@Yano
2018-02-06T00:27:44.000000Z
字数 5853
阅读 3190
爬取北京摩拜单车信息(附分析过程和详细代码)
爬虫
目的
统计北京摩拜单车的数量、分布、类型等信息。
先贴出结果:

分析过程
Fiddler 抓包
去年11月份可以在微信中抓取摩拜的小程序,但是现在不行了。当时微信小程序的API很简陋,利用代理可以直接抓取。但是现在试下挂上代理小程序都打不开了。
后来使用摩拜的APP抓取成功,附图。

获取附近单车信息的接口是:http://app.mobike.com/api/nearby/v3/nearbyBikeInfo
同时 response 是个 json,解析出来是这样的:
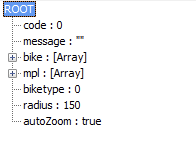
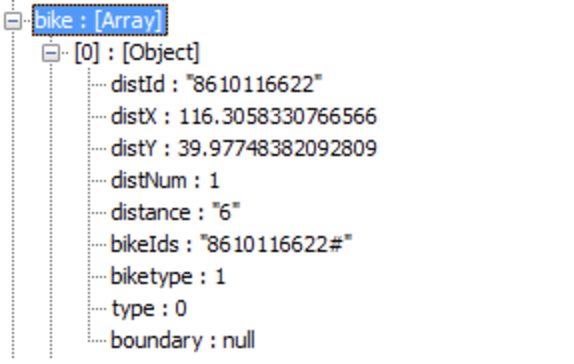
其中包括 bike 和 mpl 数组,bike 即为最终要获取的单车详细信息,结构如下:
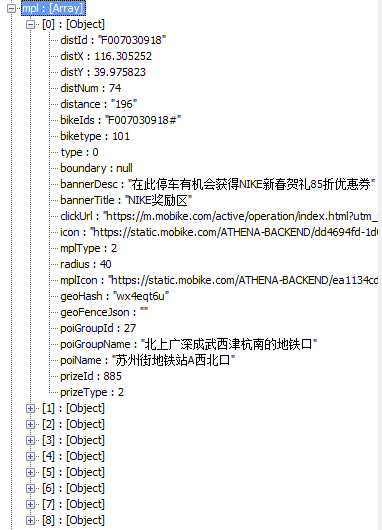
而 mpl 应该是摩拜推出的新功能,表示「停车地点」,在这些地点停车有机会获得 NIKE 新春贺礼 85 折优惠券,结构如下:
经纬度查询
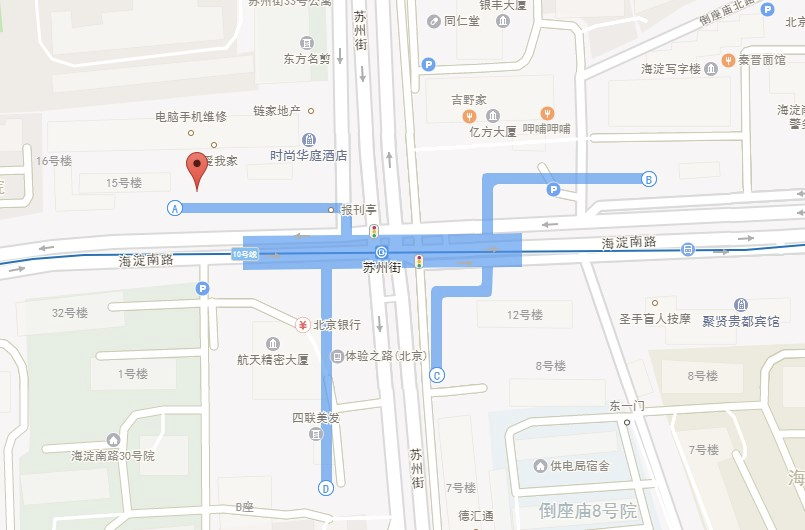
在 Fiddler 中抓取 request 发现纬度和经度分别为:39.977524,116.305863,通过经纬度查询的网站发现定位极其精准:
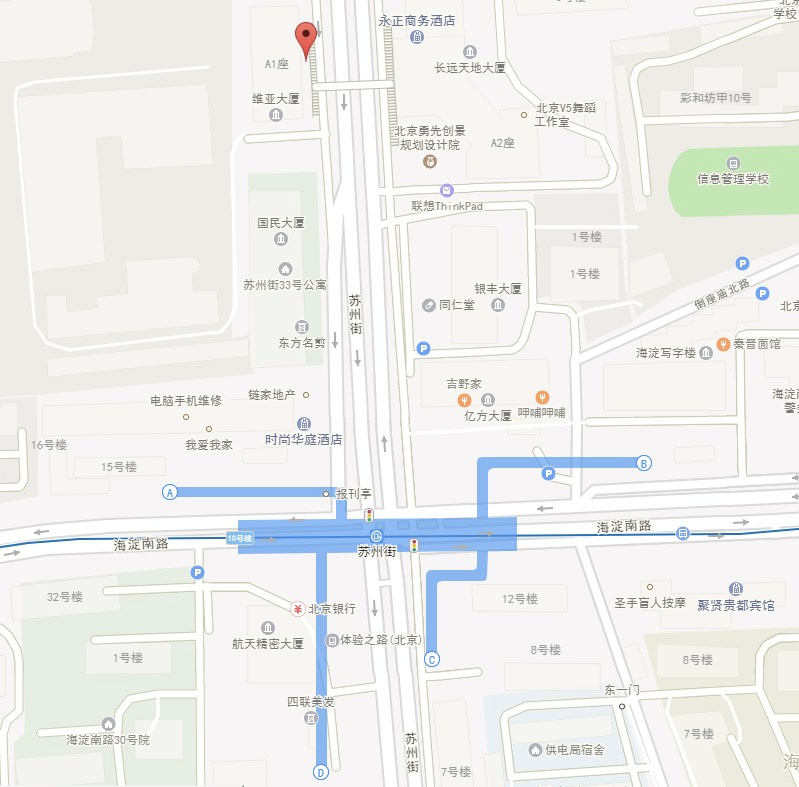
查询 response 中 mpl 信息的一个地址:39.975823, 116.305252
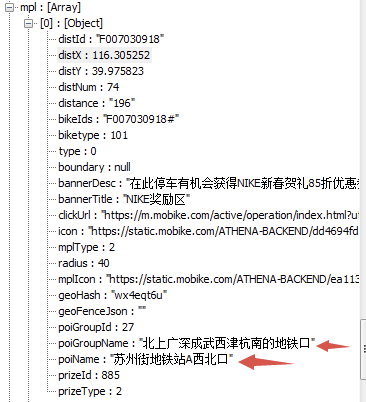
发现确实是地图上的位置:
Postman 验证
把请求参数放到 postman 中,发现能够直接给出结果:

通过调试发现 post 的几个重要参数作用如下:
- scope:爬取的范围,下面会分析;
- longitude:经度,可以精确到小数点后7位;
- latitude:纬度;
- bikenum:获取单车信息的最大数量,这个值设置大一点比较好,爬取更快;
- biketype:0应该是爬取所有类型。
经纬度与距离的换算
经纬度在不同地区,每度距离差是不同的,任意两点距离计算公式为
d=111.12cos{1/[sinΦAsinΦB十cosΦAcosΦBcos(λB—λA)]}
其中A点经度,纬度分别为λA和ΦA,B点的经度、纬度分别为λB和ΦB,d为距离.
所以可知每度大概为111千米
比如北京 B = 40、cosB = 0.766,经度变化1度,则东西方向距离变化 85.567km。
确定爬取范围
决定爬取北京五环内的摩拜单车数量,确定经纬度:
北四环西北 39.9777778168,116.2875366211
北四环东南 39.8401771328,116.4787673950
确定步长、单次爬取单车数量
这两个参数是相互影响的,单次步长越小,结果越精确,但是爬取时间就会更长;增大步长,增加单次爬取单车数量可以缩短时间,但是单位面积的单车数量并不是无限增大的。通过测试发现 scope 参数也不是可以无限增大,貌似到500就无效了。
我确定这两个参数的方法:在地图上找2个点,固定经度调节纬度,看两者爬取的单车是否有重复。
测试了4个地点:
十字路口1:
longitude=116.30581114680909&latitude=39.98106569393767
十字路口2:
longitude=116.30613220306786&latitude=39.978998558907335
维亚大厦:
longitude=116.30608720311963&latitude=39.97747017430741
