@TangWill
2019-08-08T02:59:29.000000Z
字数 16156
阅读 1372
Determining Both Surface Position and Orientation in Structured-Light-Based Sensing
大创
摘要
位置轮廓和方位轮廓是空间形状的两种主要描述方式。我们描述了一个结构光系统,再加上伪随机模式的照明和特征点的合适选择,不仅可以独立地决定单个表面元素的位置,而且还可以决定它们的方向。与传统的以被照模式元素的中心点作为特征点的设计不同,本设计采用模式元素之间的网格点作为特征点。网格点的本质在于它们在图像数据中的位置对于透视变形的影响是惰性的,它们各自的提取并不直接相互依赖,网格点具有很强的对称性,可以利用它们在图像数据中的精确定位。最重要的是,形成网格点的照明模式的网格线可以帮助确定表面法线。本文描述了如何用唯一的颜色编码对每个网格点进行标记,它们具有什么样的对称性,如何利用这种对称性在亚像素精度的图像数据中进行精确定位,以及如何在每个网格点上确定除 3D 位置以外的 3D 方向。无论是位置和方向剖面可以确定只有一个单一的模式照明和一个单一的图像捕获。
索引术语
结构光系统,三维重建,表面定向,特征提取
1、引言
在描述形状或插值表面时,方向信息与位置信息是互补的;而位置描述表面点的位置,方向(通常表示为表面法线)描述相关表面上位置的局部变化,或者等价地说,表面点的邻域在空间中是如何定向的。研究表明,方向信息有助于提高描述三维几何形状的精度[1],有助于重建物体形状[2],有助于提高描述三维几何形状的精度即使是在物体识别方面[3]。
实际上,可以通过关联相邻位置数据,从位置信息中推断出某些方位描述。然而,这种描述只是对原始位置数据的某种抽象,而不是独立的信息;(这种方向推断)的结果取决于位置数据的密集程度和推断中使用的方法(或者更准确地说,形状优先,比如平面优先或二次优先)。不同密度的位置数据,或者使用不同的方法(甚至在完全相同的位置数据上),可以生成不同的方向描述。
在文献中,各种视觉线索,如阴影[4]和纹理[5],已经被提出来确定表面方向。然而,它们的应用需要物体具有某些特性,如恒定的反照率或表面纹理的均匀分布等,这就限制了它们可以操作的对象集。这项工作解决了如何在结构光传感器中独立于位置确定方向的问题。
结构光系统是一种有效且低成本的三维信息测量方法。通过对目标物体上进行人工图案的投射,避免了对物体表面自然纹理的要求。通过在发光图案中嵌入独特的编码,使每个图案位置不同,从而在投影仪的显示面板和摄像机的图像面之间建立对应关系,实现三维重建。
在光照编码方面,至少有时间和空间方案。时间编码方案(以灰度编码照明为例)利用结构光投影和图像捕获序列为每个照明位置生成一个随时间累积的不同编码。相比之下,空间编码方案(以伪随机彩色网格投影为例)根据位置邻域的亮度剖面对每个照明位置进行编码。每个方案都有自己的利弊。时间方案不需要使用空间邻域,因此受场景中遮挡的影响较小,而空间方案可以通过单幅图像实现三维确定,从而更好地处理动态场景。在任何情况下,在任何一种方案中,都需要在照明中使用颜色方面达成某种妥协。虽然使用单色光通常可以获得更好的3D确定质量,但在照明中使用更多的颜色可以减少所需图像的数量(在时间编码的情况下)或编码邻域的大小(在空间编码的情况下),而可能会对被测物体的原始颜色轮廓造成更大的干扰。
以上关于SLS的问题都已经在文献中讨论过了,本文并不是对其进行研究。然而,现有的SLSs在很大程度上仅限于确定位置信息。这项工作旨在探索在光照是空间编码的情况下SLS如何也可以确定方向信息。
