@gyyin
2019-07-03T06:49:25.000000Z
字数 2169
阅读 626
IS文档
未分类
admin
路由
在urls.py文件中,规定了每个模块的路由,再通过include对每个模块下的路由进行了具体的定义。我们这里主要分析bank模块下的Manage Tokenization/GIRO Transactions和settings模块下的gateway为例子。
bank Manage Tokenization/GIRO Transactions
这里以bank中的Manage Tokenization/GIRO Transactions为例子来讲解一个完整的流程。
首先在bank_giro的urls里面找到对应路由映射的view文件,这里可以找到对应views下的BankGiroTransactionQueryView方法。
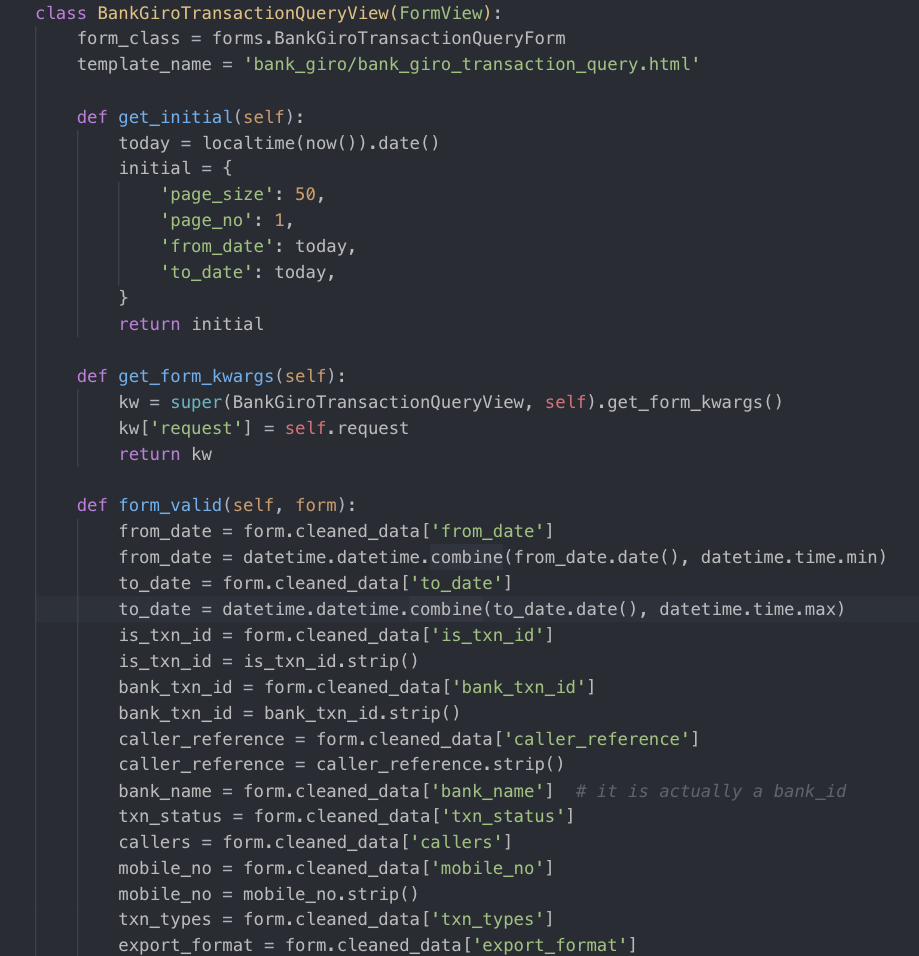
BankGiroTransactionQueryView继承了FormView,这是django提供的表单类,其中挂载了类属性form_class和template_name,这里form_class对应BankGiroTransactionQueryForm类,template_name对应的是要展示出来的html模板文件。
BankGiroTransactionQueryForm类做的事情就是规定了表单的所有字段和类型,对于多选的字段来说,可以在choices里面规定每个选项。
