@gyyin
2020-03-14T07:45:44.000000Z
字数 7067
阅读 1087
策略模式和表驱动优化你的条件语句
慕课专栏
1. 前言
在高级语言中,基本上都提供了 if else 和 switch case 这样的条件语句。在写程序的时候,常常需要指明两条或更多的执行路径,而在程序执行时,允许选择其中一条路径,或者说当给定条件成立时,则执行其中某语句,这就是条件语句的作用。
2. if else的问题
在我们平时的开发中, if else 是最常用的条件判断语句。在一些简单的场景下, if else 用起来很爽,但是在稍微复杂一点儿的逻辑中,滥用 if else 就会导致项目的可读性和可维护性大大降低。
试着想一下,如果系统中出现了一种新的情况,那么就要在原有的代码上面继续增加 if else 。这样恶性循环下去,原本只有几个 if else 最后就有可能变成十几个,甚至几十个。
知乎上有个专门吐槽这种现象的问题:为什么很多程序员不用 switch,而是大量的 if...else?
总结了一下,个人认为 if else 的主要问题就是下面这两条:
- 数据和实现逻辑是耦合的
- 无法做到对于扩展是开放的,但是对于修改是封闭的
3. 改善 if else
3.1 短路符号和三元表达式
对于简单场景下的 if 语句,我们还可以用短路符号来代替,例如:
// oldif (isSuccess) {success();}// newisSuccess && success();
我们甚至可以用三元符号来代替 if else 。不过需要注意的是,大量的三元符号容易影响代码的可读性。
// oldif (isSuccess) {success();} else {fail();}// newisSuccess ? success() : fail();
3.2 提前结束
如果每种条件下的代码逻辑比较多,也可以考虑提前跳出来结束函数,例如:
// oldfunction trafficLight(light) {if (light.color === 'red') {red();} else if (light.color === 'green') {green();} else {yellow();}}// newfunction trafficLight(light) {if (light.color === 'red') return red();if (light.color === 'green') return green();yellow();}
提前结束在比较复杂的实现逻辑下非常适合,假设在每种条件下都要做一堆逻辑处理,往往 else 和 if 都会隔了很多行,可读性很差。但如果是提前 return 出来,那我们就很容易知道当前是在哪种条件之下。
3.3 switch case
switch case 是语言自身提供的另一种条件语句。 switch 和 if 在本质上并没有区别,只是代码会更加简洁。
function trafficLight(light) {switch (light.color) {case 'red':red();break;case 'green':green();break;default:yellow();}}
也许这种场景下体现的会更加明显。
// badif (age === 10 || age === 20 || age === 30 || age === 40) {test();}// goodswitch(age) {case 10:case 20:case 30:case 40:test();}
但是 switch case 也无法解决多个相似条件下需要写多次的问题。
4. 策略模式
策略模式是我们比较常用的设计模式,其实策略模式也无法从根本上消除 if else 的使用,毕竟我们还是要判断应该实例化哪个策略类。
策略模式的作用在于将条件和实现逻辑分离,定义一个个算法,把它们一个个封装起来,并且使它们可相互替换。如果功能发生了变动,只需要修改对应策略方法就行了,这样避免了直接在 if else 里面修改代码。
在使用策略模式时,我们会创建不同的策略类,会根据条件通过 context 来加载不同的策略对象,继而在 context 中调用该策略对象的行为方法。
以下面这个红绿灯为例:
class RedLightStrategy {doAction() {red();}}class GreenLightStrategy {doAction() {green();}}class YellowLightStrategy {doAction() {yellow();}}class Context {constuctor(strategy) {this.strategy = strategy;}executeStrategy(){return this.strategy.doAction();}}function trafficLight(light) {let context = null;if (light.color === 'red') {context = new Context(new RedLightStrategy)} else if (light.color === 'green') {context = new Context(new GreenLightStrategy)} else {context = new Context(new YellowLightStrategy)}context.executeStrategy();}

因为这个例子过于简单,所以从代码上看,策略模式是绕了一个弯子。
但如果我们在每种条件下不仅仅是调用 red 、 green 、 yellow 方法呢?如果每种场景都要做更复杂的操作呢?那策略模式就能够避免对 trafficLight 中的代码进行直接修改了。
实际上这里更适合用状态模式和状态机,关于这些后面专门有一篇文章会做讲解。
5. 表驱动法
5.1 从例子说起
假如我们要做一个日历组件,那我们肯定要知道一年12个月中每个月都多少天,这个我们要怎么判断呢?最笨的方法当然是用 if else 啊。
if (month === 1) {return 31;}if (month === 2) {return 28;}...if (month === 12) {return 31;}
这样一下子就要写12次 if ,白白浪费了那么多时间,效率也很低。这个时候就会有人想到用 switch case 来做这个了,但是 switch case 也不会比 if 简化很多,依然要写12个 case 啊!!!甚至如果还要考虑闰年呢?岂不是更麻烦?
