000000 | 对数据库表具有增、删、改、查权限 |
10.1.3 从需求文档整理的数据查询需求
- 能够按以下指定条件查询筛选记录;
- 列出某个订单的商品项详情(名称、型号规格、单价、单位、数量)
- 列出某个商品对应的所有订单
- 能够按以下指定条件统计信息
- 列出每个订单的信息及其总额、折扣、折扣后的总额
- 列出某项商品的历史销量变化趋势(年月)
- 列出所有销售的收入变化趋势(年月)
- 统计每个客户的购买数量与总额,降序排序
10.2 数据查询
10.2.1 列出某个订单的商品项详情(名称、型号规格、单价、单位、数量)
select o.id,o.date,o.customer,p.*,oi.quantityfrom orders o, order_items oi, products pwhere o.id=oi.order_id and oi.product_id=p.id and o.id=1;
10.2.2 列出某个商品对应的所有订单
select p.id,p.name,p.spec,o.id,o.date,o.customerfrom products p, order_items oi, orders owhere p.id=oi.product_id and oi.order_id=o.id and p.id=1;
10.3 数据统计
10.3.1 列出每个订单的信息及其总额、折扣、折扣后的总额
select o.*, sum(p.price*oi.quantity) as sum, sum(p.price*oi.quantity)*o.discount as discount_sumfrom products p, order_items oi, orders owhere p.id=oi.product_id and oi.order_id=o.idgroup by o.id;
10.3.2 列出某项商品的历史销量变化趋势(年月)
select concat(year(o.date),'-',lpad(month(o.date),2,"0")) as yearmonth,p.id,p.name,p.spec,sum(p.price*oi.quantity) as total_price, sum(oi.quantity) as total_quantityfrom products p, order_items oi, orders owhere p.id=oi.product_id and oi.order_id=o.idgroup by yearmonthorder by yearmonth;
10.3.3 列出所有销售的收入变化趋势(年月)
select concat(year(o.date),'-',lpad(month(o.date),2,"0")) as yearmonth,sum(p.price*oi.quantity) as total_pricefrom products p, order_items oi, orders owhere p.id=oi.product_id and oi.order_id=o.idgroup by yearmonthorder by yearmonth;
10.3.4 统计每个客户的购买数量与总额,降序排序
select o.customer,sum(oi.quantity) as total_quantity, sum(p.price*oi.quantity) as total_pricefrom products p, order_items oi, orders owhere p.id=oi.product_id and oi.order_id=o.idgroup by o.customerorder by total_quantity desc, total_price desc;
第三部分 数据库的设计
第十 一章 数据库的设计原则
1 1.1 表的三个范式
范式是表的设计的规范模式。通常我们需要将表设计到第三范式的层次。
11.1.1 第一范式
(1)表的每个列的信息应当足够细化(原子性)
所谓“原子性”,就是说列的信息不能或不需要再细化。
看看下面这个表格:
| 编号 | 姓名 | 性别 | 出生日期 |
|---|---|---|---|
| 001 | 吴小燕 | 女 | 1998-11-23 |
表中各列是否足够细化,即具备“原子性”了呢?
事实上,原子性是相对的。比这个表对应的管理系统不要求对人的“姓”和“名”分开处理,那么,这张表的名列都具备了原子性。
但如果系统需要对人的“姓”和“名”分开处理,那么,“姓名”一列就不具备原子性,你应该各用一列来存储“姓”和“名”。
| 编号 | 姓 | 名 | 性别 | 出生日期 |
|---|---|---|---|---|
| 001 | 吴 | 小燕 | 女 | 1998-11-23 |
(2)表的单元格里不能存储多值
如果出现多值,就需要考虑拆分表格。
如以下表格就是不符合第一范式要求的:
联系人
| 姓名 | 电话 | 分组 |
|---|---|---|
| 李名 | 13030309887,18988977653 | 朋友,同事,同学 |
(3)每个表格行必须要有能够和其它行区分开来的一列(或多列的组合)
这样的列(或多列的组合)叫“候选键列”。
这样的列(或列的组合)可能有多个,可选定其中一个作为“主键”,其它的设定为“唯一键”
如以下表格也是不符合第一范式的:
会员名单
| 姓名 | 性别 | 出生日期 | 入会日期 |
|---|---|---|---|
| 张小敏 | 女 | 1998-02-12 | 2019-12-20 |
| 李娜 | 女 | 1999-11-23 | 2019-12-20 |
| 张小敏 | 女 | 1998-02-12 | 2019-12-20 |
同一个人?不同的人?
11.1.2 第二范式
(1)满足第一范式
(2)所有列都依赖于全部候选键列
即对于有多列组合候选键列的表来说,它的各个列的信息都同时与组合候选键列中的所有列有关。
比如,以下表格就不符合第二范式:
工时记录
| 职员编号 | 职员姓名 | 项目编号 | 项目名称 | 工时 |
|---|---|---|---|---|
| 1 | 周小小 | 17 | 光明路改造工程 | 68 |
| 1 | 周小小 | 21 | 海天小区装修 | 120 |
| 2 | 王明军 | 17 | 光明路改造工程 | 50 |
候选键列:职员编号+项目编号
“工时”列与候选键列相关(某职员在某工程上的工作时间)
“职员姓名”只与“职员编号”有关
“项目名称”只与“项目编号”有关
11.1.3 第三范式
(1)满足第二范式
(2)不能出现传递依赖
表中的列不能只依赖于其它非候选键列。
如以下表格就不符合第三范式:
员工信息
| 员工编号 | 姓名 | 性别 | 所属分公司 | 分公司地址 | 分公司电话 |
|---|---|---|---|---|---|
| 1 | 吴小娟 | 女 | 昆明分公司 | 昆明市盘龙区某路某号 | 0871-88987656 |
“所属分公司”决定于员工,因为它是员工的属性。
“分公司地址”和“分公司电话”只决定于“所属分公司”,“所属分公司”不是候选键列!
11.2 表设计要遵循的原则
11.2.1 正确识别管理的实体以及它们之间的相互关系
从需求描述中抽取管理涉及的事物,并确立它们之间的关系。
两张表可能有的关系是:“一对多”关系(特例“一对一”),“多对多关系”(需要分解为两个一对多关系)。
11.2.2 合理设计实体的属性(列)
需要满足第三范式。
11.2.3 处理多值列衍生新实体
(1)多值为实体的非共享属性值
非共享属性值,指实体专属的原子性信息,如手机号,银行卡号等。
在这种情况下,只需要把原来的表拆分成两张表(增加了一个实体),建立“一对多”关系就好。
联系人信息(需要记录多个手机号)
| 联系人编号 | 姓名 | 手机号 |
|---|---|---|
| 0103 | 王明 | 13887870987,13323467653 |
永远不要像这样:
联系人编号 姓名 手机号1 手机号2 0103 王明 13887870987 13323467653 因为通常你不知道需要预留多少个手机号码列(不要试图在以后轻易变动表结构)。
因此,“不要有同样信息的重复列”!
