@pastqing
2016-05-12T01:30:36.000000Z
字数 2773
阅读 12362
LDA的基本思想与应用
机器学习
一、LDA入门
LDA是一种概率主题模型,英文是Latent Dirichlet Allocation。
它的基本思想是:将文档集中每篇文档的主题以概率分布的形式给出,从而通过分析一些文档抽取出它们的主题(分布)出来后,便可以根据主题(分布)进行主题聚类或文本分类。同时,它是一种典型的词袋模型,即一篇文档是由一组词构成,词与词之间没有先后顺序的关系。此外,一篇文档可以包含多个主题,文档中每一个词都由其中的一个主题生成。
1. LDA生成文档
LDA是一个生成模型 , 它按照如下规则生成文档:

2. LDA物理过程
根据上述LDA生成文档的过程,可以总结为:
按照先验概率P(d)选择一篇文档d
从Dirchlet分布α中取样生成文档d的主题分布θ,也就是说主题分布θ由参数为α的Dirchlet分布生成。
从主题的多项式分布θ中取样生成文档d第j个词的主题z
从Dirchlet分布β中取样生成主题z对应的词语分布φ,也就是说词语分布φ由参数为β的Dirchlet分布生成。
从词语的多项式分布φ中取样生成词语w。
LDA生成文档的过程中,先从Dirchlet先验中随机抽取出主题分布,然后从主题分布中抽取出主题,最后从确定后的主题对应的词分布中随机抽取词。
注这里Dirchlet“随机抽取”分布,也是有一些规律的。具体可以查找相关数学理论。
下面给出LDA生成文档过程的概率图模型
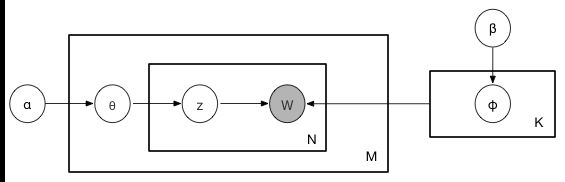
N表示文档的单词总数, M表示文档数, K表示有K个主题。
假定语料库中共有M篇文章,每篇文章下的Topic的主题分布是一个从参数为α的Dirichlet先验分布中采样得到的Multinomial分布,每个Topic下的词分布是一个从参数为β的Dirichlet先验分布中采样得到的Multinomial分布.
对于某篇文章中的第N个词,首先从该文章中出现的每个主题的Multinomial分布(主题分布)中选择或采样一个主题,然后再在这个主题对应的词的Multinomial分布(词分布)中选择或采样一个词。不断重复这个随机生成过程,直到M篇文章全部生成完成。
根据上面的概率图,我们可以给出一个联合分布:
此处的符号表示稍微不够严谨, 向量 n→k, n→m 都用 n 表示, 主要通过下标进行区分, k 下标为 topic 编号, m 下标为文档编号。
3. 用Gibbs采样对LDA进行参数估计
上面说了LDA生成文档的过程,现在反过来,假定了文档已经产生,反推其主题分布和词分布。这时候就需要估计未知参数。即需要估计的未知参数是φ(Topic-word)和θ(Doc-Topic)
MCMC方法先设法构造一条马尔科夫链,使其收敛到平稳分布恰为待估计参数的后验分布,然后通过这条马尔科夫链来产生符合后验分布的样本,并基于这些样本进行估计。
Gibbs采样对于LDA实际的物理过程如下图所示
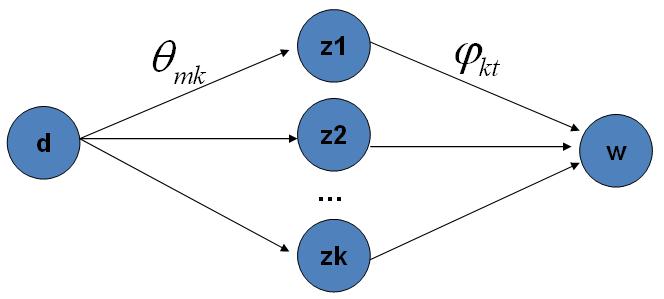
就是对这K条路径进行采样。
4. LDA训练和预测过程
训练:
利用LDA模型,我们的目标有两个:
- 估计模型中的参数φ→1,⋯,φ→K 和 θ→1,⋯,θ→M
- 对于新来的文档doc, 我们能够计算这篇topic分布。
有了 Gibbs Sampling公式,我们就可以基于语料训练LDA模型,并应用训练得到的模型对新的文档进行 topic 语义分析。训练的过程就是获取语料中的 (z,w) 的样本,而模型中的所有的参数都可以基于最终采样得到的样本进行估计。训练的流程很简单:

在 Gibbs Sampling 收敛之后,统计每篇文档中的 topic 的频率分布,我们就可以计算每一个 p(topic|doc) 概率,于是就可以计算出每一个θ→m。由于参数θ→m 是和训练语料中的每篇文档相关的,对于我们理解新的文档并无用处,所以工程上最终存储 LDA 模型时候一般没有必要保留。通常,在 LDA 模型训练的过程中,我们是取 Gibbs Sampling 收敛之后的 n 个迭代的结果进行平均来做参数估计,这样模型质量更高。
预测:

