@changedi
2017-01-08T14:00:25.000000Z
字数 4848
阅读 4151
当下流行架构中的一些技术思考
ArchSummit
本文首发于阿里云云栖社区,具体地址参见:https://yq.aliyun.com/articles/66549
时间:2016.12.2-2016.12.3
地点:北京ArchSummit会场
人物:行业内的讲师&参会人员
总体趋势
ArchSummit全球架构师峰会,在初冬的北京举行。我们一伙人奔着雾霾和技术前沿的理想追逐而去。我先聊聊这次的一个整体情况。两天行程,安排了密密麻麻的专题和演讲,但是总结来看,基本上是云计算、大数据、微服务、和高可用架构实践。相比2015,机器学习和大数据应用的内容开始变多。
具体包含的topic范围包括:(我认为的热点)
架构设计
- 实时处理(也算是大数据处理):主要是消息处理+流计算
- 高可用
- 微服务
- 云平台&云服务
- 双11
架构是永恒的话题,因此基本涵盖面比较广,内容也杂。
行业架构
- 广告&新闻
- SNS&直播
- 电商
- FinTech
实践类
实践类内容以技术热点为主,docker大热,2016智能元年。so
- docker和容器实战
- 机器学习实战
有趣的topic
个人原因,主要关注在大数据和算法应用的场景,因此更多的从这几个角度聊聊我个人觉得有趣的topic。
大数据
听了Linkedin,Facebook,百度和腾讯几个在大数据方向的分享,分别从通用和具体场景的角度,分享了各自的大数据场景,但是都主要集中在实时计算的场景下。这从侧面也看到离线批处理已经是一个稳态架构了,几乎是个大数据场景都会有自己的离线Hadoop集群。
LinkedIn的Kartik分享了一个架构图,我借鉴来说一下实时大数据大概在做的事情,下面关于大数据的内容也围绕Kartik这个分享来展开。
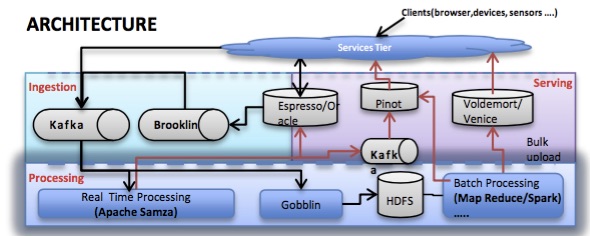
