@artman328
2022-08-31T08:55:39.000000Z
字数 67905
阅读 1596
数据库技术基础
信息技术工程系 软件工程硕士 陶冠华
Database
绪论 数据库相关概念、DBMS及其安装
(略)
第一讲 Windows 下 MariaDB 数据库管理系统的安装
第二讲 Linux下 MariaDB 数据库管理系统的安装
第三讲 Windows 下服务的管理和配置
1、图形界面管理

按 Windows徽标键+R 键,打开“运行”对话框,输入 services.msc后回车,在出现的服务管理窗口中进行操作。
2、命令行界面管理
按 Windows徽标键+R 键,打开“运行”对话框,输入 cmd后回车,可打开命令窗口。但有的命令需要管理员权限,因此需要以管理员身份打开 CMD。
(1)查看 MariaDB 服务
sc query mariadb / sc queryex mariadb 用于查看MariaDB服务器运行状态。
sc qc mariadb 用于查看MariaDB服务器配置
(2) 查看 MariaDB 服务网络监听端口
netstat -aon | findstr "mariadb服务的进程ID"
(3)启动和停止 MariaDB 服务
sc start mariadb用于启动 MariaDB 服务。
sc stop mariadb用于启动 MariaDB 服务。
(4)修改 MariaDB 的启动类型
sc config mariadb start= < auto | delayed-auto | demand | disabled >用于修改 MariaDB 服务的启动类型。
- auto: 自动,随操作系统启动而启动
- delayed-auto: 自动延迟,所有服务启动后若干时间(默认2分钟,可配置)再启动
- demand: 手动(需要时再启动)
- disabled: 禁用
3、MariaDB 服务的配置(含客户端工具配置)
MariaDB 的程序
| 程序 | 作用 |
|---|---|
| mysqld | mariadb 服务器程序 |
| mysqladmin | 管理服务器的客户端程序 |
| mysqldump | 备份数据库的客户端程序 |
| mysqlimport | 导入数据到服务器的客户端程序 |
| mysqlshow | 显示服务器中各种对象的客户端程序 |
| mysql | 与服务器交互的通用客户端程序 |
| …… |
(1)配置文件
用mysql --help 查看。
Default options are read from the following files in the given order:
C:\WINDOWS\my.ini
C:\WINDOWS\my.cnf
C:\my.ini
C:\my.cnf
C:\Program Files\MariaDB 10.7\my.ini
C:\Program Files\MariaDB 10.7\my.cnf
C:\Program Files\MariaDB 10.7\data\my.ini
C:\Program Files\MariaDB 10.7\data\my.cnf
配置文件的读取顺序,后面的相同配置会覆盖前面的。
(2)配置项
用命令名 --help查看可用配置项。
用 命令名 --print-defaults 查看当前默认配置。
(3)配置组
[mysqld]
# 配置服务器
[client]
# 配置所有客户端
[mysql]
# 配置 mysql
[mysqldump]
# 配置 mysqldump
...
第四讲 Linux 下 MariaDB 服务的管理与配置
(一)MariaDB服务的管理
1、查看 MariaDB 服务的状态和启动方式
sudo systemctl status mariadb
2、改变服务的启动方式
(1) 服务随操作系统启动而启动
sudo systemctl enable mariadb
(2)手动启动
sudo systemctl disable mariadb
3、启动服务
sudo systemctl start mariadb
4、停止服务
sudo systemctl stop mariadb
5、重启服务
sudo systemctl restart mariadb
(二)MariaDB 服务的配置
1、配置文件的位置
用:
命令 --help | more
进行查看。
2、服务器与客户端的配置
Linux 系统下的服务器和客户端配置与 Windows 下相同,不再赘述。
第五讲、 MariaDB 常用客户端程序的使用
(一)mysqladmin
mysqladmin 是用于管理服务器的一个客户端程序。此命令的格式是:
mysqladmin [各种选项] 命令 ...
常用选项:
# 服务器(默认:本机)-h主机IP或域名 或者: --host=主机IP或域名# 端口(默认:3306)-P端口号 或者: --port=端口号# 登录用户(默认:当前操作系统用户)-u用户名 或者: --user=用户名# 密码(忽略选项不用密码,忽略密码会在回车后提问)-p[密码] 或者: --password[=密码]#### 以上选项通用于各客户端程序,是登录选项
常用命令:
ping: 测试服务器的连通性(服务器是否运行中)version: 查看服务器版本号status: 查看服务器状态password: 修改用户密码create: 创建数据库drop: 删除数据库...
举例:
查看实作视频。
(二)mysqlshow
mysqlshow 是用于显示 MariaDB数据库服务器中数据库对象结构的客户端程序。
用法:
mysqlshow [各种选项] [数据库名 [表名 [列名]]]
常用选项:
登录选项与 mysqladmin 一致。
举例:【查看视频】
(三)mysqldump
mysqldump 是用于备份数据库的客户端程序。
用法:
mysqldump [各种选项] 数据库名 [表格列表] // 备份中不含数据库信息,只有表信息或 mysqldump [各种选项] --databases 数据库1 [数据库2 数据库3...]或 mysqldump [各种选项] --all-databases或 mysqldump [各种选项] --system=[SYSTEMOPTIONS]]
举例:【查看视频】
(四)mysql
mysql 是用于与服务器交互的通用客户端程序。
mysql [各种选项] [数据库名]或:mysql [各种选项] < sql脚本(备份文件等) // 可用于恢复备份
举例:【查看视频】
第六讲 mysql 客户端的使用及获取帮助
(一)客户端操作命令
(二)获取服务器端帮助
第七讲 案例一:员工信息查询与维护
本案例是基于单表的一个案例,主要学习信息的查询、统计、计算和维护。
预备工作:将数据库导入服务器
mysql -uroot -p --default-character-set=utf8mb4 < d:\sql\direct_db1.sql
(一)表结构
1、 ER图和数据字典
(1) ER图(Entity-Relationship)

(2)数据字典
| 序号 | 列名 | 含义 | 数据类型 | 可空? | 关键列 | 默认值 | 其它 |
|---|---|---|---|---|---|---|---|
| 1 | id | 编号 | 无符号大整型 | 主键 | NULL | 自动增长 | |
| 2 | name | 姓名 | 变长字符串(100) | NULL | |||
| 3 | gender | 性别 | 定长字符串(1) | NULL | |||
| 4 | birth_date | 出生日期 | 日期 | NULL | |||
| 5 | education | 学历 | 变长字符串(50) | NULL | |||
| 6 | employed_date | 聘用日期 | 日期 | NULL | |||
| 7 | department | 部门 | 变长字符串(255) | ✓ | NULL | ||
| 8 | salary | 月薪 | 小数(10位数字,2位小数) | NULL |
(二)查看表结构
1、 列出服务器中的数据库
MariaDB [(none)]> show databases;+--------------------+| Database |+--------------------+| direct_db1 || information_schema || mysql || performance_schema || sys |+--------------------+5 rows in set (0.001 sec)
2、进入数据库
MariaDB [(none)]> use direct_db1;Database changedMariaDB [direct_db1]>
3、列出数据库中的表格和视图
MariaDB [direct_db1]> show full tables;+----------------------+------------+| Tables_in_direct_db1 | Table_type |+----------------------+------------+| employees | BASE TABLE |+----------------------+------------+1 row in set (0.001 sec)MariaDB [direct_db1]>
4、 查看表结构
MariaDB [direct_db1]> desc employees;+---------------+---------------------+------+-----+---------+----------------+| Field | Type | Null | Key | Default | Extra |+---------------+---------------------+------+-----+---------+----------------+| id | bigint(20) unsigned | NO | PRI | NULL | auto_increment || name | varchar(100) | NO | | NULL | || gender | char(1) | NO | | NULL | || birth_date | date | NO | | NULL | || education | varchar(50) | NO | | NULL | || employed_date | date | NO | | NULL | || department | varchar(255) | YES | | NULL | || salary | decimal(10,2) | NO | | NULL | |+---------------+---------------------+------+-----+---------+----------------+8 rows in set (0.007 sec)
第八讲 案例一:员工信息查询与维护(续一)
(二)查看数据
先按上一讲进入 direct_db1 数据库。
SQL 语句不区分大小写,大小写是为了清晰起见。
列名和表名用反引号括起来,目的是避免与系统关键字冲突,同时也是为了清晰起见。如果明确没有冲突,也可不用括起来。
1、查看所有列的所有数据
MariaDB [direct_db1]> SELECT * FROM `employees`;
2、查看某些列的所有数据
MariaDB [direct_db1]> SELECT `id`, `name`, `gender`, `birth_date` FROM `employees`;
3、查看某列或多列组合的唯一值
MariaDB [direct_db1]> SELECT DISTINT `department` FROM `employees`;-- 多列组合MariaDB [direct_db1]> SELECT DISTINT `department`,`gender` FROM `employees`;
4、给列重命名
只是给结果集的列名重新命名,而不是对表的列重新命名。
SQL 语句只有碰到结束符号(此时是英文分号 ; )才会将语句送往服务器。因此,为清晰起见,一条语句可分为多行来写。
MariaDB [direct_db1]> SELECT-> `id` AS `编号`, `name` AS `姓名`, `gender` AS `性别`, `birth_date` AS `出生日期`-> FROM `employees`-> ;
5、 限制返回结果集的行数
限制前30行:
MariaDB [direct_db1]> SELECT * FROM `employees` LIMIT 30;
跳过100行后取30行:
MariaDB [direct_db1]> SELECT * FROM `employees` LIMIT 100, 30;-- 或者MariaDB [direct_db1]> SELECT * FROM `employees` LIMIT 30 OFFSET 100;
6、给结果集排序
SELECT MariaDB [direct_db1]> SELECT * FROM `employees`-> ORDER BY `salary` ASC; -- 以月薪升序排序。默认升序排序(可省略):ASC;降序:DESC
7、给汉字列排序
SELECT MariaDB [direct_db1]> SELECT * FROM `employees`-> ORDER BY `name`; -- 升序排序,不会按汉语拼音排序。
SELECT MariaDB [direct_db1]> SELECT * FROM `employees`-> ORDER BY CONVERT(`name` USING GBK); -- 升序排序,按汉语拼音排序。
8、多列排序
按部门中文拼音升序排序,部门相同再按月薪降序排序(超过两列均以此类推)。
MariaDB [direct_db1]> SELECT * FROM `employees`-> ORDER BY CONVERT(`department` USING GBK), `salary` DESC;
第九讲 案例一:员工信息查询与维护(续二)
(三)按条件查看数据
按条件查看数据,是指我们只需要那些符合一定条件的数据,而不是表里的所有数据。这些条件诸如:
“月薪大于某个数值的所有员工”、“月薪在某个范围的所有员工”、“年龄超过50的女性员工”等等。
我们用比较运算来确定对某列数据的要求(如果同时对多列数据有要求,需要用逻辑运算来组合这些要求),从而形成获取数据的条件。
参照: 附录二 MySQL/MariaDB 比较运算与逻辑运算
条件用 WHERE 条件表达式子句(SQL中完成一定功能的语句部分)来表达。
1、月薪查询(数值查询)
-- 月薪在5000元及以上的全体员工并按月薪从高到低进行结果排序SELECT * FROM `employees` WHERE `salary`>=5000 ORDER BY `salary` DESC;-- 月薪在5000到8000之间(不含5000和8000)的员工并按月薪从高到低进行结果排序SELECT * FROM `employees`WHERE `salary`>5000 AND `salary`<8000ORDER BY `salary` DESC;-- 月薪在5000到8000之间(含5000和8000)的员工并按月薪从高到低进行结果排序SELECT * FROM `employees`WHERE `salary`>=5000 AND `salary`<=8000ORDER BY `salary` DESC;-- 或者SELECT * FROM `employees`WHERE `salary` BETWEEN 5000 AND 8000ORDER BY `salary` DESC;
2、姓名查询(字符串查询)
-- 查找姓名为“宋琴”的员工。SELECT * FROM `employees` WHERE `name`='宋琴';-- 查找所有“张”姓员工SELECT * FROM `employees` WHERE `name` LIKE '张%';-- 查找以“明”字结尾的所有员工SELECT * FROM `employees` WHERE `name` LIKE '%明';-- 查找名字包含“丹”字的全体员工SELECT * FROM `employees` WHERE `name` LIKE '%丹%';
3、出生日期相关查询(日期查询)
(1) 函数:TIMESTAMPDIFF 介绍(Timestamp Difference)
用法:TIMESTAMPDIFF(度量单位,日期1,日期2)
功能:计算两个日期之间的间隔,度量单位由第一个参数决定。
度量单位包括:MICROSECOND(毫秒)、SECOND(秒)、MINUTE(分)、HOUR(小时)、DAY(天)、WEEK(周)、MONTH(月)、QUARTER(季度)、YEAR(年)。
如果日期1<日期2,结果为正,反之为负。
(2) 函数:NOW 和 CURDATE (Current Date)介绍
用法:NOW() -- 返回当前日期和时间
CURDATE() -- 返回当前日期
-- 找出所有于1980年及以后出生的所有员工并按出生日期从低到高排序SELECT * FROM `employees` WHERE `birth_date`>='1980-01-01' ORDER BY `birth_date` ASC;-- 日期用字符串表示法表示,推荐标准格式为:YYYY-MM-DD-- 日期可以和数值一样做各种比较运算-- 找出年龄在30岁到40岁(含30岁和40岁)之间的员工并按年龄从低到高排序SELECT *, TIMESTAMPDIFF(YEAR,`birth_date`, CURDATE()) AS `age`FROM `employees`WHERE TIMESTAMPDIFF(YEAR,`birth_date`, CURDATE()) BETWEEN 30 AND 40 -- WHERE字句中不能用别名 ageORDER BY `age` ASC; -- 别名只能用在 ORDER BY, GROUP BY 及 HAVING 子句中
4、涉及多字段的复杂查询
(1)找出月薪在5000(含)到6000(含)的女性员工,按月薪低到高排序。
SELECT * FROM `employees`WHERE `salary` BETWEEN 5000 AND 6000 AND `gender`='女'ORDER BY `salary` ASC;
(2)找出“财务室”和“人事处”的女性员工。