苏州街十字路口:
longitude=116.30627577120181&latitude=39.975675035347415
发现纬度差0.003时,两次爬取结果会有33辆单车的重叠(每个点大约有180辆单车的信息)。确定经纬度移动的步长是0.003,而单次爬取单车数量为500(99%的地点都到不了500个单车)。
header 参数
发现 header 有很多参数,甚至还有 time 和 utctime 两个时间参数。摩拜会存取每个时刻单车的静态信息吗?显然不会,这样的存储成本太高了,通过程序验证确实是这样。对于其它参数,也可以自行验证。
代码
主体代码很简洁,就是 post 发送请求,每次在地图上移动0.003的经度或纬度,直至遍历完地图上的正方形。
@Testpublic void testGetMoBike() throws IOException {OkHttpClient client = new OkHttpClient();RequestBody body = RequestBody.create(GSON, "{}");double longitudeMin = 116.2875;double longitudeMax = 116.4787;double latitudeMin = 39.8402;double latitudeMax = 39.9778;double step = 0.003;for (double longitude = longitudeMin; longitude <= longitudeMax; longitude += step) {for (double latitude = latitudeMin; latitude <= latitudeMax; latitude += step) {// 获取对应经纬度的结果List<BikeDo> bikeDos = getBikeDos(client, body, longitude, latitude);// 将每辆单车信息都存入redisrestoreBikeInfo(bikeDos);// 随机休眠,防止被封sleepRandomSeconds(2);System.out.println("经度:" + longitude + " 纬度:" + latitude + " 结束,爬取总个数:" + jedis.hlen(MAP_KEY));}}}
使用 redis 的 map 存储结果并去重,并打印出每一步的信息。这样可以在断网等异常情况时,从异常处重新开始爬取。redis 在本机可以达到 10万次/s 的连接量,就没必要在 Java 中维护这些代码了。
其余代码如下(删除了个人相关的信息,所以代码不完整):
private static Jedis jedis = RedisUtil.getJedis();private static final String MAP_KEY = "mobike";private static final Random RANDOM = new Random();private void restoreBikeInfo(List<BikeDo> bikeDos) {for (BikeDo bikeDo : bikeDos) {// 将每一个 bike 存入 redis 中if (jedis.hexists(MAP_KEY, bikeDo.getDistId())) {continue;}jedis.hset(MAP_KEY, bikeDo.getDistId(), JSON.toJSONString(bikeDo));}}private void sleepRandomSeconds(int seconds) {try {Thread.sleep(RANDOM.nextInt(seconds) * 