@BruceWang
2018-07-09T09:57:27.000000Z
字数 3369
阅读 5886
基于深度学习的肺音分类模型说明(中翎易)
课题
1. 音频相关基础知识
什么是音频、心音?
人类所能识别的声音频率为20Hz~20KHz之间,例如环境声, 也称呼吸音,可以通过听诊器横跨前壁和后壁进行听诊;肺部不适的声音被认为是crack啪声(罗勒),喘鸣音(喘鸣音),喘鸣音和胸膜音以及浊音,最后到达肺泡,这个过程中依次产生了支气管音、气管音和肺泡呼吸音常见的有:哮鸣音、湿罗音、爆裂音。
音频属性
因为在物理中,声音的振幅,振频等我们使用的是模拟信号来描述一段声音
而计算机采用的是数字信号,所以我们必须转化为它能够识别的语言
采样频率帧率
常用采样频率:44.1KHz,是每秒取样44100次.低于这个值声音会有较明显的损失,而高于这个值,人耳已经很难分辨,并且加大了所需空间。采样大小、采样宽度
采样大小就是指的采样精度,因为光有频率信息是不够的,必须获取该频率能量的值并且量化,用于表示信号强度(就好比你锤了一下桌子,用来描述你用了多大的力量去锤了桌子),采样精度一般有8,16位或者更多,数值越大,解析度就越高,录制和回放的声音就越真实;比特率
