@qidiandasheng
2022-08-14T09:45:49.000000Z
字数 26087
阅读 4909
iOS里的线程同步(锁机制)
iOS理论
前言
什么是线程安全问题
如果一段代码所在的进程中有多个线程在同时运行,那么这些线程就有可能会同时运行这段代码。假如多个线程每次运行结果和单线程运行的结果是一样的,而且其他的变量的值也和预期的是一样的,就是线程安全的。或者说:一个类或者程序所提供的接口对于线程来说是原子操作或者多个线程之间的切换不会导致该接口的执行结果存在二义性,也就是说我们不用考虑同步的问题。
由于可读写的全局变量及静态变量可以在不同线程修改,所以这两者也通常是引起线程安全问题的所在。在 Objective-C 中还包括属性和实例变量(实际上属性和实例变量本质上也可以看做类内的全局变量)。
所以就需要引入一种同步锁机制(lock)来防止多线程操作同一份代码而引发的安全问题。
相关概念
- 时间片轮转调度算法:是目前操作系统中大量使用的线程管理方式,大致就是操作系统会给每个线程分配一段时间片(通常100ms左右),这些线程都被放在一个队列中,CPU只需要维护这个队列,当队首的线程时间片耗尽就会被强制放到队尾等待,然后提取下一个队首线程执行
- 原子操作:“原子”一般指最小粒度,不可分割;原子操作也就是不可分割,不可中断的操作
- 临界区 :每个进程中访问临界资源的那段代码称为临界区(Critical Section)(临界资源是一次仅允许一个进程使用的共享资源)。每次只准许一个进程进入临界区,进入后不允许其他进程进入。不论是硬件临界资源,还是软件临界资源,多个进程必须互斥地对它进行访问
- 忙等(busy-waiting): 试图进入临界区的线程,占着CPU而不释放的状态
- 睡眠(sleep-waiting):试图进入临界区的线程,会进入睡眠状态,主动让出时间片,不会再占着CPU而不释放
- 上下文切换(Context Switch):当线程进入睡眠(sleep-waiting)的时候,cpu的核心会进行上下文切换,将该线程置于等待队列中,而其他线程就会继续执行任务,上下文切换需要花费时间
- 锁的拥有者(Lock Ownership):如果锁没有拥有者,则当它被某一条线程获取时,其他任意一条线程都可以对它进行解锁;如果锁只能有单一的拥有者,则当它被某一条线程获取时,只有这条线程可以对它进行解锁;如果锁可以有多个拥有者,则它可以同时被某多条线程获取
- 死锁:指两个或两个以上的进程(线程)在运行过程中因争夺资源而造成的一种僵局(Deadly-Embrace) ) ,若无外力作用,这些进程(线程)都将无法向前推进。一般在获得锁的线程中再次进行加锁就会发生死锁
- 饥饿(Starvation):指一个进程一直得不到资源
数据破坏
在理解如何保障临界代码的安全之前,我们需要了解数据为什么在多线程环境下被破坏。以简单的i++为例,这句代码将i自增一次,在编译成汇编代码后实际上会有三步操作:
movl -0x24(%rbp), %r8daddl $0x1, %r8dmovl %r8d, -0x24(%rbp)
完成一次i++总共分为三步:
取出
i存放到临时寄存器上对寄存器的值
+1将计算后的值存放回
i的内存
假设线程A执行i++这句代码,在完成将计算后的数值存储回i的内存之前,线程B也开始执行这句代码,最终的结果是两次i++之后,值仍然为1,这时候数据就发生了破坏。
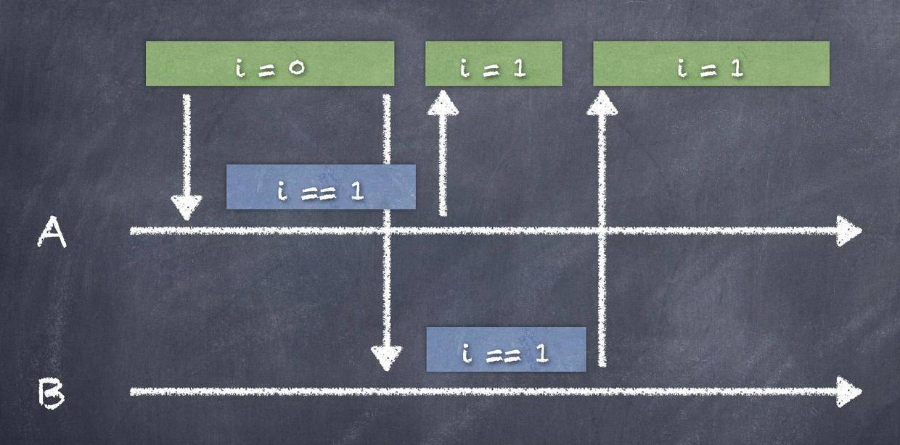
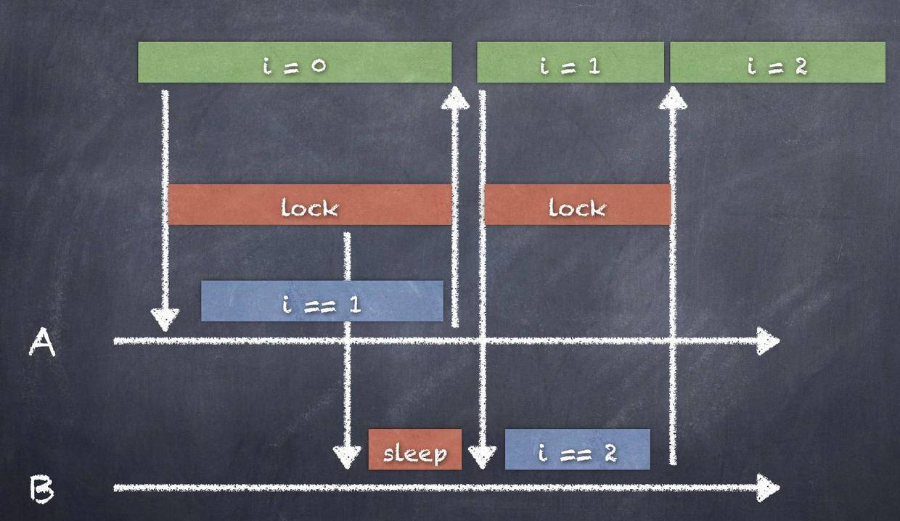
这时候使用线程锁,那么B就会等待A完成存储数据后才能执行,加锁后,B在执行i++之前会检测指令是否被锁住。如果被锁住,则开始休眠,直到A完成操作后被唤醒继续执行代码。这时候i++在多线程环境下是安全的。
原子性
nonatomic(非原子性):
非原子属性,线程不安全的,不会加锁效率高。在像iPhone这种内存较小的移动设备上,如果没有多线程间的通信,那么nonatomic就是一个非常好的选择。atomic(原子性):
原子属性,读写安全,但线程并不安全的,内部加了自旋锁,消耗大量资源效率相对低,会给系统自动生成的getter/setter方法会进行加锁操作。
这里所说的原子性就是上面说的数据破坏中的加锁,单独的多个写操作是原子性的,也就是上面所说的写操作三步完成后才能进行另一次写操作,所以并不会造成数据破坏。
但读写安全并不代表线程安全,比如以下的例子:
如果线程 A 调了 getter,与此同时线程 B 、线程 C 都调了 setter——那最后线程 A get 到的值,有3种可能:可能是 B、C set 之前原始的值,也可能是 B set 的值,也可能是 C set 的值。同时,最终这个属性的值,可能是 B set 的值,也有可能是 C set 的值。所以atomic并不能保证对象的线程安全。
优先级反转
主要出现在自旋锁上面,等待锁的线程会处于忙等(busy-wait) 状态,一直占用着 CPU 资源。循环等待是一种很大的浪费,但浪费还不是循环等待的唯一问题,它还可能造成 CPU 调度的 优先级反转(倒挂)。
在 iOS 中,系统维护了 5 个不同的线程优先级/Qos:background、utility、default、user-initiated、user-interactive。高优先级线程始终会在低优先级线程前执行,一个线程不会受到比它更低优先级线程的干扰。这种线程调度算法存在潜在的优先级反转的问题。
优先级反转就是高优先级的线程等待低优先级的线程。如果一个低优先级的线程获得锁并访问共享资源,这时一个高优先级的线程也尝试获得这个锁,它会处于忙等状态状态从而占用大量 CPU 片。此时低优先级线程无法与高优先级线程争夺 CPU 时间(抢不过),从而导致任务迟迟完不成,无法释放 lock。
比如两个线程A和B,A的优先级高于B,但这时候B线程先获得了锁,然后A线程会进入忙等状态。但由于A的优先级较高,所以获得了CPU资源,因此B无法获得CPU资源执行下面的任务。所以就变成了A等待B释放锁,B又等待着A释放CPU资源。最后形成了一个循环无法结束造成死锁。
读写者问题
有读者和写者两组并发线程,共享同一数据,当两个或以上的读线程同时访问共享数据时不会产生副作用,但若某个写线程和其他线程(读线程或写线程)同时访问共享数据时则可能导致数据不一致的错误。因此要求:
允许多个读者可以同时对共享数据执行读操作;
只允许一个写者写共享数据;
任一写者在完成写操作之前不允许其他读者或写者工作;
写者执行写操作前,应让已有的读者和写者全部退出;
NSLock(效率不高的锁)
//实现一个简单的cache- (void)setCache:(id)cacheObject forKey:(NSString *)key {if (key.length == 0) {return;}[_cacheLock lock];self.cacheDic[key] = cacheObject;...[_cacheLock unlock];}- (id)cacheForKey:(NSString *key) {if (key.length == 0) {return nil;}[_cacheLock lock];id cacheObject = self.cacheDic[key];...[_cacheLock unlock];return cacheObject;}
上述代码用互斥锁来实现多线程读写,做到了数据的安全读写,但是效率却并不是最高的,因为这种情况下,虽然写操作和其他操作之间是互斥的,但同时读操作之间却也是互斥的,这会浪费cpu资源。
那我们如果读操作不加锁呢?那读操作就不会互斥了啊,但其实这样读操作和写操作就并不互斥了,因为先写再读的话那没问题,读操作要等写操作解锁。然而先读操作的话,读的过程中容易被写操作侵占资源,造成线程不安全。
