@gyyin
2020-03-14T06:26:22.000000Z
字数 6893
阅读 935
前端开发中的 AOP 和 IOC
慕课专栏
前言
很多前端开发都知道面向对象编程(OOP),却比较少了解 AOP(面向切面编程)这个概念。如果你有使用过 Spring 或者 Nestjs 之类的框架,那就已经接触过 AOP 了。
AOP 是 OOP 的一种补充,前面介绍过的装饰器和 Proxy 都是可以实现 AOP 的一种方式,这也是为什么我把这节放到后面才来讲。
本节课将会重点介绍 AOP(面向切面编程)、IOC(控制反转)和 DI(依赖注入)、Middleware(中间件)相关的概念与实践。
什么是 AOP?
面向切面编程
AOP 是通过预编译方式和运行期动态代理实现在不修改源代码的情况下给程序动态统一添加功能的一种技术。
AOP 实际是 GoF 设计模式的延续,设计模式孜孜不倦追求的是调用者和被调用者之间的解耦,提高代码的灵活性和可扩展性,AOP可以说也是这种目标的一种实现。
在面向对象中,我们强调单一职责原则和封装,于是我们用不同的类来设计不同的方法,这样代码就分散到一个个类中,降低了复杂度,也提高了类的可重用。
class Cat {eat() {}}class Dog {eat() {}}class Duck {eat() {}}
这样看起来很完美,只是有一个问题。那就是如果有一个功能,在所有的类中都需要用到该怎么办?这种设计方式是不是增加了代码的重复性呢?比如我们需要打印出不同动物觅食的信息。
你可能会想到,我再把这部分功能提出来,放到一个新的类 class Logger 里面,在其他类需要的时候调用不就好了吗?
class Logger {log() {}}class Cat {eat() {new Logger().log()}}class Dog {eat() {new Logger().log()}}
可是这样会让不同的类耦合到一起啊,增加了类之间的耦合度。比如哪天删掉了 Logger 类的 log 方法,那么耦合了 Logger 类的所有类岂不是也要跟着一起修改?
好的软件设计不仅需要降低代码复杂度,也应该减少模块之间的耦合度。
那么有没有一种好的办法解决上面的问题呢?怎么才能让我们随心所欲的在代码中增加新的功能呢?
这就要面向切面(AOP)编程登场了。
切面,可以看做是横切进去的一个平面。通常可以将一些与主业务逻辑无关的代码抽离出来,比如日志、鉴权等等,做成一个个切面,每次调用对应方法的时候都要经过这些切面,如下图所示:
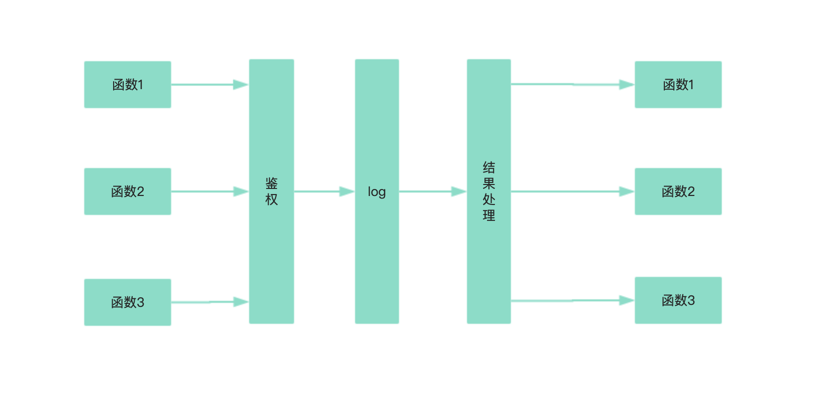
关于如何实现 AOP 没有一种特定的方式,你可以用你喜欢的方式来。
- 用代理模式可以吗?
- 可以。
- 用 Proxy 可以吗?
- 当然可以。
- 用装饰器呢?
