@pockry
2017-08-18T08:10:24.000000Z
字数 8824
阅读 2779
AI Challenger全球AI挑战赛开幕,公布千万级数据集
AI
2017年8月14日,创新工场、搜狗、今日头条在北京召开联合发布会,宣布举办首届AI Challenger全球AI挑战赛。创新工场创始人兼人工智能工程院院长李开复、搜狗CEO张小川、今日头条顾问兼技术战略研究院院长张宏江等出席会议。
AI Challenger 全球AI挑战赛是面向人工智能领域科研人才,致力于打造大型、全面的科研数据集与世界级竞赛平台,现已正式开启报名。
大赛初期开设了五场竞赛,并公布了相关的数据集,包括:
- 人体骨骼关键点检测竞赛。公布了目前规模最大的人体骨骼关键点标注数据集,包括30万张图片,标注人物达到70万人;
- 图像中文描述竞赛。数据集包括30万张图片,中文标注,包括形容词和中文成语。
- 场景分类竞赛。数据集包括10万张图片,分属于80个日常场景类别。
- 英中机器文本翻译竞赛。数据集包括1000万中英文句对,都经过译员检查和校正,是目前最大规模的口语领域英中比赛数据集。
- 英中机器同声传译竞赛。数据集同上。
竞赛从9月4日开始,到12月评选出最终结果,委员会为大赛设置了超过200万元人民币的奖励。
在人工智能领域,国际上类似的比赛有很多,如ImageNet,并且很多成果都建立在它们公布的数据之上,国内外很多公司都会参加比赛来验证自家的研究成果。但国内一直都没有一个公开的,相对丰富的中文语料的数据集。AI挑战赛的初衷,是希望通过开放数据,吸引更多优秀人才参与到算法模型的开发、设计中来。通过打造中国最大的科研数据集与世界级AI竞赛平台,推动中国人工智能领域科研创新。李开复表示,欢迎任何对人工智能感兴趣的人参与到竞赛中来,特别是欢迎各位科研院校的老师来利用他们的数据集。
据主办方宣布,创新工场、搜狗、今日头条在今后几年内还将投入数千万规模资金,完善平台建设、扩大数据集规模。
AI挑战赛的设立,打响了国内商业公司数据开放的第一炮,希望能看到有更多的公司参与进来,贡献自己的力量,一同推动国内AI领域的进步。
在现代前端应用的工程实践中,前后端分离的架构会为两端带来更多的灵活性,已成为主流趋势。与之相对的,传统的单体Web应用(Monolithic Web Application)则将前后端代码放在一起,虽然耦合性较强,但在产品研发的特定阶段仍具有较强的优势,早期的ASP.NET、Java Spring MVC,以及Ruby On Rails都是单体应用的代表性框架。
本文将以FreeWheel从单体应用改造为前后端分离的实践为例,着重介绍其间前端所遇到的挑战和解决方案。
相较消费者,商业用户对前端应用的需求更具复杂性,且更强调质量。FreeWheel深耕企业级的视频广告领域10年,其基于Ruby On Rails框架为广告主打造的Web管理应用已经历多轮迭代和演进,目前已达到20多个产品模块,1200+页面,代码量已达到143.5万行代码,其中包含39万行基于jQuery的传统JS代码。为保证其质量,其中包含了20.2万行单元测试代码,除此以外,还有独立的近2万个自动化测试脚本。在两年前,我们感受到了单体应用的局限性,并决定将其改造成为前后端分离的架构。