//实现一个简单的cache- (void)setCache:(id)cacheObject forKey:(NSString *)key {if (key.length == 0) {return;}[_cacheLock lock];self.cacheDic[key] = cacheObject;...[_cacheLock unlock];}- (id)cacheForKey:(NSString *key) {if (key.length == 0) {return nil;}id cacheObject = self.cacheDic[key];...return cacheObject;}
pthread_rwlock_t(读者写者锁)
// Initialization of lock, pthread_rwlock_t is a value type and must be declared as var in order to refer it later. Make sure not to copy it.var lock = pthread_rwlock_t()pthread_rwlock_init(&lock, nil)// Protecting read section:pthread_rwlock_rdlock(&lock)// Read shared resourcepthread_rwlock_unlock(&lock)// Protecting write section:pthread_rwlock_wrlock(&lock)// Write shared resourcepthread_rwlock_unlock(&lock)// Clean uppthread_rwlock_destroy(&lock)
接口简洁但是却不友好,需要注意pthread_rwlock_t是值类型,用=赋值会直接拷贝,不小心就会浪费内存,另外用完后还需要记得销毁,容易出错
GCD barrier(读者写者锁)
dispatch_barrier_async / dispatch_barrier_sync并不是专门用来解决读者写者问题的,barrier主要用于以下场景:当执行某一任务A时,需要该队列上之前添加的所有操作都执行完,而之后添加进来的任务,需要等待任务A执行完毕才可以执行,从而达到将任务A隔离的目的。
如果将barrier任务之前和之后的并发任务换为读操作,barrier任务本身换为写操作,就可以将dispatch_barrier_async / dispatch_barrier_sync当做读者写者锁来使用了。
//实现一个简单的cache(使用读者写者锁)static dispatch_queue_t queue = dispatch_queue_create("com.gfzq.testQueue", DISPATCH_QUEUE_CONCURRENT);- (void)setCache:(id)cacheObject forKey:(NSString *)key {if (key.length == 0) {return;}dispatch_barrier_async(queue, ^{self.cacheDic[key] = cacheObject;...});}- (id)cacheForKey:(NSString *key) {if (key.length == 0) {return nil;}__block id cacheObject = nil;dispatch_async(queue, ^{cacheObject = self.cacheDic[key];...});return cacheObject;}
这样实现的cache就可以并发执行读操作,同时又有效地隔离了写操作,兼顾了安全和效率。
atomic手动实现setter和getter
我们上面说过atomic系统内部会自动生成setter和getter方法,并在内部实现自旋锁:
// getterid objc_getProperty(id self, SEL _cmd, ptrdiff_t offset, BOOL atomic){// ...if (!atomic) return *slot;// Atomic retain release worldspinlock_t& slotlock = PropertyLocks[slot];slotlock.lock();id value = objc_retain(*slot);slotlock.unlock();// ...}
// setterstatic inline void reallySetProperty(id self, SEL _cmd, id newValue, ptrdiff_t offset, bool atomic, bool copy, bool mutableCopy){// ...if (!atomic) {oldValue = *slot;*slot = newValue;} else {spinlock_t& slotlock = PropertyLocks[slot];slotlock.lock();oldValue = *slot;*slot = newValue;slotlock.unlock();}// ...}
但是当我们自己实现setter和getter方法时就需要自己加锁了,这里我们用上面提到的GCD barrier来实现,这样在做到原子性的同时,getter之间还可以并发执行,比直接把setter和getter都放到串行队列或者加普通锁要更高效。
@property (atomic, copy) NSString *someString;- (NSString *)someString {__block NSString *tempString;dispatch_async(_syncQueue, ^{tempString = _someString;});return tempString;}- (void)setSomeString :(NSString *)someString {dispatch_barrier_async(_syncQueue, ^{_someString = someString...}}
使用场景
并非所有的读写场景都要用读者写者锁,比如YYCache
//读cache- (id)objectForKey:(id)key {if (!key) return nil;pthread_mutex_lock(&_lock);_YYLinkedMapNode *node = CFDictionaryGetValue(_lru->_dic, (__bridge const void *)(key));if (node) {node->_time = CACurrentMediaTime();[_lru bringNodeToHead:node];}pthread_mutex_unlock(&_lock);return node ? node->_value : nil;}