为了确定新的信息,我们需要一组新的特性来进行编码、标定和处理。前人在SLS上的工作[7],[8],[9],[10],[11],[12],[13],[14],[15]通常使用结构图案的中心作为特征点。然而,质心特征的使用有以下缺点:作为与模式元素的区域扩散相关的特征,质心通常在图像中对物体表面的表面反照率、不均匀的环境照明、图像噪声以及其他影响图像强度分布的干扰有其敏感的位置。透视变形也会扭曲质心位置。此外,质心的计算首先要求区分每个模式元素的边界。由于相邻模式元素的分段不是独立的,单个模式元素的定位也不是独立的。所有这些都限制了质心特征点的精确定位。
更重要的是,像中心点这样的纯位置特征不能单独提供每个特征的方向信息,不管它们的位置有多准确。其原因是,每个单一的位置基准本身并不提供约束表面法线的位置。为了确定方向,我们需要的特征点,不仅要揭示表面点在空间中的位置,还要约束表面点的邻域是如何定向的。
在这项工作中,我们提议使用模式元素之间的网格点作为特征。网格点是由照明图案的网格线相交而形成的点。不论透视距离如何,它们的位置总是在网格线相交的地方。此外,与相邻模式元质心相比,网格线的相邻交点之间的关系并不密切。因此,网格点通常比模式元素质心更具有可定位性。
此外,网格点具有一定的对称性,称为双重旋转对称(Rotational symmetry of order n, also called n-fold rotational symmetry, or discrete rotational symmetry of the nth order, with respect to a particular point (in 2D) or axis (in 3D) means that rotation by an angle of 360°/n (180°, 120°, 90°, 72°, 60°, 51 3⁄7°, etc.) does not change the object. Note that "1-fold" symmetry is no symmetry (all objects look alike after a rotation of 360°).n = 2, 180°: the dyad; letters Z, N, S; the outlines, albeit not the colors, of the yin and yang symbol; the Union Flag (as divided along the flag's diagonal and rotated about the flag's center point) original.),它对于图像噪声、图像模糊和透视投影是准不变的。利用这种对称性可以在图像域进行精确定位。
更重要的是,每个网格点不仅携带与位置相关的信息,还携带组成位置的网格线的局部曲率。本文提出了一种从光照条件下的局部曲率推导出空间成像曲面的局部法线的方法。
注意,我们确定的方位信息不是用来替代位置信息的,而是作为描述或插值形状的补充数据。还请注意,这项工作没有解决如何将独立获得的位置和方向数据结合起来的表面描述或插值。这个主题是独立研究的,事实上,关于它的文献已经有了丰富的作品集。这项工作的重点是可能性,在SLS,获得方位信息,而不是推断的立场。
本文的结构安排如下:第二部分简要回顾了以往有关位姿恢复的研究工作。我们使用的照明模式和网格点的特在第3节描述。和质心特征一样,网格点特征必须在照明中进行唯一的编码,否则SLS的本质就会被破坏。在第3节中,我们还描述了如何对每个网格点进行唯一标记。在第四节中,我们介绍了网格点具有的对称性,以及如何利用这种对称性在亚像素精度的图像域中进行定位。第五节介绍了确定每个网格点表面取向的机理。在第六部分,参数曲面和自由曲面的实验结果,包括人脸的自然外观,显示。第7节提供了结论和今后可能开展的工作。
2、前期工作
SLS已经得到了广泛的研究和越来越多的工业应用。下面,我们将简要回顾一些与SLS相关的主要工作。
2.1 通过结构光确定位置