核心组件就三部分:消息组件、流计算组件和一个可供读写的外部存储组件。消息组件是Kafka,流计算组件是Samza,存储组件的话depends,分别从几种状态需求的角度下分析了remoteDB和Samza本地状态存储用到RocksDB的选型需求。Facebook类似,消息Scribe,计算组件Puma、Stylus和Swift,存储用HBase。百度的spider 3.0系统,也有类似的实时架构,不过百度的侧重点在广告其存储组件Tera(其自己的BigTable)和BFS。腾讯消息组件是TDBank,计算组件为JStorm,状态存储使用HBase。
我们现在的很多业务场景,基本都面临着大数据的挑战,在架构选型时也都有各种考量点,集团内部也对应有MetaQ对标Kafka做消息中间件,Galaxy和JStorm做流计算。那么实时场景得到的架构设计启示是什么呢?首先是场景match,数据源要是流式的设计,对应的是批量计算。如果你的数据源不具备流式特性,那么请绕道。对于流式数据源——消息中间件,对比几个大厂的流行组件来看,也有一些架构特点。
消息中间件,我们看什么?kartik提了三点:Partition Aware、Ability to Replay、Portable across Cloud。分别对应可分区、可重放和云化,当然这是从设计角度出发看的。我说几点应用层面我的理解
| 思考项 | 思考点 |
|---|---|
| 性能 | 读写能力,消息队列不是当存储用的,是当buffer用的,要写也要读。读写能力当然都是越高越好。但是性能也经常要和其他功能性设计做trade off,纯粹的高性能,往往是要牺牲些易用性、可靠性等。Kafka单机如此高性能,也是有其日志场景的考虑在的(咱不也有TT吗)。btw,单机百万和单机十万,又有多少场景需要区别这么清楚呢? |
| 可靠性 | 数据可不可以丢。数据持久化基本大家都会做,但是持久策略不同(比如同步异步等)对于可靠性的保障不一样,场景需求什么样?这个要想清楚。 |
| 重复消费 | 实在不行就要replay追数据,数据回溯很重要 |