- 也可以。
对于面向切面编程,需要关注如下几点:
1. 切面不是 OOP 的替代,而是对 OOP 的一种补充,用于改进 OOP。
2. 切面是主业务之外的、分散在不同类和模块中的横切关注点,即公共部分。
3. 如何从业务中提取出横切关注点是面向切面编程的重要核心。
经典的 before 和 after
针对上面这个例子,可以修改函数的原型,这也是比较常用的一种方式,增加 before 和 after 两个方法。
Function.prototype.after = function (action) {const func = this;return function () {const result = func.apply(this, arguments);action.apply(this, arguments);return result;};};Function.prototype.before = function (action) {const func = this;return function () {action.apply(this, arguments);return func.apply(this, arguments);};};
因此,上面在执行 eat 方法的时候也可以对其进行改造。
const log = () => {}const cat = new Cat();cat.eat = cat.eat.after(log);cat.eat();
代理模式
第一种方法,可以使用代理模式可以解决上面的问题。只需要创建一个代理类,在这个类里面去执行 eat 方法就好了。
class ProxyLogger {constructor(animal) {this.animal = animal;}log() {}eat() {this.target.eat();this.log();}}const proxyCat = new ProxyLogger(new Cat());proxyCat.eat();
即使这个 ProxyLogger 类的 log 方法之后修改了,也不会影响其他几个类的内容。
Proxy
你可能会觉得使用代理模式需要增加新的类,而且每次都要去 new 这个类,不如用 Proxy 试试吧。
通过 Proxy 来代理类上面的 eat 方法,在执行 eat 方法之后去插入执行 log 方法。
const ProxyLog = (targetClass) => {const log = () => {} // log 方法const prototype = targetClass.prototype;Object.getOwnPropertyNames(prototype).forEach((name) => {if (name === 'eat') {prototype[name] = new Proxy(prototype[name], {apply(target, context, args) {target.apply(context, args)log()}})}})}ProxyLog(Cat);new Cat().eat();
可能你会说,我不想只打印 eat 方法的参数啊,我还想打印其他的方法呢?其实这个可以用高阶函数来扩展一下。
const ProxyLog = (targetClass) => (targetFunc) => {const log = () => {} // log 方法const prototype = targetClass.prototype;Object.getOwnPropertyNames(prototype).forEach((name) => {if (name === targetFunc) {prototype[name] = new Proxy(prototype[name], {apply(target, context, args) {target.apply(context, args)log()}})}})}ProxyLog(Cat)('eat');ProxyLog(Cat)('meow');
装饰器
上节课我们讲过 Python 中的登录鉴权的实现,那是使用装饰器来实现 AOP 的一种方式。
def auth(func):def inner(request,*args,**kwargs):v = request.COOKIES.get('user')if not v:return redirect('/login')return func(request, *args,**kwargs)return inner@authdef index(request):user = request.COOKIES.get("user")return render(request,"index.html",{"current_user": user})
装饰器有个好处就是可以使得代码看起来更加简洁、易读。上面的例子用装饰器来实现后就会更加优雅。
const logger = (target, name, descriptor) => {const log = () => {} // 打印信息const func = descriptor.value;if (typeof func === 'function') {descriptor.value = function(...args) {const results = func.apply(this, args);log();return results;}}}class Cat {@logger eat() {}}class Dog {@logger eat() {}}
中间件
如果你有使用过 express/koa 或者 redux 这些技术,对中间件这个概念一定不会陌生吧。
前端的中间件技术类似于可以自由组合、自由插拔的插件机制,你可以使用多个中间件去帮完成一些与主业务无关的任务。
图示为 koa 的洋葱模型:
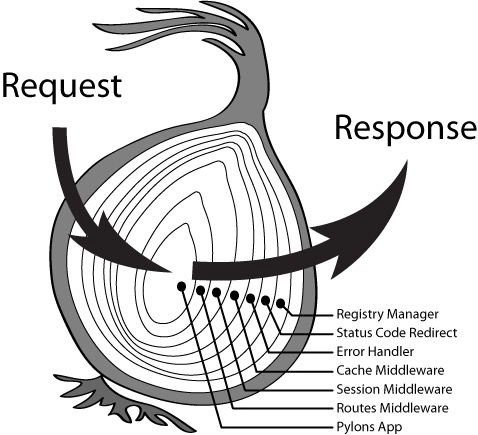
请求进来的时候,会经过一个个中间件方法,这些中间件方法会对请求进行一些处理,然后返回最终的结果,这一点儿和 AOP 很类似。
koa 中间件
以 koa 中的中间件为例子。
一般在初始化 koa 实例后,我们使用 use 方法去加载中间件(middleware),使用数组来保存中间件,中间件的执行顺序决定于 use 的调用顺序。
而每个中间件方法都有 ctx 和 next 两个参数。ctx 代表上下文对象,而 next 则是 koa-compose 定义的中间件方法。
在中间件方法中通过 next 方法可以去执行下一个中间件方法。每个请求进来的时候都会经过 use 中的这两个方法,最终打印出来 1、2、3。
const Koa = require('koa')const app = new Koa()app.use((ctx, next) => {console.log(1)next()console.log(3)})app.use((ctx) => {console.log(2)})app.listen(3000)
这种形式其实和前面讲过的 generator 有一些类似,都是需要去调用 next 才能执行下一步。
redux 中间件
redux 中也提供了中间件的形式,允许你在创建 store 的时候添加中间件去处理每次 dispatch 进来的 action。
比如大名鼎鼎的 redux-logger 和 redux-thunk,前者打印每次 action 的相关信息,后者则是改造了 action,使其支持异步请求。
我们都知道,redux 原本只支持同步的 action。以一个请求为例子,每次请求前设置 loading 状态为 true,请求结束后设置为 false,即:
const open = () => {return {type: 'OPEN',payload: true}}const close = () => {return {type: 'CLOSE',payload: false}}
如果不依赖中间件,该怎么去调用这两个方法呢?可以直接在 react 组件中去调用。
class App extends React.Component {componentDidMount() {this.fetchList();}fetchList = () => {dispatch(open());await fetch('/list');dispatch(close());}}
但是如果应用中很多组件都会用到这个请求,那该怎么办呢?当然可以将这个方法从组件中剥离出来放到公共方法中,但是 redux 提供了中间件去处理这种场景。
// actions.jsconst fetchList = (dispatch) => async () => {dispatch(open());await fetch('/list');dispatch(close());}// App.jsxclass App extends React.Component {componentDidMount() {this.props.fetchList();}}
上面用到的就是 redux-thunk 这个中间件,它对 dispatch 传入的参数进行了处理,使其支持返回一个函数。
redux-thunk 的主要源码如下:
function createThunkMiddleware(extraArgument) {return ({ dispatch, getState }) => next => action => {if (typeof action === 'function') {return action(dispatch, getState, extraArgument);}return next(action);};}
如果传给 dispatch 的是一个函数,那么就将 dispatch、getState 等参数传入并执行。否则就不做处理,直接将 action 传给下一个中间件。
控制反转
在开始之前,先从一个猫吃老鼠的例子说起。
class Cat {constructor() {this.food = new Mice();}eat() {console.log('The cat eats', this.food);}}
上面乍一看是没问题的,这么简单的几行代码会有啥问题呢?