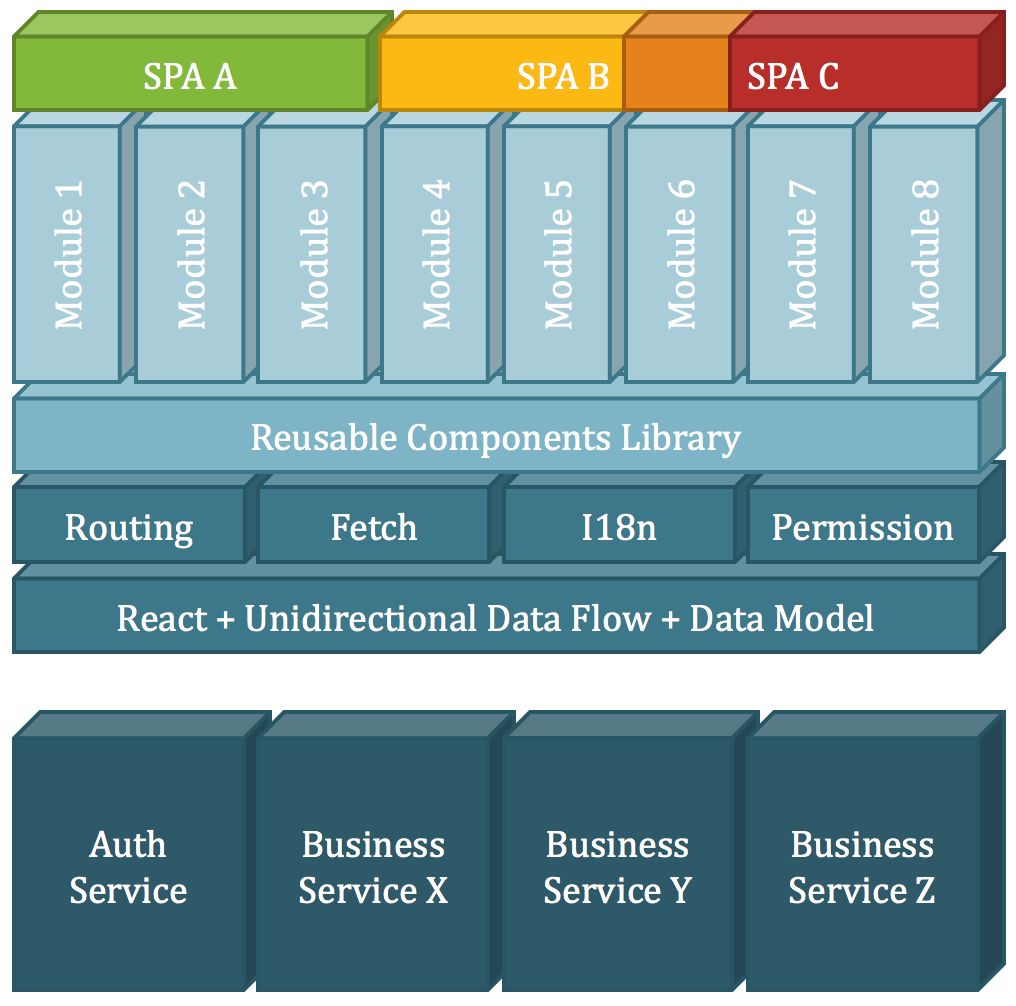
技术选型
FreeWheel前端展现的业务多种多样,但其用户体验强调高效性和高一致性。为辅助业务研发团队进一步提升前端开发的效率和效果,我们在改造前期订立了组件化的目标,力求将统一的用户体验和复杂的内部交互逻辑封装进组件,通过自动化测试保证其质量,并最终在业务模块中广泛复用。
针对以上目标,我们选择React作为新前端核心技术,以ES6作为开发语言,利用Webpack和Babel进行编译打包。以Mocha全家桶加Enzyme作为单元测试框架保证组件质量。每个业务模块均开发、打包并发布为一个独立的SPA(Single Page Application,单页应用),多个模块SPA之间,除了以统一的SSO服务保证用户认证外,并无更多的耦合,这一点保证了多个业务模块团队的工作不会互相制约。
在单向数据流框架选择上,我们基于Facebook的Flux推进了相当长的一段时间。在上线两个业务模块后,我们认识到FreeWheel的业务对前端数据流需求的复杂度远高于常见的TodoMVC样例,Flux实现这些需求时会遇到较多困难。我们评估了当时的社区新秀Redux,它能一定程度缓解我们遇到的问题但仍有局限性。我们最终决定以Redux和ImmutableJS为基础,开发一套新的单向数据流框架spark-modula。这点在下一节会有详细描述。
类似的还有前端路由。我们初期的选型是react-router,随后根据项目需要开发了新的前端路由框架spark-router。
更详细的前端框架选型如下:
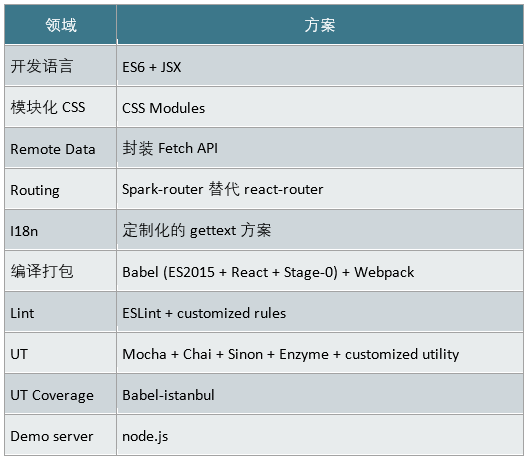
至于后端,我们的选型是以Golang开发的微服务。借此契机,团队将原来内置于单体应用中的后端服务重新做了一次梳理,并逐步重构成微服务架构中的若干个微服务。前端在通过SSO验证后,以JSON格式与微服务交换数据。这些微服务除了满足前端使用,也会通过gateway作为API暴露给我们的客户,更会为公司内部的其他微服务提供基础。后端架构不是本文重点,故不赘述,有兴趣的读者请参见FreeWheel发表的其他文章。
新轮子SparkUI
为了推进前后端分离改造,我们成立了一个专门的前端小团队,与业务模块开发团队紧密合作,经历数十个迭代,开发并完善了一套基于React的前端框架,内部名称为“SparkUI”(这一名称与Apache Spark或Java Spark无关)。下图是SparkUI框架的简要架构:
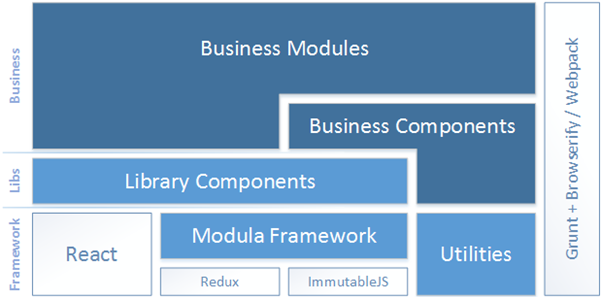
其中上游的React、Redux、ImmutableJS等框架为SparkUI的直接依赖,下游的Business Components业务组件、Business Modules业务模块则为基于SparkUI框架开发业务代码的产出;衔接上下游的,则是SparkUI的核心组成部分。