| 实时性 | 这个基本上多数场景是可以容忍部分延时的,毕竟消息队列已经异步化了,0延时就选择同步。对于MQ的老话题就是push or pull |
| 保序 | 这个往往是业务角度致命的考量,因为很多消息中间件对于这个是个01问题,要么支持,要么不支持。 |
| 成本 | 这是亘古不变的选型考虑,也是要重点去想的。当然kartik提出的云化的考量,也对云服务本身提出要求。在不同scale下的选型,也有指导了。 |
有了流形数据源,处理就成了最关键的步骤。无论是几年前的Storm,还是现在五花八门的流计算组件,对于业务的思考,我觉得可以参考Linkedin的分享中的一些思想来定义——对于流计算来说,有状态和无状态是根本性差异的。无状态简单的场景,这里我不讨论。对于有状态的设计,中间状态存储成了关键。细节的一些内容可以参考集团Galaxy的设计,看看仙隐这篇分享:http://www.atatech.org/articles/49835
Kartik在slide里也讲了流计算的难点所在:
1. 性能,这里的瓶颈在I/O,读写外部数据、中间态维持都是消耗点。
2. 稳定性,如何解决反压。
3. 多源,这个好像不是什么问题。
4. 准确性,这个没明白是否想说流计算的once语义。可是记得当时会场听到的内容,又好像是说多DC高可用的感觉。
5. 重复处理(这点好像是实时场景的通用需求),这个作者举了个很好的例子,结合机器学习算法的一些model是我们流计算的未来主战场,而model在update后,如何重新处理,这个很重要。
针对这些,Linkedin引入RocksDB和Brooklyn来解决读写外部数据。Samza通过在Yarn管理任务和容器的mapping关系,来保证每个数据源分区数据在task和container的映射是正确的。而所有的这些task中间数据都会落到Kafka的log里。这点其实在Galaxy的设计里,集团的同学也考虑到了。
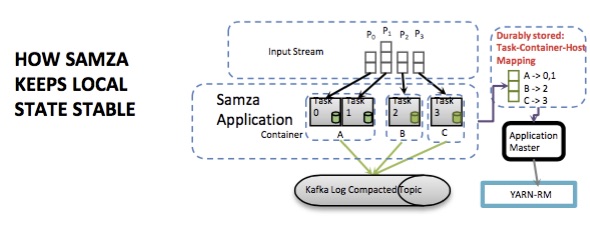