正如前面所讨论的,SLS成功的关键在于如何将唯一的代码归属于照明模式的每个位置。在这方面,有时间[16],[17],[18],[19],[20],[21],[22],[23],[24]和空间[7],[8],[9],[10],[11],[12],[13],[14],[15],[25],[26],[27],[28],[30]编码方案。时间编码方案可以获得更加密集的数据样本和更高的测量精度,但需要长时间的多路照明和图像捕获。时间编码方法的例子有格雷码[18],结合正弦波模式的格雷码[21],相移[22],线移[23],以及条移方法[24]。相比之下,空间编码方案通过相邻位置的外观轮廓标记每个模式位置。外观配置文件可以是各种灰度级别、颜色[26]或几何原语[27]。De-bruijn序列[29],[30],伪随机数组,m维数组[7],[8],[9],[10],[11],[12],[13],[14],[15]是经常使用的编码方法。该空间编码方案的优点是只需一次照明和一次图像捕获即可实现三维测量。因此,它特别适合在动态应用程序中使用。
由于这项工作假定在SLS中使用一个空间编码方案,下面,我们提供更多与之相关的工作的细节。
早期的工作包括[28]、[29]、[30],这些工作将照明结构化为条纹,并使用空间编码对每个条纹进行编码。它们的贡献在于:在条纹中使用颜色,仔细选择相邻条纹上的颜色以减少图像数据中的颜色混淆,以及综合使用区域分割和边缘检测来分割条纹。特别是在文献[28]中,使用了比唯一空间编码所需要的窗口大小更小的窗口,并使用动态编程来解决条纹的非唯一编码引起的通信模糊问题。关于位置确定的准确性,张等人报告是0.18mm,Chen等人报告的范围是0.15-0.32毫米,Pages等人报告的范围是0.3-0.6毫米。
还有像[9],[13],[26]这样的工程,将照明结构作为一个数组的模式元素,而不是条纹,并指定颜色的模式元素的目标,每个模式元素有一个邻居的颜色是独特的。在所有这些工作中,模式元素(或圆形或矩形)的中心被用作特征点。在[26]中,距离1米的表面的空间分辨率约为5毫米。在[9]中,对于距离传感器大约1.5米的物体,定位误差在2毫米以内。在[13]中,报告了(工作距离的)2%的相对误差。
2.2 方向确定
如前所述,独立的定位信息是定位信息的重要补充。一些视觉线索已被提出来确定方向。已建立的包括从阴影[4],纹理[5],高光[31],偏振[32]和光度立体[33]的形状。然而,这种方法需要一定的限制条件,如表面反照率恒定或纹理分布均匀等。
在确定结构光定向方面已经有了一些尝试。在Shrikhande和Stockman[34]的工作中,一个网格模式被投射到目标物体上。通过图像数据中网格边缘长度的变化可以推断网格点的表面方向(网格线间隔)。然而,提出的实验结果表明,在图像的某些地方可能存在较大的误差,特别是那些表面方向与参考平面大不相同的地方,或者表面曲率非零的地方。Winkelbach和Wahl[35]使用条形模式计算每个边缘点处的曲面法线。条纹图案从两个不同的角度投射到物体表面两次,每次都有一个单独的成像步骤,这样两个表面切线可用于某些图像位置。在[36]中,还提出了一种从图像中条纹的斜率和间隔确定表面法线的简化方法。该方法是基于两条边之间的曲面片是平面或非常光滑的假设。通过与参考平面上测得的带钢宽度进行比较,可以根据带钢的变形宽度估计出带钢的倾斜角。在该系统中,模式照明被假定为平行投影,并且成像为平行成像。也就是说,没有考虑摄像机和投影仪的固有参数,因投影和成像模型过于简化而引起的误差是不可避免的。
在Davies和Nixon[15]的作品中,一组六边形镶嵌的圆形斑点被用作照明模式。编码是基于邻域的使用格里芬的方法绘制每个圆形点的轮廓的颜色。假设每个圆形图案点,在物体表面的照明,从它的反射,并由摄像机成像,将显示为一个椭圆形的图像。以椭圆的中心点为特征点,通过检验椭圆在外极线方向上的剪切因子和缩放因子,提出了一种推导与椭圆中心相关的空间曲面法线的方法。