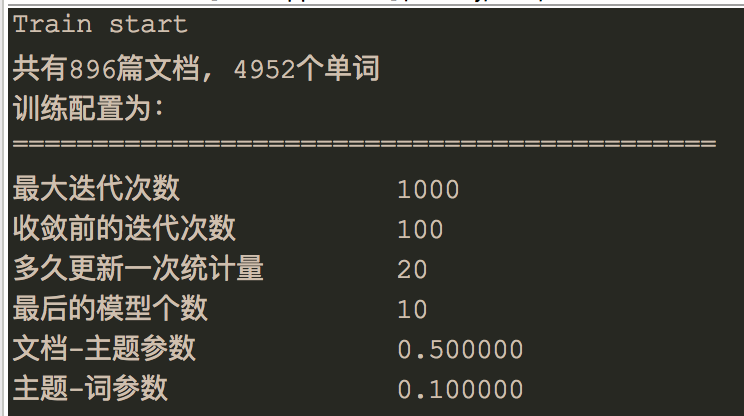
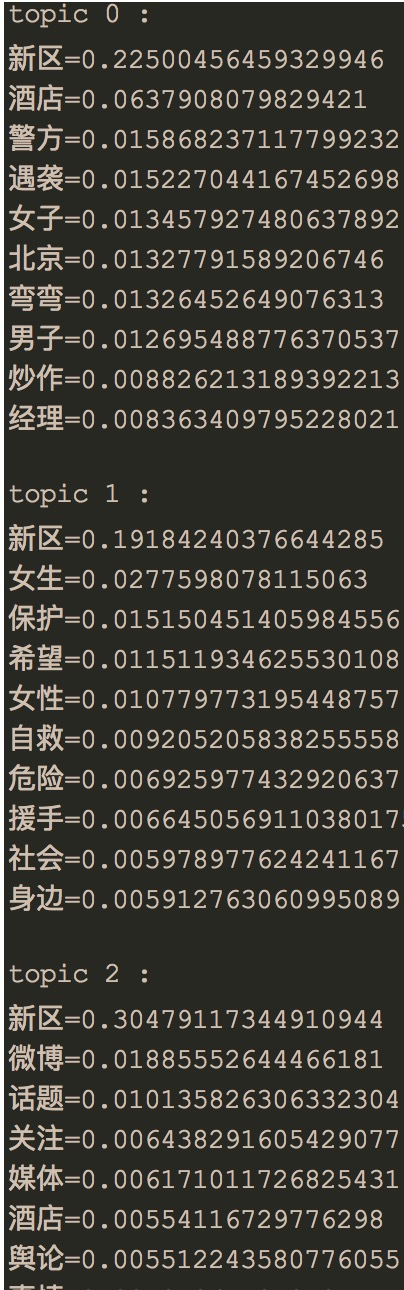
这里给出我实验的数据:
训练集使用了部分新浪微博的数据和搜狗实验室文本分类的数据:
5.应用
相似文档发现: 利用LDA训练完得到的doc-topic文件,为每个doc分别计算其他doc与该doc的主题距离,再按照距离从小到大排序,输出每个doc最相关的前n个主题文章
结合LR(逻辑回归)做一些推荐:
Topic rank:由于LDA输出的主题编号是随机的,主题也是未经排序的,因此可以开发一个为每个主题打分的算法,将显著的、有特色的主题打分高往前排,而将垃圾的、意义不明的主题往后排。
二、论文研究过程中的一些问题以及接下来的工作
1.问题
LDA这个生成模型,属于3层贝叶斯的一个模型,需要数学概率论理论基础。为了更好的得到实验结果,必须更加理解模型中包含的Dirchlet过程,以及MCMC的采样过程。实验中发现输出的topic-word矩阵每一个topic下第一个word总是相同的,可能采样算法需要调整。
相关资料:LDA数学八卦LDA这个模型是一个很好的生成式模型,但是最大的问题就如何确定给出的主题数K的范围呢?这里就涉及到下一个使用Dichlet过程的模型DPMM模型。
相关资料:扩展DPMM模型在短文本主题识别中的应用针对于短文本语料,如果仅仅对把每条微博进行分词,去停用词等处理,发现现有的分词算法对于短文分词来说效果都不好。因此需要针对短文本,结合一些基本的文本挖掘方法,提高短文本的特征提取效果。
相关资料:Short Text Understanding Through Lexical-Semantic Analysis(2015年的)
2.进一步工作
我个人认为LDA是一个非常好的模型,基于贝叶斯体系的这种方法很好。从论文研究现状来看,研究LDA的非常多。

研究DPMM的感觉不是很多,下一步打算在研究好LDA的基础上,开始研究DPMM这个模型。通过移动新闻推荐技术及其应用研究综述以及上次林老师分享的基于上下文融合的过程挖掘论文,想在微博上下文融合方面做点研究。
三、LDA理论基础
LDA的理论基础可以用一个函数,四个分布, 两个模型, 一个采样来概括。