Samza还有很多其他特点,在作者的slide中介绍较多,我就不赘述翻译了。
总体上来看,流计算的几点挑战,也是我们应用业务进行选择时的考虑点。尤其是流计算在实时性和准确性的trade off是天生的。当需要精确处理exactly-once语义支持时,选型或者实施难度会更大,这点从业务端系统能做哪些事来规避,也是要有“旁光”能看穿的架构师本领之一。有时候,你看上去实时的场景,可能不一定要用实时流计算引擎。比如,比较刺激我的Tencent OMG广告系统的分享,其中session数据的处理,就面临着长窗口期和乱序的问题,而技术同学通过“玩转”HBase解了这个业务问题。这部分可以从文末下载腾讯OMG广告技术的slide来看。
智能技术
另一部分我个人认为很好玩也感兴趣的点,就是智能技术了(偏算法的东西只能这么叫了,惭愧厚颜的贴向了“智能”的标签)
搜索和推荐
先讲讲一点资讯的搜索和推荐融合。一点资讯田明军谈到搜索和推荐的区别和联系,在他们的应用场景里,是一个典型的分层架构。数据从三个地方采集,构成数据存储层。这层是一个抽象层,其中不仅仅是存储,也配合有存储采编相关的一些应用系统,属于内部管控系统。在上层建立异构索引,为搜索提供通道。再利用搜索的技术,构建了更上层的搜索和推荐的流式服务框架,为最上层app服务。
其技术亮点有如下几个:
- 异构索引结构(多源多存储多策略)
- 统一feeder(通过配置做到自适应各种源)
- 自适应索引召回(意图识别路由)
- 排序框架(online learning)
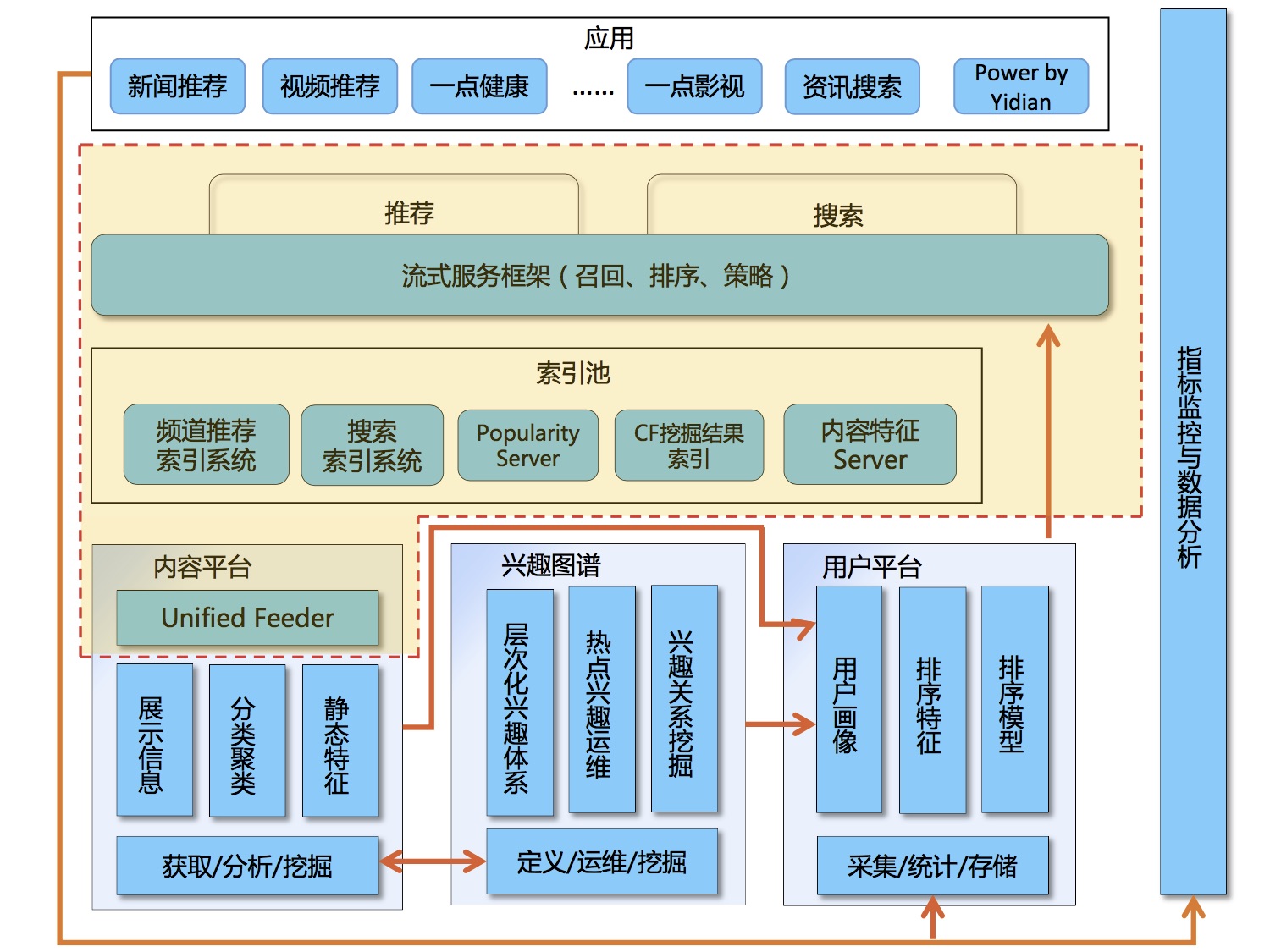
这个topic听着是很有感觉的,因为这和我当前做的事情很多思路是一致的。我们目前的产品也是要以搜索为依托来做服务。topic本身亮点之处在于异构索引不是一个针对“索引”的优化或深挖,而是利用nosql、列存等多种数据库能力来补足倒排索引的能力,建立一个通用的data access layer。