@BruceWang
2018-01-09T01:52:45.000000Z
字数 7809
阅读 3768
最新深度学习的GPU讲解:深度学习中使用GPU的经验和建议
环境配置
2018年1月1日由Bruce Wang 译自 Tim Dettmers’ Blog
深度学习是一个计算需求强烈的领域,您的GPU的选择将从根本上决定您的深度学习体验。在没有GPU的情况下,这可能看起来像是等待实验结束的几个月,或者运行一天或更长时间的实验,只是看到所选参数已关闭。
有了一个好的,坚实的GPU,人们可以快速迭代深度学习网络,并在几天而不是几个月,几小时而不是几天,几分钟而不是几小时的时间内运行实验。因此,在购买GPU时做出正确的选择至关重要。那么你如何选择适合你的GPU呢?这个博客文章将深入探讨这个问题,并会借给你的建议,这将有助于你做出适合你的选择。
拥有高速GPU是开始学习深度学习的一个非常重要的方面,因为这可以让您快速获得实践经验,这是建立专业知识的关键,您可以将深度学习应用于新问题。如果没有这种快速的反馈,只需花费太多的时间从错误中学习,而继续深入的学习可能会令人沮丧和沮丧。
借助GPU,我很快就学会了如何在一系列Kaggle比赛中应用深度学习,并且我使用深度学习方法在“部分阳光”中获得了第二名,,这是预测给定鸣叫的天气评分的任务。在比赛中,我使用了一个相当大的两层深度神经网络,整数线性单位和正则化退出,这个深度网络几乎适合我的6GB GPU内存。
我应该得到多个GPU?
受到GPU深度学习的激励,我通过组装一个带有InfiniBand 40Gbit / s互连的小型GPU集群,使自己陷入了多GPU领域。我很高兴看到多个GPU可以获得更好的结果。
我很快发现,要在多个GPU上高效地并行化神经网络不仅非常困难,而且对于稠密神经网络来说,加速只是平庸的。小型神经网络可以使用数据并行性相当高效地进行并行化处理,但是像Partly Sunny中使用的大型神经网络几乎没有任何加速。
后来我进一步冒险,我开发了一种新的8位压缩技术,与32位方法相比,您可以更高效地将密集或完全连接的层并行化。
不过,我也发现并行化可能会令人非常沮丧。我天真地优化了一系列问题的并行算法,只是发现即使在多个GPU上优化的定制代码并行性也不能很好地工作,因为您必须付出努力。您需要非常了解您的硬件,以及它如何与深度学习算法进行交互,以评估您是否能从并行化中受益。

在我的主电脑上安装:您可以看到三个GXT Titan和一个InfiniBand卡。这是一个深入学习的好设置吗?
自那时以来,GPU的并行性支持更为普遍,但与通用可用性和高效性相差甚远。当前在GPU和计算机之间实现高效算法的唯一深度学习库是CNTK,它使用微软的1位量化(高效)和块动量(非常高效)的特殊并行算法。
有了CNTK和96个GPU的集群,您可以预期约90x-95x的新线速度。Pytorch可能是支持跨机器的高效并行性的下一个库,但图书馆还没有。如果你想在一台机器上并行,那么你的选择主要是CNTK,Torch,Pytorch。这些库产生良好的加速(3.6x-3.8x),并在一台机器上具有预定义的并行算法,最多支持4个GPU。还有其他支持并行性的库,
如果你把并行的价值,我建议使用Pytorch或CNTK。
使用多个GPU没有并行性
使用多个GPU的另一个优势是,即使您没有并行化算法,您也可以在每个GPU上分别运行多个算法或实验。你没有获得加速,但是通过一次使用不同的算法或参数,你可以获得更多的性能信息。如果您的主要目标是尽快获得深入的学习体验,这对于想要同时尝试多个版本的新算法的研究人员非常有用。
如果你想学习深度学习,这在心理上很重要。执行任务和接收任务的时间间隔越短,大脑就越能够将相关记忆片段整合到一个连贯的画面中。如果您在小数据集上的单独GPU上训练两个卷积网络,您将更快感受到重要的性能表现; 您将更容易在交叉验证错误中检测到模式并正确解释它们。你将能够检测到模式,给你提示什么参数或层需要添加,删除或调整。
总体而言,可以说一个GPU几乎适用于任何任务,但是多个GPU对于加速您的深度学习模型变得越来越重要。如果您想快速学习深度学习,多款便宜的GPU也非常出色。我个人拥有相当多的小型GPU,甚至是我的研究实验。
我应该得到什么样的加速器?NVIDIA GPU,AMD GPU或Intel Xeon Phi?