可重用组件Library Components
SparkUI截止至截稿日已积累了40个子package,其中很大一部分为可重用的UI组件,我们称之为Library Components,例如spark-loading、spark-calendar、spark-raw-grid等。凡是业务模块提出的对前端组件的需求,只要与业务并不直接相关的,我们都会设计并迭代开发相应的可重用组件。
我们在设计可重用组件时,遵循的一些要点包括:
无状态组件(Stateless Component)优于状态化组件(Stateful Component);
组合组件(Composing Components)优于具有DSL(Domain Specific Language)属性的单一组件;
高阶组件(HOC,Higher-Order Component)优于混合属性(Mixins)。
应用状态管理框架spark-modula
上一节提到Flux所提供的单向数据流不能完全满足我们的业务需求。我们在对比了Flux和Redux后,决定自主开发一只新轮子。当时面对的挑战包括但不限于:
在Ruby On Rails应用中,开发团队曾设计并开发了大量的Model,这不仅是因为要遵守RoR的MVC实践,更是因为业务的复杂程度客观要求有完整的建模,并基于模型推进前端的开发。我们的新轮子需要以类似的方式来消化业务的复杂性;
在业务的前端需求中,常常有一个页面内包含2个甚至多个Grid,这些Grid之间会互相影响。比如一个典型场景:“Grid A在自动加载后,如果只包含一条记录,则自动选中这条记录,并按该记录ID读取Grid B”。这样的交互在React社区被称为副作用即Side Effects。我们的新轮子需要用相对简单的方式支持Side Effects的处理。
这只应用状态管理的新轮子我们起名为Modula,并入spark-modula包。经过快速迭代,Modula框架已正式替代早期的Flux,应用于业务模块开发。Modula包括Model模型、Constants常量、Container容器、Test Utility测试工具四个组成部分,其中Model包含Props/Hierarchy、Context、Sender/Receiver、Delegates、Bubble Event、Lifecycle Methods、Services、Local Props等概念/API。以下是一个典型的Model例子:
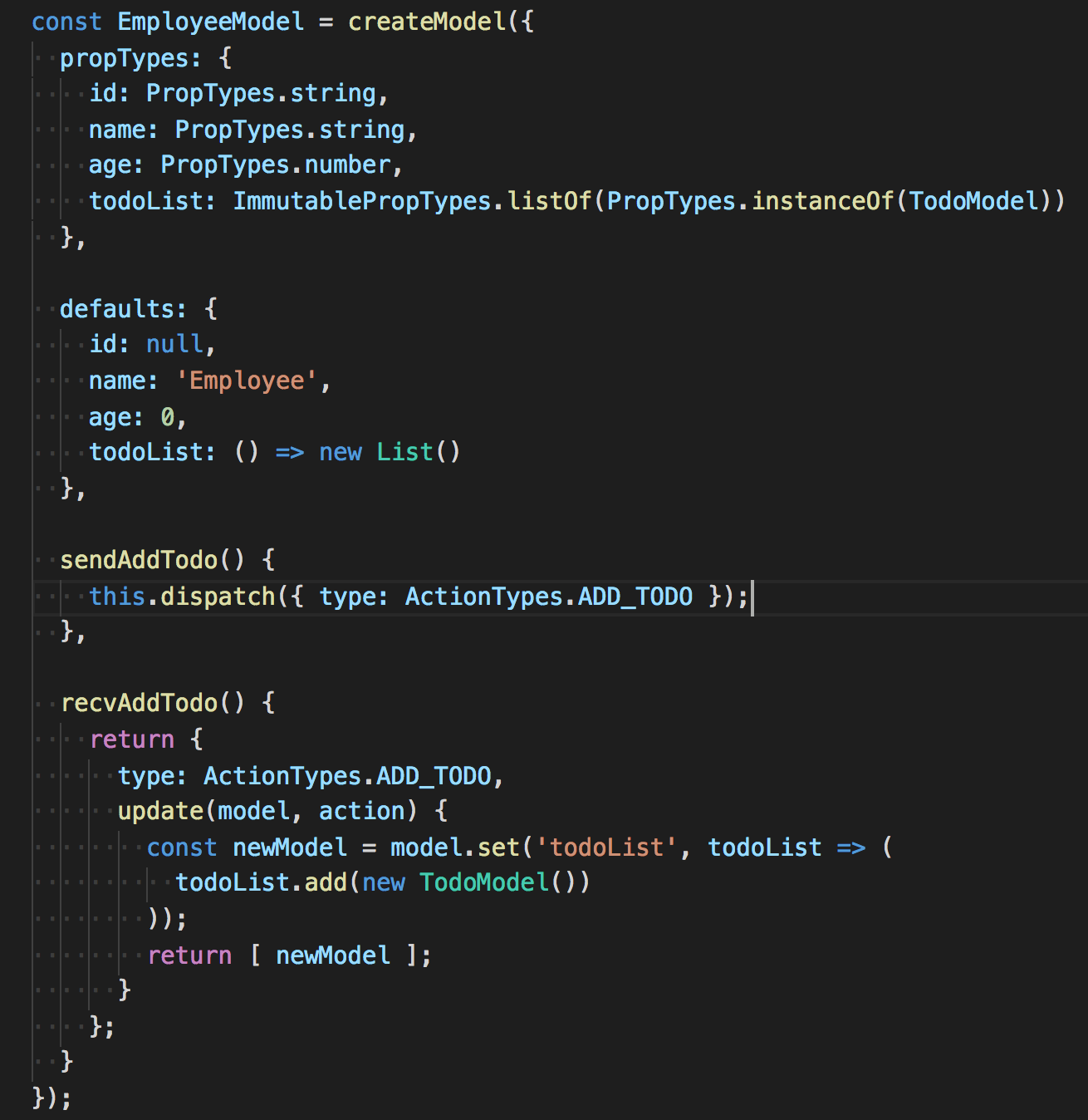
可以看出上半部分相当于Model的schema,Props/Hierarchy/Context 基于Immutable数据结构实现了数据模型;而下半部分相当于Model的行为,Sender/Receiver + Modula Container实现了单向数据流。
Modula框架基于Redux但并不限于Redux,与部分Redux生态(如redux-devtools)兼容,且已完整封装并隐藏了底层的Redux。