SELECT * FROM `employees`WHERE `department` IN ('财务室','人事处') AND `gender`='女'ORDER BY `department`;
(3)找出不在“财务室”、“人事处”和“营销部”的女性员工。
SELECT * FROM `employees`WHERE `department` NOT IN ('财务室','人事处','营销部') AND `gender`='女'ORDER BY `department`;
(3)找出月薪低于3000的员工或者月薪在1000以下的且年龄在50岁及以上的女性员工。
SELECT * FROM `employees`WHERE (`salary`<3000) OR (`salary`<10000 AND TIMESTAMPDIFF(YEAR,`birth_date`, CURDATE())>=50AND `gender`='女')ORDER BY `salary` ASC;
(4)找出月薪低于3000或者月薪高于5000,并且性别为女性或者年龄在45岁以上的男性员工。
SELECT *, TIMESTAMPDIFF(YEAR,`birth_date`,CURDATE()) AS `age` FROM `employees`WHERE (`salary`<3000 OR `salary`>5000) AND(`gender`='女' OR TIMESTAMPDIFF(YEAR,`birth_date`,CURDATE())>45 AND `gender`='男')ORDER BY `gender`, `age`, `salary`;
第十讲 案例一:员工信息查询与维护(续三)
(四)统计和计算
1、统计记录数
-- 统计表中的记录总数SELECT COUNT(*) FROM `employees`;-- 统计表中部门列中不为 NULL 的记录数SELECT COUNT(`department`) FROM `employees`;-- 统计表中部门列不为 NULL 的具有不同的值的记录数SELECT COUNT(DISTINCT `department`) FROM `employees`;-- 按条件统计表中记录数SELECT COUNT(*) FROM `employees` WHERE `salary`>10000;
2、计算表中月薪总额、平均月薪(保留两们小数)
-- sum: 总和-- avg: average, 平均值-- round: (为方便计算和表达)取数字的近似值。默认取整,或保留第二个参数指定的小数位数。SELECT SUM(`salary`) AS `月薪总额`, ROUND(AVG(`salary`),2) AS `平均月薪` FROM `employees`;
3、取出月薪的最大值和最小值
SELECT MAX(`salary`) AS `最高月薪`, MIN(`salary`) AS `最低月薪` FROM `employees`;
4、分组统计
-- 统计出各部门的员工人数(单列分组统计)SELECT `department` AS `部门`, COUNT(*) AS `员工数`FROM `employees`GROUP BY `department`;-- 统计出各部门的男女员工人数(多列分组统计)SELECT `department` AS `部门`, `gender` AS `性别`, COUNT(*) AS `员工数`FROM `employees`GROUP BY `department`,`gender`;-- 统计出各部门年龄在40岁以上的员工人数(带条件的统计)SELECT `department` AS `部门`, MIN(TIMESTAMPDIFF(YEAR,`birth_date`,CURDATE())) AS `起始年龄`,COUNT(*) AS `员工数`FROM `employees`WHERE TIMESTAMPDIFF(YEAR,`birth_date`,CURDATE())>40GROUP BY `department`;-- 显示人数在30人及以上的部门和人数(对统计结果做条件过滤)SELECT `department` AS `部门`, COUNT(*) AS `员工数`FROM `employees`GROUP BY `department`HAVING `员工数`>=30;-- 按出生年代分组统计最高月薪、最低月薪和平均月薪SELECT YEAR(`birth_date`) AS `YEAR`, MAX(`salary`), MIN(`salary`), ROUND(AVG(`salary`),2)FROM `employees`GROUP BY `YEAR`;-- 以每10岁为一个年龄段,分组统计各年龄段的最高月薪、最低月薪和平均月薪-- 比如年龄为:20+(20~29),30+,40+ ...-- CONCAT(arg1,arg2,arg3...) 将传入的多个数据(自动转换为字符串)作字符串连接-- CONCAT(20,' years ', 'old') => '20 years old'-- 如果 arg 是整数 a 和 整数 a+1 之间的一个小数(小数部分不为零):-- FLOOR(arg) 得到 a。FLOOR(2.999) => 2-- CEIL(arg) 得到 a+1。CEIL(6.0001) => 7-- 20~29 => 20-- floor(20/10) => floor(2.0) => 2 => 2 * 10 => 20-- floor(29/10) => floor(2.9) => 2 => 2 * 10 => 20SELECTCONCAT(FLOOR(TIMESTAMPDIFF(YEAR,`birth_date`,CURDATE())/10)*10, '+') AS `age`,MAX(`salary`), MIN(`salary`), ROUND(AVG(`salary`),2)FROM `employees`GROUP BY `age`;
第十一讲 案例一:员工信息查询与维护(续四)
(五)子查询
子查询,是“寄生”于一条查询语句中的完整的查询语句,其结果用于主查询语句中。子查询需要用圆括号括起来。查询可以多层嵌套,内层查询是外层查询的子查询。
1、子查询应用于结果列
例:显示员工的所有信息,并包括其所在部门的最高工资和最低工资。
SELECT *,(SELECT MAX(`b`.`salary`) FROM `employees` `b` WHERE `department`=`a`.`department`) AS `部门最高工资`,(SELECT MIN(`b`.`salary`) FROM `employees` `b` WHERE `department`=`a`.`department`) AS `部门最低工资`FROM `employees` `a`LIMIT 10;
由于子查询与主查询记录相关(判断依据:子查询不能独立执行),对每一行数据,都要执行两次子查询,查询效率低,不适合需要返回大量行的结果的查询。
2、子查询应用到 WHERE 子句
(1)例:显示工资高于部门平均工资(含)的员工信息。
SELECT *,ROUND((SELECT AVG(`b`.`salary`) FROM `employees` `b` WHERE `department`=`a`.`department`),2) AS `部门平均工资`FROM `employees` `a`WHERE `a`.`salary`>=(SELECT AVG(`b`.`salary`) FROM `employees` `b` WHERE `department`=`a`.`department`);
同样,由于子查询与主查询记录相关(判断依据:子查询不能独立执行),对每一行数据,都要执行两次子查询(一次在结果列,一次在 WHERE 子句中),查询效率低,不适合需要返回大量行的结果的查询。
(2)例:显示姓名包含'明'字的所有员工信息。
SELECT * FROM `employees`WHERE id in (SELECT `id` FROM `employees` WHERE `name` LIKE '%明%' );-- 上例仅用于说明与主查询无关的子查询的应用,其实相当于:SELECT * FROM `employees` WHERE `name` LIKE '%明%';
此例中的子查询与主查询记录不相关(子查询可独立执行),因此不会对查询的总体效率产生显著影响。
第十二讲 案例一:员工信息查询与维护(续五)
(六)数据维护
数据维护是指数据的插入、修改和删除等。
1、插入数据
插入数据的语法:
INSERT INTO 表名 [(列名1,列名2,...列名n)]VALUES(值1,值2,...值n)[,(值1,值2,...值n),...];-- 或者从另一表获取记录并插入到当前表(对应列应当具有相同数据类型和宽度)INSERT INTO 表名 [(列名1,列名2,...列名n)]SELECT 列名_1,列名_2, ... 列名_3FROM 另一表名[WHERE] ...;
如果要将数据插入到所有列,可省略列名列表。
插入的数据可以不需要包括所有列,但必须包含那些需要数据的列。如何确定必须需要数据的列?可用以下原则确定:
- 不允许为空(NULL)的列
- 且缺省值为 NULL 的(或无缺省值定义的)列
- 且无自动增长(AUTO_INCREMENT)特性的列
MariaDB [direct_db1]> desc employees;+---------------+---------------------+------+-----+---------+----------------+| Field | Type | Null | Key | Default | Extra |+---------------+---------------------+------+-----+---------+----------------+| id | bigint(20) unsigned | NO | PRI | NULL | auto_increment || name | varchar(100) | NO | | NULL | || gender | char(1) | NO | | NULL | || birth_date | date | NO | | NULL | || education | varchar(50) | NO | | NULL | || employed_date | date | NO | | NULL | || department | varchar(255) | YES | | NULL | || salary | decimal(10,2) | NO | | NULL | |+---------------+---------------------+------+-----+---------+----------------+8 rows in set (0.007 sec)
不符合以上条件的列只有 id 和 department。
注意: 对具有 AUTO_INCREMENT 特性的列,可插入 NULL 值,由其自行决定自己的取值。
以下例子添加两条数据到 employees 表。
INSERT INTO `employees`VALUES(NULL,'张琦','男','1990-02-03','本科','2021-10-12',NULL,3500.00),(NULL,'王瑶琚','女','1996-11-15','本科','2021-10-12',NULL,3000.00);
2、修改数据
修改数据的语法是:
UPDATE 表名 SET 列名1=值1 [,列名2=值2 [,...]][WHERE 条件]
以下语句将所有部门未知的员工添加到“产品部”。
UPDATE `employees` SET `department`='产品部' WHERE department IS NULL;
3、删除数据
删除数据的语法是:
DELETE FROM 表名 [WHERE 条件]
注意: 不带条件的删除将删除表中所有数据!
以下语句将删除 employees 表中编号为235的员工记录。
DELETE FROM `employees` WHERE id=235;
第十三讲 案例二:部门-员工信息查询与维护
(一)准备工作
1、导入数据库
将案例二的备份文件导入数据库服务器
mysql -uroot -p --default-character-set=utf8 < direct_db2.sql
2、查看表结构
用 mysql 客户端登录数据库服务器,进入 direct_db2 数据库。
mysql -uroot -p direct_db2
然后用以下命令查看数据库中的表。
show tables;
针对每张表,用:desc 表名; 和 show create table 表名; 查看表的定义。
(二)城市-宾客关联表讲解
表的关联:一张表需要参照其它表才能获得完整信息,则这两张表就是关联的。我们先来看以下两张表的记录。
宾客表(guests):
MariaDB [direct_db2]> select * from guests;+----+--------------------+--------+--------------+| id | sid | name | from_city_id |+----+--------------------+--------+--------------+| 1 | 530199198703210028 | 王小妮 | 4 || 2 | 510298199012120087 | 张燕 | 4 || 3 | 109877199910100136 | 李志强 | 3 || 4 | 230987198901030358 | 周超 | 1 || 5 | 310987199703280824 | 吴倩倩 | 1 || 6 | 651263199901300871 | 郑志 | NULL || 7 | 538922200110220116 | 蒋嘉乐 | 5 |+----+--------------------+--------+--------------+7 rows in set (0.001 sec)MariaDB [direct_db2]>
在以上的宾客表中,最后一列 from_city_id 从字面上看是“来自城市编号”,应该用于表明宾客来自于哪个城市,但数据是城市的编号,我们无法从编号得知宾客到底来自哪个城市。好在我们有一张关于“城市”的表。
城市表(cities):
MariaDB [direct_db2]> select * from cities;+----+------+| id | city |+----+------+| 1 | 上海 || 2 | 北京 || 3 | 广州 || 4 | 成都 || 5 | 昆明 |+----+------+5 rows in set (0.024 sec)MariaDB [direct_db2]>
结合两张表,我们显然可知道各个宾客来自哪个城市了,除了第6号宾客“郑志”。如:1号宾客来自于4号城市“成都”,3号宾客来自于3号城市“广州”等。
为了证实我们的结论——即宾客表(guests)的from_city_id参照了城市表(cities)的id,我们来查看两张表的详细定义。
MariaDB [direct_db2]> show create table guests\G*************************** 1. row ***************************Table: guestsCreate Table: CREATE TABLE `guests` (`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,`sid` char(18) NOT NULL,`name` varchar(50) NOT NULL,`from_city_id` bigint(20) unsigned DEFAULT NULL,PRIMARY KEY (`id`),UNIQUE KEY `sid` (`sid`),KEY `from_city_id` (`from_city_id`),CONSTRAINT `guests_ibfk_1` FOREIGN KEY (`from_city_id`) REFERENCES `cities` (`id`) ON DELETE SET NULL ON UPDATE CASCADE) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf81 row in set (0.000 sec)MariaDB [direct_db2]>
这是表“guests”的创建信息(竖排)。“Table” 列说明了表的名称 “guests”,“Create Table” 列的内容是创建 “guests” 表的 SQL 语句。我们把创建 “guests” 表的 SQL 语句抽取出来:
CREATE TABLE `guests` (`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT, -- 大整型无符号 不为空 自动增长`sid` char(18) NOT NULL, -- 定长字符串(18) 不为空`name` varchar(50) NOT NULL, -- 变长字符串 不为空`from_city_id` bigint(20) unsigned DEFAULT NULL, -- 大整型无符号 缺省值为nullPRIMARY KEY (`id`), -- 主键索引UNIQUE KEY `sid` (`sid`), -- 唯一索引KEY `from_city_id` (`from_city_id`), -- 普通索引CONSTRAINT `guests_ibfk_1` FOREIGN KEY (`from_city_id`) REFERENCES `cities` (`id`) ON DELETE SET NULL ON UPDATE CASCADE -- 外键约束) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8;
创建表的语法参见MariaDB说明文档。
创建表的语句可将主干抽取如下:
CREATE TABLE `guests`(逗号分隔的列定义,索引定义,约束定义...) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8;
其中的列定义:
列名 数据类型和规模 [可否为空] [缺省值] [自动增长] [约束]...,
索引定义:
索引类型 [索引名] (索引列1,索引列2...)