//写cache- (void)setObject:(id)object forKey:(id)key withCost:(NSUInteger)cost {if (!key) return;if (!object) {[self removeObjectForKey:key];return;}pthread_mutex_lock(&_lock);_YYLinkedMapNode *node = CFDictionaryGetValue(_lru->_dic, (__bridge const void *)(key));NSTimeInterval now = CACurrentMediaTime();if (node) {_lru->_totalCost -= node->_cost;_lru->_totalCost += cost;node->_cost = cost;node->_time = now;node->_value = object;[_lru bringNodeToHead:node];} else {node = [_YYLinkedMapNode new];node->_cost = cost;node->_time = now;node->_key = key;node->_value = object;[_lru insertNodeAtHead:node];}if (_lru->_totalCost > _costLimit) {dispatch_async(_queue, ^{[self trimToCost:_costLimit];});}if (_lru->_totalCount > _countLimit) {_YYLinkedMapNode *node = [_lru removeTailNode];if (_lru->_releaseAsynchronously) {dispatch_queue_t queue = _lru->_releaseOnMainThread ? dispatch_get_main_queue() : YYMemoryCacheGetReleaseQueue();dispatch_async(queue, ^{[node class]; //hold and release in queue});} else if (_lru->_releaseOnMainThread && !pthread_main_np()) {dispatch_async(dispatch_get_main_queue(), ^{[node class]; //hold and release in queue});}}pthread_mutex_unlock(&_lock);}
这里的cache由于使用了LRU淘汰策略,每次在读cache的同时,会将本次的cache放到数据结构的最前面,从而延缓最近使用的cache被淘汰的时机,因为每次读操作的同时也会发生写操作,所以这里直接使用pthread_mutex互斥锁,而没有使用读者写者锁。
所以多线程读写锁场景要符合:
(1)存在单纯的读操作(即读任务里没有同时包含写操作);
(2)读者数量较多,而写者数量较少。
自旋锁和互斥锁
自旋锁和互斥锁:
相同点
都能保证同一时间只有一个线程访问共享资源。都能保证线程安全。不同点:
互斥锁:如果共享数据已经有其他线程加锁了,线程会进入休眠状态等待锁。一旦被访问的资源被解锁,则等待资源的线程会被唤醒。
自旋锁:如果共享数据已经有其他线程加锁了,线程会以死循环的方式等待锁,一旦被访问的资源被解锁,则等待资源的线程会立即执行。打个比方
自旋锁表示有个人在上厕所,外面那个人一直在门口等待,不停的确认里面的人是否结束了。
而互斥锁则是有个人在上厕所,然后外面的那个人在睡觉,等里面的那个人上完了出来叫醒外面的这个人告诉他可以上厕所了。结论
所以说自旋锁效率会比较高,但是消耗的CPU资源会更多,所以我们一般耗时的操作都会选择互斥锁,这样就不会占用过多的CPU资源。
补充
在iOS中使用自旋锁其实是会有安全问题的,主要就是在线程的高低优先级时产生的问题。
具体来说,如果一个低优先级的线程获得锁并访问共享资源,这时一个高优先级的线程也尝试获得这个锁,它会处于 spin lock 的忙等状态从而占用大量 CPU。此时低优先级线程无法与高优先级线程争夺 CPU 时间,从而导致任务迟迟完不成、无法释放 lock。
具体可以参考ibireme的这篇文章:不再安全的 OSSpinLock。
线程不安全例子
以下例子是线程不安全的:
@property(nonatomic,assign)int ticketsCount;- (void)ticketTest{self.ticketsCount = 50;dispatch_queue_t queue = dispatch_get_global_queue(0, 0);for (NSInteger i = 0; i < 5; i++) {dispatch_async(queue, ^{for (int i = 0; i < 10; i++) {[self sellingTickets];}});}}//卖票- (void)sellingTickets{int oldMoney = self.ticketsCount;sleep(.2);oldMoney -= 1;self.ticketsCount = oldMoney;NSLog(@"当前剩余票数-> %d", oldMoney);}
如果我们把@property(nonatomic,assign)int ticketsCount;改为@property(atomic,assign)int ticketsCount;。我们发现最后剩余的票数也并不为0,这也就验证了上面所说的原子性只表示的是单独读写的原子性,并不能保证线程安全。
打个比方比如我们线程一在读int oldMoney = self.ticketsCount;时,线程二也读了这个值,则这两个读之前的操作是原子性的,并没有影响。但线程一的写和线程二的读并不是互斥的,线程二的读并不用等线程一的写完成,所以线程一和线程二读的值就可能一样,这样就造成了我们所说的线程不安全。
所以原来的原子性的粒度只分到了读和写上,那我们现在把一次读写当成一次“原子操作”,就是读写合用一把锁,也就解决了上面的问题。
以下是线程安全的例子:
@property(nonatomic,assign)int ticketsCount;pthread_mutex_t mutex;- (void)viewDidLoad {pthread_mutex_init(&mutex, NULL);}- (void)ticketTest{self.ticketsCount = 50;dispatch_queue_t queue = dispatch_get_global_queue(0, 0);for (NSInteger i = 0; i < 5; i++) {dispatch_async(queue, ^{for (int i = 0; i < 10; i++) {[self sellingTickets];}});}}//卖票- (void)sellingTickets{pthread_mutex_lock(&mutex);int oldMoney = self.ticketsCount;sleep(.2);oldMoney -= 1;self.ticketsCount = oldMoney;pthread_mutex_unlock(&mutex);NSLog(@"当前剩余票数-> %d", oldMoney);}
iOS中线程同步方案(GCD和各种锁)
锁的性能分析:

我们现在用Objective-C中几种不同方式来实现锁。
我们假设创建了一个类StudentsObject,这是一个操作数据库的类,有两个方法addStudent和removeStudent。我们不希望操作数据库时有多个线程同时调用这个对象,产生不可预期的问题,我们希望addStudent和removeStudent是互斥的。
类定义如下:
#import "StudentsObject.h"@implementation StudentsObject- (void)addStudent{NSLog(@"%@",NSStringFromSelector(_cmd));}- (void)removeStudent{NSLog(@"%@",NSStringFromSelector(_cmd));}@end
GCD之同步队列