关于SparkUI更完整的介绍,请参见后续更详细的文章。
前后端整合
从单体应用改造成前后端分离的架构后,理想状态下,前后端可以分别独立开发、测试、部署,然而若想实现整体业务,则需要将前后两端整合。本节将介绍我们开展改造工作以来,在前后端整合领域积累的部分最佳实践。
RESTful接口
后端接口均按照社区RESTful接口标准定义:
语义化URL,活用GET/POST/PUT/DELETE四种HTTP方法;
支持JSON与XML两种数据呈现格式,默认情况下,HTTP请求和响应均使用JSON,加入XML参数,请求和响应改为使用XML;
优先使用HTTP状态码(Status Code)表现后端成功状态或各类常见错误,如HTTP 200(OK)、401(Unauthorized)、422(Unprocessable Entity)等;
统一业务错误码和错误消息;
以ISO 8061标准输入输出日期时间,如:2015-09-08T01:55:28Z。
在前端我们基于浏览器fetch接口,封装了spark-fetch包,提供如下功能:
浏览器fetch的所有功能;
JSON序列化、反序列化;
为HTTP错误统一显示对话框,其中401状态会跳转至登录页面;
根据用户需要缓存特定资源;
防止Cross-Site Request Forgery (CSRF)。
我们为前端开发了一套简单的Discover服务发现,以key-value方式描述前端中会用到的RESTful服务,spark-fetch包在发起HTTP请求时只要传入key和相关参数即可。目前主要用来防止前端代码里hard-code服务URL,之后会与整个公司级别的服务发现整合起来。
除此之外,我们还在后端开发了一套API Gateway,提供认证(authentication)、限流(throttling)、跨域等公共功能。上述RESTful接口本身无须处理认证等逻辑。在部署后端服务后,只有API Gateway开放给外网访问,其他RESTful接口均限于机房内网访问,经由API Gateway的反向代理提供给外网。即前端在调用这些接口时,必须经过API Gateway调用。
认证授权
文章一开始提到的单体Web应用其实在FreeWheel有多套,分别对应于多个业务线或产品线。这些单体应用开发的阶段有先有后,架构和实现的设计也存在着差别,其中很重要的一点就是认证方式的差别,为了满足多个应用联合登录的需求,尤其是向后兼容SPA的联合登录,我们在后端以Golang开发了新的SSO服务。SPA在登录页面调用SSO接口,登录成功则获取token并存入cookie,这样后续的接口请求就会将cookie传入API Gateway以获取认证信息。
至于授权(authorization),我们在现有的Ruby On Rails应用中大部分是基于CanCan框架实现的,改造为前后端分离架构后,我们将与导航、功能入口相关的授权信息从后端完整传回前端,用前端代码判断特定导航或组件是否显示、是否禁用。当然,RESTful接口中仍有完整的授权判断逻辑。如果有恶意用户通过hack的方式修改了前端授权信息访问了本不能访问的界面,他依旧无法获得列表数据、也无法提交数据修改。
