@pastqing
2016-01-08T06:00:38.000000Z
字数 2227
阅读 3538
基于某日历app或者微博点赞数据的推荐系统
机器学习
一、背景意义
推荐系统并不是新鲜物,在很久之前就存在。随着互联网的深入发展,越来越多的信息在互联网上传播,产生了严重的信息过载。如果不采用一定的手段,用户很难从如此多的信息流中找到对自己有价值的信息。
解决信息过载问题的其中的一个手段就是设计并实施推荐系统。在很多情况下用户的意图不明确,或者很难用清晰的语义表达,甚至连用户自己都不清楚自己的需求。这种情景下解决信息过载,理解用户意图,为用户推送个性化的结果,推荐系统便是一种比较好的选择。
下面简述一下本推荐系统推荐列表构成
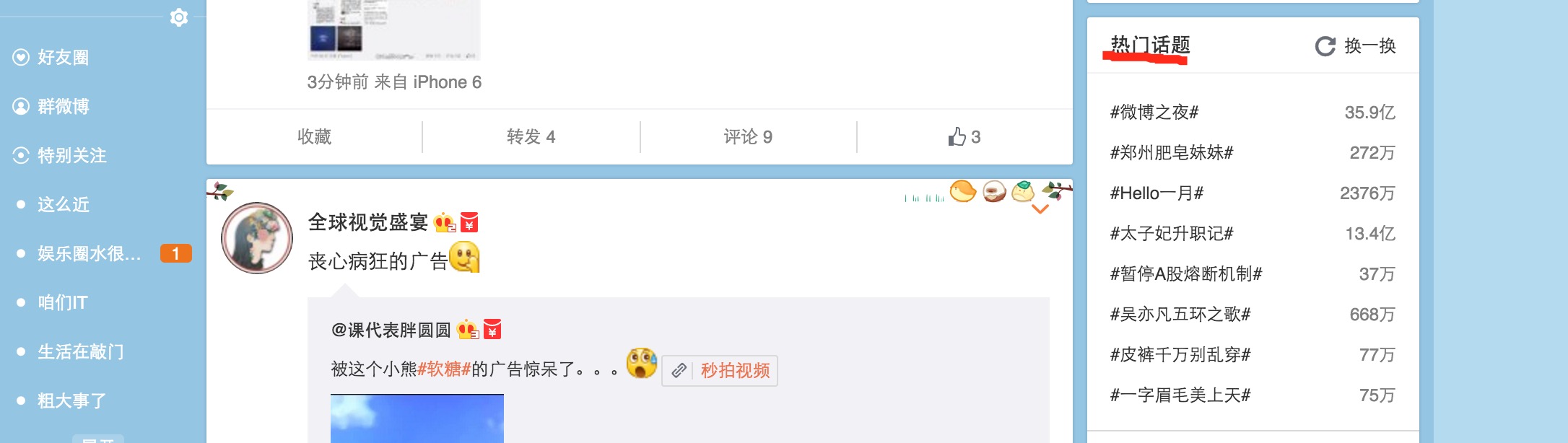
热度推荐:根据统计数据,推荐给用户当前热门的微博话题。
例如新浪微博的热门话题推荐
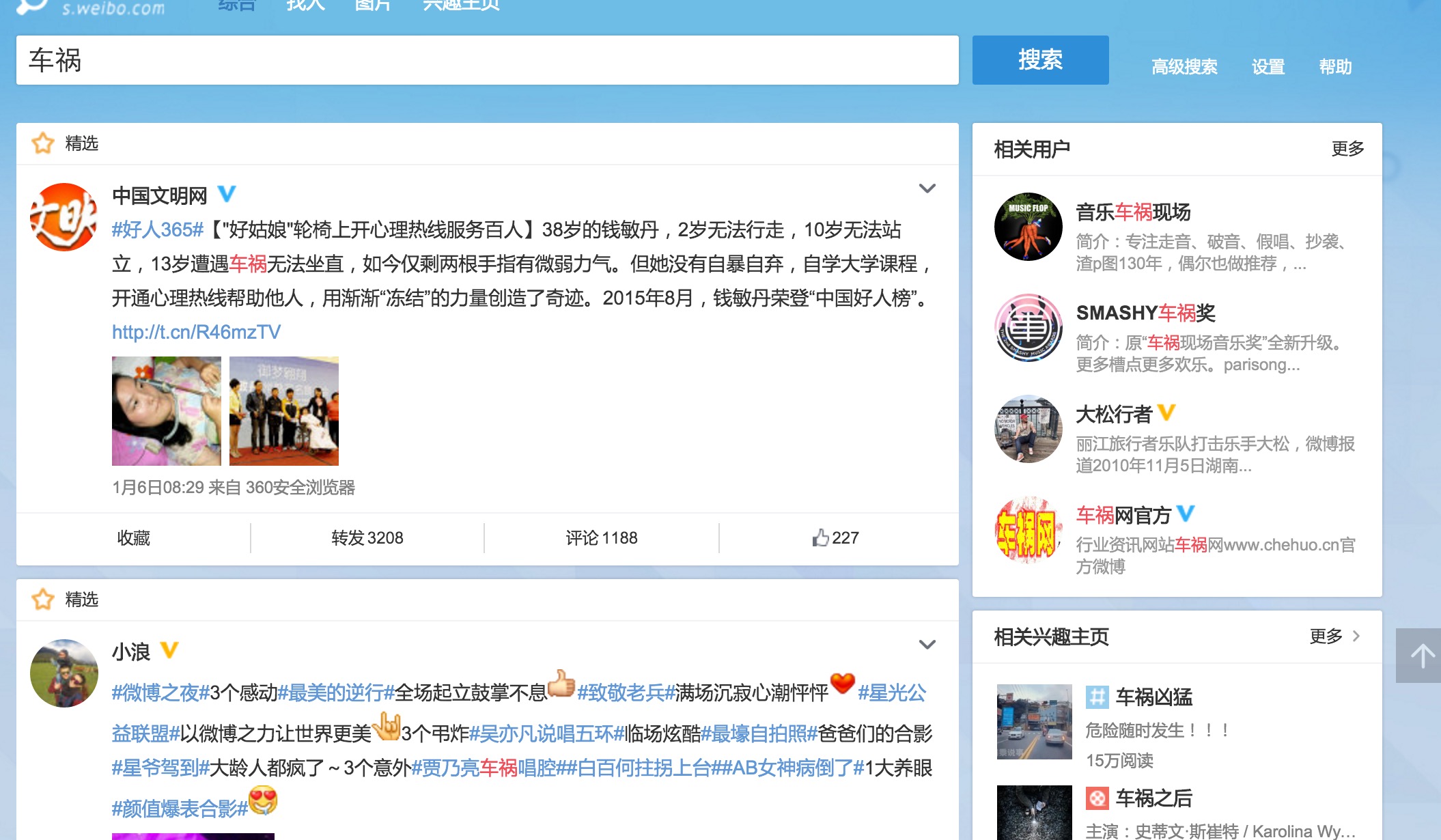
相关性推荐:根据用户的历史数据,挖掘用户历史数据中的相似关系,从而推荐相关的话题。
例如新浪微博输入查询词后相关性推荐:
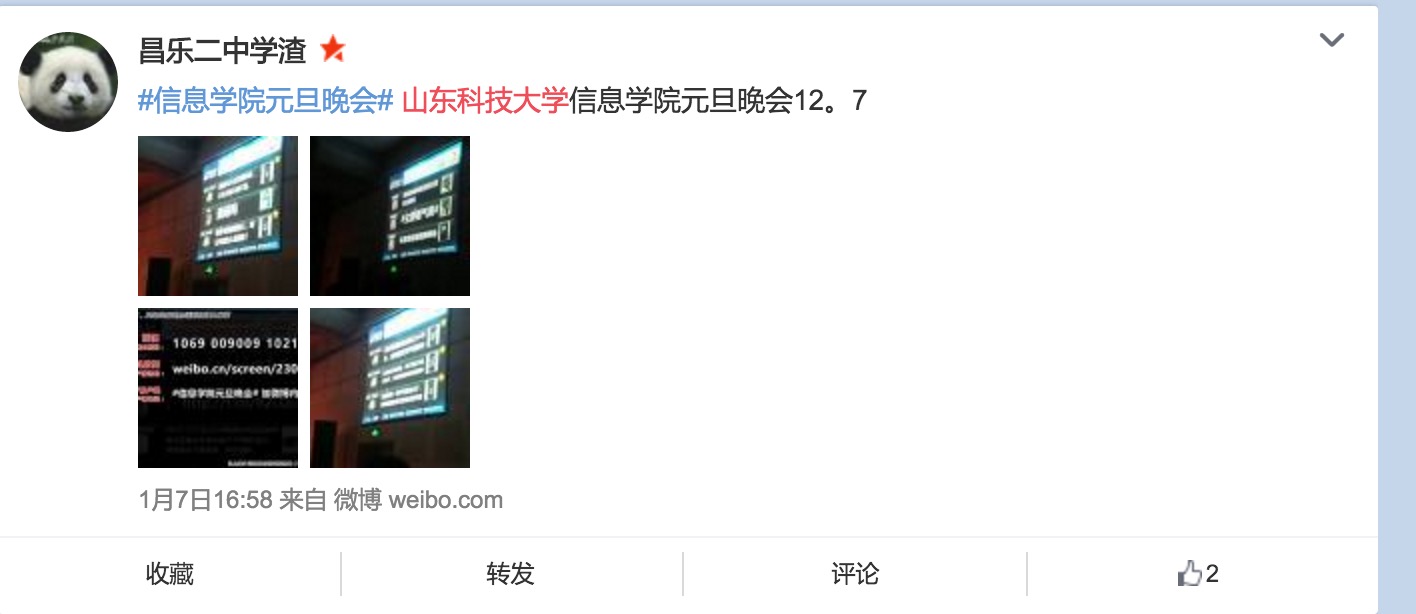