NVIDIA的标准库使得在CUDA中建立第一个深度学习库非常容易,而AMD的OpenCL则没有这样强大的标准库。现在,AMD卡没有很好的深度学习库,所以就是NVIDIA。即使未来有一些OpenCL库可用,我也会坚持使用NVIDIA:GPU计算或GPGPU社区对于CUDA来说是非常大的,而对于OpenCL而言是相当小的。因此,在CUDA社区中,很容易获得良好的开源解决方案和可靠的建议。
此外,即使深度学习刚刚起步,NVIDIA仍然深入学习。这个赌注得到了回报。而其他公司现在把钱和精力放在深度学习上,由于起步较晚,他们还是很落后。目前,除NVIDIA-CUDA之外,使用任何软硬件组合进行深度学习都将导致重大挫折。
在英特尔至强融核的情况下,广告宣称您可以使用标准的C代码,并将代码轻松转换为加速Xeon Phi代码。这个特性听起来很有趣,因为你可能认为你可以依靠C代码的庞大资源。但是,实际上只有很小部分的C代码是被支持的,所以这个功能并不是很有用,而且你可以运行的大部分C代码都很慢。
我曾经在一个至少有500个至强Phis的Xeon Phi集群上工作,对它的失望是无止境的。我无法运行我的单元测试,因为Xeon Phi MKL与Python Numpy不兼容; 我不得不重构大部分代码,因为英特尔至强融核编译器无法对模板进行适当的缩减 - 例如对于switch语句; 我不得不改变我的C接口,因为Intel Xeon Phi编译器不支持一些C ++ 11功能。所有这些都导致了我不得不在单元测试中执行的重构。这花了很多时间。这是地狱。
然后当我的代码最终执行时,一切都非常缓慢。线程调度程序(?)中存在错误(?)或问题,如果您操作的张量大小连续发生变化,则会使性能瘫痪。例如,如果您有不同大小的完全连接的图层或丢弃图层,则Xeon Phi比CPU要慢。我在一个孤立的矩阵矩阵乘法例子中复制了这个行为,并将它发送给了Intel。我从来没有从他们那里听到。所以,如果你想深入学习,那就离开至强菲斯吧!
给定预算最快的GPU
你的第一个问题可能是深度学习的GPU性能最重要的特性是:cuda核心?时钟速度?内存大小?
这两者都不是,但深度学习性能最重要的特征是内存带宽。
