@Yano
2018-05-31T08:45:40.000000Z
字数 2677
阅读 2358
Google Protocol Buffers 序列化算法分析
Java
分析一下 Google Protocol Buffers 的序列化原理。介绍参考 Google Protocol Buffers 数据交换协议
说明
详细介绍参见官方文档
编写 proto 文件
定义了4个变量 a, b, c, d,其 Field 分别为 1~4。为了展示不同类型的序列化原理,将变量分别定义成 int32, int64, fixed64, 'string'。
option java_outer_classname = "YanoTestProbuf";message YanoTest{optional int32 a = 1;optional int64 b = 2;optional fixed64 c = 3;optional string d = 4;}
测试字节码
@Testpublic void testProtoBuf() {// encode bytesbyte[] bytes = YanoTest.newBuilder().setA(1).setB(2).setC(3).setD("java").build().toByteArray();System.out.println(Arrays.toString(bytes));// decode bytesfor (byte b : bytes) {System.out.println(getBinString(b));}}private String getBinString(byte b) {return String.format("%8s", Integer.toBinaryString(b)).replace(' ', '0');}
生成的字节码
[8, 1, 16, 2, 25, 3, 0, 0, 0, 0, 0, 0, 0, 34, 4, 106, 97, 118, 97]
每个字节转换成二进制为:
00001000000000010001000000000010000110010000001100000000000000000000000000000000000000000000000000000000001000100000010001101010011000010111011001100001
让我们分析下这些字节码~~~^_^
分析字节码
首先要明确,Protocol Buffers 序列化的字节码是很紧凑的,而且是 key-value 的形式:
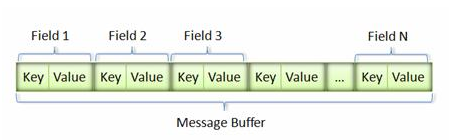
其中一个 key-value 就是一个 Field,就是定义的 abcd~
key 都是一个字节,以第一个 key 00001000 为例,key 有两个含义:
(field_number << 3) | wire_type
5 位 field_number + 3 位 wire_type,其中 wire_type 如下:
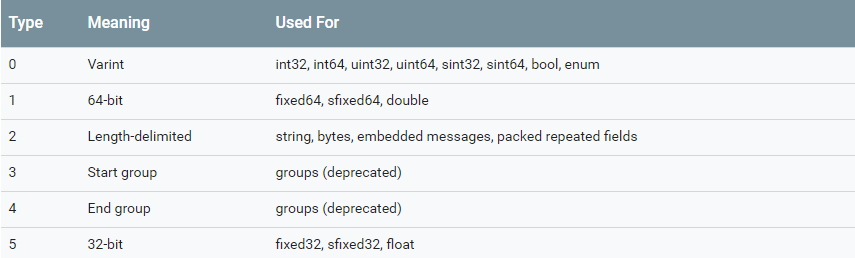
varint
Varint 是一种紧凑的表示数字的方法。它用一个或多个字节来表示一个数字,值越小的数字使用越少的字节数。这能减少用来表示数字的字节数。
比如对于 int32 类型的数字,一般需要 4 个 byte 来表示。但是采用 Varint,对于很小的 int32 类型的数字,则可以用 1 个 byte 来表示。当然凡事都有好的也有不好的一面,采用 Varint 表示法,大的数字则需要 5 个 byte 来表示。从统计的角度来说,一般不会所有的消息中的数字都是大数,因此大多数情况下,采用 Varint 后,可以用更少的字节数来表示数字信息。下面就详细介绍一下 Varint。
Varint 中的每个 byte 的最高位 bit 有特殊的含义,如果该位为 1,表示后续的 byte 也是该数字的一部分,如果该位为 0,则结束。其他的 7 个 bit 都用来表示数字。因此小于 128 的数字都可以用一个 byte 表示。大于 128 的数字,比如 300,会用两个字节来表示:1010 1100 0000 0010
下图演示了 Google Protocol Buffer 如何解析两个 bytes。注意到最终计算前将两个 byte 的位置相互交换过一次,这是因为 Google Protocol Buffer 字节序采用 little-endian 的方式。
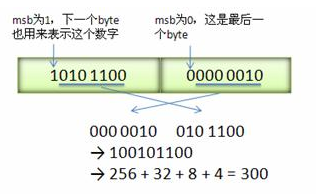
字段 a(int32)
第一个 key 00001000 的前 5 位是 1,表明是字段 a;后 3 位 wire_type 是 0,所以是 Varint(一种变长的数值类型,在表示小数值的数时更省空间)。
第一个 value 是 00000001,所以是 a = 1。
字段 b(int64)
key 00010000
field_number 2 b
wire_type 0 Varint
value 00000010 2
字段 c(fixed64,定长)
key 00011001
field_number 3 c
wire_type 1 64-bit
value 3 00000011
00000000
00000000
00000000
00000000
00000000
00000000
00000000
字段 d(string)
key 00100010
field_number 4 d
wire_type 2 Length-delimited
value java 00000100(length:4)
01101010 j
01100001 a
01110110 v
01100001 a
与 JSON 和 XML 序列化对比
JSON
上面的代码,用 JSON 来表示是这样的:
{"a":"1","b":"2","c":"3","d":"java"}
代码测试长度:
@Testpublic void testJSON() {String json = "{\"a\":\"1\",\"b\":\"2\",\"c\":\"3\",\"d\":\"java\"}";System.out.println(json.getBytes().length);}
结果是 36 个字节,而 protobuf 生成的字节码仅有 18 个字节。
说明:本例中的 protobuf 字段 c 使用了 fixed64 类型,否则还能够省 5 个字节。protobuf 还有一个非常明显的好处就是:长度与字段的名字无关。如果字段 a 叫做 apple,那么 protobuf 序列化后仍然是 18 个字节,而 JSON 则要增加 4 个字节。
XML
XML 就不必说了,ε=(´ο`*)))
Google Protocol Buffers 的一点思考
- 该协议开发过程确实有些繁琐,因为要编写 proto 文件,并生成对应语言的代码;同时因为是字节码,并不容易读取(需要将其转换成对象,打印对象)。如果要更改协议,需要频繁修改文件及代码。
- 但是正是因为这种约束,Protocol Buffers 具有非常强的版本兼容性。换做是 JSON,虽然很灵活,但是完全没有约束~~~
- Protocol Buffers 序列化的字节码非常非常小,速度很快,是游戏开发的首选。