拆分:
联系人
| 联系人编号 | 姓名 |
|---|---|
| 0103 | 王明 |
联系人手机号
| 手机号 | 联系人编号 |
|---|---|
| 13887870987 | 0103 |
| 13323467653 | 0103 |
“手机号”和“联系人编号”设定为“组合主键”,也可人为添加一列自动增长列为“主键”,“手机号”和“联系人编号”则设定为“组合唯一键”。
“联系人编号”设定为“外键”参考“联系人”表的主键“联系人编号”。
(2)多值为需要共享的值或实体
如果值是需要共享的,就必须保持一致,从而应该把它们作为实体(单独建表进行管理)来对待。
如在某个应用中,一个“联系人”有多个共享的“分组”,意味着这些分组应该有前后一致的名称。“分组”就应该作为一个实体来对待,从而避免“朋友”和“朋 友”的不一致。
多值为共享的实体后,就需要拆分为三张表,建立两个一对多关系(增加了两个实体)。
比如以下联系人信息(只需要记录一个手机号):
| 姓名 | 手机 | 分组 |
|---|---|---|
| 李名 | 13030309887 | 朋友,同事,同学 |
| 王成 | 13398897875 | 同事,朋 友 |
拆分:
联系人
| 联系人编号 | 姓名 | 手机 |
|---|---|---|
| 0123 | 李名 | 13030309887 |
| 0124 | 王成 | 13398897875 |
分组
| 分组编号 | 分组名称 |
|---|---|
| 1 | 朋友 |
| 2 | 同事 |
| 3 | 同学 |
分组-联系人
| 分组编号 | 联系人编号 |
|---|---|
| 1 | 0123 |
| 2 | 0123 |
| 3 | 0123 |
| 1 | 0124 |
| 2 | 0124 |
“分组编号”与“联系人编号”组合唯一。
第十二章 案例一 单表设计:管理库存商品
1 2.1 需求分析
12.1.1 需求与原始数据
(1)需求描述
有一商店,需要把库存商品用数据库进行管理,需求如下:
- 能够根据商品名称、品牌、型号、规格的关键字及各种价格范围查询商品并排序;
- 能够进行各种统计
- 各种商品的库存总数及成本总额;
- 某种商品在各种型号上的库存总数及成本总额;
- 能够统计表中各类数据的平均值、合计值;
- 能够列出所有商品名称而不重复。
(2)原始库存商品数据
| 名称 | 描述(品牌型号规格等) | 单位 | 销售单价 | 成本单价 | 库存量 | 成本小计 | 售价小计 |
|---|---|---|---|---|---|---|---|
| 打印机 | HP DeskJet2622 | 台 | 429.00 | 360.00 | 12 | 4320 | 5148.00 |
| 打印机 | EPSON L4168 | 台 | 1499.00 | 1100.00 | 7 | 7700.00 | 10493.00 |
| 显卡 | 蓝宝石 RX580 2048SP 4G | 张 | 1099.00 | 899.00 | 23 | 20677.00 | 25277.00 |
| 显示器 | LG HDR10 27寸 4K | 台 | 2199.00 | 1699.00 | 21 | 35679.00 | 46179.00 |
| 显卡 | 蓝宝石 RX580 2304SP 8G | 张 | 2549.00 | 1899.00 | 16 | 30384.00 | 40784.00 |
| 显示器 | AOC I2490PXH5 23.8英寸 | 台 | 799.00 | 550.00 | 12 | 6600.00 | 9588.00 |
12.2 E-R 图
12.2.1 确定管理涉及的数据实体及其关系
在本例中,实体只有一个,即“商品”。
12.2.2 确定管理涉及的各实体的属性(列)
根据需求描述与原始数据,实体目前应包含以下属性:
名称、品牌、型号、规格、单位、销售单价、成本单价、库存量、成本小计、售价小计等。
按第三范式要求,属性确立为:
商品编号、名称、品牌、型号、规格、单位、销售单价、成本单价、库存量
商品编号为自动增长的数字主键,名称、品牌、型号、规格为组合候选键,设定为“唯一组合健”。
成本小计只依赖于成本单价及库存量,且可计算得到,去除;
售价小计只依赖于销售单价及库存量,且可计算得到,去除。
通常不需要能够从其它列计算出来的列,因为存储的值和计算结果可能造成不一致。比如“成本小计”=“成本单价”ד库存量”。如果改变了“成本单价”或“库存量”,“成本小计”就需要重新计算。除非有充分理由保留计算列(比如在计算复杂耗时的情况下出于对查询性能的考虑),那就要自行实现某种机制(如触发器)来保持数据的一致性。
12.2.3 绘制 E-R 图
根据以上分析,绘制 E-R图如下:
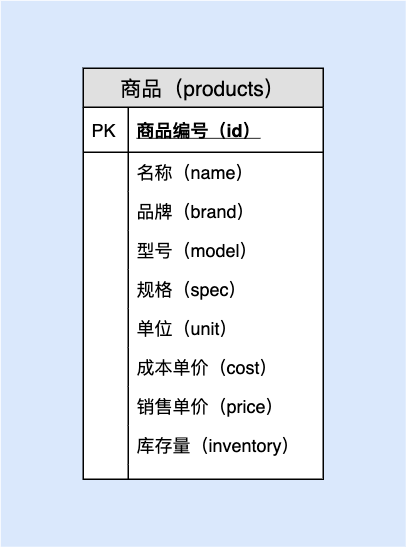
12.3 数据字典
12.3.1 表定义
表名: 商品( products)
| 序号 | 列名 | 英文名 | 数据类型 | 必填? | 关键列 | 默认值 | 其它说明 |
|---|---|---|---|---|---|---|---|
| 1 | 商品编号 | id | BIGINT UNSIGNED | ✓ | PK | NULL | AUTO_INCREMENT |
| 2 | 名称 | name | VARCHAR(50) | ✓ | UNI | NULL | 与品牌、型号、规格组合唯一 |
| 3 | 品牌 | brand | VARCHAR(200) | ✓ | NULL | 与名称、型号、规格组合唯一 | |
| 4 | 型号 | model | VARCHAR(200) | '' | 与名称、品牌、规格组合唯一 | ||
| 5 | 规格 | spec | VARCHAR(200) | '' | 与名称、品牌、型号组合唯一 | ||
| 6 | 单位 | unit | VARCHAR(10) | ✓ | NULL | ||
| 7 | 销售单价 | price | DECIMAL(10,2) | ✓ | NULL | >=0 | |
| 8 | 成本单价 | cost | DECIMAL(10,2) | ✓ | NULL | >=0 | |
| 9 | 库存量 | inventory | INT | ✓ | NULL | >=0 |
整理后的数据:
| 商品编号 | 名称 | 品牌 | 型号 | 规格 | 单位 | 销售单价 | 成本单价 | 库存量 |
|---|---|---|---|---|---|---|---|---|
| 1 | 打印机 | HP | DeskJet 2622 | 台 | 429.00 | 360.00 | 12 | |
| 2 | 打印机 | EPSON | L4168 | 台 | 1499.00 | 1100.00 | 7 | |
| 3 | 显卡 | 蓝宝石 | RX 580 | 2048SP 8G | 张 | 1099.00 | 899.00 | 23 |
| 4 | 显示器 | LG | HDR10 | 27寸 4K | 台 | 2199.00 | 1699.00 | 21 |
| 5 | 显卡 | 七彩虹 | RX 580 | 2304SP 8G | 张 | 2549.00 | 1899.00 | 16 |
| 6 | 显示器 | AOC | I2490PXH5 | 23.8英寸 | 台 | 799.00 | 550.00 | 12 |
空串与空值:
空串:''(两个紧靠着的引号间没有空隔),是一个空的字符串值,可参与字符串的运算。
空值:null,无值,真空!不能参与任何运算。比如不能做各种比较运算。
自动增长的 ID 用 INT 还是 BIGINT?