但仔细分析一下,主要问题有这两个:
1. 如果想要修改 food 的生成方式,就要到 Cat 类里面进行修改。
2. 如果 Mice 类初始化比较耗时,那么也会导致 Cat 类初始化耗时。
简单来说,就是 Cat 和 Mice 这两个类互相依赖,耦合到了一起,需要想办法将其分开。
class Cat {constructor(mice) {this.food = mice;}eat() {console.log('The cat eats', this.food);}}
所以可以将实例化的过程放到类外面,传给构造函数,这样两个类就不会耦合到一起了。
IoC(Inversion of Control),中文含义是“控制反转”,它是面向对象编程中的一种设计原则。在软件开发中,IoC 意味着将你设计好的对象交给容器控制,而不是传统的在你的对象内部直接控制。
Promise
前面讲解过 Promise 内容的时候,有提到过信任问题。由于回调函数调用是依赖于第三方模块的,我们无法知道它会被调多少次,这样就可能会出现问题。
// 无法得知 callCamera 的实现callCamera(function() {console.log("调用摄像头成功")})
而 Promise 则是将控制权交到了使用者手里,这样就可以避免受制于第三方模块的实现,我可以自己规定调用几次。
callCamera().then(() => {console.log("调用摄像头成功")})
render props
在 React 里面也有类似控制反转的概念,大名鼎鼎的 render props 就是其中一种。
以轮播图为例子,轮播图主要是渲染其中的图片列表,所以可以这样设计。
<Swiper><img src="x1" /><img src="x2" /><img src="x3" /></Swiper>
但是你无法得知 Swiper 组件会对你传入的 img 怎么做渲染,除非去看源码。但通过 render props 的形式,就可以由你自己控制来怎么渲染这些图片。
<Swiper list={list}renderList={(item, index) => (<img src={item.src} key={item.id} />)}/>
依赖注入
依赖注入和控制反转的关系
来重温一下前面的《Javascript 面向对象精读》这篇文章,我们有提到过“依赖倒置原则(Dependence Inversion Principle)”。
依赖倒置原则要求程序依赖于抽象接口,不要依赖于具体实现。简单的说就是要求对抽象进行编程,不要对实现进行编程,这样就降低了客户与实现模块间的耦合。
从字面意思来理解,控制反转意味着控制权反转,就是将控制权交出去。
那么是哪方面的控制被反转了呢?一个叫 Martin Fowler 的人经过分析得出,获取依赖对象的过程被反转了。
比如上面例子中的 food,原本控制权在 Cat 类里面,修改之后 Cat 将控制权交了出去,获得依赖对象的过程从自身管理变为了由 IOC 容器主动注入。
他给控制反转起了另一个名字,即依赖注入(Dependency Injection)。依赖注入就是在 IoC 容器运行期间将依赖动态的注入到对象中。
redux 中的依赖注入
在 mobx 和 redux 中都有注入的概念,通过 inject/connect 方法,将组件需要的状态和方法都注入进去。
// redux@connect(mapStateToProps, mapDispatchToProps)class App extends React.Component {}// mobx@inject(({ store }) => ({// ...}))class App extends React.Component {}
依赖注入的好处是对外部依赖比较清晰,便于维护。在 nestjs 中到处都能看到依赖注入的实例。
@Module({controllers: [ UsersController ],components: [ UsersService, ChatGateway ],})export class UsersModule implements NestModule {constructor(private usersService: UsersService) {}}
依赖注入的好处就是将两个对象解耦,通过一个 IoC 容器来将依赖的数据注入到另一个对象之中,这个 IoC 容器就起了桥接的作用。