我们不妨转换一下思维,每个月份对应一个数字,月份都是按顺序的,我们是否可以用一个数组来储存天数?到时候用下标来访问?这样是不是看着就要简单多了。
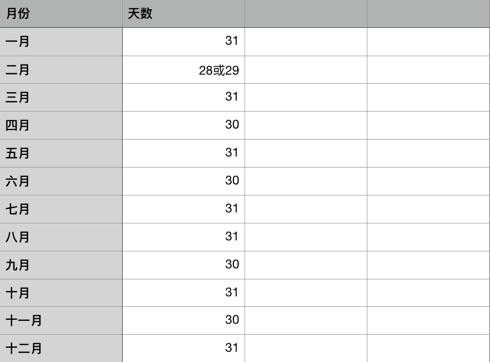
const month = new Date().getMonth(),year = new Date().getFullYear(),isLeapYear = year % 4 == 0 && year % 100 != 0 || year % 400 == 0;const monthDays = [31, isLeapYear ? 29 : 28, 31, ... , 31];const days = monthDays[month];
我们再来看一下我们介绍 switch case 时的那个 age 的问题,如果用数组保存多个 age,在判断当前值是否在数组中,这样是不是也很清晰?
// badif (age === 10 || age === 20 || age === 30 || age === 40) {test();}// goodconst ages = [10, 20, 30, 40];if (ages.indexOf(age) >= 0) {test();}
5.2 概念
看完上面的例子,相信你对表驱动法有了一定地认识。这里引用一下《代码大全》中的总结。
表驱动法就是一种编程模式,从表里面查找信息而不使用逻辑语句。事实上,凡是能通过逻辑语句来选择的事物,都可以通过查表来选择。对简单的情况而言,使用逻辑语句更为容易和直白。但随着逻辑链的越来越复杂,查表法也就愈发显得更具吸引力。
使用表驱动法前需要思考两个问题,一个是如何从表中查询,毕竟不是所有场景都像上面那么简单的,如果 if 判断的是不同的范围,这该怎么查?
另一个则是你需要在表里面查询什么,是数据?还是动作?亦或是索引?
