@qidiandasheng
2020-07-20T13:58:08.000000Z
字数 6471
阅读 2462
汇编
技术
来历
最早的时候,编写程序就是手写二进制指令,然后通过各种开关输入计算机,比如要做加法了,就按一下加法开关。后来,发明了纸带打孔机,通过在纸带上打孔,将二进制指令自动输入计算机。
为了解决二进制指令的可读性问题,工程师将那些指令写成了八进制。二进制转八进制是轻而易举的,但是八进制的可读性也不行。很自然地,最后还是用文字表达,加法指令写成 ADD。内存地址也不再直接引用,而是用标签表示。
这样的话,就多出一个步骤,要把这些文字指令翻译成二进制,这个步骤就称为 assembling,完成这个步骤的程序就叫做 assembler。它处理的文本,自然就叫做 aseembly code。标准化以后,称为 assembly language,缩写为 asm,中文译为汇编语言。
每一种 CPU 的机器指令都是不一样的,因此对应的汇编语言也不一样。
学习汇编语言,首先必须了解两个知识点:寄存器和内存模型。
内存模型:Heap
寄存器只能存放很少量的数据,大多数时候,CPU 要指挥寄存器,直接跟内存交换数据。所以,除了寄存器,还必须了解内存怎么储存数据。
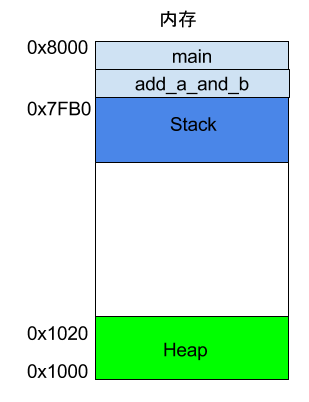
程序运行的时候,操作系统会给它分配一段内存,用来储存程序和运行产生的数据。这段内存有起始地址和结束地址,比如从0x1000到0x8000,起始地址是较小的那个地址,结束地址是较大的那个地址。

程序运行过程中,对于动态的内存占用请求(比如新建对象,或者使用malloc命令),系统就会从预先分配好的那段内存之中,划出一部分给用户,具体规则是从起始地址开始划分(实际上,起始地址会有一段静态数据,这里忽略)。举例来说,用户要求得到10个字节内存,那么从起始地址0x1000开始给他分配,一直分配到地址0x100A,如果再要求得到22个字节,那么就分配到0x1020。
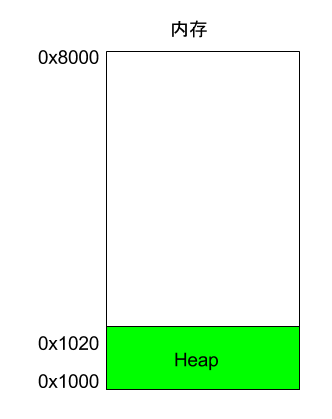
这种因为用户主动请求而划分出来的内存区域,叫做 Heap(堆)。它由起始地址开始,从低位(地址)向高位(地址)增长。Heap 的一个重要特点就是不会自动消失,必须手动释放,或者由垃圾回收机制来回收。
内存模型:Stack
除了 Heap 以外,其他的内存占用叫做 Stack(栈)。简单说,Stack 是由于函数运行而临时占用的内存区域。

请看下面的例子。
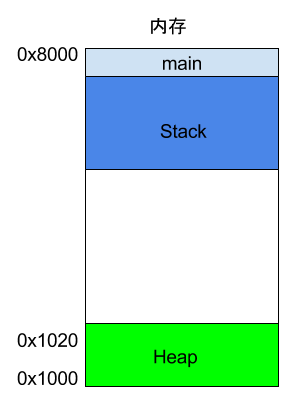
int main() {int a = 2;int b = 3;}
上面代码中,系统开始执行main函数时,会为它在内存里面建立一个帧(frame),所有main的内部变量(比如a和b)都保存在这个帧里面。main函数执行结束后,该帧就会被回收,释放所有的内部变量,不再占用空间。
如果函数内部调用了其他函数,会发生什么情况?