约束定义:
CONSTRAINT [约束名] CHECK (表达式)
我们来看看外键约束定义:
CONSTRAINT `guests_ibfk_1` FOREIGN KEY (`from_city_id`) REFERENCES `cities` (`id`) ON DELETE SET NULL ON UPDATE CASCADE -- 外键约束-- 约束 `guests_ibfk_1` 外键 (`from_city_id`) 参照 `cities` (`id`) 在删除(参照的主表记录)时设置空值(SET NULL)在更新(参照的主表记录的id)时级联更新(CASCADE)
其中提到了guests表的from_city_id是外键,参照了cities表的id(主键)。并且:
- 当被参照的主表
cities中的记录被删除时,将外键设置成空值(因为失去了原有的参照记录); - 当被参照的主表
cities中的记录的主键id被修改时,将外键级联修改到新的id值。
以下是两表对应的实体关系图:

关系解读:
一个城市可有多名来宾,一名宾客来自一个城市。城市与宾客的关系是:一对多的关系。
(三)关联表数据的获取
宾客表(guests):
MariaDB [direct_db2]> select * from guests;+----+--------------------+--------+--------------+| id | sid | name | from_city_id |+----+--------------------+--------+--------------+| 1 | 530199198703210028 | 王小妮 | 4 || 2 | 510298199012120087 | 张燕 | 4 || 3 | 109877199910100136 | 李志强 | 3 || 4 | 230987198901030358 | 周超 | 1 || 5 | 310987199703280824 | 吴倩倩 | 1 || 6 | 651263199901300871 | 郑志 | NULL || 7 | 538922200110220116 | 蒋嘉乐 | 5 |+----+--------------------+--------+--------------+7 rows in set (0.001 sec)MariaDB [direct_db2]>
城市表(cities):
MariaDB [direct_db2]> select * from cities;+----+------+| id | city |+----+------+| 1 | 上海 || 2 | 北京 || 3 | 广州 || 4 | 成都 || 5 | 昆明 |+----+------+5 rows in set (0.024 sec)MariaDB [direct_db2]>
仔细观察两张表的记录,会发现:
- 宾客表
guests中有的记录的外键值是NULL,即:我们不知道其来自哪里;如表中第 6 号宾客。 - 城市表
cities中有的城市主键id值并未在宾客表中出现,即:没有宾客来自此城市。如表中第 2 号城市。
用图示表示如下:

下面,我们分四种情况来获取关联的记录:
- 内联查询:查交集部分记录(图中两圆的交集部分)
- 强调宾客表的所有记录:查落在蓝色圆圈内的记录(含交集部分)
- 强调城市表的所有记录:查落在淡黄色圆圈内的记录(含交集部分)
- 强调两表的所有记录:查两圆内的所有记录(含交集部分)
1、内联查询:查交集部分记录(图中两圆的交集部分)
结果预期:结果集应仅包含所有在交集内出现的宾客和城市记录(外部的宾客:郑治 被排除,外部的城市:北京 被排除)。
SELECT `guests`.*, `cities`.* -- 列名前加表名限定FROM `guests` INNER JOIN `cities` -- 两表内联,次序不论ON `guests`.`from_city_id`=`cities`.`id` -- 联接条件 外键=主键;+----+--------------------+--------+--------------+----+------+| id | sid | name | from_city_id | id | city |+----+--------------------+--------+--------------+----+------+| 1 | 530199198703210028 | 王小妮 | 4 | 4 | 成都 || 2 | 510298199012120087 | 张燕 | 4 | 4 | 成都 || 3 | 109877199910100136 | 李志强 | 3 | 3 | 广州 || 4 | 230987198901030358 | 周超 | 1 | 1 | 上海 || 5 | 310987199703280824 | 吴倩倩 | 1 | 1 | 上海 || 7 | 538922200110220116 | 蒋嘉乐 | 5 | 5 | 昆明 |+----+--------------------+--------+--------------+----+------+6 rows in set (0.002 sec)
要点:
- 因为涉及两张表,列名要用 `表名`.`列名` 的形式加以区分(事实上,如果列名只在一张表中出现,可以不加表名进行限制,但加上可增加可读性);
- FROM 子句中要将两张表用 INNER JOIN 联接,次序不论;
- ON 子句说明联接条件,后面跟 外键=主键(或主键=外键)。
如果要在联接查询的基础上过滤结果集,可在基本内联查询的后面,用条件对结果集进行过滤并进行排序、限定记录范围和记录数等。
如:
SELECT `guests`.*, `cities`.*FROM `guests` INNER JOIN `cities` -- 两表内联ON `guests`.`from_city_id`=`cities`.`id` -- 联接条件 外键=主键WHERE `guests`.`sid` like '53%'ORDER BY CONVERT(`guests`.`name` USING GBK) ASC;+----+--------------------+--------+--------------+----+------+| id | sid | name | from_city_id | id | city |+----+--------------------+--------+--------------+----+------+| 7 | 538922200110220116 | 蒋嘉乐 | 5 | 5 | 昆明 || 1 | 530199198703210028 | 王小妮 | 4 | 4 | 成都 |+----+--------------------+--------+--------------+----+------+2 rows in set (0.001 sec)
2、强调宾客表的所有记录:查落在蓝色圆圈内的记录(含交集部分)
结果预期:结果集内应当包含所有的宾客记录和在交集内出现的城市记录(外部的北京被排除)。
以下采用简洁写法:表用短别名表示,去除反引号(因为确信没有表名或列名与系统关键字冲突)。
SELECT g.*, c.*FROM guests g LEFT OUTER JOIN cities c -- 或者:cities c RIGHT OUTER JOIN guests gON g.from_city_id=c.id;+----+--------------------+--------+--------------+------+------+| id | sid | name | from_city_id | id | city |+----+--------------------+--------+--------------+------+------+| 1 | 530199198703210028 | 王小妮 | 4 | 4 | 成都 || 2 | 510298199012120087 | 张燕 | 4 | 4 | 成都 || 3 | 109877199910100136 | 李志强 | 3 | 3 | 广州 || 4 | 230987198901030358 | 周超 | 1 | 1 | 上海 || 5 | 310987199703280824 | 吴倩倩 | 1 | 1 | 上海 || 6 | 651263199901300871 | 郑志 | NULL | NULL | NULL || 7 | 538922200110220116 | 蒋嘉乐 | 5 | 5 | 昆明 |+----+--------------------+--------+--------------+------+------+7 rows in set (0.001 sec)
要点:
- 因为涉及两张表,列名要用 `表名`.`列名` 的形式加以区分(事实上,如果列名只在一张表中出现,可以不加表名进行限制,但加上可增加可读性);
- FROM 子句中要将两张表用 LEFT OUTER JOIN 或 RIGHT OUTER JOIN 联接,次序不论,但要用 LEFT OUT JOIN 或 RIGHT OUTER JOIN 强调左边或右边表的所有记录;
- ON 子句说明联接条件,后面跟 外键=主键(或主键=外键)。
3、强调城市表的所有记录:查落在淡黄色圆圈内的记录(含交集部分)
结果预期:结果集内应当包含所有的城市记录和在交集内出现的宾客记录(外部的郑治被排除)。
以下采用简洁写法:表用短别名表示,去除反引号(因为确信没有表名或列名与系统关键字冲突)。
SELECT g.*, c.*FROM guests g RIGHT OUTER JOIN cities c -- 或者:cities c LEFT OUTER JOIN guests gON g.from_city_id=c.id;+------+--------------------+--------+--------------+----+------+| id | sid | name | from_city_id | id | city |+------+--------------------+--------+--------------+----+------+| 4 | 230987198901030358 | 周超 | 1 | 1 | 上海 || 5 | 310987199703280824 | 吴倩倩 | 1 | 1 | 上海 || NULL | NULL | NULL | NULL | 2 | 北京 || 3 | 109877199910100136 | 李志强 | 3 | 3 | 广州 || 1 | 530199198703210028 | 王小妮 | 4 | 4 | 成都 || 2 | 510298199012120087 | 张燕 | 4 | 4 | 成都 || 7 | 538922200110220116 | 蒋嘉乐 | 5 | 5 | 昆明 |+------+--------------------+--------+--------------+----+------+7 rows in set (0.000 sec)
要点:
- 因为涉及两张表,列名要用 `表名`.`列名` 的形式加以区分(事实上,如果列名只在一张表中出现,可以不加表名进行限制,但加上可增加可读性);
- FROM 子句中要将两张表用 LEFT OUTER JOIN 或 RIGHT OUTER JOIN 联接,次序不论,但要用 LEFT OUT JOIN 或 RIGHT OUTER JOIN 强调左边或右边表的所有记录;
- ON 子句说明联接条件,后面跟 外键=主键(或主键=外键)。
4、强调两表的所有记录:查两圆内的所有记录(含交集部分)
结果预期:所有的宾客记录和城市记录均出现。
SELECT g.*, c.*FROM guests g LEFT OUTER JOIN cities cON g.from_city_id=c.idUNIONSELECT g.*, c.*FROM guests g RIGHT OUTER JOIN cities cON g.from_city_id=c.id;+------+--------------------+--------+--------------+------+------+| id | sid | name | from_city_id | id | city |+------+--------------------+--------+--------------+------+------+| 1 | 530199198703210028 | 王小妮 | 4 | 4 | 成都 || 2 | 510298199012120087 | 张燕 | 4 | 4 | 成都 || 3 | 109877199910100136 | 李志强 | 3 | 3 | 广州 || 4 | 230987198901030358 | 周超 | 1 | 1 | 上海 || 5 | 310987199703280824 | 吴倩倩 | 1 | 1 | 上海 || 6 | 651263199901300871 | 郑志 | NULL | NULL | NULL || 7 | 538922200110220116 | 蒋嘉乐 | 5 | 5 | 昆明 || NULL | NULL | NULL | NULL | 2 | 北京 |+------+--------------------+--------+--------------+------+------+8 rows in set (0.003 sec)MariaDB [direct_db2]>
要点:
- 对两表分别强调一次进行外联查询,将两次查询的结果集用 UNION 联合起来。
第十四讲 案例二:部门-员工信息查询与维护
(四)部门员工关联表的信息获取练习
1、员工表与部门表的表间关系
首先我们来看看员工表(employees)的结构。
MariaDB [direct_db2]> desc employees;+---------------+---------------------+------+-----+---------+----------------+| Field | Type | Null | Key | Default | Extra |+---------------+---------------------+------+-----+---------+----------------+| id | bigint(20) unsigned | NO | PRI | NULL | auto_increment || name | varchar(100) | NO | | NULL | || gender | char(1) | NO | | NULL | || birth_date | date | NO | | NULL | || education | varchar(50) | NO | | NULL | || employed_date | date | NO | | NULL | || salary | decimal(10,2) | NO | | NULL | || department_id | bigint(20) unsigned | YES | MUL | NULL | |+---------------+---------------------+------+-----+---------+----------------+8 rows in set (0.013 sec)
以下是部门表(departments)的结构。
MariaDB [direct_db2]> desc departments;+-----------+---------------------+------+-----+---------+----------------+| Field | Type | Null | Key | Default | Extra |+-----------+---------------------+------+-----+---------+----------------+| id | bigint(20) unsigned | NO | PRI | NULL | auto_increment || name | varchar(100) | NO | UNI | NULL | || location | varchar(100) | NO | | NULL | || telephone | varchar(50) | NO | | | || email | varchar(100) | NO | | | |+-----------+---------------------+------+-----+---------+----------------+5 rows in set (0.007 sec)
以下是员工表(employees)的详细定义。
MariaDB [direct_db2]> show create table employees\G*************************** 1. row ***************************Table: employeesCreate Table: CREATE TABLE `employees` (`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,`name` varchar(100) COLLATE utf8mb4_unicode_ci NOT NULL,`gender` char(1) COLLATE utf8mb4_unicode_ci NOT NULL,`birth_date` date NOT NULL,`education` varchar(50) COLLATE utf8mb4_unicode_ci NOT NULL,`employed_date` date NOT NULL,`salary` decimal(10,2) NOT NULL,`department_id` bigint(20) unsigned DEFAULT NULL,PRIMARY KEY (`id`),KEY `department_id` (`department_id`),CONSTRAINT `employees_ibfk_1` FOREIGN KEY (`department_id`) REFERENCES `departments` (`id`) ON DELETE SET NULL ON UPDATE CASCADE) ENGINE=InnoDB AUTO_INCREMENT=234 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci1 row in set (0.006 sec)
第15行说明了员工表(employees)的外键 department_id 参照了部门表(departments)的主键 id。
2、查询举例
(1)获取那些尚未归到某部门的员工
a)连接查询的确定
员工尚未归到某个部门,意味着其外键 department_id 是空值(null)。因为不需要部门信息,也就不需要连接查询。
b)查询条件
员工的部门编号为空值(null)。
c)其它需求
无。
SELECT * FROM `employees` WHERE `department_id` IS NULL;+-----+--------+--------+------------+-----------+---------------+---------+---------------+| id | name | gender | birth_date | education | employed_date | salary | department_id |+-----+--------+--------+------------+-----------+---------------+---------+---------------+| 113 | 顾桂花 | 女 | 1981-12-23 | 硕士 | 2021-01-01 | 7284.00 | NULL || 191 | 张丽 | 女 | 1981-12-10 | 硕士 | 2021-01-26 | 9242.00 | NULL |+-----+--------+--------+------------+-----------+---------------+---------+---------------+2 rows in set (0.001 sec)
(2)获取那些尚未有员工的部门
a)连接查询的确定
尚未有员工,不需要员工信息,因此不需要连接查询。
b)查询条件
部门编号与当前部门编号相同的员工人数为0,需要在 WHERE 子句中判断(用子查询)。
c)其它需求
无。
SELECT * FROM `departments` `d`WHERE (SELECT COUNT(*) FROM `employees` `e` WHERE`e`.`department_id`=`d`.`id`)=0;+----+--------+----------+---------------+----------------------+| id | name | location | telephone | email |+----+--------+----------+---------------+----------------------+| 3 | 售后部 | 1511 | 0809-29871088 | service@starcomp.com || 7 | 公关部 | 1508 | 0809-29871098 | pubrela@starcomp.com |+----+--------+----------+---------------+----------------------+2 rows in set (0.001 sec)
(3)获取所有员工的 id, name, gender, birth_date, education, department(部门名称)
a)连接查询的确定
因为需要员工信息和部门信息,需要两表连接查询。又因为需要所有员工信息,因此应当采用偏向员工表的外部连接。
b)查询条件
无。
c)其它需求
为便于查看记录,结果集将按部门名称升序、员工编号升序的顺序进行排序。
SELECT `e`.`id`, `e`.`name`, `e`.`gender`, `e`.`birth_date`, `e`.`education`, `d`.`name` AS `department`FROM `employees` `e` LEFT OUTER JOIN `departments` `d` -- 员工表在左,因此 LEFT OUTER JOINON `e`.`department_id`=`d`.`id`ORDER BY CONVERT(`department` USING GBK), `e`.`id`;+-----+--------+--------+------------+-----------+------------+| id | name | gender | birth_date | education | department |+-----+--------+--------+------------+-----------+------------+| 113 | 顾桂花 | 女 | 1981-12-23 | 硕士 | NULL || 191 | 张丽 | 女 | 1981-12-10 | 硕士 | NULL || 4 | 景华 | 男 | 1978-01-06 | 硕士 | 财务室 || 35 | 银馨予 | 女 | 1986-12-05 | 本科 | 财务室 || 76 | 项志强 | 男 | 1989-05-20 | 硕士 | 财务室 || 77 | 司楠 | 男 | 1990-06-05 | 博士 | 财务室 |...| 228 | 窦伦 | 男 | 1975-06-07 | 硕士 | 营销部 || 229 | 赖桂花 | 女 | 1985-03-22 | 本科 | 营销部 || 230 | 植淑珍 | 女 | 1983-07-22 | 本科 | 营销部 || 231 | 常雪 | 女 | 1991-05-31 | 本科 | 营销部 || 232 | 苏兰英 | 女 | 1982-08-20 | 本科 | 营销部 |+-----+--------+--------+------------+-----------+------------+233 rows in set (0.001 sec)
(4)获取所有的部门及其员工信息(id, name, gender, birth_date, education)
a)连接查询的确定
因为需要来自两表的信息,需要连接查询。又因为需要所有部门,应当采用偏向部门表的外部连接。
b)查询条件
无。
c)其它需求
为便于查看结果,结果集将按部门编号升序排序。
SELECT `d`.`id`, `d`.`name`, `e`.`id` AS `eid`, `e`.`name` AS `ename`, `e`.`gender`, `e`.`birth_date`, `e`.`education`FROM `departments` `d` LEFT OUTER JOIN `employees` `e` -- 部门表在左,因此 LEFT OUTER JOINON `d`.`id`=`e`.`department_id`ORDER BY `d`.`id`;+----+--------+------+--------+--------+------------+-----------+| id | name | eid | ename | gender | birth_date | education |+----+--------+------+--------+--------+------------+-----------+| 1 | 设计部 | 1 | 萧正诚 | 男 | 1990-03-07 | 本科 || 1 | 设计部 | 6 | 陆桂香 | 女 | 1988-02-14 | 本科 || 1 | 设计部 | 11 | 刘丹丹 | 女 | 1977-04-04 | 本科 |...| 2 | 人事处 | 227 | 明洪 | 男 | 1977-07-26 | 本科 || 3 | 售后部 | NULL | NULL | NULL | NULL | NULL |...| 6 | 产品部 | 212 | 唐雪梅 | 女 | 1983-12-05 | 硕士 || 6 | 产品部 | 213 | 匡智敏 | 男 | 1974-09-03 | 硕士 || 6 | 产品部 | 224 | 金爱华 | 女 | 1976-08-07 | 本科 || 6 | 产品部 | 225 | 武松 | 男 | 1984-02-29 | 硕士 || 7 | 公关部 | NULL | NULL | NULL | NULL | NULL |+----+--------+------+--------+--------+------------+-----------+233 rows in set (0.001 sec)
(5)列出部门和员工,包括无员工的部门和无部门的员工
部门信息包括:id, name
员工信息包括:id, name, gender, birth_date, education
a)连接查询的确定
需要所有部门和所有员工的对应记录,因此应当采用全连接(实现:对员工表和部门表分别偏向一次进行外连接,将结果联合起来)。
b)查询条件
无。
c)其它需求
无。
SELECT `d`.`id`,`d`.`name`, `e`.`id` AS `eid`, `e`.`name` AS `ename`, `e`.`gender`, `e`.`birth_date`, `e`.`education`FROM `departments` `d` LEFT OUTER JOIN `employees` `e`ON `d`.`id`=`e`.`department_id`UNIONSELECT `d`.`id`,`d`.`name`, `e`.`id` AS `eid`, `e`.`name` AS `ename`, `e`.`gender`, `e`.`birth_date`, `e`.`education`FROM `departments` `d` RIGHT OUTER JOIN `employees` `e`ON `d`.`id`=`e`.`department_id`;+------+--------+------+--------+--------+------------+-----------+| id | name | eid | ename | gender | birth_date | education |+------+--------+------+--------+--------+------------+-----------+| 6 | 产品部 | 26 | 翟红 | 女 | 1975-05-08 | 硕士 || 6 | 产品部 | 36 | 路宁 | 男 | 1981-12-14 | 本科 || 6 | 产品部 | 43 | 古娟 | 女 | 1973-01-29 | 本科 |...| 2 | 人事处 | 227 | 明洪 | 男 | 1977-07-26 | 本科 || 7 | 公关部 | NULL | NULL | NULL | NULL | NULL || 3 | 售后部 | NULL | NULL | NULL | NULL | NULL || 4 | 营销部 | 3 | 申丽华 | 女 | 1978-04-22 | 本科 |...| 5 | 财务室 | 233 | 洪志明 | 男 | 1991-07-12 | 本科 || NULL | NULL | 113 | 顾桂花 | 女 | 1981-12-23 | 硕士 || NULL | NULL | 191 | 张丽 | 女 | 1981-12-10 | 硕士 |+------+--------+------+--------+--------+------------+-----------+235 rows in set (0.001 sec)
(6)列出部门和员工,包括无员工的部门和无部门的员工,结果按部门编号和员工编号进行升序排序
部门信息包括:id, name
员工信息包括:id, name, gender, birth_date, education
a)连接查询的确定
需要所有部门和所有员工的对应记录,因此应当采用全连接(实现:对员工表和部门表分别偏向一次进行外连接,将结果联合起来)。
b)查询条件
无。
c)其它需求
结果集按部门编号(departmemts.id)和员工编号(employees.id)进行升序排序。
如果需要对全连接的结果进行过滤、排序、限定记录数等,需要采取以下形式:
SELECT 列名列表FROM (全连接查询) 结果集别名[WHERE ...][ORDER BY ...][LIMIT ...]