简而言之:GPU针对内存带宽进行了优化,同时牺牲了内存访问时间(延迟)。CPU的设计恰恰相反:如果涉及少量内存(例如乘以几个数字(3 * 6 * 9)),CPU可以快速计算,但是对于大量内存(如矩阵乘法(A * B * C)他们很慢。由于内存带宽的限制,图形处理器擅长涉及大量内存的问题。当然,GPU和CPU之间还有更复杂的区别,如果您对GPU深度学习的深度感兴趣,您可以在我的quora答案中阅读关于这个问题的更多信息。
所以如果你想购买一个快速的GPU,首先要看看那个GPU的带宽。
通过内存带宽评估GPU
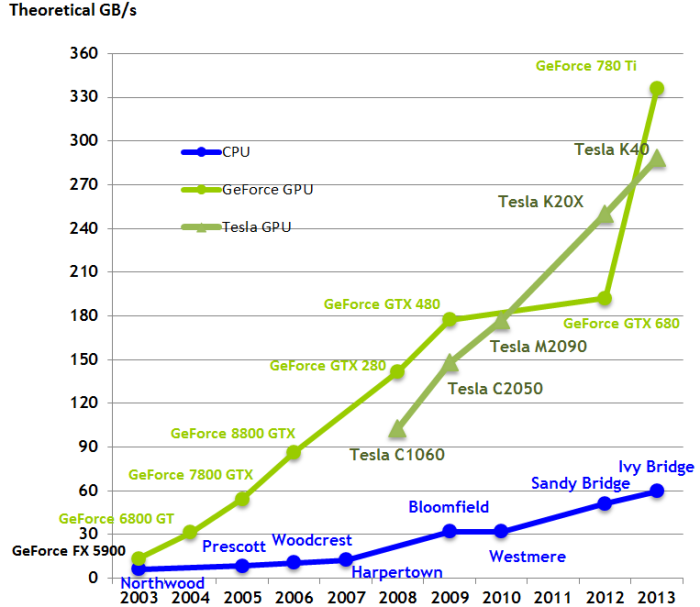
随着时间的推移,CPU和GPU的带宽比较:带宽是GPU比CPU更快的主要原因之一。
带宽可以直接在体系结构中进行比较,例如像GTX 1080和GTX 1070这样的Pascal卡的性能可以直接通过单独查看内存带宽进行比较。例如,GTX 1080(320GB / s)比GTX 1070(256 GB / s)快25%(320/256)。然而,跨体系结构,例如像GTX 1080与GTX Titan X之类的Pascal与Maxwell不能直接比较,因为不同制造工艺的架构(以纳米为单位)如何不同地利用给定的内存带宽。这使得一切都有点棘手,但仅仅整体带宽就能让你很好地概括一下GPU的速度。为了确定一个给定的预算最快的GPU可以使用这个维基百科页面以GB / s为单位查看带宽; 上市的价格是相当准确的新卡(900和1000系列),但较旧的卡比明显便宜的价格 - 特别是如果你通过eBay购买这些卡。例如,一个普通的GTX Titan X在eBay上的售价约为550美元。
另一个需要考虑的重要因素是并不是所有的架构都与cuDNN兼容。由于几乎所有深度学习库都使用cuDNN进行卷积运算,因此将GPU的选择限制在开普勒GPU或更高的版本,即GTX 600系列或更高版本。最重要的是,开普勒GPU一般都很慢。所以这意味着你应该选择900或1000系列的GPU来获得更好的性能。
为了粗略地估计这些卡在深度学习任务上的表现,我构建了一个简单的GPU等值图。如何阅读这个?例如,一个GTX 980与0.35 Titan X Pascal一样快,或者换句话说,Titan X Pascal几乎是GTX 980的三倍。
请注意,我自己并没有所有这些卡,我没有在所有这些卡上运行深入的学习基准。比较是从卡片规格与计算基准的比较中得出的(一些加密货币挖掘的情况是与深度学习在计算上相当的任务)。
