@artman328
2019-06-21T04:34:15.000000Z
字数 30664
阅读 1765
数据库技术应用
database sql
艺夫(https://www.gettoweb.net)作品,版权所有。
关于本课程
数据库主要有两个学习方向:
一是数据库技术应用方向:目的是用数据库技术来管理数据,重点在于数据定义与数据操纵(增、删、改、查等),这是软件开发人员的必备技能。
二是数据库管理系统管理方向:目的是对数据库系统进行管理,重点在于数据库管理系统的安全、性能、扩展、迁移、备份与恢复等,这些内容与特定厂商的产品特点相关,不同产品的管理、配置和调整方法有所不同,是数据库管理员的必修内容。
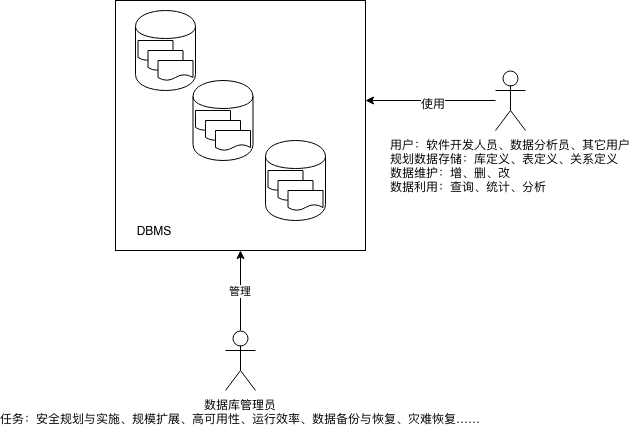
以下是使用数据库管理数据的过程。
以下是对数据库管理系统的管理维护流程。
本课程为应用方向。
第一部分、数据库的相关概念
- 数据(Data)
- 就是信息片段,如:一个数字,一个名字,一个日期,一首歌,一篇文章,一张图片等。
- 数据类型(DataType)
- 在计算机内部,所有信息的表示都是数字。但信息不同,就决定了对它们的处理不同。比如:电话号码相加、日期相加并没有任何意义。根据 SQL 标准,数据库里的数据主要有以下几种类型:数值类型、字符串类型、日期时间类型等。
数值类型:
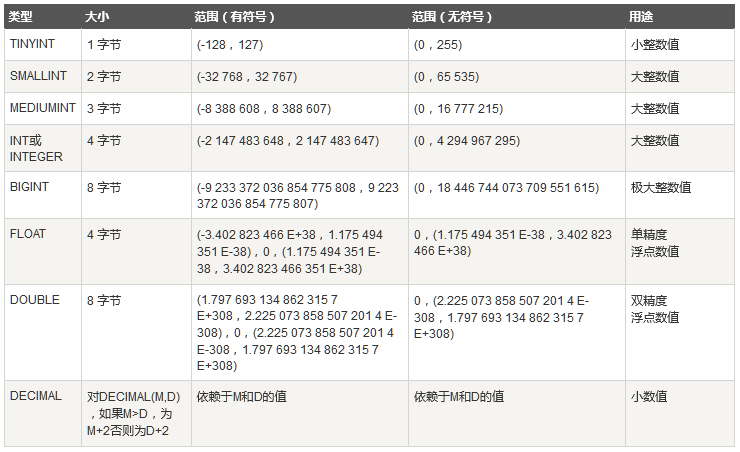
字符串类型:
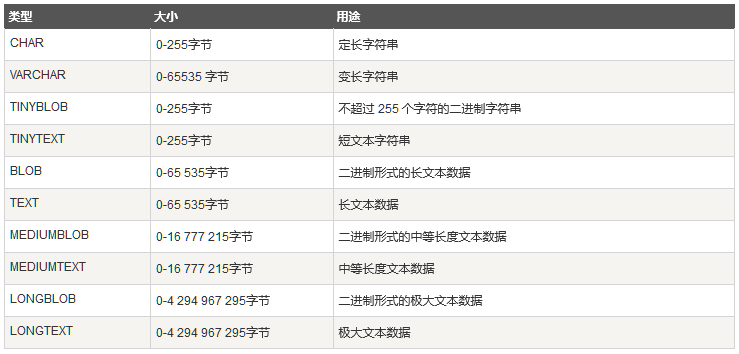
日期时间类型:

- 数据库(Database)
- 用于存储数据(事实上,数据以表的形式进行组织存储)的空间。
- 表(Table):
- 和我们传统意义上的表格一样,表格由行组成,每行由多列组成,每一列代表同一类信息(具有相同的数据类型)。表格正是数据库存储数据的地方。
- 数据库管理系统(DBMS)
- DBMS (Database Management System),用于管理多个数据库,为数据库提供并行访问控制、安全、数据一致性、访问性能调节、日志、数据备份与恢复等服务。
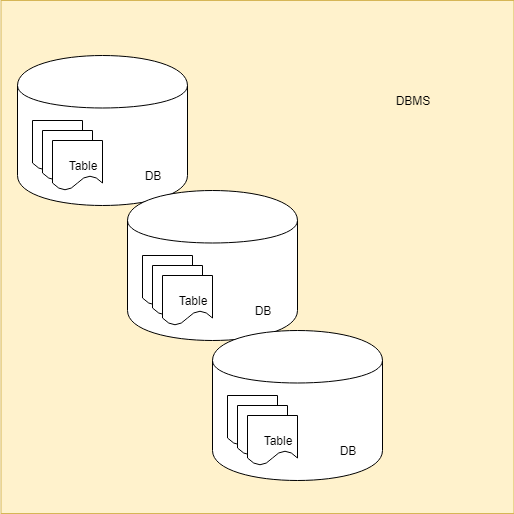
- 数据库服务器(Database Sever)
- (1)运行中的数据库管理系统服务程序;(2)运行数据库管理系统的计算机。
- 数据库客户端(Database Client)
- 可通过某种协议(比如:TCP/IP)连接数据库服务器的程序,用于与数据库管理系统交互进行各种操作和管理。
- 管理信息系统(Management Information System)
- 对信息进行管理的软件系统,这些信息是存储在数据库中的。这样的系统包括:各类网站(如:网易、淘宝、网上银行等),企事业单位的各类业务管理系统(如:人事管理、学籍管理、固定资产管理等)。世界上绝大多数管理软件都和数据库有关。
对软件开发人员来说,掌握数据库,是开发管理信息系统的基本要求!
本课程采用的讲解平台
本课程将使用 MariaDB 数据库管理系统为讲解平台。
第二部分、MariaDB 数据库管理系统的基本操作
2.1 MariaDB 简介
MariaDB, 是 MySQL DBMS 创始人继 MySQL 被卖掉后开发的 MySQL 的一个新分支。
Ulf Michael Widenius,又叫 Monty,芬兰人,于1995年开始创建 MySQL 并于1996年发布。由于MySQL为开源免费软件,并且性能不错,渐渐被越来越多的软件项目所采用。
MySQL 的 ‘My’,是他的大女儿的名字。
2008年,美国 Sun 公司收购了 MySQL 软件项目,后随着 Oracle 公司收购 Sun, MySQL 随即落入 Oracle 之手。
不满于 Oracle 对待 MySQL 的态度(更新迟缓,拒绝外人参与),在众多用户的呼吁下,Monty 另开了 MySQL 的一个分支,取名 MariaDB, 而 Maria 是他的小女儿的名字。
目前,MariaDB 的更新速度已经超过 MySQL,也有了更多的新特性。许多客户都已经转向了 MariaDB,其中包括三星、英特尔、诺基亚、新加坡开发银行等大公司,而将 MariaDB 用于 Web 站点和内部事务管理的组织更是不计其数。
2.2 MariaDB 安装与配置
2.2.1 Windows
见本教程视频。
安装过程中,可定制服务名称、TCP/IP 的监听端口等。
安装完成后,可到“服务”窗口找到对应的服务,可对服务进行操作和配置。
2.2.2 Linux
以 CentOS7 为例:
1) 安装:
yum install mariadb-server
2) 查看服务状态:
systemctl status mariadb
3) 启动服务:
systemctl start mariadb
4) 配置开机启动:
systemctl enable mariadb
5) 运行安全配置脚本
mysql_secure_installation
6) 停止服务:
systemctl stop mariadb
7) 取消开机启动:
systemctl disable mraidb
2.2.3 MacOS
1) 安装
brew install mariadb
2) 查看服务状态
brew services list | grep mariadb
3) 启动服务(同时设定为开机启动)
brew services start mariadb
4) 进行安全配置
mysql_secure_installation
5) 停止服务(同时取消开机启动)
brew services stop mariadb
2.3 客户端连接
2.3.1 图形界面客户端
2.3.2 命令行客户端
mysql [选项] [数据库]
常用选项
| 选项 | 含义 |
|---|---|
| -u | 指定登录用户名,默认为当前系统用户的用户名 |
| -p | 指定登录密码,如后面未跟密码,则会在命令行给出提示 |
| -h | 指定登录的主机,不指定则默认为本机 |
| -P | 指定服务器端口,不指定则默认为3306 |
如:
mysql -uroot -pmypassword -h72.12.34.180 -P3306
在以上连接命令中:
用户名:root
登录密码:mypassword
服务器主机:72.12.34.180
服务器主机端口:3306
2.4 用户的维护与授权
注意:所有的 SQL 语句都是以分号为结尾标志的,一条语句可按自己的意愿写成多行。语句中的所有符号都不能是中文符号!
2.4.1 创建用户
参见:https://mariadb.com/kb/en/library/create-user/
SQL 语法:
CREATE [OR REPLACE] USER [IF NOT EXISTS]user_specification [,user_specification] ...[REQUIRE {NONE | tls_option [[AND] tls_option] ...}][WITH resource_option [resource_option] ...][password_option]user_specification:username [authentication_option]authentication_option:IDENTIFIED BY 'password'| IDENTIFIED BY PASSWORD 'password_hash'| IDENTIFIED {VIA|WITH} authentication_plugin| IDENTIFIED {VIA|WITH} authentication_plugin {USING|AS} 'authentication_string'| IDENTIFIED {VIA|WITH} authentication_plugin {USING|AS} PASSWORD('password')tls_option:SSL| X509| CIPHER 'cipher'| ISSUER 'issuer'| SUBJECT 'subject'resource_option:MAX_QUERIES_PER_HOUR count| MAX_UPDATES_PER_HOUR count| MAX_CONNECTIONS_PER_HOUR count| MAX_USER_CONNECTIONS count| MAX_STATEMENT_TIME timepassword_option:PASSWORD EXPIRE| PASSWORD EXPIRE DEFAULT| PASSWORD EXPIRE NEVER| PASSWORD EXPIRE INTERVAL N DAY
如:创建一个本地用户(只能在本地登录),用密码登录:
CREATE USER 'mydbuser'@'localhost' IDENTIFIED BY 'mypassword';
或者:创建一个全局用户(可从任何主机登录),用密码登录:
CREATE USER 'globaluser'@'%' IDENTIFIED BY 'thepass';
2.4.2 修改用户
参见:https://mariadb.com/kb/en/library/alter-user/
SQL 语法:
ALTER USER [IF EXISTS]user_specification [,user_specification] ...[REQUIRE {NONE | tls_option [[AND] tls_option] ...}][WITH resource_option [resource_option] ...][password_option]user_specification:username [authentication_option]authentication_option:IDENTIFIED BY 'password'| IDENTIFIED BY PASSWORD 'password_hash'| IDENTIFIED {VIA|WITH} authentication_plugin| IDENTIFIED {VIA|WITH} authentication_plugin {USING|AS} 'authentication_string'| IDENTIFIED {VIA|WITH} authentication_plugin {USING|AS} PASSWORD('password')tls_optionSSL| X509| CIPHER 'cipher'| ISSUER 'issuer'| SUBJECT 'subject'resource_optionMAX_QUERIES_PER_HOUR count| MAX_UPDATES_PER_HOUR count| MAX_CONNECTIONS_PER_HOUR count| MAX_USER_CONNECTIONS count| MAX_STATEMENT_TIME timepassword_option:PASSWORD EXPIRE| PASSWORD EXPIRE DEFAULT| PASSWORD EXPIRE NEVER| PASSWORD EXPIRE INTERVAL N DAY
如:修改以上创建的用户“mydbuser”,让他的密码更改为'mypassword1':
ALTER USER 'mydbuser'@'localhost' identified by 'mypassword1';
2.4.3 删除用户
参见:https://mariadb.com/kb/en/library/drop-user/
SQL 语法:
DROP USER [IF EXISTS] user_name [, user_name] ...
如:删除以上创建的用户:
DROP USER 'mydbuser'@'localhost', 'globaluser'@'%';
2.4.4 给用户授权
参见:https://mariadb.com/kb/en/library/grant/
SQL 语法:
GRANTpriv_type [(column_list)][, priv_type [(column_list)]] ...ON [object_type] priv_levelTO user_specification [ user_options ...]user_specification:username [authentication_option]authentication_option:IDENTIFIED BY 'password'| IDENTIFIED BY PASSWORD 'password_hash'| IDENTIFIED {VIA|WITH} authentication_plugin| IDENTIFIED {VIA|WITH} authentication_plugin {USING|AS} 'authentication_string'| IDENTIFIED {VIA|WITH} authentication_plugin {USING|AS} PASSWORD('password')GRANT PROXY ON usernameTO username [, username] ...[WITH GRANT OPTION]user_options:[REQUIRE {NONE | tls_option [[AND] tls_option] ...}][WITH with_option [with_option] ...]object_type:TABLE| FUNCTION| PROCEDUREpriv_level:*| *.*| db_name.*| db_name.tbl_name| tbl_name| db_name.routine_namewith_option:GRANT OPTION| resource_optionresource_option:MAX_QUERIES_PER_HOUR count| MAX_UPDATES_PER_HOUR count| MAX_CONNECTIONS_PER_HOUR count| MAX_USER_CONNECTIONS count| MAX_STATEMENT_TIME timetls_option:SSL| X509| CIPHER 'cipher'| ISSUER 'issuer'| SUBJECT 'subject'
如:
1. 对已经存在的用户授予操作所有对象的所有权限
GRANT ALL PRIVILEGES ON *.* TO 'globaluser'@'%';
- 对已经存在的用户授予操作数据库「mydb」的所有对象的所有权限
GRANT ALL PRIVILEGES ON mydb.* to 'mydbuser'@'localhost';
- 创建用户并给其授权
GRANT ALL PRIVILEGES ON selldb.* TO 'selldbadmin'@'localhost' identified by 'passwordforadmin';
2.4.5 取消用户授权
参见:https://mariadb.com/kb/en/library/revoke/
SQL 语法:
REVOKEpriv_type [(column_list)][, priv_type [(column_list)]] ...ON [object_type] priv_levelFROM user [, user] ...REVOKE ALL PRIVILEGES, GRANT OPTIONFROM user [, user] ...