假定数据库系统很繁忙,并且数据量无限大,平均 1 秒产生一条新记录,用 INT 或 BIGINT 作 ID,什么时候会把可用的数值耗尽?
INT 无符号数可用 4294967295 / (365×24×60×60) = 136.19 年。
BIGINT 无符号数可用 18446744073709551615 / (365×24×60×60) = 584942417355.07 (5849 亿)年
12.3.2 触发器
(无)
12.3.3 视图
(无)
12.3.4 函数和存储过程
(无)
12.4 编写脚本
drop database if exists `db_3_1`;create database if not exists `db_3_1` default charset utf8mb4;use `db_3_1`;create table `products`(-- 列定义`id` bigint unsigned not null auto_increment,`name` varchar(100) not null,`brand` varchar(100) not null,`model` varchar(100) default '',`spec` varchar(100) default '',`unit` varchar(10) not null,`cost` decimal(8,2) not null,`price` decimal(8,2) not null,`inventory` int not null,-- 约束定义primary key(`id`),unique(`name`,`brand`,`model`,`spec`),check(`cost`>=0),check(`price`>=0),check(`inventory`>=0));-- 插入样例数据(用于测试等)INSERT INTO `products`(`id`,`name`,`brand`,`model`,`spec`,`unit`,`price`,`cost`,`inventory`)VALUES(null,'打印机','HP','DeskJet 2622','','台',429.00,360.00,12),(null,'打印机','EPSON','L4168','','台',1499.00,1100.00,7),(null,'显卡','蓝宝石','RX 580','2048P 4G','张',1099.00,899.00,23),(null,'显示器','LG','HDR10','27寸 4K','台',2199.00,1699.00,21),(null,'显卡','蓝宝石','RX 580','2304SP 8G','张',2549.00,1899.00,16),(null,'显示器','AOC','I2490PXH5','23.8英寸','台',799.00,550.00,12);
12.5 运行建库脚本并验证建库结果
12.5.1 运行脚本
MariaDB [(none)]> source [脚本所在路径\]脚本文件名;
12.5.2 验证建库结果
(1)查看表,确认表被正确建立
show tables;
(2)查看表的结构,确认列和约束被正确建立
-- 快速查看大致结构describe 表名;-- 查看详细的表定义(sql 脚本,带自动添加的默认参数)show create table 表名\G
12.6 数据操纵测试
根据需求分析中的数据操纵(增、删、改、查)需求,验证各表以及它们的相互关系的合理性。
请根据第二部分内容所学知识自行完成。
第十三章 案例二 一对一关系: 员工管理
1 3.1 需求分析
13.1.1 需求与原始数据
(1)需求描述
有一公司,用数据库管理人员信息,需求如下:
- 数据库用于记录员工的基本信息和银行帐户信息;
- 财务部门能够查看人员的所有信息,包括银行帐号信息;
- 其它部门只能看到人员的基本信息,不能查看员工银行帐号信息。
(2)原始员工记录数据
| 序号 | 身份证号 | 姓名 | 性别 | 出生日期 | 所在部门 | 工资卡开户行 | 银行卡号 |
|---|---|---|---|---|---|---|---|
| 1 | 531010198707231124 | 王小霞 | 女 | 1987-07-23 | 人事 | 中国银行 | 1234 5678 2345 1233 |
| 2 | 530103199802153211 | 李志强 | 男 | 1998-02-15 | 研发 | 中国银行 | 2323 1567 2387 9876 |
13.2 E-R 图
13.2.1 确定管理涉及的数据实体及其关系
在本例中,实体似乎只有一个,即“员工”。但从管理的角度来看,同一个员工的数据,有些数据(如银行帐户信息)只能由特定用户使用(如财务部门),从安全的角度考虑,可将它们从员工数据中剥离出来,建立具有“一对一”关系的两个实体。这样,便于从数据库系统层面限制特定用户的访问权限。
- [辨识的实体]
- 员工基本信息
- 管理人使用员工的基本信息。
- 员工银行帐号信息
- 管理和使用员工的帐户信息。
[辨识的表间关系]
每个“员工”具有一条“银行帐户”信息,每一条“银行帐户”信息属于一个“员工”,二者关系是“一对一的关系”,主表确定为“员工基本信息”,子表确定为“银行帐户信息”。
13.2.2 确定管理涉及的各实体的属性(列)
- 根据需求描述与原始数据,各实体应包含以下属性:
- 员工基本信息
- 员工编号(主键),身份证号(唯一键),姓名,性别,出生日期,所属部门。
银行帐户信息 - 帐户编号(主键),开户行,银行卡号,员工编号(外键,唯一键)
按第三范式要求,“性别”和“出生日期”均可从“身份证号”计算得到,为了保证数据的一致性,应当去除。但为了简洁起见,可保留这两个属性,但必须保证它们和身份证号中的信息一致(可用触发器进行维持)。
13.2.3 绘制 E-R 图
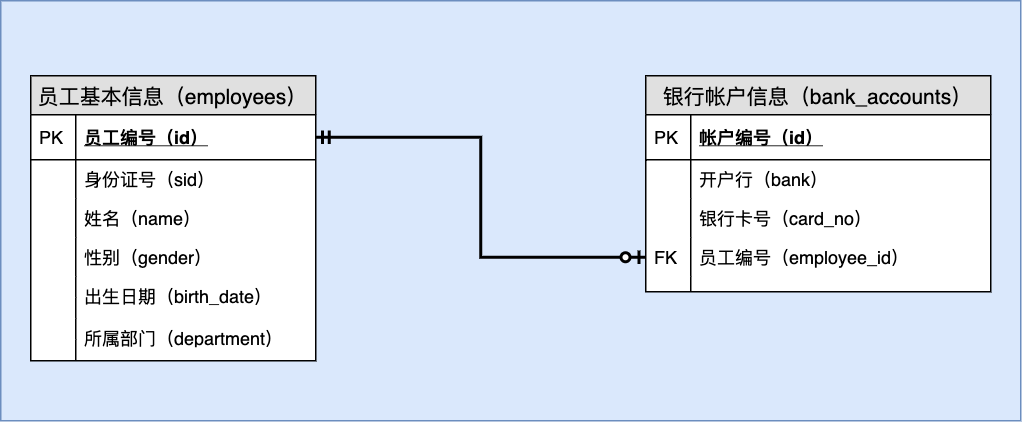
根据以上分析,绘制 E-R图如下:
13.3 数据字典
13.3.1 表定义
表名: 员工基本信息(employees)
| 序号 | 列名 | 英文名 | 数据类型 | 必填? | 关键列 | 默认值 | 其它说明 |
|---|---|---|---|---|---|---|---|
| 1 | 员工编号 | id | BIGINT UNSIGNED | ✓ | PK | NULL | AUTO_INCREMENT |
| 2 | 身份证号 | sid | CHAR(18) | ✓ | UNI | NULL | |
| 3 | 姓名 | name | VARCHAR( 50) | ✓ | NULL | ||
| 4 | 性别 | gender | CHAR(1) | NULL | 限于“男”和“女” | ||
| 5 | 出生日期 | birth_date | DATE | NULL | |||