声音有轻有响,影响声音响度的物理要素是振幅,作为数字信号,也需要能够描述出音乐的轻响,所以就有了bit这个单位,用来划分声音的轻响等级
例如16bit,就是指把波形的振幅划为2的16次方,也就是65536个等级.比特率越高,越能细致的重现乐曲的轻响变化.
- 音频格式
有损格式:MP3,AAC,WMA等
无损格式:PCM.WAV,ALS,ALAC等
有损格式一般去除的,是人类很难分辨或者无法听见的声音,极大的减少文件体积,在专业领域,则需要保证音乐的原始质量,故多使用无损格式。
备注:我们实验中使用的数据是标准无损.wav格式。
2. 数据格式以及示例
肺音频格式
| index | names | type | size | Hospital_data | Match_data |
| 0 | nchannels:声道数 | int | 1 | 1 | 1 |
| 1 | sampwidth:量化位数(byte) | int | 1 | 2 | 2 |
| 2 | framerate:采样频率 | int | 1 | 40960 | 4000 |
| 3 | nframes:采样点数 音频帧的数量 | int | 1 | 614400 | 129200 |
| 4 | comptype:压缩类型 | str | 1 | NONE | NONE |
| 5 | compname: | str | 1 | not compressed | not compressed |
f.getparams();
nframes = framerate*time(ms)
其中有两种数据:
- Hospital_data : 朗朗肺音样本 示例
- Match_data : ICBHI 比赛数据
3. 问题以及传统模型
当我们拥有数据之后,因为肺音作为一种信号信息,所以传统来说,会使用信号分析相关知识,进而得到分类、以及辅助诊断。
分析一下,目前我们的目的是:数据 ——————> 模型 ——————> 分类结果, 如下图所示

基本流程处理流程如下:
数据采集———信号处理———数据特征提取———建立分类模型———测试集测试——结果分析
4. 现有模型以及不足
以往处理方法
- 主要是时域与频域方法分析识别肺音信号
- 短时傅里叶变换(STFT)、小波分析识别、高阶谱分析法
- 小波和小波波分析技术噪声抑制
- SVM支持向量机
但是都有一个共同点就是:预处理需要很多繁琐的预处理步骤,泛化能力很弱,如下:
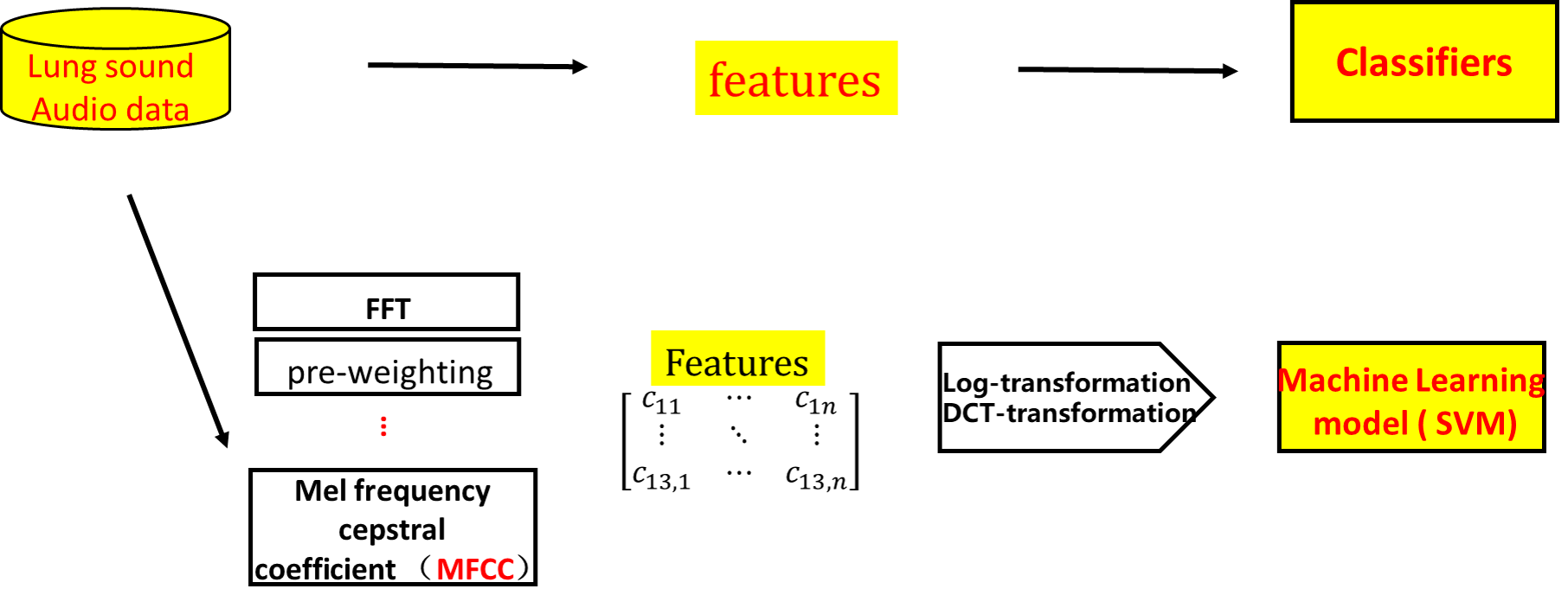
5. 数据的介绍与生成
考虑到深度学习强大的自适应能力,我们考虑如何使用深度学习等ai技术实现肺音自动分类。
如何把我们的数据转化为我们模型所需要的数据库呢?
这里需要先了解一下频谱图:
1.波形图
横坐标是时间,纵坐标是幅值,表示的是所有频率叠加的正弦波幅值的总大小随时间的变化规律。
现将该复合波形进行傅里叶变换,拆解还原成每个频率上单一的正弦波构成,相当于把二维的波形图往纸面方向拉伸,变成了三维的立体模型,而拉伸方向上的那根轴叫频率,现在从小到大每个频率点上都对应着一条不同幅值和相位的正弦波
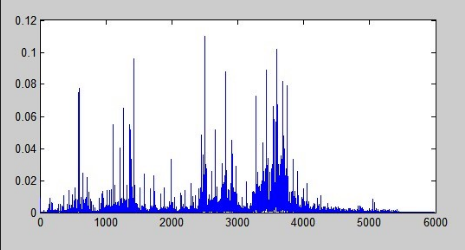
2.频谱
在这个立体模型的频率轴方向上进行切片,丢去时间轴,形成以横坐标为频率,纵坐标为幅值的频谱图,表示的是一个静态的时间点上各频率正弦波的幅值大小的分布状况
3.语谱图、声谱图
其实就是这个图的俯视图,颜色深度代表强度。
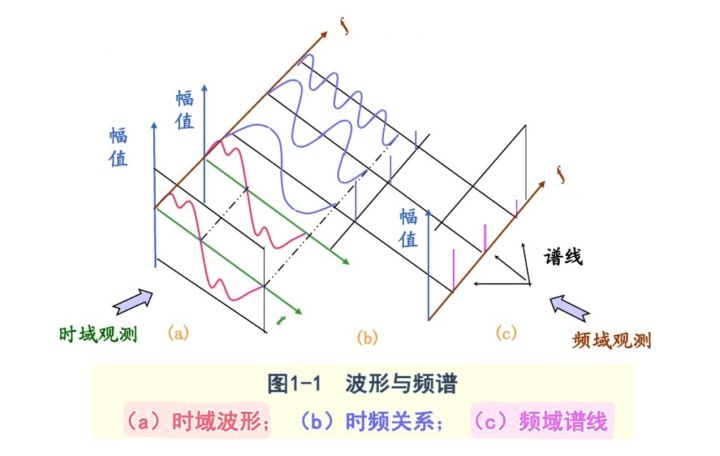
我们将现有的肺音音频数据转化成我们的语谱图,从而使用图像识别的方法进行处理。
语谱图示例:
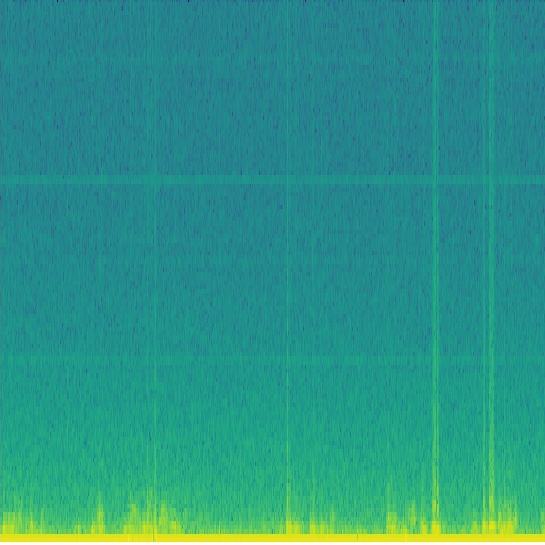
从图中可以看到明显的一条条横方向的条纹,我们称为“声纹”,可以看作特征,这就是音频转化为语谱图可以成立的依据;
条纹的地方实际是颜色深的点聚集的地方,随时间延续,就延长成条纹,也就是表示音频中频率值为该点横坐标值的能量较强,在整个语音中所占比重大,我们可以把它称作“特征”。
6. 模型核心内容说明
几乎任何数据、想要实现:分类也好、识别也好,其中的一个关键步骤就是特征提取

那么我们的整体模型架构如下:
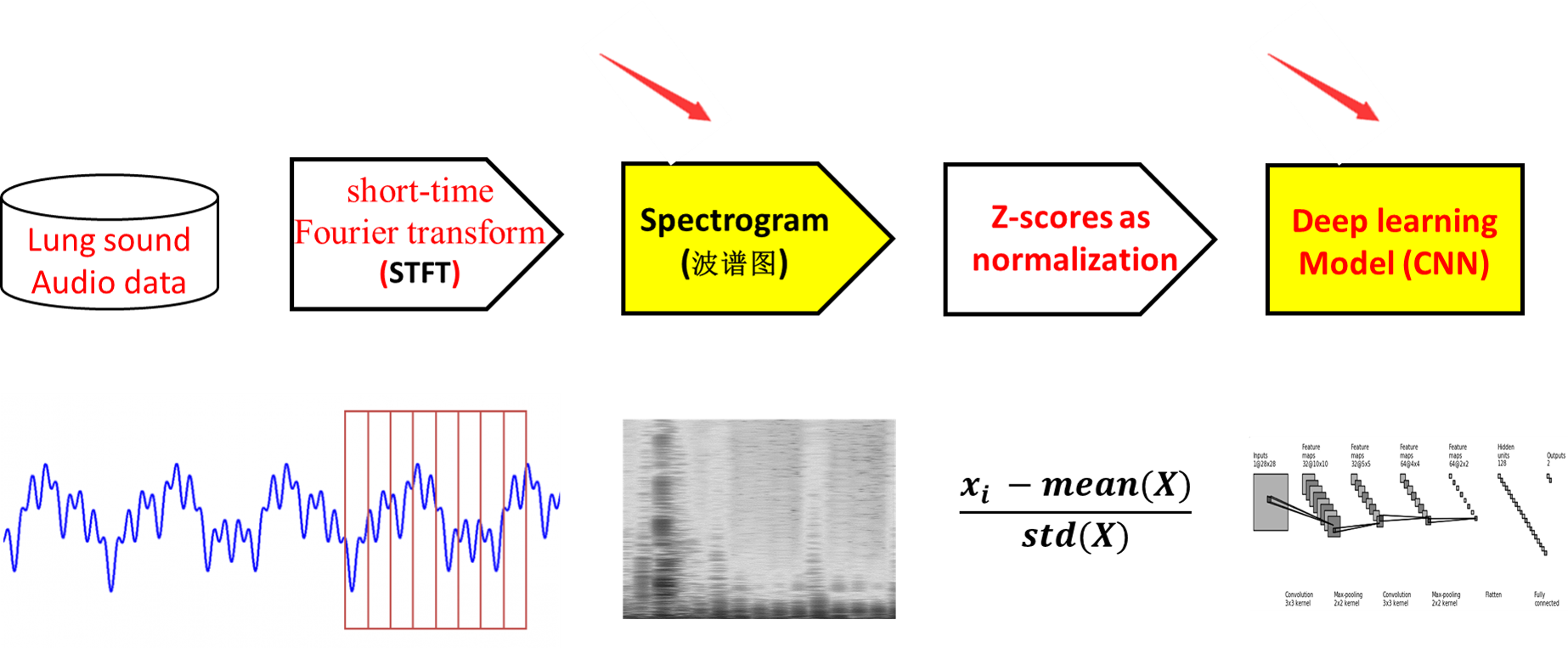
强调一点,只需要通过一步短时傅里叶变换(STFT)就可以得到Spectrogram,也就是后面深度学习CNN模型的输入数据(训练数据)。
接下来说说最核心的两部分,图像数据spectrogram的生成,以及深度学习模型的结构。
1. 图像数据spectrogram的生成
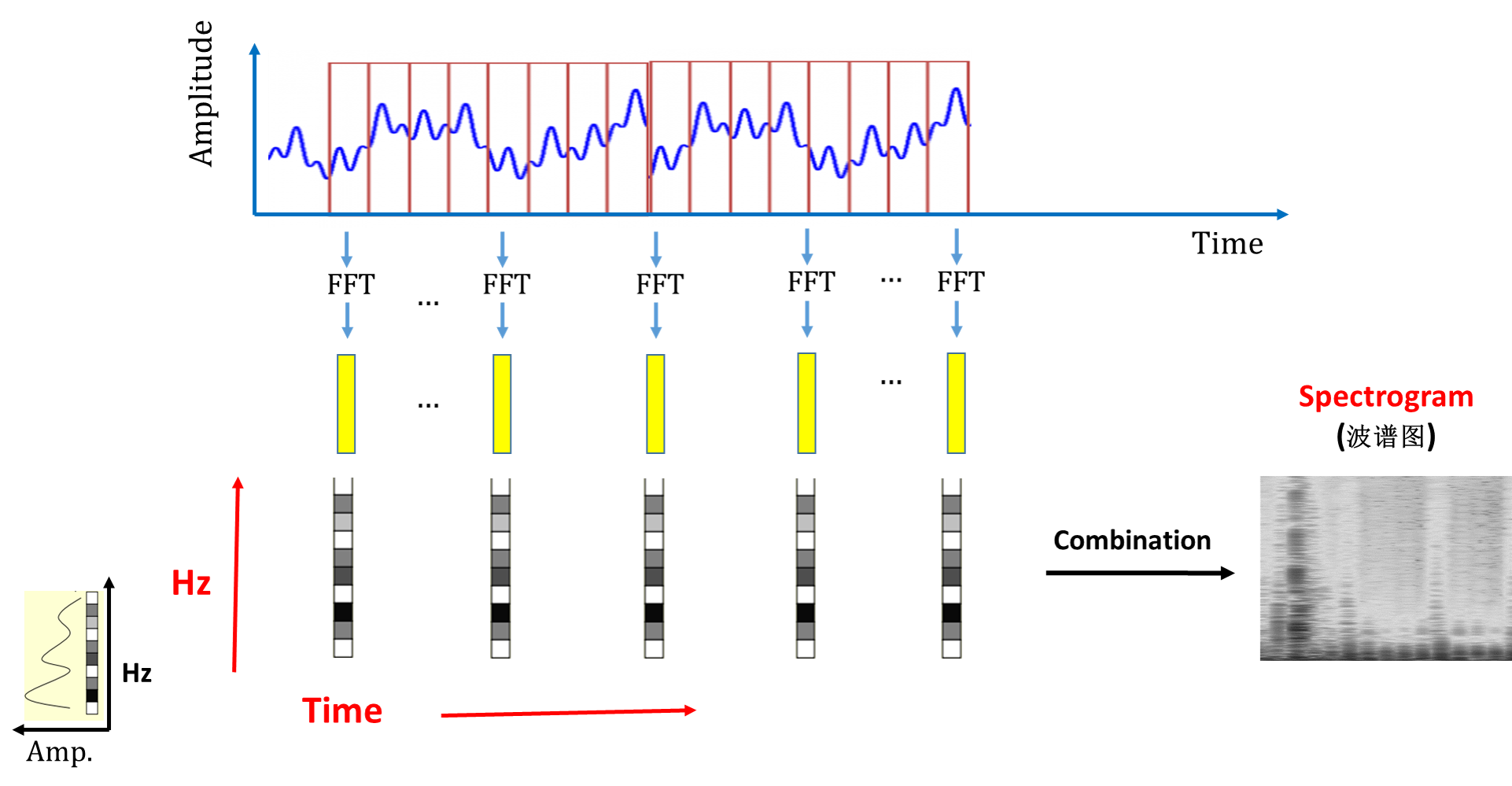
如图所示,我们通过对音频信号的分窗(win-framing),进行短时傅里叶变换,得到变换后的“矩阵”。
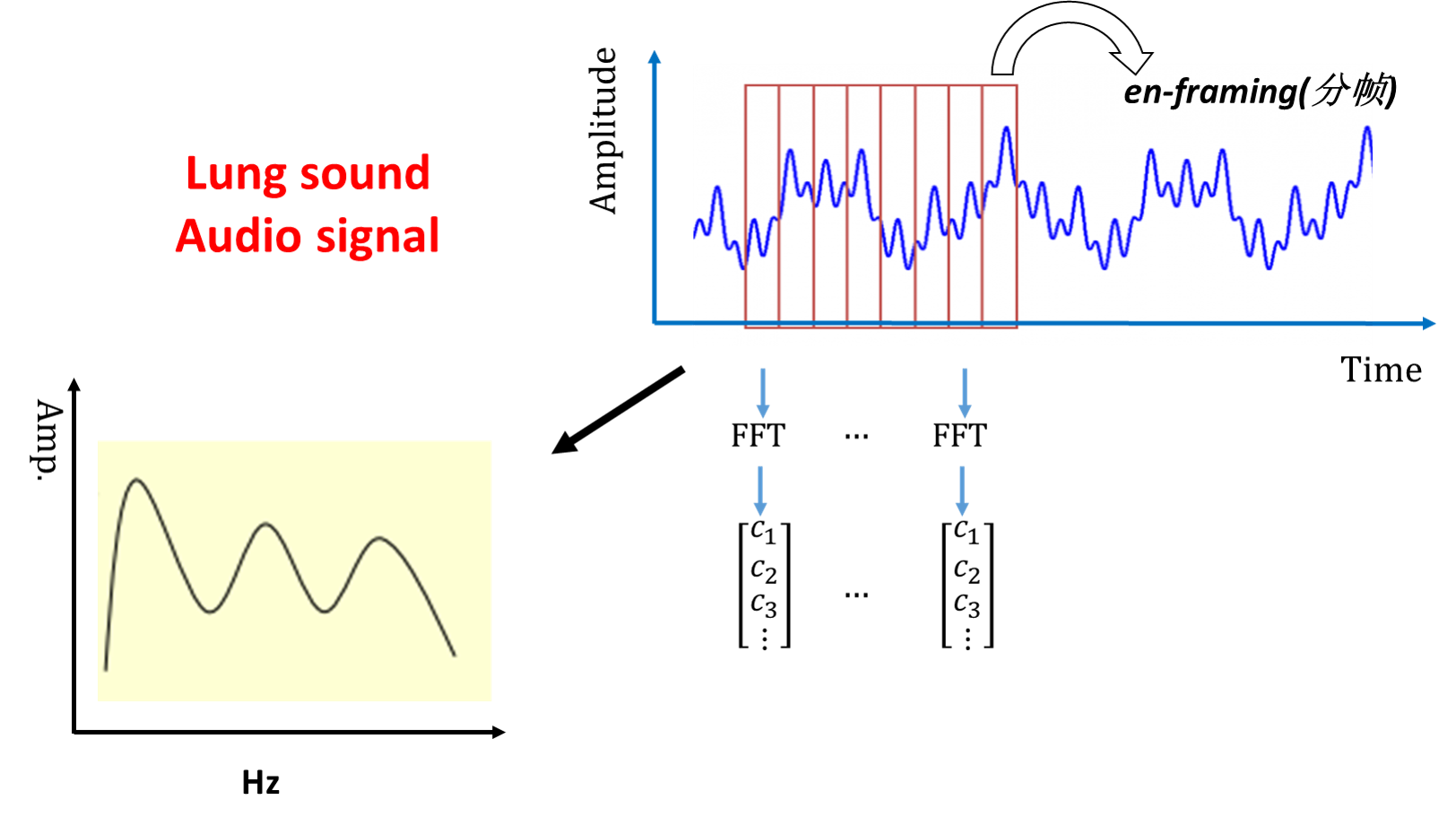
