@pastqing
2016-04-12T13:23:27.000000Z
字数 9113
阅读 3372
java集合框架——Map(一)
java java-collection-framwork
一、HashMap的基本特性
读完JDK源码HashMap.class中的注释部分,可以总结出很多HashMap的特性。
HashMap允许key与value都为null, 而Hashtable是不允许的。
HashMap是线程不安全的, 而Hashtable是线程安全的
HashMap中的元素顺序不是一直不变的,随着时间的推移,同一元素的位置也可能改变(resize的情况)
遍历HashMap的时间复杂度与其的容量(capacity)和现有元素的个数(size)成正比。如果要保证遍历的高效性,初始容量(capacity)不能设置太高或者平衡因子(load factor)不能设置太低。
与之前的相关List同样, 由于HashMap是线程不安全的, 因此迭代器在迭代过程中试图做容器结构上的改变的时候, 会产生fail-fast。通过
Collections.synchronizedMap(HashMap)可以得到一个同步的HashMap
二、Hash table 数据结构分析
Hash table(散列表,哈希表),是根据关键字而直接访问内存存储位置的数据结构。也就是说散列表建立了关键字和存储地址之间的一种直接映射
如下图, key经过散列函数得到buckets的一个索引位置。
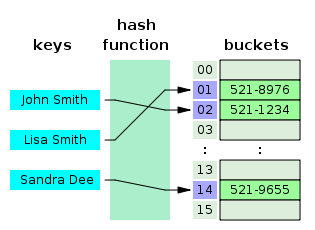
通过散列函数获取index不可避免会出现相同的情况,也就是冲突。下面简单介绍几种解决冲突的方法:
- Open addressing(开放定址法):此方法的基本思想就是遇到冲突时,顺序扫描表下N个位置,如果有空闲就填入。具体算法不再说明,下面是示意图:
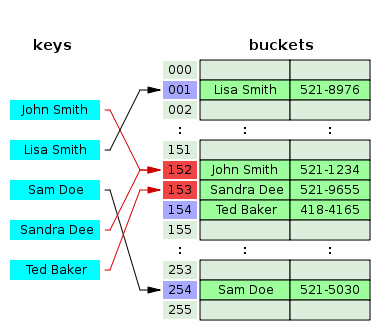
- Separate chaining(拉链):此方法基本思想就是遇到冲突时,将相同索引值的Entry用链表串起来。具体算法不再说明,下面是示意图:

JDK中的HashMap解决冲突的方法就是用的Separate chaining法。
三、HashMap源码分析(JDK1.7)
1、HashMap读写元素
- Entry
HashMap中的存放的元素是Entry类型,下面给出源码中Entry的源码:
static class Entry<K,V> implements Map.Entry<K,V> {final K key;V value;Entry<K,V> next;int hash;Entry(int h, K k, V v, Entry<K,V> n) {value = v;next = n;key = k;hash = h;}//key, value的get与set方法省略,get与set操作会在后面的迭代器中用到...public final boolean equals(Object o) {if (!(o instanceof Map.Entry))return false;Map.Entry e = (Map.Entry)o;Object k1 = getKey();Object k2 = e.getKey();if (k1 == k2 || (k1 != null && k1.equals(k2))) {Object v1 = getValue();Object v2 = e.getValue();if (v1 == v2 || (v1 != null && v1.equals(v2)))return true;}return false;}//此处将Key的hashcode与Value的hashcode做亦或运算得到Entry的hashcodepublic final int hashCode() {return Objects.hashCode(getKey()) ^ Objects.hashCode(getValue());}public final String toString() {return getKey() + "=" + getValue();}/*** This method is invoked whenever the value in an entry is* overwritten by an invocation of put(k,v) for a key k that's already* in the HashMap.*/void recordAccess(HashMap<K,V> m) {}/*** This method is invoked whenever the entry is* removed from the table.*/void recordRemoval(HashMap<K,V> m) {}}
一个Entry包括key, value, hash以及下一个Entry的引用, 很明显这是个单链表, 其实现了Map.Entry接口。
recordAcess(HashMap<K, V> 与recordRemoval(HashMap<K, V>)在HashMap中是没有任何具体实现的。但是在LinkedHashMap这两个方法用来实现LRU算法。
- get:读元素
从HashMap中获取相应的Entry, 下面给出get相关源码:
public V get(Object key) {//key是null的情况if (key == null)return getForNullKey();//根据key查找EntryEntry<K,V> entry = getEntry(key);return null == entry ? null : entry.getValue();}
getForNullKey源码
private V getForNullKey() {if (size == 0) {return null;}//遍历冲突链for (Entry<K,V> e = table[0]; e != null; e = e.next) {if (e.key == null)return e.value;}return null;}
key为Null的Entry存放在table[0]中,但是table[0]中的冲突链中不一定存在key为null, 因此需要遍历。
根据key获取entry:
final Entry<K,V> getEntry(Object key) {if (size == 0) {return null;}int hash = (key == null) ? 0 : hash(key);//通过hash得到table中的索引位置,然后遍历冲突链表找到Keyfor (Entry<K,V> e = table[indexFor(hash, table.length)];e != null;e = e.next) {Object k;if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))return e;}return null;}
以上就是HashMap读取一个Entry的过程及其源码。时间复杂度O(1)
- put:写元素
HashMap中put操作相对复杂, 因为put操作的过程中会有HashMap的扩容操作。
新写入一个元素,如果HashMap中存在要写入元素的key,则执行的是替换value的操作,相当于update。下面是put源码:
public V put(K key, V value) {//空表table的话,根据size的阈值填充if (table == EMPTY_TABLE) {inflateTable(threshold);}//填充key为Null的Entryif (key == null)return putForNullKey(value);//生成hash,得到索引Index的映射int hash = hash(key);int i = indexFor(hash, table.length);//遍历当前索引的冲突链,找是否存在对应的keyfor (Entry<K,V> e = table[i]; e != null; e = e.next) {Object k;//如果存在对应的key, 则替换oldValue并返回oldValueif (e.hash == hash && ((k = e.key) == key || key.equals(k))) {V oldValue = e.value;e.value = value;e.recordAccess(this);return oldValue;}}//冲突链中不存在新写入的Entry的keymodCount++;//插入一个新的EntryaddEntry(hash, key, value, i);return null;}
addEntry与createEntry源码:
void addEntry(int hash, K key, V value, int bucketIndex) {//插入新Entry前,先对当前HashMap的size和其阈值大小的判断,选择是否扩容if ((size >= threshold) && (null != table[bucketIndex])) {resize(2 * table.length);hash = (null != key) ? hash(key) : 0;bucketIndex = indexFor(hash, table.length);}createEntry(hash, key, value, bucketIndex);}
void createEntry(int hash, K key, V value, int bucketIndex) {Entry<K,V> e = table[bucketIndex];//头插法,新写入的entry插入当前索引位置的冲突链第一个Entry的前面table[bucketIndex] = new Entry<>(hash, key, value, e);size++;}
以上就是HashMap写入一个Entry的过程及其源码。时间复杂度O(1)
- remove移除元素:
final Entry<K,V> removeEntryForKey(Object key) {if (size == 0) {return null;}//根据key计算hash值,获取索引int hash = (key == null) ? 0 : hash(key);int i = indexFor(hash, table.length);//链表的删除,定义两个指针,pre表示前驱Entry<K,V> prev = table[i];Entry<K,V> e = prev;//遍历冲突链,删除所有为key的Enrtywhile (e != null) {Entry<K,V> next = e.next;Object k;//找到了if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k)))) {modCount++;size--;//找到第一个结点就是要删除的结点if (prev == e)table[i] = next;elseprev.next = next;e.recordRemoval(this);return e;}prev = e;e = next;}return e;}
以上就是HashMap删除一个Entry的过程及其源码。时间复杂度O(1)
2、HashMap的哈希原理(hash function)
HashMap中散列函数的实现是通过hash(Object k) 与 indexFor(int h, int length)完成, 下面看下源码:
final int hash(Object k) {int h = hashSeed;if (0 != h && k instanceof String) {return sun.misc.Hashing.stringHash32((String) k);}h ^= k.hashCode();// This function ensures that hashCodes that differ only by// constant multiples at each bit position have a bounded// number of collisions (approximately 8 at default load factor).//为了降低冲突的几率h ^= (h >>> 20) ^ (h >>> 12);return h ^ (h >>> 7) ^ (h >>> 4);}
获取Index索引源码:
static int indexFor(int h, int length) {// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";return h & (length-1);}
HashMap通过一个hash function将key映射到[0, table.length]的区间内的索引。这样的索引方法大体有两种:
hash(key) % table.length, 其中length必须为素数。JDK中HashTable利用此实现方式。
具体使用素数的原因,可以查找相关算法资料证明,这里不再陈述。hash(key) & (table.length - 1 ) 其中length必须为2指数次方。JDK中HashMap利用此实现方式。
因为length的大小为2指数次方倍, 因此hash(key) & (table.length - 1)总会在[0, length - 1]之间。但是仅仅这样做的话会出现问题一个冲突很大的问题,因为JAVA中hashCode的值为32位,当HashMap的容量偏小,例如16时,做异或运算时,高位总是被舍弃,低位运算后却增加了冲突发生的概率。
因此为了降低冲突发生的概率, 代码中做了很多位运算以及异或运算。
3、HashMap内存分配策略
- 成员变量capacity与loadFactor
HashMap中要求容量Capacity是2的指数倍, 默认容量是1 << 4 = 16。HashMap中还存在一个平衡因子(loadFactor),过高的因子会降低存储空间但是查找(lookup,包括HashMap中的put与get方法)的时间就会增加。 loadFactor默认值为0.75是权衡了时间复杂度以及空间复杂度给出的最优值。
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16static final int MAXIMUM_CAPACITY = 1 << 30;static final float DEFAULT_LOAD_FACTOR = 0.75f;
- HashMap的构造函数
HashMap的构造就是设置capacity,与loadFactor的初始值
public HashMap(int initialCapacity, float loadFactor) {if (initialCapacity < 0)throw new IllegalArgumentException("Illegal initial capacity: " +initialCapacity);if (initialCapacity > MAXIMUM_CAPACITY)initialCapacity = MAXIMUM_CAPACITY;if (loadFactor <= 0 || Float.isNaN(loadFactor))throw new IllegalArgumentException("Illegal load factor: " +loadFactor);this.loadFactor = loadFactor;threshold = initialCapacity;init();}
之前说过HashMap中capacity必须是2的指数倍, 构造函数里并没有限制,那如何保证保证capacity的值是2的指数倍呢?