如:取消用户「mydbuser」的所有授权
REVOKE ALL PRIVILEGES, GRANT OPTION FROM 'mydbuser'@localhost';
第三部分、数据库应用基础语法(DDL和DML)
注意:所有的 SQL 语句都是以分号为结尾标志的,一条语句可按自己的意愿写成多行。语句中的所有符号都不能是中文符号!
3.1 数据定义(Data Definition)
数据定义就是数据存储规划:建库、建表、建立表间关系。
3.1.1 数据库的建立与维护
在建立和维护数据库之前,您可用以下命令列出 DBMS 管理的所有数据库:
SHOW DATABASES;
还可用此命令查看某个数据库的建库详情:
SHOW CREATE DATABASE 数据库名;
3.1.1.1 建立数据库
参见:https://mariadb.com/kb/en/library/create-database/
CHARACTER SET: 字符集,字符编码方案。查看:
show character set;
COLLATE: 排序方案。查看:
show collation;
建立数据库:
CREATE [OR REPLACE] {DATABASE | SCHEMA} [IF NOT EXISTS] db_name[create_specification] ...create_specification:[DEFAULT] CHARACTER SET [=] charset_name| [DEFAULT] COLLATE [=] collation_name
如:
CREATE DATABASE `mydb` CHARACTER SET utf8;-- 或者:CREATE DATABASE `mydb` COLLATE utf8_general_ci;-- 或者:CREATE DATABASE `mydb` CHARACTER SET utf8 COLLATE utf8_unicode_ci;
3.1.1.2 修改数据库
参见:https://mariadb.com/kb/en/library/alter-database/
ALTER {DATABASE | SCHEMA} [db_name]alter_specification ...ALTER {DATABASE | SCHEMA} db_nameUPGRADE DATA DIRECTORY NAMEalter_specification:[DEFAULT] CHARACTER SET [=] charset_name| [DEFAULT] COLLATE [=] collation_name
如:把以上数据库的字符编码改为「utf8mb4」:
ALTER DATABASE `mydb` CHARACTER utf8mb4;-- 或者:ALTER DATABASE `mydb` COLLATE utf8mb4_general_ci;
3.1.1.3 删除数据库
参见:https://mariadb.com/kb/en/library/drop-database/
DROP {DATABASE | SCHEMA} [IF EXISTS] db_name
如:删除以上建立的数据库:
DROP DATABASE `mydb`;
3.1.1.4 打开数据库
USE 数据库名;
此后,所有操作均默认针对此打开的数据库。
现在,我们可列出数据库里的所有表:
SHOW TABLES;
3.1.2 表的建立与维护
为完成以下内容讲解,我们将建立一个数据库 mydb,然后建立一张表 products 存储进货商品明细。
drop database if exists `mydb`;create database if not exists `mydb` character set utf8mb4;use `mydb`;--接着建立数据表
以上三行,我们且把它叫做“调试建库三步曲”。
可用以下语句列出数据库中的表:
show tables;
可用以下语句查看一张表的列的情况:
describe 表名;
可用以下语句查看建表的 SQL 语句:
show create table 表名;
3.1.2.1 表的建立
详细语法请参见 https://mariadb.com/kb/en/library/create-table/
基本语法:
CREATE TABLE [IF NOT EXISTS] 表名(列定义[,列定义] ... [,约束定义] ...)[表选项];列定义:列名 数据类型 [可否为空] [默认值] [约束] [索引]约束定义:CONSTRAINT [约束名] 约束表达
我们需要管理的数据格式及内容如下:
| 序号 | 品名 | 型号规格 | 进货日期 | 数量 | 单位 | 进价 | 销售单价 | 实际进货金额 |
|---|---|---|---|---|---|---|---|---|
| 1 | 打印机 | CR3240 | 2017-10-10 | 10 | 台 | 2000.00 | 2500.00 | 20000.00 |
| 2 | 打印机 | BR3240 | 2017-10-10 | 10 | 台 | 2000.00 | 2500.00 | 20000.00 |
| 3 | 显示器 | LG2301 | 2017-10-25 | 8 | 台 | 750.00 | 1000.00 | 6000.00 |
| 4 | 打印机 | BJ2090 | 2017-10-30 | 6 | 台 | 2100.00 | 2700.00 | 12600.00 |
| 5 | 主板 | ASUS1175 | 2018-01-05 | 18 | 块 | 670.00 | 880.00 | 12060.00 |
| 6 | 鼠标 | Logic66 | 2018-02-10 | 80 | 个 | 30.00 | 45.00 | 2300.00 |
| 7 | 打印机 | CR3240 | 2018-02-20 | 12 | 台 | 2000.00 | 2500.00 | 24000.00 |
| 8 | 打印机 | BR3240 | 2018-03-08 | 10 | 台 | 2100.00 | 2700.00 | 21000.00 |
| 9 | 显示器 | AOC2388 | 2018-03-10 | 20 | 台 | 780.00 | 900.00 | 15600.00 |
| 10 | 键盘 | Logic101 | 2018-09-01 | 30 | 个 | 50.00 | 80.00 | 1500.00 |
| 11 | 主板 | intel1711 | 2019-01-08 | 20 | 块 | 900.00 | 1250.00 | 18000.00 |
| 12 | 键盘 | lenovo51 | 2019-01-10 | 20 | 个 | 80.00 | 120.00 | 1600.00 |
| 13 | 键盘 | lenovo51 | 2019-01-10 | 20 | 个 | 85.00 | 120.00 | 1700.00 |
| 14 | 鼠标 | lenovo67 | 2019-02-10 | 50 | 个 | 60.00 | 80.00 | 3000.00 |
为了建立表格,我们首先需要确定表格各列的数据类型、必要性、默认值等。
数据类型:为了将数据存入数据库让计算机进行正确处理,就要确定各列的数据类型;
必要性:即列的值是否可不填,不填为空(NULL);
默认值:如果没有填,是否自动填入某个值。
常用的数据类型:
数值类型
字符串类型
日期时间类型
- 序号
- 无符号整型,最多可记录近43亿行,如果怕不够(!),也可用无符号大整型。自动插入自动增长的值(流水号),必填。
- 品名
- 变长字符串,最多100g字符,必填。
- 型号规格
- 变长字符串,最多100个字符,必填。
- 进货日期
- 日期型,必填。
- 数量
- 浮点小数,长度8,精度2,必填,无默认值,大于零。(最大:999999.99,考虑有的商品数量可能为小数)
- 单位
- 变长字符串,最多50个字符,必填,默认值:“个”。(考虑外文的计量单位)
- 进价
- 大整型(bigint,以“分”存储)或小数型(decimal(10,2),以“元”存储),必填。
- 销售单价
- 同“进价”,必填。
- 实际进货金额
- 同“进价”,必填,默认值:“进价” * “数量”。
创建我们的表的 SQL 语句为:
CREATE TABLE `products`(`id` int unsigned not null auto_increment primary key,`name` varchar(100) not null,`spec` varchar(100) not null,`got_date` date not null,`quantity` float(8,2) not null,`unit` varchar(50) not null default '个',`in_price` decimal(10,2) not null,`in_price_sum_act` decimal(10,2) not null default (`in_price`*`quantity`),`out_price` decimal(10,2) not null);
3.1.2.2 表的修改
参见:https://mariadb.com/kb/en/library/alter-table/
(1)添加列
给我们的表添加一列,“备注”(memo),变长字符,最多100个字符,可不填,添加到末尾。
alter table `products` add column `memo` varchar(100);
给我们的表再添加一列,“进价小计”(in_price_sum),精确小数,10位数字,2位小数,必填,默认值:“进价” * “数量”,添加到“进价”(in_price)的后面。
alter table `products` add column `in_price_sum` decimal(10,2) not null default (`in_price` * `quantity`) after `in_price`;
(2)修改列名
把我们的表中的列“销售单价” out_price 改成 sell_price。
alter table `products` change column `out_price` `sell_price` decimal(10,2) not null;
(3)修改列定义
把“数量”(quantity)的数据类型改成 decimal(8,2)。
alter table `products` modify column `quantity` decimal(8,2) not null;
把“单位”(unit)的默认值去掉。
alter table `products` alter column `unit` drop default;
(4)删除列
删除刚才添加的“进价小计”(in_price_sum)。
alter table `products` drop column `in_price_sum`;
3.1.2.3 表的删除
-- 先创建一张表create table test(id int not null primary key,name varchar(50));-- 显示确认表已经被创建show tables;-- 删除表drop table test;
3.2 数据操纵(Data Manipulation)
数据操纵就是对数据的增、删、改、查。
3.2.1 操纵条件
数据操纵可能指针对某些行,需要条件过滤。
条件用比较运算结合逻辑运算来表达。
例如:
“当气温在30度以上或者湿度不低于70%并且时间已经超过24小时……”,这当中的“气温在30度以上”、“湿度不低于70%”以及“时间已经超过24小时”都是比较运算,“或者”、“并且”等是逻辑运算。
比较运算和逻辑运算的结果是“真”(用 1 表示)和“假”(用 0 表示)。
1、比较运算:
参见:https://mariadb.com/kb/en/library/comparison-operators/
| 运算符 | 含义 | 适合运用的数据类型 | 举例 |
|---|---|---|---|
| = | 等于 | 所有整型、字符型、日期时间型、精确小数(decimal) | 数量等于10:count=10; 姓名为 billy: name='Billy' 出生日期在1990年1月1日: birth_date='1990-01-01' 金额为1000.00元:price=1000.00 |
| <=> | 等于(可比较NULL) | 所有整型、字符型、日期时间型、精确小数(decimal) | 数量等于10:count<=>10; 姓名为 billy: name<=>'Billy' 出生日期在1990年1月1日: birth_date<=>'1990-01-01' 金额为1000.00元:price<=>1000.00 |
| > | 大于 | 所有整型、日期时间型、精确小数(decimal) | 数量大于10:count>10; 出生日期在1990年1月1日以后: birth_date>'1990-01-01' 金额为1000.00元以上:price>1000.00 |
| < | 小于 | 同上 | 数量小于10:count><10; 出生日期在1990年1月1日以前: birth_date<'1990-01-01' 金额为1000.00元以下:price<1000.00 |
| >= | 大于等于 | 同上 | |
| <= | 小于等于 | 同上 | |
| <> 或 != | 不等于 | 同 = | 性别不是'男': gender != '男' |
| LIKE | 像某个字符串,字符串中可用'%'表示任意长度的字符串,'_'表示一个任意字符。 | 字符类型 | 姓名包含'丽': name LIKE '%丽%' 姓名以'李'开头:name LIKE '李%' 姓名以'丽'结尾:name LIKE '%丽' 型号有5个字符,第一个字符是'F':spec LIKE 'F____' |
| NOT LIKE | 不像,与 LIKE 相反 | ||
| IN (v1,v2,...) | 等于 v1,v2,...中的任意一个 | 同 = | 编号为10,12,15:id IN (10,12,15) |
| NOT IN (v1,v2,...) | 不等于 v1,v2,...中的任何一个 | 同上 | 编号不是10,20,30: id NOT IN (10,20,30) |
| BETWEEN v1 AND v2 | 在 v1 到 v2 之间(含v1,v2),v1<=v2, 相当于:v>=v1 AND v<=v2 | 同上 | 数量在100到500之间:count BETWEEN 100 AND 500 |
| NOT BETWEEN v1 AND v2 | 不在v1到v2之间,相当于:v< v1 AND v>v2 | 同上 | |
| IS | 是否是 TRUE, FALSE 或 UNKNOWN | 全部 | |
| IS NOT | 是否不是 TRUE, FALSE 或 UNKNOWN | 全部 | |
| IS NULL | 为空 | 全部 | 出生日期为空:birth_date IS NULL |
| IS NOT NULL | 不为空 | 全部 | 备注不为空:memo IS NOT NULL |
2、逻辑运算:
(1)运算符
| 运算符 | 含义 | 举例 |
|---|---|---|
| AND,&& | 并且 | 数量超过100并且价格在1000员以上: quantity>100 AND price>1000 |
| OR,|| | 或者 | 性别为女性或者年龄在18岁以下: gender='女' OR age<18 |
| NOT,! | 非 | 来源不是‘进口’的产品: NOT source='进口' |
| XOR | 异或,A XOR B,A,B都为真或假时,返回0,否则返回1 | 原来的人事管理,对年龄超过50岁且是女性的人员有特殊补贴且已经加到了津贴中,现在只要满足条件之一就可享受此项补贴并补加到津贴中,找出只满足条件之一的所有人员: age>50 XOR gender LIKE '%女%' 相当于: (age>50 and gender NOT LIKE '%女%') OR (age<=50 and gender LIKE ) '%女%' |
(2)运算规则
AND:
1 AND 1 = 1
1 AND 0 = 0
0 AND 1 = 0
0 AND 0 = 0
结论:全真才得真。
OR:
1 OR 1 = 1
1 OR 0 = 1
0 OR 1 = 1
0 OR 0 = 0
结论:全假才得假
NOT:
NOT 1 = 0
NOT 0 = 1
结论:得反值。
XOR:
1 XOR 1 = 0
1 XOR 0 = 1
0 XOR 1 = 1
0 XOR 0 = 0
结论:相同得假,不同得真。
(3)运算优先级
NOT, AND, XOR, OR
3、条件组合结果解读
值:a=100, b=30, c='doing', d='2018-10-30'
a>=100 OR b>80 AND c NOT LIKE '%ch%'
(a>=100 OR b>80) AND c NOT LIKE '%ch%'
a<100 AND (b>50 OR d BETWEEN '2010-01-01' AND '2018-12-31')
a NOT IN (100,200,300) AND b BETWEEN 1 AND 100 OR c LIKE 'do%' AND d IS NULL
a>=80 OR b<=50 XOR c='doing'
4、条件组合优化
为提高运算效率,在预知结果的情况下,DBMS 会尽早结束逻辑运算。
对于 AND 连接的多个比较运算,只要遇到第一个得 0 值的比较运算,整个逻辑运算结果就是 0,并不再续续做余下的比较运算。
对于 OR 连接的多个比较运算,只要遇到第一个得 1 值的比较运算,整个逻辑运算结果就是 1,并不再续续做余下的比较运算。
优化原则:
对于 AND 连接的多个比较运算,按容易得到 0 的可能性依大到小排列;
对于 OR 连接的多个比较运算,按容易得到 1 的可能性依大到小排列;
比如数据表中有100,000条记录,其中有一列是“分类”(category),只有在很少一些行里是“未分类”(1,000行),有一列是“备注”(memo),大多数是 NULL(90,000行)。如何构建以下条件更有效?