- (void)dispatch_queue_serial{StudentsObject *obj = [[StudentsObject alloc] init];dispatch_queue_t queue = dispatch_queue_create("myQueue", DISPATCH_QUEUE_SERIAL);dispatch_async(queue, ^{[obj addStudent];sleep(3);});dispatch_async(queue, ^{[obj removeStudent];});}
输出:
2020-07-02 18:30:53.886143+0800 DSLockDemo[72683:4712327] addStudent2020-07-02 18:30:56.890092+0800 DSLockDemo[72683:4712327] removeStudent
GCD之栅栏函数
dispatch_queue_t queue = dispatch_queue_create(0, DISPATCH_QUEUE_CONCURRENT);dispatch_async(queue, ^{__block BOOL isExecuted = NO;NSURLSessionDataTask *task = [[NSURLSession sharedSession] dataTaskWithRequest:[NSURLRequest requestWithURL:[NSURL URLWithString:@"http://www.baidu.com"]] completionHandler:^(NSData * _Nullable data, NSURLResponse * _Nullable response, NSError * _Nullable error) {NSLog(@"A");isExecuted = YES;}] ;[task resume];while (isExecuted == NO) {[[NSRunLoop currentRunLoop] runMode:NSDefaultRunLoopMode beforeDate:[NSDate distantFuture]];}});dispatch_async(queue, ^{__block BOOL isExecuted = NO;NSURLSessionDataTask *task = [[NSURLSession sharedSession] dataTaskWithRequest:[NSURLRequest requestWithURL:[NSURL URLWithString:@"http://www.baidu.com"]] completionHandler:^(NSData * _Nullable data, NSURLResponse * _Nullable response, NSError * _Nullable error) {NSLog(@"B");isExecuted = YES;}] ;[task resume];while (isExecuted == NO) {[[NSRunLoop currentRunLoop] runMode:NSDefaultRunLoopMode beforeDate:[NSDate distantFuture]];}});//让barrier之前的线程执行完成之后才会执行barrier后面的操作dispatch_barrier_async(queue, ^{__block BOOL isExecuted = NO;NSURLSessionDataTask *task = [[NSURLSession sharedSession] dataTaskWithRequest:[NSURLRequest requestWithURL:[NSURL URLWithString:@"http://www.baidu.com"]] completionHandler:^(NSData * _Nullable data, NSURLResponse * _Nullable response, NSError * _Nullable error) {NSLog(@"拿到了A的值");isExecuted = YES;}] ;[task resume];while (isExecuted == NO) {[[NSRunLoop currentRunLoop] runMode:NSDefaultRunLoopMode beforeDate:[NSDate distantFuture]];}});dispatch_async(queue, ^{__block BOOL isExecuted = NO;NSURLSessionDataTask *task = [[NSURLSession sharedSession] dataTaskWithRequest:[NSURLRequest requestWithURL:[NSURL URLWithString:@"http://www.baidu.com"]] completionHandler:^(NSData * _Nullable data, NSURLResponse * _Nullable response, NSError * _Nullable error) {NSLog(@"C");isExecuted = YES;}] ;[task resume];while (isExecuted == NO) {[[NSRunLoop currentRunLoop] runMode:NSDefaultRunLoopMode beforeDate:[NSDate distantFuture]];}});dispatch_async(queue, ^{__block BOOL isExecuted = NO;NSURLSessionDataTask *task = [[NSURLSession sharedSession] dataTaskWithRequest:[NSURLRequest requestWithURL:[NSURL URLWithString:@"http://www.baidu.com"]] completionHandler:^(NSData * _Nullable data, NSURLResponse * _Nullable response, NSError * _Nullable error) {NSLog(@"D");isExecuted = YES;}] ;[task resume];while (isExecuted == NO) {[[NSRunLoop currentRunLoop] runMode:NSDefaultRunLoopMode beforeDate:[NSDate distantFuture]];}});
GCD之dispatch_group
dispatch_queue_t queue = dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0);dispatch_group_t group = dispatch_group_create();dispatch_group_async(group, queue, ^{ NSLog(@"A"); });dispatch_group_async(group, queue, ^{ NSLog(@"B"); });dispatch_group_async(group, queue, ^{ NSLog(@"C"); });dispatch_group_async(group, queue, ^{ NSLog(@"D"); });dispatch_group_notify(group, dispatch_get_main_queue(), ^{NSLog(@"all end");});
NSOperation