类初始化的时候get_initial方法会被调用,给部分表单字段添加了默认值。
而form_valid方法则是在提交表单的时候,对提交的数据做验证处理。
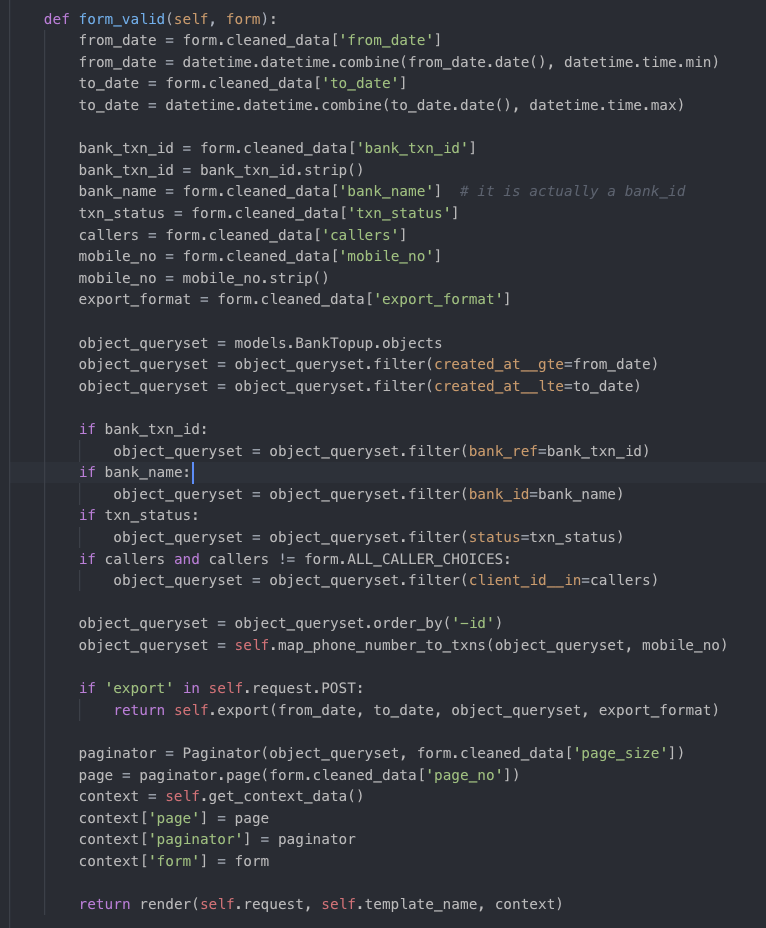
从图上可以明显地看到,这里会通过orm的形式来查询数据库,获取所有的数据,最后根据提交的形式来判断是render一个表单,还是返回一个表单文件。
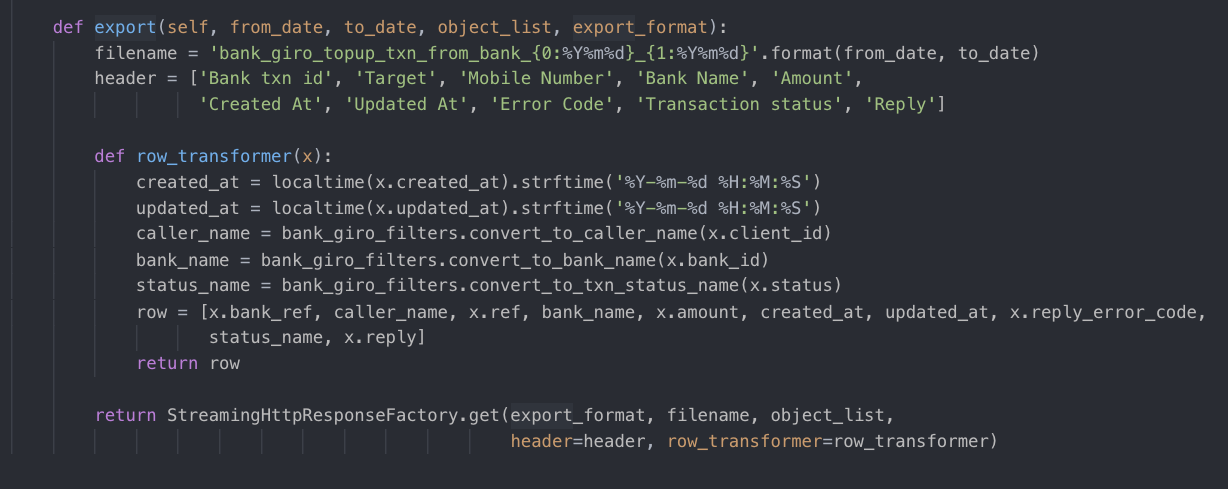
如果是导出一个表单,这里会根据export_format字段来判断导出excel还是csv格式的文件,最后调用了StreamingHttpResponseFactory方法。
StreamingHttpResponseFactory内部判断是调用CsvStreamingHttpResponse还是ExcelStreamingHttpResponse。
以ExcelStreamingHttpResponse为例子,它继承了CsvStreamingHttpResponse类。
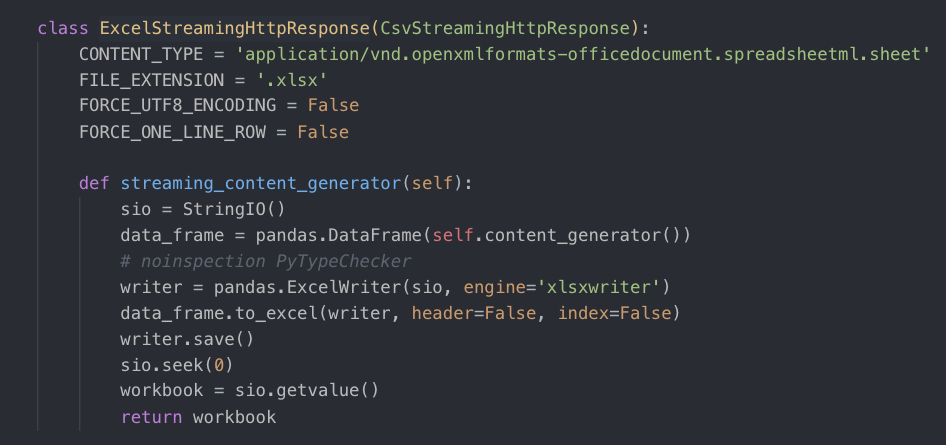
这里会规定文件的后缀名和编码,以及文档类型等等。
可以看到CsvStreamingHttpResponse在初始化的时候会调用父类的init方法,并设置了filename、header、rows等等属性,以及调用streaming_content_generator方法。