进而我们可以看到:
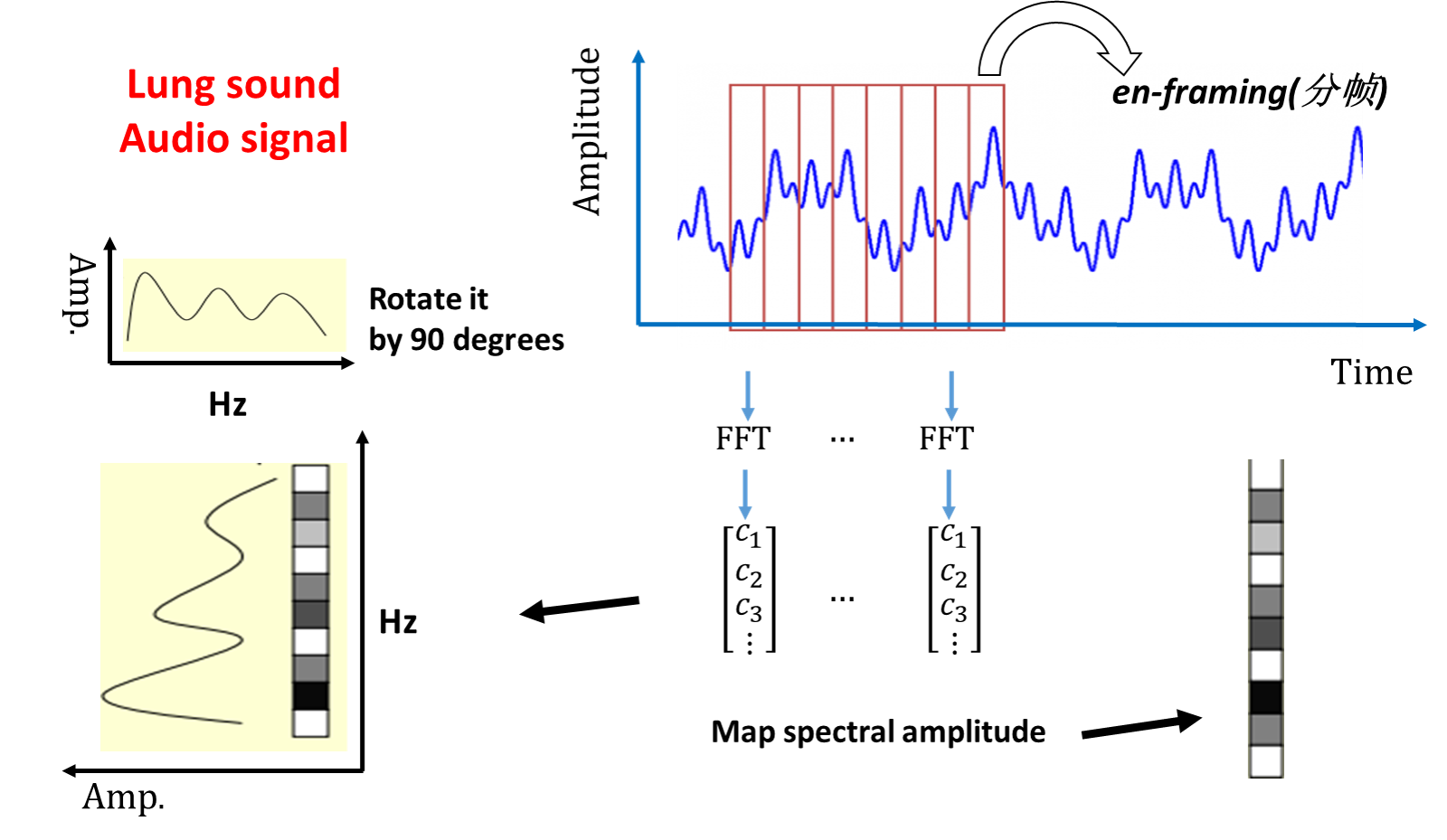
当我们合并每一部分可以得到最后的图像矩阵,也就是我们的spectrogram。
2. 深度学习模型的结构
当我们的构建好数据库,就可以通过以下模型实现特征提取及分类
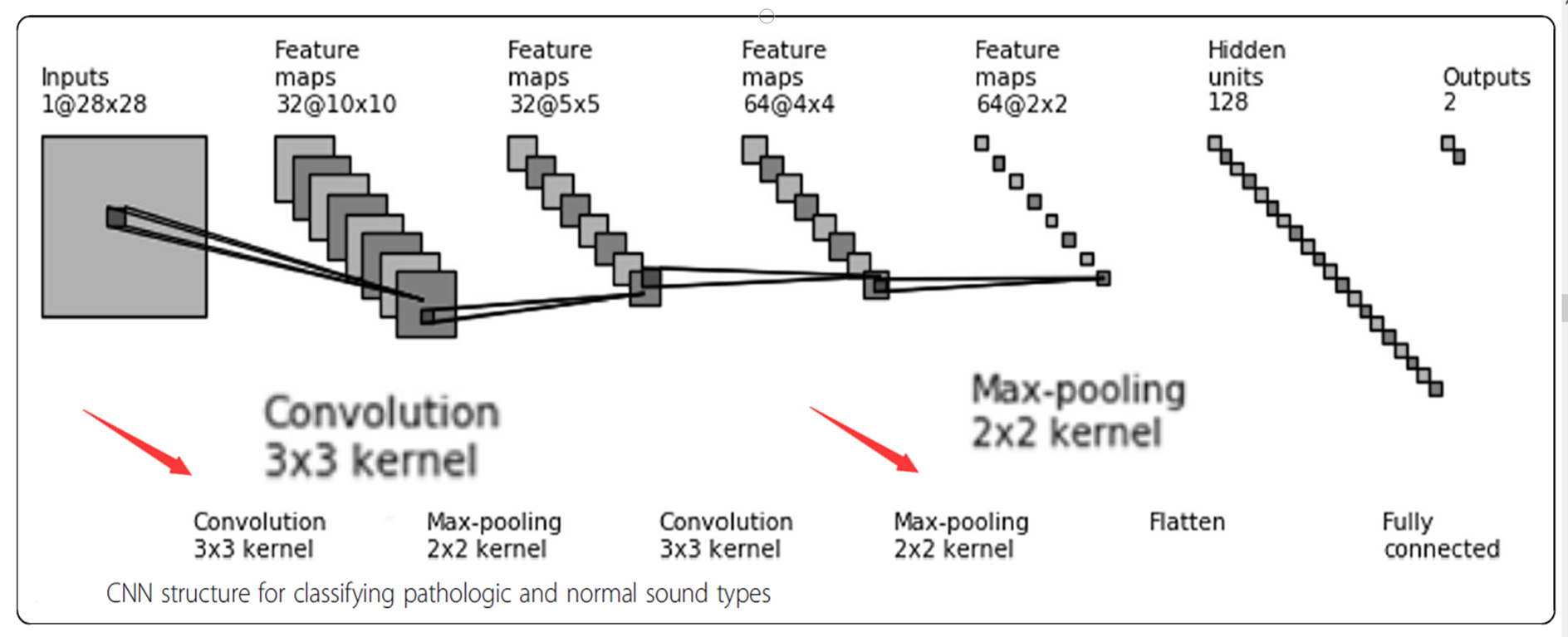
我们使用常见的3x3的卷积核、以及2x2的最大池化层,多次得到最后把特征图展开为128x1 的列矩阵,连接到最后的输出层。
那么整个效果如下:
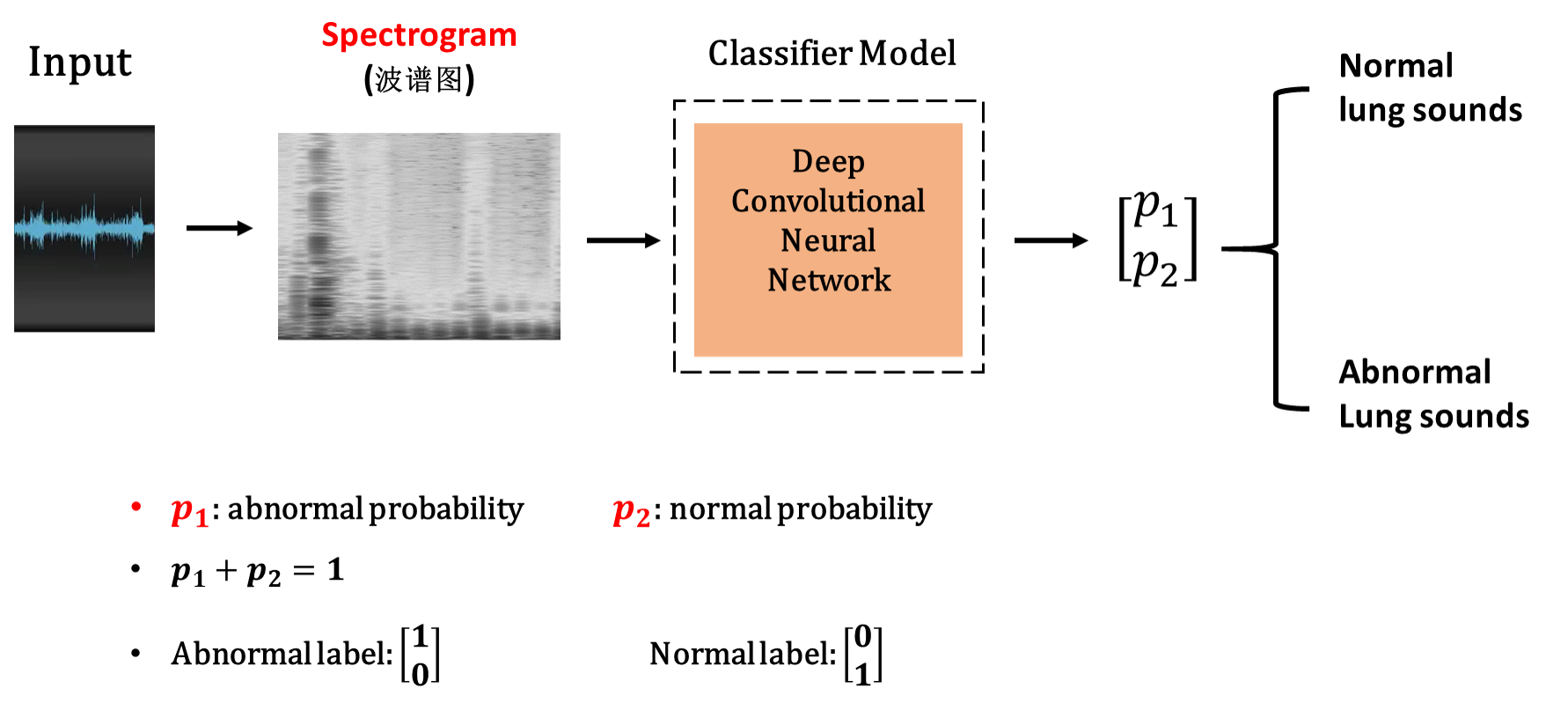
那么和传统的信号处理方法相比,我们的模型的最大优势是不需要人工干预,只需要使用深度学习模型学习肺音特征,如图:
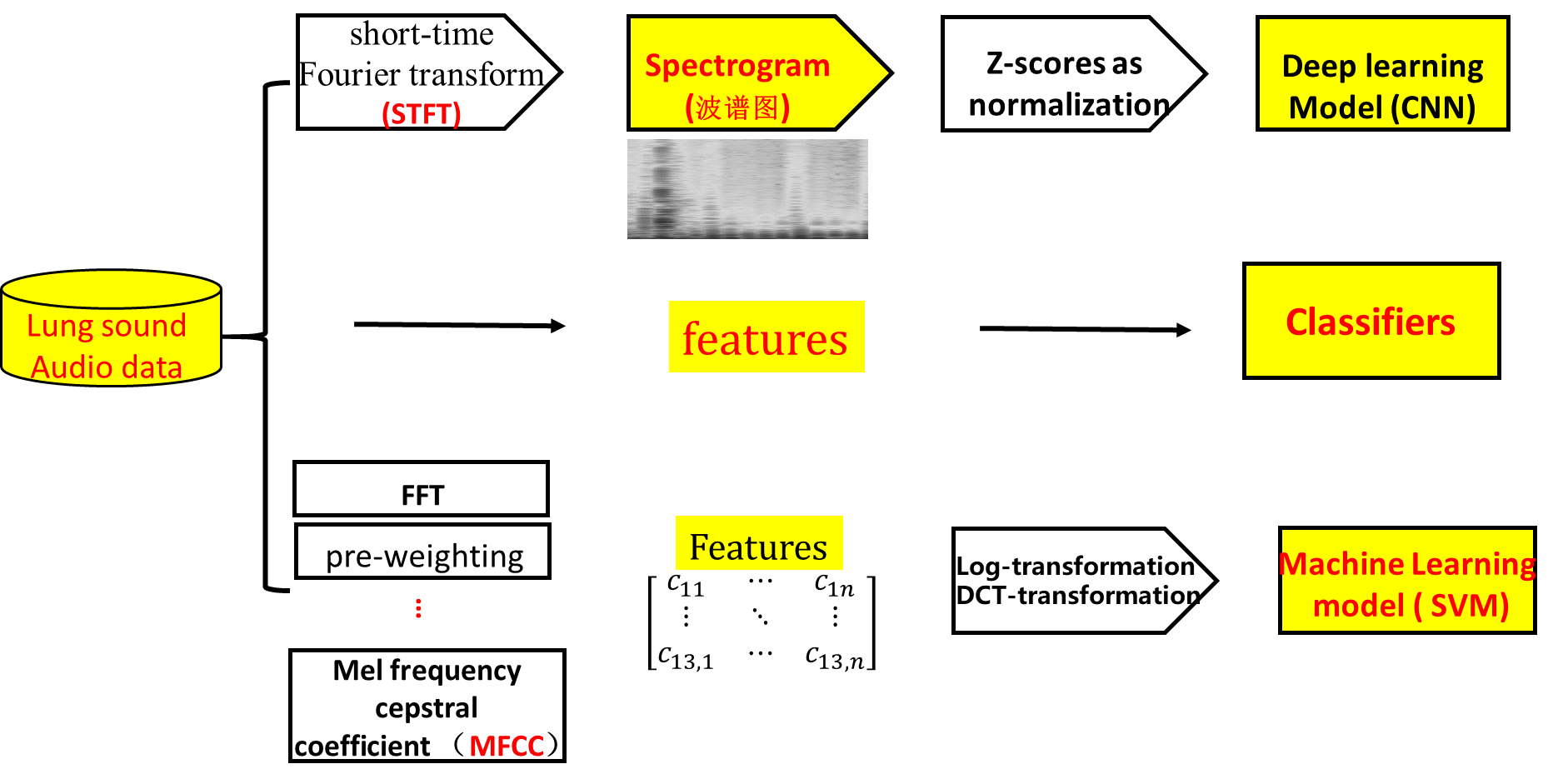
中间为一般处理步骤:数据——>特征———>分类器
上方即为我们的模型、以及下方为传统模型、可以看得出。
我们模型的优势:
- 我们的肺音检测模型清晰、简单明了
- 我们的模型使用了几乎最少的处理步骤
- 在提取特征之前给CNN网络模型提供了接近最真实的数据
7. 模型部分结果说明