以下查询将全连接的结果集按部门编号(departmemts.id)和员工编号(employees.id)进行排序:
SELECT * FROM (SELECT `d`.`id`,`d`.`name`, `e`.`id` AS `eid`, `e`.`name` AS `ename`, `e`.`gender`, `e`.`birth_date`, `e`.`education`FROM `departments` `d` LEFT OUTER JOIN `employees` `e`ON `d`.`id`=`e`.`department_id`UNIONSELECT `d`.`id`,`d`.`name`, `e`.`id` AS `eid`, `e`.`name` AS `ename`, `e`.`gender`, `e`.`birth_date`, `e`.`education`FROM `departments` `d` RIGHT OUTER JOIN `employees` `e`ON `d`.`id`=`e`.`department_id`) `a`ORDER BY `id`,`eid`;+------+--------+------+--------+--------+------------+-----------+| id | name | eid | ename | gender | birth_date | education |+------+--------+------+--------+--------+------------+-----------+| NULL | NULL | 113 | 顾桂花 | 女 | 1981-12-23 | 硕士 || NULL | NULL | 191 | 张丽 | 女 | 1981-12-10 | 硕士 || 1 | 设计部 | 1 | 萧正诚 | 男 | 1990-03-07 | 本科 || 1 | 设计部 | 6 | 陆桂香 | 女 | 1988-02-14 | 本科 || 1 | 设计部 | 11 | 刘丹丹 | 女 | 1977-04-04 | 本科 |...| 2 | 人事处 | 227 | 明洪 | 男 | 1977-07-26 | 本科 || 3 | 售后部 | NULL | NULL | NULL | NULL | NULL || 4 | 营销部 | 3 | 申丽华 | 女 | 1978-04-22 | 本科 || 4 | 营销部 | 5 | 房捷 | 男 | 1979-05-10 | 博士 |...| 6 | 产品部 | 213 | 匡智敏 | 男 | 1974-09-03 | 硕士 || 6 | 产品部 | 224 | 金爱华 | 女 | 1976-08-07 | 本科 || 6 | 产品部 | 225 | 武松 | 男 | 1984-02-29 | 硕士 || 7 | 公关部 | NULL | NULL | NULL | NULL | NULL |+------+--------+------+--------+--------+------------+-----------+235 rows in set (0.002 sec)
(7)列出某个部门的全部员工
a)连接查询的确定
列出某个部门的全体员工,即列出员工与某部门的交集部分,需要两表的内部连接查询。
b)查询条件
部门名称=某名称
c)其它需求
无。
-- 以下查询部门为“营销部”的所有员工SELECT `d`.`name` AS `department`, `e`.`id`,`e`.`name`,`e`.`gender`,`e`.`birth_date`,`e`.`education`FROM `departments` `d` INNER JOIN `employees` `e`ON `d`.`id`=`e`.`department_id`WHERE `d`.`name`="营销部";+------------+------+--------+--------+------------+-----------+| department | id | name | gender | birth_date | education |+------------+------+--------+--------+------------+-----------+| 营销部 | 3 | 申丽华 | 女 | 1978-04-22 | 本科 || 营销部 | 5 | 房捷 | 男 | 1979-05-10 | 博士 || 营销部 | 7 | 韦翔 | 男 | 1982-11-08 | 本科 || 营销部 | 8 | 台欢 | 女 | 1975-09-16 | 本科 || 营销部 | 9 | 敖洪 | 男 | 1972-04-15 | 本科 |...| 营销部 | 228 | 窦伦 | 男 | 1975-06-07 | 硕士 || 营销部 | 229 | 赖桂花 | 女 | 1985-03-22 | 本科 || 营销部 | 230 | 植淑珍 | 女 | 1983-07-22 | 本科 || 营销部 | 231 | 常雪 | 女 | 1991-05-31 | 本科 || 营销部 | 232 | 苏兰英 | 女 | 1982-08-20 | 本科 |+------------+------+--------+--------+------------+-----------+133 rows in set (0.000 sec)-- 以下查询部门为“公关部”的所有员工SELECT `d`.`name` AS `department`, `e`.`id`,`e`.`name`,`e`.`gender`,`e`.`birth_date`,`e`.`education`FROM `departments` `d` INNER JOIN `employees` `e`ON `d`.`id`=`e`.`department_id`WHERE `d`.`name`="公关部";Empty set (0.000 sec) -- 空集合(所有员工与此部门无交集)
3、统计和计算举例
(1)统计各部门的员工数、最高月薪、最低月薪、平均月薪
a)连接查询在确定
因为需要知道部门名称和员工的相关统计信息,需要两表连接查询。又因为统计针对各部门,所有部门应当都被考虑,因此采用偏向部门表的外部连接查询。
b)查询条件
无。
c)其它需求
按部门分组统计(按部门表的编号分组而不是按员工表的部门编号分组 -- 为什么?)。
SELECT `d`.`name` AS `department`, COUNT(`e`.`id`) AS `emp_count`, MAX(`e`.`salary`) AS `max_salary`, MIN(`e`.`salary`) AS `min_salary`,ROUND(AVG(`e`.`salary`),2) AS `avg_salary`FROM `departments` `d` LEFT OUTER JOIN `employees` `e`ON `d`.`id`=`e`.`department_id`GROUP BY `d`.`id` -- 不要用: `e`.`department_id`;+------------+-----------+------------+------------+------------+| department | emp_count | max_salary | min_salary | avg_salary |+------------+-----------+------------+------------+------------+| 设计部 | 24 | 11270.00 | 2633.00 | 7170.17 || 人事处 | 22 | 11813.00 | 2752.00 | 7474.77 || 售后部 | 0 | NULL | NULL | NULL || 营销部 | 133 | 11995.00 | 2580.00 | 7308.23 || 财务室 | 22 | 11950.00 | 3159.00 | 6914.09 || 产品部 | 30 | 11370.00 | 2509.00 | 6624.73 || 公关部 | 0 | NULL | NULL | NULL |+------------+-----------+------------+------------+------------+7 rows in set (0.003 sec)
(2)统计人数在30人及以上的各部门的员工数、最高月薪、最低月薪、平均月薪
a)连接查询在确定
因为需要知道部门名称和员工的相关统计信息,需要两表连接查询。在此可以考虑所有部门并采用偏向部门表的外部连接查询,也可采用内部连接(具有员工的部门一定在两表记录的交集之内)。
b)查询条件
员工人数在30人及以上(统计信息限定,用 HAVING 子句)。
c)其它需求
按部门分组统计(按部门表的编号分组而不是按员工表的部门编号分组 -- 为什么?)。
SELECT `d`.`name` AS `department`, COUNT(`e`.`id`) AS `emp_count`, MAX(`e`.`salary`) AS `max_salary`, MIN(`e`.`salary`) AS `min_salary`,ROUND(AVG(`e`.`salary`),2) AS `avg_salary`FROM `departments` `d` INNER JOIN `employees` `e` -- 或者:LEFT OUTER JOINON `d`.`id`=`e`.`department_id`GROUP BY `d`.`id`HAVING `emp_count`>=30;
第十五讲 案例二:部门-员工信息查询与维护
(五)部门员工关联表的信息维护
在员工表的详细定义中,可看到以下语句:
CONSTRAINT `employees_ibfk_1` FOREIGN KEY (`department_id`) REFERENCES `departments` (`id`) ON DELETE SET NULL ON UPDATE CASCADE
其中的:
- ON DELETE SET NUL 指当被参照的部门被删除时,原来参照此部门的员工的外键
department_id自动设置为 null(SET NULL)。 - ON UPDATE CASCADE 指当被参照的部门的主键发生变化时,员工表中原来参照此部门的记录的外键全部做级联(CASCADE)更新,即自动跟随变化。
以下的记录维护,可能需要考虑到两表的这种关系。
1、新增记录
(1)新增部门
新增被其它表参照的表(主表)的记录,对其它表不会产生影响。
INSERT INTO `departments`(id,name,location,telephone,email)VALUES(NULL, '产品检验处','1519','0809-29871082','prodcheck@starcomp.com');Query OK, 1 row affected (0.004 sec)SELECT * FROM `departments`;+----+------------+----------+---------------+------------------------+| id | name | location | telephone | email |+----+------------+----------+---------------+------------------------+| 1 | 设计部 | 1505 | 0809-29871099 | design@starcomp.com || 2 | 人事处 | 1507 | 0809-29871091 | hsdept@starcomp.com || 3 | 售后部 | 1511 | 0809-29871088 | service@starcomp.com || 4 | 营销部 | 1510 | 0809-29871092 | sell@starcomp.com || 5 | 财务室 | 1515 | 0809-29871095 | finance@starcomp.com || 6 | 产品部 | 1506 | 0809-29871097 | product@starcomp.com || 7 | 公关部 | 1508 | 0809-29871098 | pubrela@starcomp.com || 8 | 产品检验处 | 1519 | 0809-29871082 | prodcheck@starcomp.com |+----+------------+----------+---------------+------------------------+8 rows in set (0.000 sec)
(2)新增员工
新增参照其它表的表的记录,如果外键可以为NULL,可以直接忽略。忽略后新增记录并未和主表中的记录产生关联。
INSERT INTO `employees`(id,name,gender,birth_date,education,employed_date,salary)VALUES(NULL,'江伟','男','1989-08-20','本科','2020-10-10',5600.00);Query OK, 1 row affected (0.001 sec)SELECT * FROM `employees` WHERE `name`='江伟';+-----+------+--------+------------+-----------+---------------+---------+---------------+| id | name | gender | birth_date | education | employed_date | salary | department_id |+-----+------+--------+------------+-----------+---------------+---------+---------------+| 129 | 江伟 | 男 | 1978-02-18 | 本科 | 2016-10-30 | 5685.00 | 4 || 234 | 江伟 | 男 | 1989-08-20 | 本科 | 2020-10-10 | 5600.00 | NULL |+-----+------+--------+------------+-----------+---------------+---------+---------------+2 rows in set (0.004 sec)
(3)新增员工到指定部门
新增参照其它表的表的记录,对外键赋值(必须是被参照表中已经有的主键值),即建立了记录之间的关联。
INSERT INTO `employees`(id,name,gender,birth_date,education,employed_date,salary,department_id)VALUES(NULL,'王维','男','1987-11-21','本科','2020-10-10',5600.00,(select id from departments where name='产品检验处'));Query OK, 1 row affected (0.001 sec)-- 证实已经添加成功SELECT * FROM `employees` WHERE `department_id`=(SELECT `id` FROM `departments` WHERE `name`='产品检验处');+-----+------+--------+------------+-----------+---------------+---------+---------------+| id | name | gender | birth_date | education | employed_date | salary | department_id |+-----+------+--------+------------+-----------+---------------+---------+---------------+| 235 | 王维 | 男 | 1987-11-21 | 本科 | 2020-10-10 | 5600.00 | 8 |+-----+------+--------+------------+-----------+---------------+---------+---------------+1 row in set (0.002 sec)
2、修改记录
(1)修改部门编号
被参照表(主表)的主键改变,会有以下影响:
- 如果外键定义的 ON UPDATE 为 RESTRICT 或 NO ACTION,则修改编号的行为会失败;
- 如果外键定义的 ON UPDATE 为 CASCADE,则参照表(子表)的相应外键也会随之改变。
UPDATE `departments` SET `id`=100 WHERE `name`='产品检验处';Query OK, 1 row affected (0.001 sec)Rows matched: 1 Changed: 1 Warnings: 0
查看员工“王维”的部门编号是否改变。
SELECT * FROM `employees` WHERE name='王维';MariaDB [direct_db2]> SELECT * FROM `employees` WHERE name='王维';+-----+------+--------+------------+-----------+---------------+---------+---------------+| id | name | gender | birth_date | education | employed_date | salary | department_id |+-----+------+--------+------------+-----------+---------------+---------+---------------+| 235 | 王维 | 男 | 1987-11-21 | 本科 | 2020-10-10 | 5600.00 | 100 |+-----+------+--------+------------+-----------+---------------+---------+---------------+1 row in set (0.000 sec)
(2)将员工重新安排到其它部门
SELECT * FROM `employees` WHERE `name`='江伟';+-----+------+--------+------------+-----------+---------------+---------+---------------+| id | name | gender | birth_date | education | employed_date | salary | department_id |+-----+------+--------+------------+-----------+---------------+---------+---------------+| 129 | 江伟 | 男 | 1978-02-18 | 本科 | 2016-10-30 | 5685.00 | 4 || 234 | 江伟 | 男 | 1989-08-20 | 本科 | 2020-10-10 | 5600.00 | NULL |+-----+------+--------+------------+-----------+---------------+---------+---------------+2 rows in set (0.000 sec)-- 如果有多名同名员工,确定是哪一位。在此确定是第234号。UPDATE `employees` SET `department_id`=(SELECT id FROM `departments` WHERE `name`='产品检验处') WHERE id=234;Query OK, 1 row affected (0.001 sec)Rows matched: 1 Changed: 1 Warnings: 0-- 证实修改成功SELECT * FROM `employees` WHERE `name`='江伟';+-----+------+--------+------------+-----------+---------------+---------+---------------+| id | name | gender | birth_date | education | employed_date | salary | department_id |+-----+------+--------+------------+-----------+---------------+---------+---------------+| 129 | 江伟 | 男 | 1978-02-18 | 本科 | 2016-10-30 | 5685.00 | 4 || 234 | 江伟 | 男 | 1989-08-20 | 本科 | 2020-10-10 | 5600.00 | 100 |+-----+------+--------+------------+-----------+---------------+---------+---------------+2 rows in set (0.000 sec)