| 6 | 所属部门 | department | VARCHAR(50) | ✓ | NULL |
整理后的数据:
| 员工编号 | 身份证号 | 姓名 | 性别 | 出生日期 | 所在部门 |
|---|---|---|---|---|---|
| 1 | 531010198707231124 | 王小霞 | 女 | 1987-07-23 | 人事 |
| 2 | 530103199802153211 | 李志强 | 男 | 1998-02-15 | 研发 |
表名: 银行帐户信息(bank_accounts)
| 序号 | 列名 | 英文名 | 数据类型 | 必填? | 关键列 | 默认值 | 其它说明 |
|---|---|---|---|---|---|---|---|
| 1 | 帐户编号 | id | BIGINT UNSIGNED | ✓ | PK | NULL | AUTO_INCREMENT |
| 2 | 开户行 | bank | VARCHAR(100) | ✓ | NULL | 与银行卡号组合唯一 | |
| 3 | 银行卡号 | card_no | VARCHAR(50) | ✓ | NULL | ||
| 4 | 员工编号 | employee_id | BIGINT UNSIGNED | ✓ | UNI | NULL | 外键,参考 employees.id 更新:级联 删除:级联 |
整理后的数据:
| 帐户编号 | 工资卡开户行 | 银行卡号 | 员工编号 |
|---|---|---|---|
| 1 | 中国银行 | 1234 5678 2345 1233 | 1 |
| 2 | 中国银行 | 2323 1567 2387 9876 | 2 |
13.3.2 触发器
表名:雇员信息(employees)
| 序号 | 名称 | 时机 | 功能 | 其它 |
|---|---|---|---|---|
| 1 | change_dob_gender_for_ins | 插入前 | 根据身份证号取出出生日期与性别信息填入相应列, 以保证出生日期和性别与身份证上的信息一致。 |
|
| 2 | change_dob_gender_for_upd | 更新前 | 同上 |
13.3.3 视图
(无)
13.3.4 函数和存储过程
(无)
13.4 编写脚本
drop database if exists `db_3_2`;create database if not exists `db_3_2` default charset utf8mb4;use `db_3_2`;create table `employees`(-- 列定义`id` bigint unsigned not null auto_increment,`sid` char(18) not null,`name` varchar(50) not null,`gender` char(1),`birth_date` date,`department` varchar(50) not null,-- 约束定义primary key(`id`),unique key(`sid`));create table `bank_accounts`(-- 列定义`id` bigint unsigned not null auto_increment,`bank` varchar(100) not null,`card_no` varchar(50) not null,`employee_id` bigint unsigned not null,-- 约束定义primary key(`id`),unique key(`bank`,`card_no`),foreign key(`employee_id`) references `employees`(`id`)on update cascade on delete cascade);delimiter $$create trigger change_dob_gender_for_ins before insert on employeesfor each rowbegindeclare gender_bit int;declare dob char(10);set gender_bit = cast(substring(NEW.sid,17,1) as int);set dob = concat(substring(NEW.sid,7,4),'-',substring(NEW.sid,11,2),'-',substring(NEW.sid,13,2));if gender_bit % 2 = 0 thenset NEW.gender='女';elseset NEW.gender='男';end if;if to_days(str_to_date(dob, '%Y-%m-%d')) is not null thenset NEW.birth_date=dob;elsesignal sqlstate '45000' set MESSAGE_TEXT = '身份证格式错误:日期';end if;end$$create trigger change_dob_gender_for_upd before update on employeesfor each rowbegindeclare gender_bit int;declare dob char(10);set gender_bit = cast(substring(NEW.sid,17,1) as int);set dob = concat(substring(NEW.sid,7,4),'-',substring(NEW.sid,11,2),'-',substring(NEW.sid,13,2));if gender_bit % 2 = 0 thenset NEW.gender='女';elseset NEW.gender='男';end if;if to_days(str_to_date(dob, '%Y-%m-%d')) is not null thenset NEW.birth_date=dob;elsesignal sqlstate '45000' set MESSAGE_TEXT = '身份证格式错误:日期';end if;end$$delimiter ;-- 插入样例数据(用于测试等)INSERT INTO `employees`(`id`,`sid`,`name`,`department`)VALUES(1,'531010198707231124','王小霞','人事'),(2,'530103199802153211','李志强','研发');INSERT INTO `bank_accounts`(bank,card_no,employee_id)values('中国银行','1234 5678 2345 1233',1),('中国银行','2323 1567 2387 9876',2);-- 注意观察性别和出生日期已经被正确填入select * from employees;