所以这些是粗略的估计。实际的数字可能会有所不同,但通常错误应该是最小的,卡的顺序应该是正确的。另外请注意,那些利用GPU不足的小型网络会让更大的GPU看上去不好。例如,GTX 1080 Ti上的小型LSTM(128个隐藏单元;批量大小> 64)不会比在GTX 1070上运行速度快得多。为了获得图表中显示的性能差异,需要运行更大的网络具有1024个隐藏单位的LSTM(批量大小> 64)。
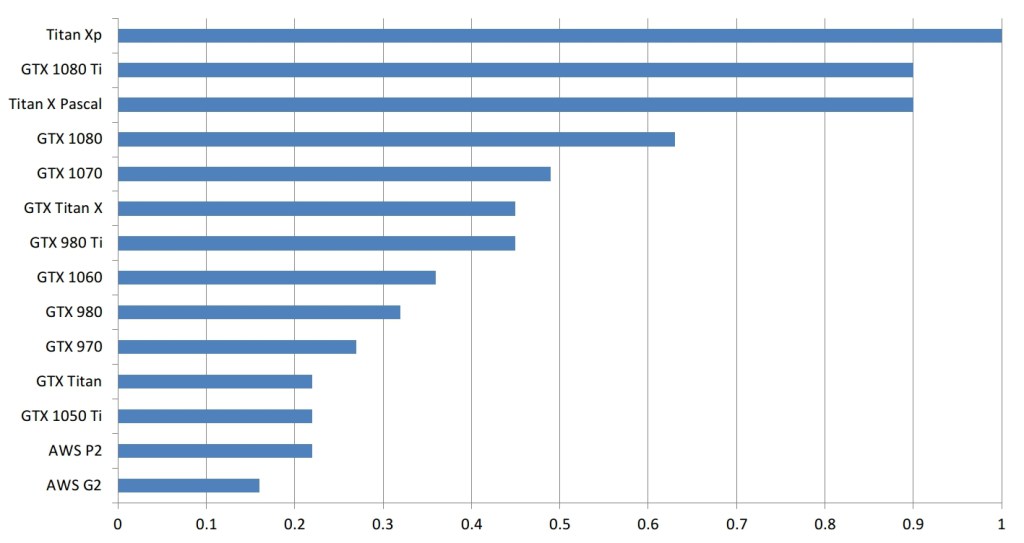
GPU之间粗略的性能比较。此比较仅适用于较大的工作负载。
成本效益分析
如果我们现在从上面画出粗略的表现指标,并将它们除以每张卡片的成本,那么就是如果我们为您赚取高昂的成本,我们最终会得出一个情节,这在某种程度上反映了我的建议。
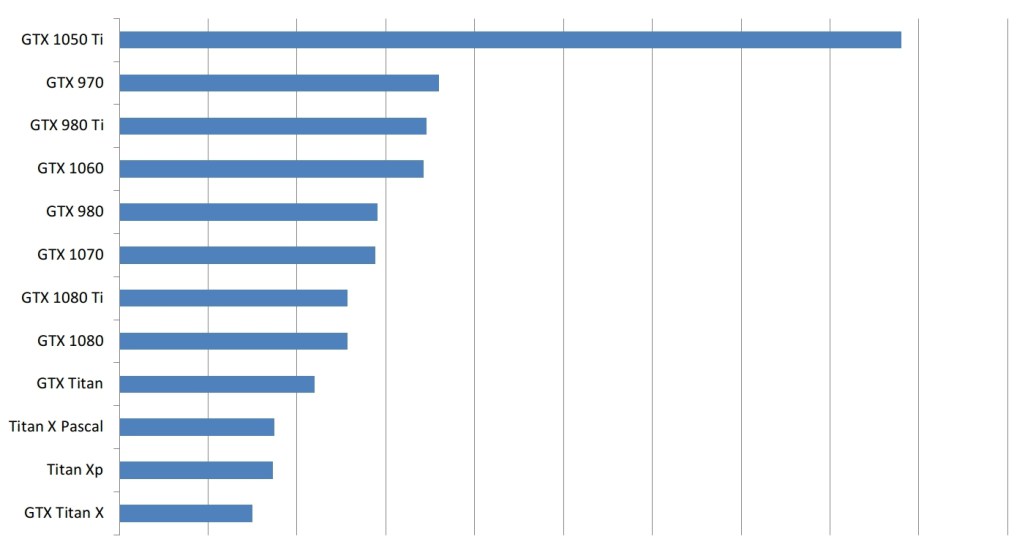
使用上面粗略的性能度量标准和亚马逊的价格来计算新卡的成本效率和旧卡的eBay价格。请注意,这个数字在很多方面都有偏差,例如它没有考虑到内存
但请注意,这种对GPU排名的衡量标准是相当有偏见的。首先,这不考虑GPU的内存大小。您经常需要比GTX 1050 Ti所能提供的内存更多的内存,因此虽然具有成本效益,但一些高级卡却没有实际可行的解决方案。
类似地,使用4个小型GPU而不是1个大型GPU是困难的,因此小型GPU具有缺点。此外,你不能购买16个 GTX 1050 Ti来获得4 GTX 1080 Ti的性能,你还需要购买3台额外的昂贵的电脑。如果我们考虑这最后一点,图表看起来像这样。
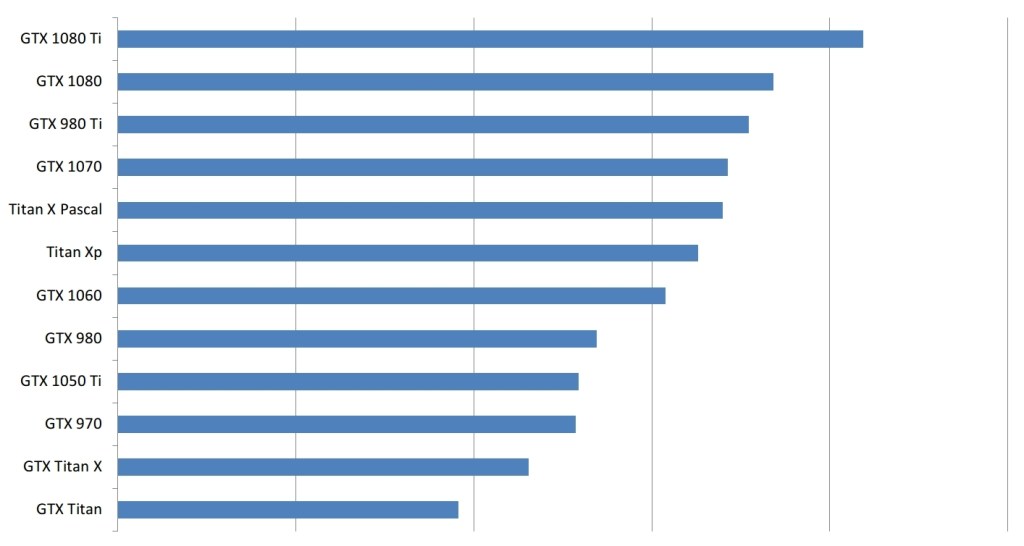
考虑到其他硬件的价格,GPU的成本效率标准化。在这里,我们比较一台完整的机器,即4个GPU,以及价值1500美元的高端硬件(CPU,主板等)。
因此,在这种情况下,如果您想要购买许多GPU,实际上代表了这种情况,如果您购买更具成本效益的计算机+ GPU组合(而不仅仅是经济高效的GPU),则毫无疑问,大GPU将赢得胜利。但是,这仍然是GPU选择的偏见。无论如何,如果您拥有有限的金额,而且首先无法负担得起,那么一个盒子里的4个GTX 1080 Ti如何具有成本效益并不重要。
因此,您可能对如何使用高性价比的卡片感兴趣,但实际上,对于您拥有的金额,您可以购买哪种性能最好的系统?您还必须处理其他问题,例如:我将有多长时间使用此GPU?我想在几年内升级GPU或整个计算机吗?我想在未来一段时间内销售当前的GPU,并购买新的更好的GPU吗?