条件:备注为空并且分类是“未分类”
“备注为空” —— 大概率,分类是“未分类” —— 小概率
category='未分类' AND memo IS NULL (完整判断:1000次)-- 比较memno IS NULL AND category='未分类' (完整判断:90,000次,90倍!)
条件:备注不为空并且分类不是“未分类”
“备注不为空” —— 小概率,分类不是“未分类” —— 大概率
memo IS NOT NULL AND category!='未分类' (完整判断:10,000次)-- 比较category!='未分类' AND memo IS NOT NULL(完整判断:99,000次,9.9倍)
条件:备注为空或者分类是“未分类”
“备注为空” —— 大概率,分类是“未分类” —— 小概率
memo IS NULL OR category='未分类'(完整判断:10,000次)-- 比较category='未分类' OR memo IS NULL(完整判断:99,000次,9.9倍)
条件:备注不为空或者分类不是“未分类”
备注不为空” —— 小概率,分类不是“未分类” —— 大概率
category!='未分类' OR memo IS NOT NULL(完整判断:1,000次)-- 比较memo IS NOT NULL OR category!='未分类'(完整判断:90,000次,90倍)
当然,只有在对表中数据分布具有统计学上的认识,并且数据分布较为极端且相对稳定的情况下,这种类型的优化才有意义。
3.2.2 插入数据
参见:https://mariadb.com/kb/en/library/insert/
演示插入数据的第一张表:
CREATE TABLE `t1`(`no` INT UNSIGNED AUTO_INCREMENT PRIMARY KEY,`name` VARCHAR(100) NOT NULL,`gender` CHAR(10) DEFAULT 'Male',`birth_date` DATE NOT NULL,`hometown` VARCHAR(50));
提前了解:
SELECT 列名1,列名2,... FROM 表名;
从表中获取所有记录,只包含指定列名的列。可用 * 代表所有列。
1、语法1:
INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE][INTO] tbl_name [PARTITION (partition_list)] [(col,...)]{VALUES | VALUE} ({expr | DEFAULT},...),(...),...[ ON DUPLICATE KEY UPDATEcol=expr[, col=expr] ... ]
(1)要点:
INSERT INTO 表名[(列1,列2,...)]
VALUES (值1,值2,...)[,(值1,值2,...), ...];
值可以是一个具体值,一个表达式(可计算得到值,包括算式、函数等),或关键字 DEFAULT。DEFAULT 指用列定义时指定的默认值(未指定时,隐含的默认值为 NULL)进行填入。对于 AUTO_INCREMENT 列,指定值为 NULL 或 DEFAULT 时自动填入下一个流水号。
如果值列表包含了全部列,并且顺序与列名一一对应,则(列1,列2,...)可省略。
可一次插入多条记录。
ON DUPLICATE KEY UPDATE col1=exp1 [,col2=exp2] ...
当插入记录与主键或唯一性列出现重复时,改为更新记录,MySQL/MariaDB 独有。
(2)举例
例一,未指明列。
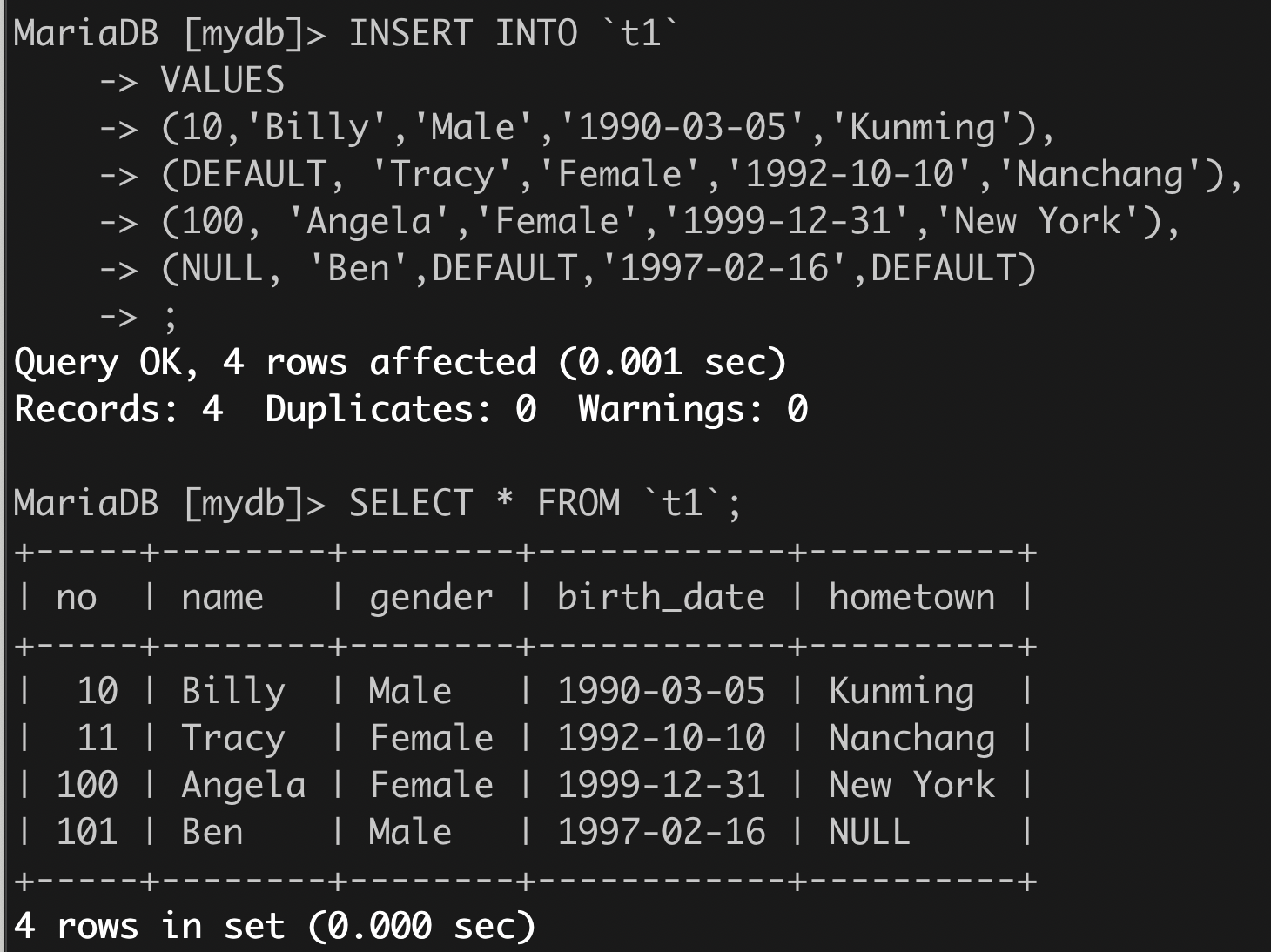
例二,指明部分列,至少指明不能为空而又未指明默认值的列。
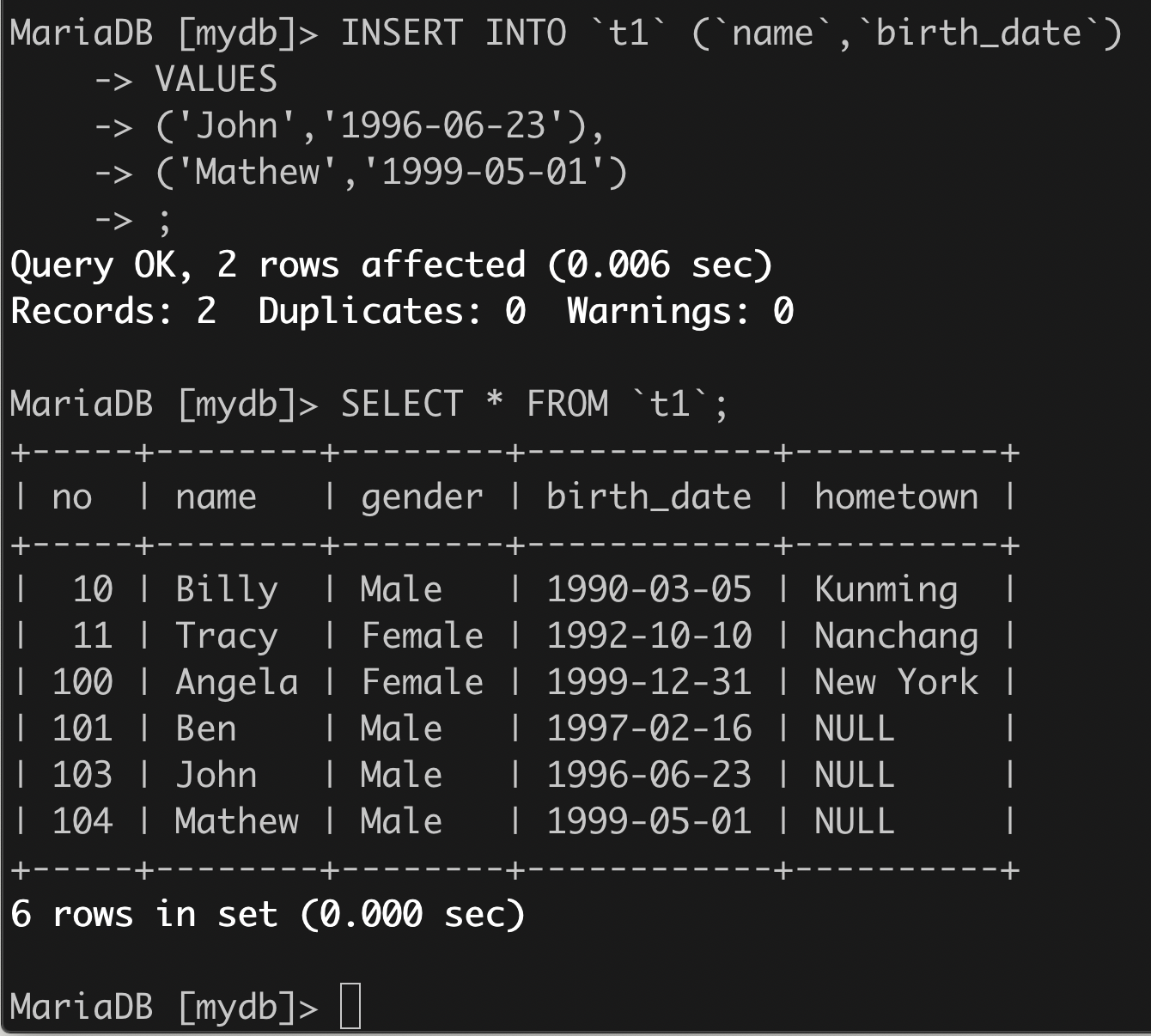
2、语法2:
INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE][INTO] tbl_name [PARTITION (partition_list)]SET col={expr | DEFAULT}, ...[ ON DUPLICATE KEY UPDATEcol=expr[, col=expr] ... ]
(1)要点:
INSERT INTO 表名 SET 列1=值1,[列2=值2] ...