在put操作时候,源码中会判断目前的哈希表是否是空表,如果是则调用inflateTable(int toSize)
private void inflateTable(int toSize) {// Find a power of 2 >= toSizeint capacity = roundUpToPowerOf2(toSize);threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);table = new Entry[capacity];initHashSeedAsNeeded(capacity);}
其中roundUpToPowerOf2就是获取大于等于给定参数的最小的2的n次幂
private static int roundUpToPowerOf2(int number) {// assert number >= 0 : "number must be non-negative";return number >= MAXIMUM_CAPACITY? MAXIMUM_CAPACITY: (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1;}
Integer.hightestOneBit(int)是将给定参数的最高位的1保留,剩下的变为0的操作,简单说就是将参数int变为小于等于它的最大的2的n次幂。
若number为2的n次幂,减1后最高位处于原来的次高位, 再左移1位仍然可以定位到最高位位置
若number不是2的n次幂,减1左移1位后最高位仍是原来的最高位
- 扩容:
HashMap在put操作的时候会发生resize行为,具体源码如下:
void resize(int newCapacity) {Entry[] oldTable = table;int oldCapacity = oldTable.length;//哈希表已达到最大容量,1 << 30if (oldCapacity == MAXIMUM_CAPACITY) {threshold = Integer.MAX_VALUE;return;}Entry[] newTable = new Entry[newCapacity];//将oldTable中的Entry转移到newTable中//initHashSeedAsNeeded的返回值决定是否重新计算hash值transfer(newTable, initHashSeedAsNeeded(newCapacity));table = newTable;//重新计算thresholdthreshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);}
void transfer(Entry[] newTable, boolean rehash) {int newCapacity = newTable.length;//遍历oldTablefor (Entry<K,V> e : table) {//遍历冲突链while(null != e) {Entry<K,V> next = e.next;if (rehash) {//重新计算hash值e.hash = null == e.key ? 0 : hash(e.key);}int i = indexFor(e.hash, newCapacity);//将元素插入到头部,头插法e.next = newTable[i];newTable[i] = e;e = next;}}}
以上就是HashMap内存分配的整个过程,总结说来就是,hashMap在put一个Entry的时候会检查当前容量与threshold的大小来选择是否扩容。每次扩容的大小是2 * table.length。在扩容期间会根据initHashSeedAsNeeded判断是否需要重新计算hash值。
四、HashMap的迭代器
HashMap中的ValueIterator, KeyIterator, EntryIterator等迭代器都是基于HashIterator的,下面看下它的源码:
private abstract class HashIterator<E> implements Iterator<E> {Entry<K,V> next; // next entry to returnint expectedModCount; // For fast-failint index; // current slot,table indexEntry<K,V> current; // current entryHashIterator() {expectedModCount = modCount;//在哈希表中找到第一个Entryif (size > 0) {Entry[] t = table;while (index < t.length && (next = t[index++]) == null);}}public final boolean hasNext() {return next != null;}final Entry<K,V> nextEntry() {//HashMap是非线程安全的,遍历时仍然先判断是否有表结构的修改if (modCount != expectedModCount)throw new ConcurrentModificationException();Entry<K,V> e = next;if (e == null)throw new NoSuchElementException();if ((next = e.next) == null) {//找到下一个EntryEntry[] t = table;while (index < t.length && (next = t[index++]) == null);}current = e;return e;}public void remove() {if (current == null)throw new IllegalStateException();if (modCount != expectedModCount)throw new ConcurrentModificationException();Object k = current.key;current = null;HashMap.this.removeEntryForKey(k);expectedModCount = modCount;}}
Key, Value, Entry这个三个迭代器进行封装就变成了keySet, values, entrySet三种集合视角。这三种集合视角都支持对HashMap的remove, removeAll, clear操作,不支持add, addAll操作。
以上就是HashMap的简要分析。
