@pastqing
2016-04-05T13:54:38.000000Z
字数 3000
阅读 3121
Java集合框架——PriorityQueue
java java-collection-framwork
一、PriorityQueue的数据结构
JDK7中PriorityQueue(优先级队列)的数据结构是二叉堆。准确的说是一个最小堆。
二叉堆是一个特殊的堆, 它近似完全二叉树。二叉堆满足特性:父节点的键值总是保持固定的序关系于任何一个子节点的键值,且每个节点的左子树和右子树都是一个二叉堆。
当父节点的键值总是大于或等于任何一个子节点的键值时为最大堆。 当父节点的键值总是小于或等于任何一个子节点的键值时为最小堆。
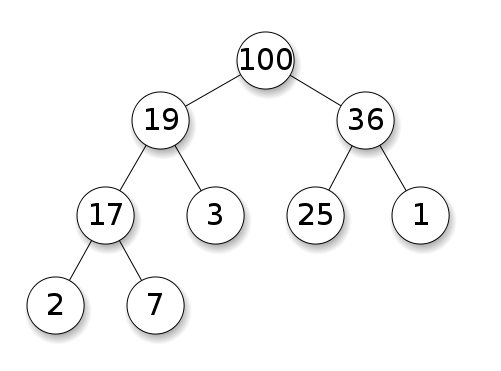
下图是一个最大堆
priorityQueue队头就是给定顺序的最小元素。
priorityQueue不允许空值且不支持non-comparable的对象。priorityQueue要求使用
Comparable和Comparator接口给对象排序,并且在排序时会按照优先级处理其中的元素。priorityQueue的大小是无限制的(unbounded), 但在创建时可以指定初始大小。当增加队列元素时,队列会自动扩容。
priorityQueue不是线程安全的, 类似的PriorityBlockingQueue是线程安全的。
二、PriorityQueue源码分析
成员:
priavte transient Object[] queue;private int size = 0;
1.PriorityQueue构造小顶堆的过程
这里我们以priorityQueue构造器传入一个容器为参数PriorityQueue(Collecntion<? extends E>的例子:
构造小顶堆的过程大体分两步:
复制容器数据,检查容器数据是否为null
private void initElementsFromCollection(Collection<? extends E> c) {Object[] a = c.toArray();// If c.toArray incorrectly doesn't return Object[], copy it.if (a.getClass() != Object[].class)a = Arrays.copyOf(a, a.length, Object[].class);int len = a.length;if (len == 1 || this.comparator != null)for (int i = 0; i < len; i++)if (a[i] == null)throw new NullPointerException();this.queue = a;this.size = a.length;}
调整,使数据满足小顶堆的结构。
首先介绍两个调整方式siftUp和siftDownsiftDown: 在给定初始化元素的时候,要调整元素,使其满足最小堆的结构性质。因此不停地从上到下将元素x的键值与孩子比较并做交换,直到找到元素x的键值小于等于孩子的键值(即保证它比其左右结点值小),或者是下降到叶子节点为止。
例如如下的示意图,调整9这个节点:
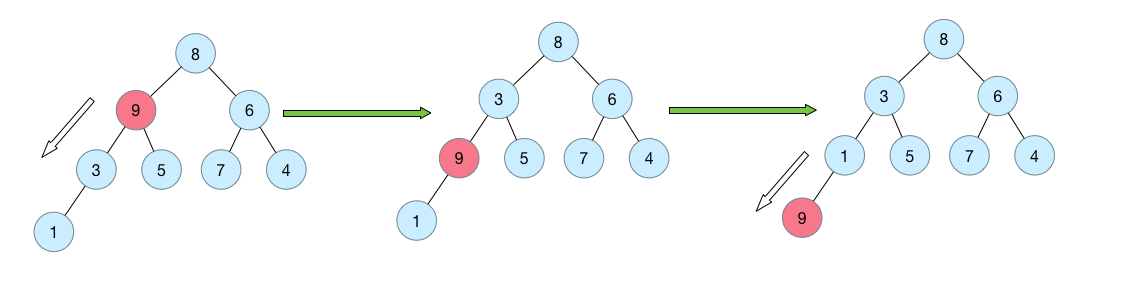
private void siftDownComparable(int k, E x) {Comparable<? super E> key = (Comparable<? super E>)x;int half = size >>> 1; // size/2是第一个叶子结点的下标//只要没到叶子节点while (k < half) {int child = (k << 1) + 1; // 左孩子Object c = queue[child];int right = child + 1;//找出左右孩子中小的那个if (right < size &&((Comparable<? super E>) c).compareTo((E) queue[right]) > 0)c = queue[child = right];if (key.compareTo((E) c) <= 0)break;queue[k] = c;k = child;}queue[k] = key;}
siftUp: priorityQueue每次新增加一个元素的时候是将新元素插入对尾的。因此,应该与siftDown有同样的调整过程,只不过是从下(叶子)往上调整。
例如如下的示意图,填加key为3的节点:
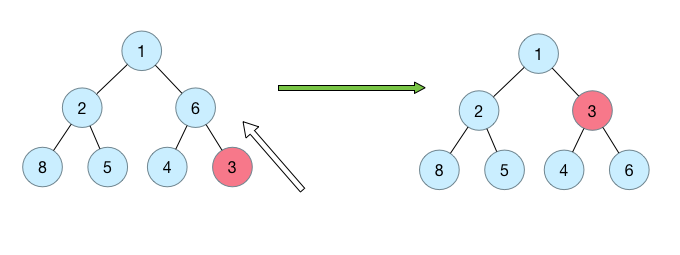
private void siftUpComparable(int k, E x) {Comparable<? super E> key = (Comparable<? super E>) x;while (k > 0) {int parent = (k - 1) >>> 1; //获取parent下标Object e = queue[parent];if (key.compareTo((E) e) >= 0)break;queue[k] = e;k = parent;}queue[k] = key;}
总体的建立小顶堆的过程就是:
private void initFromCollection(Collection<? extends E> c) {initElementsFromCollection(c);heapify();}
其中heapify就是siftDown的过程。
2.PriorityQueue容量扩容过程
从实例成员可以看出,PriorityQueue维护了一个Object[], 因此它的扩容方式跟顺序表ArrayList相差不多。
这里只给出grow方法的源码
private void grow(int minCapacity) {int oldCapacity = queue.length;// Double size if small; else grow by 50%int newCapacity = oldCapacity + ((oldCapacity < 64) ?(oldCapacity + 2) :(oldCapacity >> 1));// overflow-conscious codeif (newCapacity - MAX_ARRAY_SIZE > 0)newCapacity = hugeCapacity(minCapacity);queue = Arrays.copyOf(queue, newCapacity);}
可以看出,当数组的Capacity不大的时候,每次扩容也不大。当数组容量大于64的时候,每次扩容double。
三、PriorityQueue的应用
这里给出一个最简单的应用:从动态数据中求第K个大的数。
思路就是维持一个size = k 的小顶堆。
//data是动态数据//heap维持动态数据的堆//res用来保存第K大的值public boolean kthLargest(int data, int k, PriorityQueue<Integer> heap, int[] res) {if(heap.size() < k) {heap.offer(data);if(heap.size() == k) {res[0] = heap.peek();return true;}return false;}if(heap.peek() < data) {heap.poll();heap.offer(data);}res[0] = heap.peek();return true;}