只适合插入一条记录。
(2)举例:
INSERT INTO `t1` SET `name`='Whoever', `birth_date`='1988-09-12';
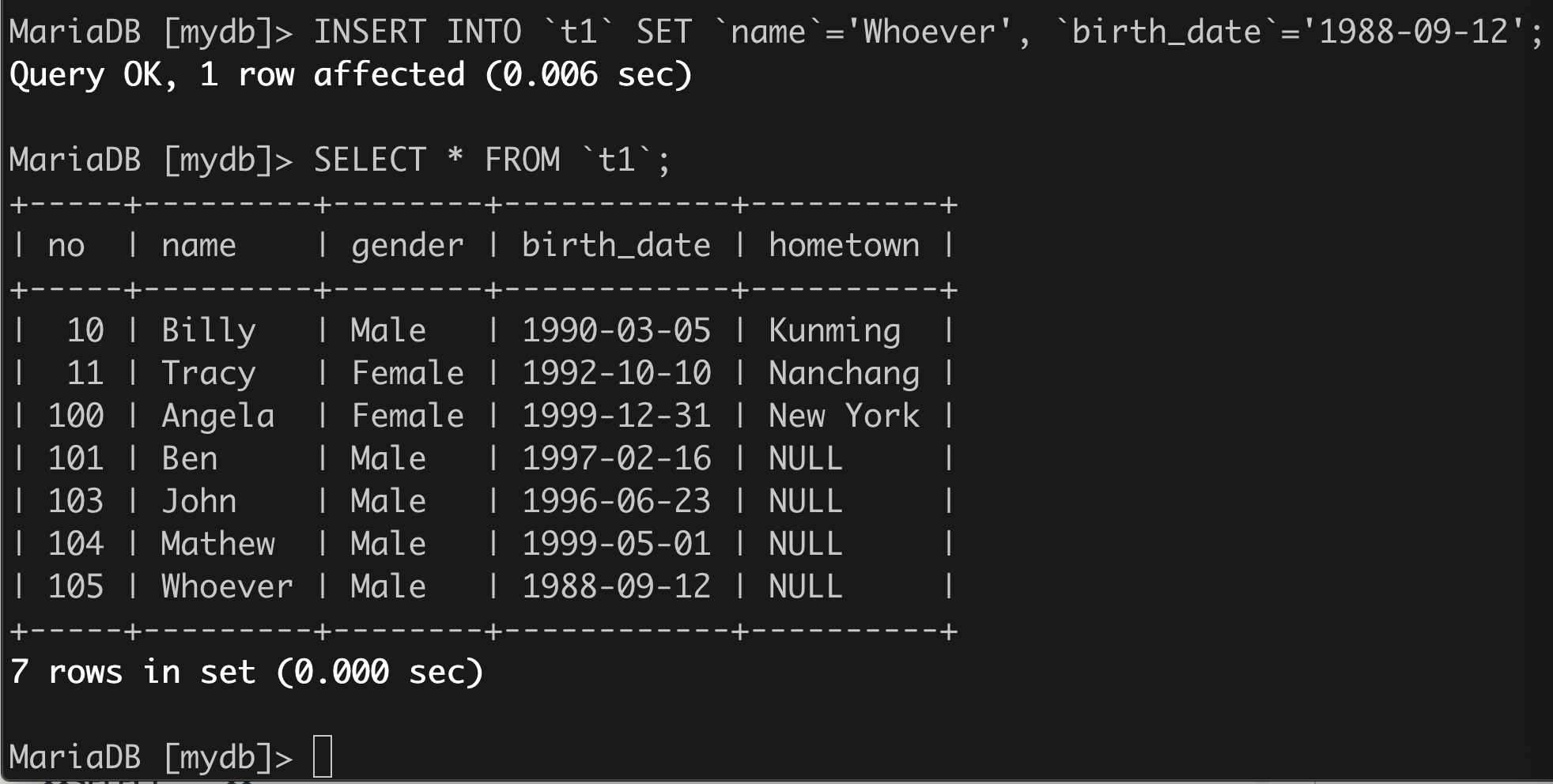
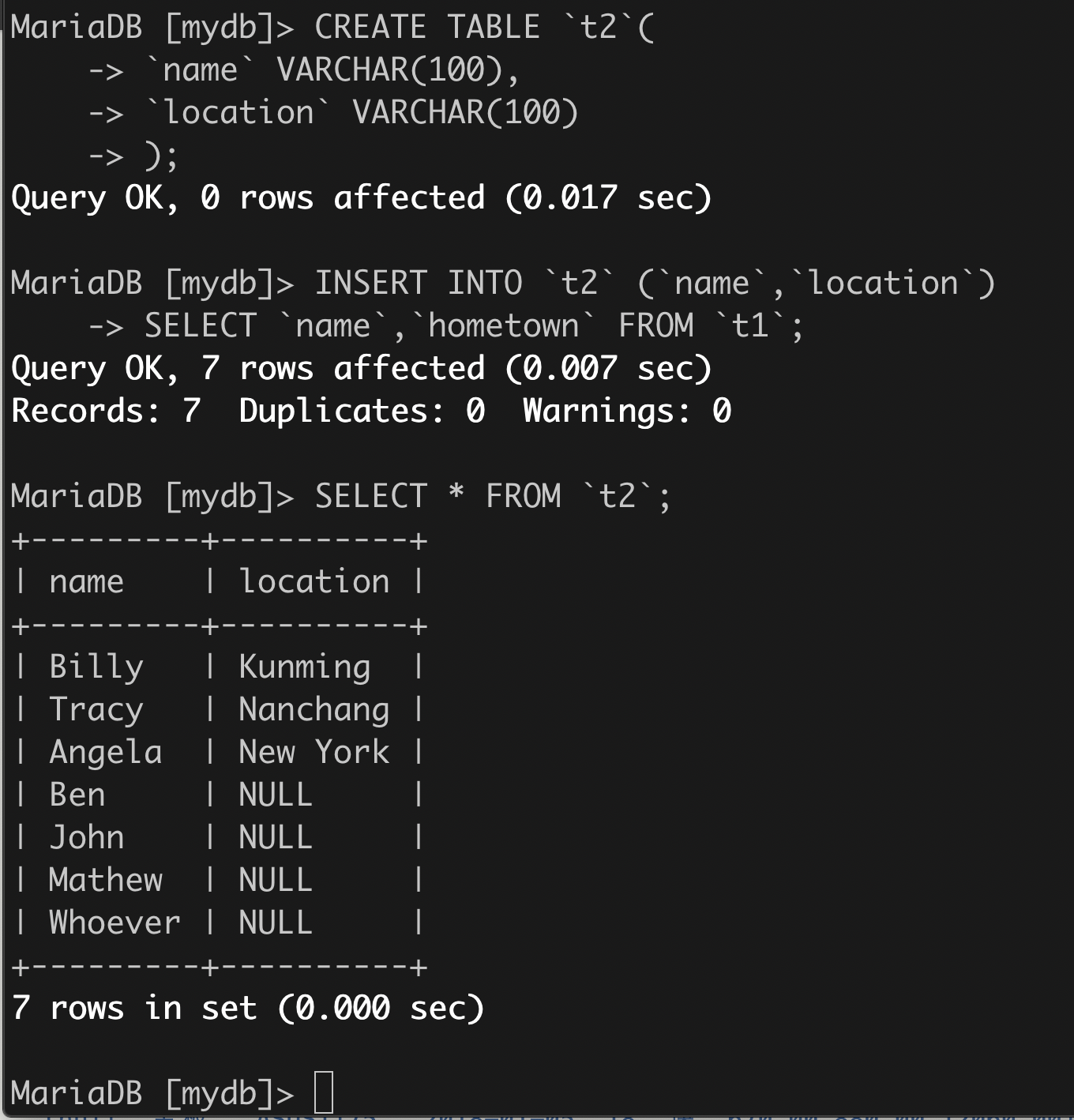
3、语法3:
INSERT [LOW_PRIORITY | HIGH_PRIORITY] [IGNORE][INTO] tbl_name [PARTITION (partition_list)] [(col,...)]SELECT ...[ ON DUPLICATE KEY UPDATEcol=expr[, col=expr] ... ]
(1)要点:
INSERT INTO 表名 [(列1,列2,...)]
SELECT ...
从 SELECT 语句(从表中获取数据)产生对应值进行插入。
可一次插入多条记录。
(2)举例
先创建用于插入数据的第二张表,再用第一张表的 name 和 hometown 来填入第二张表。
现在,我们来为 products 表插入样例数据。
INSERT INTO products(id,name,spec,got_date,quantity,unit,in_price,sell_price,in_price_sum_act)VALUES(null,'打印机','CR3240','2017-10-10',10,'台',2000.00,2500.00,20000.00),(null,'打印机','BR3240','2017-10-10',10,'台',2000.00,2500.00,20000.00),(null,'显示器','LG2301','2017-10-25',8,'台',750.00,1000.00,6000.00),(null,'打印机','BJ2090','2017-10-30',6,'台',2100.00,2700.00,12600.00),(null,'主板','ASUS1175','2018-01-05',18,'块',670.00,880.00,12060.00),(null,'鼠标','Logic66','2018-02-10',80,'个',30.00,45.00,2300.00),(null,'打印机','CR3240','2018-02-20',12,'台',2000.00,2500.00,24000.00),(null,'打印机','BR3240','2018-03-08',10,'台',2100.00,2700.00,21000.00),(null,'显示器','AOC2388','2018-03-10',20,'台',780.00,900.00,15600.00),(null,'键盘','Logic101','2018-09-01',30,'个',50.00,80.00,1500.00),(null,'主板','intel1711','2019-01-08',20,'块',900.00,1250.00,18000.00),(null,'键盘','lenovo51','2019-01-10',20,'个',80.00,120.00,1600.00),(null,'键盘','lenovo51','2019-01-10',20,'个',85.00,120.00,1700.00),(null,'鼠标','lenovo67','2019-02-10',50,'个',60.00,80.00,3000.00);
3.2.3 获取数据
参见:https://mariadb.com/kb/en/library/select/
语法:
SELECT[ALL | DISTINCT | DISTINCTROW][HIGH_PRIORITY][STRAIGHT_JOIN][SQL_SMALL_RESULT] [SQL_BIG_RESULT] [SQL_BUFFER_RESULT][SQL_CACHE | SQL_NO_CACHE] [SQL_CALC_FOUND_ROWS]select_expr [, select_expr ...][ FROM table_references[WHERE where_condition][GROUP BY {col_name | expr | position} [ASC | DESC], ... [WITH