NSOperationQueue *queue = [[NSOperationQueue alloc] init];NSBlockOperation *p1 = [NSBlockOperation blockOperationWithBlock:^{__block BOOL isExecuted = NO;NSURLSessionDataTask *task = [[NSURLSession sharedSession] dataTaskWithRequest:[NSURLRequest requestWithURL:[NSURL URLWithString:@"http://www.baidu.com"]] completionHandler:^(NSData * _Nullable data, NSURLResponse * _Nullable response, NSError * _Nullable error) {NSLog(@"A");isExecuted = YES;}] ;[task resume];while (isExecuted == NO) {[[NSRunLoop currentRunLoop] runMode:NSDefaultRunLoopMode beforeDate:[NSDate distantFuture]];}}];NSBlockOperation *p2 = [NSBlockOperation blockOperationWithBlock:^{__block BOOL isExecuted = NO;NSURLSessionDataTask *task = [[NSURLSession sharedSession] dataTaskWithRequest:[NSURLRequest requestWithURL:[NSURL URLWithString:@"http://www.baidu.com"]] completionHandler:^(NSData * _Nullable data, NSURLResponse * _Nullable response, NSError * _Nullable error) {NSLog(@"B");isExecuted = YES;}] ;[task resume];while (isExecuted == NO) {[[NSRunLoop currentRunLoop] runMode:NSDefaultRunLoopMode beforeDate:[NSDate distantFuture]];}}];NSBlockOperation *p3 = [NSBlockOperation blockOperationWithBlock:^{__block BOOL isExecuted = NO;NSURLSessionDataTask *task = [[NSURLSession sharedSession] dataTaskWithRequest:[NSURLRequest requestWithURL:[NSURL URLWithString:@"http://www.baidu.com"]] completionHandler:^(NSData * _Nullable data, NSURLResponse * _Nullable response, NSError * _Nullable error) {NSLog(@"C");isExecuted = YES;}] ;[task resume];while (isExecuted == NO) {[[NSRunLoop currentRunLoop] runMode:NSDefaultRunLoopMode beforeDate:[NSDate distantFuture]];}}];//表示p3这个操作要等p1这个操作先完成[p3 addDependency:p1];//表示p3这个操作要等p1这个操作先完成[p3 addDependency:p2];//!!!所以p3一定是最后输出,p1和p2不一定。// waitUntilFinished是否阻塞当前线程[queue addOperations:@[p1,p2,p3] waitUntilFinished:YES];// 如果是NO,那么这行打印就是随机的, 反之就是等A,B,C都打印完之后才执行NSLog(@"HAHA");
OSSpinLock
OSSPinlock 就是自旋锁,速度应该是最快的锁,等待锁的线程会处于 忙等(busy-wait) 状态,一直占用着 CPU 资源,因为它需要不断的去尝试获取锁。这种忙等状态的锁会造成一个很严重的问题,那就是优先级反转,也称为优先级倒挂。
所以,除非开发者能保证访问锁的线程全部都处于同一优先级,否则 iOS 系统中所有类型的自旋锁都不能再使用了。当然苹果还在用,SideTable 中就包含了一个自旋锁,用于对引用计数的增减操作,这种轻量操作也是自旋锁的使用场景。
OSSPinlock在iOS 10及以上被废弃。
#import <libkern/OSAtomic.h>__block OSSpinLock oslock = OS_SPINLOCK_INIT;StudentsObject *obj = [[StudentsObject alloc] init];dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{OSSpinLockLock(&oslock);[obj addStudent];sleep(3);OSSpinLockUnlock(&oslock);});dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{sleep(1);//以保证让线程2的代码后执行OSSpinLockLock(&oslock);[obj removeStudent];OSSpinLockUnlock(&oslock);});
os_unfair_lock
os_unfair_lock 是作为 OSSpinLock 的替代方案被提出来的,iOS 10.0 之后开始支持。不过从底层调用来看,等待 os_unfair_lock 的线程会处于休眠状态,而并非 OSSpinLock 的忙等状态,线程的切换是需要资源的,所以它的效率不如 OSSpinLock。
#import <os/lock.h>- (void)useOS_Unfair_Lock{__block os_unfair_lock unfairLock = OS_UNFAIR_LOCK_INIT;StudentsObject *obj = [[StudentsObject alloc] init];dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{os_unfair_lock_lock(&unfairLock);[obj addStudent];sleep(3);os_unfair_lock_unlock(&unfairLock);});dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{sleep(1);//以保证让线程2的代码后执行os_unfair_lock_lock(&unfairLock);[obj removeStudent];os_unfair_lock_unlock(&unfairLock);});}
dispatch_semaphore
dispatch_semaphore 是 GCD 实现的信号量,信号量是基于计数器的一种多线程同步机制,内部有一个可以原子递增或递减的值,关于信号量的 API 主要是三个,create、wait 和 signal。使用它我们也可以来构建一把“锁”。从本质意义上讲,信号量与锁是有区别的。