1000);} catch (InterruptedException e) {e.printStackTrace();}}private List<BikeDo> getBikeDos(OkHttpClient client, RequestBody body, double longitude, double latitude) throws IOException {Request request = createRequest(body, longitude, latitude);Response response = client.newCall(request).execute();String responseJson = response.body().string();JSONArray parse = (JSONArray) JSONObject.parseObject(responseJson).get("bike");return JSON.parseArray(parse.toJSONString(), BikeDo.class);}private Request createRequest(RequestBody body, double longitude, double latitude) {return new Request.Builder().url("http://app.mobike.com/api/nearby/v3/nearbyBikeInfo?scope=700&sign=&client_id=android&biketype=0&longitude=" + longitude + "&latitude=" + latitude + "&userid=&bikenum=600").post(body).addHeader("version", "6.7.1").addHeader("versioncode", "1649").addHeader("platform", "1").addHeader("mainsource", "4002").addHeader("subsource", "3").addHeader("os", "25").addHeader("lang", "zh").addHeader("time", DateTime.now().getMillis() + "").addHeader("country", "0").addHeader("eption", "685f8").addHeader("deviceresolution", "1080X1920").addHeader("utctime", DateTime.now().getMillis() / 1000 + "").addHeader("mobileno", "").addHeader("accesstoken", "").addHeader("uuid", "").addHeader("longitude", longitude + "").addHeader("latitude", latitude + "").addHeader("content-type", "application/x-www-form-urlencoded").addHeader("content-length", "203").addHeader("host", "app.mobike.com").addHeader("accept-encoding", "gzip").addHeader("user-agent", "okhttp/3.9.1").addHeader("connection", "Keep-Alive").addHeader("cache-control", "no-cache").addHeader("postman-token", "fc17ae5a-32e9-d2bb-eb1f-43dd6760aea6").build();}