后端Docker容器化
在业务模块开发过程中,开发人员需要在开发前端代码的同时能访问到后端接口及测试数据。如果是单体应用的开发,开发人员只要配置一套开发环境即可达到这个目标,但在前后端分离后,前端开发人员除了配置前端开发环境,还要配置后端。后端代码有更新时,需要及时检出代码并顺利编译,数据库有更新时也需要执行相应的SQL脚本。这些日常工作成为前端开发人员的痛点。
后端Docker容器化有效解决了这一痛点。我们目前的CI (Continuous Integration) Pipeline会在后端代码检入远程Git后触发编译,编译成功后会创建一个包含该编译版本的Docker image并上传至公司内部的Docker image仓库,类似的还有数据库,以及其他中间件的image。前端开发人员不再需要搭建后端开发环境,只需在开发机上安装Docker(如Docker for Mac),在前端工程内会维护一个docker-compose.xml,声明了前端工程所需要的后端Docker image,每次该文件更新后,前端开发人员只需要运行docker-compose up -d即可启动一系列Docker container,在本机运行完整的后端服务,这里甚至包含了适用于开发的部分测试数据。
整合测试
前后端的分离和整合对质量保证提出了新的要求。我们在前端编写fetch逻辑时,会以mock方式编写对应的单元测试。后端每个接口也有响应的单元测试。而这两端分别的单元测试还不足以保证软件质量,理论上讲,纵使两者单元测试覆盖率均达到100%,也不能保证覆盖所有用例。作为质量保证的关键环节,在两端的单元测试都通过后,我们的CI会执行端到端的自动化测试。这些自动化测试模仿了用户的使用场景,完整的覆盖了前端、后端、数据库乃至其他中间件。
渐进改造
SparkUI的产生为前后端分离改造提供了坚实的基础。如果按最理想的方式推进,只要业务开发团队基于SparkUI对现有的Ruby On Rails的单体应用的前端部分、基于Golang微服务方式对其后端部分进行重构改写、践行前后端整合的最佳实践,即可达成前后端分离的目标。而文章开头曾提到,现存的Rails应用体积大、复杂度高,纵使有着业务开发团队的全力支持,我们也很难在一个较短时间内彻底完成前后端分离的改造。更何况市场千变万化,在业务部门服务老客户、获取新客户过程中,产品经理们也会不断地提出新的产品需求给我们的开发团队,技术演进和业务推进两者需要取得一个平衡。我们为达成这一平衡,所提出的方案是:渐进改造。
混合工程结构
我们的业务模块在Ruby On Rails工程中是以Module方式存在的,除了公共的MVC和资源放在统一的Module里,每个业务Module都有自己的MVC和资源(这里的资源特指Javascript和CSS)。我们以业务Module作为改造的单元。