信号量在初始化时要指定 value,随后内部将这个 value 存储起来。实际操作会存在两个 value,一个是当前的value,一个是记录初始 value。
信号的 wait 和 signal 是互逆的两个操作。如果 value 大于等于 0,前者将 value 减一,此时如果 value 小于 0 就一直等待。后者将 value 加一。
初始 value 必须大于等于 0,如果为 0 并随后调用 wait 方法,线程将被阻塞直到别的线程调用了 signal 方法。
//主线程中StudentsObject *obj = [[StudentsObject alloc] init];dispatch_semaphore_t semaphore = dispatch_semaphore_create(1);//线程1dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{dispatch_semaphore_wait(semaphore, DISPATCH_TIME_FOREVER);[obj addStudent];sleep(3);dispatch_semaphore_signal(semaphore);});//线程2dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{sleep(1);dispatch_semaphore_wait(semaphore, DISPATCH_TIME_FOREVER);[obj removeStudent];dispatch_semaphore_signal(semaphore);});
输出:
2016-09-06 21:53:58.916 DSLockDemo[77879:9698257] addStudent2016-09-06 21:54:01.922 DSLockDemo[77879:9698220] removeStudent
还可以线程线程的最大并发数:
/**限制线程最大并发数*/- (void)semaphoreTest3 {dispatch_semaphore_t semaphore = dispatch_semaphore_create(3);dispatch_queue_t queue = dispatch_get_global_queue(0, 0);for (int i = 0; i < 100; i++) {dispatch_async(queue, ^{dispatch_semaphore_wait(semaphore, DISPATCH_TIME_FOREVER);NSLog(@"running");sleep(1);NSLog(@"completed...................");dispatch_semaphore_signal(semaphore);});}}
pthread_mutex(NORMAL)
pthread_mutex 有几种类型:
/** Mutex type attributes*///默认类型,普通锁,当一个线程加锁后,其余请求锁的线程将形成一个等待队列,并在解锁后按优先级获得锁。这种锁策略保证了资源分配的公平性。#define PTHREAD_MUTEX_NORMAL 0//检错锁,如果同一个线程请求同一个锁,则抛出一个错误,否则与 PTHREAD_MUTEX_NORMAL 类型动作一致。这样就保证当不允许多次加锁时不会出现最简单情况下的死锁。#define PTHREAD_MUTEX_ERRORCHECK 1//递归锁,允许同一个线程对同一个锁成功获得多次,并通过多次 unlock 解锁。如果是不同线程请求,则在加锁线程解锁时重新竞争。#define PTHREAD_MUTEX_RECURSIVE 2#define PTHREAD_MUTEX_DEFAULT PTHREAD_MUTEX_NORMAL
使用:
#import <pthread.h>//主线程中StudentsObject *obj = [[StudentsObject alloc] init];__block pthread_mutex_t mutex;pthread_mutex_init(&mutex, NULL);//线程1dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{pthread_mutex_lock(&mutex);[obj addStudent];sleep(3);pthread_mutex_unlock(&mutex);});//线程2dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{sleep(1);pthread_mutex_lock(&mutex);[obj removeStudent];pthread_mutex_unlock(&mutex);});
输出:
2016-09-06 21:51:56.586 DSLockDemo[77879:9696034] addStudent2016-09-06 21:51:59.589 DSLockDemo[77879:9696048] removeStudent
NSLock(pthread_mutex:ERRORCHECK)
NSLock是Cocoa提供给我们最基本的锁对象,这也是我们经常所使用的锁之一。
除lock和unlock方法外,NSLock还提供了tryLock和lockBeforeDate:两个方法。
tryLock方法会尝试加锁,如果锁不可用(已经被锁住),并不会阻塞线程,返回NO。
lockBeforeDate:方法会在所指定Date之前尝试加锁,如果在指定时间之前都不能加锁,则返回NO。
NSLock是对PTHREAD_MUTEX_ERRORCHECK类型的pthread_mutex_t的封装。
我们看一下下面的输出,会看到线程1锁住之后,线程2会一直等待线程1将锁置为unlock后,才会执行removeStudent方法(也就是差不多3s后)。
//主线程中StudentsObject *obj = [[StudentsObject alloc] init];NSLock *thelock = [[NSLock alloc] init];//线程1dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{[thelock lock];[obj addStudent];sleep(3);[thelock unlock];});//线程2dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{sleep(1);//以保证让线程2的代码后执行[thelock lock];[obj removeStudent];[thelock unlock];});
输出:
2016-09-06 17:57:05.427 DSLockDemo[75969:9603477] addStudent2016-09-06 17:57:08.434 DSLockDemo[75969:9603471] removeStudent
NSCondition 条件锁(pthread_mutex:NORMAL)
NSCondition是以OC对象的形式对pthread_mutex和pthread_cond_t进行了封装,NSCondition没有拥有者。
NSCondition *condition = [[NSCondition alloc] init];// 消费者- (void)remove{[condition lock];if (self.data.count == 0) {// 如果不满足条件,则等待,具体是释放锁,用条件变量来阻塞当前线程// 当条件满足的时候,条件变量唤醒线程,用锁加锁[condition wait];}[self.data removeLastObject];[condition unlock];}// 生产者- (void)add{[condition lock];[self.data addObject:@"Test"];// 信号// 条件变量唤醒阻塞的线程,用锁加锁[condition signal];[condition unlock];}