所以你可以看到,做出正确的选择并不容易。但是,如果你对所有这些问题持平衡的看法,你会得出类似于以下建议的结论。
一般的GPU建议
一般来说,我会推荐GTX 1080 Ti,GTX 1080或GTX 1070.他们都是优秀的显卡,如果你有GTX 1080 Ti的钱,你应该继续。GTX 1070比普通的GTX Titan X(Maxwell)要便宜一些。GTX 1080的成本效率比GTX 1070低一些,但是自GTX 1080 Ti推出以来,价格大幅下滑,现在GTX 1080能够与GTX 1070竞争。所有这三款显卡应该比GTX 980 Ti由于他们增加了11GB和8GB(而不是6GB)的内存。
8GB的内存可能看起来有点小,但是对于许多任务来说,这已经足够了。例如对于Kaggle比赛,大多数图像数据集,深入的风格和自然语言理解任务,您将遇到几个问题。
GTX 1060是第一次尝试深度学习的最佳入门级GPU,或者偶尔用于Kaggle比赛。我不会推荐带有3GB内存的GTX 1060变种,因为另一个变种的6GB内存已经相当有限了。但是,对于许多应用来说,6GB就足够了。GTX 1060比普通的Titan X慢,但在GTX 980的性能和eBay价格上都是可比的。
就爆炸而言,10系列设计得非常好。GTX 1050 Ti,GTX 1060,GTX 1070,GTX 1080和GTX 1080 Ti脱颖而出。GTX 1060和GTX 1050 Ti适用于初学者,GTX 1070和GTX 1080是初创公司,部分研究和工业部门以及GTX 1080 Ti的全面选择。
我通常不会推荐NVIDIA Titan Xp,因为它的性能太昂贵了。用GTX 1080 Ti代替。然而,NVIDIA Titan Xp在计算机视觉研究人员中仍然占有一席之地,他们从事大数据集或视频数据。在这些领域,每GB的内存数量,NVIDIA Titan Xp只比GTX 1080 Ti多1GB,因此在这种情况下是一个优势。我不会推荐NVIDIA Titan X(Pascal),因为NVIDIA Titan Xp速度更快,价格几乎相同。由于市场上这些GPU的稀缺性,如果你找不到可以购买的NVIDIA Titan Xp,你也可以购买Titan X(Pascal)。你也许能够从eBay抢夺便宜的Titan X(Pascal)。
如果你已经有了GTX Titan X(Maxwell)GPU,那么升级到NVIDIA Titan X(Pascal)或NVIDIA Titan Xp是不值得的。节省您的下一代GPU的钱。
如果你缺钱,但是你知道12GB内存对你来说很重要,那么eBay的GTX Titan X(Maxwell)也是一个很好的选择。
但是,大多数研究人员使用GTX 1080 Ti做得很好。大多数研究和大多数应用程序不需要额外的GB内存。
我个人会与多个GTX 1070或GTX 1080研究。我宁愿运行几个比只运行一个更快的实验慢一点的实验。在NLP中,内存限制并不像计算机视觉那么严格,所以GTX 1070 / GTX 1080对我来说也不错。我工作的任务以及如何运行我的实验决定了我的最佳选择,不管是GTX 1070还是GTX 1080。
当你选择你的GPU时,你应该以类似的方式推理。考虑一下你在做什么任务,如何运行你的实验,然后尝试找到适合这些要求的GPU。
对于GPU几乎没有钱的人来说,选项现在更加有限。亚马逊网络服务上的GPU实例现在相当昂贵和缓慢,如果您拥有更少的资金,则不再是一个不错的选择。我不推荐GTX 970,因为它很慢,即使在使用的条件下购买也是相当昂贵的(在eBay上150美元),并且存在与卡启动相关的内存问题。相反,尝试获得额外的钱购买GTX 1060更快,有更大的内存,没有内存问题。如果你买不起GTX 1060,我会选择配备4GB内存的GTX 1050 Ti。4GB可以是限制,但你将能够深入学习,如果你对模型进行一些调整,你可以得到良好的性能。