由于资源等限制,前后端分离改造在前端、后端的推进节奏并不一致。比较多的情况是Module前端改造先行,后端依旧沿用Rails原有的Controller(也有部分适配工作)。在这种情况下,Module经SparkUI改写的前端(以下统称为“新前端”)独立于Rails工程之外进行打包部署所带来的好处并不明显,故将这部分新前端代码的源码依旧放在Rails工程Module目录下,通过Webpack打包的bundle JS/CSS也按照Module对资源文件的约定(convention)放在modules/my_module/app/assets/javascripts/my_module/compiled目录下,并藉由Rails Asset Pipeline打包进Rails工程发布包进行统一部署。
对于上述bundle JS/CSS,我们仍使用Rails页面模版作为入口,以期减少对Rails工程的影响:
<%= javascript_include_tag "my_module/compiled/my_module" %><%- @js_module_alias = "my_module" %><div id="spa"></div><script>(function() {var React = require('react');var ReactDOM = require('react-dom');var AppContainer = require('<%= @js_module_alias %>').AppContainer;ReactDOM.render(React.createElement(AppContainer),document.getElementById('spa'));})();</script>
至于路由,既然我们已经在新前端中实现前端路由,那在Rails端的后端(页面)路由就可以委托给前端:
scope 'spa' doget '/', :to => 'spa#index', :as => 'spa'get '*pages', :to => 'spa#index'end
经由以上方案,我们在尽量短的周期改写了更多的业务模块,对运维的影响也非常小。对于这些业务模块,我们预期在其改写后端微服务时将前端代码从Rails里彻底分离出来,完成该模块的前后端分离。
在上述Ruby On Rails项目之外,FreeWheel也启动了若干个新项目。这些项目一步到位,直接按照前后端分离架构设计开发,其前端完全基于SparkUI。我们也基于Nginx开发了一套轻量的静态资源服务器,前端利用Webpack编译打包成tar包并独立上线。
SparkUI独立工程
在小步快跑阶段,我们将SparkUI源码直接放在Rails公共Module中,令我们可以快速验证可重用组件的设计是否满足业务需要。然而这样的结构会带来几方面问题:
版本管理。任何对Spark的迭代都会直接影响到业务模块;
开发效率。SparkUI是纯JS库,Rails工程开发环境给SparkUI开发带来一定负担;
源码权限。任何业务模块开发人员均可修改SparkUI代码,带来潜在代码冲突;
跨工程复用。任何Rails工程之外的工程在利用SparkUI时都会比较繁琐。