13.5 运行建库脚本并验证建库结果
13.5.1 运行脚本
MariaDB [(none)]> source [脚本所在路径\]脚本文件名;
13.5.2 验证建库结果
(1)查看表,确认表被正确建立
show tables;
(2)查看表的结构,确认列和约束被正确建立
-- 快速查看大致结构describe 表名;-- 查看详细的表定义(sql 脚本,带自动添加的默认参数)show create table 表名\G
(3)查看触发器
show triggers\G
13.6 数据操纵测试
请自行完成。
第十 四章 案例三 一对多关系:商品分类管理
14.1 需求分析
14.1.1 需求与原始数据
(1)需求描述
有一公司,用数据库对商品进行分类管理,商品可以按任意级别进行分类。数据查询需求如下:
- 可按分类关键字查询商品,显示商品分类(级联显示,如:服装 > 鞋 > 皮鞋...)及商品详情;
- 可按分类编号查询商品,显示商品分类(级联显示,如:服装 > 鞋 > 皮鞋...)及商品详情;
- 可按商品名称查找所有商品,显示商品分类(级联显示,如:服装 > 鞋 > 皮鞋...)及商品详情。
(2)原始数据(略)
14.2 E-R 图
14.2.1 确定管理涉及的数据实体及其关系
在本例中,可确定的实体有“商品”和“分类”。因为商品需要按任意级别进行分类,意味着分类是分级的,顶级分类 > 下级分类 > 下下级分类...,如果每级分类一个实体,则无法确定需要多少个“某级分类”实体。事实上,这种分级别的实体,它们具有同样的属性,可用一种“自关联”的实体来实现。
以“分类”为例,自关联的表实现“电器>家用电器>洗衣机”和“书籍>社科类>哲学类>外国作品”的例子:
| 分类编号 | 分类名称 | 上级分类编号 |
|---|---|---|
| 1 | 电器 | NULL |
| 2 | 家用电器 | 1 |
| 3 | 洗衣机 | 2 |
| 4 | 书籍 | NULL |
| 5 | 社科类 | 4 |
| 6 | 哲学类 | 5 |
| 7 | 外国作品 | 6 |
| 8 | 电冰箱 | 2 |
[辨识的实体]
商品分类
管理和使用商品的分级分类信息。
商品
管理和使用商品信息。
[辨识的表间关系]
每个“顶级分类”具有零个到多个“下级分类”,分类具有自关联的“一对多”关系;
每种“分类”具有多个“商品”,一个“商品”只属于一种分类。“分类”与“商品”是“一对多”的关系。
14.2.2 确定管理涉及的各实体的属性(列)
根据需求描述,各实体应包含以下属性:
商品分类
分类编号(主键),分类名称,分类说明,上级分类编号。
商品
商品编号(主键),商品代码,名称,品牌,型号,规格,单位,分类编号(外键)
表的设计满足第三范式要求。
14.2.3 绘制 E-R 图
根据以上分析,绘制 E-R图如下:
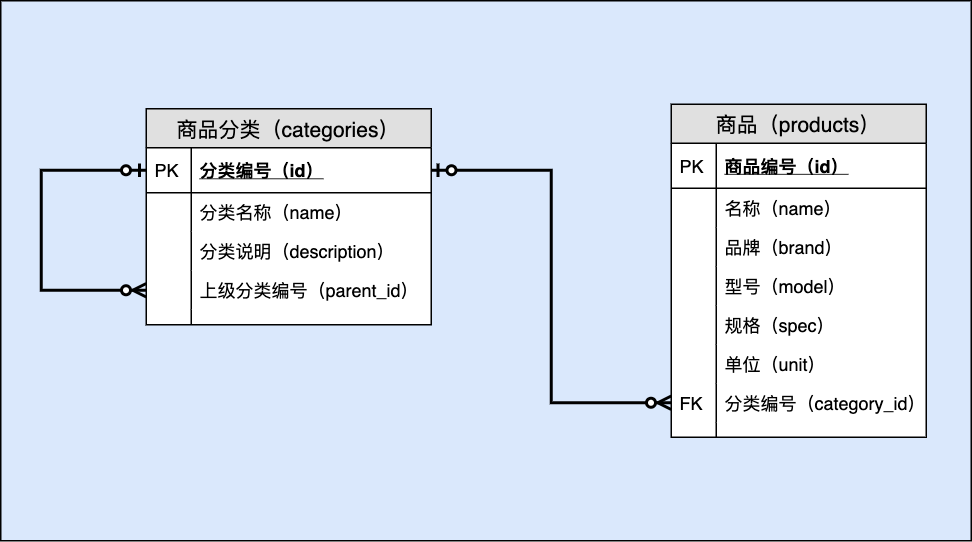
14.3 数据字典
14.3.1 表定义
表名: 商品分类( categories)
| 序号 | 列名 | 英文名 | 数据类型 | 必填? | 关键列 | 默认值 | 其它说明 |
|---|---|---|---|---|---|---|---|
| 1 | 分类编号 | id | BIGINT UNSIGNED | ✓ | PK | NULL | AUTO_INCREMENT |
| 2 | 商品代码 | code | CHAR(12) | ✓ | UNI | NULL | |
| 3 | 分类名称 | name | VARCHAR(50) | ✓ | NULL | ||
| 4 | 分类说明 | description | VARCHAR(200) | NULL | |||
| 5 | 上级分类编号 | parent_id | BIGINT UNSIGNED | FK | NULL | 参照 categories.id 更新:级联 删除:限制 |
表名: 商品(products)
| 序号 | 列名 | 英文名 | 数据类型 | 必填? | 关键列 | 默认值 | 其它说明 |
|---|---|---|---|---|---|---|---|
| 1 | 商品编号 | id | BIGINT UNSIGNED | ✓ | PK | NULL | AUTO_INCREMENT |
| 2 | 名称 | name | VARCHAR(100) | ✓ | NULL | 与品牌、型号、规格组合唯一 | |
| 3 | 品牌 | brand | VARCHAR(100) | ✓ | NULL | ||
| 4 | 型号 | model | VARCHAR(100) | '' | |||
| 5 | 规格 | spec | VARCHAR(100) | '' | |||
| 6 | 单位 | unit | VARCHAR(50) | ✓ | NULL | ||
| 7 | 分类编号 | category_id | BIGINT UNSIGNED | FK | NULL | 参照 employees.id 更新:级联 删除:置空 |
14.3.2 触发器
(无)
14.3.3 视图
(无)
14.3.4 函数和存储过程
| 序号 | 名称 | 功能 | 输入 | 返回值 | 其它 |
|---|---|---|---|---|---|
| 1 | get_cate_by_id | 获取 分类级联名称 | 分类 ID | VARCHAR(200), 级联名称,如: 电器>昆明市>盘龙区家用电器>洗衣机 |
函数 |
| 2 | get_cate_by_name | 获取一组分类级联名称 | 类别关键字 | 结果集:一组分类级联名称 | 过程 |
14.4 编写脚本
DROP DATABASE IF EXISTS `product_store`;CREATE DATABASE IF NOT EXISTS `product_store` DEFAULT CHARSET utf8mb4;USE `product_store`;CREATE TABLE `categories`(-- define columns`id` BIGINT UNSIGNED NOT NULL AUTO_INCREMENT,`name` VARCHAR(50) NOT NULL,`description` VARCHAR(200),`parent_id` BIGINT UNSIGNED,-- define constriantsCONSTRAINT `cate_pk` PRIMARY KEY (`id`),CONSTRAINT `cate-uni` UNIQUE KEY (`name`,`parent_id`),CONSTRAINT `cate-fk` FOREIGN KEY (`parent_id`) REFERENCES `categories`(`id`)ON UPDATE CASCADEON DELETE RESTRICT);CREATE TABLE `products`(-- define columns`id` BIGINT UNSIGNED NOT NULL AUTO_INCREMENT,`code` CHAR(12) NOT NULL,`name` VARCHAR(100) NOT NULL,`brand` VARCHAR(100) NOT NULL,`type` VARCHAR(100) DEFAULT '',`spec` VARCHAR(100) DEFAULT '',`unit` VARCHAR(50) NOT NULL,`category_id` BIGINT UNSIGNED,-- define constraintCONSTRAINT `prod_pk` PRIMARY KEY (`id`),CONSTRAINT `prod_code_uni` UNIQUE KEY (`code`),CONSTRAINT `prod_cate_fk` FOREIGN KEY (`category_id`) REFERENCES `categories`(`id`)ON UPDATE CASCADEON DELETE SET NULL);SET NAMES utf8;INSERT INTO `categories`VALUES(1,'电器','所有电器产品归为此类',null),(2,'服装','',null),(3,'食品','',null),(4,'家用电器','',1),(5,'工业电器','',1),(6,'空调制冷','',4),(7,'空调制冷','',5),(8,'空调','',6);INSERT INTO `products`VALUES(NULL,'P00000000001','中央空调','海尔','HR001','变频','台',8);DROP FUNCTION IF EXISTS `get_cate_by_id`;DROP PROCEDURE IF EXISTS `get_cate_by_name`;DELIMITER $$CREATE FUNCTION `get_cate_by_id`(cid BIGINT UNSIGNED) RETURNS VARCHAR(200)BEGINDECLARE cate_name VARCHAR(200);SET cate_name = '';get_name: LOOPSELECT `name`, `parent_id` INTO @name, @pid FROM `categories` WHERE `id`=cid;IF cate_name='' THENSET cate_name = @name;ELSESET cate_name = CONCAT(@name, '>' , cate_name);END IF;IF @pid IS NOT NULL THENSET cid = @pid;ITERATE get_name;ELSELEAVE get_name;END IF;END LOOP get_name;RETURN cate_name;END$$CREATE PROCEDURE `get_cate_by_name`(s_name VARCHAR(50))BEGINSELECT id,get_cate_by_id(`id`) FROM `categories` WHERE `name` LIKE CONCAT('%',s_name,'%') ORDER BY `id`;END$$DELIMITER ;SET NAMES gbk;SELECT * FROM `categories`;SELECT * FROM `products`;
14.5 运行建库脚本并验证建库结果
14.5.1 运行脚本
MariaDB [(none)]> source [脚本所在路径\]脚本文件名;
14.5.2 验证建库结果
(1)查看表,确认表被正确建立
show tables;
(2)查看表的结构,确认列和约束被正确建立
-- 快速查看大致结构describe 表名;-- 查看详细的表定义(sql 脚本,带自动添加的默认参数)show create table 表名\G
(3)查看函数
-- 列出数据库中定义的函数show function status where db='db_3_3'\G-- 显示函数 get_cate_by_id 的详细定义show create function get_cate_by_id\G
(4)查看存储过程
-- 列出数据库中定义的函数show procedure status where db='db_3_3'\G-- 显示函数 get_cate_by_name 的详细定义show create procedure get_cate_by_name\G
14.6 数据操纵测试
请插入必要的数据自行完成。
第十五章 案例四 多对多关系:工程项目管理
15.1 需求分析
15.1.1 需求与原始数据
(1)需求描述
有一工程设计公司,用数据库对工程人员在工程项目上的设计工时进行记录。一个设计人员可参与多个工程项目的设计,一个工程项目可有多个设计人员,每个工程项目具有特定的设计工时报酬。每个设计人员具有公司分配的 6 位工号。数据查询需求如下:
- 数据查询
- 查询某位设计人员参与的所有工程项目
- 查询某工程项目的所有参与人员
- 数据统计
- 统计所有设计人员在某项工程上的工时和相应报酬
(2)原始数据(略)
15.2 E-R 图
15.2.1 确定管理涉及的数据实体及其关系
在本例中,可确定的实体有“设计人员”和“工程项目”。
根据需求,一个“设计人员”可参与多个“工程项目”的设计,一个“工程项目”可有多个“设计人员”,“设计人员”与“工程项目”是“多对多”的关系。
因不可能在数据库中直接实现“多对多”的关系,我们需要增加另一个实体,将“多对多”关系分解成两个“一对多”关系。
“设计人员”与“工程项目” 之间的“参与设计”关系将二者联系在一起,这一关系产生了“工时”属性。
[辨识的实体]
设计人员
管理和使用设计人员的信息。
工程项目
管理和使用工程项目的信息。
设计记录
用于记录设计人员参与工程设计的情况
[辨识的表间关系]
“设计人员”与“工程项目”是“多对多”的关系,通过分解,一个“设计人员”与“设计记录”是“一对多”的关系,一个“工程项目”与“设计记录”也是“一对多”的关系。
15.2.2 确定管理涉及的各实体的属性(列)
根据需求描述,各实体应包含以下属性:
设计人员
人员编号(主键),工号(唯一),姓名,性别,出生日期。
工程项目
项目编号(主键),名称(唯一),地点,设计工时报酬。
设计记录
记录编号(主键),人员编号(外键),项目编号(外键),工时数。
表的设计满足第三范式要求。
15.2.3 绘制 E-R 图
根据以上分析,绘制 E-R图如下:
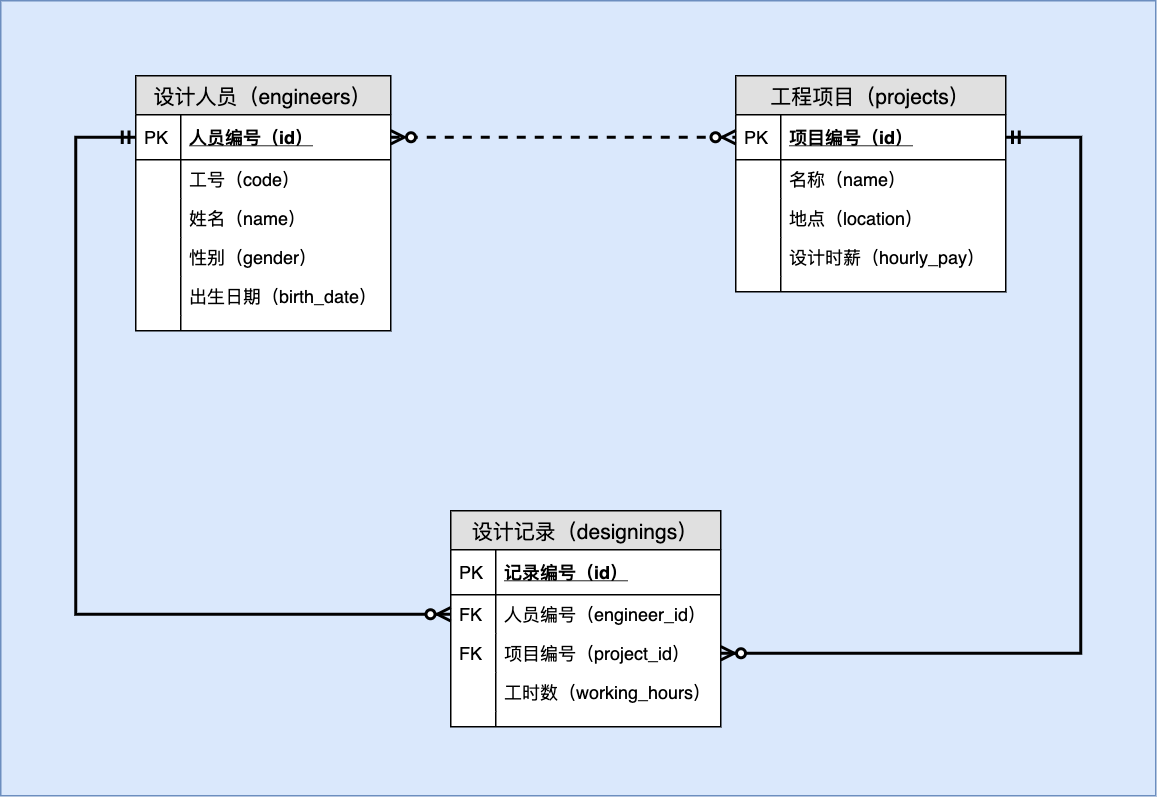
15.3 数据字典
15.3.1 表定义
表名: 设计人员(engineers)
| 序号 | 列名 | 英文名 | 数据类型 | 必填? | 关键列 | 默认值 | 其它说明 |
|---|---|---|---|---|---|---|---|
| 1 | 人员编号 | id | BIGINT UNSIGNED | ✓ | PK | NULL | AUTO_INCREMENT |
| 2 | 工号 | code | CHAR(6) | ✓ | NULL | ||
| 3 | 姓名 | name | VARCHAR(50) | ✓ | NULL | ||
| 4 | 性别 | gender | CHAR(1) | NULL | |||
| 5 | 出生日期 | birth_date | DATE | NULL |
表名: 工程项目( projects)
| 序号 | 列名 | 英文名 | 数据类型 | 必填? | 关键列 | 默认值 | 其它说明 |
|---|---|---|---|---|---|---|---|
| 1 | 项目编号 | id | BIGINT UNSIGNED | ✓ | PK | NULL | AUTO_INCREMENT |
| 2 | 名称 | name | VARCHAR(100) | ✓ | UNI | NULL | |
| 3 | 地点 | location | VARCHAR(200) | '' | |||
| 4 | 设计时薪 | hourly_pay | DECIMAL(8,2) | ✓ | NULL | >=0 |
表名: 设计记录(designings)
| 序号 | 列名 | 英文名 | 数据类型 | 必填? | 关键列 | 默认值 | 其它说明 |
|---|---|---|---|---|---|---|---|
| 1 | 记录编号 | id | BIGINT UNSIGNED | ✓ | PK | NULL | AUTO_INCREMENT |
| 2 | 人员编号 | engineer_id | BIGINT UNSIGNED | ✓ | FK | NULL | 参照 engineers.id 更新:级联 删除:限制 与“项目编号组合唯一” |
| 3 | 项目编号 | project_id | BIGINT UNSIGNED | ✓ | FK | NULL | 参照 projects.id 更新:级联 删除:限制 |
| 4 | 工时数 | working_hours | SMALL INT UNSIGNED | ✓ | NULL |
15.3.2 触发器
(无)
15.3.3 视图
(无)
15.3.4 函数和存储过程
(无)
15.4 编写脚本
drop database if exists `db_3_4`;create database if not exists `db_3_3` default charset utf8mb4;use `db_3_4`;create table `engineers`(-- 列定义`id` bigint unsigned not null auto_increment,`code` char(6) not null,`name` varchar(50) not null,`gender` char(1),`birth_date` date,-- 约束定义primary key(`id`),unique key(`code`),);create table `projects`(-- 列定义`id` bigint unsigned not null auto_increment,`name` varchar(100) not null,`location` varchar(200) default '',`hourly_pay` decimal(8,2) not null,-- 约束定义primary key(`id`),unique key(`name`));create table `designings`(-- 列定义`id` bigint unsigned not null auto_increment,`engineer_id` bigint unsigned not null,`project_id` bigint unsigned not null,`working_hours` smallint unsigned not null,-- 约束定义primary key(`id`),foreign key(`engineer_id`) references `engineers`(`id`)on update cascade on delete restrict,foreign key(`project_id`) references `projects`(`id`)on update cascade on delete restrict,unique key(`engineer_id`,`project_id`));insert into engineersvalues(1,'03031245','王小敏','女','1985-06-13'),(2,'03013267','周思明','男','1983-11-23');insert into projectsvalues(1,'光明路口改造项目','昆明市光明路',310.00),(2,'典雅小区 2 幢 1 单元 301 室装修','昆明市典雅小区二期',200.00);insert into designings(null,1,1,10),(null,1,2,2),(null,2,1,8),(null,2,2,3);
15.5 运行建库脚本并验证建库结果
15.5.1 运行脚本
MariaDB [(none)]> source [脚本所在路径\]脚本文件名;
15.5.2 验证建库结果
(1)查看表,确认表被正确建立
show tables;
(2)查看表的结构,确认列和约束被正确建立
-- 快速查看大致结构describe 表名;-- 查看详细的表定义(sql 脚本,带自动添加的默认参数)show create table 表名\G
15.6 数据操纵测试
请自行完成。
第十六章 几个综合案例
1 6.1 高校教务管理
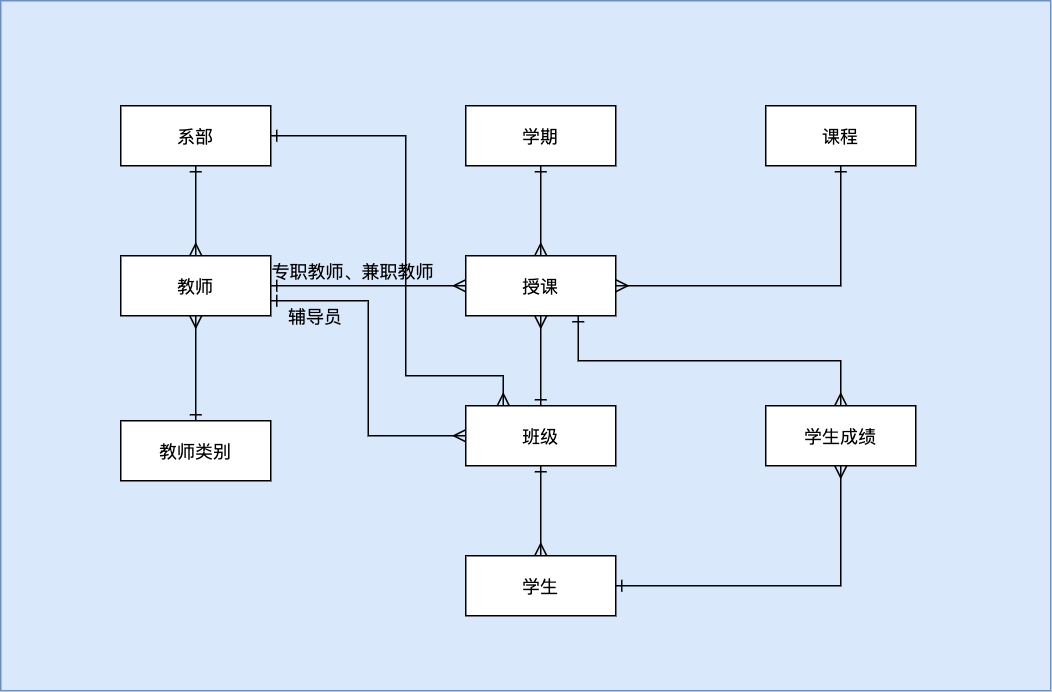
16.1.1需求描述
有一家高校,希望用计算机软件管理教务工作。请为其设计数据库对管理数据进行存储和操作。高校划分系部,系部下有班级,每个班级可有一名教师担任辅导员,专职辅导员可担任多个班级的辅导员。各系部管理自己的教师,教师分为“专职教师”、“兼职教师”、“专职辅导员”等。专职辅导员不能授课,其余教师可以跨系部任课,兼职教师周课时不得超过 6,一学期只能上一门课。
系统需要对各类教师统计工作量(教学和辅导),并记录学生成绩。
- 数据查询