int main() {int a = 2;int b = 3;return add_a_and_b(a, b);}
上面代码中,main函数内部调用了add_a_and_b函数。执行到这一行的时候,系统也会为add_a_and_b新建一个帧,用来储存它的内部变量。也就是说,此时同时存在两个帧:main和add_a_and_b。一般来说,调用栈有多少层,就有多少帧。
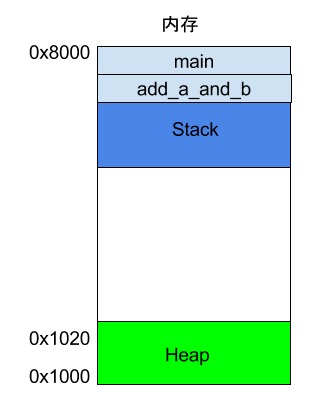
等到add_a_and_b运行结束,它的帧就会被回收,系统会回到函数main刚才中断执行的地方,继续往下执行。通过这种机制,就实现了函数的层层调用,并且每一层都能使用自己的本地变量。
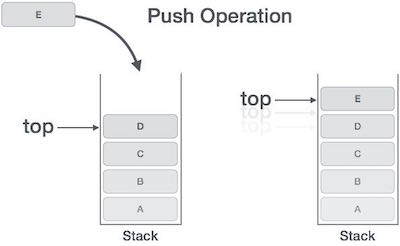
所有的帧都存放在Stack,由于帧是一层层叠加的,所以 Stack 叫做栈。生成新的帧,叫做"入栈",英文是 push;栈的回收叫做"出栈",英文是 pop。Stack 的特点就是,最晚入栈的帧最早出栈(因为最内层的函数调用,最先结束运行),这就叫做"后进先出"的数据结构。每一次函数执行结束,就自动释放一个帧,所有函数执行结束,整个 Stack 就都释放了。
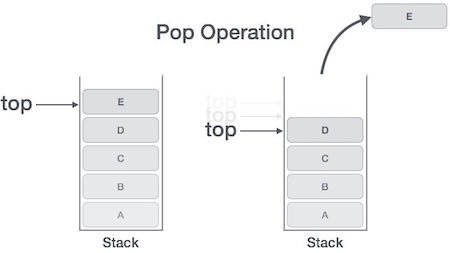
Stack 是由内存区域的结束地址开始,从高位(地址)向低位(地址)分配。比如,内存区域的结束地址是0x8000,第一帧假定是16字节,那么下一次分配的地址就会从0x7FF0开始;第二帧假定需要64字节,那么地址就会移动到0x7FB0。
寄存器
CPU 本身只负责运算,不负责储存数据。数据一般都储存在内存之中,CPU 要用的时候就去内存读写数据。但是,CPU 的运算速度远高于内存的读写速度,为了避免被拖慢,CPU 都自带一级缓存和二级缓存。基本上,CPU 缓存可以看作是读写速度较快的内存。
但是,CPU 缓存还是不够快,另外数据在缓存里面的地址是不固定的,CPU 每次读写都要寻址也会拖慢速度。因此,除了缓存之外,CPU 还自带了寄存器(register),用来储存最常用的数据。也就是说,那些最频繁读写的数据(比如循环变量),都会放在寄存器里面,CPU 优先读写寄存器,再由寄存器跟内存交换数据。

寄存器不依靠地址区分数据,而依靠名称。每一个寄存器都有自己的名称,我们告诉 CPU 去具体的哪一个寄存器拿数据,这样的速度是最快的。有人比喻寄存器是 CPU 的零级缓存。
寄存器有对应的大小,比如ARMv7的寄存器为32位,ARMv8的寄存器为64位。
32位可以组成不重复的0,1组合数就是2^32 次方种,可以代表2^32 种地址(一种地址一个字节),所以说可以寻址4GB(2^32/1024/1024/1024)的内存。
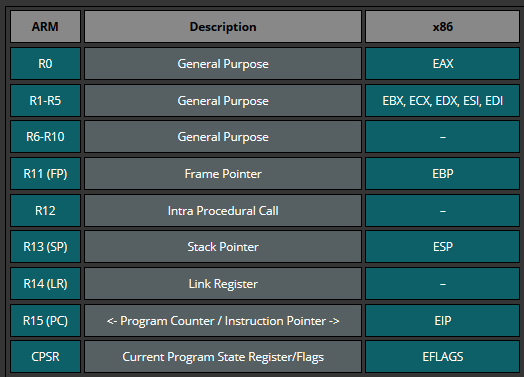
ARM寄存器和x86寄存器
ARM32和x86:
下面这张表将ARM的寄存器(32位)和x86寄存器做了一个简单类比:
ARM64:
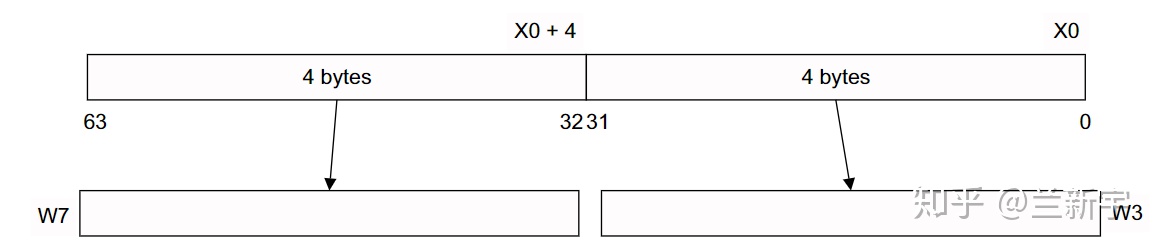
自从ARMv8出现以后,ARM的寄存器就全面进入了64位时代,通用寄存器的数量从13个(R0-R12)变成了31个(X0-X30) ,其名称中的"R"也被"X"所取代了。
为了保持和32位系统的兼容性,每个ARMv8/ARM64通用寄存器都可被当做2个32位寄存器来使用,这样的32位寄存器用"Wn"来表示。当使用 x0 - x30 访问时,它就是一个64位的数。当使用 w0 - w30 访问时,访问的是这些寄存器的低32位,如图:

| 寄存器 | 位数 | 描述 |
|---|---|---|
| x0-x30 | 64bit | 通用寄存器,如果有需要可以当做32bit使用:WO-W30 |
| FP(x29) | 64bit | (Frame Pointer)为栈基址寄存,用于保存栈底地址 |
| LR(x30) | 64bit | (Link Register) 通常称X30为程序链接寄存器,保存子程序结束后需要执行的下一条指令 |
| ZR(x31) | 64bit | (Zero Register),xzr/wzr分别代表 64/32 位,其作用就是 0,写进去代表丢弃结果,读出来是 0; |
| SP | 64bit | (Stack Pointer),栈顶寄存器,用于保存栈顶地址 |
| PC | 64bit | 程序计数器,俗称PC指针,保存将要执行的指令的地址(指向即将要执行的下一条指令),在arm64中,软件是不能改写PC寄存器的 |
| CPSR | 32bit | 状态寄存器 |
通用寄存器
ARM32:
R0~R12是通用寄存器(R12已经不完全是了),它们可以在常规操作中使用,来存储临时变量或地址。习惯上,R0常在算数运算中作为累加器,或者存储函数的返回地址。R7常用于存储系统调用号。R11常作为栈帧指针来标记函数栈帧的边界。此外,ARM的函数调用约定规定,函数的前四个参数存储在寄存器
r0~r3中。
ARM64:
X0~X30是通用寄存器,它们可以在常规操作中使用,来存储临时变量或地址。ARM64的函数调用约定规定,函数的前八个参数存储在寄存器
x0~x7中,如果参数个数超过了8个,多余的参数会存在栈上,新方法会通过栈来读取。
方法的返回值一般都在x0上;如果方法返回值是一个较大的数据结构时,结果会存在x8执行的地址上。
特殊寄存器
FP:(
Frame Pointer),栈基址寄存器,用于保存栈底地址。
ARM32:R11,ARM64:X29SP:(
Stack Point),栈顶寄存器,用于保存栈顶地址;堆栈是用来存储函数局部存储的一段内存,在函数返回时回收。堆栈指针通过减去我们要分配的空间大小,来分配堆栈上的空间。比如,我们要分配一个32 bit的空间,那么就令SP减4。
ARM32:R13
每个函数都有自己的一块操作空间,我们称其为“栈帧(
stack frame)”。寄存器fp、sp的值是栈帧范围的唯一标识。我们前面说过调用栈有多少层,就有多少帧。
LR:(
Link Register),保存调用跳转指令 bl 指令的下一条指令的内存地址;当进行函数调用时,链接寄存器被更新为调用函数指令的下一条指令的地址。这样做可以使程序在执行完子函数之后得以返回父函数。
ARM32:R14,ARM64:X30PC:(
Program Counter),程序计数器,保存将要执行的指令的地址(由操作系统决定其值,不能改写)。在执行指令时,PC总是自动的增加,增加的大小等于正在执行指令的长度。这个长度在ARM架构下是固定的,ARM模式是4字节,Thumb模式是2字节。当执行分支指令时,PC被更新为目的地址。需要注意的是,由于RISC CPU流水线优化的原因,在执行期间,ARM模式下PC等于当前指令地址加8,Thumb模式下等于当前指令地址加4,也就是后移两条指令。这不同于x86的EIP寄存器,总是指向当前指令的下一条指令。
ARM32:R15
状态寄存器 CPSR
其他寄存器是用来存放数据的,都是整个寄存器具有一个含义;而 CPSR 寄存器是按位起作用的,即,每一位都有专门的含义,记录特定的信息;如下图