3、删除记录
(1)删除部门
当被参照表(主表)的记录被删除时,会有以下影响:
- 如果外键定义的 ON DELETE 为 RESTRICT 或 NO ACTION,则删除记录的行为会失败;
- 如果外键定义的 ON DELETE 为 SET NULL时,则参照表(子表)的相应外键会被自动设置成 NULL。
部门表属于以上第二种情况。
SELECT * FROM `employees` WHERE `department_id`=(SELECT `id` FROM `departments` WHERE `name`='产品检验处');+-----+------+--------+------------+-----------+---------------+---------+---------------+| id | name | gender | birth_date | education | employed_date | salary | department_id |+-----+------+--------+------------+-----------+---------------+---------+---------------+| 234 | 江伟 | 男 | 1989-08-20 | 本科 | 2020-10-10 | 5600.00 | 100 || 235 | 王维 | 男 | 1987-11-21 | 本科 | 2020-10-10 | 5600.00 | 100 |+-----+------+--------+------------+-----------+---------------+---------+---------------+2 rows in set (0.001 sec)DELETE FROM `departments` WHERE `name`='产品检验处';Query OK, 1 row affected (0.001 sec)SELECT * FROM `employees` WHERE `id` IN (234,235);+-----+------+--------+------------+-----------+---------------+---------+---------------+| id | name | gender | birth_date | education | employed_date | salary | department_id |+-----+------+--------+------------+-----------+---------------+---------+---------------+| 234 | 江伟 | 男 | 1989-08-20 | 本科 | 2020-10-10 | 5600.00 | NULL || 235 | 王维 | 男 | 1987-11-21 | 本科 | 2020-10-10 | 5600.00 | NULL |+-----+------+--------+------------+-----------+---------------+---------+---------------+2 rows in set (0.000 sec)
(2)删除员工
删除没有被其它表参照的表的记录,不会影响其它表。
DELETE FROM `employees` WHERE `id`=235;Query OK, 1 row affected (0.001 sec)
总结:
对一对多关联表的数据维护要注意的问题:
- 外键定义中的 ON UPDATE 的以下取值对操作带来的影响
- NO ACTION / RESTRICT : 如果主表记录有子表记录所参照,对主表记录的主键的更新会失败
- CASCADE : 如果主表记录有子表记录所参照,对主表记录的主键的更新会引起子表中参照其的记录的外键值的更新。
- 外键定义中的 ON DELETE 的以下取值对操作带来的影响
- NO ACTION / RESTRICT : 如果主表记录有子表记录所参照,对主表记录的删除会失败
- CASCADE : 如果主表记录有子表记录所参照,对主表记录的删除会引起子表中参照其的记录的被删除。
- SET NULL : 如果主表记录有子表记录所参照,对主表记录的删除会引起子表中参照其的记录的外键值被设置成 NULL。
- 为子表增加记录时,外键的取值必须是主表中已经存在的主键值(或者 NULL,如果外键允许 NULL 值的话)。
第十六讲 案例三 复杂关系数据表的查询与维护
本案例综合了前面单表(独立表)、一对多关系表的数据查询与维护技能,尝试对具有复杂关系的多表的数据进行查询与维护。同时,我们要学习如何解读 SQL 程序脚本。
(一)准备工作
1、导入数据
mysql -uroot -p --default-character-set=utf8 < d:\sql\direct_db3.sql
2、登录到数据库服务器
C:\Users\Administrator> mysql -uroot -p direct_db3MariaDB [direct_db3]>
(二)了解数据库
1、查看表
MariaDB [direct_db3]> show full tables;+----------------------+------------+| Tables_in_direct_db3 | Table_type |+----------------------+------------+| config | BASE TABLE || departments | BASE TABLE || employees | BASE TABLE || project_employee | BASE TABLE || projects | BASE TABLE || working_hours | VIEW |+----------------------+------------+6 rows in set (0.000 sec)
数据库中有五张基本表和一张视图(VIEW)。视图是通过 SELECT 语句从一到多张表筛选出来的数据的结果集,它类似一张表,但并不是真正的表,不能存储数据。因此,视图是只读的。
2、表结构
MariaDB [direct_db3]> desc config;+-------+---------------------+------+-----+---------+----------------+| Field | Type | Null | Key | Default | Extra |+-------+---------------------+------+-----+---------+----------------+| id | bigint(20) unsigned | NO | PRI | NULL | auto_increment || key | varchar(255) | NO | UNI | NULL | || value | varchar(255) | NO | | | |+-------+---------------------+------+-----+---------+----------------+3 rows in set (0.002 sec)MariaDB [direct_db3]> desc departments;+-----------+---------------------+------+-----+---------+----------------+| Field | Type | Null | Key | Default | Extra |+-----------+---------------------+------+-----+---------+----------------+| id | bigint(20) unsigned | NO | PRI | NULL | auto_increment || name | varchar(100) | NO | UNI | NULL | || location | varchar(100) | NO | | NULL | || telephone | varchar(50) | NO | | | || email | varchar(100) | NO | | | |+-----------+---------------------+------+-----+---------+----------------+5 rows in set (0.011 sec)MariaDB [direct_db3]> desc employees;+---------------+---------------------+------+-----+---------+----------------+| Field | Type | Null | Key | Default | Extra |+---------------+---------------------+------+-----+---------+----------------+| id | bigint(20) unsigned | NO | PRI | NULL | auto_increment || name | varchar(100) | NO | | NULL | || gender | char(1) | NO | | NULL | || birth_date | date | NO | | NULL | || education | varchar(50) | NO | | NULL | || employed_date | date | NO | | NULL | || salary | decimal(10,2) | NO | | NULL | || department_id | bigint(20) unsigned | YES | MUL | NULL | |+---------------+---------------------+------+-----+---------+----------------+8 rows in set (0.001 sec)MariaDB [direct_db3]> desc projects;+-------------+---------------------+------+-----+---------+----------------+| Field | Type | Null | Key | Default | Extra |+-------------+---------------------+------+-----+---------+----------------+| id | bigint(20) unsigned | NO | PRI | NULL | auto_increment || name | varchar(100) | NO | | NULL | || start_date | date | NO | | NULL | || end_date | date | YES | | NULL | || description | varchar(255) | NO | | | |+-------------+---------------------+------+-----+---------+----------------+5 rows in set (0.002 sec)MariaDB [direct_db3]> desc project_employee;+--------------+---------------------+------+-----+---------+----------------+| Field | Type | Null | Key | Default | Extra |+--------------+---------------------+------+-----+---------+----------------+| id | bigint(20) unsigned | NO | PRI | NULL | auto_increment || project_id | bigint(20) unsigned | NO | MUL | NULL | || employee_id | bigint(20) unsigned | NO | MUL | NULL | || working_hour | int(10) unsigned | NO | | NULL | |+--------------+---------------------+------+-----+---------+----------------+4 rows in set (0.011 sec)ariaDB [direct_db3]> desc working_hours;+-------------------+---------------------+------+-----+---------+-------+| Field | Type | Null | Key | Default | Extra |+-------------------+---------------------+------+-----+---------+-------+| emp_id | bigint(20) unsigned | NO | | 0 | || emp_name | varchar(100) | NO | | NULL | || emp_gender | char(1) | NO | | NULL | || emp_birth_date | date | NO | | NULL | || emp_age | int(11) | YES | | NULL | || emp_employed_date | date | NO | | NULL | || dept_name | varchar(100) | YES | | NULL | || project_id | bigint(20) unsigned | NO | | 0 | || project_name | varchar(100) | NO | | NULL | || working_hours | int(10) unsigned | NO | | NULL | |+-------------------+---------------------+------+-----+---------+-------+10 rows in set (0.002 sec)
3、表间关系
寻找表的详细定义中的外键定义,以确定主表和子表。
MariaDB [direct_db3]> show create table employees\G*************************** 1. row ***************************Table: employeesCreate Table: CREATE TABLE `employees` (`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,`name` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL,`gender` char(1) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL,`birth_date` date NOT NULL,`education` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL,`employed_date` date NOT NULL,`salary` decimal(10,2) NOT NULL CHECK (`salary` >= 0),`department_id` bigint(20) unsigned DEFAULT NULL,PRIMARY KEY (`id`),KEY `employees_ibfk_1` (`department_id`),CONSTRAINT `employees_ibfk_1` FOREIGN KEY (`department_id`) REFERENCES `departments` (`id`) ON DELETE SET NULL ON UPDATE CASCADE) ENGINE=InnoDB AUTO_INCREMENT=234 DEFAULT CHARSET=utf8mb41 row in set (0.000 sec)
第15行说明 employees 表的外键 department_id 参照了 departments 表的主键 id。
主表:departments(部门)
子表:employees(员工)
MariaDB [direct_db3]> show create table project_employee\G*************************** 1. row ***************************Table: project_employeeCreate Table: CREATE TABLE `project_employee` (`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,`project_id` bigint(20) unsigned NOT NULL,`employee_id` bigint(20) unsigned NOT NULL,`working_hour` int(10) unsigned NOT NULL,PRIMARY KEY (`id`),UNIQUE KEY `UNI_PROJECT_EMPLOYEE` (`project_id`,`employee_id`),KEY `project_employee_ibfk_2` (`employee_id`),CONSTRAINT `project_employee_ibfk_1` FOREIGN KEY (`project_id`) REFERENCES `projects` (`id`) ON UPDATE CASCADE,CONSTRAINT `project_employee_ibfk_2` FOREIGN KEY (`employee_id`) REFERENCES `employees` (`id`) ON UPDATE CASCADE) ENGINE=InnoDB AUTO_INCREMENT=419 DEFAULT CHARSET=utf8mb31 row in set (0.000 sec)
第12行说明 project_employee 表的外键 project_id 参照了 projects 表的主键 id。
主表: projects(项目)
子表: project_employee(项目-员工)
第13行说明 project_employee 表的外键 employee_id 参照了 employees 表的主键 id。
主表: employess(员工)
子表: project_employee(项目-员工)
第10行说明两个外键的组合必须唯一。
基于此三行定义,说明了两个主表(员工:employees 和 项目:projects)是“多对多”的关系,即:
一个项目可由多名员工参与,一名员工可参与多个项目。
也可理解为:在数据库表的定义中,一个“多对多”关系只能分解为两个“一对多”关系来进行表示,并且要将两个外键的组合限制为唯一。具有两个外键的子表就称为中间表。
这些概念可以用下面的例子来理解。下例中,会员与俱乐部是一对多对多的关系。
我们先参照一对多关系来构建二者的关系。
会员基本信息:
| 编号 | 姓名 | 性别 | 出生日期 | 俱乐部编号(外键) |
|---|---|---|---|---|
| 1 | 张玲 | 女 | 1986-12-11 | 1,3 |
| 2 | 李明 | 男 | 1982-05-06 | 1,2,3 |
| 3 | 王建新 | 男 | 1978-03-12 | 3,4 |
俱乐部信息:
| 编号(主键) | 名称 |
|---|---|
| 1 | 篮球 |
| 2 | 羽毛球 |
| 3 | 乒乓球 |
| 4 | 网球 |
但是,在数据库系统中,列的数据不允许多值!我们看到在会员基本信息表中,俱乐部编号(外键)出现了多值,因此,此方案不可行!