slide后面的几点其实就是技术包装了,所谓自适应feeder,其实就是通过模板配置,不算真正的自适应。而自适应的索引召回里提到了意图识别,意图分析模块看样子是融合了profile和context的一个分组逻辑策略。可以根据不同的入参来路由query builder,建立不同的意图对应后面走不同的索引。这里提到了意图的兴趣图谱,不过作者没有细说。online learning部分,是利用storm做的参数服务器,这个可能和集团搜索早期的PS实现类似,而我们现在的PS能力已经远远走在前面了。搜索的pora已经进化为Porsche,具体可以参考毅行的这篇文章http://www.atatech.org/articles/23329
最后再提一下一点资讯所谓的流式处理框架,其实是一个基于akka和spray的workflow。其主要目的也是为了服务当前架构,与通用的流计算不一样,属于自定义流式服务。与我们当前系统中的很多pipeline类似。
机器学习
这次Archsummit有一个机器学习实战专题,海清分享了小蜜,腾讯也分享了微信的lookalike算法,偏算法层面的东西还是不太多。平台的话,我倒是对胡时伟的企业机器学习topic比较感兴趣,也对第四范式现在的工作希望了解一下,于是就去听了这个topic。
第四范式基于GDBT计算框架做了很多工作,类似参数服务器,但能力不仅如此,实现上,从架构图看,参数也是在HQueue存储。从目标上看,也是要做开放式平台,无需关注分布式细节,与Porsche的定位倒是有几分相似。当然这个定位应该是第四范式整体产品平台先知Prophet的定位。从其架构上来看,就是利用多源丰富的计算平台能力,将计算封装,暴露函数接口给算法开发人员。
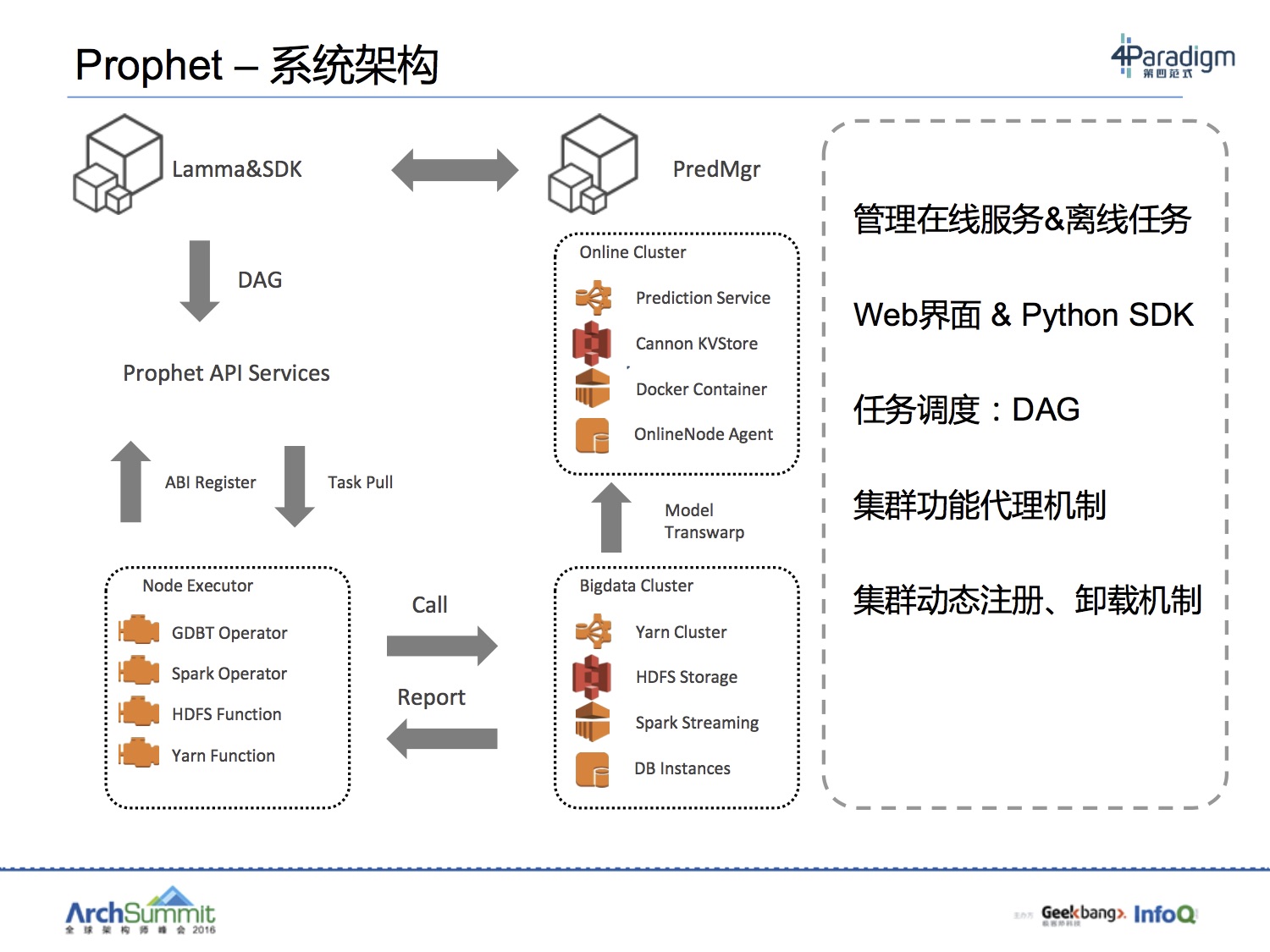