互补性推荐:根据用户的历史浏览话题记录以及语料库, 挖掘其子话题,将子话题推荐给用户。
比如我在新浪微博以中山东科技大学作为检索词,可能会检索出一些子话题的内容
以上是我设想的推荐系统的输入和输出。
二、推荐算法总体思路
1.协同过滤
协同过滤是推荐系统中的常用推荐系统算法,但是不同的数据会有的差异化。
- 基于用户的协同过滤(user-based)
- 基本假设:某App用户或者微博用户可能喜欢与其相似的用户的帖子或者微博。
- 基本思想:
利用用户的点赞(点踩), 收藏, 浏览等行为历史记录计算用户的相似度(具有相似偏好的用户,其在Item上的点赞等行为情况也倾向于更相似) - 基本步骤
假设对某一个user进行推荐
1)数据预处理
2)计算它的Top K relevance Users
利用向量距离、夹角余弦相似度、Person相关性系数等方法。
3)进行推荐:
Top-N推荐:统计这前K个用户中出现频率最高且目标用户未体验过的Item(微博或帖子),然后构建推荐列表
关联推荐:将前K个用户赞过的帖子看做K个集合,给定支持度和置信度,进行关联规则挖掘。得到关联规则后依据用户的记录推荐。
基于Item的协同过滤(item-based)
- 基本假设:用户可能赞(踩)和他之前赞(踩)的帖子或者微博。