我们在SparkUI推出1.0版本时,将其源码从Rails工程中摘出,移入一个新的纯前端工程。SparkUI在这个新工程中,仍由Babel和Webpack打包,但会作为library发布到公司Nexus上私有NPM Repository里。Rails工程或其他纯前端工程在其package.json和.npmrc配置中声明对特定版本SparkUI的依赖,执行npm install后则可以在前端代码中使用SparkUI。
这一改变大大解放了SparkUI和业务模块两方的生产力:
独立的代码库可以隐藏部分SparkUI的内部API或工具代码,防止业务模块中滥用;
不同的发版节奏令SparkUI可以追逐更高的代码质量,目前其源代码共计9.3万行,单元测试覆盖率高达99.43%;
业务模块代码可以更有计划地升级SparkUI版本,在此之前无须反复回归测试。
新老JS代码混用
对于Rails工程的部分功能模块,其前端实现有很大一部分是基于jQuery开发的JS。虽然这些代码并不是基于React或SparkUI开发的,但它们也可以直接在前后端分离后的前端中独立使用。我们在统一的粒度下,创建了一层对React友好的适配器spark-adapter,对原有jQuery JS接口进行了封装和隔离。业务模块开发人员可以自行决定对于这一部分JS代码是基于SparkUI重写还是放在Adapter中以继续沿用。
质量保证
作为商业应用,其软件质量是绝不能妥协的。前后端分离改造也不能成为降低软件质量的理由。我们保证质量的核心是测试:
SparkUI组件库本身要具有最高标准的单元测试覆盖率;
业务模块改写为新前端时,也要基于SparkUI提供的基础设施编写单元测试;
对于Rails工程原有的自动化测试脚本,在业务模块改造为基于SparkUI的新前端时,也要同时更新;
将测试加入CI (Continuous Integration) Pipeline,一有Merge Request提交就执行测试,测试成功才允许Merge;
各组lead在Merge Request上做代码审查时严格把关。
另外一个有效实践是为新上线新前端的模块提供回滚机制。因为在这一阶段,Rails工程里特定功能模块的新老前端代码可以同时存在,只需在功能入口处设置一个开关,就可以在线上执行新前端遇到严重问题时随时切换回老前端。
总结
前后端分离架构是诸多前端应用系统的必经之路,而现实情况往往需要顾及诸多历史架构。本文以单体应用为背景,设计开发可重用组件库为手段,在保证效率与质量的基础上,逐步改造为前后端分离架构。希望对同样面对这一情况的读者有所帮助。
文中提到的SparkUI框架,其中与FreeWheel业务并不直接相关的纯技术部分,比如spark-modula、spark-router等包,我们已计划将其逐步开源。希望届时能与更多的前端技术专家和群体深入探讨、共同进步,并最终对前端社区有所贡献。
前端之巅
「前端之巅」是 InfoQ 旗下关注前端技术的垂直社群。投稿请发邮件到 editors@cn.infoq.com,注明“前端之巅投稿”。