ROLLUP]][HAVING where_condition][ORDER BY {col_name | expr | position} [ASC | DESC], ...][LIMIT {[offset,] row_count | row_count OFFSET offset}][PROCEDURE procedure_name(argument_list)][INTO OUTFILE 'file_name' [CHARACTER SET charset_name] [export_options][INTO DUMPFILE 'file_name'][INTO var_name [, var_name] ][[FOR UPDATE | LOCK IN SHARE MODE] [WAIT n | NOWAIT] ]]export_options:[{FIELDS | COLUMNS}[TERMINATED BY 'string'][[OPTIONALLY] ENCLOSED BY 'char'][ESCAPED BY 'char']][LINES[STARTING BY 'string'][TERMINATED BY 'string']]
3.2.3.1 语法详解
- 1、关键词
- ALL
- 选择所有行,默认行为。
SELECT ALL * FROM `products`;
- DISTINCT
- 选择不重复的数据行,选择单列,去掉重复值(或选择多列,去掉多列组合重复值)。
SELECT DISTINCT `name`, `spec` FROM `products`;SELECT DISTINCT unit FROM products;
- DISTINCTROW
- 同 DISTINCT。
2、选择对象
SELECT 选择对象 ...
(1)全部列(字段)
SELECT * FROM `products`;
(2)部分列(字段)
SELECT `id`, `name`, `spec`, `got_date` FROM `products`;
(3)字段重命名
可用中文名。
SELECT `id` AS `编号`, `name` AS `名称`,
(4)使用内建函数
内建函数,参见:https://mariadb.com/kb/en/library/built-in-functions/
CONCAT(...): 将参数字符串联接起来。
DATE_FORMAT(date,format): 按格式输出日期。
SELECT id, CONCAT(name, '-', spec) AS `product`, DATE_FORMAT(got_date,'%Y年%m月%d日') AS `the_date` FROM `products`;
(5)使用聚合函数
聚合函数,参见:https://mariadb.com/kb/en/library/aggregate-functions/
-- 获取表的记录行数SELECT COUNT(*) FROM `products`;-- 获取实际进货金额的最大值(MAX)、最小值(MIN)、平均值(AVG)、合计值(SUM)。SELECTMAX(`in_price_sum_act`),MIN(`in_price_sum_act`),AVG(`in_price_sum_act`),SUM(`in_price_sum_act`)FROM `products`;
3、FROM 指定表
可指定多张表,且可为表指定别名。如果从多张表选择数据,如果两张或以上的表具有相同的列名,指定这种列名时,就要指明表的名称。一个可靠的做法是,把所有的列名都附上表的别名。例如:
-- a 是 table1 的别名,b 是 table2 的别名SELECT `a`.`name`, `b`.`name`FROM `table1` `a`, `table2` `b`;
4、WHERE 指定条件
指定条件是用逻辑运算符连接的比较运算表达式,可用括号改变逻辑运算组合及顺序,是获取数据最灵活生动的部分。
举例:
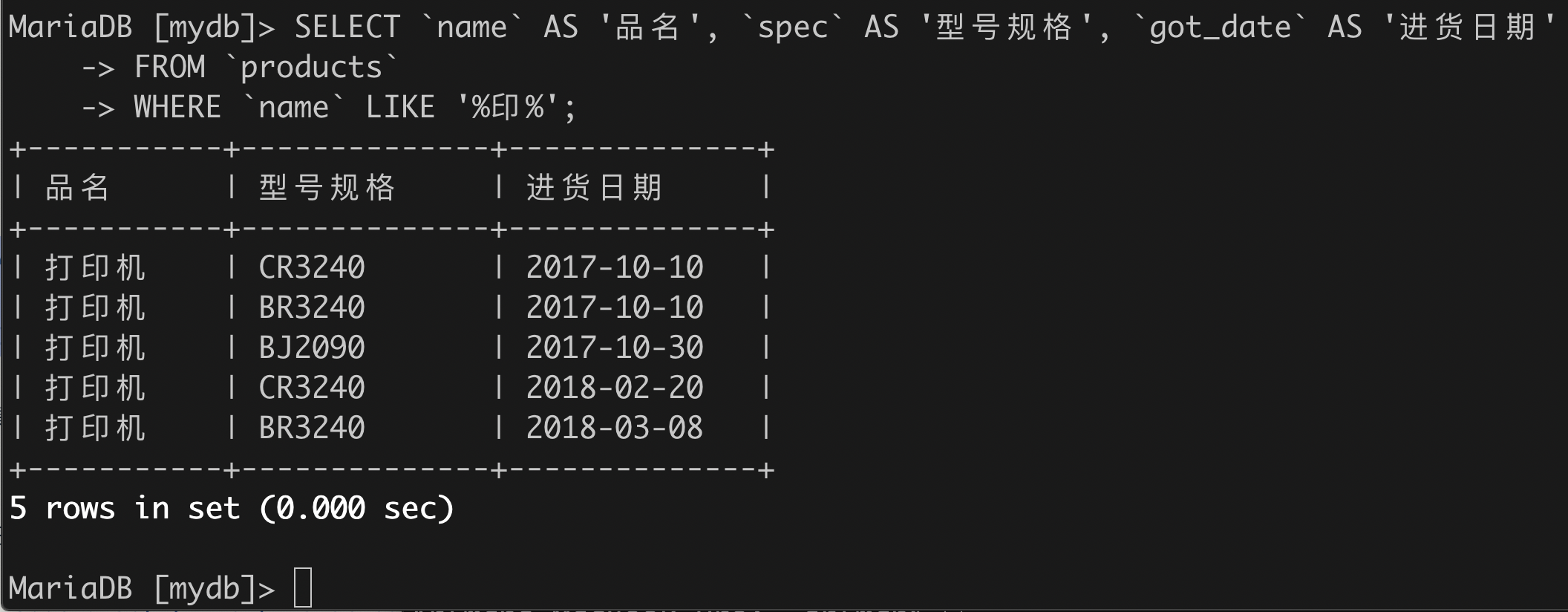
(1)模糊查找“品名”包含某关键字符串的所有商品(品名、型号规格、进货日期);
SELECT `name` AS '品名', `spec` AS '型号规格', `got_date` AS '进货日期'FROM `products`WHERE `name` LIKE '%印%';