- 基本思想及步骤
1)利用user-item rating matrix,计算item之间的相似度
对于微博,帖子等数据不仅存在文本内容,还包括图片内容,如下面的例子:
加入图片的因素后,仅仅单独计算图片相似度进行推荐是很不准确的,应该根据此微博的文本与图片的共现关系计算相似度。同一个话题下出现的多个图片之间的相似度不能简单直接计算。
2)进行预测:
加权和预测:以相似度为权重,对用户点赞情况进行加权平均
线性回归预测,先做线性回归近似,再算相似度,再加权平均。
2.基于location的推荐(location-based)
对于移动设备而言,与PC端最大的区别之一是移动设备的位置是经常发生变化的。不同的地理位置反映了不同的用户场景,在具体的业务中可以充分利用用户所处的地理位置。在推荐中,可以根据用户的实时地理位置、工作地、居住地等地理位置触发相应的策略。
- 根据App用户或者微博用户的历史浏览,历史点赞记录,历史行为记录等挖掘出某一个粒度的区域内的区域热点话题
区域热点话题
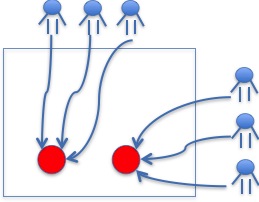
当给一个新用户推荐的时候, 根据用户的地理位置构建推荐列表
也可以根据用户出现的地理位置,采用协同过滤的方式计算用户的相似度