GTX 1050 Ti一般来说也是一个坚实的选择,如果你只是想深入学习一下,没有任何认真的承诺。
亚马逊网络服务(AWS)GPU实例
在此博客文章的以前版本中,我推荐AWS GPU现货实例,但我不会再推荐这个选项。AWS上的GPU现在非常慢(一个GTX 1080的速度是AWS GPU的四倍),价格在过去几个月急剧上升。现在再次购买你自己的GPU似乎更合理。
结论
有了这篇文章中的所有信息,您应该能够通过平衡需要的内存大小,以GB / s为单位的速度和GPU的价格来平衡选择哪一种GPU,并且这个推理在未来很多年内将会保持稳定。但是现在我的建议是要买一台GTX 1080 Ti,GTX 1070或者GTX 1080,一个GTX 1060,如果你刚刚开始深入学习或受到金钱的限制; 如果你有很少的钱,试着买一个GTX 1050 ; 如果你是计算机视觉研究人员,你可能想要一个Titan Xp。
最好的GPU整体(小幅度):Titan Xp
成本效益,但昂贵:GTX 1080 Ti,GTX 1070,GTX 1080
成本效益和便宜:GTX 1060(6GB)
- 我使用数据集> 250GB:GTX Titan X(Maxwell) ,NVIDIA Titan X Pascal或NVIDIA Titan Xp
- 我没有多少钱:GTX 1060(6GB)
- 我几乎没有钱:GTX 1050 Ti(4GB)
我做Kaggle:GTX 1060(6GB)适用于任何“正常”比赛,或GTX 1080 Ti为“深度学习竞赛”
我是一名具有竞争力的计算机视觉研究员:NVIDIA Titan Xp; 不要从现有的Titan X(Pascal或Maxwell)升级
- 我是一名研究员:GTX 1080 Ti
在某些情况下,如自然语言处理,一个GTX 1070或GTX 1080也可能是一个坚实的选择-检查你的现有机型的内存需求我想建立一个GPU集群: 这确实是复杂的,你可以得到一些想法 在这里我开始深入学习,我认真对待它:从GTX 1060(6GB)开始。
根据你选择什么样的区域,毗邻(启动,Kaggle,研究,应用深度学习)推销自己的GTX 1060和买东西更合适我想尝试深度学习,但我不认真的:GTX 1050 Ti(4或2GB)
致谢
我要感谢 Mat Kelcey 帮助我调试和测试GTX 970的自定义代码; 我要感谢Sander Dieleman让我意识到我的GPU内存建议对于卷积网络的缺点; 我要感谢Hannes Bretschneider指出GTX 580的软件依赖问题; 我要感谢Oliver Griesel指出AWS实例的笔记本解决方案。
图片来源:NVIDIA CUDA / C编程指南
本文翻译自:Tim Dettmers 的博客
转载和疑问声明
如果你有什么疑问或者想要转载,没有允许是不能转载的哈
赞赏一下能不能转?哈哈,联系我啊,我告诉你呢 ~~
欢迎联系我哈,我会给大家慢慢解答啦~~~怎么联系我? 笨啊~ ~~ 你留言也行
你关注微信公众号1.听朕给你说:2.tzgns666,3.或者扫那个二维码,后台联系我也行啦!

终于写完了,赞赏一下下嘛!
(爱心.gif) 么么哒~么么哒~么么哒
爱心从我做起,贫困山区捐衣服,为开源社区做贡献!码字不易啊啊啊,如果你觉得本文有帮助,三毛也是爱!真的就三毛,呜呜。。。
我祝各位帅哥,和美女,你们永远十八岁,嗨嘿嘿~~~