基于这两个问题,这里将查询分为以下三种:
- 直接访问
- 索引访问
- 阶梯访问
5.3 直接访问表
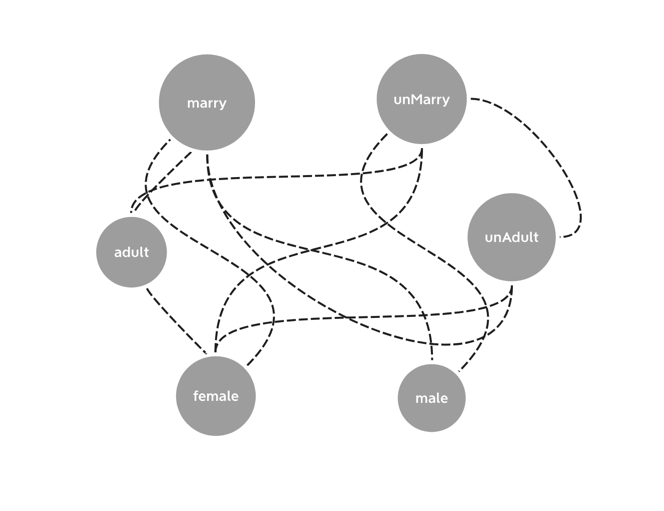
假设你在写一个保险费率的程序,这个费率会根据年龄、性别、婚姻状态等不同情况变化,如果你用逻辑控制结构(if、switch)来表示不同费率,那么会非常麻烦。
if (gender === 'female') {if (hasMarried) {if (age < 18) {//} else {//}} else if (age < 18) {//} else {//}} else {...}
我们的代码就像下面这张图一样乱七八糟的:
但是从上面的日历例子来看,这个年龄却是个范围,不是个固定的值,没法用数组或者对象来做映射,那么该怎么办呢?这里涉及到了上面说的问题,如何从表中查询?
这个问题可以用阶梯访问表和直接访问表两种方法来解决,阶梯访问这个后续会介绍,这里只说直接访问表。
有两种解决方法:
1、复制信息从而能够直接使用键值
我们可以给 1-17 年龄范围的每个年龄都复制一份信息,然后直接用 age 来访问,同理对其他年龄段的也都一样。这种方法在于操作很简单,表的结构也很简单。但有个缺点就是会浪费空间,毕竟生成了很多冗余信息。
2、转换键值
我们不妨再换种思路,如果我们把年龄范围转换成键呢?这样就可以直接来访问了,唯一需要考虑的问题就是年龄如何转换为键值。
我们当然可以继续用 if else 完成这种转换。前面已经说过,简单的 if else 是没什么问题的,表驱动只是为了优化复杂的逻辑判断,使其变得更灵活、易扩展。
enum ages {unAdult = 0adult = 1}enum genders {female = 0,male = 1}enum marry = {unmarried = 0,married = 1}const age2key = (age) => {if (age < 18) {return ages.unAdult}return ages.adult}type premiumRateType = {[ages]: {[genders]: {[marry]: {rate: number}}}}const premiumRate: premiumRateType = {[ages.unAdult]: {[genders.female]: {[marry.unmarried]: {rate: 0.1},[marry.married]: {rate: 0.2}},[genders.male]: {[marry.unmarried]: {rate: 0.3},[marry.married]: {rate: 0.4}}},[genders.adult]: {[genders.female]: {[marry.unmarried]: {rate: 0.5},[marry.married]: {rate: 0.6}},[genders.male]: {[marry.unmarried]: {rate: 0.7},[marry.married]: {rate: 0.8}}}}const getRate = (age, hasMarried, gender) => {const ageKey = age2key(age);return premiumRate[ageKey]&& premiumRate[ageKey][gender]&& premiumRate[ageKey][gender][hasMarried]}
这样,一旦判断条件出现了变化,这里只需要修改 premiumRate 里面的数据就好了。
但是觉得这个例子举得还是不够好,将代码修改为如下会更容易理解一些。
const Age = {0: "unAdult",1: "adult"}const Gender = {0: "female",1: "male"}const Marry = {0: "unMarried",1: "married"}const rateMap = {[Age[0] + Gender[0] + Marry[0]]: 0.1,[Age[0] + Gender[0] + Marry[1]]: 0.2,[Age[0] + Gender[1] + Marry[1]]: 0.3,[Age[0] + Gender[1] + Marry[0]]: 0.4,[Age[1] + Gender[0] + Marry[0]]: 0.5,[Age[1] + Gender[0] + Marry[1]]: 0.6,[Age[1] + Gender[1] + Marry[1]]: 0.7,[Age[1] + Gender[1] + Marry[0]]: 0.8,}const isAdult = (age: number) => age >= 18 ? 1 : 0const getRate = (age, hasMarried, gender) => {age = isAdult(age)return rateMap[Age[age] + Gender[gender] + Marry[marry]]}
这样才是正确的打开方式。
5.4 索引访问表
我们前面那个保险费率问题,在处理年龄范围的时候很头疼,这种范围往往不像上面那么容易得到 key。
我们当时提到了复制信息从而能够直接使用键值,但是这种方法浪费了很多空间,因为每个年龄都会保存着一份数据,但是如果我们只是保存索引,通过这个索引来查询数据呢?