查找开头:'关键字%'
查找结尾:'%关键字'
(2)查找某个日期范围的所有进货项(不含“销售单价”);
SELECT `id`, `name`, `spec`, `quantity`, `unit`,`in_price`, `got_date`, `sell_price`FROM `products`WHERE `got_date` BETWEEN '2018-01-01' AND '2018-03-01';
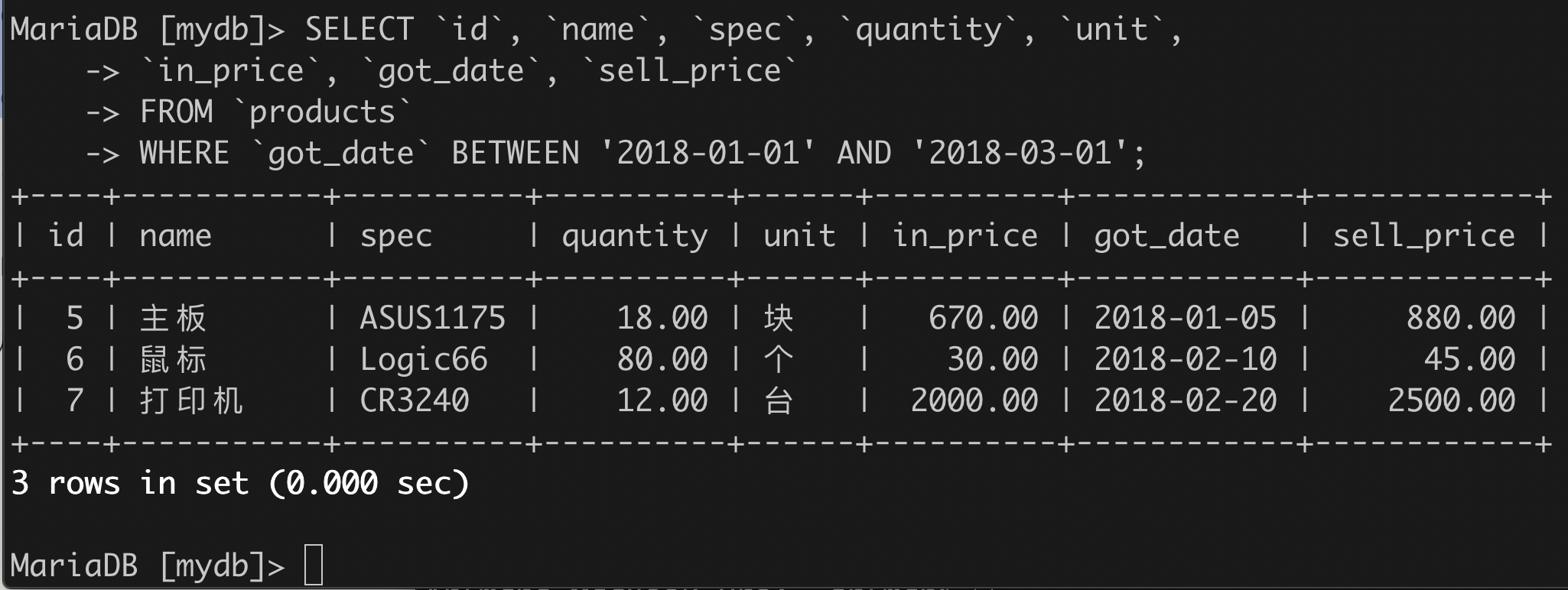
(3)列出“进价”在某个范围的所有进货项;
SELECT * FROM products WHERE in_price>700 AND in_price<2000;
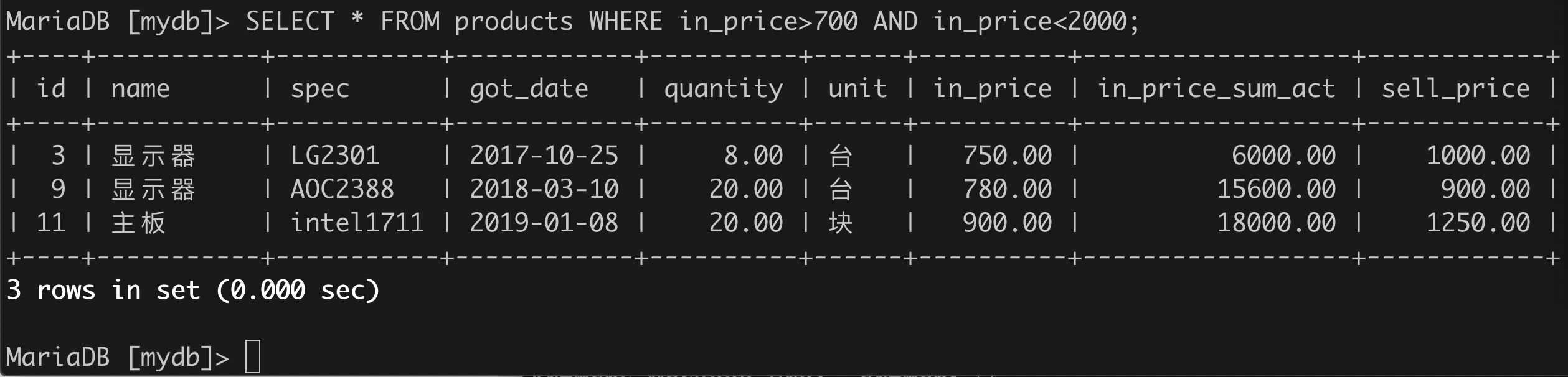
(4)找出售价高于3000或低于1000,且进货日期在最近进货日期前10天的所有商品。
SELECT * FROM `products`WHERE (`sell_price`<1000 OR 'sell_price'>3000)AND `got_date`>=(SELECT MAX(got_date) from products)-interval 10 day;
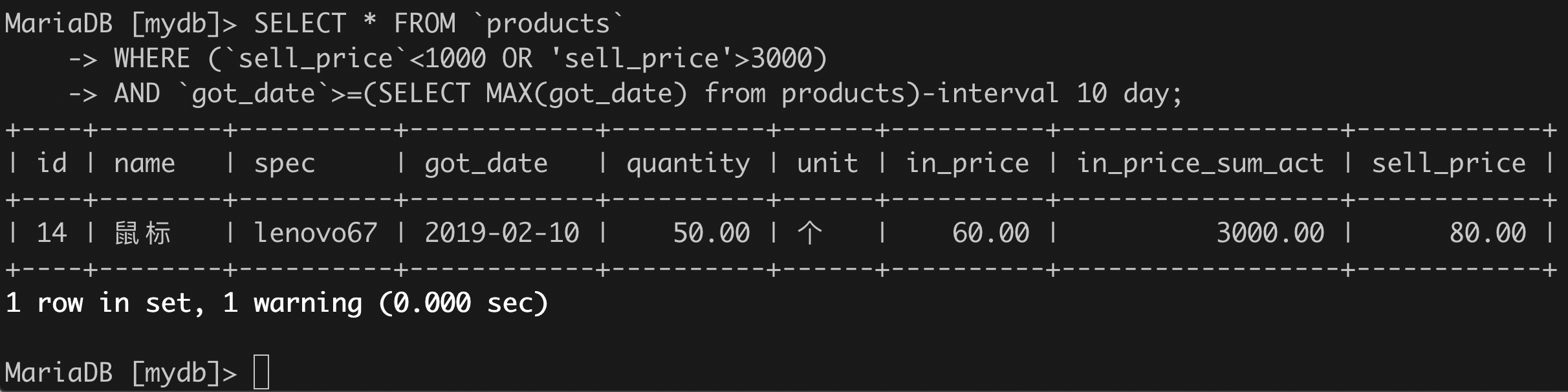
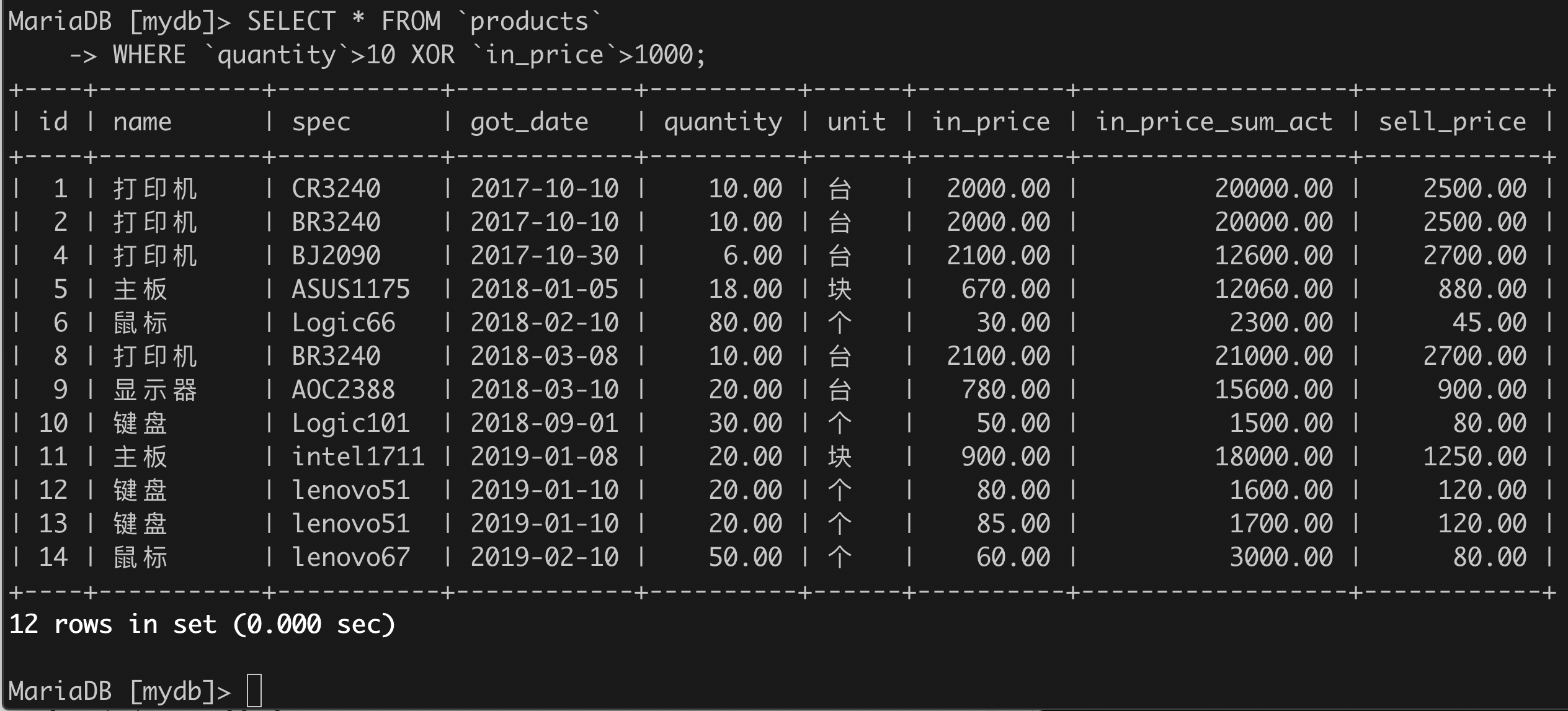
(5)找出数量大于10或者进货价大于1000元的所有进货项,但要排除二者均满足的记录。
SELECT * FROM `products`WHERE `quantity`>10 XOR `in_price`>1000;
- 5、GROUP BY 分组统计与 ORDER排序
- GROUP BY 列1 [,列2, ... 列n]
- 基于 列1...列n 的组合进行分组统计。
- ORDER BY 列1 [,列2, ... 列n]
- 先基于 列1 进行排序,然后再按 列2 排序,直到 列n。
例如:
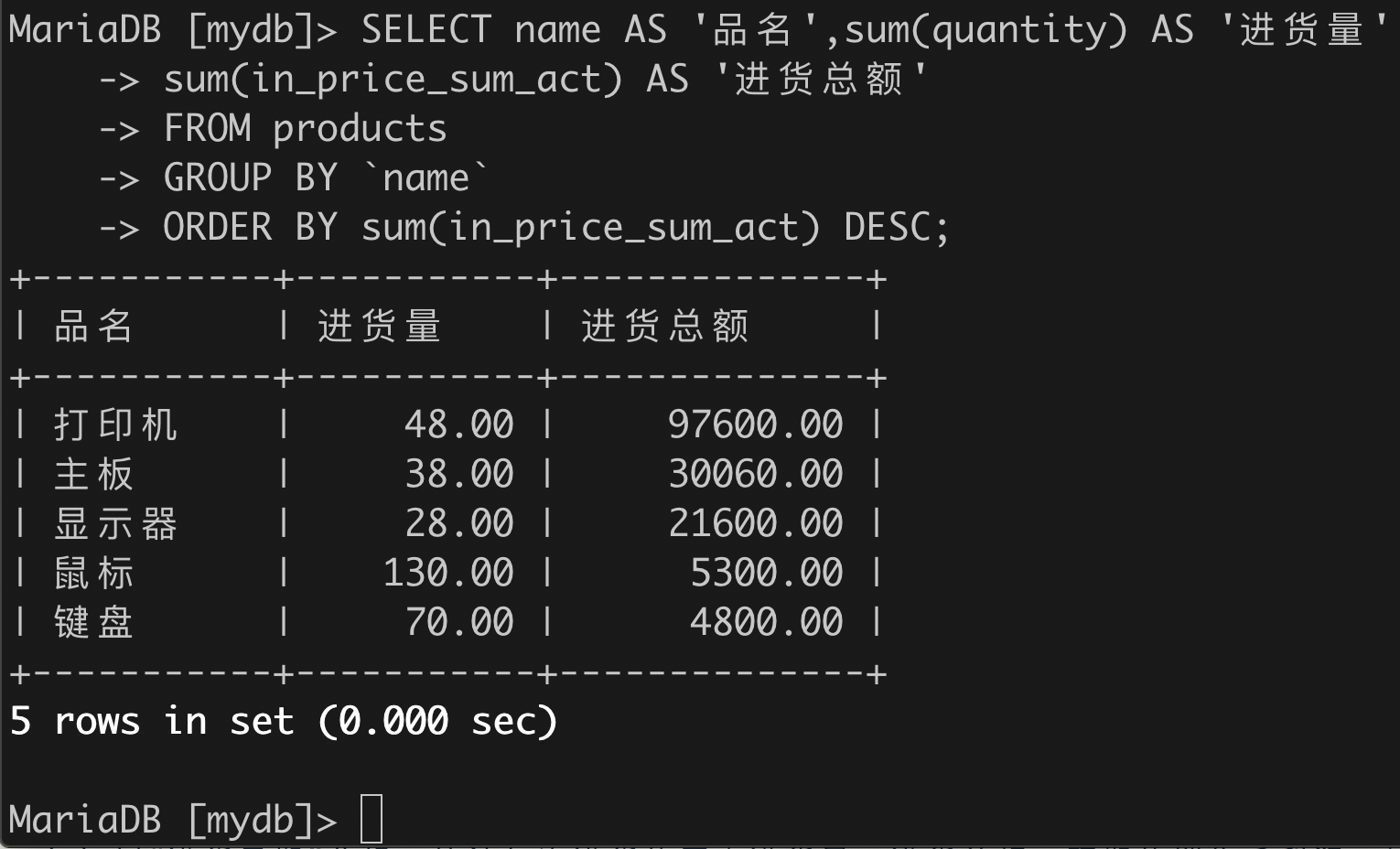
(1)以“品名”分组,统计各种商品的历史进货量、进货总额,按总额从高到低排序;
SELECT name AS '品名',SUM(quantity) AS '进货量',SUM(in_price_sum_act) AS '进货总额'FROM productsGROUP BY `name`ORDER BY SUM(in_price_sum_act) DESC;
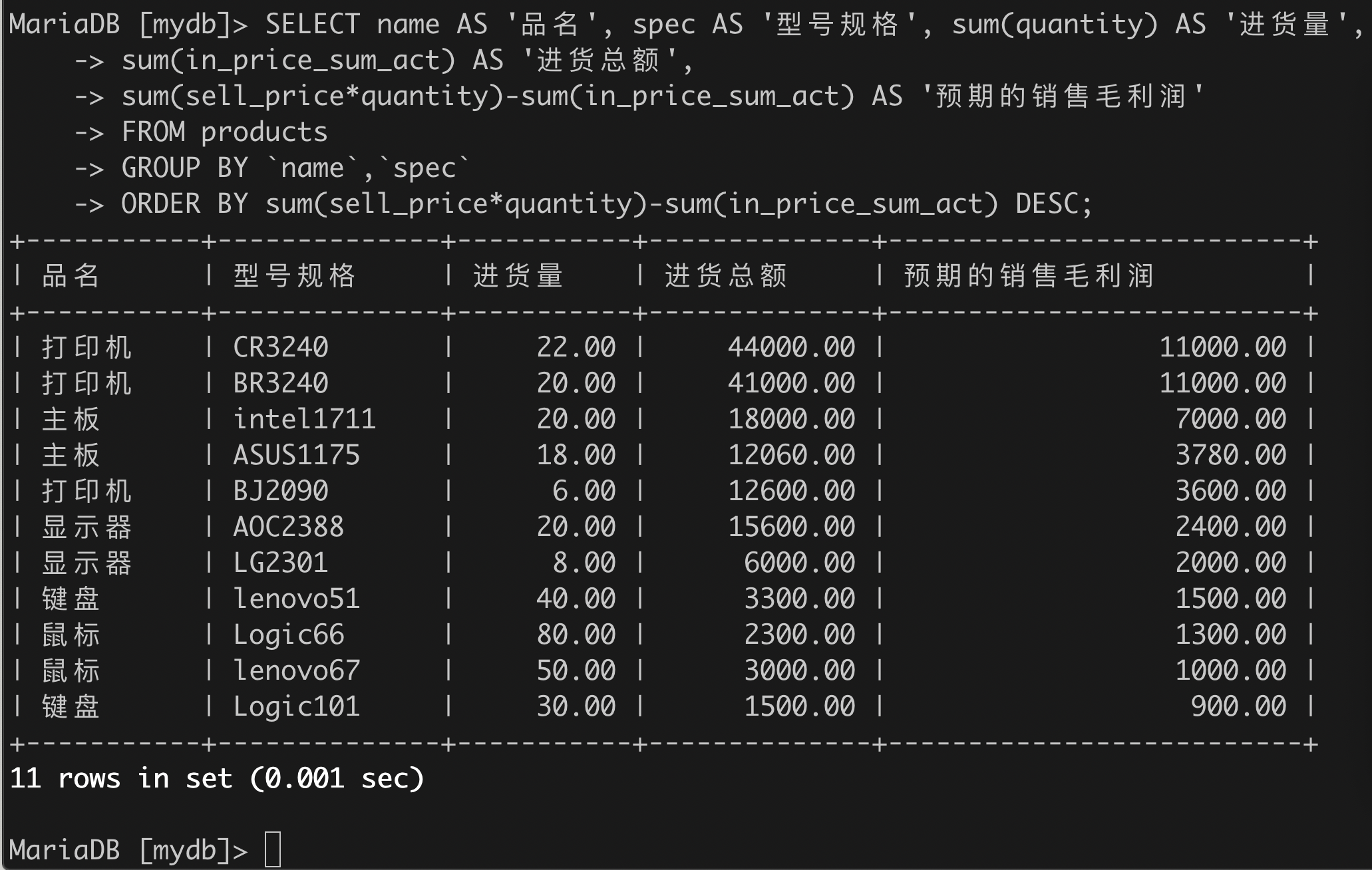
(2)以“品名”和“型号规格”分组,统计各种商品的历史进货量、进货总额、预期的销售毛利润,按毛利润从高到低排序;
SELECT name AS '品名', spec AS '型号规格', sum(quantity) AS '进货量',sum(in_price_sum_act) AS '进货总额',sum(sell_price*quantity)-sum(in_price_sum_act) AS '预期的销售毛利润'FROM productsGROUP BY `name`,`spec`ORDER BY sum(sell_price*quantity)-sum(in_price_sum_act) DESC;
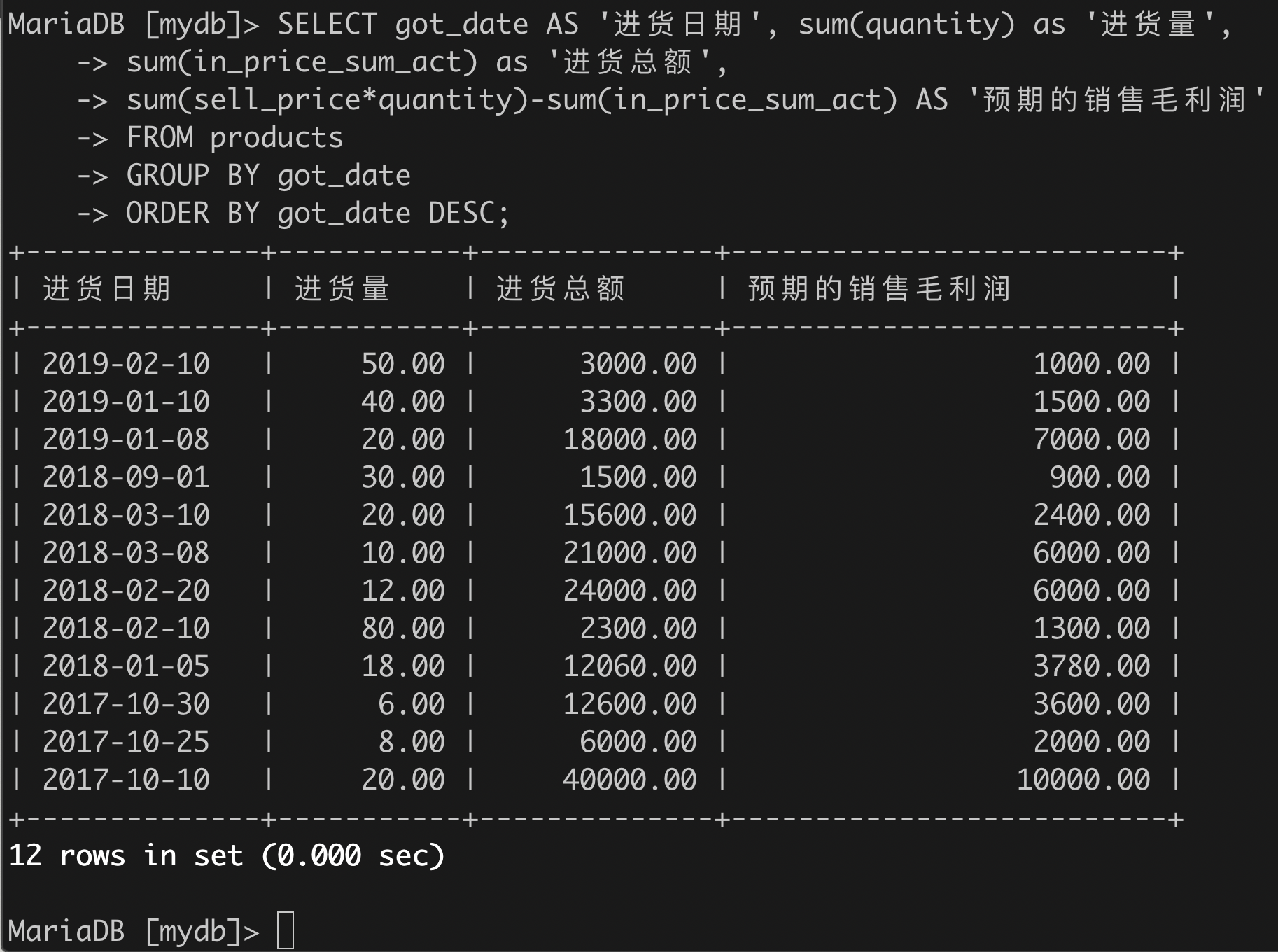
(3)以“进货日期”分组,统计每次进货的历史进货量,进货总额,预期的销售毛利润,按日期从近到远排序;
SELECT got_date AS '进货日期', sum(quantity) as '进货量',sum(in_price_sum_act) as '进货总额',sum(sell_price*quantity)-sum(in_price_sum_act) AS '预期的销售毛利润'FROM productsGROUP BY got_dateORDER BY got_date DESC;
6、HAVING 条件
在使用 GROUP BY 分组统计中,可用 HAVING 指定带聚合函数的条件。
举例:
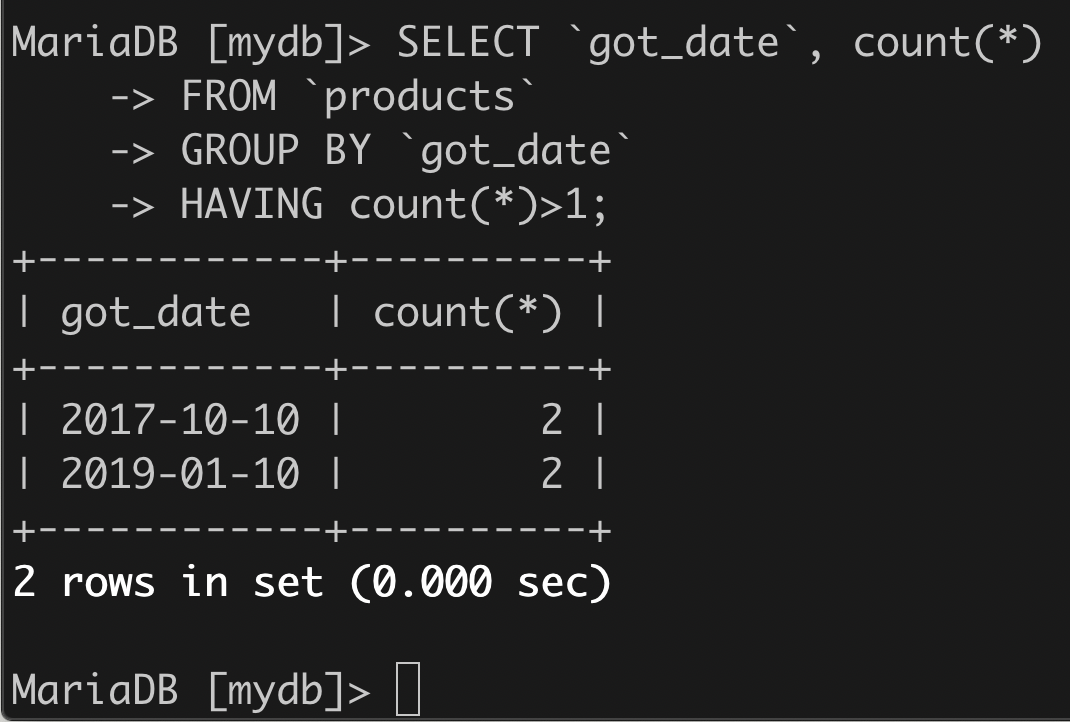
(1)哪些日子进货项超过1项?