这样的平台我认为对比现有集团的产品,PAI也好,Porsche也好,mpi也好亦或odps也好,算法应用方在实现算法落地时,从需求上来说,应该是全覆盖。prophet的界面类似PAI,我就以PAI为例来说,作为PAI,提供了比较全的算法覆盖和友好的DAG以及界面。但是算法组件使用要依赖平台提供,Porsche比较好的放大了能力,但是门槛又会高一点。其中这些具体trade off,就集团现状来说,我们已经可以通过各种平台的交叉使用,达到自己的目的,但是真的说起体验和效率,我觉得路还很长。
本来期待听一些Transfer Learning的东西,不过胡时伟讲得更偏向工程,在算法端只是一笔带过。
prophet也提到了一些模型生命周期管理和特征工程的支持。这些工作也往往占据了技术人员70%-80%的时间。如何在这些方面去优化工具,改进体验。也是很有价值的。
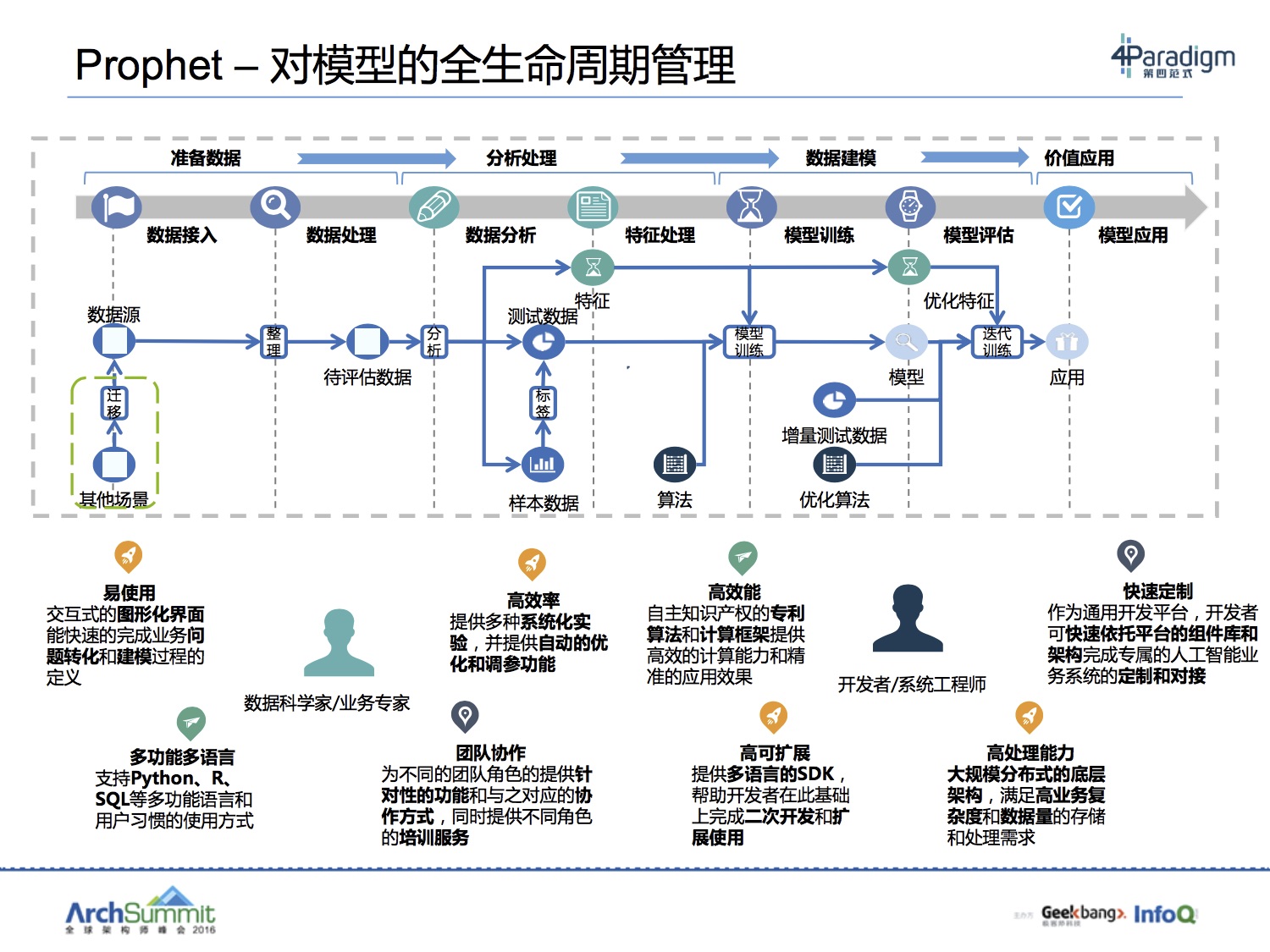
以现有的平台能力结合我们现在的工作来分享一下,集团的各种产品现在在慢慢趋向智能化,越来越多的产品背后都有简单或者复杂的ML算法逻辑,以我们当前的场景为例。我们要做文本挖掘和自动标签等工作,除了一些基础NLP算法,在PAI平台上我们在大量的实验LDA和kmeans,以及一些图聚类的算法。面临的一个主要问题是workflow虽然可以快速搭建好(这个要赞PAI的易用性和交互),但是很快会陷入如何调优达到目标结果的炼丹困境。如果local环境实验好,又涉及到local的个性化算法迁移到生产ODPS的囧境。算法的过程不仅仅是选个算法去调参的问题,特征构建和数据处理很关键,而在这一块,群策群力大家有好的特征和数据其实可以共享共建,算法因为通用所以抽象出来平台化,那么好的样本和特征是否也可以这样呢?期待未来的方向。
写在最后
技术的浪潮,时刻都在向前奔涌。大数据的生态还在迅速演变,智能技术的口号已经喊得让人耳朵都听出老茧。作为一个技术人员或者是架构设计者,更多的还是需要以结果为导向,不要被技术组件桎梏。然而也要时刻警醒自己的是,有时候了解和掌握了技术的当前能力、趋势和未来想象力,会成为你去拿到更好更大结果的保证。
Ref
部分slides可见:ppt@ArchSummit 2016 北京