pthread_mutex(Recursive)
pthread_mutex 支持递归锁,只要把 attr 的类型改成 PTHREAD_MUTEX_RECURSIVE 即可,它有单一的拥有者。
递归锁意思是同一个线程可以多次获得同一个锁,其他线程如果想要获取这把锁,必须要等待,这种锁一般都是用于递归函数的情况。
#import <pthread.h>- (void)viewDidLoad {[super viewDidLoad];[self usePthread_mutex_recursive];}pthread_mutex_t pRecursiveLock;- (void)usePthread_mutex_recursive {// 初始化锁属性pthread_mutexattr_t attr;pthread_mutexattr_init(&attr);pthread_mutexattr_settype(&attr, PTHREAD_MUTEX_RECURSIVE);// 初始化锁pthread_mutex_init(&pRecursiveLock, &attr);// 销毁attrpthread_mutexattr_destroy(&attr);[self thread1];}- (void)thread1 {pthread_mutex_lock(&pRecursiveLock);static int count = 0;count ++;if (count < 10) {NSLog(@"do:%d",count);[self thread1];}pthread_mutex_unlock(&pRecursiveLock);NSLog(@"finish:%d",count);}- (void)dealloc {// 销毁锁pthread_mutex_destroy(&pRecursiveLock);}@end
NSRecursiveLock 递归锁(pthread_mutex:RECURSIVE)
平时我们在代码中使用锁的时候,最容易犯的一个错误就是造成死锁,而容易造成死锁的一种情形就是在递归或循环中,如下代码:
//主线程中StudentsObject *obj = [[StudentsObject alloc] init];NSLock *thelock = [[NSLock alloc] init];//线程1dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{static void(^TestMethod)(int);TestMethod = ^(int value){[thelock lock];if (value > 0){[obj addStudent];sleep(3);TestMethod(value-1);}[thelock unlock];};TestMethod(5);});//线程2dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{sleep(1);//以保证让线程2的代码后执行[thelock lock];[obj removeStudent];[thelock unlock];});
输出:
2016-09-06 22:05:30.986 DSLockDemo[78082:9709497] addStudent2016-09-06 22:05:33.994 DSLockDemo[78082:9709497] *** -[NSLock lock]: deadlock (<NSLock: 0x7fc2bbd0d3d0> '(null)')2016-09-06 22:05:33.994 DSLockDemo[78082:9709497] *** Break on _NSLockError() to debug.
我们看见log打印出来了-[NSLock lock]: deadlock,这其实就是造成了死锁。
我们发现[thelock lock];和[thelock unlock];之间发生了递归,又进入了一个锁里面,但是上一层的锁又还没unlock,递归又结束不了,这时他们进入了一个互相等待的过程,所以就发生了死锁。
由于以上的代码非常的简短,所以很容易能识别死锁,但在较为复杂的代码中,就不那么容易发现了,那么如何在递归或循环中正确的使用锁呢?
此处的theLock如果换用NSRecursiveLock对象,问题便得到解决了,NSRecursiveLock类定义的锁可以在同一线程多次lock,而不会造成死锁。递归锁会跟踪它被多少次lock。每次成功的lock都必须平衡调用unlock操作。只有所有的锁住和解锁操作都平衡的时候,锁才真正被释放给其他线程获得。
//主线程中StudentsObject *obj = [[StudentsObject alloc] init];NSRecursiveLock *thelock = [[NSRecursiveLock alloc] init];//线程1dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{static void(^TestMethod)(int);TestMethod = ^(int value){[thelock lock];if (value > 0){[obj addStudent];sleep(3);TestMethod(value-1);}[thelock unlock];};TestMethod(5);});//线程2dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{sleep(1);//以保证让线程2的代码后执行[thelock lock];[obj removeStudent];[thelock unlock];});
输出(我们看到正常的输出了5次addStudent没有发生死锁):
2016-09-06 22:19:18.911 DSLockDemo[78284:9721695] addStudent2016-09-06 22:19:21.916 DSLockDemo[78284:9721695] addStudent2016-09-06 22:19:24.919 DSLockDemo[78284:9721695] addStudent2016-09-06 22:19:27.921 DSLockDemo[78284:9721695] addStudent2016-09-06 22:19:30.924 DSLockDemo[78284:9721695] addStudent2016-09-06 22:19:33.929 DSLockDemo[78284:9721830] removeStudent
NSConditionLock 条件锁
当我们在使用多线程的时候,有时一把只会lock和unlock的锁未必就能完全满足我们的使用。因为普通的锁只能关心锁与不锁,而不在乎用什么钥匙才能开锁,而我们在处理资源共享的时候,多数情况是只有满足一定条件的情况下才能打开这把锁。
NSConditionLock是对NSCondition的进一步封装,可以设置条件变量的值。通过改变条件变量的值,可以使任务之间产生依赖关系,达到使任务按照一定的顺序执行。它有单一的拥有者(不确定)。