SELECT `got_date`, count(*)FROM `products`GROUP BY `got_date`HAVING count(*)>1;
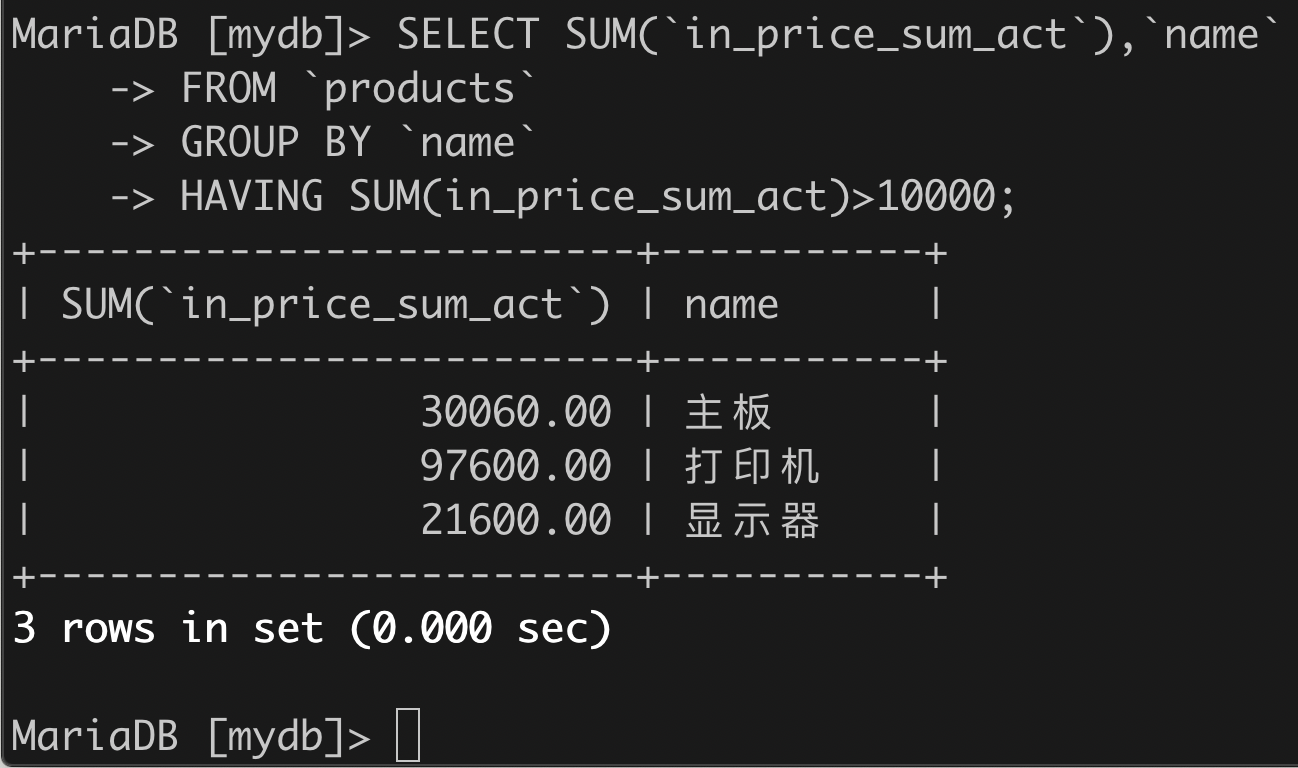
(2)按品名分组,列出实际进货总额之和大于10000元的商品。
SELECT SUM(`in_price_sum_act`),`name`FROM `products`GROUP BY `name`HAVING SUM(in_price_sum_act)>10000;
- 7、LIMIT 和 OFFSET
- LIMIT
- 指定返回的记录条数。
- OFFSET
- 指定越过多少条记录开始获取。
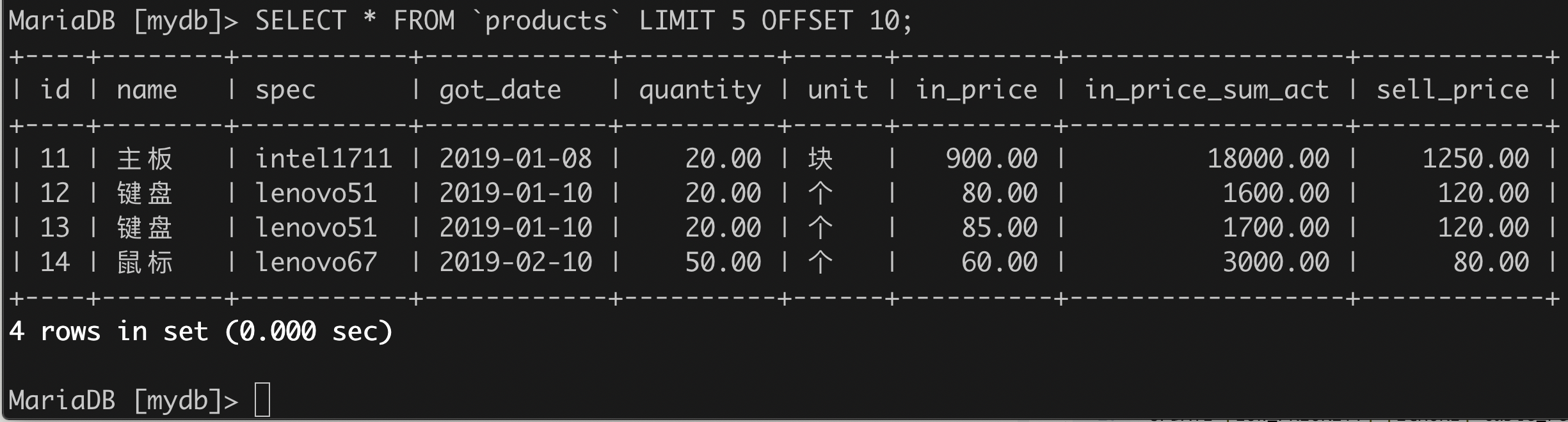
举例:按页获取记录,每页5条,现在请获取第3页的记录。
SELECT * FROM `products`LIMIT 5 OFFSET 10;
3.2.4 修改数据
参见:https://mariadb.com/kb/en/library/update/
基本语法:
UPDATE [LOW_PRIORITY] [IGNORE] table_reference[PARTITION (partition_list)]SET col1={expr1|DEFAULT} [,col2={expr2|DEFAULT}] ...[WHERE where_condition][ORDER BY ...][LIMIT row_count]
- LOW_PRIORITY
- 对于表级锁的数据库引擎,更新将推迟到没有用户在读取数据后执行。
- IGNORE
- 即使更新过程发生错误,也不要停止。
- WHERE
- 过滤条件,只更新符合条件的记录。
- ORDER BY
- 如果指定,按此顺序进行更新。
- LIMIT
- 限制更新的行数
3.2.5 删除数据
参见:https://mariadb.com/kb/en/library/delete/
第四部分、数据表的规范化
设计数据库表时,首先要考虑的是数据表的规范化问题。
4.1 什么是数据表的规范化?
就是让数据库管理系统中表的设计满足一定要求——不要让同一信息数据在多个地方重复存储,避免出现数据不一致;不要让关联的表发生参照失败,避免出现数据的不完整,同时还要顾及数据的处理效率。
为了做到这一点,数据库表应当至少做到第三级规范标准,即第三范式。前两级分别是第一、第二范式。
将表的设计从满足第一级规范开始逐级满足到一定范式(通常第三范式就足够了),就是数据表的规范化。
下面分别来讲解三个范式。
4.2 第一范式
4.2.1 第一范式的要求
第一范式要求:
1. 不要有完全相同的行;
2. 每个单元格只能有唯一值;
3. 每个单元格的值应当具有原子性(足够细致,不可再细化);
4. 每一列的所有单元格里的数据类型一致;
5. 列的顺序无关紧要。
不要着急,我们慢慢解读。
4.2.2 不要有完全相同的行
为什么?废话,不解释。
如何解决?找出表格中确定具有唯一值(不可能在多行出现重复值)的一列。如果没有这样的一列,那就要找出组合起来可以确定具有唯一性的几列。如果再找不出来,说明设计有缺陷,需要去找出这样的列或几列加入到表的结构中。
4.2.3 每个单元格只能有唯一值
“每个单元格只能有唯一值”,就是说,不要想在一个地方(单元格)放太多东西(多值),计算机并没有聪明到能够很好地处理杂乱无章的东西。比如,某公司需要记录员工信息如下(需求:记录员工所有电话,但员工必须有且只记录一个属于自己的电邮):
| 姓名 | 性别 | 出生年月 | 联系电话 | 电邮 |
|---|---|---|---|---|
| 王小二 | 男 | 1998-01-29 | 129 0909 1223, 130 1010 1234, 0871-87876666 |
wanggang@theserver.com |
现在联系电话一栏就有多个电话,计算机要处理查找电话就非常不便(花费太多的时间或者因数据不规范而变得不可能)。
如何解决?
4.2.3.1 多值转多列?
不要试图在列上解决多值问题(如下表),因为到底可能有多少值,事先是不知道的。因为有更多值,就去改变表的结构?所有用你数据库的人都会说:“你杀了我吧!” —— 他们如果要获得所有电话,程序就要改写!
| 姓名 | 性别 | 出生年月 | 联系电话1 | 联系电话2 | 联系电话3 | 电邮 |
|---|---|---|---|---|---|---|
| 王刚 | 男 | 1998-01-29 | 129 0909 1223 | 130 1010 1234 | 0871-87876666 | wanggang@theserver.com |
4.2.3.2 多值转多行?
不要试图把多值变多行(如下表),那会带来太多的重复数据。重复数据的危害是:同一数据到处存,可能造成数据不一致!比如我的姓名有的地方是王小二,有的地方可能是王二小,以谁为准?这就是数据不一致导致的问题,而这正是数据表规范化所要避免的。
| 姓名 | 性别 | 出生年月 | 联系电话 | 电邮 |
|---|---|---|---|---|
| 王小二 | 男 | 1998-01-29 | 129 0909 1223 | wanggang@theserver.com |
| 王小二 | 男 | 1998-01-29 | 130 1010 1234 | wanggang@theserver.com |
| 王二小 | 男 | 1998-01-29 | 0871-87876666 | wanggang@theserver.com |
4.2.3.3 多值的正确解决办法
拆分表格——把多值取出来,放到一个新表里。我们先来试试:
员工信息表
| 姓名 | 性别 | 出生年月 | 电邮 |
|---|---|---|---|
| 王小二 | 男 | 1998-01-29 | wanggang@theserver.com |
电话表
| 电话 | 属于 |
|---|---|
| 129 0909 1223 | ? |
| 130 1010 1234 | ? |
| 0871-87876666 | ? |
拆分表格需要建立相互之间的联系,否则数据就出现了不完整性(记住,重复数据会导致数据不一致,表格失去关联就会导致数据不完整!比如:这电话是谁的?)。我们来考虑电话属于谁怎么建立——填姓名?可能会有另外一个王小二(同名同姓)。填性别/出生年月?你也知道这简直是搞笑吧?看业务需求说,每个员工“必须有且只记录一个属于自己的电邮”,所以,这里填电邮是绝对没问题的。
| 电话 | 属主电邮 |
|---|---|
| 129 0909 1223 | wanggang@theserver.com |
| 130 1010 1234 | wanggang@theserver.com |
| 0871-87876666 | wanggang@theserver.com |
在这里,员工表信息里的“电邮”具有唯一性,从而能够保证没有任意两行记录完全相同。这一列就叫“主键列”,而电话表里的“属主电邮”指出了电话号码属于谁,参照的是员工信息表的主键,它叫做“外键”。
主键的改进。主键的选择原则:(1)主键应当具有唯一值;(2)主键应当极少需要改变(否则参照关系就需要更新,这可能是一项繁重的任务,当参照它的外键很多的时候)。在员工信息表中,“电邮”虽然具有唯一性,但却具有被改动的可能性。解决办法:添加一列流水号列(流水号没有被改动的需要),作为主键,电邮成为“候选键”(可做主键但未做),然后在建表建立约束时,对它建立唯一约束。而对于“电话表”来说,一个属主可能有多个电话,而一个电话可能有多个属主(比如在同一个办公室的员工,具有相同的办公电话),但“电话”和“属主电邮”组合必须唯一(别忘了第1条:“不要有完全相同的行”),因此二者组合就是主键。但通常为了处理上的高效,我们会用一个流水号列做主键,而把它们的组合约束为唯一。
应当注意的是,用流水号做主键,目的是让数据库系统处理参照时尽可能高效。由于流水号并不具有事务上的意义,所以要保证至少还要有候选键列的存在,否则记录仍然会有不确定性。如:
| 编号(流水) | 姓名 | 性别 | 出生年月 |
|---|---|---|---|
| 1 | 李丹 | 女 | 1980-12-30 |
| 2 | 李丹 | 女 | 1980-12-30 |
此表因流水号的存在,符合第一范式要求,但这两列记录是否重复?有可能,但因流水号的存在掩盖了数据的重复。
但是:
| 编号(流水) | 姓名 | 性别 | 出生年月 | 身份证号 |
|---|---|---|---|---|
| 1 | 李丹 | 女 | 1980-12-30 | 530103198012300026 |
| 2 | 李丹 | 女 | 1980-12-30 | 530552198012300022 |
有了一列候选键列“身份证号”,只要“身份证号”不同,就知道这其实是两个不同的人。事实上,因为给“身份证号”加了唯一约束,“身份证号”就被保证不会重复了。
回到我们的员工表和电话表,主键改进后:
员工信息表(候选键:电邮)
| 员工编号 | 姓名 | 性别 | 出生年月 | 电邮 |
|---|---|---|---|---|
| 1 | 王小二 | 男 | 1998-01-29 | wanggang@theserver.com |
电话表(候选键:电话+员工编号)
| 编号(流水) | 电话 | 员工编号 |
|---|---|---|
| 1 | 129 0909 1223 | 1 |
| 2 | 130 1010 1234 | 1 |
| 3 | 0871-87876666 | 1 |
这回就以流水号作为主键,主外键关系就能保证很稳固了。
4.2.4 每个单元格的值应当具有原子性(足够细致,不可再细化)
是否具有原子性,要看具体的事务需求。如果有需要处理姓氏的需求,则下表的“姓名”一列就不够原子性。
员工信息表(候选键:电邮)
| 员工编号 | 姓名 | 性别 | 出生年月 | 电邮 |
|---|---|---|---|---|
| 1 | 王小二 | 男 | 1998-01-29 | wanggang@theserver.com |
需要做如下改进:
员工信息表(候选键:电邮)
| 员工编号 | 姓 | 名 | 性别 | 出生年月 | 电邮 |
|---|---|---|---|---|---|
| 1 | 王 | 小二 | 男 | 1998-01-29 | wanggang@theserver.com |
| 2 | 欧 | 阳明 | 男 | 1997-10-01 | ouyangming@theserver.com |
| 3 | 欧阳 | 明 | 男 | 1995-02-16 | ouyangming216@theserver.com |
4.2.5 每一列的所有单元格里的数据类型一致
这也是显而易见的,不用多说。
4.2.6 列的顺序无关紧要
就是说,列的顺序并不影响对记录的描述。也就是说,表的列之间,并不存在某种排列关系。它们只是描述一个事物的各个属性的组合,不会因为属性排列的先后就导致所描述的对象有所不同。难懂吧?其实你想要违反还真不容易!不懂就先搁着,不会影响后续学习。
4.2.7 满足第一范式的要点总结
- 表要有主键;
- 多值列抽取出来存到另一张表,两表建立参照关系;
- 列的原子性由事务需求决定。
4.3 第二范式
4.3.1 第二范式的要求
第二范式就两条:
1. 要满足第一范式;
2. 不要有部分依赖。
我们仍然用通俗的话来讲。
4.3.2 不要有部分依赖
4.3.2.1 部分依赖的含义
先看着张表:
员工工作量统计
| 员工编号 | 员工姓名 | 员工性别 | 项目编号 | 项目名称 | 项目地址 | 工时数 |
|---|---|---|---|---|---|---|
| 1 | 李明 | 男 | 3 | 昆明正通大厦装修设计 | 昆明市正通路23号 | 220 |
| 2 | 张灵 | 女 | 3 | 昆明正通大厦装修设计 | 昆明市正通路23号 | 100 |
| 1 | 李明 | 男 | 5 | 安宁镜湖小区绿化规划 | 安宁市明日路99号 | 120 |
我们看到了重复数据,怎么来的?