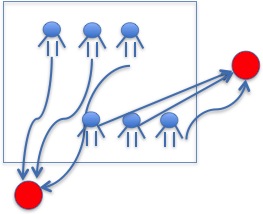
存在问题:为了保护隐私,APP以及微博允许用户关闭位置信息。
3.互补性推荐
用户可能对某一话题的微博感兴趣,同时想要了解其子话题的内容,因此我们可以构建一个话题与子话题的树, 在计算Item相似度的基础上,根据某话题的孩子结点构建推荐列表。
思路1:根据语料构建一个话题树,根据用户的历史浏览数据,搜索话题树向用户推荐子话题
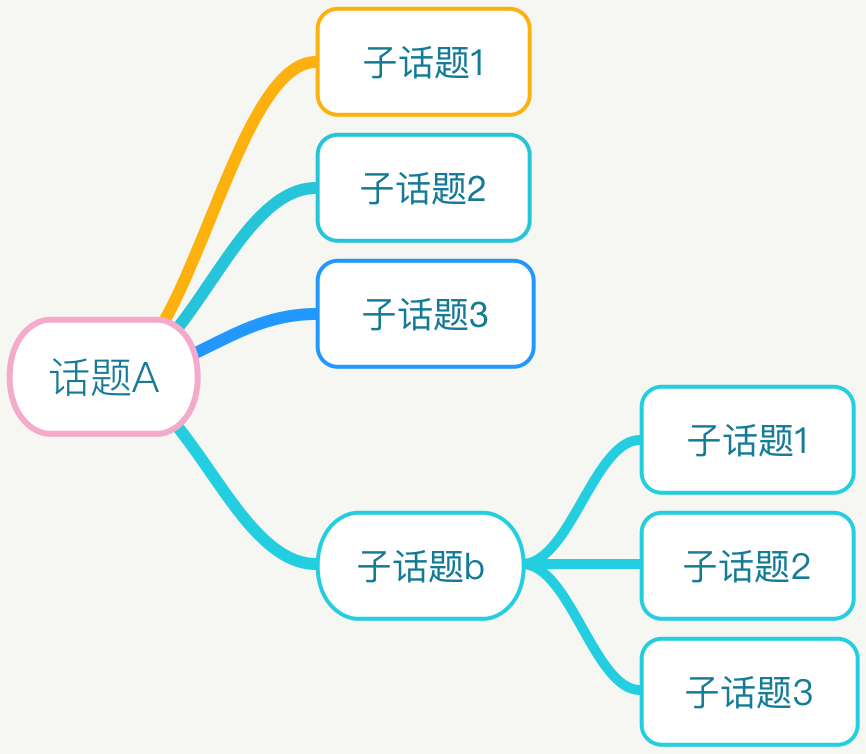
思路2:根据预料和用户历史数据做聚类,不用知道类别的标签,只需要将除去自身其他类别的内容推荐出来。
三、相关数据展示
本数据来源与中华万年历APP部分用户11月份的卡片浏览记录。
下面是中华万年历的截图:

经过统计本数据共有142671个用户, 共有83830个帖子
- 数据1: page_view_data, 记录了用户在11月份的浏览数据
具体数据有以下字段:
dev_id —用户id
stat_date —日期yyyymmdd
stat_time —时间HHMMSS
post_id —卡片/帖子id
type — 1是中华万年历卡片数据,2是lizhi社区数据