545尺寸图像数据信息
数据结果:频谱图(545*545*3 = 891075)
| Normal | Abnormal | All | Time | PosSample | NegSample |
|---|---|---|---|---|---|
| 13 | 64 | 77 | 15s | 13 | 64 |
| 模型 | 结果 | 改进 | 解决办法 |
|---|---|---|---|
| knn | 0.3 | ||
| svm | 0.82 | ||
| cnn | 0. |
36尺寸图像数据信息
把15s原始数据分割,每5秒一个频谱图,则数据量可以扩增3倍
数据结果:频谱图(36*36*3 = 3888)
| Normal | Abnormal | All | Time | PosSample | NegSample |
|---|---|---|---|---|---|
| 13*3=39 | 64*3=192 | 231 | 5 | 39 | 192 |
| 模型 | 结果 | 改进 | 解决办法 |
|---|---|---|---|
| knn | 0.3 | ||
| svm | 0.82 | ||
| ann | 0.93 | x*50*2 | |
| cnn | 0.82 |
以上即为我们的模型介绍、以及测试结果。
附录:医学英文名词对照
- 水泡: vesicular 美 [və'sɪkjʊlə]
- 肺泡:alveolus 美 [æl'vi:ələs]
- 支气管:bronchus ['brɑŋkəs];bronchi-; bronchio;
- 支气管肺泡的:broncho-alveolar
- 支气管肺泡音:bronchovesicular
- 呼吸的:respiratory 美 ['resp(ə)rə.tɔri]
- 支气管音:Bronchophony
- 胸语音: pectoriloquy
- 胸膜的: pleural 美 ['plʊərə]
- 肺的: pulmonary 美 ['pʌlmə.neri]
- 喘息,喘鸣: wheeze 美 [hwiz]
- 哮鸣音:wheezing sound,[hwiz]
- 湿罗音:moist rales
- 爆裂音:crackle 美 ['kræk(ə)l]
- 干罗音:Rhonchus
epiglottis
美 [ˌepɪˈɡlɑtɪs]
trachea
美 [ˈtreɪkiə]
alveolus
美 [æl'vi:ələs]