因此,只能将多对多关系分解为两对一对多关系,如下:
会员基本信息:
| 编号 | 姓名 | 性别 | 出生日期 |
|---|---|---|---|
| 1 | 张玲 | 女 | 1986-12-11 |
| 2 | 李明 | 男 | 1982-05-06 |
| 3 | 王建新 | 男 | 1978-03-12 |
俱乐部信息:
| 编号(主键) | 名称 |
|---|---|
| 1 | 篮球 |
| 2 | 羽毛球 |
| 3 | 乒乓球 |
| 4 | 网球 |
会员-俱乐部信息(中间表):
| 编号 | 会员编号 | 俱乐部编号 | 加入日期 |
|---|---|---|---|
| 1 | 1 | 1 | 2020-12-20 |
| 2 | 1 | 3 | 2021-03-01 |
| 3 | 2 | 1 | 2020-12-01 |
| 4 | 2 | 2 | 2021-03-02 |
| 5 | 2 | 3 | 2021-03-02 |
| 6 | 3 | 3 | 2022-01-01 |
| 7 | 3 | 4 | 2022-01-01 |
4、E-R图
基于以上对表结构和详细定义的解读,绘制的实体关系图如下。
注意:下图中我们将各张表对应的实体用其表名的名词单数来表示。
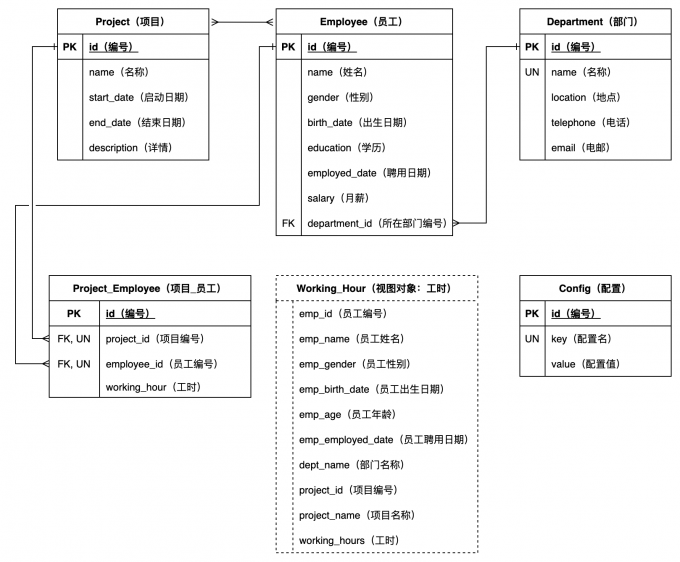
5、视图定义
MariaDB [direct_db3]> show create view working_hours\G*************************** 1. row ***************************View: working_hoursCreate View: CREATE ALGORITHM=UNDEFINED DEFINER=`root`@`localhost` SQL SECURITY DEFINER VIEW `working_hours` AS select `e`.`id` AS `emp_id`,`e`.`name` AS `emp_name`,`e`.`gender` AS `emp_gender`,`e`.`birth_date` AS `emp_birth_date`,`get_age`(`e`.`birth_date`) AS `emp_age`,`e`.`employed_date` AS `emp_employed_date`,`d`.`name` AS `dept_name`,`p`.`id` AS `project_id`,`p`.`name` AS `project_name`,`pe`.`working_hour` AS `working_hours` from (((`employees` `e` left join `departments` `d` on(`d`.`id` = `e`.`department_id`)) join `project_employee` `pe` on(`e`.`id` = `pe`.`employee_id`)) join `projects` `p` on(`p`.`id` = `pe`.`project_id`)) order by `e`.`id`,`p`.`id`character_set_client: utf8mb3collation_connection: utf8mb3_general_ci1 row in set (0.000 sec)
抽取视图定义语句(去除系统默认值):
CREATE VIEW working_hours ASSELECTe.id AS emp_id,e.name AS emp_name,e.gender AS emp_gender,e.birth_date AS emp_birth_date,get_age(e.birth_date) AS emp_age,e.employed_date AS emp_employed_date,d.name AS dept_name,p.id AS project_id,p.name AS project_name,pe.working_hour AS working_hoursFROMemployees e left join departments dON d.id = e.department_idINNER JOIN project_employee peON e.id = pe.employee_idINNER JOIN projects pON p.id = pe.project_idORDER BY e.id, p.id;
视图中用到了一个自定义函数 get_age(第7行)。
第十七讲 案例三 复杂关系数据表的查询与维护(续一)
(三)查询举例
1、查看每一位员工及其参加的每一个项目的信息
因为需要查看来自多表的信息,因此需要多表连接查询。
因为要查看“每一位”员工,确定需要偏向员工一侧的外部连接查询。
员工与项目之间没有主、外键参照关系(无法写 ON 主键=外键 子句),所有不能直接连接查询。
员工与项目是多对多的关系,它们之间有一个中间表 project-employee,与员工表和项目表都有连接。
结论:做两次连接进行查询。
人工查询过程:
- 在员工表查看当前行记录,得到员工编号;
- 在中间表查看那些具有对应员工编号(employee_id)的行,如果有多行,针对这些行:
- 在行上找到对应的项目编号(project_id);
- 在项目表上找对应编号的行,得到项目信息;
- 将员工信息和此行项目信息组合。
- 针对员工表下一行,回到以上第一步。
select id, name, gender from employees;+-----+--------+--------+| id | name | gender |+-----+--------+--------+| 1 | 萧正诚 | 男 || 2 | 邢旭 | 男 || 3 | 申丽华 | 女 |...| 233 | 洪志明 | 男 |+-----+--------+--------+233 rows in set (0.001 sec)select id, name from projects;+----+------------------------------------+| id | name |+----+------------------------------------+| 1 | 产品研发(设计编号:研85-159-553) |...| 3 | 产品研发(设计编号:研85-184-067) |...| 16 | 产品研发(设计编号:研85-733-257) |...| 21 | 产品研发(设计编号:研85-500-988) |...| 42 | 产品研发(设计编号:研85-276-243) |+----+------------------------------------+42 rows in set (0.000 sec)select * from project_employee order by employee_id;+-----+------------+-------------+--------------+| id | project_id | employee_id | working_hour |+-----+------------+-------------+--------------+| 21 | 3 | 1 | 2337 || 195 | 21 | 1 | 4131 || 142 | 16 | 1 | 1718 |...| 282 | 29 | 233 | 5068 |+-----+------------+-------------+--------------+418 rows in set (0.000 sec)
实现以上查询过程的SQL语句:
SELECT e.id, e.name, e.gender, p.id AS project_id, p.name AS project_nameFROM employees e LEFT OUTER JOIN project_employee peON e.id=pe.employee_id -- 员工编号=中间表的员工编号LEFT OUTER JOIN projects pON p.id=pe.project_id -- 中间表的项目编号=项目表的编号;+-----+-----------+--------+------------+------------------------------------------------+| id | name | gender | project_id | project_name |+-----+-----------+--------+------------+------------------------------------------------+| 1 | 萧正诚 | 男 | 3 | 产品研发(设计编号:研85-184-067) || 1 | 萧正诚 | 男 | 7 | 产品研发(设计编号:研85-627-686) || 1 | 萧正诚 | 男 | 15 | 产品研发(设计编号:研85-989-821) || 1 | 萧正诚 | 男 | 16 | 产品研发(设计编号:研85-733-257) |...| 2 | 邢旭 | 男 | 1 | 产品研发(设计编号:研85-159-553) || 2 | 邢旭 | 男 | 21 | 产品研发(设计编号:研85-500-988) ||...| 231 | 常雪 | 女 | NULL | NULL || 232 | 苏兰英 | 女 | 18 | 产品研发(设计编号:研85-113-434) || 233 | 洪志明 | 男 | 29 | 产品研发(设计编号:研85-489-042) |+-----+-----------+--------+------------+------------------------------------------------+509 rows in set (0.002 sec)
2、查看每一位员工及其参加的每一个项目的信息(含工时信息)
查询考虑同上,工时信息在中间表中,因查询涉及中间表,将中间表中需要的列直接列出即可。
SELECT e.id, e.name, e.gender, p.id AS project_id, p.name AS project_name, pe.working_hourFROM employees e LEFT OUTER JOIN project_employee peON e.id=pe.employee_idLEFT OUTER JOIN projects pON p.id=pe.project_id;
3、查看每一个项目及参与其的每一位员工的信息(含员工在此项目上的工时信息)
因为需要查看来自多表的信息,因此需要多表连接查询。
因为要查看“每一个”项目,确定需要偏向项目一侧的外部连接查询。
员工与项目之间没有主、外键参照关系(无法写 ON 主键=外键 子句),所有不能直接连接查询。
员工与项目是多对多的关系,它们之间有一个中间表 project-employee,与员工表和项目表都有连接。
结论:做两次连接进行查询。
SELECT p.id, p.name, e.id AS emp_id, e.name AS emp_name, e.gender, pe.working_hourFROM projects p LEFT OUTER JOIN project_employee peON p.id=pe.project_idLEFT OUTER JOIN employees eON e.id=pe.employee_id;
4、同上一例,但员工信息中需要包含部门名称
考虑同上,但需要将员工表与部门进行偏向员工的外部连接(可能有的员工尚无部门),以获得部门信息。
SELECT p.id, p.name, e.id AS emp_id, e.name AS emp_name, e.gender, d.name AS department_name, pe.working_hourFROM projects p LEFT OUTER JOIN project_employee peON p.id=pe.project_idLEFT OUTER JOIN employees eON e.id=pe.employee_idLEFT OUTER JOIN departments dON e.department_id=d.id;
5、统计参与项目的员工(只需要编号)的所有项目的工时总数
只考虑“参与项目的员工”,不需要考虑所有员工;
参与项目的员工的编号(id)在 project_employee 表中;
工时数也在 project_employee 表中。
结论:针对表中的 employee_id 进行分组统计 working_hour 即可。
SELECT employee_id, sum(working_hour) AS working_hoursFROM project_employeeGROUP BY employee_id;
6、统计参与项目的员工(编号、姓名、性别)的所有项目的工时总数
需要来自两张表(employees, project_employee)的信息,因此需要连接查询;
只考虑“参与项目的员工”,不需要考虑所有员工,因此不需要偏向某张表的外连查询,做内连查询即可;
结论:针对两张表内连进行分组统计 working_hour 即可。
SELECT e.id, e.name, e.gender, sum(working_hour) AS working_hoursFROM employees e INNER JOIN project_employee peON e.id=pe.employee_idGROUP BY pe.employee_id -- 或者:e.id;
7、统计每一位员工(编号、姓名、性别)的所有项目的工时总数
需要来自两张表(employees, project_employee)的信息,因此需要连接查询;
需要考虑“每一位员工”,因此需要偏向员工表的外连查询;
结论:针对两张表进行偏向员工表的外连查询,将结果集进行分组统计 working_hour 即可。
SELECT e.id, e.name, e.gender, sum(working_hour) AS working_hoursFROM employees e LEFT OUTER JOIN project_employee peON e.id=pe.employee_idGROUP BY e.id -- 但不能:pe.employee_id;
8、从视图中获取信息
CREATE VIEW working_hours ASSELECTe.id AS emp_id,e.name AS emp_name,e.gender AS emp_gender,e.birth_date AS emp_birth_date,get_age(e.birth_date) AS emp_age,e.employed_date AS emp_employed_date,d.name AS dept_name,p.id AS project_id,p.name AS project_name,pe.working_hour AS working_hoursFROMemployees e left join departments dON d.id = e.department_idINNER JOIN project_employee peON e.id = pe.employee_idINNER JOIN projects pON p.id = pe.project_idORDER BY e.id, p.id;
现在以视图为数据源,重新实现以上第6个例子。
SELECT emp_id, emp_name, emp_gender, sum(working_hours)FROM working_hoursGROUP BY emp_id;
第十八讲 SQL 编程基础
准备工作:
CREATE DATABASE IF NOT EXISTS test_routines;USE test_routines;
用 SQL 的流程控制语句,可将 SQL 语句组织起来完成特定的工作。这样的代码就叫 SQL 程序(或例程, routine)。
(一)MariaDB 例程(Routines)
MariaDB 有两种例程。
1、存储过程
存储过程,是指被存储起来的程序过程(Stored Procedure)。它是通过 CALL 语句调用的过程。
(1)存储过程的定义
CREATE PROCEDURE 过程名([[IN|OUT|INOUT]参数1 参数类型1,...])BEGIN...END
- 在参数前面加上:
- IN
- 说明是接受输入的参数
- OUT
- 用于装载输出的参数
- INOUT
- 以上二者的综合
(2)存储过程的调用
用 CALL 调用存储过程。
call 存储过程名(...);
2、函数
和存储过程不同的是,函数需要返回一个值。
(1)函数的定义
CREATE FUNCTION 函数名([参数1 参数类型1,...]) RETURNS 返回值类型BEGIN...END
(2)函数的调用
函数直接调用。
SELECT 函数名(...);
(二)编写例程需要考虑的问题
例程的定义是通过一条语句来完成的:
CREATE 例程类型 例程名 例程内容 结束符
由于例程中包含了 SQL 语句,这些语句的结束符为系统默认的结束符(逗号 ;),因此,在定义全程前,需要临时将 SQL 语句的结束符改成其它符号,以避免客户端在碰到例程中的语句结束符时,就将语句送往服务器(因为此时定义例程的语句还没有结束,送住服务器必然造成语句错误)。
因此,在编写例程之前,需要先:
DELIMITER 系统默认结束符之外的其它符号 -- 临时更改结束符
例程完成后,需要:
DELIMITER 系统默认结束符 -- 恢复系统默认结束符,通常为 ;
(三)SQL 的变量
变量用于装载数据。变量的名称不区分大小写,这意味着 name、Name、NAME 等都是同一个变量。
查看一个变量用以下语句:
SELECT 变量名;
在 MariaDB 中, 有三种不同用途的变量。
- 用户自定义变量
- 局部变量
- 系统变量
1、用户自定义变量
用户自定义变量只在定义它们的整个连接期间有效,断开后(即使重新连接也)失效。
这种变量的名称前面有一个"@" 符号。它们的声明和初始化非常直接:
SET @country = "China"; -- 或者 SELECT "China" INTO @country;SELECT @country;+----------+| @country |+----------+| China |+----------+1 row in set (0.000 sec)
以下语句将 1 号员工的 id, name, gender 分别保存在 @id, @name, @gender 变量中:
SELECT id, name, gender INTO @id, @name, @genderFROM employeesWHERE id=1;Query OK, 1 row affected (0.000 sec)SELECT @id, @name, @gender;+------+-----------+---------+| @id | @name | @gender |+------+-----------+---------+| 1 | 萧正诚 | 男 |+------+-----------+---------+1 row in set (0.000 sec)
由于自定义变量无法声明其类型,其类型由装载的数据决定。如果需要将其装载的数据转换成其它类型,需要使用 CONVERT() 或 CAST() 函数。
2、局部变量
局部变量在声明它们的程序块范围内(BEGIN ... END 之间)有效(在其下层程序块中也有效)。
局部变量需要如此声明和赋值:
-- 声明DECLARE 变量名1 [ , 变量名2] 类型 [DEFAULT 默认值];-- 赋值SET 变量名=值;-- 如:DECLARE name VARCHAR(50);SET name="Bill";DECLARE width, height, length INT DEFAULT 0;
3、系统变量
系统变量用于存储系统配置,定制系统行为,以适合用户的需要。
用以下命令查看系统变量:
-- 语法show variables [like 值];-- 如show variables; -- 查看所有变量show variables like '%char%';
用以下变量设定系统变量的值(只有那些在运行时能够动态设置的变量才有效,并且只在当前连接有效):
set 变量名=变量值;
(四)SQL 流程控制语句
1、返回值
RETURN 值; -- 结束例程,将值返回。
用于结束例程,把值返回(用于函数)。
下面这个例子虽然没有什么实质性的作用,它只是将传入的参数翻倍后返回,但能够演示 RETURN 语句的使用。
文件位置:d:\sql\ex1.sql
文件内容:
DROP FUNCTION IF EXISTS double_it; -- 如果函数 doublie_it 存在先删除DELIMITER // -- 将 SQL 结束符改成 //CREATE FUNCTION double_it(value BIGINT) RETURNS BIGINT -- 创建函数 doublie_itBEGINRETURN value*2; -- 不会被提交服务器,因为语句结束符不再是 ;END // -- 函数定义完成,语句结束,被提交服务器执行DELIMITER ; -- 将 SQL 结束符改回 ;
然后:
MariaDB [test_routines]> \. d:\sql\ex1.sqlMariaDB [test_routines]> select double_it(100);+----------------+| double_it(100) |+----------------+| 200 |+----------------+1 row in set (0.000 sec)
2、开始下一轮循环
ITERATE 标签; -- 从此回到标签表示的循环开头处开始下一轮循环
3、结束循环
LEAVE 标签; -- 从此跳出标签表示的循环从而结束循环。
4、条件
IF 条件1 THEN{...条件1满足时执行的一到多条语句...}[ ELSEIF 条件2 THEN{...条件2 满足时执行的一到多条语句...}...][ ELSE{...所有条件都不满足时执行的一到多条语句...} ]END IF;
以下例子演示条件语句的用法。
函数功能:根据输入的性别和生日信息判断是否达到法定退休年龄(男:60,女:55)。
文件位置:d:\sql\ex2.sql
文件内容:
DROP FUNCTION IF EXISTS can_retire;DELIMITER //CREATE FUNCTION can_retire(gender CHAR(1), dob Date) RETURNS BOOLEANBEGINIF gender='男' THENIF TIMESTAMPDIFF(YEAR, dob, CURDATE())>=60 THENRETURN TRUE;ELSERETURN FALSE;END IF;ELSEIF gender='女' THENIF TIMESTAMPDIFF(YEAR, dob, CURDATE())>=55 THENRETURN TRUE;ELSERETURN FALSE;END IF;ELSESIGNAL SQLSTATE '45000' SET MESSAGE_TEXT = '性别值非法!';END IF;END //DELIMITER ;
然后:
MariaDB [test_routines]> \. d:\sql\ex2.sqlMariaDB [test_routines]> select can_retire('男','1960-10-10');+--------------------------------+| can_retire('男','1960-10-10') |+--------------------------------+| 1 |+--------------------------------+1 row in set (0.000 sec)
