@BruceWang
2018-12-25T08:02:28.000000Z
字数 3797
阅读 2885
介绍# 自建模型-eeg 2
课题
介绍
总览
睡眠阶段评分 (也: 睡眠分期) 过程大部分时间仍由训练有素的技术人员手动执行, 因此非常繁琐和耗时;
虽然已经有很多公司(飞利浦、)可以提供自动睡眠分期服务,主要原因是他们的不可靠并且软件的高费用,直到今天, 研究人员和临床医生都没有开放源码的实施或软件包;
所以我们提出了一种自动睡眠分期的神经网络模型,并与传统方法的对比
睡眠质量可以与许多与健康有关的问题, 如心血管疾病, 糖尿病或肥胖;
如何分期?
我们依据把记录的eeg数据,分成每30s一段,看形状、算频率等。。。依据AASM分期规则;
理想分期图
睡眠评分自动化与评分标准问题
许多方法已经提出来自动化睡眠评分程序,但这些方法面临以下问题和缺点:
- Lack of large training databases : 没公开、涉及隐私问题、
- Inter-subject variability: 同一睡眠阶段的睡眠脑电图可以看起来非常不同, 取决于年龄, 目前的睡眠障碍和其他神经系统疾病。
- Inter-rater variability: 评分方式的大差异持续存在, 缺乏标签,不同医师给出的评分结果不一样。
- Duration of epochs:30s 是否是正确的评分方式,因为起初30s是因为一张纸上记录方便。
自动睡眠分期方法说明
- 构建数据库,然后新数据与数据库对比得到相似度, 以某个标准(similarity>0.8)得到分期结果。
- 结合专业医师的知识进行手动提取特征(功率谱、频谱等), 然后结合传统机器学习的方法(KNN、决策树等)进行分类。
频谱特征: 采用傅里叶变换或小波转换等方法从信号中提取频率分量;
通常使用的频率来自 0.5-50 Hz, 它被分为 ;时序特征:用来解释随着睡眠时间的推移大脑激活的变化。
由于每个睡眠阶段都依赖于以前的大脑状态, 所以包含时态特征提供了有关分类的重要信息。统计特征: 信号通常可以用简单的统计特性来描述, 例如信号的最小和最大值或零交叉点的个数, 例如检测眼球运动。其他统计指标为中值、峰值和信号偏斜度的标准差。
那么现在要做到的就是自动提取特征, 我们想到神经网络的优点;
即在没有人的偏见的情况下, 网络可以找到一组最佳特征。
缺点是这些特征可以是抽象和不可理解的为人和晦涩的决定过程 (黑盒过程)。
目标以及面临的问题
根据(睡眠评分自动化与评分标准问题)提到的缺点,我们的目标也就明确了:
- 自动提取特征,减小主观偏差,这里我们使用CNN来自动提取特征;
- 捕捉时序特征, 通过使用 LSTM 神经元的递归神经网络扩展网络, 就能提高性能;
- 自动特征提取可以代替手动提取特征方法吗?
- 哪些通道有助于分类,如何确保数据的平衡性?
- 除去常用到的三通道 (EEG-脑电、EMG-眼电、EOG-肌电) 是否可以得到很好地结果?
- 如果不考虑时序特征对模型有多大的影响?
- 数据的泛华性能怎么样(是否适用于其他数据)?