然而,图像中模式元素的椭圆模型隐含地假定物体表面不仅在椭圆中心点附近是平面的,而且在整个模式元素中也是平面的。对于曲率很大的物体表面,这样的模型很难被证明是正确的。此外,如果外极线碰巧通过同一颜色的多个图案元素的中心,则可能会出现歧义。此外,很少有实验结果被报道,只有使用戏剧化妆将人脸涂成白色的结果被显示出来。也没有评估表面法线和位置确定的准确程度。
与前人的工作相比,这项工作并不假设物体表面在每个图案元素的整体上是平面的,我们只是从构成网格点的图像中的网格线的局部曲率来确定点ー网格点ー表面法线。对于照明和成像过程也没有过于简化的近似;我们使用透视模型来描述这两个过程。
3、我们的系统设计
我们的SLS是根据伪随机阵列原理设计的发光图案。下面,我们首先描述如何为每个图案位置分配颜色,这样每个位置都可以有一个具有独特颜色配置文件的邻域窗口。如果使用模式元素的中心点作为特征点,则完成了编码任务。然而,我们使用的特征点ーー网格点ーー并不是附加在一个单独的模式元素上,而是附加在一些模式元素上。实际上,每个网格点正好位于许多模式元素的交叉点上。因此,我们需要一个单独的机制,对每个网格点进行唯一的编码。在这一部分,我们还提供了标记方案的说明。
3.1 图案设计
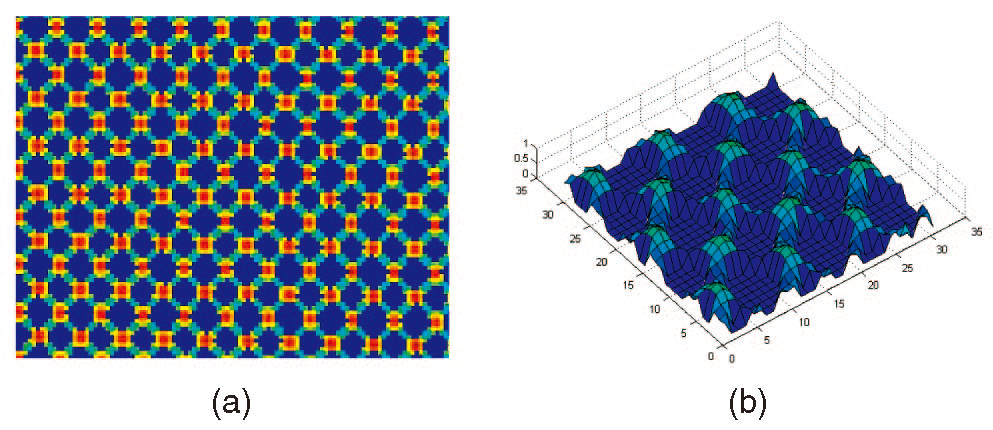
在我们的SLS中使用了由菱形元素组成的伪随机颜色模式,如图1所示。它是按以下方式构造的。一个本原多项式,定义在GaloisField上空,包含4个元素(GF4),首先用于生成伪随机序列:
从上面的本原多项式序列生成一个长度为4,095的伪随机序列。然后,通过折叠序列[37],可以产生一个大小为6563的伪随机数组。通过窗口属性的模式,每个窗口大小23在窗口组成的元素上是唯一的。这意味着每个23大小的窗口在整个窗口中只出现一次。由于伪随机阵列是在GF4上构造的,因此在图案中总共必须有四个不同的元素,在这上面,我们使用四种不同的颜色(红色、绿色、蓝色和黑色),它们之间有着鲜明的对比。图案的背景设置为白色。

在我们的设计中使用菱形元素的优点是相邻的模式元素(即前景中的元素)不共享边界,因此避免了图像中相邻模式元素之间的颜色混淆。然而,这种优势是有代价的。对于相同的图案元素大小,图案元素的数量减半。如果使用模式元素的中心点作为特征点,就像经典的做法一样,特征点的密度就会受到影响。有人可能会说,这个问题可以通过在使用中添加背景元素的中心来解决,但那就意味着把背景元素当作模式元素来处理,菱形元素设计的原始目的就失败了。图像数据中会出现颜色混淆的问题,前景元素的质心提取与邻近背景的质心提取不是独立的。
3.2 特征选择和编码
在传统的设计中,模式元素的中心点被用作特征点,这里我们使用相邻菱形元素之间的网格点作为特征点。
如图1所示,网格点的使用有一个直接的好处,即尽管使用菱形模式元素,特征点的密度仍然得到保留。
然而,就像SLS中使用的其他特性一样,每个网格点首先必须具有一个唯一的代码。下面,我们将展示如何实现这一目标。

如图2所示,网格点可以分为两种类型:和,根据点的左右两边的模式元素是白色(背景)还是有色(前景)模式元素。类型的网格点可以按照固定的顺序,例如图2中的的顺序,通过其周围个菱形元素的颜色进行编码。对于类型的网格点,我们在右下角搜索与其最接近的类型的网格点,并采用该网格点的码字作为其码字。这一点如图3所示。
为了方便起见,我们设计的投影机-摄像机系统是这样配置的:两个观察平面(即投影机的显示面板和摄像机的图像平面)的x轴和摄像机与投影机之间的基线大致平行。这使得对两个观测平面上的任何位置x;y都可以很容易地定义”左”和”右”的描述,”左”指的是x坐标略小于x的位置,”右”指的是x坐标略大于x的位置。在我们的系统中,这样的“左”和“右”描述仅仅用于识别网格点的直接相邻模式元素,以便对网格点类型进行分类。它们不是用于识别像素级别的特征,而是用于识别与模式元素一样大的特征,因此,上述配置中的小错误并不重要。