5、循环
(1)LOOP

[ 标签: ] LOOP -- 循环{...循环体:一到多条语句...}END LOOP [ 标签 ]; -- 循环语句结束
如果循环体中碰到:
- ITERATE 标签: 终止本次循环,从循环体第一句开始下一轮循环;
- LEAVE 标签:终止本次循环,并跳出循环体,执行 END LOOP 后面的语句。
- 如果没有碰到以上两条语句,到循环体最后一句就结束循环。
以下例子演示了 LOOP 循环。
存储过程功能:给予一个初始值,计算这个值需要累加多少次才能达到10000。
文件位置:d:\sql\ex3.sql
文件内容:
DROP PROCEDURE IF EXISTS get_count_loop;DELIMITER //CREATE PROCEDURE get_count_loop(IN start_value INT, OUT count INT)BEGINDECLARE total INT DEFAULT 0;SET count=0;loop_1: LOOPSET count = count + 1;SET total = total + start_value;IF total>=10000 THENLEAVE loop_1;END IF;END LOOP loop_1;END //DELIMITER ;
然后:
MariaDB [test_routines]> \. d:\sql\ex3.sqlMariaDB [test_routines]> call get_count_loop(200,@c);Query OK, 0 rows affected (0.000 sec)MariaDB [test_routines]> select @c;+------+| @c |+------+| 50 |+------+1 row in set (0.000 sec)
(2)WHILE
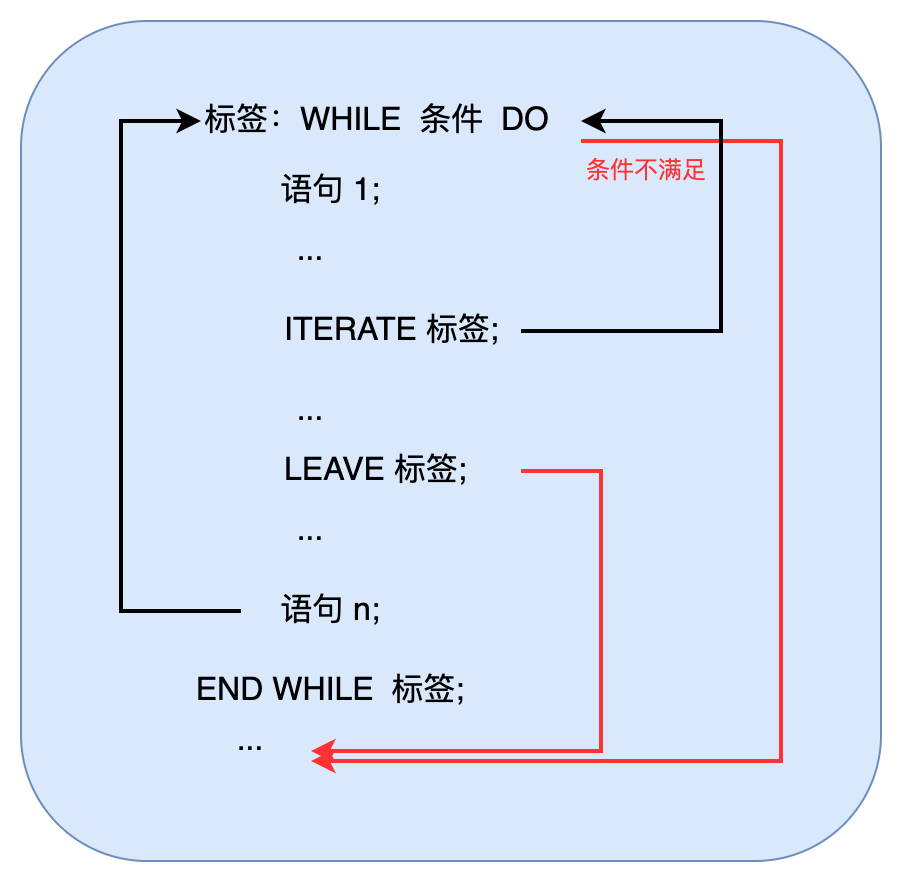
[ 标签: ] WHILE 条件 DO{...循环体:一到多条语句...}END WHILE [ 标签 ];
如果 WHILE 后面的条件不满足,循环终止,执行 END WHILE 后面的语句。
条件满足,进入循环体。
如果循环体中碰到:
- ITERATE 标签: 终止本次循环,如果条件仍然满足,从循环体第一句开始下一轮循环;
- LEAVE 标签:终止本次循环,并跳出循环体,执行 END WHILE 后面的语句。
- 如果没有碰到以上两条语句,到循环体最后一句就回头判断 WHILE 后面的条件是否满足,以决定是否继续循环。
以下例子演示了 WHILE 循环的使用。
存储过程功能:给予一个初始值,计算这个值需要累加多少次才能达到10000。
文件位置:d:\sql\ex4.sql
文件内容:
DROP PROCEDURE IF EXISTS get_count_while;DELIMITER //CREATE PROCEDURE get_count_while(IN start_value INT, OUT count INT)BEGINDECLARE total INT DEFAULT 0;SET count = 0;loop_1: WHILE total<10000 DOSET count = count + 1;SET total = total + start_value;END WHILE loop_1;END //DELIMITER ;
然后:
MariaDB [test_routines]> \. d:\sql\ex4.sqlMariaDB [test_routines]> call get_count_while(200,@c);Query OK, 0 rows affected (0.000 sec)MariaDB [test_routines]> select @c;+------+| @c |+------+| 50 |+------+1 row in set (0.000 sec)
(3)REPEAT

[ 标签: ] REPEAT -- 重复{...循环体:一到多条语句...}UNTIL 条件 -- 直到 条件END REPEAT [ 标签 ]; -- 循环语句结束
如果执行到 UNTIL 语句,且它后面的条件满足,循环终止,执行 END REPEAT 后面的语句。
如果不满足,从头开始下一轮循环。
如果循环体中碰到:
- ITERATE 标签: 终止本次循环,从循环体第一句开始下一轮循环;
- LEAVE 标签:终止本次循环,并跳出循环体,执行 END REPEAT 后面的语句。
以下例子演示了 REPEAT 循环的使用。
存储过程功能:给予一个初始值,计算这个值需要累加多少次才能达到10000。
文件位置:d:\sql\ex5.sql
文件内容:
DROP PROCEDURE IF EXISTS get_count_repeat;DELIMITER //CREATE PROCEDURE get_count_repeat(IN start_value INT, OUT count INT)BEGINDECLARE total INT DEFAULT 0;SET count = 0;loop_1: REPEATSET count = count + 1;SET total = total + start_value;UNTIL total>=10000END REPEAT loop_1;END //DELIMITER ;
然后:
MariaDB [test_routines]> \. d:\sql\ex5.sqlMariaDB [test_routines]> call get_count_repeat(200,@c);Query OK, 0 rows affected (0.000 sec)MariaDB [test_routines]> select @c;+------+| @c |+------+| 50 |+------+1 row in set (0.000 sec)
6、分支
(1)语法1
CASE 表达式WHEN 值_1 THEN{...表达式值为值_1时执行的一到多条语句...}[ WHEN 值_2 THEN{...表达式值为值_2时执行的一到多条语句...} ][ WHEN 值_n THEN result_n{...表达式值为值_n时执行的一到多条语句...} ][ ELSE{...没有值匹配时执行的一到多条语句...} ]END CASE;
以下例子演示了这种语法结构的例子。
函数功能:根据服务名称,返回默认端口号。
文件位置:d:\sql\ex6.sql
文件内容:
DROP FUNCTION IF EXISTS get_default_port;DELIMITER //CREATE FUNCTION get_default_port(protocol VARCHAR(20)) RETURNS VARCHAR(10)BEGINDECLARE port VARCHAR(10);CASE UPPER(TRIM(protocol))WHEN "HTTP" THENSET port = "80";WHEN "SSH" THENSET port = "22";WHEN "HTTPS" THENSET port = "443";WHEN "SMTP" THENSET port = "25";WHEN "FTP" THENSET port = "21";ELSESET port = "UNKOWN";END CASE;RETURN port;END //DELIMITER ;
然后:
MariaDB [test_routines]> \. d:\sql\ex6.sqlMariaDB [test_routines]> select get_default_port("http");+--------------------------+| get_default_port("http") |+--------------------------+| 80 |+--------------------------+1 row in set (0.000 sec)MariaDB [test_routines]> select get_default_port("ftp");+-------------------------+| get_default_port("ftp") |+-------------------------+| 21 |+-------------------------+1 row in set (0.000 sec)MariaDB [test_routines]> select get_default_port("smtp ");+---------------------------+| get_default_port("smtp ") |+---------------------------+| 25 |+---------------------------+1 row in set (0.000 sec)MariaDB [test_routines]> select get_default_port("whatever");+------------------------------+| get_default_port("whatever") |+------------------------------+| UNKOWN |+------------------------------+1 row in set (0.000 sec)MariaDB [test_routines]>
(2)语法2
CASEWHEN 条件_1 THEN{...条件_1满足时执行的一到多条语句...}[ WHEN 条件_2 THEN{...条件_2满足时执行的一到多条语句...} ][ WHEN 条件_n THEN{...条件_n满足时执行的一到多条语句...} ][ ELSE{...无条件满足时执行的一到多条语句...} ]END CASE;
以下例子演示这种语法结构的用法。
函数功能:根据出生日期返回相应年龄段称谓(儿童、少年、青年、中年、老年……)。
文件位置:d:\sql\ex7.sql
文件内容:
DROP FUNCTION IF EXISTS get_age_class;DELIMITER //CREATE FUNCTION get_age_class(dob DATE) RETURNS VARCHAR(10)BEGINDECLARE age INT;DECLARE class_name VARCHAR(10);SET age = TIMESTAMPDIFF(YEAR, dob, CURDATE());CASEWHEN age<7 THENSET class_name = "儿童";WHEN age>=7 AND age<18 THENSET class_name = "少年";WHEN age>=18 AND age<40 THENSET class_name = "青年";WHEN age>=40 AND age<65 THENSET class_name = "中年";WHEN age>=65 THENSET class_name = "老年";END CASE;RETURN class_name;END //DELIMITER ;
然后:
MariaDB [test_routines]> \. d:\sql\ex6.sqlMariaDB [direct_db1]> select get_age_class("1955-10-10");+-----------------------------+| get_age_class("1955-10-10") |+-----------------------------+| 老年 |+-----------------------------+1 row in set (0.000 sec)MariaDB [direct_db1]> select get_age_class("2012-10-10");+-----------------------------+| get_age_class("2012-10-10") |+-----------------------------+| 少年 |+-----------------------------+1 row in set (0.000 sec)
第十九讲 案例三 复杂关系表的查询与维护(续二)
(四)例程解读
information_schema 是 MariaDB/MySQL 系统自带的一个系统数据库,它包含了数据库管理系统中的各种元数据(Metadata,描述数据的数据)。我们可以从中列出各个数据库中定义的例程。
下面列出了当前数据库的所有例程。
其中:
- routine_name
- 例程名称
- routine_type
- 例程类型(可以是:PROCEDURE - 存储过程,FUNCTION - 函数)
- data_type
- 函数的返回值类型
- routine_definition
- 例程定义
- routine_schema
- 拥有例程的数据库
MariaDB [direct_db3]> select routine_name,routine_type, data_type,routine_definition from information_schema.routines where routine_schema='direct_db3'\G*************************** 1. row ***************************routine_name: check_ins_upd_on_employeesroutine_type: PROCEDUREdata_type:routine_definition: BEGINSET @msg = CONCAT("The employee's age (",CAST(TIMESTAMPDIFF(YEAR,bdate,edate) AS CHAR),") is not legal for work!");SELECT CAST(`value` AS INT) INTO @legal_age_for_work FROM `config` WHERE `key`='legal_age_for_work';IF TIMESTAMPDIFF(YEAR,bdate,CURDATE())<@legal_age_for_work OR TIMESTAMPDIFF(YEAR,bdate,edate)<@legal_age_for_work THENSIGNAL SQLSTATE '45000' SET MESSAGE_TEXT = @msg;END IF;IF edate>CURDATE() THENSIGNAL SQLSTATE '45000' SET MESSAGE_TEXT = "The employed date is behind today!";END IF;END*************************** 2. row ***************************routine_name: check_ins_upd_on_project_employeeroutine_type: PROCEDUREdata_type:routine_definition: BEGINDECLARE start_on DATE;SELECT e.employed_date into @employed_date FROM employees e WHERE e.id=eid;SELECT p.start_date,p.end_date INTO @start_date,@end_date FROM projects p WHERE p.id=pid;SET start_on=@start_date;IF @start_date<@employed_date THENSET start_on = @employed_date;END IF;IF @end_date IS NULL THENSET @end_date=CURDATE();END IF;IF @employed_date>@end_date THENSIGNAL SQLSTATE '45000' SET MESSAGE_TEXT = "The project has ended before the employee was employed!";END IF;IF whour>TIMESTAMPDIFF(HOUR,start_on,@end_date) THENSIGNAL SQLSTATE '45000' SET MESSAGE_TEXT = "The working hours is greater than the sum of project's hours!";END IF;END*************************** 3. row ***************************routine_name: get_ageroutine_type: FUNCTIONdata_type: introutine_definition: BEGINRETURN TIMESTAMPDIFF(YEAR,dob,curdate());END3 rows in set (0.013 sec)
1、函数
以上第三行列出了当前数据库中的函数 get_age。我们可以用以下命令查看创建函数的语句:
MariaDB [direct_db3]> show create function get_age\G*************************** 1. row ***************************Function: get_agesql_mode: STRICT_TRANS_TABLES,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTIONCreate Function: CREATE DEFINER=`root`@`localhost` FUNCTION `get_age`(dob DATE) RETURNS int(11)BEGINRETURN TIMESTAMPDIFF(YEAR,dob,curdate());ENDcharacter_set_client: utf8mb3collation_connection: utf8mb3_general_ciDatabase Collation: utf8mb4_general_ci1 row in set (0.000 sec)
将 Create Function列有内容精简后得到:
CREATE FUNCTION `get_age`(dob DATE) RETURNS int(11)BEGINRETURN TIMESTAMPDIFF(YEAR,dob,curdate());END
根据上一讲所讲内容,可将此函数的定义解读如下:
函数
get_age接受一个日期型参数dob, 最终将返回一个整型数。
函数功能:将传入的日期与当前日期做计算,得到当前日期晚于传入日期的年份数,并将此年份数返回。
应用:此函数可应用于从出生日期获取年龄。
2、存储过程
(1)check_ins_upd_on_employees
用以下命令查看此存储过程的定义。
MariaDB [direct_db3]> show create procedure check_ins_upd_on_employees\G*************************** 1. row ***************************Procedure: check_ins_upd_on_employeessql_mode: STRICT_TRANS_TABLES,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTIONCreate Procedure: CREATE DEFINER=`root`@`localhost` PROCEDURE `check_ins_upd_on_employees`(IN bdate DATE, IN edate DATE)BEGINSET @msg = CONCAT("The employee's age (",CAST(TIMESTAMPDIFF(YEAR,bdate,edate) AS CHAR),") is not legal for work!");SELECT CAST(`value` AS INT) INTO @legal_age_for_work FROM `config` WHERE `key`='legal_age_for_work';IF TIMESTAMPDIFF(YEAR,bdate,CURDATE())<@legal_age_for_work OR TIMESTAMPDIFF(YEAR,bdate,edate)<@legal_age_for_work THENSIGNAL SQLSTATE '45000' SET MESSAGE_TEXT = @msg;END IF;IF edate>CURDATE() THENSIGNAL SQLSTATE '45000' SET MESSAGE_TEXT = "The employed date is behind today!";END IF;ENDcharacter_set_client: utf8mb3collation_connection: utf8mb3_general_ciDatabase Collation: utf8mb4_general_ci1 row in set (0.000 sec)
将 Create Procedure 列的内容精简得到:
CREATE PROCEDURE `check_ins_upd_on_employees`(IN bdate DATE, IN edate DATE)BEGINSET @msg = CONCAT("The employee's age (",CAST(TIMESTAMPDIFF(YEAR,bdate,edate) AS CHAR),") is not legal for work!");SELECT CAST(`value` AS INT) INTO @legal_age_for_work FROM `config` WHERE `key`='legal_age_for_work';IF TIMESTAMPDIFF(YEAR,bdate,CURDATE())<@legal_age_for_work OR TIMESTAMPDIFF(YEAR,bdate,edate)<@legal_age_for_work THENSIGNAL SQLSTATE '45000' SET MESSAGE_TEXT = @msg;END IF;IF edate>CURDATE() THENSIGNAL SQLSTATE '45000' SET MESSAGE_TEXT = "The employed date is behind today!";END IF;END
解读--
第1行:创建一个叫做 check_ins_upd_on_employees 的存储过程,它接收两个日期型的参数。
第3行:将变量 @msg 设定为三个字符串的连接,最终成为:“The employee's age 某个数字 is not legal for work!”,即:员工的年龄某个数字对于工作不合法。而某个数字是两个传入的日期参数计算的(edate晚于bdate的年份数)。
第4行:从 config(配置) 表中获取 key(键) 为 legal_age_for_work(合法工作年龄) 的 value(值) 列的值并转换为整型数,并存入 @legal_age_for_work。
第5行:如果当前日期晚于 bdate 的年份数小于 @legal_age_for_work 或者 edate 晚于 bdate 的年份数小于 @legal_age_for_work
第6行:触发自定义错误,将第3行定义的 @msg 作为信息输出。
第8行:如果 edate 晚于当前日期,触发自定义错误,并输出信息:“The employed date is behind today!”(雇用日期晚于今天!)