方法
睡眠egg, 26 通道数据
在这里我们使用 8个 采样频率为 512 通道的数据;
18065920 = Durations*SampleFre = 35285s*512fs
| 序号 | size | Label |
|---|---|---|
| 0 | 18065920 | LOC-A2 |
| 1 | 18065920 | ROC-A2 |
| 3 | 18065920 | F4-A1 |
| 4 | 18065920 | C4-A1 |
| 5 | 18065920 | O2-A1 |
| 6 | 18065920 | F3-A2 |
| 7 | 18065920 | C3-A2 |
| 8 | 18065920 | O1-A2 |
EEG position:
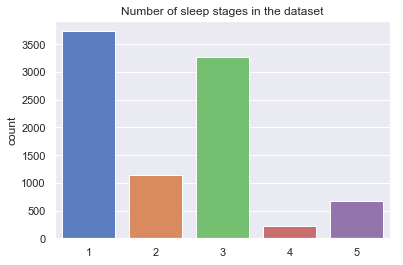
7个eeg信号的9036个 30s 的数据分布:
网络模型结构说明
总的数据量结构:9036 @ (8*30x512)= 8*15360
模拟医师分期时的分期办法,不可能只看一个通道的数据;
所以是8个通道数据齐头并进, 也即: INput = N@(8x15360),通过网络模型,对原始数据进行卷积提取特征。
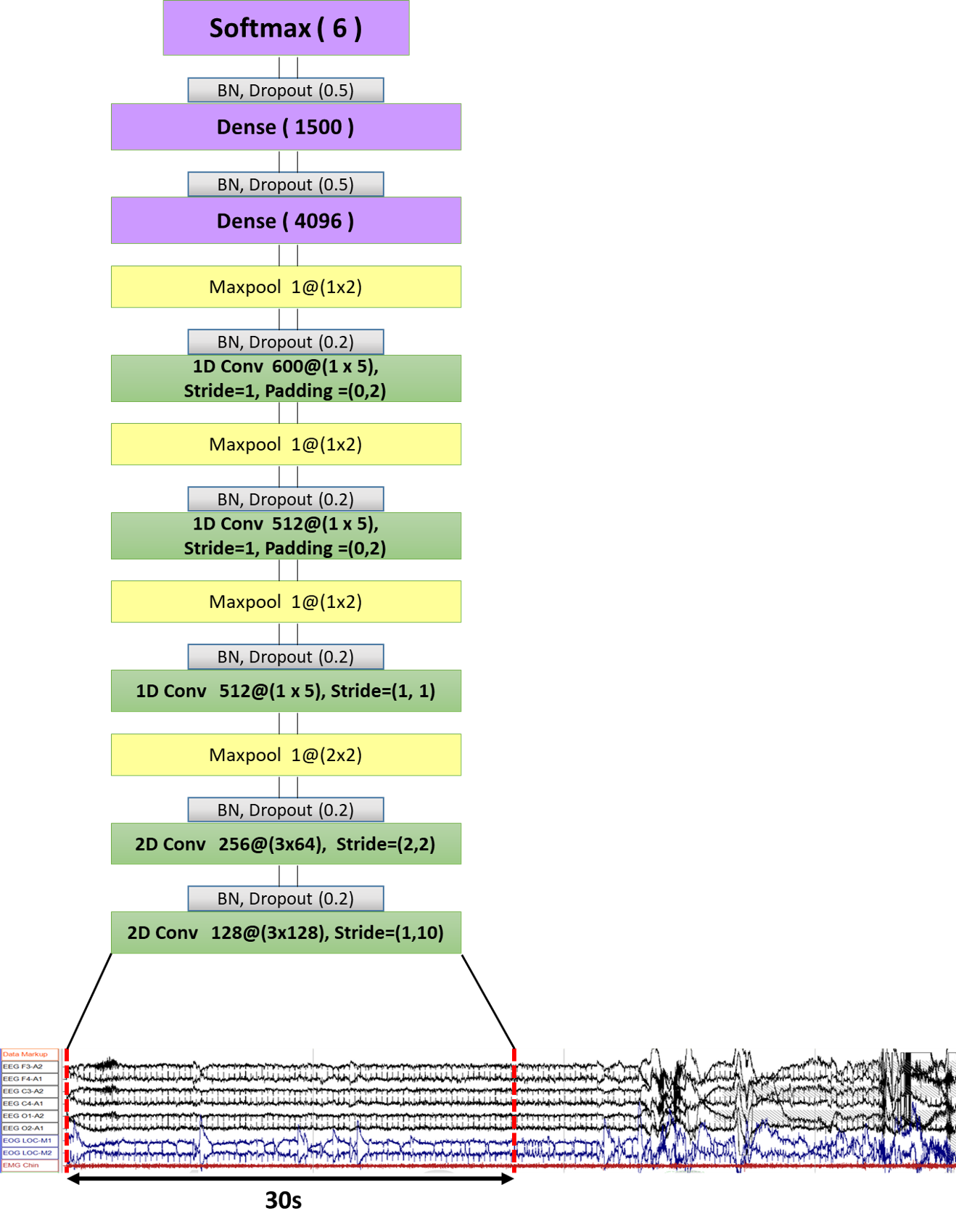
结果与分析
我们可以根据混淆矩阵看得出5个分类的准确率分别是:
| Stage | W | N1 | N2 | N3 | R | Ave Acc |
|---|---|---|---|---|---|---|
| Acc | 81.9 | 34.1 | 78.5 | 80.9 | 72.1 | 69.5 |
看得出结果刚刚“及格”,确实不是那么令人满意,不过相对与这点数据,已经是很不错的效果了。
再则我也得出了模型结果的混淆矩阵:
| Stage | W | N1 | N2 | N3 | R |
|---|---|---|---|---|---|
| W | 81.9 | 10.6 | 4.1 | 1.4 | 2.1 |
| N1 | 10.8 | 34.1 | 27.2 | 2.4 | 25.5 |
| N2 | 1.9 | 3.2 | 78.5 | 9.6 | 6.8 |
| N3 | 2.7 | 2.0 | 13.3 | 80.9 | 1.2 |
| R | 5.3 | 12.9 | 8.4 | 1.4 | 72.1 |
为什么N1的结果很低?