对于菱形元素这样大的特征,位于投影仪显示面板网格点“左”或“右”的拓扑关系类似于保存在图像数据中。有了这个,网格点类型(p1或p2)和代码字一起唯一地区分一个网格点,并允许投影仪侧和摄像机侧之间的网格点容易对应。
根据这个新的特征定义,对于的设计,编码的特征点的数量可以达到7,808,而不是3,904当质心特征使用。然而,我们必须强调,网格点的使用和质心特征的使用并不是互斥的,如果质心特征也被包含和编码,特征点的密度可以进一步提高。
4、特征提取
上面的例子表明,像质心特性一样,网格点也可以用唯一的标签进行属性化对伪随机模式进行网格点类型描述。此外,它们具有与光照变化、图像模糊和透视变形不变的优点(这可能会影响基于区域特征的定位,如质心),原因很简单,它们不是表面斑块的全局特征,而是网格线交叉点。原则上,它们可以提取比质心特征更高的精度。下面,我们描述在我们的系统中它们的提取。
由于投影仪-摄像机系统的各种光学特性(调制传递函数(MTF)、景深、传感器噪声等)以及目标物体的表面特性(纹理、反射率、曲率等)的影响,在图像中相邻的亮度图案菱形单元可能不连通。图4b中显示了一个例子。这意味着精确定位网格点在图像数据中的位置并非易事。传统的特征提取算法,如LoG[38],Harris[39],或SUSAN[40]不能处理这个问题。文献中已经提出了一些用于摄像机系统标定的角提取器,这些角提取器涉及到三维参考平面网格模式的使用。在我们的案例中,由于正在考虑的真实物体表面可以是一个曲面,这样的角抽取器,往往假定理想的平面度的模式,也不适用。为了精确定位图像数据中的网格点或角点,需要一种新的机制。

图4还说明了网格点的某些特征,这些特征对网格点的定位是有利的。这是因为它们表现出一定的局部对称性。假设颜色模式被抽象为单色模式,将颜色元素视为前景元素,其余为背景元素。因此,当以任何网格点为中心旋转180度时,和原来重合。在平面对称的研究中,这被称为二重旋转对称或者cmm对称。这种对称性在光照方面具有准不变性,具有图像噪声、图像模糊和图像失真等特点,因此在图像数据中得到了很大程度的保留,原因是在处理过程中保留了将圆盘分成对称两半的各段的共线性。在圆盘足够小的情况下,即使曲率非零也不影响三维表面的对称性。这种对称性的准不变性正是我们从图像中精确检测网格点所利用的。
4.1 网格点位置假设
我们使用的菱形图案中的一个网格点,是在垂直方向(y)和水平方向(x)上存在的相邻区域的拥有属性。更准确地说,在垂直方向上有彩色图案元素,在水平方向上有背景(白色)区域。我们使用这个属性来假设图像中网格点的候选位置。我们首先将原始图像转换为单色图像,如上所述。如图4b所示,交叉形状的掩模用于与所有 的相同大小窗口的卷积。绝对差值d,如下所示,定义为掩码在任何图像位置的响应值:
其中,表示面具的大小。的测量值表明图像强度沿x方向和y方向的积分在位置上有多大的差别。具有较高响应值的图像位置被选作网格点的候选点。这种基于模板的方案简单有效。然而,它仅仅考虑了原始强度的微分,即相对于图像噪声的精确性和鲁棒性的评价。这里只是作为一个初步步骤来假设可能的网格点位置来加速这个过程。
4.2 确认和位置化
在真正的网格点的位置显示双重旋转对称性。这可以用来确认网格点特征,以及他们在亚像素精度的精确定位。为了测量任何候选位置的双重对称的强度,我们使用位置的一个小圆窗口和它的180度旋转之间的相关系数。由于图像强度通常是正态分布的,我们采用了皮尔逊积矩相关系数(PMCC)[41]。
假设一个圆形掩模,中心位于任意候选图像位置,是绕点旋转度后的掩膜。根据PMCC的定义,我们可以写出相关系数为:
其中,指的是蒙版或的一个个体元素,是蒙版的大小, 表示 和 掩码的第 i 个元素的图像强度,分别的,和是两个掩码分布强度的平均值。上述等式可以被一个等式代替,这个等价公式避免了使用掩模的平均值,因此速度更快:
该算子仅适用于通过上述假设步骤的图像位置。计算这些点上的响应值,并从这些值生成名为响应图像的映射。图5显示了响应图像的例子。
在上使用一个阈值来提取图像位置,其中的值是一个足够强的局部最大值。然后在每个位置周围选择一个小的区域,比如像素。在每个这样的点附近的最终网格位置然后以亚像素精度计算为这个区域中所有位置的加权平均数,权重为该区域中每个位置的值:
由于该方法在网格点采用结构化而不是原始图像的灰度,因此与基于灰度的方法相比,该方法对图像噪声、模糊、表面纹理、曲率和投影变形具有更高的鲁棒性。关于网格点检测器的更多细节,例如健壮性测试,与传统算子的比较,可以在另一篇文章[42]中找到。由于提取器是基于每个网格点的局部对称性,网格点的提取是相互独立的。与使用质心点作为特征点相比,这是一个额外的优势。
5、表面定向测定
一旦特征点位于图像数据中,通过对特征点进行唯一标记,就可以实现图像平面(摄像机)和显示平面(投影仪)之间的对应,从而实现三维重建。在位置确定方面,网格点的使用与其他特征点的使用没有什么不同。
问题是,我们怎样才能超越传统的结构光制度的目标,不仅确定位置,而且确定方向。如前所述,定向[1],[2],[3],[4],[5],[15],[32],[33],[34],[35],[36]是描述3D形状不可或缺的信息。下面,我们描述一个机制派生表面法线在每个网格点,使用网格线形成它。
5.1 基本原则
考虑投影仪的显示面板中的任意网格点,以及伴随的组成网格点的两条网格线,如图6所示。假设网格点和网格线通过空间物体表面上的一个3D点在图像平面上诱导出一个图像网格点和两个图像网格线(或者更准确地说是网格曲线,因为原始网格线通常在3D中受到表面曲率的调制,而在图像数据中不显示为线)。假设显示面板中点右边的网格线的切线分别为和,并且图像平面中点右边的网格线的对应切线分别为和。
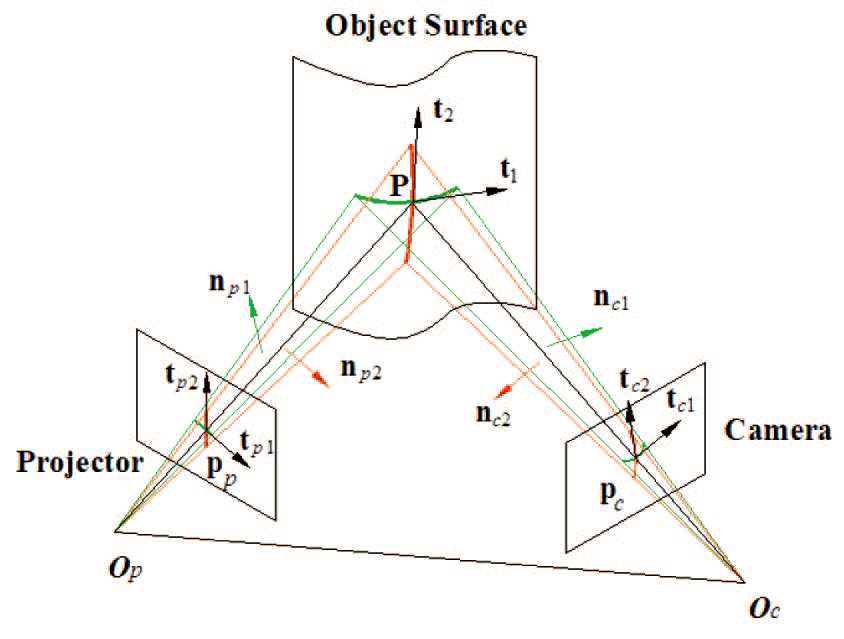
切线和网格点(以及投影仪的投影中心)在显示面板上共同形成一个来自光源的照明平面。这样一个光面在点被物体表面反射,成为到象面的投影平面。两个轻平面的交叉点和实际上定义了一个与物体表面的3D点的切线。和是完全可获得的,因为它们是系统设计下的实体,和也是如此,因为它们是从图像数据中可观察到的实体。因此,两个光面和都是可构造的,并且它们的交线可以确定。实际上,点处与物体表面的切线仅仅是两个光面的表面法线的叉积。类似地,在表面点处的另一个切线可以被确定为另外两个光平面的表面法线的交叉积和,这两个光平面都可以从设计和图像观测中获得。
换句话说,通过简单地抓取物体表面的一个投影图像,对于图像平面上位于处的任何成像网格点,可以确定物体表面在相关的3D点处的表面方向。如果图像观测值是并且图案数据是,则可以确定3D切线,并且表面法线仅为。
请注意,如果投影模式是一个规则的网格,那么投影端的图像切线和在所有网格点上都是相同的,并且已知。
5.2 图像正切检测
在这里,我们描述了如何提取图像切线观察网格点上的网格线。假设我们要确定图像在网格点的切线。图7将显示为两个短线段。有两种方法可以被采用。在一种方法中,使用邻近的网格点。如图7所示,沿着贯穿的相关网格线,有两个相邻的网格点和。这三个网格点的区别在于是一个网格点类型(类型在图7),相邻的网格点是另一种类型(图7中的型)。

图像点的切线可以通过简单的有限差分和平均由三个网格点作很好的近似确定。第二种方法使用的是图像强度。选择点周围的一个小窗口,利用强度窗口确定点周围的两个方向,使得与方向正交的强度变化是局部最大值。这两个方向分别分配给和。第一种方法对图像噪声和表面纹理较不敏感,但第二种方法不需要假设三维形状的平滑性。在我们的实现中,使用了这两种方法。对于检测到的网格点的本地密度较高的网格点,我们使用第一种方法;否则,我们使用第二种方法。