//主线程中NSConditionLock *theLock = [[NSConditionLock alloc] init];//线程1dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{for (int i=0;i<=2;i++){[theLock lock];NSLog(@"thread1:%d",i);sleep(2);[theLock unlockWithCondition:i];}});//线程2dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{[theLock lockWhenCondition:2];NSLog(@"thread2");[theLock unlock];});
输出:
2016-09-06 22:54:45.855 DSLockDemo[78760:9747003] thread1:02016-09-06 22:54:47.861 DSLockDemo[78760:9747003] thread1:12016-09-06 22:54:49.867 DSLockDemo[78760:9747003] thread1:22016-09-06 22:54:51.871 DSLockDemo[78760:9747009] thread2
在线程1中的加锁使用了lock,所以是不需要条件的,所以顺利的就锁住了,但在unlock的使用了一个整型的条件,它可以开启其它线程中正在等待这把钥匙的临界地,而线程2则需要一把被标识为2的钥匙,所以当线程1循环到最后一次的时候,才最终打开了线程2中的阻塞。但即便如此,NSConditionLock也跟其它的锁一样,是需要lock与unlock对应的,只是lock,lockWhenCondition:与unlock,unlockWithCondition:是可以随意组合的,当然这是与你的需求相关的。
这里有一个问题,你可以试试看把线程2中
[theLock lockWhenCondition:2];改为[theLock lockWhenCondition:1];。输出如下:
2016-09-06 22:57:11.877 DSLockDemo[78816:9749702] thread1:02016-09-06 22:57:13.884 DSLockDemo[78816:9749702] thread1:12016-09-06 22:57:15.889 DSLockDemo[78816:9749702] thread1:2
这里并没有如之前一样正确的输出thread2,我猜想是这样的,当循环到1的时候,马上给线程2中的锁发送了通知告诉他你可以打开这个阻塞了,这个通知的时间是有个延时的。这时我们的循环又马上进入了i==2,又[theLock lock];了。等线程2中的锁收到了通知时其实已经又被条件i==2时的锁给锁住了,它还以为被骗了呢。
其实我们只要在i==1时[theLock unlockWithCondition:i];后面加个判断if(i==1){sleep(1);}延缓下一个条件马上进入lock,然后让线程2中的锁先接受到通知进入lock。
可能我表达的会有点难理解,我打个比方吧:
比如有3个人在排队上厕所,然后第二个人上完厕所的时候给外面的朋友D打电话说我上完了现在有位置了你可以进来上了。但是现在第三个人马上进入了厕所,等D进来的时候发现还是没有位置,发现被骗了,然后愤然离去,也没上成厕所。
这时我的那个if(i==1){sleep(1);}就相当于第二个人上完的时候通知朋友D的同时跟第三个人说:你先等一会我朋友很急让他先上吧。然后D进来就可以马上上厕所了,等D上完第三个人再上。
@synchronized 关键字构建的锁(pthread_mutex:RECURSIVE)
synchronized指令实现锁的优点就是我们不需要在代码中显式的创建锁对象,便可以实现锁的机制,但作为一种预防措施,@synchronized块会隐式的添加一个异常处理例程来保护代码,该处理例程会在异常抛出的时候自动的释放互斥锁。所以如果不想让隐式的异常处理例程带来额外的开销,你可以考虑使用锁对象。
@synchronized是对pthread_mutex(Recursive)的封装,所以它支持递归加锁- 需要传入一个 OC 对象,可以理解为把这个对象当做锁来使用
- 实际上它是用
objc_sync_enter(id obj)和objc_sync_exit(id obj)来进行加锁和解锁 - 底层实现:在底层存在一个全局用来存放锁的哈希表(可以理解为锁池),对传入的对象地址的哈希值作为key,去查找对应的递归锁
- @synchronized额外还会设置异常处理机制,性能消耗较大
- @synchronized有单一的拥有者
//主线程中StudentsObject *obj = [[StudentsObject alloc] init];//线程1dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{@synchronized(obj){[obj addStudent];sleep(3);}});//线程2dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{sleep(1);@synchronized(obj){[obj removeStudent];}});
输出:
2016-09-06 21:42:41.477 DSLockDemo[77574:9683881] addStudent2016-09-06 21:42:44.485 DSLockDemo[77574:9683942] removeStudent
NSDistributedLock 分布式锁
从它的类名就知道这是一个分布式的 Lock。NSDistributedLock 的实现是通过文件系统的,所以使用它才可以有效的实现不同进程之间的互斥,但 NSDistributedLock 并非继承于 NSLock,它没有 lock 方法,它只实现了 tryLock,unlock,breakLock,所以如果需要 lock 的话,你就必须自己实现一个 tryLock 的轮询。
补充:简单查了下资料,这个锁主要用于 OS X 的开发。而iOS 较少用到多进程,所以很少在 iOS 上见到过。
程序A:
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{lock = [[NSDistributedLock alloc] initWithPath:@"/Users/mac/Desktop/earning__"];[lock breakLock];[lock tryLock];sleep(10);[lock unlock];NSLog(@"appA: OK");});
程序B:
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{lock = [[NSDistributedLock alloc] initWithPath:@"/Users/mac/Desktop/earning__"];while (![lock tryLock]) {NSLog(@"appB: waiting");sleep(1);}[lock unlock];NSLog(@"appB: OK");});
先运行程序A,然后立即运行程序B,根据打印你可以清楚的发现,当程序A刚运行的时候,程序B一直处于等待中,当大概10秒过后,程序B便打印出了appB:OK的输出,以上便实现了两上不同程序之间的互斥。/Users/mac/Desktop/earning__是一个文件或文件夹的地址,如果该文件或文件夹不存在,那么在tryLock返回YES时,会自动创建该文件/文件夹。在结束的时候该文件/文件夹会被清除,所以在选择的该路径的时候,应该选择一个不存在的路径,以防止误删了文件。