bike 类:
public class BikeDo {private String distId;private double distX;private double distY;private int distNum;private int distance;private int biketype;private int type;
结果
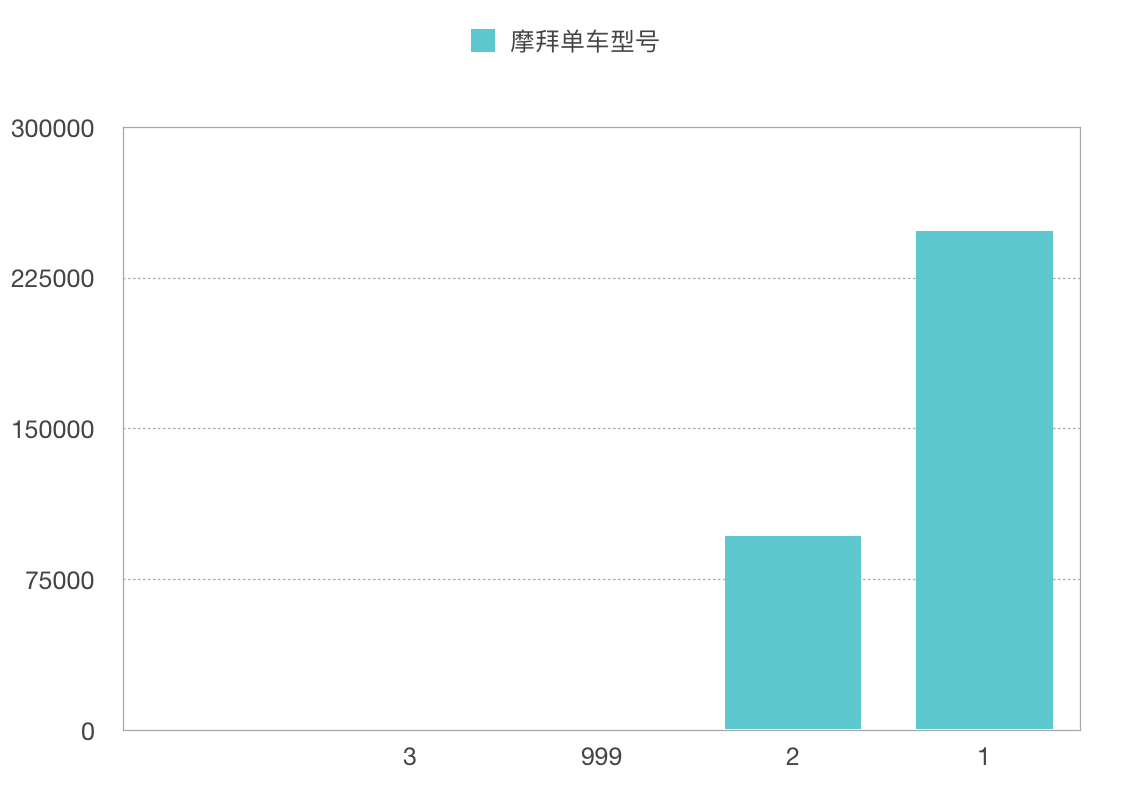
大概1个半小时,爬取到了345679个摩拜单车。
摩拜单车型号[1 x 248627, 2 x 96840, 3 x 2, 999 x 210]:
分布热力图
使用百度地图的API。
经纬度模糊
因为爬取到单车的地理位置太精确了,在地图上画热力分布精确到小数点后5位即可。所以需要统计在每个经纬度下的单车数量,并将点打印出符合百度地图API的格式(统计时将经纬度合并成一个String,否则复杂度太高)。
@Testpublic void testMobikeHeat() {String REDIS_KEY = "mobike";Map<String, String> bikesMap = jedis.hgetAll(REDIS_KEY);Multiset<String> multiset = HashMultiset.create();for (String key : bikesMap.keySet()) {BikeDo bike = JSON.parseObject(bikesMap.get(key), BikeDo.class);String mixKey = String.format("%.6f", bike.getDistX()) + String.format("%.6f", bike.getDistY());multiset.add(mixKey);}File file = new File("mobike.txt");BufferedWriter out = null;try {out = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(file, true)));for (String ele : multiset.elementSet()) {out.write("{\"lng\":"+ele.substring(0, 10)+",\"lat\":"+ele.substring(10)+",\"count\":"+multiset.count(ele)+"}," + "\r\n");}} catch (Exception e) {e.printStackTrace();} finally {try {out.close();} catch (IOException e) {e.printStackTrace();}}}
结果
结果如下,可以看出中间位置的故宫、五环西北角的圆明园、颐和园均没有单车,热力图大体是正确的。
影响精度的因素
- 五环位置不准确,爬取完才发现五环右边不是方形,爬取结果少了一块……
- 爬取过程中,正在被骑行的车没有统计到
- 在爬取过程中,车恰好从未爬取位置移动到了已爬取位置
- 报修的车无法统计
- 在爬取的过程中,断网了1个小时……时间间隔过长,精确度受影响
- 爬取是按照0.003*0.003的经纬度方形区域,没有精确计算是否能够覆盖所有区域,可能四个方形因为爬取单车数量的因素,导致区域之间有死角。
如何获取更精确的数据
- 多次爬取,去重,改变步长。这样可以爬取到因为骑行而未被爬取到的车。
- 多线程爬取,减少时间。
总结
爬取到北京五环内有345679辆单车(爬取区域少了一点),估计整个北京有45~50万单车吧。