5.3 从图像切线到表面方向
假设和是光面和的法向量,和是光面和的法向量。假设摄像机和投影仪的内部参数(模拟为另一个透视摄像机,除了光线是从它出来而不是进入它)已经校准,它们分别是焦距,和焦点。然后,四个平面法线可以被确定为:
其中表示任意非零缩放的相等性,
分别表示网格在在相机和投影仪两边的位置。
如果图像切线的平面方向和分别是和,那么上述入射光平面的平面法线可以表示为:
可以简化为,
以相机坐标系为参考,到达目标表面点de两条3D切线:
其中表示相机和投影仪坐标之间的旋转关系。
最后,点的表面取向可以确定为:
注意,用(10)表示的局部表面方向的确定是一个确定性的过程,它只需要特定点的局部图像信息即可操作。与从阴影到形状再到纹理的形状不同,它不需要假设相邻点的局部表面方向是如何相互关联的。更具体地说,它不需要迭代过程来确定局部表面方向。
上述分析表明,三维的表面方向确实可以由图像切线确定,但它也指出,对于每个成像的网格点和伴随的图像切线和,它也需要二维切线和和其他在投影仪的显示面板上的局部信息以精确确定方向。然而,在以前的工作中,如[34],[35],[36],假定在投影仪和摄像机上都有平行投影。照明和成像模型相当粗糙的近似不可避免地给确定的方向带来误差。当所考虑的图像位置离观测平面的主点越远时,误差越大。
6、实验结果
实验已经进行了使用所描述的系统来重建各种形状。我们孤立地确定了位置和方向,并检查了它们本身的质量;我们将如何最好地整合它们以改进3d重建留给未来的工作。该实验平台由XGA分辨率(即像素)的DLP投影机和分辨率的摄像机组成。工作系统的距离约为850毫米。投影机-摄像机系统首先是用我们自己开发的方法校准的[43]。一旦投影仪和照相机的几何形状和两个仪器的内参数被弄清楚,我们继续进行重建。下面,我们将展示一些重建参数化形状的结果,比如平面和棱面,以及自由形状的形状,比如胸部物体和真实的人脸(详见下文,不做精准翻译)。
6.1 形状参数的位置确定
由于参数化形状是已知的,参数化形状实验可以明确地评价重构质量。
在一个实验中,我们将结构光投影到一块平面板上来确定位置。然后对恢复的离散三维点按最小二乘误差意义拟合平面来测量板的平面度。平面拟合过程的绝对平均误差为0.131mm(或工作距离850mm的0.015%),拟合标准差仅为0.1mm或0.011%。
我们还在半径约97毫米的球体上进行了类似的实验。图案投影下的球面如图8a所示。定位结果如图8b所示。用最小二乘误差法对重建的数据点进行球面拟合。拟合过程的绝对平均残留量为0.202mm,标准差仅为0.067mm。如图8c和8d所示是带状表面的重建结果。重建结果具有良好的应用价值。
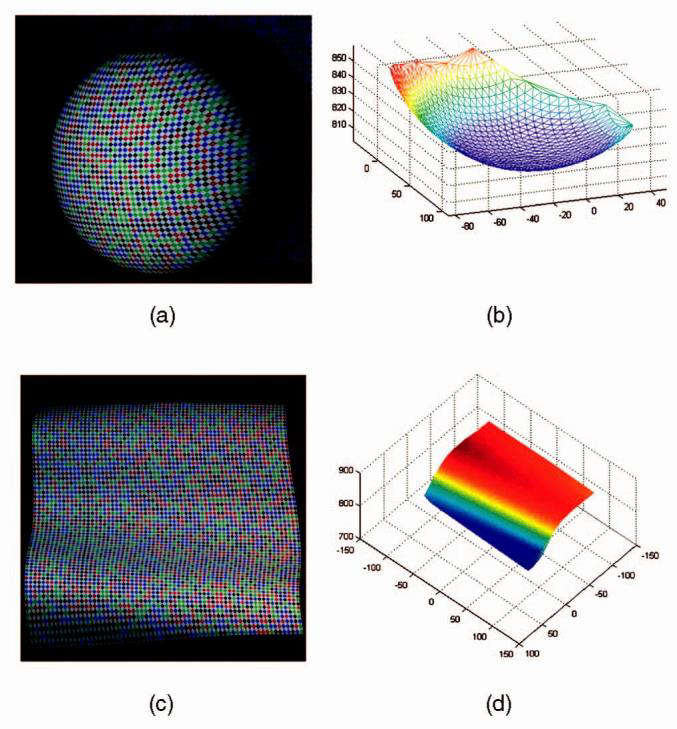
表1列出了文献中报道的其他一些方法的3D测定结果。因为不同方法采用的实验指标和误差评定标准不同,列表不作直接比较,仅供粗略参考。尽管如此,有迹象表明,拟议的系统的性能与其他以二维模式为基础的系统相当,甚至更好。该系统是一个空间编码系统,只需要一个图像捕获操作,其结果甚至可与一些时间方法的操作需要多个图像捕获相媲美。当然,这种比较是不确定的,因为公平的比较应该包括建立所有这些系统,使用相同的图案大小,使用相同的颜色集,采用相同的编码窗口大小,并用相同的投影机-摄像机校准系统进行校准。这将需要一个单独的研究。尽管如此,上述实验至少表明该系统具有良好的性能,我们将其归功于特征点的精确定位以及投影仪和摄像机设置的精确校准。
6.2 形状参数的方向确定
我们还使用第4节中描述的方法分别重建了上述对象的表面法线。在平面形状上,表面法线的大小约为毫米。局部方向的恢复分布与理想平面的分布只有很小的差异,平均相对标准差为0.69度,平均相对误差为0.13度。如果用平行投影模型代替,就会得到更大的差值ーー平均偏差为1.65度,标准差为0.48度。实验表明,采用一个更精确的投影模型,就像我们的系统一样,可能会导致很大的不同。作为参考,在以前的工作,如[34],[35],[36],在2至8度范围内的方向差异被报告。