stat_view — APP内浏览的次数
stat_click — 点击查看详情的次数
每个用户对同一内容可能会有多次记录,表示用户的多次浏览/查看详情行为
下面是数据部分截图:
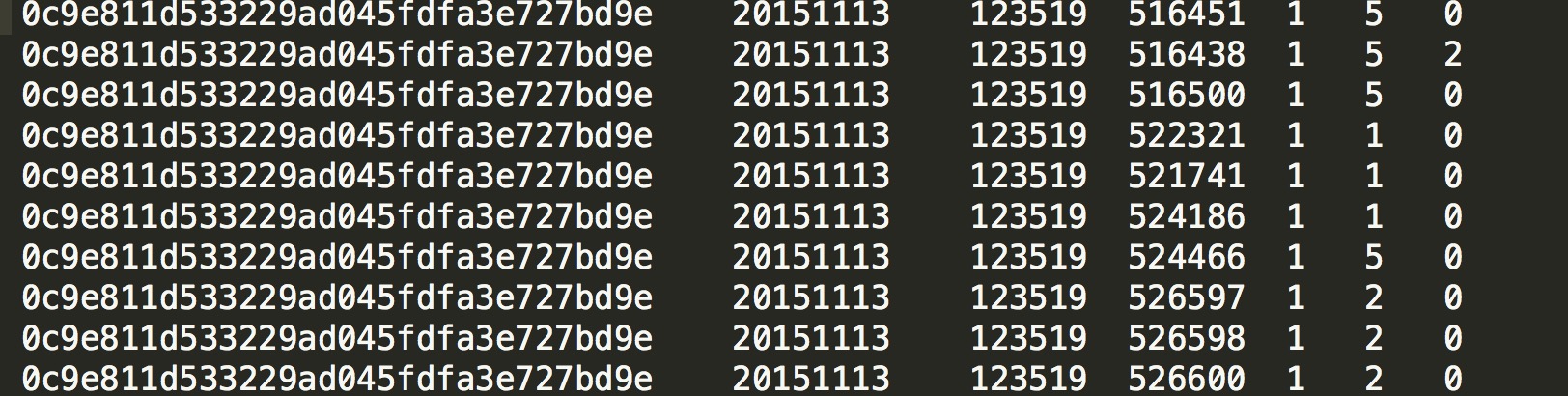
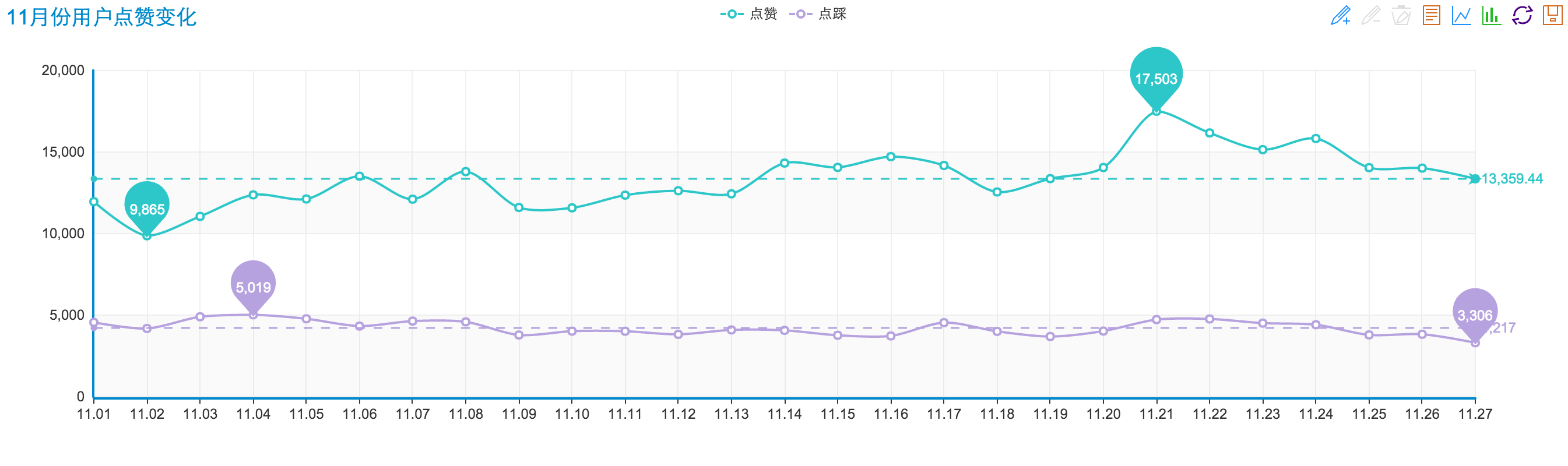
针对此表数据,我做了一些简单的统计分析。
- 数据2:post_data,记录了11月卡片/帖子的具体内容
具体数据有以下字段:
id —帖子id
title —帖子title,可能为空
content --帖子内容
下面是数据部分截图:

基于此数据,我打算建模做一个文本挖掘。
我简单提取了关键词,下面是关键词截图

- 数据3:train,记录了11月份前27天用户的交互记录
具体数据有以下字段:
dev_id —用户id
post_id —卡片/帖子id
praise —1表示赞,2表示踩
time —时间yyyymmddHHMMSS
下面是数据部分截图:
四、目前存在的问题
1. 个人理论知识不足:没有研究过推荐系统,读的论文太少,因此对特定业务数据的如何做推荐,用何种模型都很不清楚。不会抽象。
2.拿到了数据不会分析,或者是分析不到关键点。