假设人刚出生是0岁,最多能活到 100 岁,那么我们需要创建一个长度为 101 的数组,数组的下标对应着人的年龄,这样在 0-17 的每个年龄我们都储存 '<18',在18-65储存 '18-65', 在65以上储存 '>65'。这样我们通过年龄就可以拿到对应的索引,再通过索引来查询对应的数据。
看起来这种方法要比上面的直接访问表更复杂,但是在一些很难通过转换键值、数据占用空间很大的场景下可以试试通过索引来访问。
const ages: string[] = ['<18', '<18', '<18', '<18', ... , '18-65', '18-65', '18-65', '18-65', ... , '>65', '>65', '>65', '>65']const ageKey: string = ages[age];
5.5 阶梯访问表
同样是为了解决上面那个年龄范围的问题,阶梯访问没有索引访问直接,但是会更节省空间。
为了使用阶梯方法,你需要把每个区间的上限写入一张表中,然后通过循环来检查年龄所在的区间,所以在使用阶梯访问的时候一定要注意检查区间的端点。
const ageRanges: number[] = [17, 65, 100],keys: string[] = ['<18', '18-65', '>65'],len: number = keys.length;const getKey = (age: number): string => {for (let i = 0; i < len; i++) {console.log('i', i)console.log('ageRanges', ageRanges[i])if (age <= ageRanges[i]) {return keys[i]}}return keys[len-1];}
5.6 表驱动的力量
恰好我在微信群里面看到过这样一个问题,这是表驱动法的一种典型应用场景。

我们将360度分为八个方向,分别是 0-45、46-90、91-135 等等依次类推。
这个我们应该怎么做呢?恐怕我们最先想到的就是用 if 进行判断了。
if (degree < 45) {} else if (degree < 90) {} else if (degree < 135) {// 一直到360}
如何用表驱动的思想来解决呢?这恰好又是我们上面说的如何从表中查询的问题,关键点在于如果把 0-45 这个范围给映射成一个常量,我们只需要定义一个转化规则,那么就很方便的使用对象来管理我们的执行函数了。
这个例子中的转化规则就是通过观察是否在两个临界值之间,判断当前属于哪个key 值。
const keys = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H'],range = [45, 90, 135, 180, 225, 270, 315, 360];const degree2key = (age) => {const len = range.length;for (let i = 0; i < len; i++) {if (age <= range[i]) {return keys[i];}}}const map = {'A': () => {},'B': () => {}}map[degree2key(45)]();map[degree2key(36)]();
也许这段代码你看起来会比较更难理解一些,其实这就是阶梯访问表的形式。表驱动最大的意义就是将条件判断(数据)和逻辑剥离分开,将条件用可配置的表(对象 or 数组)来管理,也可以消除 magic number。
引用知乎大V Ivony 的一段话:
分析和阅读一段代码的时候,很多时候是有侧重面的,有时候侧重于数据,有时候侧重于逻辑。假设我们有这样一个需求,当某某值小于100时,就如何如何。那这个里面的100就是数据,当需求变更为某某值小于200时,才如何如何,那么我们关注的点在于这个数据的修改。而不是整个逻辑的修改,数据的剥离,有助于我们更快的发现修改点和修改代码。
6. 总结
这节我们介绍了很多优化 if else 的方法,这些方法没有哪一种是最好的,在不同的场景下我们应该合理的选择方法。
在简单场景下,应该优先使用 if else 来做,对于稍微复杂的场景,可以用 switch case 来让代码更加简洁,而对于很复杂的场景,可以考虑使用表驱动法和策略模式来将判断逻辑和代码实现分开维护。