这是一张员工工作量统计表,与员工和项目相关。但我们看到“员工编号”和“项目编号”都有重复值,不可能单独做主键。但二者的组合必须唯一,否则就会出现相同的行或错误的行。因此二者组合为唯一组合候选键列(可做主键的列)。
所谓部分依赖,是指表中有的列只依赖于组合候选键中的部分列(或者说只决定于组合候选键中的部分列)。
我们考察这张表,“员工姓名”和“员工性别”,只决定于"员工编号”,与“项目编号”无关;“项目名称”和“项目地址”只决定于“项目编号”,于“员工编号”无关。这些都是“部分依赖”。
4.3.2.2 解决办法
出现部分依赖,是因为试图在涉及多个关联事物的一张表中描述只属于单个事物的属性,从而出现了大量不合理的重复数据。为了不丢失这些属性,采用拆分表的办法解决重复数据问题。
员工工作量统计
| 员工编号 | 项目编号 | 工时数 |
|---|---|---|
| 1 | 3 | 220 |
| 2 | 3 | 100 |
| 1 | 5 | 120 |
员工信息
| 员工编号 | 姓名 | 性别 |
|---|---|---|
| 1 | 李明 | 男 |
| 2 | 张灵 | 女 |
项目信息
| 项目编号 | 名称 | 地址 |
|---|---|---|
| 3 | 昆明正通大厦装修设计 | 昆明市正通路23号 |
| 5 | 安宁镜湖小区绿化规划 | 安宁市明日路99号 |
4.3.3 满足第二范式的要点总结
把只依赖部分主键的列抽取,放到另一张表,两表建立参照关系。
4.4 第三范式
4.4.1 第三范式要求
- 满足第二范式
- 不要有传递依赖
我们来看看怎么说。
4.4.2 传递依赖
表中有的列并不直接依赖于主键,而是依赖其它直接依赖于主键的列。
4.4.2.1 什么是传递依赖
我们用实例看一下。
| 产品编号 | 产品名称 | 型号规格 | 厂商 | 厂商电话 | 厂商地址 |
|---|---|---|---|---|---|
| P0001 | 打印机 | Brother 23 | 浙江天地科技公司 | 0570-98767898 | 浙江台洲某大道133号 |
| P0002 | 显示器 | LG 2876 | 天津LG分厂 | 022-76767890 | 天津市滨江大道77号 |
| P0003 | 路由器 | 7685 | 浙江天地科技公司 | 0570-98767898 | 浙江台洲某大道133号 |
在这张表中,“产品编号”是主键。“厂商”直接与“产品编号”有关(浙江天地科技公司生产的 Brother 23 打印机,编号为 P0001 ,而不是电话号码是 0570--98767898 的拥有者生产的 Brother 23 打印机,编号为 P0001 ,因为电话号码可能被改变,地址也是如此),但“厂商电话”、“厂商地址”却只与“厂商”有关。这就是传递依赖。
另一个实例。
| 员工编号 | 发放年月 | 应发 | 应扣 | 实发 |
|---|---|---|---|---|
| E001 | 2018-05 | 7800 | 600 | 7200 |
“实发”依赖于“应发”和“应扣”,而“应发”和“应扣”依赖于“员工编号”和“发放年月”(组合主键),这也是一种传递依赖。事实上,“实发”是一个可由其它计算出来的列。
4.4.2.2 解决办法
第一种情况拆分表格。
| 产品编号 | 产品名称 | 型号规格 | 厂商编号 |
|---|---|---|---|
| P0001 | 打印机 | Brother 23 | M001 |
| P0002 | 显示器 | LG 2876 | M002 |
| P0003 | 路由器 | 7685 | M001 |
| 厂商编号 | 厂商 | 厂商电话 | 厂商地址 |
|---|---|---|---|
| M001 | 浙江天地科技公司 | 0570-98767898 | 浙江台洲某大道133号 |
| M002 | 天津LG分厂 | 022-76767890 | 天津市滨江大道77号 |
第二种情况,直接删除计算列。
| 员工编号 | 发放年月 | 应发 | 应扣 |
|---|---|---|---|
| E001 | 2018-05 | 7800 | 600 |
4.4.3 满足第三范式的要点总结
- 对于通过传递依赖主键的非计算列,抽取出来到另一张表,两表建立参照关系。
- 对于计算列,直接干掉!
第五部分 复杂数据的存储规划
5.1 表间关系的多重性
5.2 数据实体建模
5.2.1 实体及其属性
5.2.2 实体间关系
5.3 数据字典
5.3.1 根据实体关系图(ER)编写数据字典
5.3.2 根据数据字典编写建表 SQL 脚本
5.3.3 表间关系撕裂的规则
5.4 高级话题
5.4.1 触发器
5.4.2 存储过程
5.4.3 自定义函数
5.4.4 视图
第六部分、数据库应用案例
6.1 待办事宜(难度:1,最高:5)
6.1.1 问题描述
某待办事宜管理应用,需要用数据库存储数据。数据包含:事项名称、截止日期、办理状态、完成日期,应用对数据处理的要求可描述如下:
1. 可根据关键词、办理状态、完成日期等查找待办事项;
2. 可统计已完成的事项数目;
3. 可统计未完成的事项数目;
4. 可统计已过截止日期,但仍未办理的事项数目;
5. 可列出已过截止日期,但仍未办理的事项(含过期天数),按过期天数进行降序排序;
6. 可列出未过截止日期,未办理的事项数目;
7. 可列出未过截止日期,未办理的事项(含距截止日期的天数),按距截止日期的天数进行升序排序。
请画出ER图,建立数据字典,并完成定义数据库和表的SQL脚本;建立表后插入样例数据,对以上数据处理要求写出对应的SQL语句。
6.1.2 分析与建模
根据以上问题描述,可找出一个数据实体:待办事宜。属性为:事项名称、截止日期、办理状态、完成日期。可用 E-R 图表示如下:
6.1.3 数据字典
| 序号 | 列名 | 含义 | 数据类型 | 可为空 | 默认值 | 键 | 其它 |
|---|---|---|---|---|---|---|---|
| 1 | id | 编号 | INT UNSIGNED | 主键 | 自动增长 | ||
| 2 | task_name | 事项名称 | VARCHAR(100) | ||||
| 3 | due_date | 截止日期 | DATE | ||||
| 4 | done | (完成状态)已完成 | CHAR(1) | 'F' | |||
| 5 | done_date | 完成日期 | DATE | ✔ |
6.1.4 建库脚本
DROP DATABASE IF EXISTS task_db;CREATE DATABASE IF NOT EXISTS task_db DEFAULT CHARSET utf8mb4;USE task_db;CREATE TABLE tasks (`id` INT UNSIGNED NOT NULL AUTO_INCREMENT,`task_name` VARCHAR(100) NOT NULL,`due_date` DATE NOT NULL,`done` CHAR(1) NOT NULL DEFAULT 'F',`done_date` DATE,PRIMARY KEY (`id`));
6.1.5 插入样例数据
利用 NodeJS 平台进行样例数据插入。
var faker = require("faker");const mysql = require("mysql2");const conn = mysql.createConnection({host: "localhost",user: "root",password: "",database: "task_db"});var sql = "INSERT INTO tasks (task_name,due_date,done,done_date) VALUES ?";faker.locale = "zh_CN";var data = [];Date.prototype.addDays = function(days) {var date = new Date(this.valueOf());date.setDate(date.getDate() + days);return date;};for (let i = 0; i < 50; i++) {d = [];d.push(faker.lorem.words(faker.random.number({ min: 3, max: 8 })));var due = faker.date.between("2019-01-01", "2019-08-30");d.push(due);var finished = faker.random.arrayElement(["F", "T", "T", "T", "T"]);d.push(finished);if (finished == "T") {d.push(faker.date.between(new Date(due).addDays(-5), new Date(due).addDays(5)));} else {d.push(null);}data.push(d);}console.log(data.length);conn.query(sql, [data], function(err) {if (err) throw err;conn.end();});
6.1.6 数据操作
1、 可根据关键词、办理状态、完成日期等查找待办事项;
SELECT * FROM `tasks` WHERE `task_name` like '%关键词%';SELECT * FROM `tasks` WHERE `done`='T';SELECT * FROM `tasks` WHERE `done_date` BETWEEN '2019-06-01' AND '2019-06-03';
2、可统计已完成的事项数目;
SELECT COUNT(*) FROM `tasks` WHERE `done`='T';
3、可统计未完成的事项数目;
SELECT COUNT(*) FROM `tasks` WHERE `done`='F';
4、可统计已过截止日期,但仍未办理的事项数目;
SELECT COUNT(*) FROM `tasks` WHERE `done`='F' AND `due_date`<NOW();
5、可列出已过截止日期,但仍未办理的事项(含过期天数),按过期天数进行降序排序;
SELECT *, DATEDIFF(NOW(),due_date) as `passed_days` FROM `tasks` WHERE `done`='F' AND `due_date`<NOW() ORDER BY `passed_days` DESC;
6、可列出未过截止日期,未办理的事项数目;
SELECT COUNT(*) FROM `tasks` WHERE `done`='F' and due_date>NOW();
7、可列出未过截止日期,未办理的事项(含距截止日期的天数),按距截止日期的天数进行升序排序。
SELECT *, DATEDIFF(due_date, NOW()) as `left_days` FROM `tasks` WHERE `done`='F' and due_date>NOW() ORDER BY `left_days`;
6.2 员工管理(难度:2,最高:5)
6.2.1 问题描述
某公司需要用数据库存储员工数据,涉及的数据包含:部门名称、部门电话、部门地址、员工姓名、身份证号、性别、出生日期、年龄、学历、雇佣日期、解雇日期、职位等。在公司内部,每个员工只能在一个部门。对数据处理的要求:
1. 可按部门统计当前员工数目;
2. 可按姓名查找员工,并列出其所有信息以及所在部门的名称;
3. 可按年龄统计当前员工数目;
4. 可按性别统计当前员工数据;
5. 可按学历统计当前员工数目;
6. 可列出某一部门的全体当前员工;
请画出ER图,建立数据字典,并完成定义数据库和表的SQL脚本;建立表后插入样例数据,对以上数据处理要求写出对应的SQL语句。
6.2.2 分析与建模
6.2.3 数据字典
6.2.4 建库脚本
6.2.5 插入样例数据
6.2.6 数据操作
6.3 项目薪酬统计(难度:2,最高:5)
6.3.1 问题描述
某公司需要记录员工在项目上的业绩(工时数衡量),数据包括:员工姓名、性别、职称、项目名称、工时数、单位工时薪酬、薪酬等。其中,『单位工时薪酬』由职称确定,目前为:助理工程师 - 300元,工程师 - 500元,高级工程师 - 800元。对以上数据的处理要求为:
1. 按项目统计应发的薪酬总额,按薪酬总额降序排序;
2. 按员工统计获得的薪酬总额,按薪酬总额降序排序;
3. 按姓名查找员工并列出其所参与的所有项目及薪酬;
4. 按名称查找项目并列出其所有参与者的信息及薪酬;
5. 列出薪酬总额超出10000元的工程项目,并按总额降序排序。
请画出ER图,建立数据字典,并完成定义数据库和表的SQL脚本;建立表后插入样例数据,对以上数据处理要求写出对应的SQL语句。
6.3.2 分析与建模
6.3.3 数据字典
6.3.4 建库脚本
6.3.5 插入样例数据
6.3.6 数据操作
6.4 商品管理(难度:3,最高:5)
6.4.1 需求描述
某商店需要管理商品,并将商品进行了分类(分类没有级别限制)。数据包括:类别名称、商品名称、型号规格、数量、单价、金额小计等。对数据的处理要求为:
1. 能够列出所有顶级分类;
2. 能够列出所有底级分类;
3. 能够列出某一分类下的下一级分类;
4. 能够列出所有分类,包含名称和路径(诸如:『电器类>家用电器>厨房电器>...』);
5. 能够列出某个分类下在全部子分类,包含名称和路径(诸如:『家用电器>厨房电器>...』);
6. 可从某一子类开始,列出其上一级分类,直至顶级分类;
7. 可列出各个分类的下一级子分类的数目;
8. 列出某一分类及其所有下级子分类包含的所有商品。
6.4.2 分析与建模
6.4.3 数据字典
6.4.4 建库脚本
6.4.5 插入样例数据
6.4.6 数据操作
6.5 商品销售(难度:4,最高:5)
6.5.1 需求描述
某商店需要管理商品和销售,对商品和分类的管理如上题,商品增加进货价。现商店需要管理销售,涉及的数据包括客户、开票人、销售日期、商品明细等。对数据的处理增加如下:
1. 可按开票员统计历史销售总金额;
2. 可按客户统计历史购买额;
3. 可按商品统计历史销售额;
4. 可查询一定历史时期内某项商品的各年度(或各季度或各月)的销售情况;
5. 可按年度(季度或月份)统计各种商品的毛利润。
5.5.2 分析与建模
5.5.3 数据字典
5.5.4 建库脚本
5.5.5 插入样例数据
5.5.6 数据操作
6.6 学院管理(难度:5,最高:5)
6.6.1 需求描述
某学院含多个管理部门和教学系部,教学系部下设多个专业,各专业有不同入学年份的各个班级,每个班级都有一名教职员工担任班主任(一名员工可同时承担多个班级的班主任)。每个部门下有教职员工,每个教职员工只隶属于一个部门。各专业有特定计划课程,一名老师(含外聘)可承担多门课程的教学任务。学生的各科成绩要得到记录。学生在校期间的操行情况也要得到记录。预先考虑到的数据处理包括:
1. 可查询某部门下的所有员工;
2. 可统计学院各类职称的人员分布;
3. 可查看某专业的课程;
4. 可统计各班主任所负责的班级数;
5. 可查看每个学生的操行情况;
6. 可列出每个学生的各科课程成绩;
7. 可列出某专业的全部班级;
8. 可列出某位教师所担任的全部课程;
9. 可列出某部门负责的全部专业。