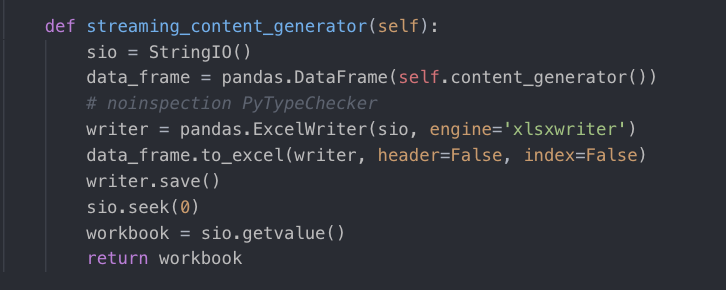
这里streaming_content_generator已经被ExcelStreamingHttpResponse重写,这里调用content_generator,content_generator里面又调用了row_transformer方法,对rows数据进行转换,得到所有的rows数据,最后streaming_content_generator方法中调用一个IO,将rows写入到文件中并返回。
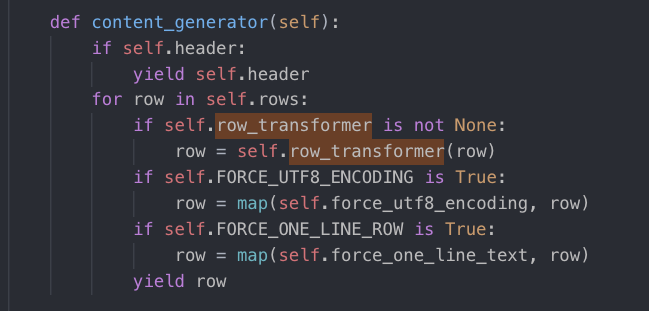
增删
如果想要在文件中增删一列新的属性,这里需要在export方法的header里面进行定义。
Gateway Manage
Gateway Manage主要是展示一个列表,可以对列表数据进行编辑,并更新到数据库中。
我们从urls中找到了对应的方法在GatewayListView类中,这个类上挂载了model、template_name、title,渲染起来非常简单,在模板文件中平铺数据,并对编辑按钮绑定了接口操作。
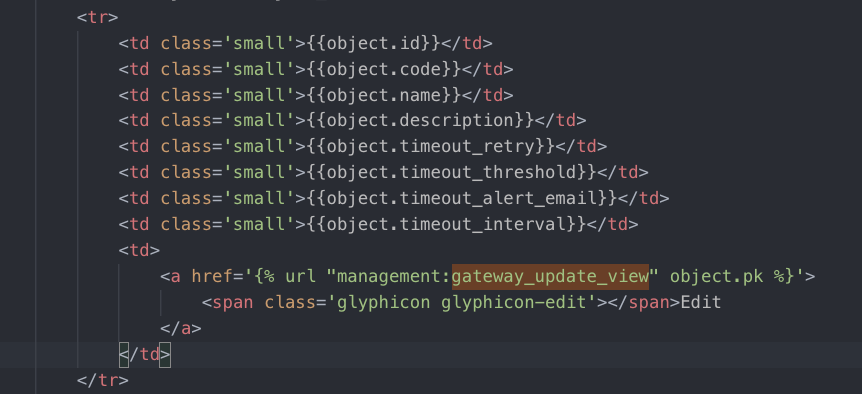
可以看到编辑的时候调用了另一个接口gateway_update_view,GatewayUpdateView中依然挂载了对应的model和template文件,最后有个表单验证方法,总之这个模块相当简单,不再多说。