- 查询某系部的所有教师
- 查某班级的所有学生
- 查询某学期某教师的所有任课记录
- 查询某班某学期的所有授课课程
- 查询某教师辅导的所有在校班级
- 查询某班某课程的所有学生成绩
- 数据统计
- 统计每个教师在某学期的所有周课时数
16.1.2 确定管理涉及的数据实体及其关系
根据描述与分析,绘制 E-R图如下:
16.2 进销存管理
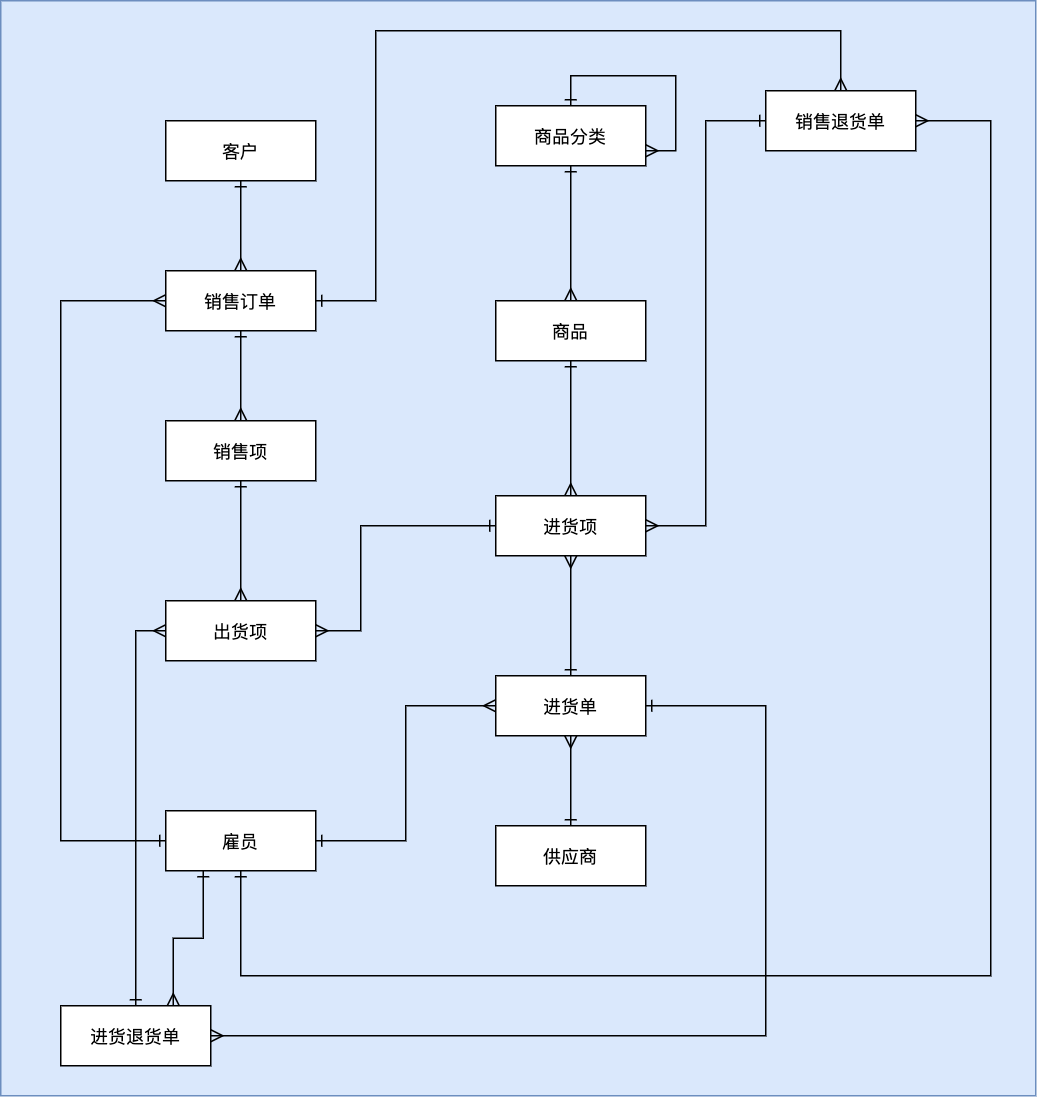
16.2.1 需求描述
某商店需要用计算机软件进行进销存及客户管理。成本核算采用先进先出法。商品可多级分类。
- 数据查询
- 查询商品的所有库存
- 列出某分类的所有商品
- 列出某客户的所有订单
- 列出本月过生日的所有客户
- 查询某商品的库存量
- 显示所有低于库存警戒线的商品
- 列出某商品的成本单价和库存量
- 数据统计
- 统计某商品在过去十二个月的每月销量
- 列出客户历史购买的商品数量和总额,从高到低排序
- 列出所有销售订单的销售总额、成本总额及毛利润
16.2.2 确定管理涉及的数据实体及其关系
根据描述与分析,绘制 E-R图如下:
附录
附录一 MySQL/MariaDB 常用数据类型速查表
(1)数值型
| 类型 | 大小 | 范围(有符号) | 范围(无符号) | 用途 |
|---|---|---|---|---|
| TINYINT | 1 字节 | (-128,127) | (0,255) | 微整数值 |
| SMALLINT | 2 字节 | (-32 768,32 767) | (0,65 535) | 小整数值 |
| MEDIUMINT | 3 字节 | (-8 388 608,8 388 607) | (0,16 777 215) | 中等整数值 |
| INT或INTEGER | 4 字节 | (-2 147 483 648,2 147 483 647) | (0,4 294 967 295) | 大整数值 |
| BIGINT | 8 字节 | (-9,223,372,036,854,775,808,9 223 372 036 854 775 807) | (0,18 446 744 073 709 551 615) | 极大整数值 |
| FLOAT | 4 字节 | (-3.402 823 466 E+38,-1.175 494 351 E-38),0,(1.175 494 351 E-38,3.402 823 466 351 E+38) | 0,(1.175 494 351 E-38,3.402 823 466 E+38) | 单精度浮点数值 |
| DOUBLE | 8 字节 | (-1.797 693 134 862 315 7 E+308,-2.225 073 858 507 201 4 E-308),0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 双精度浮点数值 |
| DECIMAL | 对DECIMAL(M,D) ,如果M>D,为M+2否则为D+2 | 依赖于M和D的值 | 依赖于M和D的值 | 小数值 |
(2)日期和时间类型
| 类型 | 大小(字节) | 范围 | 格式 | 用途 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | '-838:59:59'/'838:59:59' | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901/2155 | YYYY | 年份值 |
| DATETIME | 8 | 1000-01-01 00:00:00/9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| TIMESTAMP | 4 | 1970-01-01 00:00:00/2038 结束时间是第 2147483647 秒,北京时间 2038-1-19 11:14:07,格林尼治时间 2038年1月19日 凌晨 03:14:07 |
YYYYMMDD HHMMSS | 混合日期和时间值,时间戳 |
(3)字符串类型
| 类型 | 大小 | 用途 |
|---|---|---|
| CHAR | 0-255字节 | 定长字符串 |
| VARCHAR | 0-65535 字节 | 变长字符串 |
| TINYTEXT | 0-255字节 | 短文本字符串 |
| TEXT | 0-65 535字节 | 长文本数据 |
| MEDIUMTEXT | 0-16 777 215字节 | 中等长度文本数据 |
| LONGTEXT | 0-4 294 967 295字节 | 极大文本数据 |
(4)二进制类型(图像、音频、视频、二进制程序代码……)
| 类型 | 大小 | 用途 |
|---|---|---|
| TINYBLOB | 0-255字节 | 不超过 255 个字节的二进制数据 |
| BLOB | 0-65 535字节 | 二进制数据 |
| MEDIUMBLOB | 0-16 777 215字节 | 二进制中等长度数据 |
| LONGBLOB | 0-4 294 967 295字节 | 二进制极大长度数据 |
附录二 MySQL/MariaDB 比较运算与逻辑运算
比较运算
| 序号 | 运算符 | 含义 | 举例 |
|---|---|---|---|
| 1 | = | 等于 | name='王晓晓' |
| 2 | != | 不等于 | price!=800 |
| 3 | > | 大于 | count>1500 |
| 4 | >= | 大于或等于 | dateOfBirth>='1990-12-31' |
| 5 | < | 小于 | age<18 |
| 6 | <= | 小于等于 | age<=18 |
| 7 | between x and y | 介于 x 和 y 之间(含 x 和 y) | age between 18 and 60 |
| 8 | in (a,b,...) | 值等于 a,b,...中的任意一个 | loaction in ('昆明','上海','北京') |
| 9 | like 'xyz' | 像(匹配),% 代表零到任意多个任意字符的组合 | name like '李%' name like '%明' name like '%小%' |
逻辑运算
| 序号 | 运算符 | 含义 | 举例 |
|---|---|---|---|
| 1 | and | 并且 | a>10 and b>30(两条都要满足) |
| 2 | or | 或者 | a>10 or b>30(只要一条满足即可) |
| 3 | not | 不(否定) | name not like '%so%' id not in (1,10,12) |
| 4 | xor | 异或(相异为真) | age>18 xor title='' |