存储过程功能:用于判断员工的雇用是否合法(年龄必须满足合法工作年龄,雇用日期不得晚于当前日期)。
(2)check_ins_upd_on_project_employee
用以下命令查看具体定义:
MariaDB [direct_db3]> show create procedure check_ins_upd_on_project_employee\G*************************** 1. row ***************************Procedure: check_ins_upd_on_project_employeesql_mode: STRICT_TRANS_TABLES,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTIONCreate Procedure: CREATE DEFINER=`root`@`localhost` PROCEDURE `check_ins_upd_on_project_employee`(IN pid bigint unsigned, IN eid bigint unsigned, IN whour INT)BEGINDECLARE start_on DATE;SELECT e.employed_date into @employed_date FROM employees e WHERE e.id=eid;SELECT p.start_date,p.end_date INTO @start_date,@end_date FROM projects p WHERE p.id=pid;SET start_on=@start_date;IF @start_date<@employed_date THENSET start_on = @employed_date;END IF;IF @end_date IS NULL THENSET @end_date=CURDATE();END IF;IF @employed_date>@end_date THENSIGNAL SQLSTATE '45000' SET MESSAGE_TEXT = "The project has ended before the employee was employed!";END IF;IF whour>TIMESTAMPDIFF(HOUR,start_on,@end_date) THENSIGNAL SQLSTATE '45000' SET MESSAGE_TEXT = "The working hours is greater than the sum of project's hours!";END IF;ENDcharacter_set_client: utf8mb3collation_connection: utf8mb3_general_ciDatabase Collation: utf8mb4_general_ci1 row in set (0.000 sec)
将 Create Procedure 列的内容精简得到:
CREATE PROCEDURE `check_ins_upd_on_project_employee`(IN pid bigint unsigned, IN eid bigint unsigned, IN whour INT)BEGINDECLARE start_on DATE;SELECT e.employed_date into @employed_date FROM employees e WHERE e.id=eid;SELECT p.start_date,p.end_date INTO @start_date,@end_date FROM projects p WHERE p.id=pid;SET start_on=@start_date;IF @start_date<@employed_date THEN -- 如果员工雇用日期晚于项目开始日期SET start_on = @employed_date; -- 设定 start_on 为雇用日期END IF;IF @end_date IS NULL THEN -- 如果项目结束日期为空SET @end_date=CURDATE(); -- 将 @end_date 设定为当前日期END IF;IF @employed_date>@end_date THEN -- 如果员工雇用日期晚于项目终止日期SIGNAL SQLSTATE '45000' SET MESSAGE_TEXT = "The project has ended before the employee was employed!"; -- 引发错误:员工雇用时项目已经结束!END IF;IF whour>TIMESTAMPDIFF(HOUR,start_on,@end_date) THEN -- 如果工时数超过项目小时总数SIGNAL SQLSTATE '45000' SET MESSAGE_TEXT = "The working hours is greater than the sum of project's hours!";END IF;END
功能:将员工加入项目时检查——员工的雇用日期不能晚于该项目的结束日期(或当前日期)
3、触发器
MariaDB [direct_db3]> show create function get_age\G*************************** 1. row ***************************Function: get_agesql_mode: STRICT_TRANS_TABLES,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTIONCreate Function: CREATE DEFINER=`root`@`localhost` FUNCTION `get_age`(dob DATE) RETURNS int(11)BEGINRETURN TIMESTAMPDIFF(YEAR,dob,curdate());ENDcharacter_set_client: utf8mb3collation_connection: utf8mb3_general_ciDatabase Collation: utf8mb4_general_ci1 row in set (0.000 sec)
抽取定义:
CREATE FUNCTION get_age(dob DATE) RETURNS int(11)BEGINRETURN TIMESTAMPDIFF(YEAR,dob,curdate());END
函数定义的语法:
CREATE FUNCTION 函数名(参数1 数据类型, 参数2 数据类型, ...) RETURNS 返回值类型BEGIN -- 函数体开始END -- 函数体结束
因此,上档函数体只有一句:
-- 返回参数中的日期 dob 到当前日期的年数RETURN TIMESTAMPDIFF(YEAR,dob,curdate());
可见,get_age 函数接受一个日期类型的参数 dob,返回 dob 到当前日期的年数。
7、查看触发器
触发器是一段 SQL 程序,它会在某个事件(记录插入、记录更新、记录删除等)的时间点(发生前、发生后)被执行。
触发器的目的是用来响应这些事件,在事件的发生前后做必要的工作,以保证某些规则的实施(如数据完整性、数据合法性等)。
MariaDB [direct_db3]> show triggers\G*************************** 1. row ***************************Trigger: before_insert_on_employees -- 触发器名称Event: INSERT -- 触发事件(插入)Table: employees -- 针对表Statement: BEGIN -- 语句CALL check_ins_upd_on_employees(NEW.birth_date,NEW.employed_date);-- 上一行调用了存储过程 check_ins_upd_on_employeesENDTiming: BEFORE -- 执行时机(之前,即事件之前)Created: 2022-04-21 16:08:37.76sql_mode: STRICT_TRANS_TABLES,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTIONDefiner: root@localhostcharacter_set_client: utf8mb3collation_connection: utf8mb3_general_ciDatabase Collation: utf8mb4_general_ci*************************** 2. row ***************************Trigger: before_update_on_employeesEvent: UPDATETable: employeesStatement: BEGINCALL check_ins_upd_on_employees(NEW.birth_date,NEW.employed_date);ENDTiming: BEFORECreated: 2022-04-21 16:08:37.77sql_mode: STRICT_TRANS_TABLES,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTIONDefiner: root@localhostcharacter_set_client: utf8mb3collation_connection: utf8mb3_general_ciDatabase Collation: utf8mb4_general_ci*************************** 3. row ***************************Trigger: before_insert_on_project_employeeEvent: INSERTTable: project_employeeStatement: BEGINCALL check_ins_upd_on_project_employee(NEW.project_id,NEW.employee_id,NEW.working_hour);ENDTiming: BEFORECreated: 2022-04-21 16:08:37.81sql_mode: STRICT_TRANS_TABLES,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTIONDefiner: root@localhostcharacter_set_client: utf8mb3collation_connection: utf8mb3_general_ciDatabase Collation: utf8mb4_general_ci*************************** 4. row ***************************Trigger: before_update_on_project_employeeEvent: UPDATETable: project_employeeStatement: BEGINCALL check_ins_upd_on_project_employee(NEW.project_id,NEW.employee_id,NEW.working_hour);ENDTiming: BEFORECreated: 2022-04-21 16:08:37.81sql_mode: STRICT_TRANS_TABLES,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTIONDefiner: root@localhostcharacter_set_client: utf8mb3collation_connection: utf8mb3_general_ciDatabase Collation: utf8mb4_general_ci4 rows in set (0.001 sec)
(二)
附录
附录一 MySQL/MariaDB 常用数据类型速查表
(1)数值型
| 类型 | 大小 | 范围(有符号) | 范围(无符号) | 用途 |
|---|---|---|---|---|
| TINYINT (tiny interger) |
1 字节 | (-128,127) | (0,255) | 微整数值 |
| SMALLINT | 2 字节 | (-32 768,32 767) | (0,65 535) | 小整数值 |
| MEDIUMINT | 3 字节 | (-8 388 608,8 388 607) | (0,16 777 215) | 中等整数值 |
| INT或INTEGER | 4 字节 | (-2 147 483 648,2 147 483 647) | (0,4 294 967 295) | 大整数值 |
| BIGINT | 8 字节 | (-9,223,372,036,854,775,808,9 223 372 036 854 775 807) | (0,18 446 744 073 709 551 615) | 极大整数值 |
| FLOAT | 4 字节 | (-3.402 823 466 E+38,-1.175 494 351 E-38),0,(1.175 494 351 E-38,3.402 823 466 351 E+38) | 0,(1.175 494 351 E-38,3.402 823 466 E+38) | 单精度浮点数值 |
| DOUBLE | 8 字节 | (-1.797 693 134 862 315 7 E+308,-2.225 073 858 507 201 4 E-308),0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 双精度浮点数值 |
| DECIMAL | 对DECIMAL(M,D) ,如果M>D,为M+2否则为D+2 | 依赖于M和D的值 | 依赖于M和D的值 | 小数值 |
(2)日期和时间类型
| 类型 | 大小(字节) | 范围 | 格式 | 用途 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | '-838:59:59'/'838:59:59' | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901/2155 | YYYY | 年份值 |
| DATETIME | 8 | 1000-01-01 00:00:00/9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| TIMESTAMP | 4 | 1970-01-01 00:00:00/2038 结束时间是第 2147483647 秒,北京时间 2038-1-19 11:14:07,格林尼治时间 2038年1月19日 凌晨 03:14:07 |
YYYYMMDD HHMMSS | 混合日期和时间值,时间戳 |
(3)字符串类型
| 类型 | 大小 | 用途 |
|---|---|---|
| CHAR | 0-255字节 | 定长字符串 |
| VARCHAR | 0-65535 字节 | 变长字符串 |
| TINYTEXT | 0-255字节 | 短文本字符串 |
| TEXT | 0-65 535字节 | 长文本数据 |
| MEDIUMTEXT | 0-16 777 215字节 | 中等长度文本数据 |
| LONGTEXT | 0-4 294 967 295字节 | 极大文本数据 |
(4)二进制类型(图像、音频、视频、二进制程序代码……)
| 类型 | 大小 | 用途 |
|---|---|---|
| TINYBLOB | 0-255字节 | 不超过 255 个字节的二进制数据 |
| BLOB | 0-65 535字节 | 二进制数据 |
| MEDIUMBLOB | 0-16 777 215字节 | 二进制中等长度数据 |
| LONGBLOB | 0-4 294 967 295字节 | 二进制极大长度数据 |
附录二 MySQL/MariaDB 比较运算与逻辑运算
1、比较运算
| 序号 | 运算符 | 含义 | 举例 |
|---|---|---|---|
| 1 | = | 等于 | name='王晓晓' |
| 2 | != | 不等于 | price!=800 |
| 3 | > | 大于 | count>1500 |
| 4 | >= | 大于或等于 | dateOfBirth>='1990-12-31' |
| 5 | < | 小于 | age<18 |
| 6 | <= | 小于等于 | age<=18 |
| 7 | between x and y | 介于 x 和 y 之间(含 x 和 y) | age between 18 and 60 |
| 8 | in (a,b,...) / not in () | 值等于 a,b,...中的任意一个 | loaction in ('昆明','上海','北京') |
| 9 | like '...' | 像(匹配),% 代表零到任意多个任意字符的组合 | name like '李%' name like '%明' name like '%小%' |
| 10 | is null | 为空值(注意:空值判断不能用 = 运算符!) | department is null |
2、逻辑运算
| 序号 | 运算符 | 含义 | 举例 |
|---|---|---|---|
| 1 | and | 并且 | a>10 and b>30(两条都要满足) |
| 2 | or | 或者 | a>10 or b>30(只要一条满足即可) |
| 3 | not | 不(否定) | name not like '%so%' id not in (1,10,12) |
| 4 | xor | 异或(相异为真) | age>18 xor title='' |