vendor
vendor的项目比较简单,我们以测试环境的Third Party Services模块为例子。
首先找到ACS Bill Offline Reconciliation对应的view类ACSBillOfflineReconciliationView, 这些挂载方法和上面的admin基本一样,不再多说,主要分析form_valid这个方法。
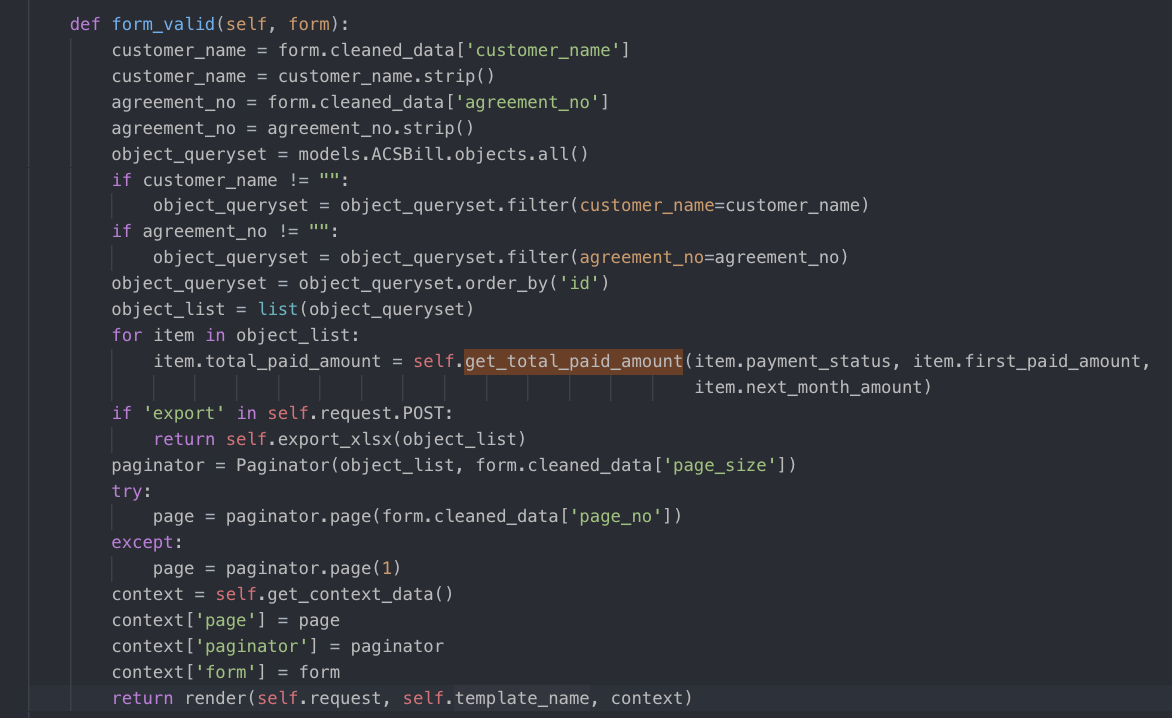
如果传入了customer_name就按customer_name查询,如果传入了agreement_no,就按agreement_no来查询。
如果只是search操作,那就把查询到的数据返回给模板,渲染出来。
如果是export操作,那么就会调用export_xlsx函数。
export_xlsx里面返回一个http应答头,规定了content_type,本地化了一下当前的时间。
xlsxwriter.Workbook创建一个新的excel文件,self.workbook.add_worksheet创建了一个工作表,写入了当前的行头row。
遍历数据库列表数据后,将数据一条条写入excel文件中并保存,最后返回这个应答。
ps:这里后端是从数据库拿到所有的数据,在Paginator里面做的分页功能,本质上每次还是查询的全量数据(感觉这里的实现不太好,没必要每次都查全量数据)。
参考链接
1. XlsxWriter的使用