注: CPSR 寄存器是 32 位的。
- CPSR 的 低8位(包括 I、F、T 和 M[4:0])称为控制位,程序无法修改,除非 CPU 运行于 特权模式下,程序才能修改控制位。
N、Z、C、V 均为条件码标志位;其内容可被算术或逻辑运算的结果所改变,并且可以决定某条指令是否被执行。
N(Negative)标志: CPSR 的第 31 位是 -N,符号标志位;记录相关指令执行后其结果是否为负数,如果为负数,则 N = 1;如果是非负数,则 N = 0。
Z(Zero)标志: CPSR 的第 30 位是 Z,0标志位;记录相关指令执行后,其结果是否为0,如果结果为0,则 Z = 1;如果结果不为0,则 Z = 0。
C(Carry)标志: CPSR 的第 29 位是C,进位标志位;
- 加法运算:当运算结果产生了 进位 时(无符号数溢出),C = 1,否则 C = 0 ;
- 减法运算(包括 CMP): 当运算时产生了 借位 时(无符号数溢出),C = 0,否则 C = 1 。
V(Overflow)标志: CPSR 的第 28 位是 V,溢出标志位;在进行有符号数运算的时候,如果超过了机器所能标识的范围,称为溢出。
指令
ARM64经常用到的汇编指令
MOV X1,X0 ;将寄存器X0的值传送到寄存器X1ADD X0,X1,X2 ;寄存器X1和X2的值相加后传送到X0SUB X0,X1,X2 ;寄存器X1和X2的值相减后传送到X0AND X0,X0,#0xF ; X0的值与0xF相位与后的值传送到X0ORR X0,X0,#9 ; X0的值与9相位或后的值传送到X0EOR X0,X0,#0xF ; X0的值与0xF相异或后的值传送到X0LDR X5,[X6,#0x08] ;ld:load; X6寄存器加0x08的和的地址值内的数据传送到X5LDP x29, x30, [sp, #0x10] ; ldp :load pair ; 一对寄存器, 从内存读取数据到寄存器STR X0, [SP, #0x8] ;st:store,str:往内存中写数据(偏移值为正); X0寄存器的数据传送到SP+0x8地址值指向的存储空间STUR w0, [x29, #-0x8] ;往内存中写数据(偏移值为负)STP x29, x30, [sp, #0x10] ;store pair,存放一对数据, 入栈指令CBZ ;比较(Compare),如果结果为零(Zero)就转移(只能跳到后面的指令)CBNZ ;比较,如果结果非零(Non Zero)就转移(只能跳到后面的指令)CMP ;比较指令,相当于SUBS,影响程序状态寄存器CPSRB ;跳转指令,可带条件跳转与cmp配合使用BL ;带返回的跳转指令, 返回地址保存到LR(X30)BLR ; 带返回的跳转指令,跳转到指令后边跟随寄存器中保存的地址(例:blr x8 ;跳转到x8保存的地址中去执行)RET ;子程序返回指令,返回地址默认保存在LR(X30)
STR/STP
str (store register) :将寄存器中的值写入到内存中,如:
str w9, [sp, #0x8] ; 将寄存器 w9 中的值保存到栈内存 [sp + 0x8] 处
strb: (store register byte) 将寄存器中的值写入到内存中(只存储一个字节),如:
strb w8, [sp, #7] ; 将寄存器 w8 中的低 1 字节的值保存到栈内存 [sp + 7] 处
stp:入栈指令(str 的变种指令,可以同时操作两个寄存器),如:
stp x29, x30, [sp, #0x10] ; 将 x29, x30 的值存入 sp 偏移 16 个字节的位置
LDR/STR
在x86架构中,不管是寄存器之间,还是寄存器和内存之间,都可以使用MOV指令,并且直接操作内存单元上的数据是被允许的。
在ARM架构中,寄存器间传送数据的指令依然是MOV,比如"MOV Ra Rb" 就是把Rb里存放的数据传送给Ra,但内存单元上的数据不允许被直接操作,而是必须先放到寄存器中,为此就有了把内存的内容传送到寄存器的指令LDR(Load),以及把寄存器的内容传送回内存的指令STR(Store)。
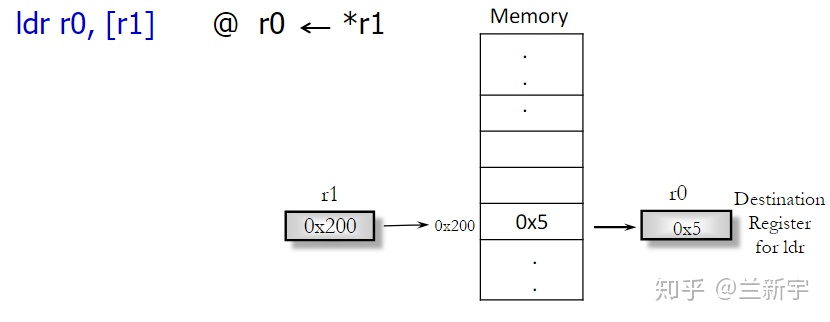
传送的时候,内存单元的地址存放在一个寄存器中(比如R1),用[R1]表示,"[]"在这里就对应C语言里的"*",表示取地址里的内容。假设R1里存放的是0x200,内存中地址0x200处的内容是0x5,那么"ldr r0, [r1]"就是将0x5放入r0中。
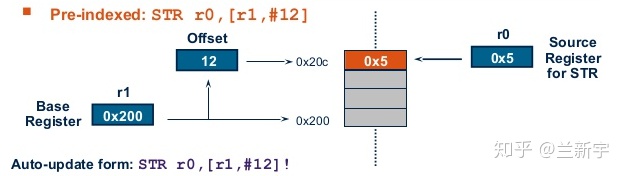
通用寄存器的数量一共就那么多,直接用寄存器的值来获取内存地址的数量实在太有限了,更多的时候,是通过寄存器的值(基址)加上一个偏移/索引(offset/index)来指向内存对应的单元,索引的大小可以由立即数提供,也可以由寄存器存储的值提供:
STR R0,[R1, #12] // R0 --> [R1+12]LDR R4,[R5, R6] // R4 <-- [R5+R6]
如果索引对基址的更改发生在数据传输之前,则称为"预索引"(pre-index),传输前后寄存器R1的值都不会改变。
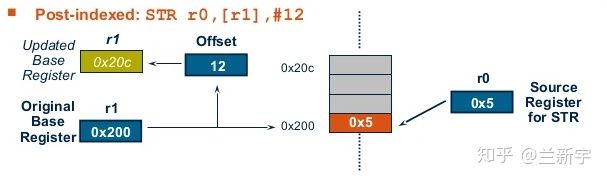
如果索引对基址的更改发生在数据传输之后(注意下图"[]"位置的改变),则称为"后索引"(post-index),传输后寄存器R1的内容将变为加上其原来的值加上索引后的值。"后索引"其实算是一种二合一的指令,比如"str r0, [r1], #12"就等同于"str r0, [r1]"加上"r1 = r1+12"。
子程序返回
子程序返回的三种方法:
1.MOV PC,LR2.BL LR3.在子程序入口处使用以下指令将R14存入堆栈STMFD SP!, {<Regs>,LR}对应的,使用以下指令可以完成子程序的返回LDMFD SP!, {<Regs>,LR}
lr就是连接寄存器(Link Register, LR),在ARM体系结构中LR的特殊用途有两种:一是用来保存子程序返回地址;二是当异常发生时,LR中保存的值等于异常发生时PC的值减4(或者减2),因此在各种异常模式下可以根据LR的值返回到异常发生前的相应位置继续执行。
当通过BL或BLX指令调用子程序时,硬件自动将子程序返回地址保存在R14(LR)寄存器中。在子程序返回时,把LR的值复制到程序计数器PC即可实现子程序返回。
示例解析
int add_a_and_b(int a, int b) {return a + b;}int main() {return add_a_and_b(2, 3);}
x86汇编示例:汇编语言入门教程
xcode查看汇编代码:Debug->Debug WorkFlow-> Always Show Disassembly。
在要查看汇编代码的代码中放置断点.然后,当代码到达该断点时,您可以查看汇编代码.
汇编Hook objc_msgSend
从汇编角度分析objc_msgSend的hook过程
Hook objc_msgSend -- 从 0.5 到 1