确定了上述球形物体和带状表面的方位图。图9显示了两个形状恢复后的取向图。

虽然没有关于物体表面法线的真实情况,但我们使用了一些推断的参考来评估我们方向确定的质量。在球形物体上,我们假设物体是一个近乎完美的球体,并在最小二乘误差意义下识别出最适合上述确定位置数据的理想球体。然后以这样一个球体的表面法线作为参考。我们直接从图像数据确定的方向数据,而不是通过位置数据,与上述参考平均只有1.13度的差异。
为了进行比较,我们还采用经典的方法从上述位置数据推导出方位数据,并将这种方位数据的方位提取与上述参考数据进行了比较。我们首先从位置数据生成一个三角网格,重建的三维位置作为三角形补丁的角点。球形物体的网格如图8b所示。在每个补片上,可以从补片的三个角点位置确定局部表面法线。然后计算每个网格点的表面法线,将周围三角形补丁的表面法线作为一个加权平均数,每个三角形补丁的权重与补丁的面积成比例。从位置数据中提取的方位信息与上述参考值差异较大,平均为5.41度。
我们的对比实验表明,直接从网格线确定的定位信息与从位置数据推断的定位信息不同,一般更准确。
6.3 不规则形状的重建
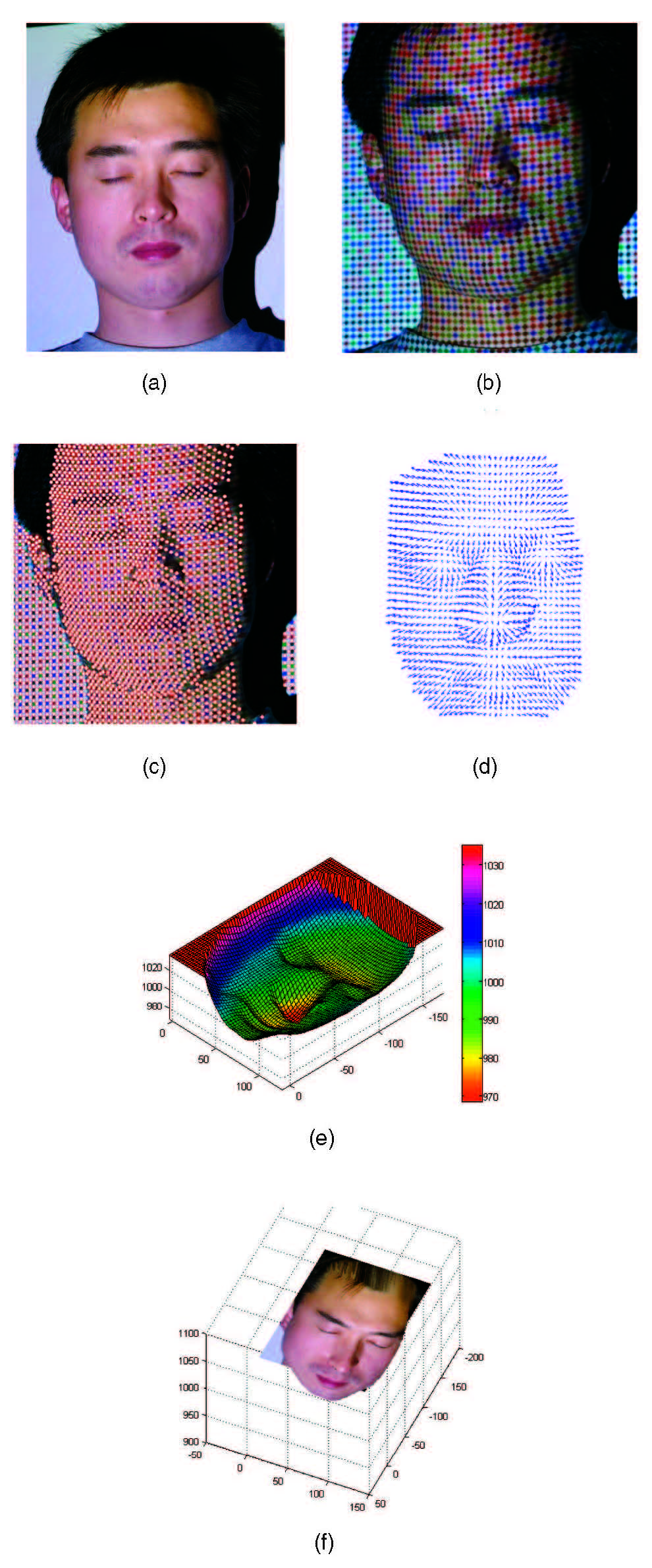
我们还利用所提出的系统来确定一些自由形状的位置和方向,如胸像物体和一个自然面容的人脸。图10a和11b显示了经过图案照明检查的表面。

网格点检测是确定位置和方位的第一步。图10b显示了胸部物体图像上的网格点检测结果。尽管由于形状曲率的变化,图像投影中的图案失真较大,但大多数网格点都能够被正确地检测到。鼻部附近区域的曲率值变化较大。有几个网格点被漏掉了,但是该区域的大多数网格点都被我们的网格点检测器正确检测到了。
人脸图像的网格点检测由于颜色变化较大和纹理的存在而更具挑战性。然而,我们的网格点提取器在检索大多数网格点是有效的,如图11c所示。拔除器在一些区域失败,特别是鼻子和眉毛附近有严重的咬合。偶尔的特征提取缺失可以通过对物体表面的插值来补偿,最终的重建仍然具有足够的质量。我们已经尝试了传统的特征检测器,如LoG,Harris,SUSAN,和模板方法来检测质心特征,但是结果很不理想。特征检测结果的比较细节可以在另一份报告[42]中找到。总之,使用网格点作为特征点,再加上所描述的网格点检测器,可以以比传统的质心特征更高的精度检测更多的特征点。
在提取的网格点确定位置后,可以构建两个物体的深度图,它们分别显示在图10c和图11e中。特别是在人脸上的实验中,如上所述是网格点丢失或者编码不正确。采用中值滤波去除恢复的三维点的异常值,并在局部邻域上进行简单的插值,填补位置数据中偶尔出现的遗漏。有了这些,我们的最终结果有超过2200个网格点重建成功。插值的三维模型如图11e所示。图11f显示了已确定的三维人脸与原始纹理映射在顶部。
我们还分别确定了方向图,其结果见图10d和图11d。通过将恢复的三维信息投影到不同的视点,我们可以直观地检验重建的质量。经检验,重建的深度图和定位图质量合理。
7、结论和未来的工作
我们已经描述了如何使用空间编码的结构光系统不仅可以确定3d位置,而且可以独立地确定3d方向。这是通过在系统中具有一些特定的设计特性而实现的。它们包括采用网格点而不是质心点作为特征点,以及包含一种机制,可以从组成网格的网格线的局部曲率中提取网格点的方向信息。该系统的几个重要问题是,即如何对网格点进行唯一标记,以及如何精确地提取网格点。针对这些问题,我们提出了解决方案。
实验结果表明,该系统不仅可以确定传统SLS无法确定的定位方向,而且由于采用了网格点特征以及这些特征具有更好的定位能力,从而提供了更高密度和精度的位置信息。
未来的工作将是如何以一种完整的方式整合位置和方向信息,从而实现更高质量的形状重建。