由于医师的分类是依据AASM规则来分期的,所以AASM规则一定程度上决定着分期准确性也即---标签的准确性
实验原因
从分期结果来看, 经过仔细对比模型的结果,和原始标签(医师)结果, 也就是 混淆矩阵(confusion matirx):
| Stage | W | N1 | N2 | N3 | R |
|---|---|---|---|---|---|
| W | 81.9 | 10.6 | 4.1 | 1.4 | 2.1 |
| N1 | 10.8 | 34.1 | 27.2 | 2.4 | 25.5 |
| N2 | 1.9 | 3.2 | 78.5 | 9.6 | 6.8 |
| N3 | 2.7 | 2.0 | 13.3 | 80.9 | 1.2 |
| R | 5.3 | 12.9 | 8.4 | 1.4 | 72.1 |
可以看出除了其他结果都很好,但是N1的结果真的是差强人意,不过一半;
紧接着分析,看一看模型把N1都分到了哪里,看得出多数分到了W stage 和 REM stage。结合 附录的分期特征与波型表,我们也可以看出确实有一些特征重合。
数据原因
从这 7个eeg信号的9036个 30s 的数据分布可以看出数据分布是极不平衡的, 对于N3只有 202 个30s数据:
再则仔细剖析了数据的标签属性,可以看到有很多“? ” 的标签,也就是“UNKNOW”, 当然这里指的是 “5”
这一类,因为01234分别代表 W,N1,N2,N3,R, stages;

分期规则原因
30s 是否正确?
历史上,使用30秒间隔是因为纸张速度为10 mm / s,非常适合观看alpha和锭,一页相当于30秒
N1期 — N1期睡眠是从觉醒状态到睡眠的典型过渡期。其特征是低振幅混合性脑电波频率,处于θ波范围(4-7Hz),占一帧的至少50%。眼动通常缓慢且为旋转运动。N1期是最浅的睡眠期,可说是在清醒期与睡眠期之间的一个过渡阶段;
首先N1期是由WK期过度到Ni期的一个衔接期,相对于其他期来说,期间特征非常不明显,再则“首夜效应(first night effect)”对于医师的分类首先就是一个极大的干扰;
- 可能是患者正在进行心理调整以适应睡眠实验室监测的“首夜效应(first night effect)”,那么泛化性能肯定降低;
- 首先N1期是由WK期过度到Ni期的一个衔接期,相对于其他期来说,期间特征非常不明显,有交叉;
- N1期是所有分期里面最难分类的期,它没有相对明显固定的期特征;
由于监督学习的结果是由标签决定的,最高准确率也就是标签的准确率,所以就产生一个悖论,如果想超越标签肯定是不可能的,而改善标签的准确率,又是由医师决定的,结果可想而知。
附录
| 波型 | 波段 | 期特征 |
|---|---|---|
| (0.5-4 hz)、 有些资料是0.5-2hz | WK、N3 | |
| (4-8 hz)、 | N1、N2 | |
| (8-12 hz)、 | WK、REM | |
| (12-40 hz)、 | N2(部分) | |
| (40-100 hz), | 不多用,因为在睡眠分期主要考虑0.5-50hz | |
| K复合波 | (12-16 hz) | N2 |
| 序号 | size | Label |
|---|---|---|
| label:01 | 18065920 | LOC-A2 |
| label:02 | 18065920 | ROC-A2 |
| label:03 | 9032960 | Chin1-Chin2 |
| label:04 | 18065920 | F4-A1 |
| label:05 | 18065920 | C4-A1 |
| label:06 | 18065920 | O2-A1 |
| label:07 | 18065920 | F3-A2 |
| label:08 | 18065920 | C3-A2 |
| label:09 | 18065920 | O1-A2 |
| label:10 | 4516480 | ECG1-ECG2 |
| label:11 | 1129120 | AIRFLOW |
| label:12 | 4516480 | Nasal Pressur |
| label:13 | 1129120 | THOR |
| label:14 | 1129120 | ABDO |
| label:15 | 9032960 | Snore |
| label:16 | 564560 | Pos Sensor |
| label:17 | 564560 | SpO2 |
| label:18 | 564560 | Ox Status |
| label:19 | 4516480 | LEG/L |
| label:20 | 4516480 | LEG/R |
| label:21 | 564560 | Pulse |
| label:22 | 1129120 | CPAP Flow |
| label:23 | 2258240 | HR |
| label:24 | 2258240 | PTT |
| label:25 | 564560 | CPAP Press |
| label:26 | 9032960 | Pleth |
